spss
实验报告
实验名称:描述性统计分析
实验目的与要求:
1. 了解统计描述的常用工具及SPSS中的统计描述模块。
2. 掌握分类变量和连续变量的统计描述方法及指标。
实验内容提要:
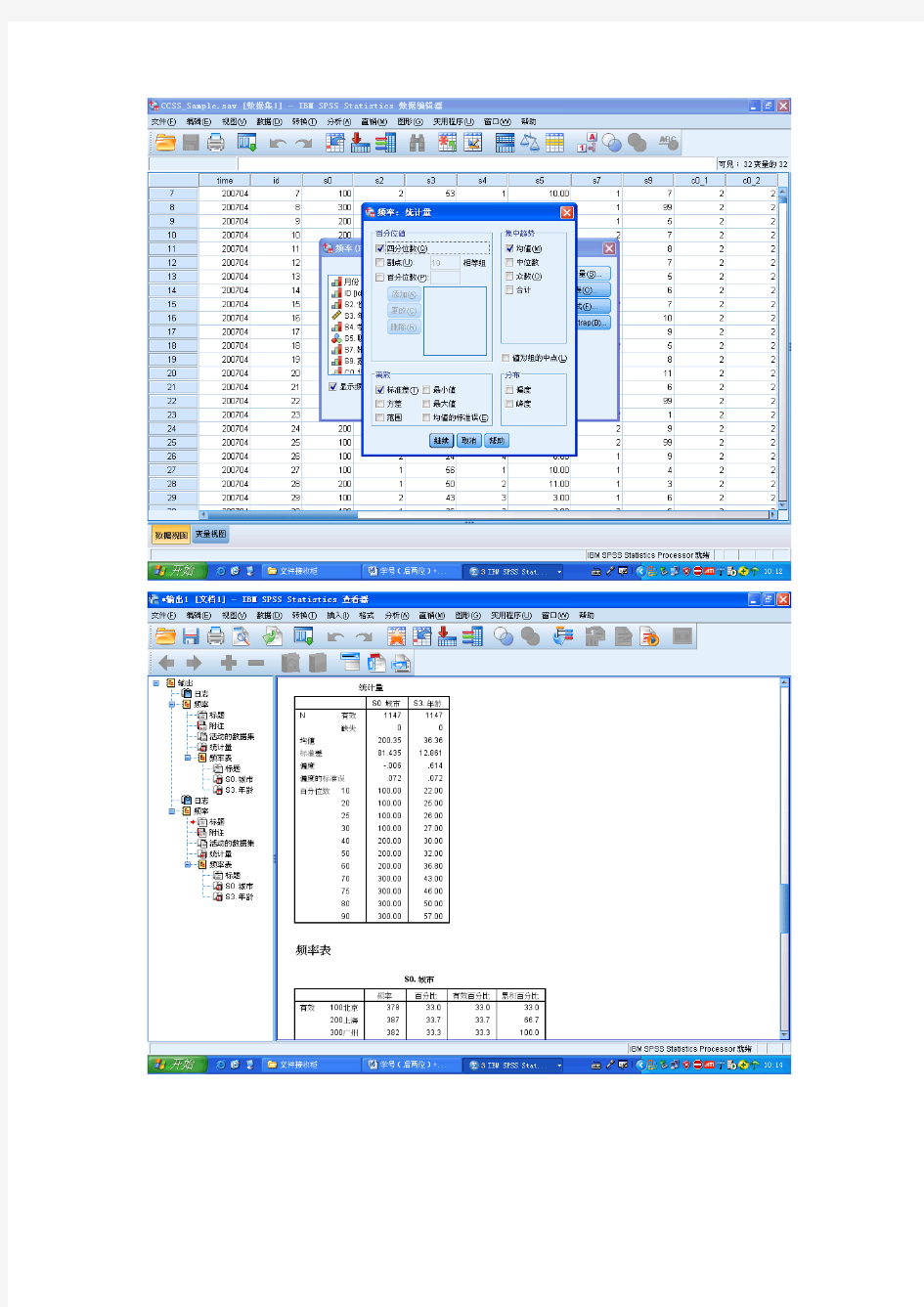
1.根据CCSS_Sample.sav数据,分析受访者的年龄分布情况,尝试分城市/合并描述。
2.根据SPSS自带数据Employee data.sav,分析员工性别、受教育程度、少数民族、职位类别的分布情况,并尝试分析这些属性之间的关系以及这些属性和工资之间的关系。
实验步骤:
1根据CCSS_Sample.sav数据,分析受访者的年龄分布情况,尝试分城市/合并描述。
数据—拆分文件分析—统计描述——频率
2.根据SPSS自带数据Employee data.sav,分析员工性别、受教育程度、少数民族、职位类别的分布情况,并尝试分析这些属性之间的关系以及这些属性和工资之间的关系。
(1)分析员工性别、受教育程度、少数民族、职位类别的分布情况
(2)尝试分析这些属性之间的关系
性别* 雇佣类别交叉制表
雇佣类别合计职员保管员经理
性别女
计数206 0 10 216
性别中的% 95.4% 0.0% 4.6% 100.0%
雇佣类别中的% 56.7% 0.0% 11.9% 45.6% 男
计数157 27 74 258
性别中的% 60.9% 10.5% 28.7% 100.0%
雇佣类别中的% 43.3% 100.0% 88.1% 54.4%
合计计数363 27 84 474 性别中的% 76.6% 5.7% 17.7% 100.0%
雇佣类别中的% 100.0% 100.0% 100.0% 100.0%
性别* 少数民族分类交叉制表
少数民族分类合计
否是
性别女
计数176 40 216
性别中的% 81.5% 18.5% 100.0%
少数民族分类中的% 47.6% 38.5% 45.6% 男
计数194 64 258
性别中的% 75.2% 24.8% 100.0%
少数民族分类中的% 52.4% 61.5% 54.4%
合计计数370 104 474 性别中的% 78.1% 21.9% 100.0% 少数民族分类中的% 100.0% 100.0% 100.0%
雇佣类别中的% 6.6% 0.0% 41.7% 12.4%
17 年计数 3 0 8 11 教育水平(年)中的% 27.3% 0.0% 72.7% 100.0% 雇佣类别中的% 0.8% 0.0% 9.5% 2.3%
18 年计数 2 0 7 9 教育水平(年)中的% 22.2% 0.0% 77.8% 100.0% 雇佣类别中的% 0.6% 0.0% 8.3% 1.9%
19 年计数 1 0 26 27 教育水平(年)中的% 3.7% 0.0% 96.3% 100.0% 雇佣类别中的% 0.3% 0.0% 31.0% 5.7%
20 年计数0 0 2 2 教育水平(年)中的% 0.0% 0.0% 100.0% 100.0% 雇佣类别中的% 0.0% 0.0% 2.4% 0.4%
21 年计数0 0 1 1 教育水平(年)中的% 0.0% 0.0% 100.0% 100.0% 雇佣类别中的% 0.0% 0.0% 1.2% 0.2%
合计计数363 27 84 474 教育水平(年)中的% 76.6% 5.7% 17.7% 100.0% 雇佣类别中的% 100.0% 100.0% 100.0% 100.0%
教育水平(年)* 少数民族分类交叉制表
少数民族分类合计
否是
教育水平(年)8 年
计数39 14 53
教育水平(年)中的% 73.6% 26.4% 100.0%
少数民族分类中的% 10.5% 13.5% 11.2% 12 年
计数139 51 190
教育水平(年)中的% 73.2% 26.8% 100.0%
少数民族分类中的% 37.6% 49.0% 40.1% 14 年
计数 5 1 6
教育水平(年)中的% 83.3% 16.7% 100.0%
少数民族分类中的% 1.4% 1.0% 1.3% 15 年
计数90 26 116
教育水平(年)中的% 77.6% 22.4% 100.0%
少数民族分类中的% 24.3% 25.0% 24.5% 16 年
计数52 7 59
教育水平(年)中的% 88.1% 11.9% 100.0%
少数民族分类中的% 14.1% 6.7% 12.4% 17 年
计数8 3 11
教育水平(年)中的% 72.7% 27.3% 100.0%
少数民族分类中的% 2.2% 2.9% 2.3% 18 年
计数8 1 9
教育水平(年)中的% 88.9% 11.1% 100.0%
少数民族分类中的% 2.2% 1.0% 1.9% 19 年
计数26 1 27
教育水平(年)中的% 96.3% 3.7% 100.0%
少数民族分类中的% 7.0% 1.0% 5.7% 20 年
计数 2 0 2
教育水平(年)中的% 100.0% 0.0% 100.0%
少数民族分类中的% 0.5% 0.0% 0.4% 21 年
计数 1 0 1
教育水平(年)中的% 100.0% 0.0% 100.0%
少数民族分类中的% 0.3% 0.0% 0.2%
合计计数370 104 474 教育水平(年)中的% 78.1% 21.9% 100.0% 少数民族分类中的% 100.0% 100.0% 100.0%
(3)这些属性和工资之间的关系
实验结果与结论:
通过实验了解统计描述的常用工具及SPSS中的统计描述模块,掌握分类变量和连续变量的统计描述方法及指标。
可知男性工资比女性高,教育程度高,工资高。少数民族工资比汉族低。职位高,工资高。
成绩评定:
实验日期:2014.3.11
指导教师签名:敖希琴
spss_期末试题库
