Cassandra集群安装
Cassandra集群在CentOS平台的安装
一、安装前准备
1.实验规划
Cassandra是一套开源分布式NoSql数据库,集Google的Big Table数据模式与Amazon 的Dynamo完全分布式架构于一身。它最初由FaceBook开发,在2008年转为开源项目。由于良好的可扩展性被许多知名网站采用,成为一种流行的分布式结构化数据存储方案。
Cassandra的主要特点是它是由一堆数据库节点共同组成的一个分布式网络服务,且使用了去中心化的模式。对Cassandra的一个写操作会被复制到若干节点上,而对它的一个读操作则会被路由到某个节点执行。对于一个Cassandra集群,要扩展性能非常容易,只需往集群中增加节点即可。
本次实验的目的是搭建一个Cassandra集群,并在此基础上进行若干测试。实验环境计划使用三个物理节点,全部由虚拟机实现。具体如下:
2.准备虚拟服务器
1)在本地计算机上安装VMWare Station
注意不要安装精简版或绿色版(可能会发生虚拟机ping不通的情况),本实验安装的是12.1.1汉化版,过程从略。
2)在VMWare Station里安装虚拟机母本
为与将来的开发生产环境保持一致,本实验选择的是64位CentOS 7 build1604版,安装好的虚拟机名称为CentOS_7,它将作为以后其它虚拟机的克隆母本,过程从略。
3)为虚拟机配置固定IP
Centos 虚拟机的IP默认是DHCP,需要改为固定IP。
在VMWare里,设置VMnet8模式的各项,包括:去掉DHCP、设置子网网关、IP掩码、DNS、选定VMnet8(NAT模式),具体从略。
再启动虚拟机,以root登录Centos,在图形界面下修改网络适配器设置,具体从略。
4)安装必要服务
yum -y update
再安装必要的服务,具体从略。
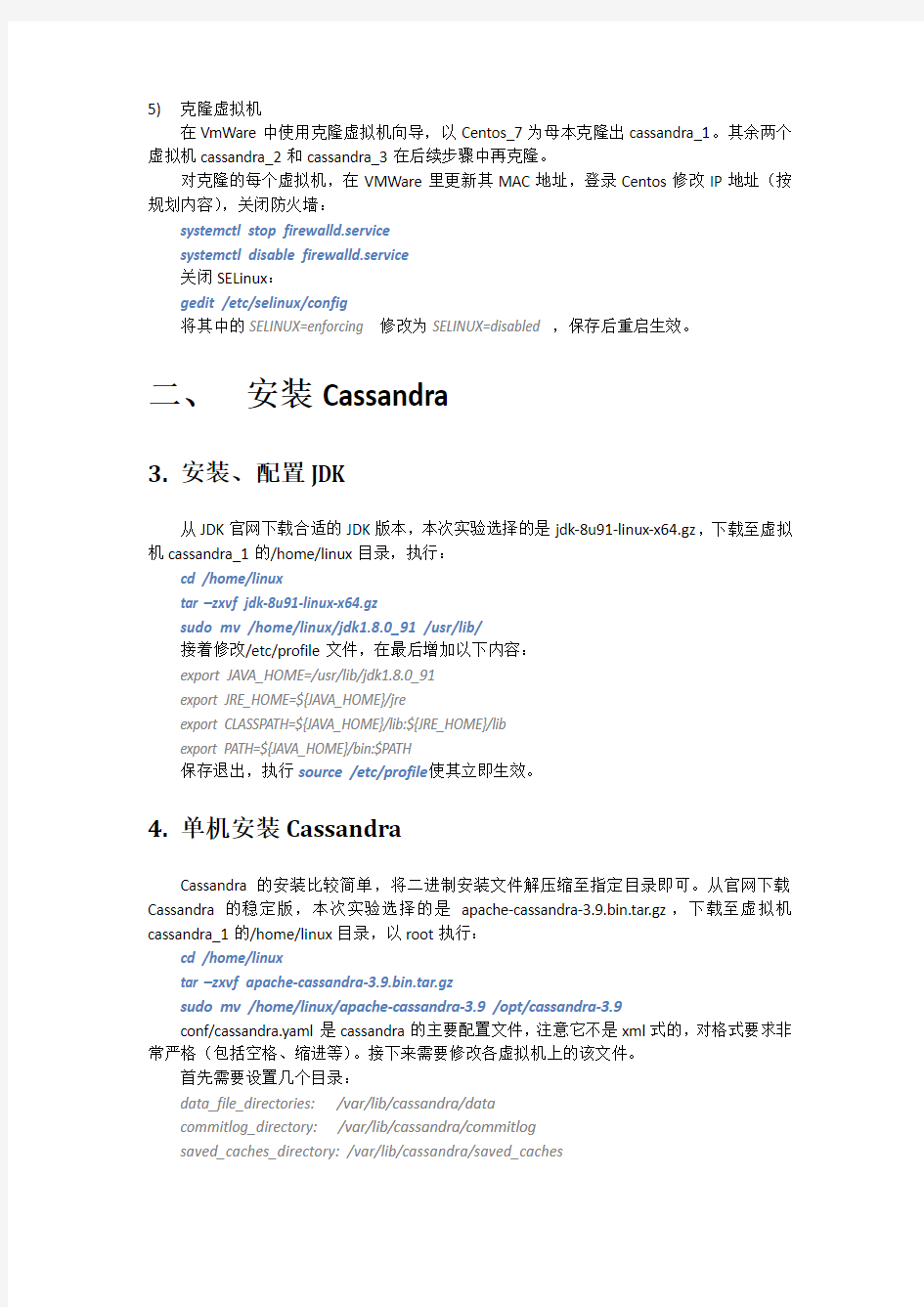
5)克隆虚拟机
在VmWare中使用克隆虚拟机向导,以Centos_7为母本克隆出cassandra_1。其余两个虚拟机cassandra_2和cassandra_3在后续步骤中再克隆。
对克隆的每个虚拟机,在VMWare里更新其MAC地址,登录Centos修改IP地址(按规划内容),关闭防火墙:
systemctl stop firewalld.service
systemctl disable firewalld.service
关闭SELinux:
gedit /etc/selinux/config
将其中的SELINUX=enforcing修改为SELINUX=disabled,保存后重启生效。
二、安装Cassandra
3.安装、配置JDK
从JDK官网下载合适的JDK版本,本次实验选择的是jdk-8u91-linux-x64.gz,下载至虚拟机cassandra_1的/home/linux目录,执行:
cd /home/linux
tar –zxvf jdk-8u91-linux-x64.gz
sudo mv /home/linux/jdk1.8.0_91 /usr/lib/
接着修改/etc/profile文件,在最后增加以下内容:
export JAVA_HOME=/usr/lib/jdk1.8.0_91
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
保存退出,执行source /etc/profile使其立即生效。
4.单机安装Cassandra
Cassandra的安装比较简单,将二进制安装文件解压缩至指定目录即可。从官网下载Cassandra的稳定版,本次实验选择的是apache-cassandra-3.9.bin.tar.gz,下载至虚拟机cassandra_1的/home/linux目录,以root执行:
cd /home/linux
tar –zxvf apache-cassandra-3.9.bin.tar.gz
sudo mv /home/linux/apache-cassandra-3.9 /opt/cassandra-3.9
conf/cassandra.yaml是cassandra的主要配置文件,注意它不是xml式的,对格式要求非常严格(包括空格、缩进等)。接下来需要修改各虚拟机上的该文件。
首先需要设置几个目录:
data_file_directories: /var/lib/cassandra/data
commitlog_directory: /var/lib/cassandra/commitlog
saved_caches_directory: /var/lib/cassandra/saved_caches
在cassandra.yaml中找到相应项,去掉前面的注释符即可(注意别改空格和缩进)。
保存退出后,以root添加用户、目录,赋予权限:
groupadd cassandra
useradd -s /bin/bash -g cassandra cassandra
mkdir /var/lib/cassandra/
mkdir /var/lib/cassandra/data
mkdir /var/lib/cassandra/commitlog
mkdir /var/log/cassandra/saved_caches
chown -R cassandra: cassandra /opt/ cassandra-3.9
chown -R cassandra: cassandra /var/lib/cassandra
然后启动Cassandra:
su - cassandra
cd /opt/cassandra-3.9/bin
./cassandra
在输出内容(大致在结束前两屏)中,如果出现“INFO hh:mm:ss Node localhost/127.0.0.1 state jump to NORMAL”表示单机安装成功。
如要停止Cassandra,先查出其pid:
ps -aux | grep cassandra
再kill掉查询处理的pid。
5.配置Cassandra集群
在VmWare中,以cassandra_1为母本克隆出cassandra_2和cassandra_3。对每个克隆出的虚拟机,依次修改MAC、静态IP,不赘述。
接下来仍需修改cassandra.yaml文件。Cassandra采用去中心化模式,所以一个节点启动之后需要通知整个集群才能加入,这通过Cassandra 配置文件里的seeds 设置项完成。所谓的seeds 就是能够联系集群中所有节点的若干节点,一般挑选出几个比较稳定的节点即可。本实验中,挑选cassandra_1作为seeds,配置它的cassandra.yaml时与其它两个节点略有不同,具体为:
对于cassandra_1,seeds由127.0.0.1改为192.168.64.151,listen_address和rpc_address 由localhost改为192.168.64.151;对于另两个节点,seeds由127.0.0.1改为192.168.64.151,而listen_address和rpc_address由localhost改为它们的IP。
在各个节点上启动Cassandra。首次启动时,建议使用-f选项以前端方式运行(便于调试和观察日志信息),先启动seeds节点,然后每隔一定时间(不少于30秒)再启动另外一个节点,否则后启节点可能无法加入集群(报错信息:Other bootstrapping/leaving/moving nodes detected, cannot bootstrap while cassandra.consistent.rangemovement is true)。以后再启动无需加-f选项,顺序也不再重要,只需seeds节点启动即可。如果此时出现“The number of initial tokens (by initial_token) specified is different from num_tokens value”的错误信息,需要清空有关目录后再重新初始化集群:
