服务器更换硬盘经验总结

服务器更换硬盘
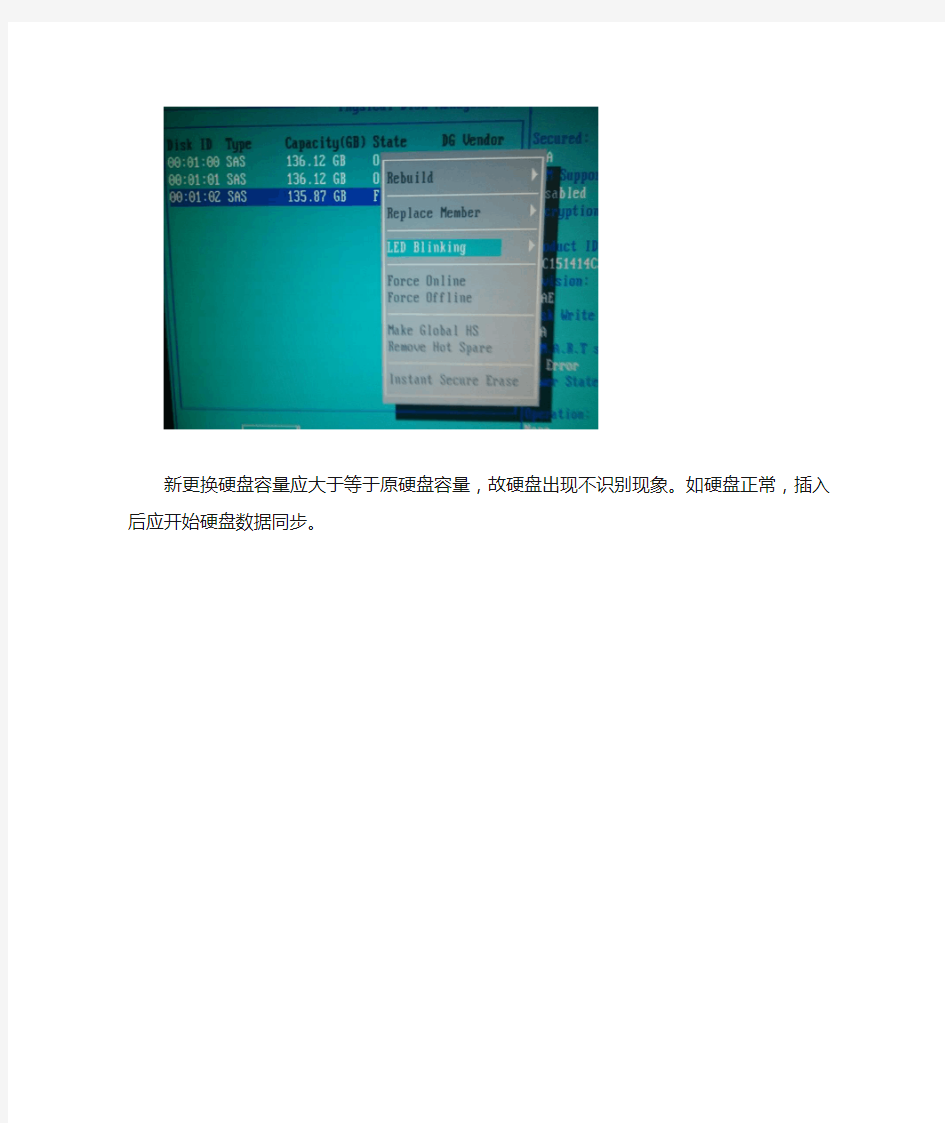
一台R720服务器一块硬盘红灯报警,需更换硬盘。到现场后,首先将故障硬盘抽出硬盘槽位(2),然后更换硬盘托架,将更换好托架的硬盘插入原槽位。新插入硬盘灯闪烁几下后状态灯和数据等常亮,根据经验应该是硬盘未识别到。经用户同意后重启机器Ctrl+R键进RAID配置界面看到硬盘状态如下图:
按Ctrl+N键进入PD Mgmt看硬盘容量为135.87GB,小于原硬盘容量。
新更换硬盘容量应大于等于原硬盘容量,故硬盘出现不识别现象。如硬盘正常,插入后应开始硬盘数据同步。
ai更换硬盘方法
当主机硬盘丢失 #lsvg -lp rootvg 结果 rootvg: PV_NAME PV STATE TOTAL PPs FREE PPs FREE DISTRIBUTION hdisk0 active 542 0 00..00..00..00..00 hdisk1 missing 542 0 00..00..00..00..00 #chpv -va hdisk1 看看能不能找回来 如果找不回来,则必须尽早予以跟换,跟换前必须做好备份! 先查看机器是否有磁带机,若无则 1、外置磁带机连接 #cfgmgr -v #lsdev -Cc tape 看一下 rmt0是不是avaiable 2、内置磁带机则直接备份 #smitty mksysb 3、查看硬盘的S/N,P/N号 #lscfg –vl hdisk* 查看物理卷 lspv 查看逻辑卷组 lsvg 查看在用的逻辑卷组 lsvg –o # lsvg -o
#sysdumpdev –l 4、查看所有硬盘(包括逻辑盘)的状态 # lsdev -Cc disk 查看7133磁盘柜硬盘状态 #lsdev –Cc pdisk 5、把HDISK0从ROOTVG中不做MIRROW #unmirrorvg rootvg hdisk0 (长时间40分钟) 查看物理卷 #lspv 这时HDISK0不在和HDISK1为MIRROR 把hdisk0从rootvg中去除 #reducevg rootvg hdisk0 (长时间0分2钟) 在HDISK1上创建boot image #bosboot –ad hdisk1 改变启动设备的顺序 #bootlist –m normal hdisk1 cd0 删除HDISK0 #rmdev –l hdisk0 –d #lspv #lscfg –vl hdisk0 以上2条命令不会显示HDISK0的相关信息 (如果无法unmirrorvg 和 rmdev 的话,就只能直接关机换盘了。) 6、关机后将对应的硬盘予以跟换,如果是热插拔的则可以热跟换。#shutdown –F 7、开机
硬盘掉线后的REBUILD修复操作全过程
DELL 服务器硬盘掉线后的REBUILD修复操作全过程 注意:对阵列以及硬盘操作可能会导致数据丢失,请在做任何操作之前,确认您的数据已经妥善备份!!! LSI BIOS界面下如何做硬盘修复 当硬盘配置阵列后,带有冗余的阵列,例如比较常用的RAID1与RAID5。在RAID 阵列使用中,如果因为某些原因(例如硬盘有坏道,硬盘检测不到,突然关机,断电等等)导致其中一块硬盘的数据未能及时更新,数据与其他硬盘无法同步,RAID卡就会把这块硬盘的状态标识为FAILED。根据RAID级别的算法特性,这样的阵列中允许有一块硬盘出现问题,系统仍然可以继续正常运行。 如果机器能够正常运行,而从外面可以看到一块硬盘闪黄灯,或者LCD上提示DRIVER FAILED,或者RAID卡报警,诸如此类的现象,说明这个时候阵列中有一块硬盘出现问题了。阵列虽然可以用,但是已经处于一个没有安全冗余的级别,要尽快修复! 注意:发现有硬盘状态不正常时,请尽可能先将重要数据妥善备份!!! 修复可以在系统下安装的Array Manager下进行,会有文档专门介绍,这里着重说明如何在LSI RAID BIOS中进行硬盘的修复。在硬盘修复中不需要用到的菜单功能将不着重介绍。 1、进入LSI RAID BIOS。在机器开机自检过程中按CTRL+M进入。 可以看到界面如下图: 2、为了保险起见,请先确认RAID级别,Objects-Logical Driver,选择要操作的逻辑驱动器,选择View/Update Parameters。
在弹出的菜单中,需要注意下列几项(建议将上图中红圈内所有的信息记录下来!) #RAID=:RAID级别 #Size=:容量 #Stripes=:相连接的物理阵列中的磁条(物理驱动器)数量 #Stripe Size=:条带大小 需要特别注意的是 #State=:逻辑驱动器状态。分别为OPTIMAL、DEGRADED、OFFLINE OPTIMAL是指逻辑驱动器状态正常,如果一个逻辑驱动器State=OPTIMAL,如上图,说明这个逻辑驱动器状态正常,不需要修复或者已经修复成功。 DEGRADED是指逻辑驱动器处于降级状态,这个时候驱动器还可以被正常访问,但是由于有一个硬盘掉线,所以没有安全冗余。通常在DEGRADED状态下需要做REBUILD修复。 OFFLINE是指逻辑驱动器中有两个或两个以上的硬盘掉线,逻辑驱动器处于不可被访问的状态。这个情况后续专门会有文档介绍。 3、确认了机器配置的是RAID5(RAID1操作步骤相同)并且State状态是DEGRADED,说明逻辑驱动器需要修复。按ESC键退回至Management Menu菜单,选择Objects-Physical Driver,回车后会有一段时间等待扫描,如下图
