神经网络介绍

神经网络简介
神经网络简介:
人工神经网络是以工程技术手段来模拟人脑神经元网络的结构和特征的系统。利用人工神经网络可以构成各种不同拓扑结构的神经网络,他是生物神经网络的一种模拟和近似。神经网络的主要连接形式主要有前馈型和反馈型神经网络。常用的前馈型有感知器神经网络、BP 神经网络,常用的反馈型有Hopfield 网络。这里介绍BP (Back Propagation )神经网络,即误差反向传播算法。 原理:
BP (Back Propagation )网络是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一。BP 神经网络模型拓扑结构包括输入层(input )、隐层(hide layer)和输出层(output layer),其中隐层可以是一层也可以是多层。
图:三层神经网络结构图(一个隐层)
任何从输入到输出的连续映射函数都可以用一个三层的非线性网络实现 BP 算法由数据流的前向计算(正向传播)和误差信号的反向传播两个过程构成。正向传播时,传播方向为输入层→隐层→输出层,每层神经元的状态只影响下一层神经元。若在输出层得不到期望的输出,则转向误差信号的反向传播流程。通过这两个过程的交替进行,在权向量空间执行误差函数梯度下降策略,动态迭代搜索一组权向量,使网络误差函数达到最小值,从而完成信息提取和记忆过程。
单个神经元的计算:
设12,...ni x x x 分别代表来自神经元1,2...ni 的输入;
12,...i i ini w w w 则分别表示神经
元1,2...ni 与下一层第j 个神经元的连接强度,即权值;j b 为阈值;()f ?为传递函数;j y 为第j 个神经元的输出。若记001,j j x w b ==,于是节点j 的净输入j S 可表示为:0*ni
j ij i i S w x ==∑;净输入j S 通过激活函数()f ?后,便得到第j 个神经元的
输出:0
()(*),ni
j j ij i i y f S f w x ===∑
激活函数:
激活函数()f ?是单调上升可微函数,除输出层激活函数外,其他层激活函数必须是有界函数,必有一最大值。 BP 网络常用的激活函数有多种。 Log-sigmoid 型:1
(),,0()11x
f x x f x e
α-=
-∞<<+∞<<+,'()()(1())f x f x f x α=- tan-sigmod 型:2()1,,1()11x f x x f x e α-=--∞<<+∞-<<+,2(1())
'()2
f x f x α-=
线性激活函数purelin 函数:y x =,输入与输出值可取任意值。
BP 网络通常有一个或多个隐层,该层中的神经元均采用sigmoid 型传递函数,输出层的神经元可以采用线性传递函数,也可用S 形函数。
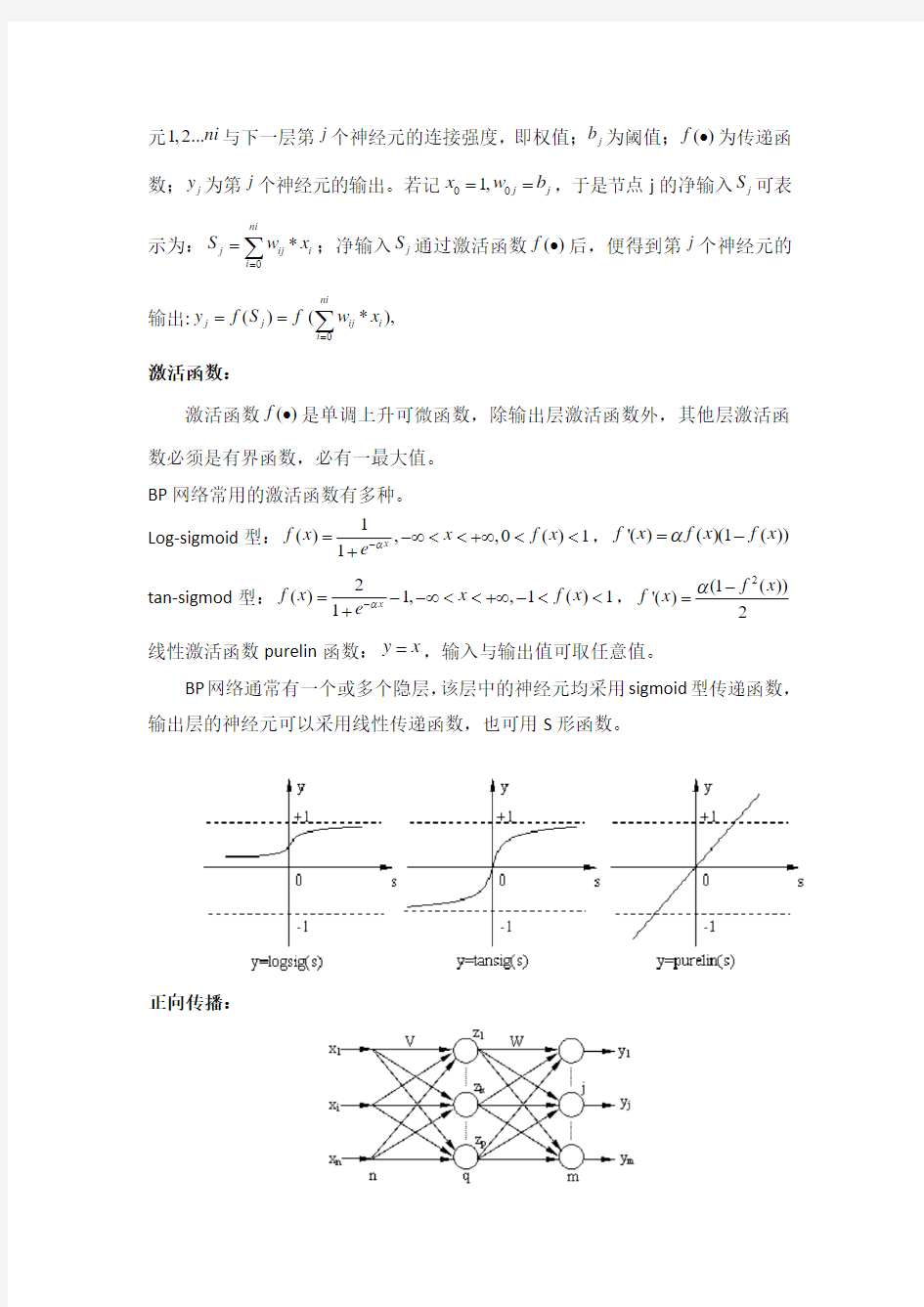
正向传播:
设 BP 网络的输入层有ni 个节点,隐层有nh 个节点,输出层有no 个节点,输入层与隐层之间的权值为ik w (ik w 为(1)*ni nh +的矩阵),隐层与输出层之间的权值为kj w (kj w 为(1)*nh no +的矩阵),隐层的传递函数为1()f ?,输出层的传递函数为2()f ?,则隐层节点的输出为(将阈值写入求和项中):
10(*),1,2...ni
k ik i i z f w x k nh
===∑;输出层节点的输出为:
20
(*),1,2...nh j kj k k y f w z j no ===∑由此,BP 网络就完成了ni 维空间向量对no 维空间
的近似映射。
def update(self , inputs):#更新ai[],ah[],a0[]中的元素,所以输入的元素个数必须跟输入层一样,将
三层先填满数据
if len (inputs) != self .ni-1:
raise ValueError ('wrong number of inputs')
for i in range (self .ni-1):#将数据导入初始层
self .ai[i] = inputs[i]
for j in range (self .nh1):#将输入层的数据传递到隐层
sum = 0.0
for i in range (self .ni):
sum = sum + self .ai[i] * self .wi[i][j] self .ah[j] = sigmoid(sum)#调用激活函数
for k in range (self .no):
sum = 0.0
for j in range (self .nh2):
sum = sum + self .ah[j] * self .wo[j][k] self .ao[k] = purelin(sum)
return self.ao[:]#返回输出层的值
反向传播:
误差反向传播的过程实际上就是权值学习的过程。网络权值根据不同的训练模式进行更新。常用的有在线模式和批处理模式。在线模式中的训练样P 本是逐
个处理的,而批处理模式的所有训练样本是成批处理的。
输入P 个学习样本,用12,...p X X X 来表示,第p 个样本输入到网络后计算得
到输出p
j y ,1,2...j no =。采用平方型误差函数,于是得到第p 个样本的误差
p
E : 210.5*()no
p p p j j j E t y ==-∑ 式中:p j t 为期望输出。 输出层权值的调整:
用梯度下降法调整
kj
w ,使误差
p
E 变小。梯度下降法原理即是沿着梯度下降
方向目标函数变化最快,梯度为2()'()*p p p kj j j j k kj
E w t y f S z w ??=
=--?,其中误差信
号2()'()p p yj j j j t y f S δ=-,权值的改变量为负梯度方向
2()'()*p p kj kj j j j k w w t y f S z ηη?=-?=-,η为学习率
output_deltas = [0.0] * self .no for k in range (self .no):
error2 = targets[k]-self .ao[k]#输出值与真实值之间的误差
output_deltas[k] = dpurelin(self .ao[k]) * error2#输出层的局部梯度,导数乘以误差,不在隐层就这么定义
for j in range (self .nh2):#更新隐层与输出层之间的权重
for k in range (self .no):
change = output_deltas[k]*self .ah[j]#权值的校正值w 的改变量(若没有冲量,且学习率为1
的时候)
self .wo[j][k] = self .wo[j][k] + N*change + M*self .co[j][k]
self .co[j][k] = change
#print N*change, M*self.co[j][k]
隐层权值的调整:
梯度为211
()'()'()*no
p p p ik j j j kj k i j ik
E w t y f S w f S x w =??=
=--?∑,其中误差信号
