案例1(方差分析)
完全随机分析
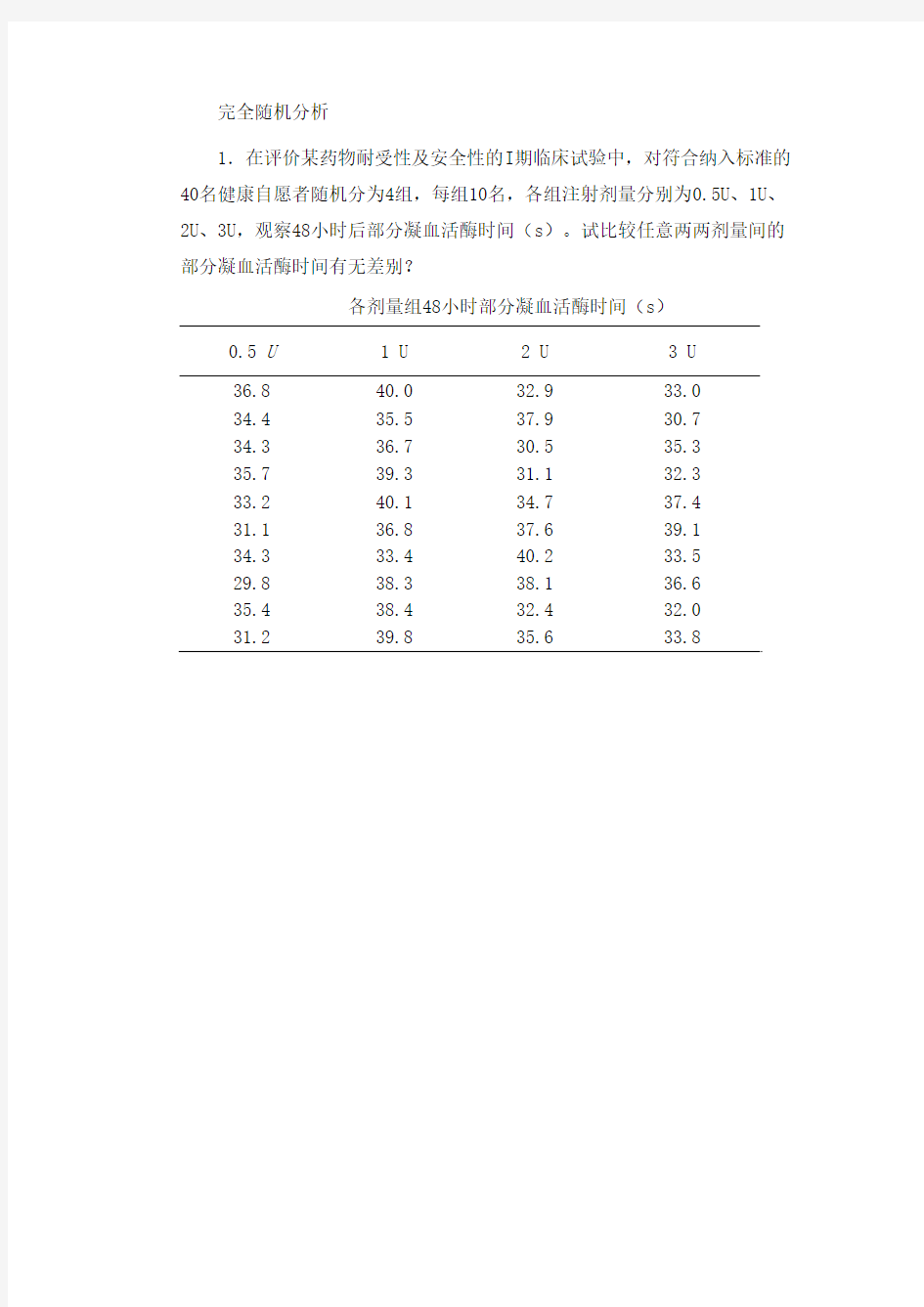
1.在评价某药物耐受性及安全性的I期临床试验中,对符合纳入标准的40名健康自愿者随机分为4组,每组10名,各组注射剂量分别为0.5U、1U、2U、3U,观察48小时后部分凝血活酶时间(s)。试比较任意两两剂量间的部分凝血活酶时间有无差别?