双机热备ServHA 镜像集群节点更换操作教程
ServHA镜像集群节点更换(或重新连入)操作手册一、手册目的 本手册介绍ServHA镜像集群的节点更换、节点重新连入的操作步骤,当用户部分硬件损坏、系统及其应用重新安装导致的原有集群配置丢失时,可按照本手册操作步骤对集群进行恢复。 注:如严格按照本手册操作,可以在集群对外服务不中断的情况下将重新连入的节点加入集群。 手册中我们假定原有集群中一台服务器的集群配置完全丢失(同时其应用也均未安装,如更换了硬盘、重新安装了操作系统),下文中这台配置丢失的服务器我们称之为“新节点”(因为其配置完全丢失,在集群看来,这完全是一个全新的节点),原有的正常服务的主机我们称之为“原节点”。 本手册前提为:新节点完全与集群脱离关系,原节点还在受集群管理,集群对外服务正常,只是新节点在集群看来已经完全离线。 (我们以一次MySQL镜像集群恢复全过程作为例子,至于其他应用其原理与操作步骤都与此例相同。) 二、配置前准备工作 首先镜像集群中目前对外正在服务,所以新节点连入时,其业务数据必须以原节点为准,在配置前,必须在新节点划分出一个大于等于原节点镜像盘空间的分区,这个分区作为新节点的镜像盘,这样才能在不损失数据(数据是以原节点镜像盘为准的)的同时将新节点连入镜像集群,这点非常重要。同时记得将新节点的IP地址等还原为离线前的状态(即设置新节点的IP地址为之前集群中离线节点的IP地址)。
在新节点完全脱离集群后,集群工作状态如下图(配置监控端):(此例中节点192.168.1.91 为新节点、192.168.1.92为原节点)双机连接状态 资源树状态,此时原节点正常对外服务(即192.168.1.92) 镜像包状态
服务器更换新硬盘做系统的详细操作步骤
服务器更换新硬盘做系统的详细操作步骤 当服务器系统损坏或硬盘故障需要更换新硬盘时需要重做服务器系统。以下操作主要是以服务器的一块硬盘备份到另一块的详细操作步骤: 一.关闭服务器 1.登陆服务器使用SecureCRT登录服务器 用户名:root 密码:root 即可登录服务器 2.关闭程序输入cd /export/home/tjsc20/runs/etc路径回车,反复执行scshut回车待 屏幕出现如下图字样说明应用关闭成功
3.备份文件使用winscp登录服务器,主机名为服务器IP地址,用户名密码都为tjsc20 然后点击登录 将shell.tar文件夹放入/export/home/tjsc20目录下 使用CRT登录服务器进入/export/home/tjsc20/目录下执行tar -xvf shell.tar命令用tjsc20用户解压cd /export/home/tjsc20/shell目录下执行 ./Data_Backup.sh 使用wincp将备份文件考到本地。 4.关闭监听使用su – oracle命令切换用户,密码也是oracle,成功后首先执行lsnrctl stop命令关闭监听,然后执行sqlplus / as sysdba进入数据库,最后执行shutdown immediate关闭数据库待屏幕出现如下图字样代表数据库关闭成功,最后执行exit退出
5.关机su–root命令切换超级用户,密码为rootroot切换后执行init 5关机 二.做系统 ※需要显示器,键盘,鼠标连接至服务器。 6.更换硬盘待服务器关机后0槽放置好硬盘,1槽放置需要做系统的新硬盘,后按住 开机键待听带风扇启动的声音后松开开机键 7.复制系统开机自检过程中出现ctrl+c提示,按ctrl+c进入LSI Logic Config Utility
GHOST全盘镜像制作(全盘备份)教程
GHOST全盘镜像制作(全盘备份)教程. 首先您必须准备两个硬盘. 硬盘1为源硬盘也就是您要备份至其它硬盘的主硬盘.以下简称为源盘 硬盘2用来存放备份硬盘1镜像的磁盘.以下简称为目标盘. 注意事项: 创建全盘镜像时建议使用GHOST 8.2或以前版本,不建议使用GHOST 8.3,容易引起制作后出现“不是有效镜像”或制作成功后硬盘空间被占用了而找不到备份的镜像问题。 目标盘容量至少需要跟源盘一样大,或者更大。 目标盘用来存放镜像的分区容量至少需要跟源盘一样大,或者更大。 目标盘分区格式建议使用FAT32分区,如果在WINDOWS下不能分超过32G的FAT32分区,建议在MAXDOS下使用DISKGEN。或其它DOS下分区软件如:DM,GDISK,SPFDISK 等,可以支持分出无限大小的FAT32分区。 如果使用NTFS分区格式,经常会出现镜像制作成功后硬盘空间被占用了而找不到备份的镜像问题。 如果出现镜像制作成功后硬盘空间被占用了而找不到备份的镜像问题,请参见此https://www.wendangku.net/doc/3e7923692.html,/bbs/read.php?tid=23699 进入正题,首先将目标盘安装到主板的IDE2接口上(请一定要注意,否则后果很严重,主板上有标),然后将目标盘整个硬盘分为一个区. 启动系统后进入MAXDOS,输入DISKGEN 后回车.出现DISKGEN菜单后如下图: 图1:
按键盘上的ALT+D (如果不熟悉键盘操作,请在运行DISKGEN前运行MOUSE加载鼠标驱动),选择“第2硬盘”回车。使用键盘上的TAB键切换至左边的圆柱形容量图上,切换过去后圆柱形容量图边框会有红色线,请注意观看。如果存在其它分区请先将这些分区删除。(请此确认此硬盘的资料已经备份)使用光标↑↓切换选择存在的分区,按DEL键将存在的分区一个一个删除。删除完毕后,再按F8存盘。 接下来在开始分区,切换到圆柱形容量图,按回车,创建新分区,出现“请输入新分区的大小”如下图 图2:
DELL PowerEdge服务器如何更换RAID上出现故障的硬盘驱动器
DELL Perc S100/S110/S300:如何更换软件 RAID 上出现故障的硬盘驱动器 本文说明如何更换Perc S100 卡中的故障磁盘。 作为提醒,Perc S100 卡是一种RAID 解决方案,仅与Windows 服务器软件兼容。此卡与Vmware Esx 或Linux 不兼容。 重要信息: 此过程仅适用于更换出现故障的硬盘驱动器(故障状态)以开始重建。 注意: Dell 建议您对数据进行完整备份,以便在您的 RAID 上执行操作。 步骤 启动服务器时(在启动操作系统之前),按Ctrl 和R 按钮可访问Perc S100/S110/S300 的BIOS。 在使用Perc S100/S110/S300 更改服务器中的磁盘时,新硬盘将显示在stauts "NO RAID" 中 此光盘无法作为RAID 的一部分被识别。在板上,Perc S100/S110/S300 应用特定签名。要将其集成到RAID 中,我们将擦除签名。 要在RAID 中集成此磁盘,您必须按如下所示操作: 向下滚动到选项:删除虚拟磁盘,然后按enter键。
选择NonRAID中的磁盘(在本例中为:1-NonRAID) 按Insert键以选择磁盘1。
按enter键,您将看到以下屏幕: 按C键确认。(驱动器将进入Ready (就绪)。)我们将此磁盘移至备份(热备用)。 向下滚动以管理全局热备用,然后按enter键。 选择分配全局热备用,然后将密钥移植:
选择我们刚刚通过就绪状态的驱动器,然后按下Insert key: 然后按enter键进行确认。 按m键返回到主菜单。 RAID 由软件管理,重建将不会启动等待服务器重启。
模拟更换硬盘以及迁移lp及lv(笔记)
先介绍几个命令 第一个命令:migratelp 命令 用途 在不同的物理卷上,将已分配的逻辑分区从一个物理分区移动到另一个物理分区。 语法 migratelp LVname/LPartnumber[ /Copynumber ] DestPV[/PPartNumber] 描述 migratelp将指定的逻辑卷LVname的逻辑分区LPartnumber移动到DestPV 物理卷。如果目标物理分区PPartNumber已指定,则使用指定的分区,否则使用逻辑卷的内部区域策略来选择目标分区。在缺省情况下,迁移第一个有问题的镜像副本。可以为Copynumber指定 1、2 或 3 的值来迁移一个特殊的镜像副本。 注:在并发卷组的情况下,必须考虑其他活动的并发节点上的分区使用情况,它是由lvmstat 报告。 migratelp命令不能迁移条带化逻辑卷的分区。 安全性 要使用migratelp,必须具有 root 用户权限。 示例 1.要将逻辑卷 lv00 的第一个逻辑分区移动到 hdisk1,请输入:migratelp lv00/1 hdisk1 2.要将逻辑卷 hd2 的第三个逻辑分区的第二个镜像副本移动到 hdisk5,请 输入: migratelp hd2/3/2 hdisk5
3.要将逻辑卷 testlv 的第 25 个逻辑分区的第三个镜像副本移动到 hdisk7,请输入: migratelp testlv/25/3 hdisk7/100 第二个命令:migratepv [ -i] [ -l LogicalVolume] SourcePhysicalVolume DestinationPhysicalVolume... 描述 migratepv命令将已分配的物理分区和它们包含的数据从SourcePhysicalVolume移到一个或多个其他物理分区。要限制传送到特定的物理卷,请在DestinationPhysicalVolume参数中使用一个或多个物理卷的名称;否则,卷组中的所有物理卷都可以传送。所有的物理卷必须在相同的卷组中。指定的源物理卷不能包含在DestinationPhysicalVolume参数列表中。 注: 所有的“逻辑卷管理器”迁移函数都是通过创建涉及的逻辑卷的镜像,然后重新同步逻辑卷来工作的。然后删除原始的逻辑卷。如果migratepv命令用于移动包含主转储设备的逻辑卷,则在命令执行过程中系统将不能够访问主转储设备。因此,在此执行过程中的转储操作将失败。要避免这一点,可以在使用sysdumpdev命令之前重新分配一个主转储设备,或者在使用migratepv之前确保有从转储设备。 您可以使用基于 Web 的系统管理器(wsm)中的卷应用程序来更改卷特征。您也可以使用“系统管理接口工具”(SMIT)smit migratepv快速路径来运行该命令。 注: 对于并发方式卷组,在 SSA 磁盘上增强并发方式是活动的或并发方式是活动的时,migratepv才可以使用。 -i从标准输入中读取DestinationPhysicalVolume参数。 -l LogicalVolume 仅移动已分配到指定的逻辑卷和位于指定的源物理卷上的物理分区。 示例 1.要将物理分区从 hdisk1 移动到 hdisk6 和 hdisk7 上,请输入: migratepv hdisk1 hdisk6 hdisk7