rm -rf /var/lib/cassandra/data/*
rm -f /var/lib/cassandra/commitlog/*
待集群启动后,可使用nodetool在任一节点上查看节点信息,如:
./nodetool -h 192.168.64.151 ring #查看所有节点运行情况
./nodetool -h 192.168.64.151 info #查看指定节点详细信息
./nodetool -h 192.168.64.151 cfstats #查看指定节点的数据结构
./nodetool -h 192.168.64.153 removetoken #移除一个已经宕掉的节点
三、测试Cassandra事务处理
6.对事务ACID的支持
对于关系型数据库,事务的ACID(原子性、一致性、隔离性和持久性)特性是理应满足的标准行为。对于非关系型的Cassandra,并不提供完整的ACID支持,对各个特性的支持程度如下:
●原子性:指事务要么全部成功要么全部回滚。Cassandra只提供有限度的支持,一
是以Batch方式执行增、删、改,二是在2.0版后以轻量级事务防止并行事务间的
冲突。
●一致性:指事务不能使数据库处于不一致状态。Cassandra对此提供可选择的可用
性和一致性,用户可以选择运行准则——多少节点必须收到指令。
●隔离性:指事务之间不能互相干扰。在1.1版之后,Cassandra提供了行一级的隔
离级别,不会出现一个事务中正在更新的部分数据会被另一个事务读取到的现象。
●持久性:指事务完成后,更改能够被持久保持。Cassandra对此是确定的,并且以
复制到多节点的方式增强了本地的持久性。
在随后的测试中,重点是对原子性的实现方法进行测试。
7.用CQL创建测试对象
CQL是Cassandra的类SQL查询语言,执行cqlsh可进入cql控制台:
cd /opt/cassandra-3.9/bin
./cqlsh 192.168.64.151
注意:cqlsh后可以是任何一个节点的IP,效果完全一致。
1)创建keyspace
cqlsh> CREATE KEYSPACE testkp WITH replication={'class':'SimpleStrategy', 'replication_factor':1};
创建一个名为testkp的keyspace(相当于关系数据库中的database),副本策略为SimpleStrategy,复制因子为1。
2)创建Column family
cqlsh> USE testkp;
cqlsh:testkp> CREATE COLUMNFAMILY users( name varchar PRIMARY KEY, gender varchar, coursesum int);
cqlsh:testkp> CREATE COLUMNFAMILY courses (ID int PRIMARY KEY, name varchar, course varchar);
创建两个column family(相当于数据库中的table):第一个名为users,key为name,其余2列分别为gender和coursesum,第二个名为courses,key为ID,其余2列分别为name 和course。
3)插入数据
cqlsh:testkp> INSERT INTO users(name, gender, coursesum) VALUES('John', 'M', 0);
cqlsh:testkp> INSERT INTO users(name, gender, coursesum) VALUES('Mary', 'F', 0);
向users插入两条初始记录,至于对courses的操作在随后进行。
4)查询数据
cqlsh:testkp> select * from users;
cqlsh:testkp> select * from courses;
结果分别返回2行数据及0行数据,与前面操作相符。
8.用Java测试事务
Cassandra通过Thrift(一种多语言服务开发框架)提供了多种语言支持接口,如Java、C++、C#、Python等。在本节将使用Java来对Cassandra进行操作,主要是实验对事务的支持度,包括Batch模式和轻量级事务两方面。
1)建立/断开连接
相关代码比较固定,如下示例:
QueryOptions options = new QueryOptions();
options.setConsistencyLevel(ConsistencyLevel.QUORUM);
Cluster cluster = Cluster.builder()
.addContactPoints("192.168.64.151")
.withCredentials("cassandra", "cassandra")
.withQueryOptions(options).build();
session = cluster.connect("testkp");
//test code here…;
session.close();
cluster.close();
2)BATCH模式(拼串方式)
BATCH模式是将若干cql语句(只支持Insert, Update和Delete)组成一个整体执行,虽然可以保证原子性(要么全部成功要么全部失败),但不保证隔离性(可能读取到不一致的数据)。由于Cassandra没有RollBack机制,原子性是通过batchlog实现的,效率比普通cql 要低。
如果对cql很熟悉,可使用拼cql串来实现。PreparedStatement或RegularStatement都行,推荐使用PreparedStatement。相关代码示例:
String cql = "BEGIN BATCH "
+ "INSERT INTO courses(ID, name, course) VALUES(?, ?, ?); "
+ "UPDATE users SET coursesum=? WHERE name=?; "
+ "APPLY BATCH";
PreparedStatement ps = (PreparedStatement) session.prepare(cql);
session.execute(ps.bind(1, "John", "Math", 1, "John"));
3)BATCH模式(使用BatchStatement)
Batch的另一种实现方式是使用BatchStatement,这应该是Cassandra的默认选择。相关
代码示例:
RegularStatement insert = QueryBuilder.insertInto("testkp","courses")
.values(new String[]{"ID", "name", "course"},
new Object[] {2, "Mary", "Language"});
RegularStatement update = QueryBuilder.update("testkp","users")
.with(QueryBuilder.set("coursesum", 1))
.where(QueryBuilder.eq("name", "Mary"));
BatchStatement batch = new BatchStatement();
batch.add(insert);
batch.add(update);
session.execute(batch);
4)轻量级事务(拼串方式)
Cassandra的轻量级事务,是指通过附加IF EXISTS或IF NOT EXISTS来避免race condition 的问题。举例:当接收到相同rowkey的两条insert,如果带有if not exist,cassandra会将后提交的insert覆盖前一个。这是通过paxos来解决的。