一、单项选择题(共112小题) 1、SPSS的安装类型有()D.以上都是 2、数据编辑窗口的主要功能有() D.A和B 3、()文件格式是SPSS独有的,一般无法通过Word,Excel等其他软件打开。A.sav 4、()是SPSS为用户提供的基本运行方式。D.以上都是 5、()是SPSS中有可用的基本数据类型 D.以上都是 6、spss数据文件的扩展名是( ) D..sav 7、数据编辑窗口中的一行称为一个()B.个案 8、变量的起名规则一般:变量名的字符个数不多于()C. 8 9、统计学依据数据的计量尺度将数据划分为三大类,它不包括() A. 定值型数据 10、在横向合并数据文件时,两个数据文件都必须事先按关键变量值() A.升序排序 11、SPSS算术表达式中,字符型()应该用引号引起来。A 常量 12、复合条件表达式又称逻辑表达式,在逻辑运算中,下列()运算最优先。 A.NOT 13、数据选取的方法中,()是按符合条件的数据进行选取。A 按指定条件选取 14、通过()可以达到将数据编辑窗口中的技术数据还原为原始数据的目的. B 加权处理 15、SPSS的()就是将数据编辑窗口中数据的行列互换 A 数据转置 16、SPSS软件是20世纪60年代末,由()大学的三位研究生最早研制开发的。B、斯坦福大学 17、SPSS中进行参数检验应选择()主窗口菜单。D、分析 18、SPSS中进行输出结果的保存应选择()主窗口菜单。A、视图 19、SPSS中进行数据的排序应选择()主窗口菜单。C、数据 20、SPSS中绘制散点图应选择()主窗口菜单。C、图形 21、SPSS中生成新变量应选择()主窗口菜单。A、转换 22、SPSS中聚类分析应选择()主窗口菜单。D、分析 23、()的功能是定义SPSS数据的结构、录入编辑和管理待分析的数据。 A.数据编辑窗口 24、()的功能是显示管理SPSS统计分析结果、报表及图形。 B.结果输出窗口 25、Spss输出结果保存时的文件扩展名是()B..spv 26、()是访问和分析Spss变量的唯一标识。B.变量名
SPSS学习资料
SPSS(社会科学统计软件)学习资料 参考书: SPSS for Windows:Base System User’ s Guide. Marija J. Norusis. SPSS Inc. 卢纹岱等编著:SPSS for Windows 从入门到精通。电子工业出版社,1996年. SPSS for Windows made Simple. 3rd ed. Paul R. Kinnear & Colin D. Gray Psychological Press,Ltd.,1999 Electronic Statistical Textbook (from StatSoft) .statsoft./textbook/stathome.html 作业: 必须在次周周一前用电子邮件,磁盘或打印形式交给主讲教师和辅导上机的助教。 讲义: 课前在网上下载或接收电子邮件。 成绩评定方法: 期末考试, 期中考试,和作业,出勤。 期末考试 40% 期中考试 30% 作业,出勤 30% 总成绩 100
第一章数据和文件 1准备分析用数据 1.1数据收集 主要是通过测量方法收集必需的数据。测量方法可以是实验、测验、问卷调查等等。应尽可能包括自己所需要的所有变量,因为从分析中排除不必要的变量比收集附加变量要容易得多。 1.2数据编码 当我们通过问卷或测验收集了很多的数据回来后,接下来的工作就是把这些数据录入到计算机里。为了输入数据简单,一种方法是在录入前用数据或符号表述被试的回答,这就是数据编码。下面是一个编码表: 些特殊信息的Case。 (编码示例) 不管你自己对SPSS使用多么熟悉,在数据录入前对数据进行系统的编码是非常必要的,它可以使你避免混乱,清楚了解数据的意义。 1.3数据文件 SPSS有三种文件:SYNTAX 文件(文本文件,以.sps为后缀)、DATA文件(数
【精品】(最新)多选题数据的SPSS多重对应分析操作方法
多选题数据的SPSS多重对应分析操作方法 出处:江苏通灵翠钻有限公司发布日期:2008年04月17日10:18 多选题又称多重应答(Multiple Response),即针对同一个问题被访者可能回答出多个有效的答案,它是市场调查研究中十分常见的数据形式。对多选题数据的分析除了使用SPSS 中的“Multiple Response”命令进行频数分析和交叉分析之外,还可以使用“Data Reduction”命令中的“Optimal Scaling”(最优尺度分析)进行多重对应分析,用以挖掘该数据与其他若干个变量之间的相互关系。 一、多选题数据在SPSS中的录入方式 SPSS软件中对于多选题答案的标准纪录方式有两种:(1)多重二分法(Multiple dichotomy method)即把本道多选题的每个候选答案均看作一个变量Variable来定义,0代表没有被选中,1代表被选中。(2)多重分类法(Multiple category method)即根据被访者可能提供的答案数量来设置相应个数的变量Variable(假设被访者最多只能选择n个不同答案,则在SPSS中设置n个变量用以录入本道多选题数据)。 实际操作中我们基本都会采用第二种数据录入方式,因为大多数被访者只会选择相对少数几个候选答案作为自己所提交的答案,如果我们采用第一种录入方式就显得繁琐,输入数据时也容易出错,尤其是当样本量增大时,不利于提高工作效率。 二、案例介绍 某次市场调研项目中向被访者收集以下数据,A1题为多选题,把上述数据以第二种方式录入进SPSS软件中,其中设置a101、a102、a103三个变量用来录入多选题A1,并定义好相应的变量值标签(Values)如图1。 三、多选题两种数据录入格式的转换 由于只有第一种数据录入方式才是符合统计分析原则的数据排列格式,能够直接进行后续的