各剂量组48小时部分凝血活酶时间(s)
0.5 U 1 U 2 U 3 U
36.8 40.0 32.9 33.0
34.4 35.5 37.9 30.7
34.3 36.7 30.5 35.3
35.7 39.3 31.1 32.3
33.2 40.1 34.7 37.4
31.1 36.8 37.6 39.1
34.3 33.4 40.2 33.5
29.8 38.3 38.1 36.6
35.4 38.4 32.4 32.0
31.2 39.8 35.6 33.8
SPSS方差分析案例实例
SPSS 第二次作业——方差分析 1、案例背景: 在一些大型考试中,为了保证结果的准确和一致性,通常针对一些主观题,都采取由多个老师共同评审的办法。在评分过程中,老师对学生的信息不可见,同时也无法看到其他评分,保证了结果的公正性。然而也有特殊情况的发生,导致了成绩的不稳定,这就使得对不同教师的评分标准考察变得十分必要。 2、案例所需资料及数据的获取方式和表述,变量的含义以及类型: 所需资料:抽样某地某次考试中不同教师对不同的题目的学生成绩的评分; 获取方式:让一组学生前后参加四次考试,由三位教师进行批改后收集数据; 变量含义、类型:一份试卷的每道主观题由三名教师进行评定,3个教师的评定结果可看成事从同一总体中抽出的3个区组,它们在四次评定的成绩是相关样本。 表1如下: 3、分析方法: 用方差分析的方法对四个总体的平均数差异进行综合性的F 检验。 4、数据的检验和预处理: a) 奇异点的剔除:经检验得无奇异点的剔除; b) 缺失值的补齐:无; c) 变量的转换(虚拟变量、变量变换):无; d) 对于所用方法的假设条件的检验:进行正态性和方差齐性的检验。 正态性,用QQ 图进行分析得下图: 教师 题目 1 2 3 a 27.3 28.5 29.1 b 29.0 29.2 28.3 c 26.5 28.2 29.3 d 29.7 25.7 27.2
得到近似满足正态性。 ?对方差齐性的检验: 用SPSS对方差齐性的分析得下表: Test of Homogeneity of Variances 分数 Levene Statistic df1 df2 Sig. .732 2 9 .508 易知P〉0.05,接受方差齐性的假设。 5、分析过程: a) 所用方法:单因素方差分析;方差分析中的多重比较。 b) 方法细节: ●单因素方差分析 第一步,提出假设: H0:μ1=μ2=μ3;(教师的评定基本合理,即均值相同) H1:μi(i=1,2,3)不全相等;(教师的评定不够合理,均值有差异)第二步,为检验H0是否成立,首先计算以下统计量:
全国各地区可支配收入与消费性支出异方差检验综合案例分析
全国各地区可支配收入与消费性支出异方差检验综合案例分析 小组成员:翟丽萍孙琴令穆小斌 张丹冶贵花王淏珑 指导老师:毛锦凰
2009年全国各地区城镇居民平均每人全年家庭可支配收入与消费性支出 地区 可支配消费性收入(x)支出(y) 北京26738.48 17893.30 天津21402.01 14801.35 河北14718.25 9678.75 山西13996.55 9355.10 内蒙古15849.19 12369.87 辽宁15761.38 12324.58 吉林14006.27 10914.44 黑龙江12565.98 9629.60 上海28837.78 20992.35 江苏20551.72 13153.00 浙江24610.81 16683.48 安徽14085.74 10233.98 福建19576.83 13450.57 江西14021.54 9739.99 山东17811.04 12012.73 河南14371.56 9566.99 湖北14367.48 10294.07 湖南15084.31 10828.23 广东21574.72 16857.50 广西15451.48 10352.38 海南13750.85 10086.65 重庆15748.67 12144.06 四川13839.40 10860.20 贵州12862.53 9048.29 云南14423.93 10201.81 西藏13544.41 9034.31 陕西14128.76 10706.67 甘肃11929.78 8890.79 青海12691.85 8786.52 宁夏14024.70 10280.00 新疆12257.52 9327.55
单因素方差分析和多因素方差分析简单实例
单因素方差分析实例 [例6-8]在1990 年秋对“亚运会期间收看电视的时间”调查结果如下表所示。 问:收看电视的时间比平日减少了(第一组)、与平日无增减(第二组)、比平日增加了(第三组)的三组居民在“对亚运会的总态度得分”上有没有显著的差异?即要检验从“态度”上看,这三组居民的样本是取自同一总体还是取自不同的总体 在SPSS 中进行方差分析的步骤如下: (1)定义“居民对亚运会的总态度得分”变量为X(数值型),定义组类变量为G(数 值型),G=1、2、3 表示第一组、第二组、第三组。然后录入相应数据,如图6-66所示 图6-66 方差分析数据格式 (2)选择[Analyze]=>[Compare Means]=>[One-Way ANOVA...],打开[One-Way ANOVA]主对 话框(如图6-67所示)。从主对话框左侧的变量列表中选定X,单击按钮使之进入[Dependent List]框,再选定变量G,单击按钮使之进入[Factor]框。单击[OK]按钮完成。
图6-67 方差分析对话框 (3)分析结果如下: 因此,收看电视时间不同的三个组其对亚运会的态度是属于三个不同的总体。 多因素方差分析 [例6-11]从由五名操作者操作的三台机器每小时产量中分别各抽取1 个不同时段的产 量,观测到的产量如表6-31所示。试进行产量是否依赖于机器类型和操作者的方差分析。
SPSS 的操作步骤为: (1)定义“操作者的产量”变量为X(数值型),定义机器因素变量为G1(数值型)、操作 者因素变量为G2(数值型),G1=1、2、3 分别表示第一、二、三台机器,G2=1、2、3、4、5 分别表示第1、2、3、4、5 位操作者。录入相应数据,如图6-68所示。 图6-68 双因素方差分析数据格式 (2)选择[Analyze]=>[General Linear Model]=>[Univariate...],打开[Univariate]主对话框(如图6-69所示)。从主对话框左侧的变量列表中选定X,单击按钮使之进入[Dependent List]框,再选定变量G1 和G2,单击按钮使之进入[Fixed Factor(s)]框。单击[OK]按钮