轻量级事务可以使用拼cql串的方式,PreparedStatement或RegularStatement都行。代码示例:
String cql = "INSERT INTO courses(ID, name, course) VALUES(?, ?, ?) "
+ "IF NOT EXISTS;";
PreparedStatement ps = (PreparedStatement) session.prepare(cql);
session.execute(ps.bind(3, "Tom", "Physics"));
5)轻量级事务(使用QueryBuilder)
轻量级事务也可通过QueryBuilder类来实现,这样代码显得更规范和抽象,通常使用的是RegularStatement。示例代码:
RegularStatement delete = QueryBuilder.delete()
.from("testkp","courses")
.where(QueryBuilder.eq("name", "Tom"))
.ifExists();
session.execute(delete);
服务器集群设计
服务器集群设计 服务器集群技术随着服务器硬件系统与网络操作系统的发展而产生的,在可用性、高可靠性、系统冗余等方面越来越发挥重要中用,是核心系统必不可少的。数据库保存者抄表系统的数据,是整个信息系统的关键所在。 解决系统可靠性的措施通常是备份和群集。备份不能快速恢复,主要用于安全保存,数据库和系统的快速故障恢复通常采用HA(高可用)群集模式, HA 能提供不间断的系统服务,在线系统发生故障时,离线系统能立即发现故障并立即进行接管,继续对外提供服务。HA技术可以有效防止关键业务主机宕机而造成的系统停止运行,被广泛采用。HA技术有两种模式: 具有公共存储系统的HA 数据存储在公共的存储系统上,服务器1为活动服务器,服务器2为待机服务器(备份服务器),当服务器1发生故障时(软或硬件故障),服务器2通过私有网络(心跳路径)侦测到服务器1的故障并自动接管服务器1上所有的资源(如IP地址、存储系统、数据库服务、计算机名等),继续为客户机提供数据或其他应用服务。 独立存储系统的HA数据存储在各自服务器的独占存储设备上(内置磁盘或磁盘阵列) ,没有共享存储系统,数据保存在每个服务器独占的存储设备上。通过镜像技术使每台服务器的数据保持同步,切换时间更短,可靠性比共享存储系统的方案更高,并避免了单点崩溃的可能性,增加了数据的安全性及系统的可用性。两台服务器之间的距离不受外部存储设备连接线的限制,因而可以将两台服务器放置在不同位置。
根据上述分析、系统要求、应用软件采用三层结构的优势以及艾因泰克在发电企业几十家的建设经验,方案采用独立存储系统的HA模式。 由于两套数据库服务器只有一台在线工作,方案本着最大限度节约资源的原则,充分高性能服务器的性能,在备用服务器上运行系统的WEB应用。采用双机双应用,互为备用结构。即在线数据库服务器是 WEB应用服务器的备用服务器,在线WEB应用服务器是数据库服务器的备用服务器。这种结构不但充分发挥性能服务器的优势,又保证关键服务器具有自动备用服务器。不但节约了成本,而且避免了采用共用存储设备单点故障带来的数据丢失的灾难,是最佳的选择。 数据库和应用服务器集群结构如下图: 服务器采用2台PowerEdge R900,配置7块146G磁盘,2块磁盘组成RAID 1镜像,作为操作系统盘。5块组成磁盘组成RAID 5,作为数据盘。 集群镜像软件选用RoseMirrorHA。RoseMirrorHA是一个可靠的、稳定的、高性能的应用高可用保护解决方案,实现应用程序的保护,保证了业务的持续运
WindowsServer2016虚拟机安装Oracle12cRAC
WindowsServer2016虚拟机安装Oracle12c_RAC 群集磁盘2:ASM 第1章安装环境确认 1.1 硬件平台(Hyper-V) RAC-A 1G内存双网卡 RAC-B 1G内存双网卡 iscsi服务器1G内存 1.2 软件环境 操作系统:Windows Server 2016 Oracle软件:Oracle Database 12c Release 1 (12.1.0.2.0)
集群工具:Oracle Database Grid Infrastructure (12.1.0.2.0) 磁盘管理工具:ASM 1.3 安装平台信息 第2章环境准备 2.1 修改主机名 在两台主机上分别执行,计算机——右键(属性),主机名设置为RAC-A和RAC-B。 2.2 关闭防火墙 关闭所有防火墙。
停止Windows Firewall系统服务。 在主机1和主机2上ping对方的公用和私用地址,要求都能ping通。 2.3 配置DEP 在两台主机上,计算机——右键(属性)——更改设置——高级(设置)——数据执行保护(DEP),选择仅为基本windows程序和服务启用(重启后才能生效)。
2.4 关闭UAC 在两台主机上,控制面板(小图标方式查看)——用户账户——更改用户账户控制设置,改为从不通知,确定(重启后生效)。 2.5 禁用媒体感知功能 因为在网络调试时,Windows 的“媒体感知”功能会检测出本机和局域网设备没有正常连通,接着可能就会禁用捆绑在网卡上的某些网络协议,其中就包括TCP/IP 协议。由于TCP/IP 协议被禁用了,这样该TCP/IP 应用程序就无法进行调试了。(该设置重启生效) 在HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\Tcpip\Parameters中添加键值如下:
服务器集群实验
2003服务器集群实验 一、服务器集群简介 什么是服务器群集?有何作用? 服务器群集是一组协同工作并运行Microsoft群集服务(Microsoft Cl uster Service,MSCS)的独立服务器。它为资源和应用程序提供高可用性、故障恢复、可伸缩性和可管理性。它允许客户端在出现故障和计划中的暂停时,依然能够访问应用程序和资源。如果群集中的某一台服务器由于故障或维护需要而无法使用,资源和应用程序将转移到可用的群集节点上。 服务器群集不同于NLB群集,服务器群集是有独立计算机系统(节点)构成的组,不同节点协同工作,就像单个系统一样,从而确保关键的应用程序和资源始终可由客户端使用。用于访问量较少的企业内网的服务器的冗余和可靠性。 哪些版本的操作系统支持服务器群集? 只有两个版本的windows server 2003系统支持该技术:企业版和数据中心版。 服务器群集的应用范围? 服务器群集最多可以支持8个节点,可实现DHCP、文件共享、后台打印、MS SQL server、exchange server等服务的可靠性。 二、群集专业术语 节点: 构建群集的物理计算机 群集服务: 运行群集管理器或运行群集必须启动的服务 资源: IP地址、磁盘、服务器应用程序等都可以叫做资源 共享磁盘: 群集节点之间通过光纤SCSI 电缆等共同连接的磁盘柜或存储 仲裁资源: 构建群集时,有一块磁盘会用来仲裁信息,其中包括当前的服务状态各个节点的状态以及群集转移时的一些日志 资源状态: 主要指资源目前是处于联机状态还是脱机状态 资源依赖: 资源之间的依存关系 组: 故障转移的最小单位 虚拟服务器: 提供一组服务--如数据库文件和打印共享等 故障转移: 应用从宕机的节点切换到正常联机的节点
两台服务器的集群方案