spss统计分析报告期末考精彩试题
《统计分析软件》试(题)卷 班级xxx班xxx 学号xxx 说明:1.本试卷分析结果写在每个题目下面(即所留空白处); 2.考试时间为100分钟; 3.每个试题20分。 一、(20分)已经给出某个班的学生基本情况及其学习成绩的两个SPSS数据文件,学生成绩一.sav;学生成绩二.sav。要求: (1)将所给的两个SPSS数据文件“学生成绩一.sav”与“学生成绩二.sav”合并,并保存为“成绩.sav.” (2)对所建立的数据文件“成绩.sav”进行以下处理: 1)按照性别求出男、女数学成绩的各种统计量(包括平均成绩、标准差等)。 2)计算每个学生的总成绩、并按照总成绩的大小进行排序 3)把数学成绩分成优、良、中三个等级,规则为优(X≥85),良(75≤X≤84),中(X≤74),并对优良中的人数进行统计。
分析: (2) 描述统计量 性别N 极小值极大值均值标准差 男数学 4 77.00 85.00 82.2500 3.77492 有效的N (列表状态) 4 女数学16 67.00 90.00 78.5000 7.09930 有效的N (列表状态)16
注:成绩优良表示栏位sxcj 优为1 良为2 中为3 由表统计得,成绩为优的同学有4人,占总人数的20%;良的同学有12人,占总人数的60%;中的同学有4人,占总人数的40%。 二、(20分)为了解笔记本电脑的市场情况,针对笔记本电脑的3种品牌,进行了满意度调查,随机访问了30位消费者,让他们选出自己满意的品牌,调查结果见下表,其中变量“职业”的取值中,1表示文秘人员,2表示管理人员,3表示工程师,4表示其他人;3个品牌变量的取值中,1表示选择,0表示未选数据见Excel 数据文件“调查.exe”。根据所给数据完成以下问题 (1)将所给数据的Excel文件导入到SPSS中,要求SPSS数据文件写出数据结构(包括变量名,变量类型,变量值标签等)命,并保存为:“调查. Sav”。 (2)试利用多选项分析,利用频数分析来分析消费者对不同品牌电脑的满意度状况;分析不同职业消费者对笔记本品牌满意度状况。
SPSS课程学习心得体会
应用统计分析学习报告 本科的时候有概率统计和数理分析的基础,但是从来没有接触过应用统计分析的东西,spss也只是听说过,从来没有学过。一直以为这一块儿会比较难,这学期最初学的时候,因为没有认真看老师给的英文教材,课下也没有认真搜集相关资料,所以学起来有些吃力,总感觉听起来一头雾水。老师说最后的考核是通过提交学习报告,然后我从图书馆里借了些教材查了些资料,发现很多问题都弄清楚了。结合软件和书上的例子,实战一下,发现spss 的功能相当强大。最后总结出这篇报告,以巩固所学。 spss,全称是statistical product and service solutions,即“统计产品与服务解决方案”软件,是ibm公司推出的一系列用于统计学分析运算、数据挖掘、预测分析和决策支持任务的软件产品及相关服务的总称,也是世界上公认的三大数据分析软件之一。spss具有统计分析功能强大、操作界面友好、与其他软件交互性好等特点,被广泛应用于经济管理、医疗卫生、自然科学等各个领域。具体到管理方面,spss也是一个进行数据分析和预测的强大工具。这门课中也会用到amos软件。 关于spss的书,很多都是首先介绍软件的。这个软件易于安装,我装的是19.0的,虽然20.0有一些改变和优化,但是主体都是一样的,而且都是可视化界面,用起来很方面且容易上手。所以,我学习的重点是卡方检验和t检验、方差分析、相关分析、回归分析、因子分析、结构方程模型等方法的适用范围、应用价值、计算方式、结果的解释和表述。 首先是t检验这一部分。由于参数检验的基础不牢固,这部分也是最初开始接触应用统计的东西,学起来很多东西拿不准,比如说原假设默认的是什么。结果出来后依然分不清楚是接受原假设还是拒绝原假设。不过现在弄懂了。这部分很有用的是t检验。t检验应用于当样本数较小时,且样本取自正态总体同时做两样本均数比较时,还要求两样本的总体方差相等时,已知一个总体均数u,可得到一个样本均数及该样本标准差,样本来自正态或近似正态总体。t检验分为单样本t检验、独立样本t检验、配对样本t检验。其中,单样本t 检验是样本均数与总体均数的比较的t检验,用于推断样本所代表的未知总体均数μ与已知的总体均数uo有无差别;独立样本t检验主要用于检验两个样本是否来自具有相同均值的总体,即比较两个样本的均值是否相同,要求两个样本是相互独立的;配对样本t检验中,要正确理解“配对”的含义,主要用于检验两个有联系的正态总体的均值是否有显著差异,跟独立检验的区别就是样本是否是配对样本。这几个方法用软件操作起来都是相对简单的,关键是分清楚什么时候用这个什么时候用那个。 然后是方差分析。方差分析就是将索要处理的观测值作为一个整体,按照变异的不同来源把观测值总变异的平方和以及自由度分解为两个或多个部分,获得不同变异来源的均值与误差均方,通过比较不同变异来源的均方与误差均方,判断各样本所属总体方差是否相等。方差分析主要包括单因素方差分析、多因素方差分析和协方差分析等。这一部分在学习的过程中出现一些问题,就是用spss来操作的时候分不清观测变量和控制变量,如果反了的话会导致结果的不准确。其次,对bonferroni、tukey、scheffe等方法的使用目的不清楚,现在基本掌握了多重比较方法选择:一般如果存在明确的对照组,要进行的是验证性研究,即计划好的某两个或几个组间(和对照组)的比较。宜用bonferroni(lsd)法;若需要进行多个均数间的两两比较,且各组个案数相等,适宜用tukey法;其他情况宜用scheffe法。最后,对方差齐性检验、多重比较检验、趋势检验理解不够透彻,在方差检验中,post hoc键有lsd 的选项:当方差分析f检验否定了原假设,即认为至少有两个总体的均值存在显著性差异时,须进一步确定是哪两个或哪几个均值显著地不同,则需要进行多重比较来检验。lsd即是一种多因变量的三个或三个以上水平下均值之间进行的两两比较检验。 相关分析是研究现象之间是否存在某种依存关系,并对具体有依存关系的现象探讨(转载于:spss课程学习心得体会)其相关方向以及相关程度,是研究随机变量之间的相关关系的一