服务器Raid教程:全程图解手把手教你如何做RAID
没有做过亲手raid的朋友,这里有一篇受益匪浅的实战全程图解教程!不妨一看! 其实在论坛中,提到有关磁盘阵列配置的网友远不止上面这一位,针对这种情况,笔者就以一款服务器的磁盘阵列配置实例向大家介绍磁盘阵列的具体配置方法。当然,不同的阵列控制器的具体配置方法可能不完全一样,但基本步骤绝大部分是相同的,完全可以参考。 说到磁盘阵列(RAID,Redundant Array of Independent Disks),现在几乎成了网管员所必须掌握的一门技术之一,特别是中小型企业,因为磁盘阵列应用非常广泛,它是当前数据备份的主要方案之一。然而,许多网管员只是在各种媒体上看到相关的理论知识介绍,却并没有看到一些实际的磁盘阵列配置方法,所以仍只是一知半解,到自己真正配置时,却无从下手。本文要以一个具体的磁盘阵列配置方法为例向大家介绍磁盘阵列的一些基本配置方法,给出一些关键界面,使各位对磁盘阵列的配置有一个理性认识。当然为了使各位对磁盘阵列有一个较全面的介绍,还是先来简要回顾一下有关磁盘阵列的理论知识,这样可以为实际的配置找到理论依据。 一、磁盘阵列实现方式 磁盘阵列有两种方式可以实现,那就是“软件阵列”与“硬件阵列”。 软件阵列是指通过网络操作系统自身提供的磁盘管理功能将连接的普通SCSI卡上的多块硬盘配置成逻辑盘,组成阵列。如微软的Windows NT/2000 Server/Server 2003和NetVoll的NetWare两种操作系统都可以提供软件阵列功能,其中Windows NT/2000 Server/Server 2003可以提供RAID 0、RAID 1、RAID 5;NetWare操作系统可以实现RAID 1功能。软件阵列可以提供数据冗余功能,但是磁盘子系统的性能会有所降低,有的降代还比较大,达30%左右。 硬件阵列是使用专门的磁盘阵列卡来实现的,这就是本文要介绍的对象。现在的非入门级服务器几乎都提供磁盘阵列卡,不管是集成在主板上或非集成的都能轻松实现阵列功能。硬件阵列能够提供在线扩容、动态修改阵列级别、自动数据恢复、驱动器漫游、超高速缓冲等功能。它能提供性能、数据保护、可靠性、可用性和可管理性的解决方案。磁盘阵列卡拥有一个专门的处理器,如Intel的I960芯片,HPT370A/372 、Silicon Image SIL3112A等,还拥有专门的存贮器,用于高速缓冲数据。这样一来,服务器对磁盘的操作就直接通过磁盘阵列卡来进行处理,因此不需要大量的CPU及系统内存资源,不会降低磁盘子系统的性能。阵列卡专用的处理单元来进行操作,它的性能要远远高于常规非阵列硬盘,并且更安全更稳定。
RoseMirrorHA 配置替换IP的操作步骤
RoseMirrorHA配置替换IP的操作说明 由于网络访问或应用服务主动发送数据包等情况,RoseMirrorHA需要配置替换IP,以实现正常的网络访问。RoseMirrorHA配置替换IP的操作步骤说明如下。 已经创建应用服务的情况下,配置替换IP的操作说明。 1. 执行rcc命令,打开RoseMirrorHA的管理工具RCC,如下图所示。 2. 分别选中主机视图区域,右键菜单中选择“通信”,将RCC与两台主机的RoseMirrorHA服务的通信IP更换为私网心跳IP,如下图所示。两台主机都需要更换通信IP。
3. 在通信窗口中,将“主机”指定为私网心跳IP,如下所示,请根据情况输 入实际环境中的私网心跳IP。点击“确定”。 4. 将两台主机的通信IP修改为私网心跳IP后,待RCC与RoseMirrorHA 服务连接成功后,如未登录,登录后查看所创建的应用服务状态。如现为“带入”状态,选中应用服务,右键菜单中执行“带出”应用服务操作。 应用服务“带出”状态如下所示:
5. 选中已“带出”的应用服务,右键菜单选择“修改/查看”,如下图所示:
6. 在修改应用服务的窗口中,切换至“活动IP”页面,勾选“替换IP地址”,点击“确定”即可保存修改配置。 7. 修改“替换IP”配置后,选中应用服务,右键菜单选择“带入”,即可将应用服务带入。如下图所示。
8. 带入后,测试通过活动IP的网络数据是否能够正常通信。 未创建应用服务的情况下,配置替换IP的操作说明。 1. 配置RCC连接RoseMirrorHA服务时,指定私网心跳IP连接 RoseMirrorHA。 2. 在创建应用服务过程中,在“活动IP”页面,勾选“替换IP地址”即可。
HP服务器增加硬盘实施方案