本文由szg81贡献 doc1。 七台服务器的集群方案 在传统的终端/主机的网络模式时代,终端功能简单,无需维护工作,在主机一端进行专门的管理与维护,具有资源共享、便于 管理的特点。但是,主机造价昂贵,终端没有处理能力,限制了网络的规模化发展。之后的客户机/服务器模式推进了计算产业 的标准化和开发化的发展,为系统提供了相当大的灵活性,但是随着分布系统规模的规模扩大,系统的维护和管理带来了巨大 的开销。面向 Internet 的服务型应用,需要高性能的硬件平台作为支持,将并行技术应用在服务器领域中,是计算机发展的必然 趋势。并行处理技术在高性能计算领域中,高可用和高性能是集群服务器系统发展的两个重要方向。 集群的概念 集群英文名称是 CLUSTER,是一组相互独立的、通过高速网络互联的计算机,它们构成了一个组,并以单一系统的模式加以管 理。一个客户与集群相互作用时,集群像是一个独立的服务器。集群配置是用于提高可用性和可缩放性。和传统的高性能计算 机技术相比,集群技术可以利用各档次的服务器作为节点,系统造价低,可以实现很高的运算速度,完成大运算量的计算,具 有较高的响应能力,能够满足当今日益增长的信息服务的需求。 集群技术应用的需求 Internet 用户数量呈几何级数增长和科学计算的复杂性要求计算机有更高的处理能力,而 CPU 的发展无法跟上不断增长的需求, 于是我们面临以下问题: ●大规模计算如基因数据的分析、气象预报、石油勘探需要极高的计算性能。 ●应用规模的发展使单个服务器难以承担负载。 ●不断增长的需求需要硬件有灵活的可扩展性。 ●关键性的业务需要可靠的容错机制。 IA 集群系统(CLUSTER)的特点 ●由若干完整的计算机互联组成一个统一的计算机系统; ●可以采用现成的通用硬件设备或特殊应用的硬件设备,例如专用的通讯设备; ●需要特殊软件支持,例如支持集群技术的操作系统或数据库等等; ●可实现单一系统映像,即操作控制、IP 登录点、文件结构、存储空间、I/O 空间、作业管理系统等等的单一化; ●在集群系统中可以动态地加入新的服务器和删除需要淘汰的服务器, 从而能够最大限度地扩展系统以满足不断增长的应用的需 要; ●可用性是集群系统应用中最重要的因素,是评价和衡量系统的一个重要指标; ●能够为用户提供不间断的服务,由于系统中包括了多个结点,当一个结点出现故障的时候,整个系统仍然能够继续为用户提供 服务; ●具有极高的性能价格比,和传统的大型主机相比,具有很大的价格优势; ●资源可充分利用,集群系统的每个结点都是相对独立的机器,当这些机器不提供服务或者不需要使用的时候,仍然能够被充分 利用。而大型主机上更新下来的配件就难以被重新利用了。 实现服务器集群的硬件配置 ●网络服务器 七台 ●服务器操作系统硬盘 七块 ●ULTRA 160 LVD SCSI 磁盘阵列 一个 ●18G SCSI 硬盘 十块 ●网络服务网卡 十四块 服务器集群的实践步骤 ●在安装机群服务之前的准备: 1、 十四块 18G SCSI 硬盘组成磁盘阵列,做 RAID5。 2、 两台服务器要求都配置双网卡,分别安装 Microsoft Windows Server2008 操作系统,并配置网络。 3、 所有磁盘必须设置成基本盘,阵列磁盘分区必须大于 7 个。 4、 每台服务器都要加入域当中,成为域成员,并且在每台服务器上都要有管理员权限。 ●安装配置服务器网络要点 1、在这一部分,每个服务器需要两个网络适配器,一个连接公众网,一个连接内部网(它只包含了群集节点) 内部网适配器 。 建立点对点的通信、群集状态信号和群集管理。每个节点的公众网适配器连接该群集到公众网上,并在此驻留客户。 2、安装 Microsoft Windows 2000 Adwance Server 操作系统后,开始配置每台服务器的网络。在网络连接中我们给连接公众网的 命名为"外网",连接内部网的命名为"内网"并分别指定 IP 地址为:节点 1:内网:ip:10.10.10.11 外网 ip:192.168.0.192 子网 掩码:255.255.255.0 网关:192.168.0.191(主域控制器 ip) ;节点 2:内网:ip:10.10.10.12 外网 ip:192.168.0.193 子网掩码: 255.255.255.0 网关:192.168.0.191;节点 3:内网:ip:10.10.10.13 外网 ip:192.168.0.194 子网掩码:255.255.255.0 网关: 192.168.0.191;节点 4:内网:ip:10.10.10.14 外网 ip:192.168.0.195 子网掩码:255.255.255.0 网关:192.168.0.191;节点 5: 内
Oracle_11g 安装图解(详细版)
Oracle 11g安装图文攻略 呵呵,花了一个多小时,左右把11g安装折腾好了。其中折腾SQL Developer 花了好长时间,总算搞定了。好了,先总结下安装步骤,希望给后面的童鞋提高安装效率。呵呵。 一、Oracle 下载 注意Oracle分成两个文件,下载完后,将两个文件解压到同一目录下即可。路径名称中,最好不要出现中文,也不要出现空格等不规则字符。 官方下地址: https://www.wendangku.net/doc/456372979.html,/technetwork/database/enterprise-edition/downloads/ index.html以下两网址来源此官方下载页网。 win 32位操作系统下载地址: https://www.wendangku.net/doc/456372979.html,/otn/nt/oracle11g/112010/win32_11gR2_database_ 1of2.zip https://www.wendangku.net/doc/456372979.html,/otn/nt/oracle11g/112010/win32_11gR2_database_ 2of2.zip win 64位操作系统下载地址: https://www.wendangku.net/doc/456372979.html,/otn/nt/oracle11g/112010/win64_11gR2_database_ 1of2.zip https://www.wendangku.net/doc/456372979.html,/otn/nt/oracle11g/112010/win64_11gR2_database_ 2of2.zip 二、Oracle安装 1. 解压缩文件,将两个压缩包一起选择,鼠标右击 -> 解压文件如图
存储服务器集群配置
系统结构: 两台服务器集群,通过网络同时与阵列相连。其中一台为当前活动服务器,另一台热备。 服务器间通过心跳线相连,确保集群讯息传递。 目的: 为防止单点故障,集群服务通过服务器即时切换,实现任意一台服务器故障后,用户依然能对阵列上所存储的资源进行操作而不受影响,为维修或更换设备赢得时间。 整体思路: 1.在阵列上创建仲裁分驱和共享分驱 2.启动集群服务器中的一台A,查看是否识别出阵列上划分的空间。是则格式化分驱, 并启动集群服务器B,检查其是否识别已分驱的磁盘。是则关闭服务器B,然后在 服务器A上创建集群 3.选择域,输入要创建的集群名称 4.输入节点A主机名,可点击BROWSE选择服务器名称 5.等待系统执行前至配置,如无异常执行下一步 6.输入集群ip地址,此地址为虚拟集群服务器地址,并无实际设备存在
7.在域服务器上创建一个集群用户,在集群向导中输入用户名密码 8.点击QUORUM选择在阵列上创建的仲裁磁盘,结束配置 9.启动集群服务器B,启动集群管理服务,选择加入集群。 10.选择要加入集群的节点服务器B 11.等待配置完成,若无异常进行下一步 12.输入集群服务器所在域的域用户密码 13.检察配置信息,无误则结束配置 14.右键单击RESOURCE新建资源 15.输入资源名称并选择资源类型及所在组 16.将与之关联的服务器加入相关组 17.设置共享名称及路径,单击完成结束配置 18.设置共享资源完全共享权限 19.在当前管理服务器上设置共享磁盘的权限 一.环境准备条件: 1.域服务器至少一台 2.在域中创建用户,为后边集群服务器登陆使用 3.两台准备做集群的节点服务器,需配置双网卡。 4.准备心跳线一根,将两台节点服务器相连。 二。配置集群 域用户:cluster 主机A信息: 主机A名称:NASA 域名:12.CALT.CASC 公网IP:10.21.0.171 心跳IP:192.168.0.1 主机B信息: 主机B名称:NASB 域名:12.CALT.CASC 公网IP:10.21.0.172 心跳IP:192.168.0.2
