第7章-数据降维--机器学习与应用第二版

第7章数据降维
在很多应用问题中向量的维数会很高。处理高维向量不仅给算法带来了挑战,而且不便于可视化,另外还会面临维数灾难(这一概念将在第14章中介绍)的问题。降低向量的维数是数据分析中一种常用的手段。本章将介绍最经典的线性降维方法-主分量分析,以及非线性降维技术-流形学习算法。
7.1主成分分析
在有些应用中向量的维数非常高。以图像数据为例,对于高度和宽度都为100像素的图像,如果将所有像素值拼接起来形成一个向量,这个向量的维数是10000。一般情况下,向量的各个分量之间可能存在相关性。直接将向量送入机器学习算法中处理效率会很低,也影响算法的精度。为了可视化显示数据,我们也需要把向量变换到低维空间中。如何降低向量的维数并且去掉各个分量之间的相关性?主成分分析就是达到这种目的方法之一。
7.1.1数据降维问题
主成分分析(principal component analysis,简称PCA)[1]是一种数据降维和去除相关性的方法,它通过线性变换将向量投影到低维空间。对向量进行投影就是对向量左乘一个矩阵,得到结果向量:
y Wx
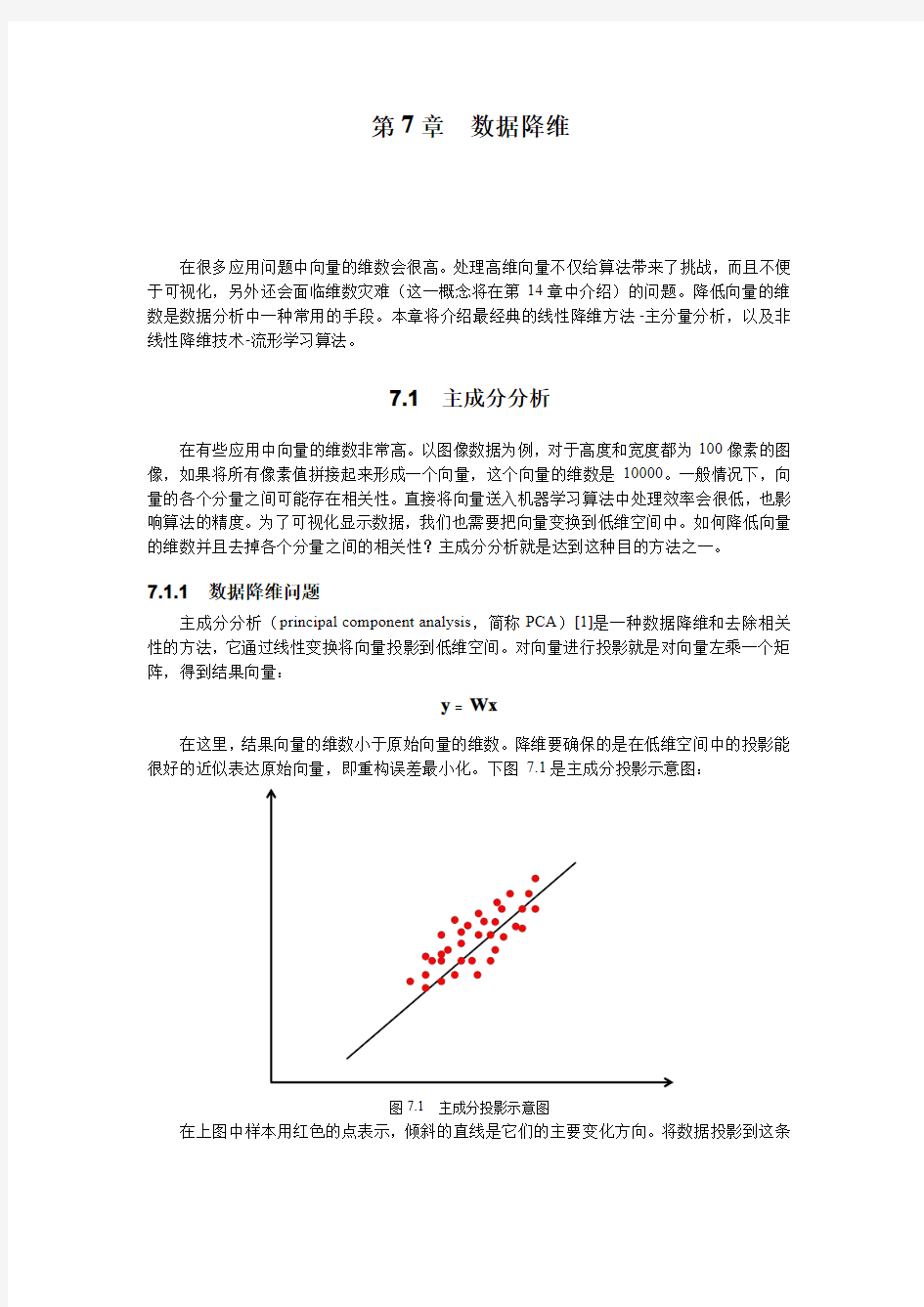
在这里,结果向量的维数小于原始向量的维数。降维要确保的是在低维空间中的投影能很好的近似表达原始向量,即重构误差最小化。下图7.1是主成分投影示意图:
图7.1主成分投影示意图
在上图中样本用红色的点表示,倾斜的直线是它们的主要变化方向。将数据投影到这条
直线上即能完成数据的降维,把数据从2维降为1维。
7.1.2计算投影矩阵
核心的问题是如何得到投影矩阵,和其他机器学习算法一样,它通过优化目标函数而得到。首先考虑最简单的情况,将向量投影到1维空间,然后推广到一般情况。假设有n 个d 维向量i x ,如果要用一个向量0x 来近似代替它们,这个向量取什么值的时候近似代替的误差最小?如果用均方误差作为标准,就是要最小化如下函数:
()2
001n i i L ==-∑x x x 显然问题的最优解是这些向量的均值:
1
1n i i n ==∑m x 证明很简单。为了求上面这个目标函数的极小值,对它求梯度并令梯度等于0,可以得到:
()()001
2n i i L =?=-=∑x x x 0
解这个方程即可得到上面的结论。只用均值代表整个样本集过于简单,误差太大。作为改进,可以将每个向量表示成均值向量和另外一个向量的和:
i i a =+x m e
其中e 为单位向量,i a 是标量。上面这种表示相当于把向量投影到一维空间,坐标就是i a 。当e 和i a 取什么值的时候,这种近似表达的误差最小?这相当于最小化如下误差函数:
()2
1,n i i i L a a ==+-∑e m e x 为了求这个函数的极小值,对i a 求偏导数并令其为0可以得到:
()T 20
i i a +-=e m e x 变形后得到:
()
T T i i a =-e e e x m 由于e 是单位向量,因此T
1=e e ,最后得到:()
T i i a =-e x m 这就是样本和均值的差对向量e 做投影。现在的问题是e 的值如何选确定。定义如下的散布矩阵:
()()
T
1n i i i ==--∑S x m x m 这个矩阵是协方差矩阵的n 倍,协方差矩阵的计算公式为:
()()T 1
1n i i i n ==--∑Σx m x m 将上面求得的i a 代入目标函数中,得到只有变量e 的函数:
()()()
()()()()()()()()
()()()()()()()()()T 1
T T T 1
T 22111
2T T 1
1T T T 1
1T 2 2 n i i i i i n i i i i i i i n n n i i i i i i i n n i i i i i n n i i i i i i L a a ααααα==========+-+-=+-+--=-+--=--+--=---+--=--∑∑∑∑∑∑∑∑∑e e m x e m x e e e m x m x m x m x m x e
x m m x m x e
x m x m e m x m x e Se +m x ()()
T
1n i i i =-∑m x 上式的后半部分和e 无关,由于e 是单位向量,因此有1=e 的约束,这可以写成T 1=e e 。要求解的是一个带等式约束的极值问题,可以使用拉格朗日乘数法。构拉格朗日函数:
()()
T T ,1L λλ=-+-e e Se e e 对e 求梯度并令其为0可以得到:
22λ-=Se +e 0
即:
λ=Se e
λ就是散度矩阵的特征值,e 为它对应的特征向量,因此上面的最优化问题可以归结为矩阵的特征值和特征向量问题。矩阵S 的所有特征向量给出了上面极值问题的所有极值点。矩阵S 是实对称半正定矩阵,因此所有特征值非负。事实上,对于任意的非0向量x ,有:
()()()()()()()()T T T
1T T 1
T T T
1 0n i i i n i i i n i i i ===??=-- ???=--=--≥∑∑∑x Sx x x m x m x x x m x m x
x
x m x x m 因此这个矩阵半正定。这里需要最大化T e Se 的值,由于:
T T λλ
==e Se e e 因此λ为散度矩阵最大的特征值时,T
e Se 有极大值,目标函数取得极小值。将上述结论从一维推广到'
d 维,每个向量可以表示成:'
1d i i i a ==+∑x m e 在这里i e 都是单位向量,并且相互正交,即寻找低维空间中的标准正交基。误差函数变成:
'2
11n d ij j i
i j a ==+-∑∑m e
x 和一维情况类似,可以证明,使得该函数取最小值的j e 为散度矩阵最大的'd 个特征值
对应的单位长度特征向量。即求解下面的优化问题:
()
T T min tr -=W W SW
W W I 其中tr 为矩阵的迹,I 为单位矩阵,该等式约束保证投影基向量是标准正交基。矩阵W 的列j e 是要求解的基向量。散度矩阵是实对称矩阵,属于不同特征值的特征向量相互正交。前面已经证明这个矩阵半正定,特征值非负。这些特征向量构成一组基向量,我们可以用它们的线性组合来表达向量x 。从另外一个角度来看,这种变换将协方差矩阵对角化,相当于去除了各分量之间的相关性。
从上面的推导过程我们可以得到计算投影矩阵的流程为:
1.计算样本集的均值向量。将所有向量减去均值,这称为白化。