HP服务器增加硬盘实施方案 一、Raid配置(进机房操作) 1、停止服务器上的进程 用xsmgss用户登录,执行 stop 2、停数据库(oracle用户) /home/oracle/>sqlplus /nolog SQL> conn / as sysdba SQL> shutdown immediate SQL>exit 3、停数据库的监听 /home/oracle/>lsnrctl LSNRCTL> stop 4、停服务器插入硬盘 5、重启服务器 6、Raid配置过程 (1)开机自检到阵列卡界面,在阵列卡初始化完成之后,会出现配置阵列的快捷键,如图 示
(2)上面提示信息说明,进入阵列卡的配置程序需要按 F8 进入阵列卡的配置程序。可以看到机器阵列卡的配置程序有4个初始选项: Create Logical Drive 创建阵列 View Logical Driver 查看阵列 Delete Logical Driver 删除阵列 Select as Boot Controller 将阵列卡设置为机器的第一个引导设备 注意:最后一个选项,将阵列卡设置为机器的第一个引导设备。这样设置后,重新启动机器,就会没有该选项。 注:如果按F8键不能进入上面的阵列配置主页面而是进入此页面
用键盘方向键选择“Exit”,按“Enter”进入 按“Enter”后服务器检测RAID卡,这时一直按“F8”也会进入阵列配置页面如图:
(3). 选择"Select as Boot Controller",出现红色的警告信息。选择此选项,服务器的第一个引导设备是阵列卡(SmartArray 642),按"F8"进行确认。 (4).按完"F8",确认之后,提示,确认改变,必须重新引导服务器,改变才可以生效。
服务器磁盘阵列详细图解
服务器磁盘阵列详细图解 RAID 0 RAID 0又称为Stripe或Striping,它代表了所有RAID级别中最高的存储性能。RAID 0提高存储性能的原理是把连续的数据分散到多个磁盘上存取,这样,系统有数据请求就可以被多个磁盘并行的执行,每个磁盘执行属于它自己的那部分数据请求。这种数据上的并行操作可以充分利用总线的带宽,显著提高磁盘整体存取性能。如图1所 示: 从理论上讲,三块硬盘的并行操作使同一时间内磁盘读写速度提升了3倍。但由于总线带宽等多种因素的影响,实际的提升速率肯定会低于理论值,大量数据并行传输与串行传输比较,提速效果显著显然毋庸置疑。 RAID 0的缺点是不提供数据冗余,因此一旦用户数据损坏,损坏的数据将无法得到恢复。 RAID 0具有的特点,使其特别适用于对性能要求较高,而对数据安全不太在乎的领域,如图形工作站等。对于个人用户,RAID 0也是提高硬盘存储性能的绝佳选择。 容错性:没有冗余类型:没有 热备盘选项:没有读性能:高 随机写性能:高连续写性能:高 需要的磁盘数:一个或多个 可用容量:总的磁盘的容量 典型应用:无故障的迅速读写,要求安全性不高,如图形工作站等。 RAID 1 RAID 1又称为Mirror或Mirroring,它的宗旨是最大限度的保证用户数据的可用性和可修复性。 RAID 1的操作方式是把用户写入硬盘的数据百分之百地自动复制到另外一个硬盘上。当读取数据时,系统先从RAID 0的源盘读取数据,如果读取数据成功,则系统不去管备份
盘上的数据;如果读取源盘数据失败,则系统自动转而读取备份盘上的数据,不会造成用户工作任务的中断。当然,我们应当及时地更换损坏的硬盘并利用备份数据重新建立Mirror,避免备份盘在发生损坏时,造成不可挽回的数据损失。 由于对存储的数据进行百分之百的备份,在所有RAID级别中,RAID 1提供最高的数据安全保障。同样,由于数据的百分之百备份,备份数据占了总存储空间的一半,因而,Mirror 的磁盘空间利用率低,存储成本高。 Mirror虽不能提高存储性能,但由于其具有的高数据安全性,使其尤其适用于存放重要数据,如服务器和数据库存储等领域。 容错性:有冗余类型:复制 热备盘选项:有读性能:低 随机写性能:低连续写性能:低 需要的磁盘数:只需2个或2*N个 可用容量:只能用磁盘容量的50% 典型应用:随机数据写入,要求安全性高,如服务器、数据库存储领域。 RAID 0+1 RAID 0+1:正如其名字一样RAID 0+1是RAID 0和RAID 1的组合形式,也称为RAID 10。以四个磁盘组成的RAID 0+1为例,其数据存储方式如图所示:RAID 0+1是存储性能和数据安全兼顾的方案。它在提供与RAID 1一样的数据安全保障的同时,也提供了与RAID 0近似的存储性能。 由于RAID 0+1也通过数据的100%备份提供数据安全保障,因此RAID 0+1的磁盘空间利用率与RAID 1相同,存储成本高。
Hard disk replace and sync(换刀片服务器硬盘步骤)
1.Replace hard disk 1)Restart the system , when we see “MPT SAS BIOS”, chose “CTRL+C”. 2)Chose “SAS1064E/C1064E”, press “Enter”. 3)Chose“RAID PROPERTIES”,press “Enter”.