spss多选题录入与分析
spss多选题录入与分析1 -----不限定选择项的录入及分析 2011-03-12 20:57 在市场调查和社会学调查等问卷设计过程中,通常会设计各种多选题,甚至排序而这些多选题或排序题又是必不可少的,因此就需要对各种多选题、排序题进行录入和入和分析为例,来讨论下多选题和排序题的录入及分析。 1多选题的录入和分析 分析时,由于var001-var005是一个多选题的答案,因此需要先进行多重响应设计,
如下所示 或者在“分析”---“表”----“多响应集”中,如下所示 两者弹出的窗口相差不大,我们以第一种“定义变量集”来进行,点击之后,弹出 在“设置定义”对话框会列出所有的需要设置的变量,其中包括多选题的变量,将移入右边“集合中的变量”,然后下方的“将变量编码为”“二分法”,计数值输入“1的频率,然后名称中输入该多选题的题目名称之后,“添加”到“多响应集”,点击定义好之后,再点击“多重响应”,可以看到,多出两个菜单选项,如下所示
spss统计分析期末考试题
《统计分析软件》试(题)卷 班级 xxx班姓名 xxx 学号 xxx 说明:1.本试卷分析结果写在每个题目下面(即所留空白处); 2.考试时间为100分钟; 3.每个试题20分。 一、(20分)已经给出某个班的学生基本情况及其学习成绩的两个SPSS数据文件,学生成绩一.sav;学生成绩二.sav。要求: (1)将所给的两个SPSS数据文件“学生成绩一.sav”与“学生成绩二.sav”合并,并保存为“成绩.sav.” (2)对所建立的数据文件“成绩.sav”进行以下处理: 1)按照性别求出男、女数学成绩的各种统计量(包括平均成绩、标准差等)。 2)计算每个学生的总成绩、并按照总成绩的大小进行排序 3)把数学成绩分成优、良、中三个等级,规则为优(X≥85),良(75≤X ≤84),中(X≤74),并对优良中的人数进行统计。
分析: 描述统计量 性别N极小值极大值均值标准差 男数学477.0085.0082.2500 3.77492有效的 N (列表状态)4 女数学1667.0090.0078.50007.09930有效的 N (列表状态)16
注:成绩优良表示栏位sxcj 优为1 良为2 中为3 由表统计得,成绩为优的同学有4人,占总人数的20%;良的同学有12人,占总人数的60%;中的同学有4人,占总人数的40%。 二、(20分)为了解笔记本电脑的市场情况,针对笔记本电脑的3种品牌,进行了满意度调查,随机访问了30位消费者,让他们选出自己满意的品牌,调查结果见下表,其中变量“职业”的取值中,1表示文秘人员,2表示管理人员,3表示工程师,4表示其他人;3个品牌变量的取值中,1表示选择,0表示未选数据见Excel数据文件“调查.exe”。根据所给数据完成以下问题 (1)将所给数据的Excel文件导入到SPSS中,要求SPSS数据文件写出数据结构(包括变量名,变量类型,变量值标签等)命,并保存为:“调查. Sav”。 (2)试利用多选项分析,利用频数分析来分析消费者对不同品牌电脑的满意度状况;分析不同职业消费者对笔记本品牌满意度状况。 分析:
spss多选题的录入及分析
spss多选题录入与分析1 不限定选择项的录入及分析 在市场调查和社会学调查等问卷设计过程中,通常会设计各种多选题,甚至排序题,来进行信息的搜集,而这些多选题或排序题又是必不可少的,因此就需要对各种多选题、排序题进行录入和分析,在这里以spss的录入和分析为例,来讨论下多选题和排序题的录入及分析。 1多选题的录入和分析
spss 期末题库
课程名称:《SPSS分析方法与应用》 课程号: 2007422 一、单项选择题(共112小题) 1、试题编号:1000110,答案:RetEncryption(D)。 SPSS的安装类型有() A. 典型安装 B.压缩安装 C.用户自定义安装 D.以上都是 2、试题编号:1000310,答案:RetEncryption(D)。 数据编辑窗口的主要功能有() A.定义SPSS数据的结构 B.录入编辑和管理待分析的数据 C.结果输出 和B 3、试题编号:1000410,答案:RetEncryption(A)。 ()文件格式是SPSS独有的,一般无法通过Word,Excel等其他软件打开。 4、试题编号:1000510,答案:RetEncryption(D)。 ()是SPSS为用户提供的基本运行方式。 A.完全窗口菜单方式 B.程序运行方式 C.混合运行方式 D.以上都是 5、试题编号:1000810,答案:RetEncryption(D)。 ()是SPSS中有可用的基本数据类型 A.数值型 B.字符型 C.日期型 D.以上都是 6、试题编号:1000910,答案:RetEncryption(D)。 spss数据文件的扩展名是( ) A..htm B..xls C..dat D..sav 7、试题编号:1001010,答案:RetEncryption(B)。 数据编辑窗口中的一行称为一个() A.变量 B.个案 C.属性 D.元组 8、试题编号:1001110,答案:RetEncryption(C)。