211
()'()'()no
p p zk j j j kj k j t y f S w f S δ==-∑,从而得到隐层各神经元的权值调整公式为:
211
()'()'()*no
p p ik ik j j j kj k i j w w t y f S w f S x ηη=?=-?=-∑
hidden_deltas = [0.0] * self .nh2#隐层的局部梯度 for j in range (self .nh2): error1 = 0.0
for k in range (self .no):
error1 = error1 + output_deltas[k]*self .wo[j][k]
hidden_deltas[j] = dsigmoid(self .ah[j]) * error1#隐层的梯度定义:不在隐层的梯度与权重的积
再求和,然后与导数的乘积
for i in range (self .ni):#更新输入层与隐层之间的权重
for j in range (self .nh1):
change = hidden_deltas[j]*self .ai[i]
self .wi[i][j] = self .wi[i][j] + N*change + M*self .ci[i][j] self .ci[i][j] = change
注:在训练集中我们考虑的是单个模式的误差,实际上我们需要训练集里所有模式的全局误差211
1
0.5*()P
no
P
p
p j
j
p p j p E t y E ====-=∑∑∑,在这种在线训练中,一个权值
更新有可能减少某个单个模式的误差,然而却增加了训练全集上的误差。不过给出大量这种单次更新,却可以降低总误差。
参数简介:
① 初始权值、阈值:初始的权值需要有一个范围w w w -<<,如果w 选的太小,一个隐单元的网络激励将较小,只有线性模型部分被实现,如果w 较大,隐单元可能在学习开始前就达到饱和。阈值一般也是随机数。
② 学习率参数:η—学习率,范围在0.001~10之间。学习率是BP 训练中的一个重要参数,学习率过小,则收敛过慢;学习率过大,则可能修正过头,导致震荡甚至发散。
③ 动量参数:动量法权值实际是对标准BP 算法的改进,具体做法是:将上一次权值调整量的一部分迭加到按本次误差计算所得的权值调整量上,作为本次的实际权值调整量,即: ()()(1)w n w n w n ηα?=-?+?-其中:α为动量系数,通常0<α<0.9;这种方法所加的动量因子实际上相当于阻尼项,它减小了学习过程
中的振荡趋势,从而改善了收敛性降低了网络对于误差曲面局部细节的敏感性,有效的抑制了网络陷入局部极小。
④ 隐层节点数:隐层节点数过少,则网络结构不能充分反映节点输入与输出之间的复杂函数关系;节点数过多又会出现过拟合现象。隐层节点数的选择至今尚无统一而完整的的理论指导,一般只能由经验选定,具体问题具体分析。 注:隐层节点经验公式法:(经验公式完全是凭经验获得,缺少相应的理论依据,对特定的样本有效,缺乏普适性的公式。)假设三层神经网络的输入层、隐层、输出层的节点数分别为M,H,N ,
①最佳隐层节点数取值范围为a N M H ++=,其中a 为1-10之间的常数(最常用的)
②当输入节点大于输出节点时,隐层最佳节点数为N M H *= ③最佳隐层节点数取值范围为1)2(*++=N M H ④根据kolmogorov 定理,最佳隐层节点数为12+=M H
⑤最佳隐层节点数为满足下公式的整数0,i 0=>>∑=i
H N
i i H C H P C ,如果
⑥最佳隐层节点数为满足下公式的整数P H 2log = 其中⑤⑥适用于批量训练模式
BP 学习训练过程如下:
1) 初始化网络,对网络参数及各权系数进行赋值,权值系数取随机数 2) 输入训练样本,通过个节点间的连接情况正向逐层计算各层的值,并与真实
值相比较,得到网络的输入误差
3) 依据误差反向传播规则,按照梯度下降法调整各层之间的权系数,使整个神
经网络的连接权值向误差减小的方向转化
4) 重复(2)和(3),直到预测误差满足条件或是训练次数达到规定次数,结
束。
参数调整说明
神经网络算法对于不同的网络需用不同的参数,参数的选择需要根据已知的测试数据进行训练测试,称这个调试参数的过程为试错法。
神经网络试错:神经网络需要设置的参数比较多,初始权值、学习率、动量系数、隐层节点数需要依据具体问题具体设置,要分类数目越多,参数调整难度越大。
调整过程中需不断观察误差和正确率的变化。无论调整哪个参数,遵循的原则为:如果调小该参数,正确率增大则继续调小该参数,到达某一临界值如果继续调小参数正确率减小,则在该临界值附近寻找最优的该参数的取值;反之亦然。具体的调整步骤为:
1)初始权值的范围选择,范围不宜太大,一般为(-0.2,0.2)或(-0.3,0.3)
2)动量系数的选择,一般0-0.9之间,宜先随机设定一个,先进行学习率和隐
层节点数的调整,如果学习率和隐层节点数的调整都找不到较高正确率,最后返回来调整动量单元。
3)学习率一般越小越好,一般先固定学习率为0.01,进行隐层节点数的调试,
如果在隐层经验公式的取值范围内找不到使得正确率较高的隐层节点数,再返回来调整学习率,取0.02,0.05,0.1,0.3,0.5等值,具体问题具体试错
分析。
4)根据经验公式对隐层节点数进行调整,常用的为①隐层节点数取值范围为
+
=,其中三层神经网络的输入层、隐层、输出层的节点数分别H+
M
a
N
为M,H,N,a为1-10之间的常数
5)最后对训练次数进行设置,如果随着训练次数的增加,误差一直处于下降的
状态,则增大训练次数;如果随着训练次数增加,误差不再继续下降,则无需增加训练次数。
参数调整没有确切的固定顺序,以最终能达到所需正确率为标准。
神经网络做分类预测:
输入数据预处理:
对于原始数据,不同评价指标往往具有不同的量纲和量纲单位,这样的情况会影响到数据分析的结果,为了消除指标之间的量纲影响,需要进行数据标准化(或归一化)处理,以解决数据指标之间的可比性。原始数据经过数据标准化处理后,各指标处于同一数量级,适合进行综合对比评价。
常用的归一化方法:
离差标准化:对原始数据进行线性变换,使结果值映射到[0,1]之间。转换函数如
下:*
min max min x
x
-
=
-
,其中max为样本数据的最大值,min为样本数据的最小值。
Z-score标准化:这种方法给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。经过处理的数据符合标准正态分布,即均值为0,
标准差为1,转化函数为:*x
x
μ
σ
-
=,其中为μ所有样本数据的均值,σ为所
有样本数据的标准差。
做分类时训练集输出数据预处理:
用0,1的行向量做输出表示数据的分类情况,若原始数据被分成n类,某
个样本属于第i类,则该样本对应的输出为[0,0,1,0,,0]
,第i个位置为0,其余位置为1。
做预测时训练集输出数据预处理:
对输出层的数据进行归一化,训练测试完毕后进行反归一化。
(eg:Fault.NNA分7类,computer_performance预测)
参考文献:
[1]高鹏毅. BP神经网络分类器优化技术研究[D].华中科技大学,2012.