4)We can see which hard disk is broken, i f it's broken , the “PredFail”is “YES”. 5)Find out the broken hard disk as we see in the “View Array”, and replace it.
2.Sync. 1)Restart the system , when we see “MPT SAS BIOS”, chose “CTRL+C”. 2)Chose “SAS1064E/C1064E”, press “Enter”.
3)Chose “RAID PROPERTIES”,p ress “Enter ”. 4)Chose “View Existing Array”,p ress “Enter” . 5)Chose “Manage Array“press “Enter”.
6)Chose “Delete Array“ to delete the old raid.
7)P ress “Space” in “RAID Disk“ [No],c hose “M”,it will change to be [Yes].The second hard disk need the same process.
小型机更换内置硬盘实施方案
小型机更换内置硬盘实施方案 一、检查工作内容: 1、# lsvg -l rootvg //如何查看硬盘是否做过mirror? 2、#bootlist -m normal -o //查看当前的引导顺序 3、lsdev -Cc disk //检查硬盘状态 4、errpt //检查错误日志 5、diag //诊断硬盘 6、lspv 记录hdisk0 序列号 lscfg –vl hdisk0 lssrc –g cluster 显示如下两个进程表示HACMP是启动状态: subsystem group PID status clstrmge cluster 22454 active clsmuxpd cluster 15874 active 可观察CLUSTER的启动:/usr/es/adm/cluster.log, /tmp/hacmp.out CLUSTER的版本lslpp –l|grep cluster 网络的状态netstat -ni 二、更换硬盘操作: 1、unmirrorvg rootvg hdisk0 2、reducevg rootvg hdisk0 或reducevg -d rootvg hdisk0 3、chpv -c hdisk0 4、rmdev -dl hdisk0 bootlist -m normal hdisk1 关机换盘或通过diag进行热更换 5、chdev -l hdisk0 -a pv=yes 6、extendvg roovg hdisk0 或#extendvg -f rootvg hdisk0 强制把hdisk0加入到rootvg 7、mirrorvg roovg 8、chvg -Qn roovg 9、bosboot -ad hdisk0 bosboot -ad hdisk1 10、bootlist -m normal hdisk0 hdisk1 验证:
服务器硬盘丢失解决办法
如果是SCIS的硬盘,上500W的电源偶尔也会出供电方面的小问题。很多标着500W的电源,在长时间处于高功率的情况下有时400W不到都能让导致当机。 一但暴力关机或是断电的话就可能会有问题。 解决的方法是: 1:更换电源。用了一个实际功率400W的服务器电源。 2:硬盘找不到,可能是主版的问题 “硬盘丢失”故障检查处理方法 “硬盘丢失”故障指系统开机时无法检测到硬盘的故障现象,“硬盘丢失”类故障属硬盘子系统硬件故障,大多需要打开机箱检修。“自检硬盘失败”故障在系统加电自检、初始化时常会给出以下信息: no fixed disk present(硬盘不存在) hdd controller failure(硬盘控制器错误) device error(驱动器错误) drive not ready error(驱动器未准备就绪) hard disk configuration error (硬盘配置错误) hard disk controller failure (硬盘控制器失效) hard disk failure (硬盘失效) reset failed(硬盘复位失败) fatal error bad hard disk (硬盘致命错误) no hard disk installed (没有安装硬盘) device error(驱动器错误) 常见“硬盘丢失”故障包括大致包括“cmos硬盘参数丢失”、“bios不识硬盘”和“自检查硬盘失败”三类。以下分别讨论处理方法。 1、cmos硬盘参数丢失 “cmos硬盘参数丢失”故障指bios能够识别安装的硬盘,但开机启动时bios中设置硬盘参数被自动更新的故障现象。•分析与处理 “cmos硬盘参数丢失”故障主要由主板cmos电路故障、病毒或软件改写cmos参数导致,“cmos硬盘参数丢失”故障可按以下步骤检查处理: 1)如果关机一段时间以后,cmos参数自动丢失,使用时重新设置后,又能够正常启动计算机。这往往是cmos电池接触不良或cmos电池失效引起的,建议检查cmos电池,确保接触良好,并用电压表检查cmos电池电压,正常情况应为3v左右(早其有些主板cmos电池电压为3.6v),如果cmos电池电压远低于正常值,说明cmos电池已经失效,一定要及时更换电池,以避免电池漏液,污染主板,将导致主板的损坏。 2)如果是运行程序中死机后cmos参数自动丢失,很可能是病毒或软件改写cmos 参数导致,请先对系统进行清除病毒工作,以排除某些攻击cmos的病毒所造成的故障。 3)如果系统安装有防病毒软件,如pc-cillin,这些软件发现病毒后会改写cmos,自动将硬盘设置为无。
windows server2003_域服务器更换硬盘迁移的问题