变量的起名规则一般:变量名的字符个数不多于() A. 6 B. 7 C. 8 D. 9 9、试题编号:1001210,答案:RetEncryption(A)。 统计学依据数据的计量尺度将数据划分为三大类,它不包括() A. 定值型数据 B.定距型数据 C.定序型数据 D.定类型数据 10、试题编号:1001310,答案:RetEncryption(A)。 在横向合并数据文件时,两个数据文件都必须事先按关键变量值() A.升序排序 B.降序排序 C.不排序 D.可升可降 11、试题编号:1001810,答案:RetEncryption(A)。 SPSS算术表达式中,字符型()应该用引号引起来。 A 常量 B变量 C算术运算符 D函数 12、试题编号:1001910,答案:RetEncryption(A)。 复合条件表达式又称逻辑表达式,在逻辑运算中,下列()运算最优先。 B AND C OR D都不是 13、试题编号:1002010,答案:RetEncryption(A)。 数据选取的方法中,()是按符合条件的数据进行选取。 A 按指定条件选取 B 随即选取 C选取某一区域内样本 D过滤变量选取 14、试题编号:1002110,答案:RetEncryption(B)。 通过()可以达到将数据编辑窗口中的技术数据还原为原始数据的目的。 A 数据转置 B 加权处理 C 数据才分 D以上都是 15、试题编号:1002210,答案:RetEncryption(A)。 SPSS的()就是将数据编辑窗口中数据的行列互换 A 数据转置 B 加权处理 C 数据才分 D以上不都是 16、试题编号:1002310,答案:RetEncryption(B)。 SPSS软件是20世纪60年代末,由()大学的三位研究生最早研制开发的。 A、哈佛大学 B、斯坦福大学 C、波士顿大学 D、剑桥大学 17、试题编号:1002710,答案:RetEncryption(D)。 SPSS中进行参数检验应选择()主窗口菜单。 A、视图 B、编辑 C、文件 D、分析 18、试题编号:1002810,答案:RetEncryption(A)。 SPSS中进行输出结果的保存应选择()主窗口菜单。 A、视图 B、编辑 C、文件 D、分析 19、试题编号:1002910,答案:RetEncryption(C)。 SPSS中进行数据的排序应选择()主窗口菜单。 A、视图 B、编辑 C、数据 D、分析
spss学习心得
学院:传播学院专业:10级广播电视新闻学 学号:129012010023 姓名:许咪咪 学习SPSS有感——与EXCEL之比较 在学习SPSS软件的过程中,自己不敢有丝毫松懈,但同时感到学习压力很大,有一定的学习难度,软件的操作可以通过短时间内熟悉,但对数据的结果分析还需要很大很大的提高。在掌握了SPSS相关技能和熟知了SPSS之于EXCEL的优越性之后,SPSS成了往后我进行数据分析、调查的首选软件,如若能自由地结合二者使用,便是更佳选择。 Excel的基本功能中包括了比较强大的数据处理功能,还提供了丰富的工作表函数,可以完成很多类型的数据处理和分析任务。除了工作表函数以外,Excel还提供了一个称为“分析工具库”的加载宏。 Excel应用的普及性,许多人都把它作为最常用的统计软件来使用。Excel提供的统计功能包括数据管理、描述统计、概率计算、假设检验、方差分析和回归分析等等,对于统计学原理所涉及的大部分内容已经足够了。然而,在学习Excel 的统计功能以前我们有必要先交待一下Excel在统计分析方面的局限性。 1、就统计学原理所涉及的统计方法而言,Excel没有直接提供的方法包括:箱线图(Boxplot)、茎叶图、相关系数的p-值、无交互作用可重复的双因素方差分析、方差分析中的多重比较、非参数检验方法、质量控制图等。 2、按照优秀图形的标准,Excel做出的很多图形都不合格。Excel的有些图形可能适合于普通大众,但不适合用于科学报告中。例如二维图形的三维表示,圆柱图,圆锥图等等。 Excel提供的有些图形可能永远不应该使用。 3、Excel不能很好的处理缺失值(Missing data)问题。总体来说Excel对缺失值的处理方式远不如专门的统计软件恰当。 4、虽然大部分情况下Excel的计算结果都是可靠的,但在一些极端情况下Excel 的计算程序不够稳定和准确(特别是Excel2003以前的版本中);有些自动功能可能会导致意想不到地结果。 总体来说,Excel为我们输入和管理数据、描述数据特征、制作统计表和统计图都提供了强大的支持,但在处理复杂的计算时有时候误差相对较大,因而一些数据处理专家建议人们避免采用Excel处理复杂的统计问题。SPSS能在简单操作基础上,解决EXCEL存在的这些问题,甚至非统计学相关专业的人员也可以利用这个软件对复杂的统计问题进行处理、分析。 平时我惯常使用的数据分析软件也是Excel。虽然使用Excel可以对数据进行透视、分类、筛选以及计算相关系数等,但是这些操作都需要自己每一步每一步的进行手动操作,而使用SPSS软件在对数据进行整理时,只需对软件某选项内设
使用SPSS软件对多项选择题作卡方检验的方法
市场研究200510■■市场调研中经常遇到多项选择题的统计问题。本文选择如下例子,说明传统的统计方法,并提出卡方检验的方法。您挑选Mp3时考虑的因素有哪些(多选):(1)价格;(2)款式;(3)品牌;(4)购买 地点;(5)购场的环境与氛围;(6)个人情绪;(7)其他。 一直以来,这类题目使用SPSS软件的MultipleResponse进行统计分析,具体方法如下: 第一步:打开MultipleResponse对话框的DefineSets。第二步:将待设置的多项选择题变量(SetDefinition)选入变量设置框(VariablesinSet)。 第三步:根据输入变量的编码方式选择读码方式(VariablesAreCodedAs…)。本例子采用直接输入法(详见《市场研究》2005年5期拙作),分列读取后在类别变量的Range中填入“1-7” 。第四步:设置新变量名为“偏好”之后点击Add、Close即完成设置。 