[2]模式分类(原书第二版)/(美)迪达(Duda.R.O.)等著;李宏东等译.—北京:机械工业出版社,2003.9
[3]机器学习/(美)米歇尔(Mitchell,T.M.)著;曾华军等译.—北京:机械工业出版社,2003.1
中间层激活函数有界,可以将神经元输出限定在一个范围内,故系统的状态不会发生发散现象,使得系统可以从初态朝着渐近稳定状态演变
神经网络的应用及其发展
神经网络的应用及其发展 [摘要] 该文介绍了神经网络的发展、优点及其应用和发展动向,着重论述了神经网络目前的几个研究热点,即神经网络与遗传算法、灰色系统、专家系统、模糊控制、小波分析的结合。 [关键词]遗传算法灰色系统专家系统模糊控制小波分析 一、前言 神经网络最早的研究20世纪40年代心理学家Mcculloch和数学家Pitts合作提出的,他们提出的MP模型拉开了神经网络研究的序幕。神经网络的发展大致经过三个阶段:1947~1969年为初期,在这期间科学家们提出了许多神经元模型和学习规则,如MP模型、HEBB学习规则和感知器等;1970~1986年为过渡期,这个期间神经网络研究经过了一个低潮,继续发展。在此期间,科学家们做了大量的工作,如Hopfield教授对网络引入能量函数的概念,给出了网络的稳定性判据,提出了用于联想记忆和优化计算的途径。1984年,Hiton教授提出Boltzman机模型。1986年Kumelhart等人提出误差反向传播神经网络,简称BP 网络。目前,BP网络已成为广泛使用的网络;1987年至今为发展期,在此期间,神经网络受到国际重视,各个国家都展开研究,形成神经网络发展的另一个高潮。神经网络具有以下优点: (1) 具有很强的鲁棒性和容错性,因为信息是分布贮于网络内的神经元中。 (2) 并行处理方法,使得计算快速。 (3) 自学习、自组织、自适应性,使得网络可以处理不确定或不知道的系统。 (4) 可以充分逼近任意复杂的非线性关系。 (5) 具有很强的信息综合能力,能同时处理定量和定性的信息,能很好地协调多种输入信息关系,适用于多信息融合和多媒体技术。 二、神经网络应用现状 神经网络以其独特的结构和处理信息的方法,在许多实际应用领域中取得了显著的成效,主要应用如下: (1) 图像处理。对图像进行边缘监测、图像分割、图像压缩和图像恢复。
人工神经网络原理及实际应用
人工神经网络原理及实际应用 摘要:本文就主要讲述一下神经网络的基本原理,特别是BP神经网络原理,以及它在实际工程中的应用。 关键词:神经网络、BP算法、鲁棒自适应控制、Smith-PID 本世纪初,科学家们就一直探究大脑构筑函数和思维运行机理。特别是近二十年来。对大脑有关的感觉器官的仿生做了不少工作,人脑含有数亿个神经元,并以特殊的复杂形式组成在一起,它能够在“计算"某些问题(如难以用数学描述或非确定性问题等)时,比目前最快的计算机还要快许多倍。大脑的信号传导速度要比电子元件的信号传导要慢百万倍,然而,大脑的信息处理速度比电子元件的处理速度快许多倍,因此科学家推测大脑的信息处理方式和思维方式是非常复杂的,是一个复杂并行信息处理系统。1943年Macullocu和Pitts融合了生物物理学和数学提出了第一个神经元模型。从这以后,人工神经网络经历了发展,停滞,再发展的过程,时至今日发展正走向成熟,在广泛领域得到了令人鼓舞的应用成果。本文就主要讲述一下神经网络的原理,特别是BP神经网络原理,以及它在实际中的应用。 1.神经网络的基本原理 因为人工神经网络是模拟人和动物的神经网络的某种结构和功能的模拟,所以要了解神经网络的工作原理,所以我们首先要了解生物神经元。其结构如下图所示: 从上图可看出生物神经元它包括,细胞体:由细胞核、细胞质与细胞膜组成;
轴突:是从细胞体向外伸出的细长部分,也就是神经纤维。轴突是神经细胞的输出端,通过它向外传出神经冲动;树突:是细胞体向外伸出的许多较短的树枝状分支。它们是细胞的输入端,接受来自其它神经元的冲动;突触:神经元之间相互连接的地方,既是神经末梢与树突相接触的交界面。 对于从同一树突先后传入的神经冲动,以及同一时间从不同树突输入的神经冲动,神经细胞均可加以综合处理,处理的结果可使细胞膜电位升高;当膜电位升高到一阀值(约40mV),细胞进入兴奋状态,产生神经冲动,并由轴突输出神经冲动;当输入的冲动减小,综合处理的结果使膜电位下降,当下降到阀值时。细胞进入抑制状态,此时无神经冲动输出。“兴奋”和“抑制”,神经细胞必呈其一。 突触界面具有脉冲/电位信号转换功能,即类似于D/A转换功能。沿轴突和树突传递的是等幅、恒宽、编码的离散电脉冲信号。细胞中膜电位是连续的模拟量。 神经冲动信号的传导速度在1~150m/s之间,随纤维的粗细,髓鞘的有无而不同。 神经细胞的重要特点是具有学习功能并有遗忘和疲劳效应。总之,随着对生物神经元的深入研究,揭示出神经元不是简单的双稳逻辑元件而是微型生物信息处理机制和控制机。 而神经网络的基本原理也就是对生物神经元进行尽可能的模拟,当然,以目前的理论水平,制造水平,和应用水平,还与人脑神经网络的有着很大的差别,它只是对人脑神经网络有选择的,单一的,简化的构造和性能模拟,从而形成了不同功能的,多种类型的,不同层次的神经网络模型。 2.BP神经网络 目前,再这一基本原理上已发展了几十种神经网络,例如Hopficld模型,Feldmann等的连接型网络模型,Hinton等的玻尔茨曼机模型,以及Rumelhart 等的多层感知机模型和Kohonen的自组织网络模型等等。在这众多神经网络模型中,应用最广泛的是多层感知机神经网络。 这里我们重点的讲述一下BP神经网络。多层感知机神经网络的研究始于50年代,但一直进展不大。直到1985年,Rumelhart等人提出了误差反向传递学习算法(即BP算),实现了Minsky的多层网络设想,其网络模型如下图所示。它可以分为输入层,影层(也叫中间层),和输出层,其中中间层可以是一层,也可以多层,看实际情况而定。
人工神经网络BP算法简介及应用概要
科技信息 2011年第 3期 SCIENCE &TECHNOLOGY INFORMATION 人工神经网络是模仿生理神经网络的结构和功能而设计的一种信息处理系统。大量的人工神经元以一定的规则连接成神经网络 , 神经元之间的连接及各连接权值的分布用来表示特定的信息。神经网络分布式存储信息 , 具有很高的容错性。每个神经元都可以独立的运算和处理接收到的信息并输出结果 , 网络具有并行运算能力 , 实时性非常强。神经网络对信息的处理具有自组织、自学习的特点 , 便于联想、综合和推广。神经网络以其优越的性能应用在人工智能、计算机科学、模式识别、控制工程、信号处理、联想记忆等极其广泛的领域。 1986年 D.Rumelhart 和 J.McCelland [1]等发展了多层网络的 BP 算法 , 使BP 网络成为目前应用最广的神经网络。 1BP 网络原理及学习方法 BP(BackPropagation 网络是一种按照误差反向传播算法训练的多层前馈神经网络。基于 BP 算法的二层网络结构如图 1所示 , 包括输入层、一个隐层和输出层 , 三者都是由神经元组成的。输入层各神经元负责接收并传递外部信息 ; 中间层负责信息处理和变换 ; 输出层向 外界输出信息处理结果。神经网络工作时 , 信息从输入层经隐层流向输出层 (信息正向传播 , 若现行输出与期望相同 , 则训练结束 ; 否则 , 误差反向进入网络 (误差反向传播。将输出与期望的误差信号按照原连接通路反向计算 , 修改各层权值和阈值 , 逐次向输入层传播。信息正向传播与误差反向传播反复交替 , 网络得到了记忆训练 , 当网络的全局误差小于给定的误差值后学习终止 , 即可得到收敛的网络和相应稳定的权值。网络学习过程实际就是建立输入模式到输出模式的一个映射 , 也就是建立一个输入与输出关系的数学模型 :