2.计算样本集的协方差矩阵。
3.对方差矩阵进行特征值分解,得到所有特征值与特征向量。
4.将特征值从大到小排序,保留最大的一部分特征值对应的特征向量,以它们为行,形成投影矩阵。
具体保留多少个特征值由投影后的向量维数决定。使用协方差矩阵和使用散度矩阵是等
价的,因为后者是前者的n倍,而矩阵A和n A有相同的特征向量。
7.1.3向量降维
得到投影矩阵之后可以进行向量降维,将其投影到低维空间。向量投影的流程为:
1.将样本减掉均值向量。
2.左乘投影矩阵,得到降维后的向量。
7.1.4向量重构
向量重构根据投影后的向量重构原始向量,与向量投影的作用和过程相反。向量重构的流程为:
1.输入向量左乘投影矩阵的转置矩阵。
2.加上均值向量,得到重构后的结果。
从上面的推导过程可以看到,在计算过程中没有使用样本标签值,因此主成分分析是一种无监督学习算法。除了标准算法之外它还有多个变种,如稀疏主成分分析,核主成分分析[2][8],概率主分量分析等。
7.2流形学习
主成分分析是一种线性降维技术,对于非线性数据具有局限性,而在实际应用中很多时候数据是非线性的。此时可以采用非线性降维技术,流形学习(manifold learning)是典型的代表。除此之外,第9章介绍的人工神经网络也能完成非线性降维任务。这些方法都使用非线性函数将原始输入向量x映射成更低维的向量y,向量y要保持x的某些信息:
()
φ
y x
=
流形是几何中的一个概念,它是高维空间中的几何结构,即空间中的点构成的集合,可以简单的将流形理解成二维空间的曲线,三维空间的曲面在更高维空间的推广。下图7.2是三维空间中的一个流形,这是一个卷曲面:
图7.2三维空间中的一个流形
很多应用问题的数据在高维空间中的分布具有某种几何形状,即位于一个低维的流形附近。例如同一个人的人脸图像向量在高维空间中可能是一个复杂的形状。流形学习假设原始数据在高维空间的分布位于某一更低维的流形上,基于这个假设来进行数据的分析。对于降维,要保证降维之后的数据同样满足与高维空间流形有关的几何约束关系。除此之外,流形学习还可以用实现聚类,分类以及回归算法,在后面各章中将会详细介绍。
假设有一个D 维空间中的流形M ,即D
M ? ,流形学习降维要实现的是如下映射:d
M → 其中d D 。即将D 维空间中流形M 上的点映射为d 维空间中的点。下面介绍几种典型的流形降维算法。
7.2.1局部线性嵌入
局部线性嵌入[3](locally linear embedding ,简称LLE )将高维数据投影到低维空间中,并保持数据点之间的局部线性关系。其核心思想是每个点都可以由与它相邻的多个点的线性组合来近似重构,投影到低维空间之后要保持这种线性重构关系,即有相同的重构系数,这也体现了它的名字。
假设数据集由n 个D 维向量i x 组成,它们分布在D 维空间中的一个流形附近。每个数据点和它的邻居位于或者接近于流形的一个局部线性片段上,即可以用邻居点的线性组合来重构,组合系数体现了局部面片的几何特性:
i ij j
j w ≈∑x x
权重ij w 为第j 个数据点对第i 个点的组合权重,这些点的线性组合被用来近似重构数据点i 。权重系数通过最小化下面的重构误差确定:
211min ij n n w i ij j
i j w ==-∑∑x x 在这里还加上了两个约束条件:每个点只由它的邻居来重构,如果j x 不在i x 的邻居集合里则权重值为0。另外限定权重矩阵的每一行元素之和为1,即:
1
ij j w =∑这是一个带约束的优化问题,求解该问题可以得到权重系数。这一问题和主成分分析要求解的问题类似。可以证明,这个权重值对平移、旋转、缩放等几何变换具有不变性。
假设算法将向量从D 维空间的x 映射为d 维空间的y 。每个点在d 维空间中的坐标由下面的最优化问题确定:
211min i n n i ij j
i j w ==-∑∑y y y 这里的权重和上一个优化问题的值相同,在前面已经得到,是已知量。这里优化的目标是i y ,此优化问题等价于求解稀疏矩阵的特征值问题。得到y 之后,即完成了从D 维空间到d 维空间的非线性降维。
下图7.3为用LLE 算法将手写数字图像投影到3维空间后的结果:
图7.3LLE 算法投影到3维空间后的结果
7.2.2拉普拉斯特征映射
拉普拉斯特征映射[4](简称LE )是基于图论的方法。它为样本点构造带权重的图,然后计算图的拉普拉斯矩,对该矩阵进行特征值分解得到投影变换结果。这个结果对应于将样本点投影到低维空间,且保持样本点在高维空间中的相对距离信息。
图是离散数学和数据结构中的一个概念。一个图由顶点和边构成,任意两个节点之间可能都有边进行连接。边可以带有值信息,称为权重,例如两点之间的距离。下图7.4是一个
简单的图:
图7.4一个简单的无向图
图的边可以是有向的,也可以是无向的,前者称为有向图,后者称为无向图。可以将地图表示成一个图,每个地点是顶点,如果两个地点之间有路连接,则有一条边。如果这条路是单行线,则边是有向的,否则是无向的。
顶点的度定义为该顶点所关联的边的数量,对于有向图它还分为出度和入度,出度是指从一个顶点射出的边的数量,入度是连入一个节点的边的数量。无向图可以用三元组形式化的表示:
()
,,V E w 其中V 是顶点的集合,E 是边的集合,w 是边的权重函数,它为每条边赋予一个正的权重值。假设i 和j 为图的顶点,ij w 为边(),i j 的权重,由它构成的矩阵W 称为邻接矩阵。
显然,无向图的邻接矩阵是一个对称矩阵。
拉普拉斯矩阵是图的一种矩阵表示,通过邻接矩阵而构造。定义顶点i 的带权重的度为与该节点相关的所有边的权重之和,即邻接矩阵每一行元素之和
i ij j
d w =∑定义矩阵D 为一个对角矩阵,其主对角线元素为每个顶点带权重的度:
1...0........0...n d d ??????????
其中n 为图的顶点数。图的拉普拉斯矩阵定义为:
=-L D W
无向图的拉普拉斯矩阵是一个对称矩阵,可以证明它是半正定矩阵。对于任意的非0向量f ,有:
T T T 2
111
221111********* 1 221 221 22n n n
i i ij i j i i j n n n n i i ij i j j j i i j j n n n n n n ij i ij i j ji j i j i j j i ij i ij d f w f f d f w f f d f w f w f f w f w f w f ==============-=-??=-+ ???