域服务器迁移 方案一: 找了一台普通的机器,装server 2003 ,加入域,然后配置成备份域服务器。域数据copy完成后,关闭主服务器,然后安装本地的服务器dhcp和dns,再参照下面升级备份域服务器为主域服务器,按照提示重启什么的。 然后老的机器更换硬盘,重装,再和前面操作一样,配置成备份域服务器,在关闭主服务器的情况下,再次升级备份域服务器为主域服务器。 (在这个过程中可能会有IP地址变更,和迁移当中DNS报错的情况,根据提示,把DNS里面一些错误的配置信息更改掉就可以了。) AD恢复主域控制器 本文讲述了在多域控制器环境下,主域控制器由于硬件故障突然损坏,而又事先又没有做好备份,如何使额外域控制器接替它的工作,使Active Directory正常运行,并在硬件修理好之后,如何使损坏的主域控制器恢复。 ------------------------------- 目录 Active Directory操作主机角色概述 环境分析 从AD中清除主域控制器https://www.wendangku.net/doc/3e7923692.html, 对象 在额外域控制器上通过ntdsutil.exe工具执行夺取五种FMSO操作 设置额外域控制器为GC(全局编录) 重新安装并恢复损坏主域控制器附:用于检测AD中五种操作主机角色的脚本 --------------------------- 一、Active Directory操作主机角色概述 Active Directory 定义了五种操作主机角色(又称FSMO): 架构主机schema master 具有架构主机角色的 DC 是可以更新目录架构的唯一DC。这些架构更新会从架构主机复制到目录林中的所有其它域控制器中。架构主机是基于目录林的,整个目录林中只有一个架构主机。 域命名主机domain naming master 具有域命名主机角色的 DC 是可以执行以下任务的唯一 DC:向目录林中添加新域。从目录林中删除现有的域。添加或删除描述外部目录的交叉引用对象。 相对标识号(RID)主机 RID master 主机此操作主机负责向其它 DC 分配 RID 池。只有一个服务器执行此任务。在创建安全主体(例如用户、组或计算机)时,需要将 RID 与域范围内的标识符相结合,以创建唯一的安全标识符 (SID)。每一个 Windows 2000 DC 都会收到用于创建对象的 RID 池(默认为 512)。RID 主机通过分配不同的池来确保这些 ID 在每一个 DC 上都是唯一的。通过 RID 主机,还可以在同一目录林中的不同域之间移动所有对象。 域命名主机是基于目录林的,整个目录林中只有一个域命名主机。相对标识号(RID)主机是基于域的,目录林中的每个域都有自己的相对标识号(RID)主机。
手把手教你组装raid5及raid1磁盘阵列服务器【详细版】
也许一些刚刚玩服务器DIY的朋友一听到raid这个词就犯头晕,分不清楚到底说的是啥意思。raid 模式虽多,但以我的理解其实就是把2个以上的硬盘组合在一起,一块用,以达到更快的速度和更高的安全性,大家不需要了解太多raid模式,只要知道raid0、raid1和raid5就足够在服务器行业混饭了(其实什么也不知道照样混饭的人也很多),用唐华的大白话说,所谓raid0就是两块硬盘合成一块硬盘用,例如两个80G的硬盘,做成raid0模式,就变成一块160G的大硬盘,理论上硬盘传输速度也加倍,但是这种模式安全性很低,一旦一个硬盘坏了,两个硬盘里的所有数据都会报销,因此服务器上最好不用这种模式。 所谓raid1就是两块硬盘互相做同步备份(镜像),例如两块80G的硬盘,做成raid1模式,总容量还是80G没变化,硬盘传输速度也没变化,但是两个硬盘里的数据保持同步,完全一样,一旦其中一个硬盘坏了,靠另一个硬盘,服务器依然能正常运行,这种模式很安全,所以现在很多中低端服务器采取这种raid模式,这种模式简单实用,用不高的硬件成本即可实现,我很喜欢。至于raid5,则过去一直是高档服务器的专利,即使是在今天,你翻翻许多名牌服务器的价目表,在1-2万元的产品里也很难觅到raid5的身影,采用raid5可以兼顾raid0的速度、容量和raid1的安全性,是个听起来很完美的磁盘阵列方案。 硬件raid5组建: 最近又亲手给一个朋友组装了一台采用双核心P4 820D处理器的8硬盘的1U机架式存储型服务器,在组装过程中,分别组建了硬件Raid5和软件Raid5的磁盘阵列,过程很值得玩味,现在写出详细的设置过程,以期抛砖引玉,给大家带来更多一点启发。 首先将服务器组装好,然后给硬盘插上SATA的数据线,插入主板上的四个SATA接口,用并口线连接好我的LG刻录机当光驱用,这个主板只提供了1个并口IDE接口用来接光驱正好,连上显示器、键盘、鼠标,开机测试,启动顺利,按DEL键进入bios。 在BIOS里看到,主板已经识别出四块西数250G大容量硬盘和LG刻录机。
数据中心P系列小型机硬盘更换步骤
历史版本记录
目录 1编写目的 (3) 2北方中心DATA VG 硬盘更换步骤 (3)
1 编写目的 由于北方数据中心小机硬盘更换将成为日常工作内容之一,为方便大家将工作流程化,特编写文档。由于各种小机硬盘分布情况不尽相同,本文将举出4种北方中心小机硬盘更换例子。 例子1:环境为单硬盘rootvg加上单硬盘datavg的小型机,其中rootvg的PV名称为hdisk0,datavg的PV名称为hdiak1,需要替换datavg的PV名称为hdiak2。 例子2:环境为单硬盘rootvg加上单硬盘datavg的小型机,其中rootvg的PV名称为hdisk0,datavg的PV名称为hdiak1,需要替换rootvg的PV名称为hdiak2。 例子3:环境为双硬盘mirror的rootvg加上双硬盘mirror的datavg的小型机,其中rootvg的两个PV名称为hdiak0,hdisk1,datavg的两个PV名称为hdisk2,hdisk3,其中hdisk2需要被替换。 