多节点集群多机互备解决方案
https://www.wendangku.net/doc/456372979.html,nderSoft(LVGUI-ch.DOC) Normal **项目 多机互备集群解决方案 销售:王晓强 作者:市场部 上海联鼎软件股份有限公司 https://www.wendangku.net/doc/456372979.html, 版权所有 目录 第一章引言2 1.1公司介绍2 1.2背景3 1.3方案设计总原则5 第二章需求描述6 2.1需求概述6 2.2现状说明和存在问题6 2.3总体需求说明7 第三章方案设计7 3.1项目风险分析8 3.2需解决的问题8
3.3设计原则9 第四章方案描述10 4.1总体方案概述10 4.2集群系统方案概述11 4.3工作流程简单描述11 4.4L ANDER C LUSTER软件的优势:12 第五章方案优势13 第六章技术规格19 第一章引言 1.1公司介绍 联鼎软件(Landersoft)是领先的核心业务及数据安全系统解决方案供应商,致力于通过保障用户关键应用及核心电子化数据,确保企业在全球信息化持续发展进程中无间断的竞争力及信心。产品面向应用高可用性,以及全球范围内的核心系统容灾及数据保护。在中国已有超过5000个用户,9500例安装,市场占有率达到前三位,覆盖金融、电信、医疗、政府、交通、电力、教育、制造业、基础资源等行业,已被证明适用于各种应用、服务器、存储硬件和相关设备并实现互操作。 联鼎软件拥有先进的多平台测试开发系统及前瞻性的用户体验中心。公司大中华区总部设在上海,南亚总部设在新加坡,在中国大型城市设有分支机构,形成具有强大优势的销售管理体系和技术支持体系,能够更好、更及时的响应用户需求。 联鼎认为,未来十年,随着IT技术的加速发展,社会对IT环境及服务将高度依赖,保障企业
搭建一个服务器集群
搭建一个服务器集群 包含负载均衡,HA高可用,MySQL主从复制,备份服务器,和监控服务器,服务用discuz 论坛演示 服务器配置如下 服务器名服务器ip服务器作用 backup192.168.199.180备份+zabbix监控+NFS Nginx1192.168.199.142主Director Nginx2192.168.199.145从Director Apache1192.168.199.200Apache1 Apache2192.168.199.210Apache2 Apache3192.168.199.233Apache3 Mysql1192.168.199.126主mysql Mysql2192.168.199.131从mysql Mysql3192.168.199.197从mysql VIP192.168.199.3Apache负载均衡VIP 在所有服务器上操作 #关闭selinux sed-i's/SELINUX=enforcing/SELINUX=disabled/'/etc/selinux/config&&setenforce0; #清空iptables iptables-F&&service iptables save; #安装nfs服务 yum install-y nfs-utils epel-release 配置backup服务器 mkdir-p/data/discuz#建立discuz应用目录 mkdir/opt/backup#建立backup目录 #设置目录的属主和属组 chown-R shared:shared/data/discuz chown-R shared:shared/opt/backup vi/etc/exports#设置共享目录 /data/discuz/192.168.199.0/24(rw,sync,all_squash,anonuid=500,anongid=500) /opt/backup/192.168.199.0/24(rw,sync,all_squash,anonuid=500,anongid=500) /etc/init.d/rpcbind start;/etc/init.d/nfs start#启动NFS服务 配置mysql服务器 #挂载NFS服务器backup目录 mount-t nfs-onolock192.168.199.180:/opt/backup/opt vi/etc/fstab 192.168.199.180:/opt/backup/opt nfs nolock00 安装MySQL #在3台mysql服务器上下载mysql5.7的二进制安装文件
服务器虚拟化集群技术方案
XX科研院所 服务器虚拟集群系统 技术方案
目录 1前言 (1) 2项目建设必要性分析 (1) 3方案设计 (3) 3.1总体拓扑 (3) 3.2方案概述 (3) 3.3VM WARE 服务器虚拟化方案 (5) 3.3.1服务器虚拟化方案概述 (5) 3.3.2方案架构及描述 (7) 3.3.3方案优势 (15) 3.4C ITRIX X EN DE SKTOP桌面虚拟化方案 (16) 3.4.1桌面虚拟化概述 (16) 3.4.2方案架构及描述 (29) 3.4.3Citrix产品及功能描述 (36) 3.5V F OGLIGHT虚拟环境监控方案 (40) 3.5.1虚拟环境监控方案概述 (40) 3.5.2方案介绍 (44) 3.6接入网络解决方案 (54) 3.6.1方案描述 (54) 3.6.2物理布局设计 (58) 3.6.3方案优势 (59) 3.6.4业务服务器区接入层设计的创新发展 (60) 3.6.5基于Nexus产品的创新设计总结 (64) 4配置方案 (65)
1前言 广泛采用的IT 平台在应用范围和复杂性方面急速发展,服务器数量、网络复杂程度和存储容量也随着一波波的技术变革而激增。由此导致的诸多问题目前仍在困扰着各信息化部门。如:服务器利用率低下、多应用并存导致系统不稳定、整机备份还原困难、计划内或计划外的停机导致服务中断等。 服务器虚拟化技术,经过数十年的发展,成功的解决了这些问题,为基础资源整合提供了理想的解决方案。通过部署服务器虚拟集群,将多个服务器、网络存储设备、备份系统等作为一个资源池,从资源池中灵活的分配适当的资源给相应的应用,使得上述问题迎刃而解。今天,服务器虚拟化技术已经被广泛应用在各个领域,作为绿色数据中心的核心技术手段,发挥着重大的作用。 2项目建设必要性分析 随着信息化工作的不断推进,XX科研院所已建立若干重要应用系统等。这些系统的正常运行切实保障了XX科研院所的科研生产顺利开展,大大提高了工作效率和科研能力。这些应用无不需要良好的服务器环境作为支撑,而且随着应用数量及性能要求的不断提高,对服务器环境资源的要求也将越来越高。同时,随着科研生产对信息化的依赖性增强,保障数据中心稳定、不间断的运行显得越来越重要。 数据中心现有多台服务器,每台服务器都运行多个应用服务。目前主要存在以下几个问题: 1.服务器资源使用率不均匀平均使用率低于40%。 2.计划外或计划内停机维护,影响应用服务的不间断运行。 3.部署新应用的成本较高。 这些问题越来越严重的影响着数据中心安全稳定的运行,解决这些问题迫在眉睫。
oracle 11g 安装图解
oracle 11g 安装图解 启动OUI后出现“选择安装方式”窗口,我们选择:高级安装 步骤3:出现“选择安装类型”窗口,选择我们需要安装的版本。我们在此肯定是选择企业版。
至于产品语言不用选择,它会根据当前系统的语言自动调整!步骤4:出现“安装位置”窗口
Oracle 基目录:用于安装各种与ORACLE软件和配置有关的文件的顶级目录。 软件位置:用于存放安装具体ORACLE产品的主目录和路径。在此我们使用默认的配置。 在此ORACLE会选择剩余空间最多的盘作为基目录和安装目录的所在盘。 可以输入一个电子邮件或是metalink接收安全问题通知,在此我直接输入一个电子邮件,当然也可以是metalink用户信息!