变量设置完成后,就可以作多项选择题的列联表分析了。本例 选择不同性别学生的消费偏好。打开MultipleResponse对话框中的Crosstabs,将性别点击进入Column框,并设置其Range为“1-2”,其中1表示男生,2表示女生;将MultipleResponse框中的“$偏好”点击进入Rows框。其他使用默认设置后点击“OK”即可。结果如下: 本例只选择了15份样本,其中男生7人,女生8人。表格中的数据表明,选择价格的男生有6人,女生有6人,共计12人次;选择款式的男生有5人,女生有7人,共计12人次,其他以此类推。 此后,建立新的数据文件,设置两个变量,变量名分别为“性别”与“偏好”。按照表1的数据,以此输入的数据,其中,性别中的1表示男生,2表示女生;偏好中的1表示价格,2表示款式,3表示品牌,4表示购买地点,5表示购场环境,6表示个人情绪,如下: 使用 SPSS 软 件对多项选择题作卡方检验的方法 "华中农业大学曾祥明任佳慧 表1多项选择题的一般结果(%baseoncase) Count 价格款式品牌 购买地点购场环境个人情绪 ColumnTotal 男 6571017(46.7%) 女 6763208(53.3%) RowTotal12(80.0%)12(80.0%)13(86.7%)4(26.7%)2(13.3%)1(6.7%)15(100.0) Percentsandtotalsbasedonrespondents;15validcases;0miss-ingcases 理论与方法 ! "
《spss统计软件》练习题库及答案
华中师范大学网络教育学院 《SPSS统计软件》练习题库及答案(本科) 一、选择题(选择类) (A)1、在数据中插入变量的操作要用到的菜单是: A Insert Variable; B Insert Case; C Go to Case; D Weight Cases (C)2、在原有变量上通过一定的计算产生新变量的操作所用到的菜单是: A Sort Cases; B Select Cases; C Compute; D Categorize Variables — (C)3、Transpose菜单的功能是: A 对数据进行分类汇总; B 对数据进行加权处理; C 对数据进行行列转置; D 按某变量分割数据 (A)4、用One-Way ANOVA进行大、中、小城市16岁男性青年平均身高的比较,结果给出sig.=,说明: A. 按照显著性水平,拒绝H0,说明三种城市的平均身高有差别; B. 三种城市身高没有差别的可能性是; C. 三种城市身高有差别的可能性是; 、 D. 说明城市不是身高的一个影响因素 (B)5、下面的例子可以用Paired-Samples T Test过程进行分析的是:A 家庭主妇和女大学生对同种商品喜好的差异; B 服用某种药物前后病情的改变情况; C 服用药物和没有服用药物的病人身体状况的差异; D性别和年龄对雇员薪水的影响 二、填空题(填空类) 6、Merge Files菜单用于合并数据库有两种情况:如果两数据库变量相同,是_观测对象__的合并;如果不同,则是_变量__的合并。 7、用于对计数资料和有序分类资料进行统计描述和简单的统计推断,在分析时可以产生二维或多维列联表,在统计推断时能进行卡方检验的菜单是_ Crosstabs __。 % 8、One-Samples T Test过程用于进行样本所在总体均数___与__已知总体均数_的比较。 三、名词解释(问答类) 9、Repeated Measures:重复测量的方差分析,指的是一个因变量被重复测量好几次,从而同一个个体的几次观察结果间存在相关,这样就不满足普通分析的要求,需要用重复测量的方差分析模型来解决。 10、Chi-Square test:卡方检验,它是非参数检验的一种方法,来检验变量的几个取值所占百分比是否和我们期望的比例没有统计学差异。比如我们在人群中抽取了一个样本,可以用该方法来分析四种血型所占的比例是否相同(都是25%),或者是否符合我们所给出的一个比例(如分别为10%、30%、40%和20%)。 四、简答题(问答类) 11、用SPSS对数据进行分析的基本流程是什么 答:(1)、将数据输入SPSS,并保存; { (2)、进行必要的预分析(分布图、均数标准差等的描述等),以确定应采用的检验方法; (3)、按题目要求进行统计分析; (4)、保存和导出分析结果。 12、对数据进行方差分析时,Univariate菜单和Multivariate菜单最大的区别是什么 答:当因变量只有一个时,使用Univariate菜单,当因变量不止一个时,使用Multivariate菜单。 13、简述SPSS打开其它格式数据的几种方法 答:(1)、直接打开:选择菜单File==>Open==>Data或直接单击快捷工具栏上的打开按钮; (2)、使用数据库查询打开:选择菜单File==>Open Database==>New Query,根据向导打开数据; (3)、使用文本向导读入文本文件:选择菜单File==>Read Text Data ) 14、指定数据按某个变量进行排序需要用到哪个菜单
SPSS学习心得