SPSS-单因素方差研究分析(ANOVA)-案例解析
SPSS单因素方差分析(ANOVA)- 案例解析
作者:日期:
SPSS单因素方差分析(?ANOVA)案例解析 2011-08-30 11:10 这几天一直在忙电信网上营业厅用户体验优化改版事情,今天将我最近学习SPSS单因素方差分析(ANOVA分析,今天希望跟大家交流和分享一下: 继续以上一期的样本为例,雌性老鼠和雄性老鼠,在注射毒素后,经过一段时间,观察老鼠死亡和存活情况。 研究的问题是:老鼠在注射毒液后,死亡和存活情况,会不会跟性别有关? 样本数据如下所示:(a代表雄性老鼠b代表雌性老鼠0代表死亡1代表活着tim 代表注射毒液后,经过多长时间,观察结果) 点击“分析”一一比较均值------ 单因素AVOVA,如下所示:
从上图可以看出,只有“两个变量”可选,对于“组别(性别)”变量不可选,这里可能需要进行“转换”对数据重新进行编码, 点击“转换”一“重新编码为不同变量”将a,b"分别用8,9进行替换,得到如 下结果”
組别 g g生存时间tim 生存结局stat us ro a51r3.w \ a70/ 8.00 a131;' a.oo 131I 3 OG i a23 1 I BOO a301 1 9.00 1 a J 300\ 8.00._1 a羽1\ 000 a421\ B.OO a421\ s.oo a450 \ S 00./d h 119 00 b319.0C ]b3 19.00 Tb119 00 101900 b1519.00 ]b 1519.00 b2319.00 〕b3019 00 此时的8代表a(雄性老鼠)9代表b雌性老鼠,移入“因变量列表”框内,将“性别”移入“因子” 按钮,如下所示: 我们将“生存结局”变量框内,点击“两两比较”
异方差完整案例分析
20世纪70年代中期,美国能源 部门试 图基于各地过去的汽油消耗量和人口变动情况 以及其他一些因素给各地区、 各州甚至 各零售点直接分配汽油。实现这种分配必须将大量因素作为各州 (各地区)的燃油消耗量(应 变量)的函数而建立模型。 而对于这样的横截面 模型,即使是估计的模型,也很可能会具有异 方差问题。 在模型中,应变量为各州的燃油消耗量,可能的解释变量包括:与各州规模大小相关 的变量(例如公路里程数、注册的机动车数量和人口),以及与各州规模大小无关的变量(例 如燃油税率和最高限速)。因为在模型中反映各州规模大小的变量不应多于一个(如果包含 过多变量容易导致多重共线性),因为有许多州的最高限速相同(但在时间序列模型中,它 将是一个有用的变量)。因此,一个合理的模型为: PCON i f (REG,TAX ) i o i REG i 2 TAX i i ( 10-20) 式中 PCON i ――第i 个州的燃油消耗量(百万 BTU ), REG i ――第i 个州的注册机动车数量(千辆), TAX i ――第i 个州的燃油税率(美分/加仑), i ――经典误差项。 我们可以认为一个州注册的汽车数量越多, 该州所消耗的燃油也越多; 而一个州的燃油 税率越高则该州的燃油消耗量越小 (10-20),得到: 二我们搜集那一时期的数据(见表 10-1 )用于估计方程 PCON i 551.7 0.1861REG i 53.59TAX i ( 10-21) (0.0117) ( 16.86) t 15.88 3.18 R 1 2 0.861 N 50 表10-1燃油消费例子中的数据 PCON UHM TAX REG POP e state 270 2.2 9 743 1136 62.335 Maine 122 2.4 14 774 948 176.52 New Hampshire 58 0.7 11 351 520 30.481 Vermont 821 20.6 9.9 3750 5750 101.87 Massachusetts 1 在方程中我们也可用TAX * REG 或者TAX * POP ( POP 代表第i 个州的人口)取代TAX 作为方程的解 释变量。我们在第7.5节中讨论虚拟变量斜率时曾介绍了一个关于交互项的更为复杂的例子。对于一个给 定的税率,它对一个大州的燃油消耗的影响要比对一个小州的影响大得多,而用反映州的规模大小的变量 乘以TAX 会使所得到的新变量(交互项)能够更好地 度量这一效应。 10.5 —个更完整的例子 让我们来看一个更完整的基于横殿面的异方差的例子。
SPSS-单因素方差分析(ANOVA)-案例解析资料讲解
SPSS- 单因素方差分析( ANOVA) - 案例解 析
SPSS单因素方差分析(ANOVA)案例解析 2011-08-30 11:10 这几天一直在忙电信网上营业厅用户体验优化改版事情,今天将我最近习SPSS单因素方差分析(ANOVA分析,今天希望跟大家交流和分享一下: 继续以上一期的样本为例,雌性老鼠和雄性老鼠,在注射毒素后,经过一段时间,观察鼠死亡和存活情况。 研究的问题是:老鼠在注射毒液后,死亡和存活情况,会不会跟性别有关? 样本数据如下所示:(a代表雄性老鼠b代表雌性老鼠0代表死亡1代表着tim 代表注射毒液后,经过多长时间,观察结果) 点击“分析”一一比较均值-------- 单因素AVOVA,如下所示:
从上图可以看出,只有“两个变量”可选,对于“组别(性别)”变量不可选, 进行“转换”对数据重新进行编码, 点击“转换”一“重新编码为不同变量”将a,b"分别用8,9进行替换,得到如下结果”这里可能需
此时的8代表a(雄性老鼠)9代表b雌性老鼠,我们将“生存结局”变量移入“因变量列表框内,将“性别”移入“因子”框内,点击“两两比较”按钮,如下所示:
“勾选“将定方差齐性”下面的项 点击继续 LSD选项,和“未假定方差齐性”下面的Tamhane's T2 选点击“选项”按钮,如下所示: I固疋和随枫效果(号 IN有建同備性檯验迥) 匚旦rown-Forsythe(B) El Welches} 姑朱値 ?按分析顺序排麒个案? 「I I S3 Affifi 勾选“描述性”和“方差同质检验”以及均值图等选项,得到如下结果:
方差分析几个案例