步骤5:再向下就是对安装环境进行检测,如果不满足条件则会给出相应的提示,如图所示: 在此是因为我的内存不足,所以会报此提示,那么我们在此调整内存,以满足条件后再继续安装。
步骤6:出现“选择配置选项”如图:
在此选择安装数据库。 如果是“配置自动存储管理”,则自动存储管理(ASM)可用来自动化和简化对数据文件、控制文件和日志文件的优化布局。自动存储管理(ASM)将每个文件切割成许多小扩展文件,并将它们平均分散在一个磁盘组的所有磁盘上。一旦自动存储管理(ASM)磁盘组建立,创建和删除文件的时候,Oracle数据库都会从磁盘组自动分配存储空间。 如果是“仅安装软件”,则只安装ORACLE软件,在安装之后还需要再运行数据库配置助手创建数据库。 步骤7:出现“选择数据库配置”窗口,在此需要选择在安装过程中创建的数据库类型。 一般用途/事务处理:适合各种用途的预配置数据库。 数据仓库:创建适用于特定需求并运行复杂查询环境。常用于存储并快速访问大量记录数据。 高级:安装结束后运行ORACLE DBCA后,用户才可以配置数据库。
两台服务器集群巧搭建
服务器集群系统中,服务器不再分布在各处,而是集中在一起统一进行管理和维护。它保持了分布式客户机/服务器模式的开发性、可扩展性的优点,同时又具备了终端/主机模式的资源共享和集中易于管理的优点。 服务器集群系统中,服务器不再分布在各处,而是集中在一起统一进行管理和维护。它保持了分布式客户机/服务器模式的开发性、可扩展性的优点,同时又具备了终端/主机模式的资源共享和集中易于管理的优点。相对集中的集群系统,降低了系统管理的成本,而且还提供了和大型服务器系统相媲美的处理能力。 在传统的终端/主机的网络模式时代,终端功能简单,无需维护工作,在主机一端进行专门的管理与维护,具有资源共享、便于管理的特点。但是,主机造价昂贵,终端没有处理能力,限制了网络的规模化发展。之后的客户机/服务器模式推进了计算产业的标准化和开发化的发展,为系统提供了相当大的灵活性,但是随着分布系统规模的规模扩大,系统的维护和管理带来了巨大的开销。 面向Internet的服务型应用,需要高性能的硬件平台作为支持,将并行技术应用在服务器领域中,是计算机发展的必然趋势。并行处理技术在高性能计算领域中,高可用和高性能是集群服务器系统发展的两个重要方向。 集群的概念 集群英文名称是CLUSTER,是一组相互独立的、通过高速网络互联的计算机,它们构 成了一个组,并以单一系统的模式加以管理。一个客户与集群相互作用时,集群像是一个独立的服务器。集群配置是用于提高可用性和可缩放性。 和传统的高性能计算机技术相比,集群技术可以利用各档次的服务器作为节点,系统造价低,可以实现很高的运算速度,完成大运算量的计算,具有较高的响应能力,能够满足当今日益增长的信息服务的需求。 #P# 集群技术应用的需求 Internet用户数量呈几何级数增长和科学计算的复杂性要求计算机有更高的处理能力,而CPU的发展无法跟上不断增长的需求,于是我们面临以下问题: ●大规模计算如基因数据的分析、气象预报、石油勘探需要极高的计算性能。
售后服务集群服务器安装
(售后服务)集群服务器安 装
WIN2Kadvanceserver集群服务器安装 壹:安装要求 1.软件要求 于群集里的所有计算机上,均安装了MicrosoftWindows2000AdvancedServer或 Windows2000DataCenterServer。 2.硬件要求 群集服务节点的硬件,必须满足Windows2000AdvancedServer或Windows2000DataCenterServer的硬件要求。这些要求可于产品兼容性查找页面找到。 群集硬件必须是于群集服务硬件兼容性列表里的(HCL)。到Windows硬件兼容性列 表中,查询群集,就能够找到最新的群集服务HCL。 俩台满足HCL的计算机,分别具有如下配置: 有所安装的Windows2000AdvancedServer或 Windows2000DataCenterServer的启动盘。该启动盘不能位于下面 所描述的共享存储总线上。 共享的磁盘有独立的PCI存储适配器(SCSI或光纤)。启动盘适配器 除外。 群集里的每台计算机有俩块PCI网络适配器。 有HCL兼容的外部存储单元,它跟所有的计算机相连。它被作为群 集磁盘使用。建议使用独立磁盘冗余阵列(RAID)。 用存储线缆,将共享设备连接到所有的计算机。可参考制造商的指南, 配置存储设备。 3.网络要求 唯壹的NetBIOS群集名。 五个独立的、静态的IP地址:俩个用于内部网的网络适配器(192.0.0.1、192.0.0.2), 俩个用于外接公众网的网络适配器(10.10.100.1、10.10.100.2),壹个用于群集本身 (10.10.100.3)。
服务器集群技术方案
服务器集群技术方案 集群(Cluster )技术是发展高性能计算机的一项技术。它是一组相互独立的计算机,利用高速通信网络组成一个单一的计算机系统,并以单一系统的模式加以管理。其出发点是提供高可靠性、可扩充性和抗灾难性。一个集群包含多台拥有共享数据存储空间的服务器,各服务器通过内部局域网相互通信。当一台服务器发生故障时,它所运行的应用程序将由其它服务器自动接管。在大多数模式 下,集群中所有的计算机拥有一个共同的名称,集群内的任一系统上运行的服务 都可被所有的网络客户使用。采用集群系统通常是为了提高系统的稳定性和网络中心的数据处理能力及服务能力。 当前主流的集群方式包括以下几种: 1. 服务器主备集群方式 服务器主-备方式由一台服务器在正常运行状态提供对外服务,其它集群节点作为备份机,备份机在正常状态下不接受外部的应用请求,实时对生产机进行检测,当生产机停机时才会接管应用服务,因此设备利用率最高可达50%主备 方式集群如下图所示,节点2为正常提供服务的服务器,运行多个应用 (pkgA,pkgB..),节点1平时只监控节点2的状态,不对外提供服务,当节点2 出现故障时,节点1将把两个应用接管过来,并对外提供服务。 图表错误!文档中没有指定样式的文字。-1主备方式集群 2. 服务器互备份集群方式 多台服务器组成集群,每台服务器运行独立的应用,同时作为其它服务器的 备份机,当主应用中断,服务将被其它集群节点所接管,接管服务的节点将运行自身应用和
故障服务器的应用,这种方式各集群节点的硬件资源均可被应用于对外服务。互备方式集群如下图所示,节点1和节点2分别运行1个或多个不同的应用,但只对外提供本地的主应用,两个节点之间互相进行监控,集群中任何一个节点出现故障后,另一个节点把故障节点的主应用接管过来,所有应用服务由一台服务器完成。 图表错误!文档中没有指定样式的文字。-2互备份方式集群 这种方式的主要缺点在于: 由于需要重新启动数据库核心进程,无法保证数据库系统连续不间断地运行 在系统切换的过程中,客户端与服务器之间的数据库连接会中断,需要重新进行数 据库的连接和登录工作 由于数据库系统只能在一台服务器上运行,另一台服务器无法分担系统的负载,实 际上造成了客户投资的浪费。在有些系统中,为了解决双机负载分担的问题,将应 用系统人为分割为两个数据库系统,分别在两台服务器上运行。这种方式在一定程 度上解决了负载分担的问题,但给系统管理、统计分析等业务处理带来了很多额外 的复杂性 3. 服务器并行集群方式 集群有多台服务器构成,同时提供相同的应用,可以实现多台服务器之间的负载均衡, 提供大访问量的应用需求,如Web访问及数据库等应用,服务器并行集群方式一般由应用系 统自身(如OracleRAC中间件负载均衡等)或外部专用服务器负载均衡设备实现。 jL# R?i uat Hiti.iEMXff DLM珀心XM4子耳 vVLH Ctid TW