人工神经网络的发展及应用
人工神经网络的发展与应用 神经网络发展 启蒙时期 启蒙时期开始于1980年美国著名心理学家W.James关于人脑结构与功能的研究,结束于1969年Minsky和Pape~发表的《感知器》(Perceptron)一书。早在1943年,心理学家McCulloch和数学家Pitts合作提出了形式神经元的数学模型(即M—P模型),该模型把神经细胞的动作描述为:1神经元的活动表现为兴奋或抑制的二值变化;2任何兴奋性突触有输入激励后,使神经元兴奋与神经元先前的动作状态无关;3任何抑制性突触有输入激励后,使神经元抑制;4突触的值不随时间改变;5突触从感知输入到传送出一个输出脉冲的延迟时问是0.5ms。可见,M—P模型是用逻辑的数学工具研究客观世界的事件在形式神经网络中的表述。现在来看M—P 模型尽管过于简单,而且其观点也并非完全正确,但是其理论有一定的贡献。因此,M—P模型被认为开创了神经科学理论研究的新时代。1949年,心理学家D.0.Hebb 提出了神经元之间突触联系强度可变的假设,并据此提出神经元的学习规则——Hebb规则,为神经网络的学习算法奠定了基础。1957年,计算机学家FrankRosenblatt提出了一种具有三层网络特性的神经网络结构,称为“感知器”(Perceptron),它是由阈值性神经元组成,试图模拟动物和人脑的感知学习能力,Rosenblatt认为信息被包含在相互连接或联合之中,而不是反映在拓扑结构的表示法中;另外,对于如何存储影响认知和行为的信息问题,他认为,存储的信息在神经网络系统内开始形成新的连接或传递链路后,新 的刺激将会通过这些新建立的链路自动地激活适当的响应部分,而不是要求任何识别或坚定他们的过程。1962年Widrow提出了自适应线性元件(Ada—line),它是连续取值的线性网络,主要用于自适应信号处理和自适应控制。 低潮期 人工智能的创始人之一Minkey和pape~经过数年研究,对以感知器为代表的网络系统的功能及其局限性从数学上做了深入的研究,于1969年出版了很有影响的《Perceptron)一书,该书提出了感知器不可能实现复杂的逻辑函数,这对当时的人工神经网络研究产生了极大的负面影响,从而使神经网络研究处于低潮时期。引起低潮的更重要的原因是:20世纪7O年代以来集成电路和微电子技术的迅猛发展,使传统的冯·诺伊曼型计算机进入发展的全盛时期,因此暂时掩盖了发展新型计算机和寻求新的神经网络的必要性和迫切性。但是在此时期,波士顿大学的S.Grossberg教授和赫尔辛基大学的Koho—nen教授,仍致力于神经网络的研究,分别提出了自适应共振理论(Adaptive Resonance Theory)和自组织特征映射模型(SOM)。以上开创性的研究成果和工作虽然未能引起当时人们的普遍重视,但其科学价值却不可磨灭,它们为神经网络的进一步发展奠定了基础。 复兴时期 20世纪80年代以来,由于以逻辑推理为基础的人工智能理论和冯·诺伊曼型计算机在处理诸如视觉、听觉、联想记忆等智能信息处理问题上受到挫折,促使人们
循环神经网络(RNN, Recurrent Neural Networks)介绍
循环神经网络(RNN, Recurrent Neural Networks)介绍 标签:递归神经网络RNN神经网络LSTMCW-RNN 2015-09-23 13:24 25873人阅读评论(13) 收藏举报分类: 数据挖掘与机器学习(23) 版权声明:未经许可, 不能转载 目录(?)[+]循环神经网络(RNN, Recurrent Neural Networks)介绍 这篇文章很多内容是参考: https://www.wendangku.net/doc/228039418.html,/2015/09/recurrent-neural-networks-tutorial-part-1-introd uction-to-rnns/,在这篇文章中,加入了一些新的内容与一些自己的理解。 循环神经网络(Recurrent Neural Networks,RNNs)已经在众多自然语言处理(Natural Language Processing, NLP)中取得了巨大成功以及广泛应用。但是,目前网上与RNNs有关的学习资料很少,因此该系列便是介绍RNNs的原理以及如何实现。主要分成以下几个部分对RNNs进行介绍: 1. RNNs的基本介绍以及一些常见的RNNs(本文内容); 2. 详细介绍RNNs中一些经常使用的训练算法,如Back Propagation Through Time(BPTT)、Real-time Recurrent Learning(RTRL)、Extended Kalman Filter(EKF)等学习算法,以及梯度消失问题(vanishing gradient problem) 3. 详细介绍Long Short-Term Memory(LSTM,长短时记忆网络);
外文翻译---神经网络概述
外文原文与译文 外文原文 Neural NetworkIntroduction 1.Objectives As you read these words you are using a complex biological neural network. You have a highly interconnected set of some 1011neurons to facilitate your reading, breathing, motion and thinking. Each of your biological neurons,a rich assembly of tissue and chemistry, has the complexity, if not the speed, of a microprocessor. Some of your neural structure was with you at birth. Other parts have been established by experience. Scientists have only just begun to understand how biological neural networks operate. It is generally understood that all biological neural functions, including memory, are stored in the neurons and in the connections between them. Learning is viewed as the establishment