SPSS应用 交叉频数表:统计量用卡方检验,观察实际频数、期望频数、剩余(观察频数-期望频数)、标准化剩余 卡方检验:一般要求列联表中的期望频数小于5的格子数不超过20%,否则会夸大卡方值,容易得出拒绝结论,可以合并单元格。 样本书对卡方有影响可以用修正的卡方检验 phi系数和V系数(0~1)之间,越大表示行列变量地相关性越大。 单因素方差分析的多重比较:总体均值存在差异时,F检验不能说明那个水平造成了观察变量的显著差异,多重比较对每个水平的均值逐对进行比较检验。 多重比较方法选择:一般如果存在明确的对照组,要进行的是验证性研究,即计划好的某两个或几个组间(和对照组)的比较。宜用Bonferroni(LSD)法;若需要进行多个均数间的两两比较(探索性研究),且各组个案数相等,适宜用Tukey法;其他情况宜用Scheffe法。 聚类分析:变量的选择——无关变量有时会引起严重的错分,应当只引入在不同类间有显著差别的变量,尽量只使用相同类型的变量进行分析 共线性问题——对记录聚类结果有较大的影响,最好先进行预处理 变量的标准化——变量变异程度相差非常大时需要进行,标准化后会消弱有用变量的作用 异常值——影响较大,还没有比较好的解决办法,尽力避免 分类数——从实用角度讲,2~8 类比较合适 K-means Cluster 过程——样本量大于100时有必要考虑,只能使用连续性变量 Hierarchical Cluster 过程——一旦观测、变量被划定类别,其分类结果就不会在进行更改;可以对变量或记录进行聚类;变量可以为连续或分类变量;提供的距离测量方法非常丰富;运算速度较慢 具体的分类数不明时,需要输出全部结果;方差和均数相差不大,无需进行标准化 判别分析Fisher判别法——与主成份分析有关;对分布、方差等都没有什么限制Bayes 判别——计算该样品落入各个子域的概率;强项是进行多类判别;要求总体呈多元正态分布 判别分析适用条件——各变量为连续性或有序分分类变量;样本来自一个多元正态总体(该前提几乎做不到);各组的协方差矩阵相等(类似与方差分析中的方差齐性);变量间独立,无共线性;违反条件影响也不大 主成份分析 因子负荷——即表达式中个因子的系数值,用于反映因子和各个变量间的密切程度,其实质是两者间的相关系数 公因子方差比(Communalitise)指提取公因子后,变量中信息分别被提取出的比例,或者说原变量的方差中由公因子决定的比例 特征根——可以被看成是主成份影响力度的指标,代表引入该因子、主成分后可以解释
SPSS多选题的数据录入方法
SPSS问卷分析之编码录入及描述统计详解 问卷调查的方法用得很广泛,第一步面临的就是问卷编码问题,有很多外专业的同学都在问这个问题,现在通过举例的方法详细讲解如下,以方便第一次接触SPSS的同学也能做简单的分析。后面还有分析时的操作步骤,以及比较适用的深入统计分析方法的简单介绍。自己写的,错误之处请指正. 调查分析问卷回收,在经过核实和清理后就要用SPSS做数据分析,首先的第一步就是把问题编码录入。 SPSS的问卷分析中一份问卷是一个案,首先要根据问卷问题的不同定义变量。定义变量值得注意的两点:一区分变量的度量,Measure的值,其中Scale是定量、Ordinal是定序、Nominal是指定类;二注意定义不同的数据类型Type 各色各样的问卷题目的类型大致可以分为单选、多选、排序、开放题目四种类型,他们的变量的定义和处理的方法各有不同,我们详细举例介绍如下: 1 单选题:答案只能有一个选项 例一当前贵组织机构是否设有面向组织的职业生涯规划系统? A有 B 正在开创 C 没有D曾经有过但已中断 编码:只定义一个变量,Value值1、2、3、4分别代表A、B、C、D 四个选项。 录入:录入选项对应值,如选C则录入3 2 多选题:答案可以有多个选项,其中又有项数不定多选和项数定多选。 (1)方法一(二分法): 例二贵处的职业生涯规划系统工作涵盖哪些组群?画钩时请把所有提示考虑在内。 A月薪员工B日薪员工C钟点工 编码:把每一个相应选项定义为一个变量,每一个变量Value值均如下定义:“0” 未选,“1” 选。
录入:被调查者选了的选项录入1、没选录入0,如选择被调查者选AC,则三个变量分别录入为1、0、1。 (2)方法二: 例三你认为开展保持党员先进性教育活动的最重要的目标是那三项: 1()2 ()3() A、提高党员素质 B、加强基层组织 C、坚持发扬** D、激发创业热情 E、服务人民群众 F、促进各项工作 编码:定义三个变量分别代表题目中的1、2、3三个括号,三个变量Value值均同样的以对应的选项定义,即:“1” A,“2” B,“3” C,“4” D,“5” E,“6” F 录入:录入的数值1、2、3、4、5、6分别代表选项ABCDEF,相应录入到每个括号对应的变量下。如被调查者三个括号分别选ACF,则在三个变量下分别录入1、3、6。 注:能用方法二编码的多选题也能用方法编码,但是项数不定的多选只能用二分法,即方法一是多选题一般处理方法。 3 排序题:对选项重要性进行排序 例四您购买商品时在①品牌②流行③质量④实用⑤价格中对它们的关注程度先后顺序是(请填代号重新排列)第一位第二位第三位第四位第五位 编码:定义五个变量,分别可以代表第一位第五位,每个变量的Value都做如下定义:“1” 品牌,“2” 流行,“3” 质量,“4” 实用,“5” 价格 录入:录入的数字1、2、3、4、5分别代表五个选项,如被调查者把质量排在第一位则在代表第一位的变量下输入“3“。 4 选择排序题: 例五把例三中的问题改为“你认为开展保持党员先进性教育活动的最重的目标是那三项,并按重要性从高到低排序”,选项不变。 编码:以ABCDEF6个选项分别对应定义6个变量,每个变量的Value都做同样的如下定义:“1” 未选,“2” 排第一,“3” 排第二,“4” 排第三。
调查问卷数据SPSS分析中—多项选择问题处理方法