WIN2008+sqlserver2008+iscsi存储集群配置详细过程
WIN2008+SQLserver2008集群iscsi存储详细安装配置过程 YC 二〇一〇年二月
目录 一、系统结构 (3) 二、配置域成员和ISCSI存储连接 (4) 三、三、两台服务器功能和角色支持环境安装 (8) 四、w in2008 集群验证和配置 (9) 五、安装SQLServer2008 需要的Framework3.5 以上 (18) 六、六、安装SQLServer2008 集群(主节点) (19) 七、七、将备用节点加入SQLServer2008 集群中 (28) 八、客户端利用ODBC测试SQLServer2008 集群能否访问 (35)
近期实施过多个Windows2008+SQLServer2008 集群系统,根据记忆写下详细实施过程。供大家参考。 群集安装环境需要提前做好准备工作,搭建域环境,需要三台服务器,一台作为域控,另外两台为成员服务器,为两台成员服务器创建账户并分配权限,在DNS 服务器上做好名称和地址的映射关系。 设置网络连接,至少双网卡,分为内外网,外网优先级高。 设置好共享磁盘,需要添加三块磁盘,分别作为SQL 数据盘、仲裁盘和msdtc 资源盘。 一、系统结构 1、整体拓扑图如下: 2、Windows2003 storage server:做ISCSI 存储 iscsi 对外发布ip: 192.168.2.6 端口3260 划分
安装完成2 台数据库服务器的Windows2008 系统,添加对应驱动,分别更改主机名为Datasrv1 和 Datasrv2。 设置Public 网卡地址和DNS 解析服务器的IP 地址。
WAS集群部署方案及安装配置手册
W A S集群部署方案及安装 配置手册 Prepared on 24 November 2020
1. 部署方案参考 如上图所示,中间件平台主要包括两大部分: ●负载分发层 ?包括两台服务器,通过Heartbeat实现HA,提供浮动IP给客户 端,保证了系统不存在单点故障问题 ?负载分发软件采用IBM HTTP Server实现 ?通过IBM HTTP Server配置虚拟主机,实现对不同应用的请求进行 分发到不同的后台WAS中间件集群。 ●WAS中间件集群 ?包括两台4CPU(每CPU 4Core)服务,每个服务器上通过水平扩展可 以启动多个WAS服务器。 ?基于应用部署要求,为每个应用建立一个集群,逻辑上实现应用之 间的隔离。 ?每个集群可以根据应用的负载,动态分配WAS服务器实例数。如 HR应用访问量较大则分配4个WAS实例。
?但最小要保证一个集群至少包括2个WAS实现,并且这两个实例 分别在不同的物理服务器上,这样才能保证不出现单点故障。 ?部署管理器,部署在WAS Server1上。 2. WebSphere 7安装及配置 此安装配置说明仅供参考,还需要根据现场实现情况进行调整。 2.1.WAS安装 一、四台服务器拓朴结构 四台机器IP地址,名称与安装内容 主机名IP 安装软件(组件)
其中DM控制台管理用户admin,口令 两个web服务器的管理用户也是admin,口令 二、安装后验收 可打开应用服务器主机的控制管理台,管理用户admin,口令****** 服务器->集群下建有应用集群 服务器->应用服务器下建有两个WEB服务 节点共有五个,分别是一个控制节点(一个dmgr节点),两个受控节点(两个app 节点),两个非受控节点(两个web节点) 集群下各受控节点已同步,并启动服务;两个WEB服务已生成插件、传播插件并启动。 在DMGR控制管理台可直接控制两个WEB的启动与停止。 三、安装前系统检查 ?群集安装时,确认所有机子的日期要一致 ?确认磁盘空间足够 两个应用服务器的安装文件放在/was_install 两个WEB服务器的安装文件放在/http_install 安装目录都是安装于默认的/opt目录下
服务器双机热备方案
双机热备方案 双机热备针对的是服务器的临时故障所做的一种备份技术,通过双机热备,来避免长时间的服务中断,保证系统长期、可靠的服务。 1.集群技术 在了解双机热备之前,我们先了解什么是集群技术。 集群(Cluster)技术是指一组相互独立的计算机,利用高速通信网络组成一个计算机系统,每个群集节点(即集群中的每台计算机)都是运行其自己进程的一个独立服务器。这些进程可以彼此通信,对网络客户机来说就像是形成了一个单一系统,协同起来向用户提供应用程序、系统资源和数据,并以单一系统的模式加以管理。一个客户端(Client)与集群相互作用时,集群像是一个独立的服务器。计算机集群技术的出发点是为了提供更高的可用性、可管理性、可伸缩性的计算机系统。一个集群包含多台拥有共享数据存储空间的服务器,各服务器通过内部局域网相互通信。当一个节点发生故障时,它所运行的应用程序将由其他节点自动接管。 其中,只有两个节点的高可用集群又称为双机热备,即使用两台服务器互相备份。当一台服务器出现故障时,可由另一台服务器承担服务任务,从而在不需要人工干预的情况下,自动保证系统能持续对外提供服务。可见,双机热备是集群技术中最简单的一种。 2. 双机热备适用对象 一般邮件服务器是要长年累月工作的,且为了工作上需要,其邮件备份工作就绝对少不了。有些企业为了避免服务器故障产生数据丢失等现象,都会采用RAID 技术和数据备份技术。但是数据备份只能解决系统出现问题后的恢复;而RAID
技术,又只能解决硬盘的问题。我们知道,无论是硬件还是软件问题,都会造成邮件服务的中断,而RAID及数据备份技术恰恰就不能解决避免服务中断的问题。 要恢复服务器,再轻微的问题或者强悍的技术支持,服务器都要中断一段时间,对于一些需要随时实时在线的用户而言,丢失邮件就等于丢失金钱,损失可大可小,这类用户是很难忍受服务中断的。因此,就需要通过双机热备,来避免长时间的服务中断,保证系统长期、可靠的服务。 3. 实现方案 双机热备有两种实现模式,一种是基于共享的存储设备的方式,另一种是没有共享的存储设备的方式,一般称为纯软件方式。 1)基于共享的存储设备的方式 基于存储共享的双机热备是双机热备的最标准方案。对于这种方式,采用两台服务器(邮件系统同时运行在两台服务器上),使用共享的存储设备磁盘阵列(邮件系统的数据都存放在该磁盘阵列中)。两台服务器可以采用互备、主从、并行等不同的方式。在工作过程中,两台服务器将以一个虚拟的IP地址对外提供服务,依工作方式的不同,将服务请求发送给其中一台服务器承担。同时,服务器