of new connections between neurons or the modification of existing connections. This leads to the following question: Although we have only a rudimentary understanding of biological neural networks, is it possible to construct a small set of simple artificial “neurons” and perhaps train them to serve a useful function? The answer is “yes.”This book, then, is about artificial neural networks. The neurons that we consider here are not biological. They are extremely simple abstractions of biological neurons, realized as elements in a program or perhaps as circuits made of silicon. Networks of these artificial neurons do not have a fraction of the power of the human brain, but they can be trained to perform useful functions. This book is about such neurons, the networks that contain them and their training. 2.History The history of artificial neural networks is filled with colorful, creative individuals from many different fields, many of whom struggled for decades to
人工神经网络题库
人工神经网络 系别:计算机工程系 班级: 1120543 班 学号: 13 号 姓名: 日期:2014年10月23日
人工神经网络 摘要:人工神经网络是一种应用类似于大脑神经突触联接的结构进行信息处理的数学模型。在工程与学术界也常直接简称为神经网络或类神经网络。神经网络是一种运算模型,由大量的节点(或称神经元)之间相互联接构成,由大量处理单元互联组成的非线性、自适应信息处理系统。它是在现代神经科学研究成果的基础上提出的,试图通过模拟大脑神经网络处理、记忆信息的方式进行信息处理。 关键词:神经元;神经网络;人工神经网络;智能; 引言 人工神经网络的构筑理念是受到生物(人或其他动物)神经网络功能的运作启发而产生的。人工神经网络通常是通过一个基于数学统计学类型的学习方法(Learning Method )得以优化,所以人工神经网络也是数学统计学方法的一种实际应用,通过统计学的标准数学方法我们能够得到大量的可以用函数来表达的局部结构空间,另一方面在人工智能学的人工感知领域,我们通过数学统计学的应用可以来做人工感知方面的决定问题(也就是说通过统计学的方法,人工神经网络能够类似人一样具有简单的决定能力和简单的判断能力),这种方法比起正式的逻辑学推理演算更具有优势。 一、人工神经网络的基本原理 1-1神经细胞以及人工神经元的组成 神经系统的基本构造单元是神经细胞,也称神经元。它和人体中其他细胞的关键区别在于具有产生、处理和传递信号的功能。每个神经元都包括三个主要部分:细胞体、树突和轴突。树突的作用是向四方收集由其他神经细胞传来的信息,轴突的功能是传出从细胞体送来的信息。每个神经细胞所产生和传递的基本信息是兴奋或抑制。在两个神经细胞之间的相互接触点称为突触。简单神经元网络及其简化结构如图2-2所示。 从信息的传递过程来看,一个神经细胞的树突,在突触处从其他神经细胞接受信号。 这些信号可能是兴奋性的,也可能是抑制性的。所有树突接受到的信号都传到细胞体进行综合处理,如果在一个时间间隔内,某一细胞接受到的兴奋性信号量足够大,以致于使该细胞被激活,而产生一个脉冲信号。这个信号将沿着该细胞的轴突传送出去,并通过突触传给其他神经细胞.神经细胞通过突触的联接形成神经网络。 图1-1简单神经元网络及其简化结构图 (1)细胞体 (2)树突 (3)轴突 (4)突触
多层循环神经网络在动作识别中的应用
Computer Science and Application 计算机科学与应用, 2020, 10(6), 1277-1285 Published Online June 2020 in Hans. https://www.wendangku.net/doc/228039418.html,/journal/csa https://https://www.wendangku.net/doc/228039418.html,/10.12677/csa.2020.106132 Multilayer Recurrent Neural Network for Action Recognition Wei Du North China University of Technology, Beijing Received: Jun. 8th, 2020; accepted: Jun. 21st, 2020; published: Jun. 28th, 2020 Abstract Human action recognition is a research hotspot of computer vision. In this paper, we introduce an object detection model to typical two-stream network and propose an action recognition model based on multilayer recurrent neural network. Our model uses three-dimensional pyramid di-lated convolution network to process serial video images, and combines with Long Short-Term Memory Network to provide a pyramid convolutional Long Short-Term Memory Network that can analyze human actions in real-time. This paper uses five kinds of human actions from NTU RGB + D action recognition datasets, such as brush hair, sit down, stand up, hand waving, falling down. The experimental results show that our model has good accuracy and real-time in the aspect of monitoring video processing due to using dilated convolution and obviously reduces parameters. Keywords Action Recognition, Dilated Convolution, Long Short-Term Memory Network, Deep Learning 多层循环神经网络在动作识别中的应用 杜溦 北方工业大学,北京 收稿日期:2020年6月8日;录用日期:2020年6月21日;发布日期:2020年6月28日 摘要 人体动作识别是目前计算机视觉的一个研究热点。本文在传统双流法的基础上,引入目标识别网络,提出了一种基于多层循环神经网络的人体动作识别算法。该算法利用三维扩张卷积金字塔处理连续视频图