SPSS多项选择问题处理方法 多项选择题是定量问卷调查中常见的封闭式选择题,这种选择题的出现可以在确定的范围内更多的考察被调研对象的看法。在针对消费者的调研中,这种选择题多是出现在针对品牌知名度,包括提示前知名度、第一提及率,提示后知名度的分析中。 ?常见的分析方法 一般的研究分析手段主要应用包括EXCEL与SPSS在内的频次分析,然后再将在不同数据字段同一类选项数据进行加总,然后再以被调研对象的总体数量为基数,二者相除来得到多项选择题中各选项在总体中的占有率,这种各选项占有率的加总大于1。 例如某类产品品牌知名度调查中,关于该类产品您能想起哪些品牌? 01 品牌A 02品牌B 03品牌C 04品牌D 05品牌E 06品牌F 07其它品牌_____ 该问题在数据字段设计时最少要设计10个字段以供数据录入与分析。按上面的数据分析方法,先在这10个字段中进行分别的频次计算,然后进行加总再除以总基数,得到该选项的总体占有比率。以A选项为例: (01字段中A的占有率+02字段中A的占有率+ …… +06字段中A的占有率)/被调对象总数=A的占有率以此类推分别计算出其它品牌的占有率,频次计算次数与分类加和计算次数比较繁杂,其工作量在被选项较少时还算省事,但当被选项数量在十几个、二十几个甚至三十几个时,该分析方法则极大降低了分析人员的工作效率。 ?高效率数据分析方法 运用SPSS重组再分析的数据方法将极大提高数据分析效率并降低人为计算失误。 在SPSS数据库中运用 “Multiple Response”对多组数据进行组合再定义,这样会针对每个单一选择题定义出一个新的字段组,在新字段组中对变量区间进行定义,再针对新字段组进行频次分析。当完成单一字段设置后,可运用程序段对其它多项选择题进行再利用分析,这样可以大大提高多项选择题数据分析效率。 分析程序例举: ************** MULT RESPONSE GROUPS=$tsh '新字段组名称' (var00018 var00019 var00020 var00021 var00022 var00013 var00014 var00015 var00016 var00017 (1,111))
SPSS期末考试整理
●一。变量的赋值 1.乘方(**),例如二的三次方:2**3 2.不同规则的赋值:转换→计算变量(如果),每一个规则的赋值都要重新进行此步骤(但注意每一遍的变量名都不变,并且他都会问你要不要替换成新的变量,你选是就行了) 3.不同规则的赋值:(1)转换→重新编码为不同变量:输入变量,输出变量,要点击“变化量”才可保存输出变量→新值和旧值:值(直接选取取值)、范围(最大到最小的范围,包含端点值),点击“添加”成功保存新值和旧值→所有不同取值规则都完成后点击继续、确定,则在变量视图多出一个新变量(2)若不想包含端点值,可以采取小数的方式变换,eg. 899.9(小数位比该变量属性的小数位多一位就行了) (3)这种要先把BMI按照男女分开,然后再分组的,可以在对话框中点击“如果”选项进行设置,并且要分别对男女进行上述操作(一共做两遍)。 二。离散化 1可视离散化:转换→可视分箱,分割点:所以想生成几组,就定义几个分割点;填写第一个分割点的时候就必须填写最小值;一定要选中上端点排除。 三。排序 1.转换→自动重新编码:不分组,从头到尾排序 2.转换→个案排秩(1)多层次数据:基于A变量对B变量进行排序。(例如,基于职称对收入进行排序,就是不同职称各自组内排工资的高低)(2)设置秩1;绑定值 四。时间序列:转换→变动值 五。查找与计数:转换→对个案内的值计数(查找“基本工资800-900女职工”,生成新变量,满足这个条件的标为1,不符合这个标准的标为0,男职工标为缺失。范围:包含上限下限) ●六。数据→个案排序:把变量顺序完全按照你想要的标准排序,所有的变量顺序都会改变 七。拆分文件:要分男女进行数据统计:数据→拆分文件→比较组/按组输出,分组依据。不分男女进行数据统计:数据→拆分文件→分析所有个案 八。选择个案(例如只选择三年级的变量进行分析):数据→选择个案→如果条件满足:如果;随机个案样本;基于时间或个案范围;使用过滤变量(例如要把身高为缺失值和值为0的剔除)→输出:过滤(不符合条件的数据会画上“/”,原始数据并未删除);将选定个案复制到新数据集(形成一个新的SPSS数据文件,原始数据并未删除);删除未选定的个案(删除原始数据,不建议使用)→之后在分析的时候就只会分析三年级的变量。不想只分析三年及,记得重新做这一步。 九。加权个案:数据→加权个案(例。100分的有5人)。不想加权了,记得重新做这一步。 十。分类汇总(1)例如算不同年级的人的身高的均值、方差…(只能计算函数)(2)数据→汇总,分界变量(分类标准变量),变量摘要(计算变量),函数:选择计算变量函数,变量名称与标签:定义新生成变量的名称与标签 ●十一。长宽数据的转换 1.长数据变宽数据:索引变量消失变成score的尾缀 (1)数据→重组(重构)→个案重组为变量,标识变量,索引变量,电脑会自动帮你选出是xx xx要重构(不同疗程值不同的变量)。选完上述这些之后就一直点下一步&完成&立即重构&确定即可 (2)注意:当有多个变量需要重构时要自己决定“新变量组的顺序”。(A1A2B1B2;A1B1A2B2) 2.宽数据变长数据:score的尾缀消失变成索引变量 (1)数据→重组(重构)→变量重组为个案,个案组标识:使用选定变量,固定变量(手动选择,电脑不会自动帮你选出了),要转置的变量即值不固定的要重构的变量(手动选择,电脑不会自动帮你选出了)。选完上述这些之后就一直点击下一步&完成&立即重构数据&确定就行了 (2)当有多个变量需要重构时,这块的操作要特别注意:○1首先在“变量组数目”中选择“多个”○2然后在“选择变量”里要对于不同的“目标变量”分别定义“要转置的变量”(在本题中,即对于kidid目标变量定义一遍要转置的变量;对于age目标变量在定义一遍要转置的变量。其中,这两个要转置的变量必须是完全不同的)。但只需要定义一次“个案组标识”&“固定变量”(固定变量是相对于kidid & age都固定的那些变量;而不是说在对kidid进行转置的时候,age就是固定变量了;因此,固定变量只用定义一次且固定变量可以为空)。并且,你要特别注意,“个案组标识”里选择的变量& n个“要转置的变量”里选择的变量&“固定变量”里选择的变量都必须是完全不相同的。