负载均衡解决方案设计设计
一、用户需求 本案例公司中现有数量较多的服务器群: WEB网站服务器 4台 邮件服务器 2台 虚拟主机服务器 10台 应用服务器 2台 数据库 2台(双机+盘阵) 希望通过服务器负载均衡设备实现各服务器群的流量动态负载均衡,并互为冗余备份。并要求新系统应有一定的扩展性,如数据访问量继续增大,可再添加新的服务器加入负载均衡系统。 二、需求分析 我们对用户的需求可分如下几点分析和考虑: 1.新系统能动态分配各服务器之间的访问流量;同时能互为冗余,当其中 一台服务器发生故障时,其余服务器能即时替代工作,保证系统访问的 不中断; 2.新系统应能管理不同应用的带宽,如优先保证某些重要应用的带宽要 求,同时限定某些不必要应用的带宽,合理高效地利用现有资源;
3.新系统应能对高层应用提供安全保证,在路由器和防火墙基础上提供了 更进一步的防线; 4.新系统应具备较强的扩展性。 o容量上:如数据访问量继续增大,可再添加新的服务器加入系统; o应用上:如当数据访问量增大到防火墙成为瓶颈时,防火墙的动态负载均衡方案,又如针对链路提出新要求时关于Internet访问 链路的动态负载均衡方案等。 三、解决方案 梭子鱼安全负载均衡方案总体设计 采用服务器负载均衡设备提供本地的服务器群负载均衡和容错,适用于处在同一个局域网上的服务器群。服务器负载均衡设备带给我们的最主要功能是:
当一台服务器配置到不同的服务器群(Farm)上,就能同时提供多个不同的应用。可以对于每个服务器群设定一个IP地址,或者利用服务器负载均衡设备的多TCP端口配置特性,配置超级服务器群(SuperFarm),统一提供各种应用服务。
数据库服务器的部署
DATA服务器集群安装
ORACLE 10G For Window2003双机容错系统 安装概述 本次平台数据库的部署是利用Windows2003企业版自带的集群功能和ORACLE的FAIL SAFE 双机模块在两台HP的DL380 G4服务器上实现数据库的双机切换。由于Windows2003系统的集群安装在前面两台WEB应用服务器上已经做了很详细的说明,与此唯一不同的就是两台数据库服务器的名称分别为DATASER1和DATASER2。因此数据库的部署,我们的重点是安装数据库和部署FAIL SAFE软件。 一.前期需求: 操作系统:Windows 2003企业版 数据库:Oracle 10G 工作机:DATASER1 备份机:DATASER2 私有网络: DATASER1: 10.0.0.3 DATASER2: 10.0.0.4 公共网络: DATASER1: 10.14.8.13 DATASER2: 10.14.8.14 共享磁盘: Q,S: 数据库服务器集群地址:10.14.8.16 Oracle访问地址:10.14.8.17 Oracle services: 1) OracleoraEM10g_home1TNSlistener 2)OracleServiceCYZX
二.双机集群相关配置和结构图 DATASER1 ★DL380G4本身2个72GB硬盘做RAID0+1,安装WIN2003 SERVER.硬盘只有一个分区C:,光盘为D:★服务器集成端口1作为外部通讯网卡,IP地址:10.0.0.3 ★服务器集成端口2作为两台主机之间的心跳网卡,IP地址:10.14.8.13 ★服务器名:DATASER1 ★域名: ★管理员口令: administrator\qaz123 DATASER2 ★DL380G4本身2个72GB硬盘做RAID0+1,安装WIN2003 SERVER.硬盘只有一个分区C:,光盘为D:★服务器集成端口1作为外部通讯网卡,IP地址:10.0.0.4 ★服务器集成端口2作为两台主机之间的心跳网卡,IP地址:10.14.8.14 ★服务器名:DATASER2 ★域名: ★管理员口令: administrator\qaz123 MSA1000集群套件信息 ★MSA1000上3个300BG硬盘,做RAID5,逻辑盘符Q: S: ★Q:盘1000M作为集群的数据同步区, S:盘作为数据区 ★集群IP地址:10.14.8.16 ORACLE 10G信息 ★ORACLE名称: ★ORACEL口令: sys\sysman 群集虚拟信息 ★虚拟主机IP地址:10.14.8.17 ★群集资源组: oraclu 网络要求: ★唯一的 NetBIOS 群集名称。
两台服务器集群巧搭建
两台服务器集群巧搭建 服务器集群系统中,服务器不再分布在各处,而是集中在一起统一进行管理和维护。它保持了分布式客户机/服务器模式的开发性、可扩展性的优点,同时又具备了终端/主机模式的资源共享和集中易于管理的优点。 服务器集群系统中,服务器不再分布在各处,而是集中在一起统一进行管理和维护。它保持了分布式客户机/服务器模式的开发性、可扩展性的优点,同时又具备了终端/主机模式的资源共享和集中易于管理的优点。相对集中的集群系统,降低了系统管理的成本,而且还提供了和大型服务器系统相媲美的处理能力。 在传统的终端/主机的网络模式时代,终端功能简单,无需维护工作,在主机一端进行专门的管理与维护,具有资源共享、便于管理的特点。但是,主机造价昂贵,终端没有处理能力,限制了网络的规模化发展。之后的客户机/服务器模式推进了计算产业的标准化和开发化的发展,为系统提供了相当大的灵活性,但是随着分布系统规模的规模扩大,系统的维护和管理带来了巨大的开销。 面向Internet的服务型应用,需要高性能的硬件平台作为支持,将并行技术应用在服务器领域中,是计算机发展的必然趋势。并行处理技术在高性能计算领域中,高可用和高性能是集群服务器系统发展的两个重要方向。 集群的概念 集群英文名称是CLUSTER,是一组相互独立的、通过高速网络互联的计算机,它们构 成了一个组,并以单一系统的模式加以管理。一个客户与集群相互作用时,集群像是一个独立的服务器。集群配置是用于提高可用性和可缩放性。 和传统的高性能计算机技术相比,集群技术可以利用各档次的服务器作为节点,系统造价低,可以实现很高的运算速度,完成大运算量的计算,具有较高的响应能力,能够满足当今日益增长的信息服务的需求。 #P# 集群技术应用的需求 Internet用户数量呈几何级数增长和科学计算的复杂性要求计算机有更高的处理能力,而CPU的发展无法跟上不断增长的需求,于是我们面临以下问题: ●大规模计算如基因数据的分析、气象预报、石油勘探需要极高的计算性能。 ●应用规模的发展使单个服务器难以承担负载。 ●不断增长的需求需要硬件有灵活的可扩展性。 ●关键性的业务需要可靠的容错机制。 #P# IA集群系统(CLUSTER)的特点 ●由若干完整的计算机互联组成一个统一的计算机系统; ●可以采用现成的通用硬件设备或特殊应用的硬件设备,例如专用的通讯设备;