例子4:环境为双硬盘mirror的rootvg加上双硬盘mirror的datavg小型机,其中rootvg的两个PV名称为hdiak0,hdisk1,datavg的两个PV名称为hdisk2,hdisk3,其中hdisk0需要被替换。 2 北方中心数据中心P系列小机硬盘更换步骤 例子1: 注意:在更换硬盘之前,必须做好数据的备份工作。 1.将小机上的应用停掉。在空槽位插入新硬盘,使用cfgmgr 和lspv命令后,看新盘是否可用。如果新盘没有分配新的PID,那么执行chdev命令添加新硬盘的PID。 #chdev –l hdiak2 –a pv=yes 2.将新增加的硬盘hdisk2加入到datavg中: #extendvg –f datavg hdisk2 因为硬盘的数据迁移只能在同一个卷组中进行。 3.确保在新增加的硬盘中有足够的空间存储源硬盘的数据: #lspv hdisk1 |grep "USED PPs" 例如输出如下: USED PPs : 97(1552 megabytes)
SUN-SVM-在线更换硬盘-RAID1
在线更换硬盘 说明:现有一台Sun T5220的主机系统的一个分区镜像损坏,分区处于维护模式,系统有如下报错:
一.基本检测: 1. 尝试同步分区 2.查看传输状态 结果:同步时,磁盘状态显示传输错误一直增加,分区镜像无法同步,需要在线更换损坏磁盘。 二.在线更换: 1.查询分区镜像信息
bash-3.2# metastat d6 d6: 镜像 次镜像0: d16 状态:确定 次镜像1: d26 状态:需要维护 传送:1 读入选项:roundrobin (缺省) 写入选项:parallel (缺省) 大小:74549376 块(35 GB) d16: d6 的次镜像 状态: 确定 大小:74549376 块(35 GB) 条0: 设备引导块Dbase 状态Reloc 热备援 c1t0d0s6 0 否确定是 d26: d6 的次镜像 状态: 需要维护 调用:metareplace d6 c1t1d0s6 <新设备> 大小:74549376 块(35 GB) 条0: 设备引导块Dbase 状态Reloc 热备援 c1t1d0s6 0 否维护是 bash-3.2# metadb flags first blk block count a m p luo 16 8192 /dev/dsk/c1t0d0s4 a p luo 8208 8192 /dev/dsk/c1t0d0s4 a p luo 16 8192 /dev/dsk/c1t1d0s4 a p luo 8208 8192 /dev/dsk/c1t1d0s4 a p luo 16400 8192 /dev/dsk/c1t1d0s4 bash-3.2# metastat -p d7 -m d17 d27 1 d17 1 1 c1t0d0s7 d27 1 1 c1t1d0s7 d5 -m d15 d25 1 d15 1 1 c1t0d0s5 d25 1 1 c1t1d0s5 d3 -m d13 d23 1 d13 1 1 c1t0d0s3 d23 1 1 c1t1d0s3
服务器RAID-硬盘容量扩展
Extend - Dell 近来遇到了服务器磁盘空间不够的问题,短期内无法更换服务器硬件,只能采购更大容量的硬盘,所以研究了一下如何扩展服务器RAID 硬盘容量,而又不需要重新安装OS和应用,这样就不必影响对业务和用户。手头的都是Dell 的服务器,还有一些HP的老机器,分别作了一些研究和测试,最后在生产环境中成功完成,记录在此。 首先,有两个名词Extend,Expand,中文翻译过来都差不多,但是用在RAID 容量扩展上,分别特指不同的的功能,Dell,HP的文档中都相同(应该是RAID adapter 供应商的通用标准名词吧), 所以我特意将blog的标题中的名词用英文表示,以做区别。 1. Extend ----- 这是指已经做好的RAID中,不增加或删除硬盘,而是更换为更大容量的硬盘,然后将RAID扩展到所有可用磁盘空间,例如下面例子中的RAID1 的两个73G硬盘,先热插拔更换一个为更大的300G硬盘,等RAID 恢复完成(只使用300G上的73G),再热插拔另一块。待这块RAID 恢复也完成的时候(两个300G 硬盘上各只使用了73G 做RAID1),扩展RAID1 到整个2*300G。 2. Expand ----- 这是向现有的RAID 中加入或者删除容量完全相同的硬盘,来调节RAID 磁盘空间的方法。例如,向现有RAID1 的2*73 G中再加入两块73G硬盘。当然最好是品牌,规格于RAID中原来的硬盘完全相同的,如果稍有差异也可以。expand 有个特殊之处就是可以在expand的过程中改变RAID,例如从原来的RAID 1 2*73G 变成RAID5 4*73G,或者RAID10 4*73G。如果原来是RAID5 4*73G 也可以通过expand 拿两块硬盘出来变成RAID1 2*73G.
- 服务器更换新硬盘做系统的详细操作步骤
- GDC-SA2100服务器硬盘更换演示
- 服务器RAID1模式替换硬盘说明
- 服务器Raid教程:全程图解手把手教你如何做RAID..
- 硬盘掉线后的REBUILD修复操作全过程
- DELL服务器磁盘阵列的扩容
- DELL PowerEdge服务器如何更换RAID上出现故障的硬盘驱动器
- 更换服务器硬盘步骤
- DELL 服务器 磁盘RAID制作与系统安装
- 25块硬盘海量存储服务器组装过程
- SUN服务器更换硬盘
- 华为服务器硬盘更换指导书
- DELL_服务器硬盘掉线后的REBUILD修复操作全过程
- 服务器硬盘维护总结
- Dell poweredge 2950 服务器添加新硬盘
- X86服务器存储-浪潮服务器在线换盘步骤
- HP服务器增加硬盘实施方案
- Hard disk replace and sync(换刀片服务器硬盘步骤)
- DELL RAID下添加硬盘或更换硬盘
- dell服务器硬盘状态恢复上线