Hopfield神经网络综述
题目:Hopfield神经网络综述 一、概述: 1.什么是人工神经网络(Artificial Neural Network,ANN) 人工神经网络是一个并行和分布式的信息处理网络结构,该网络结构一般由许多个神经元组成,每个神经元有一个单一的输出,它可以连接到很多其他的神经元,其输入有多个连接通路,每个连接通路对应一个连接权系数。 人工神经网络系统是以工程技术手段来模拟人脑神经元(包括细胞体,树突,轴突)网络的结构与特征的系统。利用人工神经元可以构成各种不同拓扑结构的神经网络,它是生物神经网络的一种模拟和近似。主要从两个方面进行模拟:一是结构和实现机理;二是从功能上加以模拟。 根据神经网络的主要连接型式而言,目前已有数十种不同的神经网络模型,其中前馈型网络和反馈型网络是两种典型的结构模型。 1)反馈神经网络(Recurrent Network) 反馈神经网络,又称自联想记忆网络,其目的是为了设计一个网络,储存一组平衡点,使得当给网络一组初始值时,网络通过自行运行而最终收敛到这个设计的平衡点上。反馈神经网络是一种将输出经过一步时移再接入到输入层的神经网络系统。 反馈网络能够表现出非线性动力学系统的动态特性。它所具有的主要特性为以下两点:(1).网络系统具有若干个稳定状态。当网络从某一初始状态开始运动,网络系统总可以收敛到某一个稳定的平衡状态; (2).系统稳定的平衡状态可以通过设计网络的权值而被存储到网络中。 反馈网络是一种动态网络,它需要工作一段时间才能达到稳定。该网络主要用于联想记忆和优化计算。在这种网络中,每个神经元同时将自身的输出信号作为输入信号反馈给其他神经元,它需要工作一段时间才能达到稳定。 2.Hopfiel d神经网络 Hopfield网络是神经网络发展历史上的一个重要的里程碑。由美国加州理工学院物理学家J.J.Hopfield 教授于1982年提出,是一种单层反馈神经网络。Hopfiel d神经网络是反馈网络中最简单且应用广泛的模型,它具有联想记忆的功能。 Hopfield神经网络模型是一种循环神经网络,从输出到输入有反馈连接。在输入的激励下,会产生不断的状态变化。 反馈网络有稳定的,也有不稳定的,如何判别其稳定性也是需要确定的。对于一个Hopfield 网络来说,关键是在于确定它在稳定条件下的权系数。 下图中,第0层是输入,不是神经元;第二层是神经元。
几种神经网络模型及其应用
几种神经网络模型及其应用 摘要:本文介绍了径向基网络,支撑矢量机,小波神经网络,反馈神经网络这几种神经网络结构的基本概念与特点,并对它们在科研方面的具体应用做了一些介绍。 关键词:神经网络径向基网络支撑矢量机小波神经网络反馈神经网络Several neural network models and their application Abstract: This paper introduced the RBF networks, support vector machines, wavelet neural networks, feedback neural networks with their concepts and features, as well as their applications in scientific research field. Key words: neural networks RBF networks support vector machines wavelet neural networks feedback neural networks 2 引言 随着对神经网络理论的不断深入研究,其应用目前已经渗透到各个领域。并在智能控制,模式识别,计算机视觉,自适应滤波和信号处理,非线性优化,语音识别,传感技术与机器人,生物医学工程等方面取得了令人吃惊的成绩。本文介绍几种典型的神经网络,径向基神经网络,支撑矢量机,小波神经网络和反馈神经网络的概念及它们在科研中的一些具体应用。 1. 径向基网络 1.1 径向基网络的概念 径向基的理论最早由Hardy,Harder和Desmarais 等人提出。径向基函数(Radial Basis Function,RBF)神经网络,它的输出与连接权之间呈线性关系,因此可采用保证全局收敛的线性优化算法。径向基神经网络(RBFNN)是 3 层单元的神经网络,它是一种静态的神经网络,与函数逼近理论相吻合并且具有唯一的最佳逼近点。由于其结构简单且神经元的敏感区较小,因此可以广泛地应用于非线性函数的局部逼近中。主要影响其网络性能的参数有3 个:输出层权值向量,隐层神经元的中心以及隐层神经元的宽度(方差)。一般径向基网络的学习总是从网络的权值入手,然后逐步调整网络的其它参数,由于权值与神经元中心及宽度有着直接关系,一旦权值确定,其它两个参数的调整就相对困难。 其一般结构如下: 如图 1 所示,该网络由三层构成,各层含义如下: 第一层:输入层:输入层神经元只起连接作用。 第二层:隐含层:隐含层神经元的变换函数为高斯核. 第三层:输出层:它对输入模式的作用做出响应. 图 1. 径向基神经网络拓扑结构 其数学模型通常如下: 设网络的输入为x = ( x1 , x2 , ?, xH ) T,输入层神经元至隐含层第j 个神经元的中心矢 为vj = ( v1 j , v2 j , ?, vIj ) T (1 ≤j ≤H),隐含层第j 个神经元对应输入x的状态为:zj = φ= ‖x - vj ‖= exp Σx1 - vij ) 2 / (2σ2j ) ,其中σ(1≤j ≤H)为隐含层第j个神
神经网络应用实例