??=-+ ???=-∑∑∑∑∑∑∑∑∑∑∑∑∑f Lf f Df f Wf
()()211
211
1 02n n i j ji j i j n n ij i j i j f w f w f f ====+=-≥∑∑∑∑因此拉普拉矩阵半正定,另外还可以证明0是这个矩阵的特征值。
假设有一批样本点1,...,n x x ,它们是D 空间的点,目标是将它们变换为更低维的d 空间中的点1,...,n y y ,其中d D 。在这里假设1x ,...,x k M ∈,其中M 为嵌入l 空间中的一个流形。
算法为样本点构造加权图,图的节点是每一个样本点,边为每个节点与它的邻居节点之间的相似度,每个节点只和它的邻居有连接关系。算法的目标是投影之后保持在高维空间中的距离关系,假设投影后到低维空间后的坐标为y ,它通过最小化如下目标函数实现
211min i n n i j ij
i j w ==-∑∑y y y 此函数的含义是如果样本i x 和j x 的相似度很高即在高维空间中距离很近,则它们之间的边的权重ij w 很大,因此投影到低维空间中后两个点要离得很近,即i y 和j y 要很接近,否则会产生一大个的损失值。根据上面证明拉普拉斯矩阵半正定时的结论,求解该目标函数等价于下面的优化问题
()
T T min tr =Y Y LY Y DY I
其中[]12...d =Y y y y 为投影后的坐标按列构成的矩阵,这里加上了等式约束条件以消掉y 的冗余,选用矩阵D 来构造等式约束是因为其主对角线元素即节点的加权度反映了图的每个节点的重要性。通过拉格朗日乘数法可以证明,这个问题的最优解是如下广义值问题的解
λ=Lf Df
可以证明这个广义特征值问题的所有特征值非负。最优解为这个广义特征值问题除去0之外的最小的d 个广义特征值对应的特征向量,这些向量按照列构成矩阵Y 。下面给出拉
普拉斯特征映射算法的流程。
算法的第一步是构造图的节点的邻接关系。如果样本点i x 和样本点j x 的距离很近,则为图的节点i 和节点j 建立一条边。判断两个样本点是否解接近的方法有两种。第一种是计算二者的欧氏距离,如果距离小于某一值ε则认为两个样本很接近
2i j ε
- 第二步是计算边的权重,在这里也有两种选择。第一种方法为,如果节点i 和节点j 是联通的,则它们之间的边的权重为: 2exp i j ij w ??- ?=- ??? x x 否则0ij w =。其中t 是一个人工设定的大于0的实数。第二种方式是如果节点i 和节点j 是联通的则它们之间的边的权重为1,否则为0。 第三步是特征映射。假设构造的图是联通的,即任何两个节点之间都有路径可达,如果不联通,则算法分别作用于每个联通分量上。根据前面构造的图计算它的拉普拉斯矩阵,然后求解如下广义特征值和特征向量问题 λ=Lf Df 前面已经证明拉普拉斯矩阵半正定,根据它以及矩阵D 的定义,可以证明广义特征值非负。假设01,...,d -f f 是这个广义特征值问题的解,它们按照特征值的大小升序排列,即 01 0...d λλ-=≤≤去掉值为0的特征值0λ,剩下的前d 个特征值对应的特征向量即为投影结果 ()()() 1,...,i d i i →x f f 图7.5 是拉普拉斯特征映射对三维数据进行降维的一个例子 图7.5拉普拉斯特征映射对三维数据降维 上图中左侧为三维空间中的样本分布,右图为降维后的结果。这种变换起到的效果大致上相当于把三维空间中的曲面拉平之后铺到二维平面上,保持了样本在流形上的距离关系。 7.2.3局部保持投影 局部保持投影(Locality preserving projections ,简称LPP )[5]通过最好的保持一个数据集的邻居结构信息来构造投影映射,其思路和拉普拉斯特征映射类似,区别在于不是直接得到投影结果而是求解投影矩阵。 假设有样本集1,...,m x x ,它们是n 空间中的向量。这里的目标是寻找一个变换矩阵A ,将这些样本点映射到更低维的l 空间,得到向量1,...,m y y ,使得i y 能够代表i x ,其中l n : T i i =y A x 假设1,...,n M ∈x x ,其中M 是l 空间中的一个流形。目标函数与拉普拉斯特征映射相同,定义为22T T 1111 1122m m m m i j ij i j ij i j i j w w ====-=-∑∑∑∑y y A x A x 所有矩阵的定义与拉普拉斯特征映射相同。投影变换矩阵为[]12 ...d =A a a a 即 T =y A x 假设矩阵X 为所有样本按照列构成的矩阵。根据与拉普拉斯特征映射类似的推导,这等价于求解下面的问题 T T T T min 1 =a a XLX a a XDX a 通过拉格朗日乘数法可以证明,此问题的最优解是下面广义特征值问题的解 T T λ=XLX a XDX a 可以将这种做法推广到高维的情况。下面给出局部保持投影算法的流程。 算法的第一步是根据样本构造图,这和拉普拉斯特征映射的做法相同,包括确定两个顶点是否连通以及计算边的权重,在这里不再重复介绍。 第二步是特征映射,计算如下广义特征值问题 T T λ=XLX a XDX a 假设上面广义特征向量问题的解为1,...,d a a ,它们对应的特征值满足 1....l λλ<< 要寻找的降维变换矩阵为: [] T 12,..i i i l →==x y A x A a a a A 是一个n l ?的矩阵。对向量左乘矩阵T A 即可完成数据的降维。 7.2.4等距映射 等距映射(Isomap )[6]使用了微分几何中测地线的思想,它希望数据在向低维空间映射之后能够保持流形上的测地线距离。 测地线源自于大地测量学,是地球上任意两点之间在球面上的最短路径。在三维空间中两点之间的最短距离是它们之间线段的长度,但如果要沿着地球表面走,最短距离就是测地线的长度,因为我们不能从地球内部穿过去。这里的测地线就是球面上两点之间大圆上劣弧的长度。算法计算任意两个样本之间的测地距离,然后根据这个距离构造距离矩阵。最后通过距离矩阵求解优化问题完成数据的降维,降维之后的数据保留了原始数据点之间的距离信息。 在这里测地线距离通过图构造,是图的两个节点之间的最短距离。算法的第一步构造样本集的邻居图,这和前面介绍的两种方法相同。如果两个数据点之间的距离小于指定阈值或者其中一个节点在另外一个节点的邻居集合中,则两个节点是联通的。假设有N 个样本,则邻居图有N 个节点。邻居图的节点i 和j 之间边的权重为它们之间的距离ij w ,距离的计算公式可以有多种选择。 第二步计算图中任意两点之间的最短路径长度,可以通过经典的Dijkstra 算法实现。假设最短路径长度为(),G d i j ,由它构造如下矩阵: (){} ,G G d i j =D 其元素是所有节点对之间的最短路径长度。算法的第三步根据矩阵D G 构造d 维嵌入y ,这通过求解如下最优化问题实现: ()()2 11min ,N N G i j i j d i j ==--∑∑y y y 这个问题的解y 即为降维之后的向量。这个目标函数的意义是向量降维之后任意两点之间的距离要尽量的接近在原始空间中这两点之间的最短路径长度,因此可以认为降维尽量保留了数据点之间的测地距离信息。下图7.6为等距映射将手写数字图像投影到3维空间后的结果: 图7.6等距映射的投影结果 7.2.5随机近邻嵌入 随机近邻嵌入(stochastic neighbor embedding ,简称SNE )[10]基于如下思想:在高维空间中距离很近的点投影到低维空间中之后也要保持这种近邻关系,在这里距离通过概率体现。假设在高维空间中有两个点样本点i x 和j x ,j x 以j i p 的概率作为i x 的邻居,将样本之间的欧氏距离转化成概率值,借助于正态分布,此概率的计算公式为 ()() 22 22exp /2exp /2i j i j i i k i k i p σσ≠--=--∑x x x x 其中i σ表示以i x 为中心的正态分布的标准差,这个概率的计算公式类似于第11.4节将要介绍的softmax 回归。上式中除以分母的值是为了将所有值归一化成概率。由于不关心一个点与它自身的相似度,因此0j i p =。投影到低维空间之后仍然要保持这个概率关系。假设i x 和j x 投影之后对应的点为i y 和j y ,在低维空间中对应的近邻概率记为j i q ,计算公式与上面的相同,但标准差统一设为1/2()() 22exp exp i j j i i k k i q ≠--=--∑y y y y 上面定义的是点i x 与它的一个邻居点的概率关系,如果考虑所有其他点,这些概率值构成一个离散型概率分布i P ,是所有样本点成为i x 的邻居的概率。在低维空间中对应的概率分布为i Q ,投影的目标是这两个概率分布尽可能接近,因此需要衡量两个概率分布之间的相似度或距离。在机器学习中一般用KL (Kullback-Leibler )散度衡量两个概率分布之间的距离,在生成对抗网络、变分自动编码器中都有它的应用。假设x 为离散型随机变量,()p x 和()q x 是它的两个概率分布,KL 散度定义为 ()()()() log x p x KL p q p x q x =∑KL 散度不具有对称性,即一般情况下()() KL p q KL q p ≠。KL 散度是非负的,如果两个概率分布完全相同,有极小值0。对于连续型随机变量,则将求和换成定积分。 由此得到投影的目标为最小化如下函数()()111log l l l j i i i i j i i i j j i p L KL P Q p =====∑∑∑y 这里对所有样本点的KL 散度求和,l 为样本数。把概率的计算公式代入KL 散度,可以将目标函数写成所有i y 的函数。目标函数对i y 的梯度为 ()() 2i i j i j i j j i j i j L p q p q ?=--+-∑y y y 计算出梯度之后可用梯度下降法迭代,得到的最优i y 值即为i x 投影后的结果。 7.2.5t-分布随机近邻嵌入 虽然SNE 有较好的效果,但训练时难以优化,而且容易导致拥挤问题(crowding problem )。t 分布随机近邻嵌入(t-distributed Stochastic Neighbor Embedding ,简称t-SNE ) [11]是对SNE 的改进。t-SNE 采用了对称的概率计算公式,另外在低维空间中计算样本点之间的概率时使用t 分布代替了正态分布。 在SNE 中i j p 和j i p 是不相等的,因此概率值不对称。可以用两个样本点的联合概率替代它们之间的条件概率解决此问题。在高维空间中两个样本点的联合概率定义为 ()() 22 22exp /2exp /2i j ij k l k l p σσ≠--=--∑x x x x 显然这个定义是对称的,即ij ji p p =。同样的,低维空间中两个点的联合概率为 ()()2 2exp exp i j ij k l k i q ≠--=--∑y y y y 目标函数采用KL 散度,定义为()()KL 11 log l l ij i ij i j ij p L D P Q p q ====∑∑y 但这样定义联合概率会存在异常值问题。如果某一个样本i x 是异常点即离其他点很远,则所有的2i j -x x 都很大,因此与i x 有关的ij p 很小,从而导致低维空间中的i y 对目标函数影响很小。解决方法是重新定义高维空间中的联合概率,具体为 j i i j ij p p p += 这样能确保对所有的i x 有 12ij j p n >∑,因此每个样本点都对目标函数有显著的贡献。目标函数对i y 的梯度为()()4i ij ij i j j L p q ?=--∑y y y 这种方法称为对称SNE 。 对称SNE 虽然对SNE 做了改进,但还存在拥挤问题,各类样本降维后聚集在一起而缺乏区分度。解决方法是用t 分布替代高斯分布,计算低维空间中的概率值。相比于正态分布,t 分布更长尾。如果在低维空间中使用t 分布,则在高维空间中距离近的点,在低维空间中距离也要近;但在高维空间中距离远的点,在低维空间中距离要更远。因此可以有效的拉大各个类之间的距离。使用t 分布之后,低维空间中的概率计算公式为 ()() 1 21211i j ij k l k l q --≠+-=+-∑y y y y 目标函数同样采用KL 散度。目标函数对的i y 梯度为 ()()() 1241i ij ij i j i j j L p q -?=--+-∑y y y y y 同样的,求得梯度之后可以用梯度下降法进行迭代从而得到i y 的最优解。 7.3实验程序 下面通过实验程序介绍主成分分析的使用。程序基于sklearn ,使用iris 数据集。程序将4维的特征向量投影到2维平面,根据样本的标签值将样本点显示成不同的颜色。在创建和 训练PCA模型时需要指定降维后的维数,这里为2。程序代码如下 import matplotlib.pyplot as plt from sklearn import datasets from sklearn.decomposition import PCA import matplotlib %matplotlib inline #载入iris数据集 iris=datasets.load_iris() #特征向量为4维的 X=iris.data #标签值用于将样本显示成不同的颜色 y=iris.target target_names=iris.target_names #创建PCA对象,并计算投影矩阵,对X执行降维操作,得到降维后的结果X_r pca=PCA(n_components=2) X_r=pca.fit(X).transform(X) plt.figure() colors=['navy','turquoise','darkorange'] lw=2 #显示降维后的样本 for color,i,target_name in zip(colors,[0,1,2],target_names): plt.scatter(X_r[y==i,0],X_r[y==i,1],color=color,alpha=.8,lw=lw, label=target_name) plt.legend(loc='best',shadow=False,scatterpoints=1) plt.title('PCA of IRIS dataset') plt.show() 程序运行结果如下图7.7所示。 图7.7PCA对iris数据集的降维结果 除PCA之外,sklearn还支持本章介绍的其他降维算法。 7.4应用 主成分分析被大量的用于科学与工程数据分析中需要数据降维的地方,是一种通用性非常好的算法。在人脸识别早期它被直接用于人脸识别问题[7],将在下一章中详细介绍。流形学习在高维复杂数据集上得到了更好的表现,如人脸图像[9]和其他图像的分类问题。 参考文献 [1]Ian T.Jolliffe.Principal Component Analysis.Springer Verlag,New York,1986. [2]Sebastian Mika,Bernhard Scholkopf,Alexander J Smola,Klausrobert Muller,Matthias Scholz Gun.Kernel PCA and de-noising in feature spaces.neural information processing systems,1999. [3]Roweis,Sam T and Saul,Lawrence K.Nonlinear dimensionality reduction by locally linear embedding. Science,290(5500).2000:2323-2326. [4]Belkin,Mikhail and Niyogi,https://www.wendangku.net/doc/2d2982228.html,placian eigenmaps for dimensionality reduction and data representation.Neural computation.15(6).2003:1373-1396. [5]He Xiaofei and Niyogi,Partha.Locality preserving projections.NIPS.2003:234-241. [6]Tenenbaum,Joshua B and De Silva,Vin and Langford,John C.A global geometric framework for nonlinear dimensionality reduction.Science,290(5500).2000:2319-2323. [7]Matthew Turk,Alex Pentland.Eigenfaces for recognition.Journal of Cognitive Neuroscience,1991 [8]Scholkopf,B.,Smola,A.,Mulller,K.-P.Nonlinear component analysis as a kernel eigenvalue problem. Neural Computation,10(5),1299-1319,1998. [9]He,Xiaofei,et al.Face recognition using Laplacianfaces.Pattern Analysis and Machine Intelligence, IEEE Transactions on27.3(2005):328-340. [10]Geoffrey E Hinton,Sam T Roweis.Stochastic Neighbor Embedding.neural information processing systems,2002. [11]Maaten,Laurens van der,and Geoffrey Hinton.Visualizing data using t-SNE.Journal of machine learning research9.Nov(2008):2579-2605. ·博士论坛· 高维数据降维方法研究 余肖生,周 宁 (武汉大学信息资源研究中心,湖北武汉430072) 摘 要:本文介绍了MDS 、Isomap 等三种主要的高维数据降维方法,同时对这些降维方法的作用进 行了探讨。 关键词:高维数据;降维;MDS ;Isomap ;LLE 中图分类号:G354 文献标识码:A 文章编号:1007-7634(2007)08-1248-04 Research on Methods of Dimensionality Reduction in High -dimensional Data YU Xiao -s heng ,ZH OU Ning (Research Center for Information Resourc es of Wuhan University ,W uhan 430072,China ) A bstract :In the paper the authors introduce three ke y methods of dimensionality r eduction in high -dimen -sional dataset ,such as MDS ,Isomap .At the same time the authors discuss applications of those methods .Key words :high -dimensional data ;dimensionality reduction ;MDS ;Isomap ;LLE 收稿日期:2006-12-20 基金项目:国家自科基金资助项目(70473068) 作者简介:余肖生(1973-),男,湖北监利人,博士研究生,从事信息管理与电子商务研究;周 宁(1943-),男, 湖北钟祥人,教授,博士生导师,从事信息组织与检索、信息系统工程、电子商务与电子政务研究. 1 引 言 随着计算机技术、多媒体技术的发展,在实际应用中经常会碰到高维数据,如文档词频数据、交易数据及多媒体数据等。随着数据维数的升高,高维索引结构的性能迅速下降,在低维空间中,我们经常采用Lp 距离(当p =1时,Lp 距离称为Man -hattan 距离;当p =2时,Lp 距离称为Euclidean 距离)作为数据之间的相似性度量,在高维空间中很多情况下这种相似性的概念不复存在,这就给基于高维数据的知识挖掘带来了严峻的考验【1】 。而这些高维数据通常包含许多冗余,其本质维往往比原始的数据维要小得多,因此高维数据的处理问题可以归结为通过相关的降维方法减少一些不太相关的数据而降低它的维数,然后用低维数据的处理办法进行处理 【2-3】 。高维数据成功处理的关键在于降维方 法的选择,因此笔者拟先介绍三种主要降维方法, 接着讨论高维数据降维方法的一些应用。 2 高维数据的主要降维方法 高维数据的降维方法有多种,本文主要讨论有代表性的几种方法。 2.1 MDS (multidimensional scaling )方法 MDS 是数据分析技术的集合,不仅在这个空间上忠实地表达数据之间联系,而且还要降低数据集的维数,以便人们对数据集的观察。这种方法实质是一种加入矩阵转换的统计模式,它将多维信息 通过矩阵运算转换到低维空间中,并保持原始信息之间的相互关系 【4】 。 每个对象或事件在多维空间上都可以通过一个 点表示。在这个空间上点与点之间的距离和对象与对象之间的相似性密切相关。即两个相似的对象通过空间临近的两个点来表示,且两个不相似的对象 第25卷第8期2007年8月 情 报 科 学 Vol .25,No .8 August ,2007 计算机工程应用技术 本栏目责任编辑:梁 书 较大规模数据应用PCA 降维的一种方法 赵桂儒 (中国地震台网中心,北京100045) 摘要:PCA 是一种常用的线性降维方法,但在实际应用中,当数据规模比较大时无法将样本数据全部读入内存进行分析计 算。文章提出了一种针对较大规模数据应用PCA 进行降维的方法,该方法在不借助Hadoop 云计算平台的条件下解决了较大规模数据不能直接降维的问题,实际证明该方法具有很好的应用效果。关键词:主成分分析;降维;大数据中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2014)08-1835-03 A Method of Dimensionality Reduction for Large Scale Data Using PCA ZHAO Gui-ru (China Earthquake Networks Center,Beijing 100045,China) Abstract:PCA is a general method of linear dimensionality reduction.It is unable to read all the sample data into the memory to do analysis when the data scale becomes large.A method of dimensionality reduction for large scale data using PCA without Ha?doop is proposed in this paper.This method solves the problem that it can ’t do dimensionality reduction directly on large scale data.Practice proves that this method has a good application effect.Key words:PCA;dimensionality reduction;large scale data 现实生活中人们往往需要用多变量描述大量的复杂事物和现象,这些变量抽象出来就是高维数据。高维数据提供了有关客观现象极其丰富、详细的信息,但另一方面,数据维数的大幅度提高给随后的数据处理工作带来了前所未有的困难。因此数据降维在许多领域起着越来越重要的作用,通过数据降维可以减轻维数灾难和高维空间中其他不相关属性。所谓数据降维是指通过线性或非线性映射将样本从高维空间映射到低维空间,从而获得高维数据的一个有意义的低维表示的过程。 主成分分析(Principal Component Analysis ,PCA )是通过对原始变量的相关矩阵或协方差矩阵内部结构的研究,将多个变量转换为少数几个综合变量即主成分,从而达到降维目的的一种常用的线性降维方法。这些主成分能够反映原始变量的绝大部分信息,它们通常表示为原始变量的线性组合。在实际应用中当数据规模超过计算机内存容量(例如16G)时就无法将样本数据全部读入内存来分析原始变量的内部结构,这成为PCA 在实际应用中存在的一个问题。该文从描述PCA 变换的基本步骤出发,提出了一种不需要Hadoop 等云计算平台即可对较大规模数据进行降维的一种方法,实际证明该方法具有很好的应用效果。 1PCA 变换的基本步骤 PCA 是对数据进行分析的一种技术,主要用于数据降维,方法是利用投影矩阵将高维数据投影到较低维空间。PCA 降维的一般步骤是求取样本矩阵的协方差矩阵,计算协方差矩阵的特征值及其对应的特征向量,由选择出的特征向量构成这个投影矩阵。 ?è???????? ÷÷÷÷÷÷cov(x 1,x 1),cov(x 1,x 2),cov(x 1,x 3),?,cov(x 1,x N )cov(x 2,x 1),cov(x 2,x 2),cov(x 2,x 3),?,cov(x 2,x N ) ?cov(x N ,x 1),cov(x N ,x 2),cov(x N ,x 3),?,cov(x N ,x N )(1)假设X M ×N 是一个M ×N (M >N ),用PCA 对X M ×N 进行降维分析,其步骤为:1)将矩阵X M ×N 特征中心化,计算矩阵X M ×N 的样本的协方差矩阵C N ×N ,计算出的协方差矩阵如式(1)所示,式中x i 代表X M ×N 特征中心化后的第i 列; 2)计算协方差矩阵C N ×N 的特征向量e 1,e 2...e N 和对应的特征值λ1,λ2...λN ,将特征值按从大到小排序; 3)根据特征值大小计算协方差矩阵的贡献率及累计贡献率,计算公式为: θi =λi ∑n =1 N λn i =1,2,...,N (2) 收稿日期:2014-01-20基金项目:国家留学基金资助项目(201204190040)作者简介:赵桂儒(1983-),男,山东聊城人,工程师,硕士,迈阿密大学访问学者,主要研究方向为多媒体信息处理。 1835 高维数据的低维表示综述 一、研究背景 在科学研究中,我们经常要对数据进行处理。而这些数据通常都位于维数较高的空间,例如,当我们处理200个256*256的图片序列时,通常我们将图片拉成一个向量,这样,我们得到了65536*200的数据,如果直接对这些数据进行处理,会有以下问题:首先,会出现所谓的“位数灾难”问题,巨大的计算量将使我们无法忍受;其次,这些数据通常没有反映出数据的本质特征,如果直接对他们进行处理,不会得到理想的结果。所以,通常我们需要首先对数据进行降维,然后对降维后的数据进行处理。 降维的基本原理是把数据样本从高维输入空间通过线性或非线性映射投影到一个低维空间,从而找出隐藏在高维观测数据中有意义的低维结构。(8) 之所以能对高维数据进行降维,是因为数据的原始表示常常包含大量冗余: · 有些变量的变化比测量引入的噪声还要小,因此可以看作是无关的 · 有些变量和其他的变量有很强的相关性(例如是其他变量的线性组合或是其他函数依赖关系),可以找到一组新的不相关的变量。(3) 从几何的观点来看,降维可以看成是挖掘嵌入在高维数据中的低维线性或非线性流形。这种嵌入保留了原始数据的几何特性,即在高维空间中靠近的点在嵌入空间中也相互靠近。(12) 数据降维是以牺牲一部分信息为代价的,把高维数据通过投影映射到低维空间中,势必会造成一些原始信息的损失。所以在对高维数据实施降维的过程中如何在最优的保持原始数据的本质的前提下,实现高维数据的低维表示,是研究的重点。(8) 二、降维问题 1.定义 定义1.1降维问题的模型为(,)X F ,其中D 维数据空间集合{}1N l l X x ==(一般为D R 的一个子集),映射F :F X Y →(),x y F x →= URL:https://www.wendangku.net/doc/2d2982228.html,/14072.html 特征选择(排序)对于数据科学家、机器学习从业者来说非常重要。好的特征选择能够提升模型的性能,更能帮助我们理解数据的特点、底层结构,这对进一步改善模型、算法都有着重要作用。 特征选择主要有两个功能: 1.减少特征数量、降维,使模型泛化能力更强,减少过拟合 2.增强对特征和特征值之间的理解 拿到数据集,一个特征选择方法,往往很难同时完成这两个目的。通常情况下,选择一种自己最熟悉或者最方便的特征选择方法(往往目的是降维,而忽略了对特征和数据理解的目的)。 在许多机器学习的书里,很难找到关于特征选择的容,因为特征选择要解决的问题往往被视为机器学习的一种副作用,一般不会单独拿出来讨论。本文将介绍几种常用的特征选择方法,它们各自的优缺点和问题。 1 去掉取值变化小的特征Removing features with low variance 这应该是最简单的特征选择方法了:假设某种特征的特征值只有0和1,并且在所有输入样本中,95%的实例的该特征取值都是1,那就可以认为这个特征作用不大。如果100%都是1,那这个特征就没意义了。当特征值都是离散型变量的时候这种方法才能用,如果是连续型变量,就需要将连续变量离散化之后才能用,而且实际当中,一般不太会有95%以上都取某个值的特征存在,所以这种方法虽然简单但是不太好用。可以把它作为特征选择的预处理,先去掉那些取值变化小的特征,然后再从接下来提到的特征选择方法中选择合适的进行进一步的特征选择。 2 单变量特征选择Univariate feature selection 单变量特征选择能够对每一个特征进行测试,衡量该特征和响应变量之间的关系,根据得分扔掉不好的特征。对于回归和分类问题可以采用卡方检验等方式对特征进行测试。 这种方法比较简单,易于运行,易于理解,通常对于理解数据有较好的效果(但对特征优化、提高泛化能力来说不一定有效);这种方法有许多改进的版本、变种。 2.1 Pearson相关系数Pearson Correlation 皮尔森相关系数是一种最简单的,能帮助理解特征和响应变量之间关系的方法,该方法衡量的是变量之间的线性相关性,结果的取值区间为[-1,1],-1表示完全的负相关(这个变量下降,那个就会上升),+1表示完全的正相关,0表示没有线性相关。 Pearson Correlation速度快、易于计算,经常在拿到数据(经过清洗和特征提取之后的)之后第一时间就执行。 Pearson相关系数的一个明显缺陷是,作为特征排序机制,他只对线性关系敏感。如果关系是非线性的,即便两个变量具有一一对应的关系, Pearson相关性也可能会接近0。 2.2 互信息和最大信息系数Mutual information and maximal information coefficient (MIC) 收稿日期:2008211226;修回日期:2009201224 基金项目:国家自然科学基金资助项目(60372071);中国科学院自动化研究所复杂系统与智能科学重点实验室开放课题基金资助项目(20070101);辽宁省教育厅高等学校科学研究基金资助项目(2004C031) 作者简介:吴晓婷(19852),女(蒙古族),内蒙古呼伦贝尔人,硕士研究生,主要研究方向为数据降维、模式识别等(xiaoting wu85@hot m ail . com );闫德勤(19622),男,博士,主要研究方向为模式识别、数字水印和数据挖掘等. 数据降维方法分析与研究 3 吴晓婷,闫德勤 (辽宁师范大学计算机与信息技术学院,辽宁大连116081) 摘 要:全面总结现有的数据降维方法,对具有代表性的降维方法进行了系统分类,详细地阐述了典型的降维方法,并从算法的时间复杂度和优缺点两方面对这些算法进行了深入的分析和比较。最后提出了数据降维中仍待解决的问题。 关键词:数据降维;主成分分析;局部线性嵌入;等度规映射;计算复杂度 中图分类号:TP301 文献标志码:A 文章编号:100123695(2009)0822832204 doi:10.3969/j .jssn .100123695.2009.08.008 Analysis and research on method of data dimensi onality reducti on WU Xiao 2ting,Y AN De 2qin (School of Co m puter &Infor m ation Technology,L iaoning N or m al U niversity,D alian L iaoning 116081,China ) Abstract:This paper gave a comp rehensive su mmarizati on of existing di m ensi onality reducti on methods,as well as made a classificati on t o the rep resentative methods systematically and described s ome typ ical methods in detail.Further more,it deep ly analyzed and compared these methods by their computati onal comp lexity and their advantages and disadvantages .Finally,it p r oposed the crucial p r oble m s which needed t o be res olved in future work in data di m ensi onality reducti on . Key words:data di m ensi onality reducti on;p rinci pal component analysis (PCA );l ocally linear e mbedding (LLE );is ometric mapp ing;computati onal comp lexity 近年来,数据降维在许多领域起着越来越重要的作用。通过数据降维可以减轻维数灾难和高维空间中其他不相关属性,从而促进高维数据的分类、可视化及压缩。所谓数据降维是指通过线性或非线性映射将样本从高维空间映射到低维空间,从而获得高维数据的一个有意义的低维表示的过程。数据降维的数学描述如下:a )X ={x i }N i =1是D 维空间中的一个样本集, Y ={y i }N i =1是d (d < 在大数据时代,数据挖掘是最关键的工作。大数据的挖掘是从海量、不完全的、有噪声的、模糊的、随机的大型数据库中发现隐含在其中有价值的、潜在有用的信息和知识的过程,也是一种决策支持过程。其主要基于人工智能,机器学习,模式学习,统计学等。通过对大数据高度自动化地分析,做出归纳性的推理,从中挖掘出潜在的模式,可以帮助企业、商家、用户调整市场政策、减少风险、理性面对市场,并做出正确的决策。目前,在很多领域尤其是在商业领域如银行、电信、电商等,数据挖掘可以解决很多问题,包括市场营销策略制定、背景分析、企业管理危机等。大数据的挖掘常用的方法有分类、回归分析、聚类、关联规则、神经网络方法、Web 数据挖掘等。这些方法从不同的角度对数据进行挖掘。 1.分类 分类是找出数据库中的一组数据对象的共同特点并按照分类模式将其划分为不同的类,其目的是通过分类模型,将数据库中的数据项映射到摸个给定的类别中。可以应用到涉及到应用分类、趋势预测中,如淘宝商铺将用户在一段时间内的购买情况划分成不同的类,根据情况向用户推荐关联类的商品,从而增加商铺的销售量。 它可以应用到客户的分类、客户的属性和特征分析、客户满意度分析、客户的购买趋势预测等,如一个汽车零售商将客户按照对汽车的喜好划分成不同的类,这样营销人员就可以将新型汽车的广告手册直接邮寄到有这种喜好的客户手中,从而大大增加了商业机会。 分类的方法有:决策树、贝叶斯、人工神经网络。 1.1决策树 决策树是用于分类和预测的主要技术之一,决策树学习是以实例为基础的归纳学习算法,它着眼于从一组无次序、无规则的实例中推理出以决策树表示的分类规则。构造决策树的目的是找出属性和类别间的关系,用它来预测将来未知类别的记录的类别。它采用自顶向下的递归方式,在决策树的内部节点进行属性的比较,并根据不同属性值判断从该节点向下的分支,在决策树的叶节点得到结论。 1.2贝叶斯 贝叶斯(Bayes)分类算法是一类利用概率统计知识进行分类的算法,如朴素贝叶斯 重金属多组分分析的研究现状 近年来,随着科技的进步,单组分重金属的检测技术已经非常成熟,但是在实际污染体系中重金属离子种类繁多,且它们之间往往存在相互干扰,传统的化学分析方法和化学分析仪器难以一次性精确的检测出各个重金属离子的浓度,需要对共存组分进行同时测定。 对共存组分进行同时测定,传统的化学分析方法是首先通过加入各种掩蔽剂进行组分的预分离,然后采用单组分重金属检测技术进行分析检测。这种方法的分离过程往往冗长繁琐,实验条件苛刻,费时费力,而且检测精度低,无法应用于污染现场的检测。 随着计算机科学技术、光谱学和化学信息学的发展,复杂体系的多组分分析已成为当今光谱技术的研究热点,应用范围涉及环境监测、石油化工、高分子化工、食品工业和制药工业等领域,而且需求日益显著。由于多重金属离子共存时会产生重金属离子间的相互作用,因此在用化学分析仪器检测时会产生相干数据干扰,对实验结果产生影响,为了使测试结果更加准确,需要在实验的基础上建立数学模型,用于数据处理,消除各重金属离子共存时产生的相干数据干扰。近年来,引入化学计量学手段,用“数学分离”部分代替复杂的“化学分离”,从而达到重金属离子的快速、简便分析测定[1]。 化学计量学是一门通过统计学或数学方法将对化学体系的测量值与体系的状态之间建立联系的学科,它应用数学、统计学和其他方法和手段(包括计算机)选择最优试验设计和测量方法,并通过对测量数据的处理和解析,最大限度地获取有关物质系统的成分、结构及其他相关信息。目前,已有许多化学计量学方法从不同程度和不同方面解决了分析化学中多组分同时测定的问题,如偏最小二乘法(PLS)、主成分回归法(PCR)、Kalman滤波法、多元线性回归(MLR)等,这些方法减少了分离的麻烦,并使试验更加科学合理。 (1) 光谱预处理技术 这些方法用来降噪、消除无关信息。 ①主成分分析法 在处理多元样本数据时,假设总体为X=(x1,x1,x3…xn),其中每个xi (i=1,2,3,…n)为要考察的数量指标,在实践中常常遇到的情况是这n个指标之间存在着相关关系。如果能从这n个指标中构造出k个互不相关的所谓综合指标(k 大数据降维的经典方法 近来由于数据记录和属性规模的急剧增长,大数据处理平台和并行数据分析算法也随之出现。 近来由于数据记录和属性规模的急剧增长,大数据处理平台和并行数据分析算法也随之出现。于此同时,这也推动了数据降维处理的应用。实际上,数据量有时过犹不及。有时在数据分析应用中大量的数据反而会产生更坏的性能。 最新的一个例子是采用2009 KDD Challenge 大数据集来预测客户流失量。该数据集维度达到15000 维。大多数数据挖掘算法都直接对数据逐列处理,在数据数目一大时,导致算法越来越慢。该项目的最重要的就是在减少数据列数的同时保证丢失的数据信息尽可能少。 以该项目为例,我们开始来探讨在当前数据分析领域中最为数据分析人员称道和接受的数据降维方法。 缺失值比率(Missing Values Ratio) 该方法的是基于包含太多缺失值的数据列包含有用信息的可能性较少。因此,可以将数据列缺失值大于某个阈值的列去掉。阈值越高,降维方法更为积极,即降维越少。该方法示意图如下: 低方差滤波(Low Variance Filter) 与上个方法相似,该方法假设数据列变化非常小的列包含的信息量少。因此,所有的数据列方差小的列被移除。需要注意的一点是:方差与数据范围相关的,因此在采用该方法前需要对数据做归一化处理。算法示意图如下: 高相关滤波(High Correlation Filter) 高相关滤波认为当两列数据变化趋势相似时,它们包含的信息也显示。这样,使 用相似列中的一列就可以满足机器学习模型。对于数值列之间的相似性通过计算相关系数来表示,对于名词类列的相关系数可以通过计算皮尔逊卡方值来表示。相关系数大于某个阈值的两列只保留一列。同样要注意的是:相关系数对范围敏感,所以在计算之前也需要对数据进行归一化处理。算法示意图如下: 随机森林/组合树(Random Forests) 组合决策树通常又被成为随机森林,它在进行特征选择与构建有效的分类器时非常有用。一种常用的降维方法是对目标属性产生许多巨大的树,然后根据对每个属性的统计结果找到信息量最大的特征子集。例如,我们能够对一个非常巨大的数据集生成非常层次非常浅的树,每颗树只训练一小部分属性。如果一个属性经常成为最佳分裂属性,那么它很有可能是需要保留的信息特征。对随机森林数据属性的统计评分会向我们揭示与其它属性相比,哪个属性才是预测能力最好的属性。算法示意图如下: 主成分分析(PCA) 主成分分析是一个统计过程,该过程通过正交变换将原始的n 维数据集变换到一个新的被称做主成分的数据集中。变换后的结果中,第一个主成分具有最大的方差值,每个后续的成分在与前述主成分正交条件限制下与具有最大方差。降维时仅保存前m(m < n) 个主成分即可保持最大的数据信息量。需要注意的是主成分变换对正交向量的尺度敏感。数据在变换前需要进行归一化处理。同样也需要注意的是,新的主成分并不是由实际系统产生的,因此在进行PCA 变换后会丧失数据的解释性。如果说,数据的解释能力对你的分析来说很重要,那么PCA 对你来说可能就不适用了。算法示意图如下: 反向特征消除(Backward Feature Elimination) 高维面板数据降维与变量选择方法研究 张波方国斌 2012-12-14 14:35:56 来源:《统计与信息论坛》(西安)2012年6期第21~28页内容提要:从介绍高维面板数据的一般特征入手,在总结高维面板数据在实际应用中所表现出的各种不同类型及其研究理论与方法的同时,主要介绍高维面板数据因子模型和混合效应模型;对混合效应模型随机效应和边际效应中的高维协方差矩阵以及经济数据中出现的多指标大维数据的研究进展进行述评;针对高维面板数据未来的发展方向、理论与应用中尚待解决的一些关键问题进行分析与展望。 关键词:高维面板数据降维变量选择 作者简介:张波,中国人民大学统计学院(北京100872);方国斌,中国人民大学统计学院,安徽财经大学统计与应用数学学院(安徽蚌埠233030)。 一、引言 在社会现象观测和科学实验过程中经常会产生面板数据。这类数据通过对多个个体在不同时间点上进行重复测度,得到每个个体在不同样本点上的多重观测值,形成时间序列和横截面相结合的数据,也就是所谓的“面板数据”。由于应用背景的不同,面板数据有时也称作纵向数据(longitudinal data)。面板数据广泛产生于经济学、管理学、生物学、心理学、健康科学等诸多领域。 随着信息技术的高速发展,数据采集、存储和处理能力不断提高,所谓的高维数据分析问题不断涌现。对于多元统计分析而言,高维问题一般指如下两种情形:一种是变量个数p较大而样本量n相对较小,例如药物试验中有成千上万个观测指标而可用于实验观测的病人个数较少;另一种是变量个数户不大但是样本个数n较多,例如一项全国调查牵涉到大量的调查对象,而观测指标个数相对较少。面板数据高维问题较多元(时序)高维问题更为复杂,因为面板数据至少包括两个维度:时间和横截面。在实际应用中,不同个体在不同时间进行观测时可以获得多个指标值。为了以下论述的方便,用p表示指标个数,T表示观测期长度,N表示个体(individual)或主题(subject)个数。数理统计中所提到的高维(大维)问题,通常是指个体数N、时期长度T或指标个数p这三个变量中的一个或多个可以趋向于无穷。具体应用中,只要N、T和p中有一个或多个大于某个给定的临界值,都称为高维问题。 本文主要研究两种基本类型的高维面板问题:一类为面板数据分析中解释变量个数p非常多,超过个体数N和时期数T,比如零售商业网点成千上万种商品扫描数据,央行和国家统计部门得到的多个指标在不同个体宏观经济观测数据等;另一类是混合效应模型中随机效应和固定效应设定时方差协方差矩阵所需确定的参数个数较多,某些参数的值趋向于零,要对方差协方差矩阵进行变量选择,此时针对固定效应和随机效应可以采用不同的变量选择策略。 二、高维面板数据因子模型 大型数据集构成的社会经济面板的特点是具有成百上千个观测指标,也就是具有所谓的高维特征。由于这种特征的存在,采用经典统计计量分析方法很难进行处理。因子模型(factor model)不仅可以有效降低数据的维度,而且可以充 (一)数据降维——主成分分析(PCA) 本文主要目的是了解PCA的计算流程以及MATLAB自带的PCA函数参数说明,从数据的计算过程了解PCA的结果。借鉴其他人工作,在此做一些总结,希望对他人有所帮助。 PCA思想:利用降维的思想,把多个特征转化为少数的几个综合特征,其中每个成分都是原始变量的线性组合,且各成分之间互不相关,从而这些成分能够反映原始变量的绝大部分信息,且所含信息互不重叠。 PCA过程:1矩阵标准化。2.计算标准化的矩阵协方差;3计算协方差矩阵的特征值和特征向量,并按照特征值从大到小排序;4.根据要求(这一步计算贡献率)选取降多少维,计算标准化矩阵*特征向量的个数,即为所要将的维数。(即我们最终所要的数据)1)验证:MATLAB(pca函数),数据hald load hald [coeff,score,latent,tsquared,explained,mu] = pca(ingredients); coeff为主成分系数,也是特征向量的按照特征值从大到小排序。 Score为主成分分数,为标准化的数据*coeff Latent为主成分方差,即为从大到小排列的特征值。 Tsquared为H otelling’s T-Squared Statistic,标准化的score的平方和(每一行) Explained每个主成分的贡献率,我们可以看出前两个加在一起,一共97%多,即前两个成分都能表示数据的大部分信息。 Mu:X的每一列的均值。 以上是MATLAB自带的函数。接下来进行验证。 数据ingredient中心化 计算得分: 我们发现score=F,表明能反推到原始数据(注意此结果不是唯一,接下来会表明);至此,那么什么数据是我们想要的呢?我们知道我们要前两个主成分。最终的结果是score的前两列就可以了(这才是我们进行PCA主要的目的)。 2)我们重新编写程序,看看有何差异 1.数据中心化,我们得到X; 2.计算协方差; 3.计算协方差的特征值和特征向量并对特征值从大到小排序 数据分析中常用的降维方法有哪些 对大数据分析感兴趣的小伙伴们是否了解数据分析中常用的降维方法都有哪些呢?本篇文章小编和大家分享一下数据分析领域中最为人称道的七种降维方法,对大数据开发技术感兴趣的小伙伴或者是想要参加大数据培训进入大数据领域的小伙伴就随小编一起来看一下吧。 近来由于数据记录和属性规模的急剧增长,大数据处理平台和并行数据分析算法也随之出现。于此同时,这也推动了数据降维处理的应用。实际上,数据量有时过犹不及。有时在数据分析应用中大量的数据反而会产生更坏的性能。 我们今天以2009 KDD Challenge 大数据集来预测客户流失量为例来探讨一下,大多数数据挖掘算法都直接对数据逐列处理,在数据数目一大时,导致算法越来越慢。因此,下面我们一下来了解一下数据分析中常用的降维方法。 缺失值比率(Missing Values Ratio) 该方法的是基于包含太多缺失值的数据列包含有用信息的可能性较少。因此,可以将数据列缺失值大于某个阈值的列去掉。阈值越高,降维方法更为积极,即降维越少。 低方差滤波(Low Variance Filter) 与上个方法相似,该方法假设数据列变化非常小的列包含的信息量少。因此,所有的数据列方差小的列被移除。需要注意的一点是:方差与数据范围相关的,因此在采用该方法前需要对数据做归一化处理。 高相关滤波(High Correlation Filter) 高相关滤波认为当两列数据变化趋势相似时,它们包含的信息也显示。这样,使用相似列中的一列就可以满足机器学习模型。对于数值列之间的相似性通过计算相关系数来表示,对于名词类列的相关系数可以通过计算皮尔逊卡方值来表示。相关系数大于某个阈值的两列只保留一列。同样要注意的是:相关系数对范围敏感,所以在计算之前也需要对数据进行归一化处理。 随机森林/组合树(Random Forests) 组合决策树通常又被成为随机森林,它在进行特征选择与构建有效的分类器时非常有用。一种常用的降维方法是对目标属性产生许多巨大的树,然后根据对每个属性的统计结果找到信息量最大的特征子集。例如,我们能够对一个非常巨大的数据集生成非常层次非常浅的树,每颗树只训练一小部分属性。