方差分析方法 方差分析是统计分析方法中,最重要、最常用的方法之一。本文应用多个实例来阐明方差分析的应用。在实际操作中,可采用相应的统计分析软件来进行计算。 1. 方差分析的意义、用途及适用条件 1.1 方差分析的意义 方差分析又称为变异数分析或F检验,其基本思想是把全部观察值之间的变异(总变异),按设计和需要分为二个或多个组成部分,再作分析。即把全部资料的总的离均差平方和(SS)分为二个或多个组成部分,其自由度也分为相应的部分,每部分表示一定的意义,其中至少有一个部分表示各组均数之间的变异情况,称为组间变异(MS组间);另一部分表示同一组内个体之间的变异,称为组内变异(MS组内),也叫误差。SS除以相应的自由度(υ),得均方(MS)。如MS组间>MS组内若干倍(此倍数即F值)以上,则表示各组的均数之间有显著性差异。 方差分析在环境科学研究中,常用于分析试验数据和监测数据。在环境科学研究中,各种因素的改变都可能对试验和监测结果产生不同程度的影响,因此,可以通过方差分析来弄清与研究对象有关的各个因素对该对象是否存在影响及影响的程度和性质。 1.2 方差分析的用途 1.2.1 两个或多个样本均数的比较。 1.2.2 分离各有关因素,分别估计其对变异的影响。 1.2.3 分析两因素或多因素的交叉作用。 1.2.4 方差齐性检验。 1.3 方差分析的适用条件 1.3.1 各组数据均应服从正态分布,即均为来自正态总体的随机样本(小样本)。 1.3.2 各抽样总体的方差齐。 1.3.3 影响数据的各个因素的效应是可以相加的。 1.3.4 对不符合上述条件的资料,可用秩和检验法、近似F值检验法,也可以经过变量变换,使之基本符合后再按其变换值进行方差分析。一般属Poisson分布的计数资料常用平方根变换法;属于二项分布的百分数可用反正弦函数变换法;当标准差与均数之间呈正比关系,用平方根变换法又不易校正时,也可用对数变换法。 2. 单因素方差分析(单因素多个样本均数的比较) 根据某一试验因素,将试验对象按完全随机设计分为若干个处理组(各组的样本含量可相等或不等),分别求出各组试验结果的均数,即为单因素多个样本均数。 用方差分析比较多个样本均数的目的是推断各种处理的效果有无显著性差异,如各组方差齐,则用F检验;如方差不齐,用近似F值检验,或经变量变换后达到方差齐,再用变换值作F检验。如经F检验或近似F值检验,结论为各总体均数不等,则只能认为各总体均数之间总的来说有差异,但不能认为任何两总体均数之间都有差异,或某两总体均数之间有差异。必要时应作均数之间的两两比较,以判断究竟是哪几对总体均数之间存在差异。 在环境科学研究中,常常要分析比较不同季节对江、河、湖水中某种污染物的含量
spss 多因素方差分析例子
作业8:多因素方差分析 1,data0806-height是从三个样方中测量的八种草的高度,问高度在三个取样地点,以及八种草之间有无差异?具体怎么差异的? 打开spss软件,打开data0806-height数据,点击Analyze->General Linear Model->Univariate 打开: 把plot和species送入Fixed Factor(s),把height送入Dependent Variable,点击Model 打开:
选择Full factorial,Type III Sum of squares,Include intercept in model(即全部默认选项),点击Continue回到Univariate主对话框,对其他选项卡不做任何选择, 结果输出:
因无法计算MM e rror,即无法分开MM intercept和MM error,无法检测interaction的影响,无法进行方差分析, 重新Analyze->General Linear Model->Univariate打开: 选择好Dependent Variable和Fixed Factor(s),点击Model打开: 点击Custom,把主效应变量species和plot送入Model框,点击Continue回到Univariate主对话框,点击Plots:
Univariate对话框,点击Options:
把OVERALL,species, plot送入Display Means for框,选择Compare main effects,Bonferroni,点击Continue回到Univariate对话框, 输出结果: 可以看到:SS species=33.165,df species=7,MS species=4.738;SS plot=33.165,df plot=7,MS plot=4.738;SS error=21.472,df error=14,MS error=1.534; Fspecies=3.089,p=0.034<0.05;Fplot=12.130,p=0.005<0.01; 所以故认为在5%的置信水平上,不同样地,不同物种之间的草高度是存在差异的。
SPSS处理多元方差分析报告例子
实验三多元方差分析 一、实验目的 用多元方差分析说明民族和城乡对人均收入和文化程度的影响。 二、实验要求 调查24个社区,得到民族与城乡有关数据如下表所示,其中人均收入为年 均,单位百元。文化程度指15岁以上小学毕业文化程度者所占百分比。试依此 数据通过方差分析说明民族和城乡对人均收入和文化程度的影响。 三、实验内容 1.依次点击“分析”---- “常规线性模型”----“多变量”,将“人均收入”和“文化程 度”加到“因变量”中,将“民族”和“居民”加到“固定因子”中,如下图一所示。 民族农村城市 人均收入文化程度人均收入文化程度 1 46,50,60,68 70,78,90,93 52,58,72,75 82,85,96,98 2 52,53,63,71 71,75,86,88 59,60,73,77 76,82,92,93 3 54,57,68,69 65,70,77,81 63,64,76,78 71,76,86,90
【图一】 2.点击“选项”,将“输出”中的相关选项选中,如下图二所示: 【图二】 3.点击“继续”,“确定”得到如下表一的输出:
【表一】 常规线性模型 主体间因子 值标签N 民族 1.00 1 8 2.00 2 8 3.00 3 8 居民 1.00 农村12 2.00 城市12 描述性统计量 民族居民均值标准差N 人均收入1 农村56.0000 9.93311 4 城市64.2500 11.02648 4 总计60.1250 10.66955 8 2 农村59.7500 8.99537 4 城市67.2500 9.10586 4 总计63.5000 9.28901 8 3 农村62.0000 7.61577 4 城市70.2500 7.84750 4 总计66.1250 8.40812 8 总计农村59.2500 8.45442 12 城市67.2500 8.89458 12 总计63.2500 9.41899 24 文化程度1 农村82.7500 10.68878 4 城市90.2500 7.93200 4 总计86.5000 9.59166 8
方差分析案例
“地域”与“抑郁” 朱平辉改编自西南财大网(案例分析者刘玲同学) 一、案例简介 美国人作了一项调查,研究地理位置与患抑郁症之间的关系。他们选择了60个65岁以上的健康人组成一个样本,其中20个人居住在佛罗里达,20个人居住在纽约、20个人居住在北卡罗来纳。对中选的每个人给出了测量抑郁症的一个标准化检验,搜集到表1中的资料,较高的得分表示较高的抑郁症水平。 研究的第二部分考虑地理位置与患有慢性病的65岁以上的人患抑郁症之间的关系,这些慢性病诸如关节炎、高血压、心脏失调等。这种身体状况的人也选出60个组成样本,同样20个人居住在佛罗里达,20个人居住在纽约、20个人居住在北卡罗来纳。这个研究记录 央视主持人崔永元对外公开其患有抑郁症后,使人们对这种精神疾病有了更多的关注。通过对以上两个数据集统计分析,你能从中看出什么结论?你对该疾病有什么认识? 二、抑郁症的相关知识 抑郁症有两种含义,广义的抑郁症包括情感性精神病、抑郁性神经症、反应性抑郁症、更年期抑郁症等;狭义的则仅指情感性精神病抑郁症。抑郁症在国外是一种十分常见的精神
疾病,据报告,其患病率最高竟占人群的10%左右,而且社会经济情况较好的阶层,患病率越高。世界卫生组织预测,抑郁症将成为21世纪人类的主要杀手。全世界患有抑郁症的人数在不断增长,而抑郁症患者中有10—15%面临自杀的危险……引起抑郁症的原因有很多,为了了解地理位置对抑郁症是否有影响,我们做如下的案例分析: 三、地理位置与患抑郁症之间是否有关系 作为对65岁以上的人长期研究的一部分,在纽约洲北部地区的Wentworth医疗中心的社会学专家和内科医生进行了一项研究,以调查地理位置与患抑郁症之间的关系。选择了60个相当健康的人组成一个样本,其中20人居住在佛罗里达,20人居住在纽约,20人居住在北卡罗米纳。对中选的人给出了测量抑郁症的一个标准化实验,搜集到表1中的资料,较高的分表示较高的抑郁症水平。 研究的第二部分考虑地理位置与患有慢性病的65岁以上的人患抑郁症之间的关系,这些慢性病诸如关节炎、高血压、心脏失调等。这种状况的人也选出60个组成样本,同样20人居住在佛罗里达,20人居住在纽约,20人居住在北卡罗米纳。 要求根据所给的样本数据,做出以下管理报告: 描述统计学方法概括说明两部分研究的资料,关于抑郁症的得分,你的初步观测结果是什么? 对两个数据集使用方差分析方法,陈述每种情况下被检验的假设,你的结论是什么? 用推断法说明单个处理均值的合理性 讨论这个研究的推广和你认为有用的其他分析 四、有关统计方法 本案例是通过单因素的方差分析,对各个地区的抑郁症得分均值进行假设检验。分别检验地理位置对健康人群和慢性病患者是否有影响,以及影响程度,进而得出结论。 五、案例分析 首先:数据资料中的数据,并不能直接看出地区与患抑郁症之间有联系与否。我们可以根据所给的样本资料,得到以下信息: (一)健康的被调查者中:佛罗里达地区平均得分=5.55 纽约地区平均得分=8 北卡罗米纳地区平均得分=7.05 (二)患抑郁症的被调查者中:佛罗里达地区平均得分=13.6 纽约地区平均得分=15.25 北卡罗米纳地区平均得分=13.95 (三)我们给出不同地区所有被调查者的平均得分情况 佛罗里达地区平均得分=9.575 纽约地区平均得分=11.625 北卡罗米纳地区平均得分=10.5
异方差案例分析
异方差案例分析 中国农村居民人均消费支出主要由人均纯收入来决定。农村人均纯收入除从事农业经营的收入外,还包括从事其他产业的经营性收入以及工资性收入、财产收入和转移支付收入等。为了考察从事农业经营的收入和其他收入对中国农村居民消费支出增长的影响,可使用如下双对数模型: 1122ln ln ln Y X X βββμ0=+++ 其中,Y 表示农村家庭人均消费支出,X 1表示从事农业经营的收入,X 2表示其他收入。下表列出了中国2001年各地区农村居民家庭人均纯收入及消费支出的相关数据。 中国2001年各地区农村居民家庭人均纯收入与消费支出 单位:元
资料来源:《中国农村住户调查年鉴》(2002)、《中国统计年鉴》(2002)。 我们不妨假设该线性回归模型满足基本假定,采用OLS 估计法,估计结果如下: 12?ln 1.6550.3166ln 0.5084ln Y X X =++ (1.87) (3.02) (10.04) R 2=0.7831 R 2=0.7676 D.W.=1.89 F=50.53 RSS=0.8232
图1 估计结果显示,其他收入而不是从事农业经营的收入的增长,对农户消费支出的增长更具有刺激作用。下面对该模型进行异方差性检验。 1.图示法。 首先做出Y与X1、X2的散点图,如下:
图2 可见1X 基本在其均值附近上下波动,而2X 散点存在较为明显的增大趋势。 再做残差平方项2 ?i e 与1ln X 、2ln X 的散点图:
图3 图4 可见图1中离群点相对较少而图2呈现较为明显的单调递增的
异方差性。故初步判断异方差性主要是2X引起的。 2.G-Q检验 根据上述分析,首先将原始数据按X2升序排序,去掉中间7个数据,得到两个容量为12的子样本,记数据较小的样本为子样本1,数据较大的为子样本2。对子样本1进行OLS回归,结果如下: 图5 得到子样本1的残差平方和RSS1=0.064806; 再对子样本2进行OLS回归,结果如下:
单因素方差分析和多因素方差分析简单实例 (1)