神经网络 在石灰窑炉的建模与控制中的应用神经网络应用广泛,尤其在系统建模与控制方面,都有很好应用。下面简要介绍神经网络在石灰窑炉的建模与控制中的应用,以便更具体地了解神经网络在实际应用中的具体问题和应用效果。 1 石灰窑炉的生产过程和数学模型 石灰窑炉是造纸厂中一个回收设备,它可以使生产过程中所用的化工原料循环使用,从而降低生产成本并减少环境污染。其工作原理和过程如图1所示,它是一个长长的金属圆柱体,其轴线和水平面稍稍倾斜,并能绕轴线旋转,所以又 CaCO(碳酸钙)泥桨由左端输入迴转窑,称为迴转窑。含有大约30%水分的 3 由于窑的坡度和旋转作用,泥桨在炉内从左向右慢慢下滑。而燃料油和空气由右端喷入燃烧,形成气流由右向左流动,以使泥桨干燥、加热并发生分解反应。迴转窑从左到右可分为干燥段、加热段、煅烧段和泠却段。最终生成的石灰由右端输出,而废气由左端排出。 图1石灰窑炉示意图 这是一个连续的生产过程,原料和燃料不断输入,而产品和废气不断输出。在生产过程中首先要保证产品质量,包括CaO的含量、粒度和多孔性等指标,因此必须使炉内有合适的温度分布,温度太低碳酸钙不能完全分解,会残留在产品中,温度过高又会造成生灰的多孔性能不好,费燃料又易损坏窑壁。但是在生产过程中原料成分、含水量、进料速度、燃油成分和炉窑转速等生产条件经常会发生变化,而且有些量和变化是无法实时量测的。在这种条件下,要做到稳定生产、高质量、低消耗和低污染,对自动控制提出了很高的要求。 以前曾有人分析窑炉内发生的物理-化学变化,并根据传热和传质过程来建立窑炉的数学模型,认为窑炉是一个分布参数的非线性动态系统,可以用二组偏
人工神经网络及其应用实例_毕业论文
人工神经网络及其应用实例人工神经网络是在现代神经科学研究成果基础上提出的一种抽 象数学模型,它以某种简化、抽象和模拟的方式,反映了大脑功能的 若干基本特征,但并非其逼真的描写。 人工神经网络可概括定义为:由大量简单元件广泛互连而成的复 杂网络系统。所谓简单元件,即人工神经元,是指它可用电子元件、 光学元件等模拟,仅起简单的输入输出变换y = σ (x)的作用。下图是 3 中常用的元件类型: 线性元件:y = 0.3x,可用线性代数法分析,但是功能有限,现在已不太常用。 2 1.5 1 0.5 -0.5 -1 -1.5 -2 -6 -4 -2 0 2 4 6 连续型非线性元件:y = tanh(x),便于解析性计算及器件模拟,是当前研究的主要元件之一。
离散型非线性元件: y = ? 2 1.5 1 0.5 0 -0.5 -1 -1.5 -2 -6 -4 -2 2 4 6 ?1, x ≥ 0 ?-1, x < 0 ,便于理论分析及阈值逻辑器件 实现,也是当前研究的主要元件之一。 2 1.5 1 0.5 0 -0.5 -1 -1.5 -2 -6 -4 -2 2 4 6
每一神经元有许多输入、输出键,各神经元之间以连接键(又称 突触)相连,它决定神经元之间的连接强度(突触强度)和性质(兴 奋或抑制),即决定神经元间相互作用的强弱和正负,共有三种类型: 兴奋型连接、抑制型连接、无连接。这样,N个神经元(一般N很大)构成一个相互影响的复杂网络系统,通过调整网络参数,可使人工神 经网络具有所需要的特定功能,即学习、训练或自组织过程。一个简 单的人工神经网络结构图如下所示: 上图中,左侧为输入层(输入层的神经元个数由输入的维度决定),右侧为输出层(输出层的神经元个数由输出的维度决定),输入层与 输出层之间即为隐层。 输入层节点上的神经元接收外部环境的输入模式,并由它传递给 相连隐层上的各个神经元。隐层是神经元网络的内部处理层,这些神 经元在网络内部构成中间层,不直接与外部输入、输出打交道。人工 神经网络所具有的模式变换能力主要体现在隐层的神经元上。输出层 用于产生神经网络的输出模式。 多层神经网络结构中有代表性的有前向网络(BP网络)模型、
Hopfield神经网络综述
题目: Hopfield神经网络综述 一、概述: 1.什么是人工神经网络(Artificial Neural Network,ANN) 人工神经网络是一个并行和分布式的信息处理网络结构,该网络结构一般由许多个神经元组成,每个神经元有一个单一的输出,它可以连接到很多其他的神经元,其输入有多个连接通路,每个连接通路对应一个连接权系数。 人工神经网络系统是以工程技术手段来模拟人脑神经元(包括细胞体,树突,轴突)网络的结构与特征的系统。利用人工神经元可以构成各种不同拓扑结构的神经网络,它是生物神经网络的一种模拟和近似。主要从两个方面进行模拟:一是结构和实现机理;二是从功能上加以模拟。 根据神经网络的主要连接型式而言,目前已有数十种不同的神经网络模型,其中前馈型网络和反馈型网络是两种典型的结构模型。 1)反馈神经网络(Recurrent Network) 反馈神经网络,又称自联想记忆网络,其目的是为了设计一个网络,储存一组平衡点,使得当给网络一组初始值时,网络通过自行运行而最终收敛到这个设计的平衡点上。反馈神经网络是一种将输出经过一步时移再接入到输入层的神经网络系统。 反馈网络能够表现出非线性动力学系统的动态特性。它所具有的主要特性为以下两点:(1).网络系统具有若干个稳定状态。当网络从某一初始状态开始运动,网络系统总可以收敛到某一个稳定的平衡状态; (2).系统稳定的平衡状态可以通过设计网络的权值而被存储到网络中。 反馈网络是一种动态网络,它需要工作一段时间才能达到稳定。该网络主要用于联想记忆和优化计算。在这种网络中,每个神经元同时将自身的输出信号作为输入信号反馈给其他神经元,它需要工作一段时间才能达到稳定。 2.Hopfield神经网络 Hopfield网络是神经网络发展历史上的一个重要的里程碑。由美国加州理工学院物理学家J.J.Hopfield 教授于1982年提出,是一种单层反馈神经网络。Hopfield神经网络是反馈网络中最简单且应用广泛的模型,它具有联想记忆的功能。 Hopfield神经网络模型是一种循环神经网络,从输出到输入有反馈连接。在输入的激励下,会产生不断的状态变化。 反馈网络有稳定的,也有不稳定的,如何判别其稳定性也是需要确定的。对于一个Hopfield 网络来说,关键是在于确定它在稳定条件下的权系数。 下图中,第0层是输入,不是神经元;第二层是神经元。
循环神经网络注意力的模拟实现
循环神经网络注意力的模拟实现 我们观察PPT的时候,面对整个场景,不会一下子处理全部场景信息,而会有选择地分配注意力,每次关注不同的区域,然后将信息整合来得到整个的视觉印象,进而指导后面的眼球运动。将感兴趣的东西放在视野中心,每次只处理视野中的部分,忽略视野外区域,这样做最大的好处是降低了任务的复杂度。 深度学习领域中,处理一张大图的时候,使用卷积神经网络的计算量随着图片像素的增加而线性增加。如果参考人的视觉,有选择地分配注意力,就能选择性地从图片或视频中提取一系列的区域,每次只对提取的区域进行处理,再逐渐地把这些信息结合起来,建立场景或者环境的动态内部表示,这就是本文所要讲述的循环神经网络注意力模型。 怎么实现的呢? 把注意力问题当做一系列agent决策过程,agent可以理解为智能体,这里用的是一个RNN 网络,而这个决策过程是目标导向的。简要来讲,每次agent只通过一个带宽限制的传感器观察环境,每一步处理一次传感器数据,再把每一步的数据随着时间融合,选择下一次如何配置传感器资源;每一步会接受一个标量的奖励,这个agent的目的就是最大化标量奖励值的总和。 下面我们来具体讲解一下这个网络。 如上所示,图A是带宽传感器,传感器在给定位置选取不同分辨率的图像块,大一点的图像块的边长是小一点图像块边长的两倍,然后resize到和小图像块一样的大小,把图像块组输出到B。 图B是glimpse network,这个网络是以theta为参数,两个全连接层构成的网络,将传感器输出的图像块组和对应的位置信息以线性网络的方式结合到一起,输出gt。 图C是循环神经网络即RNN的主体,把glimpse network输出的gt投进去,再和之前内部信息ht-1结合,得到新的状态ht,再根据ht得到新的位置lt和新的行为at,at选择下一步配置传感器的位置和数量,以更好的观察环境。在配置传感器资源的时候,agent也会