如果一个属 如何进行数据降维 —主成分分析与因子分析的比较 当我们使用统计分析方法进行多变量分析的时候,变量个数太多就会增加分析的复杂性。遇到这种情况,我们一般需要采取降维的方法对变量进行降维,以期更好来进行后续的分析工作。因子分析和主成分分析就是我们常用的两种变量降维的方法。但哪种方法更好呢?本文将对这两种方法来进行比较,希望大家能从相互的比较过程中,找到适合自己分析的降维方法。 首先,先来给大家简单的介绍下这两种方法的原理。 一般而言,针对某一个响应的若干因子之间存在着一定的相关性,因子分析就是在这些变量中找出隐藏的具有代表性的因子,将相同本质的变量归入一个因子,以此来减少变量的数目。 而对于主成分来说,这种相关性意味着这些变量之间存在着一定的信息重叠,主成分分析将重复的因子(相关性强的因子)删去,通过建立尽可能保持原有信息、彼此不相关的新因子来对响应进行重新的刻画。 从统计学上来看,主成分分析本质上是一种通过线性变换来进行数据集简化的技术,它是将数据从现有的坐标系统变换到一个新的坐标系统中,然后将数据投影的第一大方差在第一个坐标(称为第一主成分)上,第二大方差在第二个坐标(第二主成分)上,依次类推。 相比较主成分分析,因子分析不是对原始变量的重新组合,而是对原始变量进行分解,分解为公共因子与特殊因子两部分,然后通过构造因子模型,将原始观察变量分解为公共因子因子的线性组合。简而言之,主成分分析是将主要成分表示为原始观察变量的线性组合,而因子分析是将原始观察变量表示为新因子的线性组合。 基于两个方法的原理及实施步骤,我们不难看出,由于因子分析可以使用旋转技术帮助解释因子,在解释方面更加有优势。大致说来,当需要寻找潜在的因子,并对这些因子进行解释的时候,更加倾向于使用因子分析,并且借助旋转技术帮助更好解释。而如果想把现有的变量变成少数几个新的变量(新的变量几乎带有原来所有变量的信息)来进入后续的分析,则可以使用主成分分析。 此外,主成分分析主要是作为一种探索性的技术,可以同聚类分析和判别分析一起使用,帮助我们更好的进行多元分析,特别是当变量很多,数据样本量少的情况,一些统计分析方 数据降维 随着信息获取与处理技术的飞速发展,人们获取信息和数据的能力越来越强,高维数据频繁地出现于科学研究以及产业界等相关领域。为了对客观事物进行细致的描述,人们往往需要利用到这些高维数据,如在图像处理中,数据通常为m*n大小的图像,若将单幅图像看成图像空间中的一个点,则该点的维数为m*n 维,其对应的维数是相当高的,在如此高维的空间中做数据处理无疑会给人们带来很大的困难,同时所取得的效果也是极其有限的;再如网页检索领域一个中等程度的文档集表示文档的特征词向量通常高达几万维甚至几十万维;而在遗传学中所采集的每个基因片段往往是成千上万维的。另外,若直接处理高维数据,会遇到所谓的“维数灾难”(Curse of dimensionality)问题:即在缺乏简化数据的前提下,要在给定的精度下准确地对某些变量的函数进行估计,我们所需要的样本数量会随着样本维数的增加而呈指数形式增长[1]。因此,人们通常会对原始数据进行“数据降维”。 数据降维是指通过线性或者非线性映射将高维空间中的原始数据投影到低维空间,且这种低维表示是对原始数据紧致而有意义的表示,通过寻求低维表示,能够尽可能地发现隐藏在高维数据后的规律[2]。对高维数据进行降维处理的优势体现在如下几个方面:1)对原始数据进行有效压缩以节省存储空间;2)可以消除原始数据中存在的噪声;3)便于提取特征以完成分类或者识别任务;4)将原始数据投影到2维或3维空间,实现数据可视化。主流的数据降维算法主要有七种,其名称和对比如图1所示,接下来会进行详细地介绍其中的五种:线性的PCA、MDS、LDA以及非线性的Isomap、LLE。 图1 七种不同降维算法及其对比 1.PCA(Principal Component Analysis, 主成成分分析法) 什么是高维数据_高维数据如何定义 高维数据的概念其实不难,简单的说就是多维数据的意思。平时我们经常接触的是一维数据或者可以写成表形式的二维数据,高维数据也可以类推,不过维数较高的时候,直观表示很难。 目前高维数据挖掘是研究重点, 这是它的特点:高维数据挖掘是基于高维度的一种数据挖掘,它和传统的数据挖掘最主要的区别在于它的高维度。目前高维数据挖掘已成为数据挖掘的重点和难点。随着技术的进步使得数据收集变得越来越容易,导致数据库规模越来越大、复杂性越来越高,如各种类型的贸易交易数据、Web 文档、基因表达数据、文档词频数据、用户评分数据、WEB使用数据及多媒体数据等,它们的维度(属性)通常可以达到成百上千维,甚至更高。 由于高维数据存在的普遍性,使得对高维数据挖掘的研究有着非常重要的意义。但由于“维灾”的影响,也使得高维数据挖掘变得异常地困难,必须采用一些特殊的手段进行处理。随着数据维数的升高,高维索引结构的性能迅速下降,在低维空间中,我们经常采用欧式距离作为数据之间的相似性度量,但在高维空间中很多情况下这种相似性的概念不复存在,这就给高维数据挖掘带来了很严峻的考验,一方面引起基于索引结构的数据挖掘算法的性能下降,另一方面很多基于全空间距离函数的挖掘方法也会失效。解决的方法可以有以下几种:可以通过降维将数据从高维降到低维,然后用低维数据的处理办法进行处理;对算法效率下降问题可以通过设计更为有效的索引结构、采用增量算法及并行算法等来提高算法的性能;对失效的问题通过重新定义使其获得新生。 高维数据挖掘是基于高维度的一种数据挖掘,它和传统的数据挖掘最主要的区别在于它的高维度。目前高维数据挖掘已成为数据挖掘的重点和难点。随着技术的进步使得数据收集变得越来越容易,导致数据库规模越来越大、复杂性越来越高,如各种类型的贸易交易数据、Web 文档、基因表达数据、文档词频数据、用户评分数据、WEB使用数据及多媒体数据等,它们的维度(属性)通常可以达到成百上千维,甚至更高。 由于高维数据存在的普遍性,使得对高维数据挖掘的研究有着非常重要的意义。但由于“维 权重确定方法综述 引言 多指标综合评价是指人们根据不同的评价目的,选择相应的评价形式据此选择多个因素或指标,并通过一定的评价方法将多个评价因素或指标转化为能反映评价对象总体特征的信息,其中评价指标与权重系数确定将直接影响综合评价的结果。评价指标权重的确定是多目标决策的一个重要环节,因为多目标决策的基本思想是将多目标决策结果值纯量化,也就是应用一定的方法、技术、规则(常用的有加法规则、距离规则等)将各目标的实际价值或效用值转换为一个综合值;或按一定的方法、技术将多目标决策问题转化为单目标决策问题。指标权重是指标在评价过程中不同重要程度的反映,是决策(或评估)问题中指标相对重要程度的一种主观评价和客观反映的综合度量。按照权数产生方法的不同多指标综合评价方法可分为主观赋权评价法和客观赋权评价法两大类,其中主观赋权评价法采取定性的方法由专家根据经验进行主观判断而得到权数,然后再对指标进行综合评价,如层次分析法、综合评分法、模糊评价法、指数加权法和功效系数法等。客观赋权评价法则根据指标之间的相关关系或各项指标的变异系数来确定权数进行综合评价,如熵值法、神经网络分析法、TOPSIS法、灰色关联分析法、主成分分析法、变异系数法等。权重的赋值合理与否,对评价结果的科学合理性起着至关重要的作用;若某一因素的权重发生变化,将会影响整个评判结果。因此,权重的赋值必须做到科学和客观,这就要求寻求合适的权重确定方法。下面就对当前应用较多的评价方法进行阐述。 一、变异系数法 变异系数法是直接利用各项指标所包含的信息,通过计算得到指标的权重。是一种客观赋权的方法。此方法的基本做法是:在评价指标体系中,指标取值差异越大的指标,也就是越难以实现的指标,这样的指标更能反映被评价单位的差 URL:https://www.wendangku.net/doc/2d2982228.html,/14072.html 特征选择(排序)对于数据科学家、机器学习从业者来说非常重要。好的特征选择能够提升模型的性能,更能帮助我们理解数据的特点、底层结构,这对进一步改善模型、算法都有着重要作用。 特征选择主要有两个功能: 1.减少特征数量、降维,使模型泛化能力更强,减少过拟合 2.增强对特征和特征值之间的理解 拿到数据集,一个特征选择方法,往往很难同时完成这两个目的。通常情况下,选择一种自己最熟悉或者最方便的特征选择方法(往往目的是降维,而忽略了对特征和数据理解的目的)。 在许多机器学习的书里,很难找到关于特征选择的内容,因为特征选择要解决的问题往往被视为机器学习的一种副作用,一般不会单独拿出来讨论。本文将介绍几种常用的特征选择方法,它们各自的优缺点和问题。 1 去掉取值变化小的特征 Removing features with low variance 这应该是最简单的特征选择方法了:假设某种特征的特征值只有0和1,并且在所有输入样本中,95%的实例的该特征取值都是1,那就可以认为这个特征作用不大。如果100%都是1,那这个特征就没意义了。当特征值都是离散型变量的时候这种方法才能用,如果是连续型变量,就需要将连续变量离散化之后才能用,而且实际当中,一般不太会有95%以上都取某个值的特征存在,所以这种方法虽然简单但是不太好用。可以把它作为特征选择的预处理,先去掉那些取值变化小的特征,然后再从接下来提到的特征选择方法中选择合适的进行进一步的特征选择。 2 单变量特征选择 Univariate feature selection高维数据降维方法研究
较大规模数据应用PCA降维的一种方法
高维数据的低维表示综述
常见的特征选择或特征降维方法
数据降维方法分析与研究_吴晓婷
数据挖掘经典方法
多组分分析方法综述
大数据降维的经典方法
高维面板数据降维与变量选择方法研究
数据降维PCAmatlab
数据分析中常用的降维方法有哪些
如何进行数据降维—主成分分析与因子分析的比较
数据降维
什么是高维数据_高维数据如何定义
权重确定方法综述
常见的特征选择或特征降维方法