百度文库- 让每个人平等地提升自我 单因素方差分析实例 [例6-8]在1990 年秋对“亚运会期间收看电视的时间”调查结果如下表所示。 问:收看电视的时间比平日减少了(第一组)、与平日无增减(第二组)、比平日增加了(第三组)的三组居民在“对亚运会的总态度得分”上有没有显著的差异?即要检验从“态度”上看,这三组居民的样本是取自同一总体还是取自不同的总体 在SPSS 中进行方差分析的步骤如下: (1)定义“居民对亚运会的总态度得分”变量为X(数值型),定义组类变量为G(数 值型),G=1、2、3 表示第一组、第二组、第三组。然后录入相应数据,如图6-66所示 图6-66 方差分析数据格式 (2)选择[Analyze]=>[Compare Means]=>[One-Way ANOVA...],打开[One-Way ANOVA]主对 话框(如图6-67所示)。从主对话框左侧的变量列表中选定X,单击按钮使之进入[Dependent List]框,再选定变量G,单击按钮使之进入[Factor]框。单击[OK]按钮完成。 图6-67 方差分析对话框 (3)分析结果如下: 因此,收看电视时间不同的三个组其对亚运会的态度是属于三个不同的总体。 多因素方差分析 [例6-11]从由五名操作者操作的三台机器每小时产量中分别各抽取1 个不同时段的产 量,观测到的产量如表6-31所示。试进行产量是否依赖于机器类型和操作者的方差分析。SPSS 的操作步骤为: (1)定义“操作者的产量”变量为X(数值型),定义机器因素变量为G1(数值型)、操作 者因素变量为G2(数值型),G1=1、2、3 分别表示第一、二、三台机器,G2=1、2、3、4、5 分别表示第1、2、3、4、5 位操作者。录入相应数据,如图6-68所示。 图6-68 双因素方差分析数据格式 (2)选择[Analyze]=>[General Linear Model]=>[Univariate...],打开[Univariate]主对话框(如图6-69所示)。从主对话框左侧的变量列表中选定X,单击按钮使之进入[Dependent List]框,再选定变量G1 和G2,单击按钮使之进入[Fixed Factor(s)]框。单击[OK]按钮 图6-69 单变量多因素方差分析主对话框 (3)分析结果如下: 因此,可以认为机器类型和操作者的影响均是显著的。 1
R案例分析_异方差
第五章 案例分析 一、问题的提出和模型设定 为了分析不同省份或城市的交通和通讯支出的规划提供依据,分析交通和通讯支出与可支配收入的关系,建立交通和通讯支出与可支配收入的回归模型。假定交通和通讯支出与可支配收入满足线性约束,则理论模型设定为 i i i cum income u αβ=+?+ (1) 其中i cum 表示交通和通讯支出,i income 表示可支配收入。 由1999年《中国统计年鉴》得到如下数据 注:见数据文件cumexp_income.csv 二、参数估计 利用最小二乘法估计模型(1)的参数: mydata.lm <- lm(cumexp ~ income) summary(mydata.lm) R 软件输出的结果为: Call: lm(formula = cumexp ~ income) Residuals: Min 1Q Median 3Q Max -97.465 -19.986 -5.111 15.532 184.115
Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -56.91798 36.20624 -1.572 0.127 income 0.05808 0.00648 8.962 1.02e-09 *** --- Signif. codes : 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 50.48 on 28 degrees of freedom Multiple R-squared: 0.7415, Adjusted R-squared: 0.7323 F-statistic: 80.32 on 1 and 28 DF, p-value: 1.021e-09 估计结果为: ?56.920.06(36.21)(0.01) cum income =-+ 20.74 ..504880.32R s e F === 括号内为标准差。 三、检验模型的异方差 (一)图示法 par(mfrow=c(1,2)) plot(cumexp ~ income, col="red") abline(mydata.lm) plot(residuals(mydata.lm)^2 ~ income,col="blue") 从上图可以看出,残差平方对解释变量X 的散点图主要分布在图形中的下三角部分,大40006000 8000200300400500 600 a.散点图及回归线income c u m e x p 4000600080000500010000200003000 0 b.残差平方的散点图 income r e s i d u a l s (m y d a t a .l m )^2
最新方差分析实例
让4名学生前后做3份测验卷,得到如下表的分数,运用方差分析法可以推断分析的问题是:3份测验卷测试的效果是否有显著性差异? 1、确定类型 由于4名学生前后做3份试卷,是同一组被试前后参加三次考试,4位学生的考试成绩可看成是从同一总体中抽出的4个区组,它们在三个测验上的得分是相关样本。 2、用方差分析方法对三个总体平均数差异进行综合性地F检验 检验步骤如下: 第一步,提出假设: 第二步,计算F检验统计量的值: 因为是同一组被试前后参加三次考试,4位学生的考试成绩可看成是从同一总体中抽出的4个区组,它们在三个测验上的得分是相关样本,所以可将区组间的个别差异从组内差异中分离出来,剩下的是实验误差,这样就可以选择公式(6.6)组间方差与误差方差的F比值来检验三个测验卷的总体平均数差异的显著性。 ①根据表6.4的数据计算各种平方和为: 总平方和: 组间平方和: 区组平方和: 误差平方和:
②计算自由度 总自由度: 组间自由度: 区组自由度: 误差自由度: ③计算方差 组间方差: 区组方差: 误差方差: ④计算F值 第三步,统计决断 根据,α=0.01,查F值表,得到,而实际计算的F检验统计量的值为,即P(F >10.9)<0.01, 样本统计量的值落在了拒绝域内,所以拒绝零假设,接受备择假设,即三个测验中至少有两个总体平均数不相等。 3、用q检验法对逐对总体平均数差异进行检验 检验步骤如下: 第一步,提出假设: 第二步,因为是多个相关样本,所以选择公式(6.8)计算q检验统计量的值:
在为真的条件下,将一次样本的有关数据及代入上式中,得到A和B两组的平均数之差的q值,即: 以此类推,就可得到每对样本平均数之间差异比较的q值,如下表所示: 第三步,统计决断 为了进行统计决断,在本例中,将A,B,C共3组学生英语单词测验成绩的等级排列为: A与C之间和B与C之间包含有1,2两个组,a=2;A与B之间包含有1,2,3三个组,a=3。 根据,得到当a=2时,q检验的临界值为 ; 当a=3时,q检验的临界值为;将表(6.5)中的q检验统计量的值与q临界值进行比较,得到表(6.6)中的3次测验成绩各对平均数之间的比较结果:表6.6 3次测试各对样本平均数之差q值的比较结果
spss方差分析实例
SPSS——单因素方差分析实例 单因素方差分析也称作一维方差分析。它检验由单一因素影响的一个(或几个相互独立的)因变量由因素各水平分组的均值之间的差异是否具有统计意义。还可以对该因素的若干水平分组中哪一组与其他各组均值间具有显著性差异进行分析,即进行均值的多重比较。One-Way ANOVA过程要求因变量属于正态分布总体。如果因变量的分布明显的是非正态,不能使用该过程,而应该使用非参数分析过程。如果几个因变量之间彼此不独立,应该用Repeated Measure过程。 [例子] 调查不同水稻品种百丛中稻纵卷叶螟幼虫的数量,数据如表1-1所示。 表1-1不同水稻品种百丛中稻纵卷叶螟幼虫数 数据保存在“data1.sav”文件中,变量格式如图1-1。 分析水稻品种对稻纵卷叶螟幼虫抗虫性是否存在显著性差异。 2)启动分析过程 点击主菜单“Analyze”项,在下拉菜单中点击“Compare Means”项,在右拉式菜单中点击“0ne-Way ANOVA”项,系统打开单因素方差分析设置窗口如图1-2。
3)设置分析变量 因变量: 选择一个或多个因子变量进入“Dependent List”框中。本例选择“幼虫”。 因素变量: 选择一个因素变量进入“Factor”框中。本例选择“品种”。 4)设置多项式比较 单击“Contrasts”按钮,将打开如图1-3所示的对话框。该对话框用于设置均值的多项式比较。 定义多项式的步骤为: 均值的多项式比较是包括两个或更多个均值的比较。例如图1-3中显示的是要求计算“1.1×mean1-1×mean2”的值,检验的假设H0:第一组均值的1.1倍与第二组的均值
SPSS-单因素方差分析(ANOVA) 案例解析
SPSS-单因素方差分析(ANOVA) 案例解析 2011-08-30 11:10 这几天一直在忙电信网上营业厅用户体验优化改版事情,今天将我最近学习SPSS单因素方差分析(ANOVA)分析,今天希望跟大家交流和分享一下: 继续以上一期的样本为例,雌性老鼠和雄性老鼠,在注射毒素后,经过一段时间,观察老鼠死亡和存活情况。 研究的问题是:老鼠在注射毒液后,死亡和存活情况,会不会跟性别有关? 样本数据如下所示:(a代表雄性老鼠 b代表雌性老鼠 0代表死亡 1 代表活着 tim 代表注射毒液后,经过多长时间,观察结果) 点击“分析”——比较均值———单因素AVOVA, 如下所示:
从上图可以看出,只有“两个变量”可选, 对于“组别(性别)”变量不可选,这里可能需要进行“转换”对数据重新进行编码, 点击“转换”—“重新编码为不同变量” 将a,b"分别用8,9进行替换,得到如下结果”
此时的8 代表a(雄性老鼠) 9代表b雌性老鼠,我们将“生存结局”变量移入“因变量列表”框内,将“性别”移入“因子”框内,点击“两两比较”按钮,如下所示:
“ 勾选“将定方差齐性”下面的 LSD 选项,和“未假定方差齐性”下面的Tamhane's T2选项点击继续 点击“选项”按钮,如下所示: 勾选“描述性”和“方差同质检验” 以及均值图等选项,得到如下结果:
结果分析:方差齐性检验结果,“显著性”为0,由于显著性0<0.05 所以,方差齐性不相等,在一般情况下,不能够进行方差分析 但是对于SPSS来说,即使方差齐性不相等,还是可以进行方差分析的, 由于此样本组少于三组,不能够进行多重样本对比 从结果来看“单因素ANOVA” 分析结果,显著性0.098,由于 0.098>0.05 所以可以得出结论: 生存结局受性别的影响不显著 很多人,对这个结果可能存在疑虑,下面我们来进一步进行论证,由于“方差齐性不相等”下面我们来进行“非参数检验”检验结果如下所示:(此处采用的是“Kruskal-Wallis "检验方法)
方差分析实例分析
方差分析实例分析 摘要:为研究货架的高度和宽度两个因素的影响,本文基于shelf 数据,分别对高度和宽度进行方差分析。首先对数据进行高度和宽度进行分组,并进行描述性统计分析。其次,利用Bartlett 检验进行方差其次性检验,以检验数据在不同的水平下方差是否相同。最后,利用aov()函数进行单因素方差分析、交互作用的双因素方差分析。其结果表明:单因素方差分析结果表明:高度的bottom 、middle 、top 三个水平设置要求不相同,宽度的reg 、wide 两个水平设置要求相同。三个高度设置的需求和两个宽度设置的要求之间的关系是一样的。 关键词:方差其次性检验;方差分析;高度;宽度;货架 1 引言 方差分析是在20世纪20年代发展起来的一种统计方法,它是由英国统计学家费希尔在进行实验设计时为解释实验数据而首先引入的。从形式上看,方差分析是比较多个总体的均值是否相等;但是其本质上是研究变量之间的相互关系。方差分析主要用于研究一个数值因变量与一个或多个分类自变量的关系。方差分析(analysis of variance ,ANOV A )就是通过检验各总体的均值是否相等来判断分类型自变量对数值型因变量是否有显著影响。 本文基于shelf 数据,分别对高度和宽度进行方差分析。首先对数据进行高度和宽度进行分组,并进行描述性统计分析。其次,利用Bartlett 检验进行方差其次性检验,以检验数据在不同的水平下方差是否相同。最后,利用aov()函数进行单因素方差分析和有交互作用的双因素方差分析,以说明三个层次高度的要求是否相同,两个层次的宽度要求是否相同,以 及宽度设置的需求和高度之间的关系。 2货架数据描述性统计分析 对shelf 数据进行三个层次高度进行分组,分别分为bottom 、middle 、top 三个层次。对宽度进行reg 、wide 两个层次进行分组。表1给出了shelf 数据的原始数据表,表2给出了高度 三个层次的描述性统计结果,表3给出了宽度两个层次的描述性统计结果。 从表2可看出,bottom 的平均值为55.8,方差为6.136;middle 的平均值为77.2,方差为9.628;top 的平均值为51.5,方差为2.716。其结果表明:三个水平的货架高度平均值存在差异,但是其方差也有差别。表3可看出,reg 的平均值为60.8,方差为129.4050;wide 的平均值为62.2,方差为165.2775。货架的宽度wide 的方差较大,其说明货架的宽度wide 的波动性较大。 height width Mean reg wide bottom 58.20 55.70 55.8 bottom 53.70 52.50 bottom 55.80 58.90 Mean 55.90 55.70 middle 73.00 76.20 77.2 middle 78.10 78.40 middle 75.40 82.10 Mean 75.50 78.90