神经网络的应用及其发展
神经网络的应用及其发展 来源:辽宁工程技术大学作者:苗爱冬 [摘要] 该文介绍了神经网络的发展、优点及其应用和发展动向,着重论述了神经网络目前的几个研究热点,即神经网络与遗传算法、灰色系统、专家系统、模糊控制、小波分析的结合。 [关键词]遗传算法灰色系统专家系统模糊控制小波分析 一、前言 神经网络最早的研究20世纪40年代心理学家Mcculloch和数学家Pitts 合作提出的,他们提出的MP模型拉开了神经网络研究的序幕。神经网络的发展大致经过三个阶段:1947~1969年为初期,在这期间科学家们提出了许多神经元模型和学习规则,如MP模型、HEBB学习规则和感知器等;1970~1986年为过渡期,这个期间神经网络研究经过了一个低潮,继续发展。在此期间,科学家们做了大量的工作,如Hopfield教授对网络引入能量函数的概念,给出了网络的稳定性判据,提出了用于联想记忆和优化计算的途径。1984年,Hiton教授提出Boltzman机模型。1986年Kumelhart等人提出误差反向传播神经网络,简称BP 网络。目前,BP网络已成为广泛使用的网络;1987年至今为发展期,在此期间,神经网络受到国际重视,各个国家都展开研究,形成神经网络发展的另一个高潮。神经网络具有以下优点: (1) 具有很强的鲁棒性和容错性,因为信息是分布贮于网络内的神经元中。 (2) 并行处理方法,使得计算快速。 (3) 自学习、自组织、自适应性,使得网络可以处理不确定或不知道的系统。 (4) 可以充分逼近任意复杂的非线性关系。 (5) 具有很强的信息综合能力,能同时处理定量和定性的信息,能很好地协调多种输入信息关系,适用于多信息融合和多媒体技术。 二、神经网络应用现状 神经网络以其独特的结构和处理信息的方法,在许多实际应用领域中取得了显著的成效,主要应用如下: (1) 图像处理。对图像进行边缘监测、图像分割、图像压缩和图像恢复。 (2) 信号处理。能分别对通讯、语音、心电和脑电信号进行处理分类;可用于海底声纳信号的检测与分类,在反潜、扫雷等方面得到应用。 (3) 模式识别。已成功应用于手写字符、汽车牌照、指纹和声音识别,还可用于目标的自动识别和定位、机器人传感器的图像识别以及地震信号的鉴别等。 (4) 机器人控制。对机器人眼手系统位置进行协调控制,用于机械手的故障诊断及排除、智能自适应移动机器人的导航。 (5) 卫生保健、医疗。比如通过训练自主组合的多层感知器可以区分正常心跳和非正常心跳、基于BP网络的波形分类和特征提取在计算机临床诊断中的应用。 (6) 焊接领域。国内外在参数选择、质量检验、质量预测和实时控制方面都
介绍人工神经网络的发展历程和分类.
介绍人工神经网络的发展历程和分类 1943年,心理学家W.S.McCulloch 和数理逻辑学家W.Pitts 建立了神经网络和数学模型,称为MP 模型。他们通过MP 模型提出了神经元的形式化数学描述和网络结构方法,证明了单个神经元能执行逻辑功能,从而开创了人工神经网络研究的时代。1949年,心理学家提出了突触联系强度可变的设想。60年代,人工神经网络的到了进一步发展,更完善的神经网络模型被提出。其中包括感知器和自适应线性元件等。M.Minsky 等仔细分析了以感知器为代表的神经网络系统的功能及局限后,于1969年出版了《Perceptron 》一书,指出感知器不能解决高阶谓词问题。他们的论点极大地影响了神经网络的研究,加之当时串行计算机和人工智能所取得的成就,掩盖了发展新型计算机和人工智能新途径的必要性和迫切性,使人工神经网络的研究处于低潮。在此期间,一些人工神经网络的研究者仍然致力于这一研究,提出了适应谐振理论(ART 网)、自组织映射、认知机网络,同时进行了神经网络数学理论的研究。以上研究为神经网络的研究和发展奠定了基础。1982年,美国加州工学院物理学家J.J.Hopfield 提出了Hopfield 神经网格模型,引入了“计算能量”概念,给出了网络稳定性判断。 1984年,他又提出了连续时间Hopfield 神经网络模型,为神经计算机的研究做了开拓性的工作,开创了神经网络用于联想记忆和优化计算的新途径,有力地推动了神经网络的研究,1985年,又有学者提出了波耳兹曼模型,在学习中采用统计热力学模拟退火技术,保证整个系统趋于全局稳定点。1986年进行认知微观结构地研究,提出了并行分布处理的理论。人工神经网络的研究受到了各个发达国家的重视,美国国会通过决议将1990年1月5日开始的十年定为“脑的十年”,国际研究组织号召它的成员国将“脑的十年”变为全球行为。在日本的“真实世界计算(RWC )”项目中,人工智能的研究成了一个重要的组成部分。 人工神经网络的模型很多,可以按照不同的方法进行分类。其中,常见的两种分类方法是,按照网络连接的拓朴结构分类和按照网络内部的信息流向分类。按照网络拓朴结构分类网络的拓朴结构,即神经元之间的连接方式。按此划分,可将神经网络结构分为两大类:层次型结构和互联型结构。层次型结构的神经网络将神经
神经网络详解
一前言 让我们来看一个经典的神经网络。这是一个包含三个层次的神经网络。红色的是输入层,绿色的是输出层,紫色的是中间层(也叫隐藏层)。输入层有3个输入单元,隐藏层有4个单元,输出层有2个单元。后文中,我们统一使用这种颜色来表达神经网络的结构。 图1神经网络结构图 设计一个神经网络时,输入层与输出层的节点数往往是固定的,中间层则可以自由指定; 神经网络结构图中的拓扑与箭头代表着预测过程时数据的流向,跟训练时的数据流有一定的区别; 结构图里的关键不是圆圈(代表“神经元”),而是连接线(代表“神经元”之间的连接)。每个连接线对应一个不同的权重(其值称为权值),这是需要训练得到的。 除了从左到右的形式表达的结构图,还有一种常见的表达形式是从下到上来
表示一个神经网络。这时候,输入层在图的最下方。输出层则在图的最上方,如下图: 图2从下到上的神经网络结构图 二神经元 2.结构 神经元模型是一个包含输入,输出与计算功能的模型。输入可以类比为神经元的树突,而输出可以类比为神经元的轴突,计算则可以类比为细胞核。 下图是一个典型的神经元模型:包含有3个输入,1个输出,以及2个计算功能。 注意中间的箭头线。这些线称为“连接”。每个上有一个“权值”。
图3神经元模型 连接是神经元中最重要的东西。每一个连接上都有一个权重。 一个神经网络的训练算法就是让权重的值调整到最佳,以使得整个网络的预测效果最好。 我们使用a来表示输入,用w来表示权值。一个表示连接的有向箭头可以这样理解: 在初端,传递的信号大小仍然是a,端中间有加权参数w,经过这个加权后的信号会变成a*w,因此在连接的末端,信号的大小就变成了a*w。 在其他绘图模型里,有向箭头可能表示的是值的不变传递。而在神经元模型里,每个有向箭头表示的是值的加权传递。 图4连接(connection) 如果我们将神经元图中的所有变量用符号表示,并且写出输出的计算公式的话,就是下图。