异方差完整案例分析
10.5 一个更完整的例子 让我们来看一个更完整的基于横殿面的异方差的例子。20世纪70年代中期,美国能源部门试图基于各地过去的汽油消耗量和人口变动情况以及其他一些因素给各地区、各州甚至各零售点直接分配汽油。实现这种分配必须将大量因素作为各州(各地区)的燃油消耗量(应变量)的函数而建立模型。而对于这样的横截面模型,即使是估计的模型,也很可能会具有异方差问题。 在模型中,应变量为各州的燃油消耗量,可能的解释变量包括:与各州规模大小相关的变量(例如公路里程数、注册的机动车数量和人口),以及与各州规模大小无关的变量(例如燃油税率和最高限速)。因为在模型中反映各州规模大小的变量不应多于一个(如果包含过多变量容易导致多重共线性),因为有许多州的最高限速相同(但在时间序列模型中,它将是一个有用的变量)。因此,一个合理的模型为: 012(,)i i i i i PCON f REG TAX REG TAX εβββε+- =+=+++ (10-20) 式中 i PCON ——第i 个州的燃油消耗量(百万BTU ), i REG ——第i 个州的注册机动车数量(千辆), i TAX ——第i 个州的燃油税率(美分/加仑), i ε——经典误差项。 我们可以认为一个州注册的汽车数量越多,该州所消耗的燃油也越多;而一个州的燃油 税率越高则该州的燃油消耗量越小1 。我们搜集那一时期的数据(见表10-1)用于估计方程(10-20),得到: i i i TAX REG PCON 59.531861.07.551-+=∧ (10-21) (0.0117) (16.86) 15.88t = 3.18- 20.861R = 50N = 表10-1 燃油消费例子中的数据 PCON UHM TAX REG POP e state 270 2.2 9 743 1136 62.335 Maine 122 2.4 14 774 948 176.52 New Hampshire 58 0.7 11 351 520 30.481 Vermont 821 20.6 9.9 3750 5750 101.87 Massachusetts 1 在方程中我们也可用*TAX REG 或者*TAX POP (i POP 代表第i 个州的人口)取代TAX 作为方程的解 释变量。我们在第7.5节中讨论虚拟变量斜率时曾介绍了一个关于交互项的更为复杂的例子。对于一个给定的税率,它对一个大州的燃油消耗的影响要比对一个小州的影响大得多,而用反映州的规模大小的变量乘以TAX 会使所得到的新变量(交互项)能够更好地度量这一效应。
spss多因素方差分析例子
1, data0806-height 是从三个样方中测量的八种草的高度,问高度在三个取样地点,以及 八种草之间有无差异?具体怎么差异的? 打 开 spss 软 件 , 打 开 data0806-height 数 据 , 点 击 Analyze->General Linear Model->Univariate 打开: 把 plot 和 species 送入 Fixed Factor(s) ,把 height 送入 Dependent Variable ,点击 Model 打开: 选择 Full factorial , Type III Sum of squares , Include intercept in model (即 全部默认选项) ,点击 Continue 回到 Univariate 主对话框,对其他选项卡不做任何选 择, 结果输出: 因无法计算 ???? ??rror ,即无法分开 ???? intercept 的影响,无法进行方差分析, 重新 Analyze->General Linear Model->Univariate 打开: 选择好 Dependent Variable 和 Fixed Factor(s) 点击Custom,把主效应变量 species 和plot 送入 Model 框,点击 Continue 回到Univariate 主对话框,点击 Plots : 把 date 送入 Horizontal Axis ,把 depth 送入 Separate Lines ,点击 Add ,点击 Continue 回到 Univariate 对话框,点击 Options : 把 OVERALL,species, plot 送入 Display Means for 框,选择 Compare main effects , Bonferroni ,点击 Continue 回到 Univariate 对话框, 输出结果: 可以看到: SS species =, df species =7, MS species= ;SS plot =, df plot =7, MS plot= ;SS error =, df error =14, MS error= ; Fspecies= , p=<;Fplot=,p=<; 所以故认为在 5%的置信水平上,不同样地,不同物种之间的草高度是存在差异的。 该表说明: SSspecies= ,dfspecies=7 ,MSspecies= ;SSerror= ,dferror=14 ,MSerror= ; Fspecies= , p=<; 物种间存在差异: SSplot= , dfplot=7 , MSplot= ; SSerror= , dferror=14 , MSerror= ; Fplot=,p=<; 不同的物种间在差异: 由边际分布图可知:类似结论:草的高度在不同样地的条件之间有差异( Fplot=,p=< ),具 体是,样地一和样地三之间存在的差异最大;八种不同草的高度也存在差异( Fspecies= , p=<),具体是第四 和 ???? error ,无法检测 interaction ,点击 Model 打开: