Keil复制中文注释出现乱码的解决办法
Keil uVosion4.7复制中文注释到记事本出现乱码 Hefei Fulaide Electronics Science&technology Co., Ltd. ------------------------------------------------------------------------------------------------------------------------------------------------------ 地址:安徽省、合肥市、肥东县、店埠镇,合肥市福来德电子科技有限公司
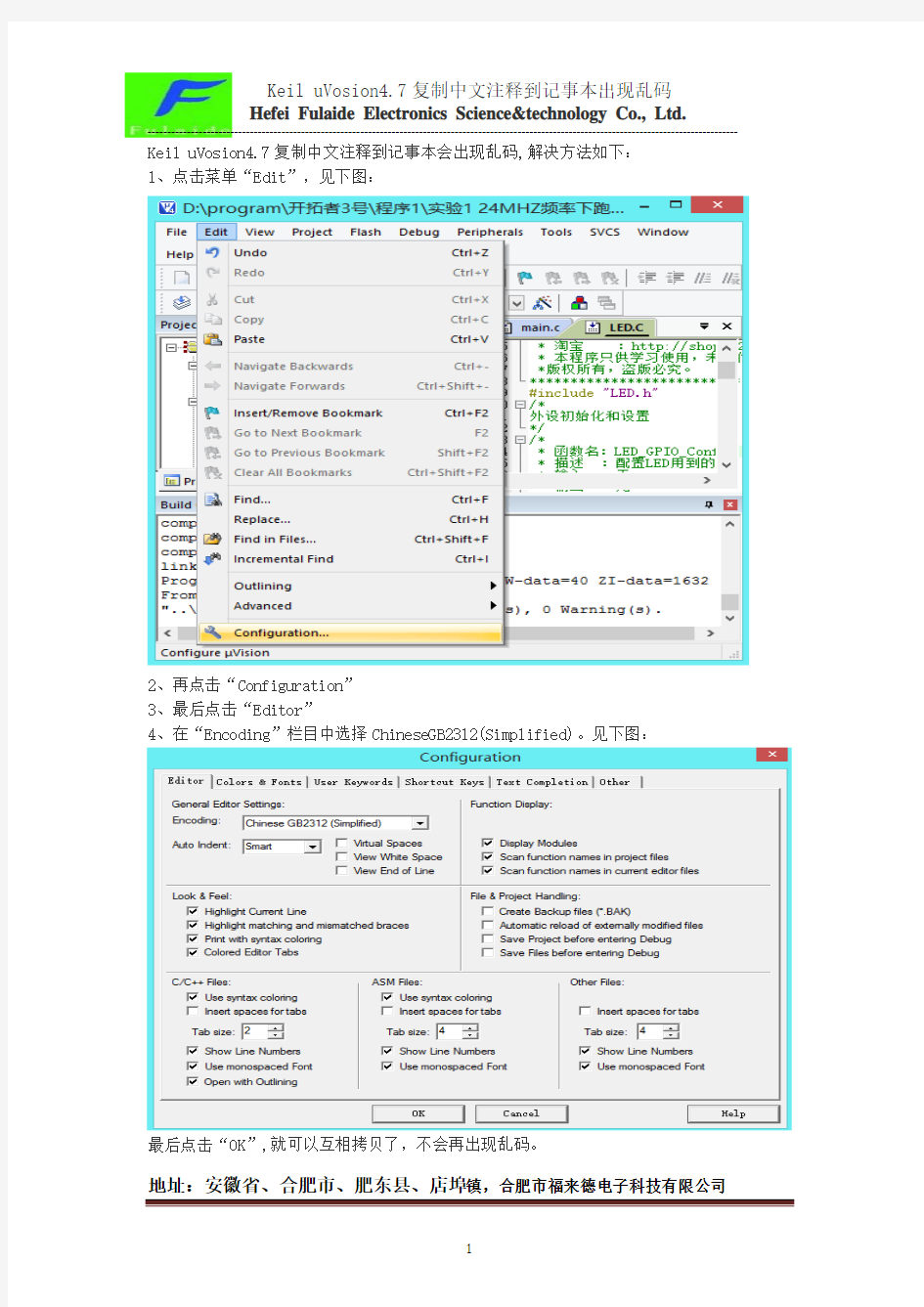
1 Keil uVosion4.7复制中文注释到记事本会出现乱码,解决方法如下:
1、点击菜单“Edit”,见下图:
2、再点击“Configuration”
3、最后点击“Editor”
4、在“Encoding”栏目中选择ChineseGB2312(Simplified)。见下图:
最后点击“OK”,就可以互相拷贝了,不会再出现乱码。
中文乱码解决大全
SSH开发过程中的中文问题汇总 作者:Rainisic来源:博客园发布时间:2012-01-11 14:26 阅读:50 次原文链接[收藏] 在使用SSH开发的过程中,我们经常会因为各种各样的中文乱码问题而苦恼。之前开发的过程中遇到过一些,但是都没有记录下来,这次,我就遇到的中文问题进行一个汇总,希望能够对大家有所帮助。 1. 平台环境参数 操作系统:Windows 7 旗舰版64位 JDK版本:JDK 1.6 / JDK 1.7 (此处由于JDK 7 发布不久,所以对两个版本进行测试) 开发环境:Eclipse Java EE Indigo 网站容器:Tomcat 7.0 开发框架: Struts 2.3.1.1-GA Spring 3.1.0-release Hibernate 4.0.0-Final / Hibernate 3.6.9-Final (此处由于Hibernate 4 final 刚刚发布不久,所以对两个版本进行测试) 2. 中文问题汇总 (1)HTML中未指定文件编码 问题描述:在HTML中未指定文件编码,在部分浏览器中将会出现中文乱码。 解决方案:在HTML的head标签中指定文档编码,代码如下(请根据DOCTYPE选择): // HTML 4.01 Transitional
// HTML 5 (2)表单提交使用GET方法 问题描述:在HTML form 中提交表单的时候使用method="get"导致中文乱码。 解决方案:form表单的method设置为post,代码如下:
(3)JSP文件中未指定文档编码类型 问题描述:在JSP文件中未指定JSP文档编码,在浏览器中会出现中文乱码。 解决方案:在JSP文件首部增加指定文档编码的代码,代码如下: <%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%> (4)文件编码不正确 问题描述:由于Java文件、JSP文件等文件编码不正确,导致中文乱码。 解决方案:设置文件的默认编码为UTF-8(如果需要使用其他编码,请确保上述两个编码格式与文件编码相同) 设置方法: 当前文件编码修改:该文件右键→Properties→Resource,右侧Text file encoding→Other →UTF-8 默认文件编码修改: 0. Windows→Preferences 打开Eclipse配置选项窗口。 1. General→Content Type,右侧Text 下面所需要的文件类型Default encoding设置为UTF-8解决keil不能设置字体和颜色的问题
很多朋友都在想,怎么让keil C51与ARM能够并存使用。有安装经验的朋友都知道,安好C51后再安ARm,C51不能正常工作;安好ARM后再安C51,ARM不能正常工作. 网上也有相关解决办法,不过不怎么样,要么不详细,要么就是复制粘贴。不多说看图片: 我想大家一定发现问题了,就是在c51的编译器等目录下面没有他的目标路径而arm有,所以他肯定会提示工具不匹配之类的问题。解决方法很简单,根据ARM的样子也写个路径就OK了, 第一:先安装C51(必须先安装C51,不能先安装ARM,否则会失败。) 第二:安装keil ARM(不能安装在同一个文件夹下)
我当前安装的是mdk arm4.53 第三:打开keil c51和keil arm 两个文件夹,分别找到tools.ini
分别打开两个“tools.ini”,将keil C51文件夹下的tools.ini文件中[C51]段复制到keil ARM中tools.ini文件的最后;将keil ARM文件夹下的tools.ini文件中[ARM]段复制到keil C51中tools.ini文件的最后: tools.ini -->keil ARM [UV2] ORGANIZATION="小川电子工作室" NAME="小川电子工作室", "小川电子工作室" EMAIL="paulhyde@https://www.wendangku.net/doc/4f10655169.html," ARMSEL=1 BOOK0=UV4\RELEASE_NOTES.HTM("uVision Release Notes",GEN) [ARM] PATH="D:\Keil ARM\ARM\" VERSION=4.50 PATH1="C:\Program Files\arm-none-eabi-gcc-4_6\" TOOLPREFIX=arm-none-eabi- CPUDLL0=SARM.DLL(TDRV0,TDRV5,TDRV6,TDRV10) # Drivers for ARM7/9 devices CPUDLL1=SARMCM3.DLL(TDRV1,TDRV2,TDRV3,TDRV4,TDRV5,TDRV7,TDRV8,TDR V9,TDRV11,TDRV12,TDRV13) # Drivers for Cortex-M devices CPUDLL2=SARMCR4.DLL(TDRV7) # Drivers for Cortex-R4 devices BOOK0=HLP\RELEASE_NOTES.HTM("Release Notes",GEN) BOOK1=HLP\ARMTOOLS.chm("Complete User's Guide Selection",C) BOOK2=HLP\RL_RELEASE_NOTES.HTM("RL-ARM Release Notes",GEN)
JSP中文乱码的产生原因及解决方案
JSP中文乱码的产生原因及解决方案 在JSP的开发过程中,经常出现中文乱码的问题,可能一直困扰着大家,现在把JSP 开发中遇到的中文乱码的问题及解决办法写出来供大家参考。首先需要了解一下Java中文问题的由来: Java的内核和class文件是基于unicode的,这使Java程序具有良好的跨平台性,但也带来了一些中文乱码问题的麻烦。原因主要有两方面,Java和JSP文件本身编译时产生的乱码问题和Java程序于其他媒介交互产生的乱码问题。首先Java(包括JSP)源文件中很可能包含有中文,而Java和JSP源文件的保存方式是基于字节流的,如果Java和JSP编译成class文件过程中,使用的编码方式与源文件的编码不一致,就会出现乱码。基于这种乱码,建议在Java文件中尽量不要写中文(注释部分不参与编译,写中文没关系),如果必须写的话,尽量手动带参数-ecoding GBK或-ecoding gb2312或-ecoding UTF-8编译;对于JSP,在文件头加上<%@ page contentType="text/html;charset=GBK"%>或 <%@ page contentType="text/html;charset=gb2312"%>基本上就能解决这类乱码问题。 下面是一些常见中文乱码问题的解决方法(下面例子中ecoding采用的是gb2312,也可设为ecoding GBK或ecoding UTF-8): 一、 JSP页面乱码 这种乱码问题比较简单,一般是页面编码不一致导致的乱码,一般新手容易出现这样的问题,具体分以下两种情况: 未指定使用字符集编码 下面的显示页面(display.jsp)就出现乱码:
乱码形成原因及消除方法大全 八
乱码形成原因及消除方法大全八 乱码形成原因及消除方法大全.txt生活,是用来经营的,而不是用来计较的。感情,是用来维系的,而不是用来考验的。爱人,是用来疼爱的,而不是用来伤害的。金钱,是用来享受的,而不是用来衡量的。谎言,是用来击破的,而不是用来装饰的。信任,是用来沉淀的,而不是用来挑战的。乱码形成原因及消除方法大全 2008-01-18 14:08乱码形成原因及消除方法大全当我们浏览网页、打开文档或邮件,运行软件时,经常会看到乱码,通常是由于源文件编码,Windows 不 能正确识别造成的的,也可能是其他原因。乱码给我们带来了太多的烦恼,为了帮助大家彻底摆脱乱码 ,下面我们就来探讨一下乱码的形成原因及其消除方法。 一、乱码有五种类型 常见的乱码,一般可以分成五种类型:第一类是文本/文档文件乱码,这一般是由于源文件编码,与
Windows使用的编码不通用造成的;第二类是网页乱码,形成原因与第一类乱码类似;第三类是Windows 系统界面乱码,即中文Windows的菜单、桌面、提示框等显示乱码,主要是Windows注册表中有关字体的 部分设置不当引起的;第四类是应用程序的界面乱码,即各种应用程序(包括游戏)本来显示中文的地 方出现乱码,形成原因比较复杂,有第二类的乱码原因,也可能是软件用到的中文链接库,被英文链接 库覆盖造成的;第五类是邮件乱码,形成原因也极其复杂。 二、如何消除应用程序的界面乱码? 目前有些软件发行了Unicode版本,这是一种通用的字符编码标准,涵盖了全球多种语言及古文和专 业符号,这种版本的软件运行在任何系统和语言上都不会乱码,如果是非Unicode编码的程序,就会有乱
Keil C编译器常见警告与错误信息的解决方法
1.Warning280:’i’:unreferenced local variable 说明局部变量i在函数中未作任何的存取操作 解决方法消除函数中i变量的宣告 2Warning206:’Music3’:missing function-prototype 说明Music3()函数未作宣告或未作外部宣告所以无法给其他函数调用 解决方法将叙述void Music3(void)写在程序的最前端作宣告如果是其他文件的函数则要写成extern void Music3(void),即作外部宣告 3Compling:C:\8051\MANN.C Error:318:can’t open file‘beep.h’ 说明在编译C:\8051\MANN.C程序过程中由于main.c用了指令#include“beep.h”,但却找不到所致 解决方法编写一个beep.h的包含档并存入到c:\8051的工作目录中 4Compling:C:\8051\LED.C Error237:’LedOn’:function already has a body 说明LedOn()函数名称重复定义即有两个以上一样的函数名称 解决方法修正其中的一个函数名称使得函数名称都是独立的 5***WARNING16:UNCALLED SEGMENT,IGNORED FOR OVERLAY PROCESS SEGMENT:?PR?_DELAYX1MS?DELAY 说明DelayX1ms()函数未被其它函数调用也会占用程序记忆体空间 解决方法去掉DelayX1ms()函数或利用条件编译#if…..#endif,可保留该函数并不编译 6***WARNING6:XDATA SPACE MEMORY OVERLAP FROM:0025H TO:0025H 说明外部资料ROM的0025H重复定义地址 解决方法外部资料ROM的定义如下 Pdata unsigned char XFR_ADC_at_0x25其中XFR_ADC变量的名称为0x25,请检查是否有其它的变量名称也是定义在0x25处并修正它 7WARNING206:’DelayX1ms’:missing function-prototype C:\8051\INPUT.C Error267:’DelayX1ms‘:requires ANSI-style prototype C:\8051\INPUT.C 说明程序中有调用DelayX1ms函数但该函数没定义即未编写程序内容或函数已定义但
解决jsp中文显示问题
解决: jsp页面中文显示问题 <%@ page pageEncoding=”gb2312″ %>,决定jsp页面编写时的编码。 <%@ page content_type=”text/html;charset=UTF-8″ %>,决定jsp页面显示在客户端浏览器的编码。 在解决这个问题的同时,我还发现了一篇至今为止我所见过的解决java中文问题最彻底的文章: 上篇:https://www.wendangku.net/doc/4f10655169.html,/pcedu/empolder/gj/java/0404/ 366404.html 下篇:https://www.wendangku.net/doc/4f10655169.html,/pcedu/empolder/gj/java/0405/ 368760.html 深入Java中文问题及最优解决方法 Abstract:本文深入分析了Java程序设计中Java编译器对java源文件和JVM对class类文件的编码/解码过程,通过此过程的解析透视出了Java编程中中文问题产生的根本原因,最后给出了建议的最优化的解决Java中文问题的方法。 1、中文问题的来源 计算机最初的操作系统支持的编码是单字节的字符编码,于是,在计算机中一切处理程序最初都是以单字节编码的英文为准进行处理。随着计算机的发展,为了适应世界其它民族的
语言(当然包括我们的汉字),人们提出了UNICODE编码,它采用双字节编码,兼容英文字符和其它民族的双字节字符编码,所以,目前,大多数国际性的软件内部均采用UNICODE编码,在软件运行时,它获得本地支持系统(多数时间是操作系统)默认支持的编码格式,然后再将软件内部的UNICODE转化为本地系统默认支持的格式显示出来。Java的JDK和JVM即是如此,我这里说的JDK是指国际版的JDK,我们大多数程序员使用的是国际化的JDK版本,以下所有的JDK均指国际化的JDK版本。我们的汉字是双字节编码语言,为了能让计算机处理中文,我们自己制定的gb2312、GBK、GBK2K等标准以适应计算机处理的需求。所以,大部分的操作系统为了适应我们处理中文的需求,均定制有中文操作系统,它们采用的是GBK,GB2312编码格式以正确显示我们的汉字。如:中文Win2K默认采用的是GBK编码显示,在中文WIN2k中保存文件时默认采用的保存文件的编码格式也是GBK 的,即,所有在中文WIN2K中保存的文件它的内部编码默认均采用GBK编码,注意:GBK是在GB2312基础上扩充来的。 由于Java语言内部采用UNICODE编码,所以在JAVA程序运行时,就存在着一个从UNICODE编码和对应的操作系统及浏览器支持的编码格式转换输入、输出的问题,这个转换过程有着一系列的步骤,如果其中任何一步出错,则显示出来的汉字就会出是乱码,这就是我们常见的JAVA中文问题。
cmd窗口显示中文乱码及无法输入中文解决方法
cmd窗口显示中文乱码及无法输入中文解决方法 (2009-05-09 19:13:12) 分类:软件应用 标签: it 中文显示为乱码 临时解决方案: 在 CMD 中运行 chcp 936。 永久解决方案: 打开不正常的 CMD 或命令提示符窗口后,单击窗口左上角的图标,选择弹出的菜单中的“默认值”,打开如下图的对话框。单击第一个“选项”选项卡,将默认的代码页改为 936 后重启 CMD。 附:
如果改了以后无法生效,窗口的“默认值”和“属性”没变,进入注册表,在 HKEY_CURRENT_USER 下找到 console 项下的 Console 以及其下可能有 的 %SystemRoot%_system32_cmd.exe(这个 %SystemRoot%_system32_cmd.exe 下有的 codepage 话就改,如果没有就不管它),codepage值改为 936(十进制)或 3a8(十六进制)。 936(十进制)/3a8(十六进制) 是简体中文的,如是其它语言,要改为对应的代码。然后再执行第二段中所述的操作。 还可能和 CMD 的默认值的“字体”设置有关。 在 CMD 的“默认值”和“属性”的“字体”选项卡中中确认设定的字体是可以显示中文字符的字体,并且确定字体文件没有被破坏。字体最好设置为默认的点阵字体。 还是不行,干脆把%SystemRoot%_system32_cmd.exe内容备份下,然后清空它。或是把以下内容保存为REG文件导入试试。 Windows Registry Editor Version 5.00 [HKEY_CURRENT_USER\Console\%SystemRoot%_system32_cmd.exe] "QuickEdit"=dword:00000800 "CodePage"=dword:000003a8 "WindowSize"=dword:001e005a "FontSize"=dword:000c0008 "FontFamily"=dword:00000030 "FontWeight"=dword:00000190 "FaceName"="Terminal" ============================================================= 无法输入中文 确认以下事项: 1.CMD 里中文字符可以正常显示(上文). 2.注册表中 HKEY_CURRENT_USER\Console 及 HKEY_CURRENT_USER\Console\%SystemRoot%_system32_cmd.exe] 下LoadConIme 的值为 1. 3.conime.exe 这个文件存在,没有受到破坏,并且正常运行.
win7系统常见的乱码问题解决方法
win7系统常见的乱码问题解决方法 win7系统乱码的问题,经常会碰到一些软件是简体中文的,可是在win7系统中却出来乱码的问题?400pc小编教你破解是哪些原因造成win7系统乱码。 近期,居住香港的姐姐也安装了Windows 7,不过,令她烦恼的是使用一些简体中文的软件出现了乱码。而这些软件都无法找到繁体版本,比如:迅雷,即使勉强安装好也无法轻松使用。难道香港用户就无法使用这些简体软件了吗?其实,Windows 7自身已经提供了完善的解决方案了。 一、Windows 7乱码问题来龙去脉 旅居香港的姐姐安装的是我提供的简体中文版本的Windows 7旗舰版,按理是可以顺利兼容简体软件的,然而问题就出在姐姐对默认的安装设置进行了修改。因为姐姐经常使用繁体软件,她将系统的“区域和语言”的“格式”、“位置”、“默认输入语言”、“非Unicode程序的语言”都设置成了更加顺手的香港繁体。 我们知道Unicode也可称为统一码,为每种语言的每个字符设置了统一且唯一的二进制编码,以满足跨语言、跨平台进行文本转换处理的要求,然而,还是有不少程序并不支持该编码,这时就有必要设置非Unicode程序使用的语言编码了。像迅雷这样的软件就支持简体中文编码,而不支持Unicode,当设置了香港繁体的非Unicode 就会出现乱码,同理,将非Unicode设置为简体后,很多不支持Unicode的繁体软件也会出现乱码。这个乱码问题难道是两难的吗?其实,我们使用Windows 7的语言包补丁安装功能就可以顺利解决。 二、巧妙解决Windows 7乱码 1.安装合适的语言包 首先,要能安装多种语言包的Windows 7只能是旗舰版或者企业版,接着我们就来解决这个问题吧。我们点击“开始-Windows Update”打开自动更新窗口。 在窗口中点击“34个可选更新”链接,在可以下载安装的语言包列表中选择“繁体中文语言包”,确定即可。 回到刚才的窗口点击“安装更新”按钮开始下载安装。 安装完语言包补丁需要重启。重启的过程需要配置补丁。
Android读取中文文件乱码解决方法
最近在做个MP3播放器,出现中文乱码问题,在网上找了很多解决办法,我整理了出现乱码的点和解决方案,拿出来和大家共享一下 1.读取中文文件乱码解决方法 package com.apj.conv; import java.io.BufferedInputStream; import java.io.BufferedReader; import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.IOException; import java.io.InputStreamReader; import android.app.Activity; import android.os.Bundle; import android.os.Environment; import android.widget.TextView; public class ConverActivity extends Activity { private TextV iew textview ; @Override public void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(https://www.wendangku.net/doc/4f10655169.html,yout.main); textview = (TextView) findView ById(R.id.lrctext); System.out.println("==============convertCodeAndGetText begin============== ") ; ///获得SDCard中文件的路径 String path = Environment.getExternalStorageDirectory().getAbsolutePath()+ File.separator ; String tochinese = convertCodeAndGetText(path+"a.txt"); System.out.println(tochinese); System.out.println("==============cconvertCodeAndGetText end=============="); textview.setText(tochinese); }
Keil编译常见问题
Error: L6200E Error: L6200E: Symbol temp multiply defined (by and .在编译的时候出现了这个问题,但是检查不出来,希望各位大侠帮帮忙 什么变量你给付了两次值 你看看是不是那个外部变量你又给赋值了 申明,其他.c文件对应的.h文件中用extern引用 error: #20 error: #20: identifier "TIM2_IRQChannel" is undefined 谁能说说,哪里错了 你的固件库里的库文件没有添加进工程里面,所以出现未定义的情况。 TIM2_IRQChannel指定时器2的中断通道没有定义,其实在固件库对这些参数都有定义,宏定义代替了一串寄存器地址数据。需要将.C文件添加到工程文件中 warning: #1-D (7): warning: #1-D: last line of file ends without a newline 当使用keil编译时,弹出这样的警告信息:(7): warning: #1-D: last line of file ends without a newline 这个是由于在main函数的“}”后,没有加回车。 只要在main函数的“}”后加回车键,此警告信息即可消除。 error:#65 ...(27):error:#65:expected a ";"
分数送你了,问题在你回答之前已经解决了,头文件里的结构体定义里的最后一行没有加";" 如NB menu{..}; error:#1113: 折腾了大半天,才搞明白一个空操作的指令 先在网上查有的说是__asm{NOP;},从里调用,可犄角旮旯全找了,也没看到什么的文件。如果直接用,就出现error:#1113:InlineassemblernotpermittedwhengeneratingThumbcode 最后搜索这条错误,知道是因为__asm("指令");这种语法是内联汇编(inlineassembly)的语法。而RMDK下,内联汇编仅支持ARM汇编语言,不支持Thumb或者Thumb-2汇编语言;但内嵌汇编器支持Thumb和Thumb-2。 __asm放到一个单独的子函数再被调用就没问题了 如下: __asmvoidnop(void) { NOP } 然后在之后的C代码中调用该函数: voidmain() { ... nop(); ...? }
关于Linux下中文乱码的完整解决方案
关于Linux下中文显示为乱码的完整解决方案Linux,作为一款免费的操作系统,相对于高额费用的Windows系列操作系统,有着更强的优势,所以,许多人也都开始学习Linux操作系统的知识。但是,由于Windows 系列操作系统还是当今社会的主流,所以,人们少不了在Windows和Linux系统之间进行文件的传输。 但是一个新问题出现了,那就是中文乱码问题,这个问题困扰着无数的Linux用户,尤其是Linux的初学者,对于这个问题相当的头疼。 主要问题如下: 1、ssh中,中文显示为乱码:在Wind ows 系统下,用ssh远程连接Linux系统,对于在Linux下显示正常的中文,在ssh中却显示为完全无法识别的乱码字符。 2、中文传输乱码:把Wind ows中的中文文件传输到Linux操作系统中,原本在Wind ows下显示正常的文件,到了Linux系统下,成了无法识别的乱码。 分析其原因,是因为Linux和Wind ows系统下,所用户的字符集不同,Linux系统使用的是Unicod e字符集,而Wind ows使用的是GB字符集。所以,在网上出现了两种解决方案: 方法一:使用Putty代替secure shell client(ssh):在Putty终端设置中,修改wind ow-〉Translation中的Received data assumed to be in which character set值为Linux 中的字符集UTF-8,再连接Linux,
发现这时,Linux中的中文可以正常显示了。 但是一个新问题出现了,把Wind ows中的文件上传了Linux 中,原本在Wind ows下显示正常的中文文件,现在却成了乱码。 所以,这个方法无法彻底解决乱码问题。 方法二:修改Linux默认字符集,把Linux的默认字符集修改为和Wind ows中的字符集一致的GB18030或GB2312,重启Linux系统后,再用ssh终端连接,这时,修改字符集后的中文文件都已经能正常显示,而且,从Wind ows中新上传的中文文件也能正常显示了。这个方法不错。 但是,Linux系统在安装时,产生的中文字符(中文文件夹名、中文文件名、中文文件)在新的字符集下,却又全都显示成了乱码。 有什么方法可以彻底解决乱码问题,使在Linux系统下,所有的中文字符都可以正常显示呢? 本人综合了网上的各种解决方案,经过多次实验,终于找到了一个比较完整的解决方案,步骤如下: 第一步:用英文安装Linux系统:在安装Linux系统时,采用默认的英文安装,而不要使用中文。 第二步:修改字符集:在Linux系统安装成功以后,修改系统的默认字符集,操作如下: 在Fedora Linux系统中,编辑/etc/sysconfig/i18n文件,修改LANG 值为zh_CN.GB2312或zh_CN.GB18030,保存退出。 在OpenSuSE Linux系统中,编辑/etc/sysconfig/language文件,
Keil5编译问题
cannot open source input file “core_cm4.h”解决方法 装了比MDK5.11A更高版本的MDK后,可能出现编译标准例程报如下错误: ..\SYSTEM\sys\stm32f4xx.h(470): error: #5: cannot open source input file "core_cm4.h": No such file or directory 实际出错是在stm32f4xx.h,如图1所示: 图1 找不到core_cm4.h路径. 该core_cm4.h文件在stm32f4xx.h里面被引用,实际上是ARM CMSIS的东西,路径在MDK 安装路径下,为: MDK安装目录\ARM\Pack\ARM\CMSIS\4.1.1\CMSIS\Include
一般来说,装了CMSIS支持包就应该可以找到才对,但是部分客户电脑无法找到,原因未知. 不过,我们可以通过手动制定路径的办法,解决这个问题. 添加方法:点击魔术棒-->C/C++选项卡-->Include Paths ,选择我们MDK安装目录,找到\ARM\Pack\ARM\CMSIS\4.1.1\CMSIS\Include,如图2所示: 图2 手动添加CMSIS头文件路径. 之后,多次点击确认,回到主界面. 再重新编译,即可解决问题. 方法二: 个人建议,当找到上述的路径之后,可以看到include目录,所以可以直接将当前的目录拷贝出来(不过要注意MDK版本),直接放到当前工程的目录下,通过魔术棒-?C++-?include
包含以下编译就OK,(以后对新工程的使用方便快捷(MDK版本没有发生变化的情况下)),具体的操作见下图: keil5 编译程序出现错误Error: L6411E: No compatible library exists with a definition of startup symbol __main Error: L6411E: No compatible library exists with a definition of startup symbol __main. 之前装过ADS,ADS与MDK冲突,依据网友提供的资料,最终的解决办法如下 在我的电脑点击属性>高级系统设置>高级>环境变量>在系统变量中>新建
网页中文乱码完美解决方案
网页中文乱码 既然后面charset设置为gb2312,那么你打开这个网页,然后另存,保存的时候记得把编码改成gb2312,不然的话charset就会误导浏览器,这样就会乱码了。 2.php编网页出现乱码,我把编码改成utf-8 前台显示正常了,但是有东西输入到数据库再提取出来还是不正常 3.apache+php+mysql 为何会出现乱码 我们在做PHP项目的时候,经常会遇到中文乱码的问题,有时候编码问题还导致MYSQL的报错。中文乱码总共有三个原因 1:APACHE服务器设置导致乱码 2:PHP,或者HTML页面编码导致中文乱码 3:MYSQL数据库的表以及字段编码导致中文乱码 我们分别从这三个部分来探究PHP程序设计中的编码问题 在这之前我们要了解一些基本理论: 1、文件编码 每个文件在保存的时候都可以选择以什么编码保存,例如用WINDOWS的记事本创建一个文件可以选择ANSI 以及UTF8等等编码。我们选择了什么编码该文件就以这种编码方式保存在硬盘上。读取该文件数据的时候也会指定一种编码来打开,如果指定的编码与文件保存的时候的编码不一样的话就会出现乱码 2、HTML的编码 在网页头部一般有这样一个 区域 这个的意思是让客户端知道,接下来输出的是html代码(text/html),并且以下输出的内容都将是utf-8编码的。如果我们用记事本创建一个HTML文件该文件包含 但是在保存的时候却以ANSI编码格式保存,那么我们用浏览器打开这个文件时,浏览器看见META 行的UTF8编码设置后就将文件以UTF8格式输出,而文件本来是ANSI编码,这样便出现了中文乱码。 一:APACHE服务器编码 在APACHE配置文件中有一行是编码的设置默认的是AddDefaultCharset ISO-8859-1,大部分人认为应该将这句改为AddDefaultCharset UTF-8 。而蜗牛认为这是误人子弟。这项配置是告诉APACHE服务器选用什么样的编码来输出WEB页面(这样做会忽略,HTML页面中的页面编码的设置EG:),如果我们建立一个GB2312的页面就会出现中文乱码。所以最好的方法是将AddDefaultCharset ISO-8859-1这一项注释掉#AddDefaultCharset 二:PHP编码问题 php最终生成的是文本文件,而他要从数据库中取出文本数据,还要把文本数据写到数据库中。由于MYSQL并不知道PHP发送给他的是什么编码的数据,所以需要客户端PHP告诉他存取的是什么编码的数据。然后MYSQL会自动将PHP传送来的数据转换成目标编码格式的
使用filter解决中文乱码问题
关键字: 使用filter解决中文乱码问题 一.在web.xml中配置 xml 代码
Java中文乱码问题产生原因分析
Java中文乱码问题产生原因分析 在计算机中,只有二进制的数据,不管数据是在内存中,还是在外部存储设备上。对于我们所看到的字符,也是以二进制数据的形式存在的。不同字符对应二进制数的规则,就是字符的编码。字符编码的集合称为字符集。 17.1.1 常用字符集 在早期的计算机系统中,使用的字符非常少,这些字符包括26个英文字母、数字符号和一些常用符号(包括控制符号),对这些字符进行编码,用1个字节就足够了(1个字节可以表示28=256种字符)。然而实际上,表示这些字符,只使用了1个字节的7位,这就是ASCII编码。
1.ASCII ASCII(American Standard Code for Information Interchange,美国信息互换标准代码),是基于常用的英文字符的一套电脑编码系统。每一个ASCII码与一个8位(bit)二进制数对应。其最高位是0,相应的十进制数是0~127。例如,数字字符“0”的编码用十进制数表示就是48。另有128个扩展的ASCII码,最高位都是1,由一些图形和画线符号组成。ASCII是现今最通用的单字节编码系统。 ASCII用一个字节来表示字符,最多能够表示256种字符。随着计算机的普及,许多国家都将本地的语言符号引入到计算机中,扩展了计算机中字符的范围,于是就出现了各种不同的字符集。 2.ISO8859-1 因为ASCII码中缺少£、ü和许多书写其他语言所需的字符,为此,可以通过指定128以后的字符来扩展ASCII码。国际标准组织(ISO)定义了几个不同的字符集,它们是在ASCII码基础上增加了其他语言和地区需要的字符。其中最常用的是ISO8859-1,通常叫做Latin-1。Latin-1包括了书写所有西方欧洲语言不可缺少的附加字符,其中0~127的字符与ASCII码相同。ISO 8859另外定义了14个适用于不同文字的字符集(8859-2到8859-15)。这些字符集共享0~127的ASCII码,只是每个字符集都包含了128~255的其他字符。 3.GB2312和GBK GB2312是中华人民共和国国家标准汉字信息交换用编码,全称《信息交换用汉字编码字符集-基本集》,标准号为GB2312-80,是一个由中华人民共和国国家标准总局发布的关于简化汉字的编码,通行于中国大陆和新加坡,简称国标码。 因为中文字符数量较多,所以采用两个字节来表示一个字符,分别称为高位和低位。为了和ASCII码有所区别,中文字符的每一个字节的最高位都用1来表示。GB2312字符集是几乎所有的中文系统和国际化的软件都支持的中文字符集,也是最基本的中文字符集。它包含了大部分常用的一、二级汉字和9区的符号,其编码范围是高位0xa1-0xfe,低位也是0xa1-0xfe,汉字从0xb0a1开始,结束于0xf 7fe。 为了对更多的字符和符号进行编码,由前电子部科技质量司和国家技术监督局标准化司于1995年12月颁布了GBK(K是“扩展”的汉语拼音第一个字母)编码规范,在新的编码系统里,除了完全兼容GB2312外,还对繁体中文、一些不常用的汉字和许多符号进行了编码。它也是现阶段Windows和其他一些中文操作系统的默认字符集,但并不是所有的国际化软件都支持该字符集。不过要注意的是GBK不是国家标准,它只是规范。GBK字符集包含了20 902个汉字,其编码范围是0x8140-0xfefe。 每个国家(或区域)都规定了计算机信息交换用的字符编码集,这就造成了交流上的困难。想像一下,你发送一封中文邮件给一位远在西班牙的朋友,当邮件通过网络发送出去的时候,你所书写的中文字符会按照本地的字符集GBK转换为二进制编码数据,然后发送出去。当你的朋友接收到邮件(二进制数据)后,查看信件时,会按照他所用系统的字符集,将二进制编码数据解码为字符,然而由于两种字符集之间编码的规则不同,导致转换出现乱码。这是因为,在不同的字符集之间,同样的数字可能对应了不同的符号,也可能在另一种字符集中,该数字没有对应符号。 为了解决上述问题,统一全世界的字符编码,由Unicode协会1制定并发布了Unicode编码。 4.Unicode Unicode(统一的字符编码标准集)使用0~65535的双字节无符号数对每一个字符进行编码。它不仅包含来自英语和其他西欧国家字母表中的常见字母和符号,也包含来自古斯拉夫语、希腊语、希伯来语、阿拉伯语和梵语的字母表。另外还包含汉语和日语的象形汉字和韩国的Hangul音节表。 目前已经定义了40000多个不同的Unicode字符,剩余25000个空缺留给将来扩展使用。其中大约20 1Unicode协会是由IBM、微软、Adobe、SUN、加州大学伯克利分校等公司和组织所组成的非营利性组织。
url中文乱码解决大全
使用tomcat 时,相信大家都回遇到中文乱码的问题,具体表现为通过表单取得的中文数据为乱码。 一、初级解决方法 通过一番检索后,许多人采用了如下办法,首先对取得字符串按照 iso8859-1 进行解码转换,然后再按照gb2312 进行编码,最后得到正确的内容。示例代码如下: http://xxx.do?ptname='我是中国人' String strPtname = request.getParameter("ptname"); strPtname = new String(strPtname.getBytes("ISO-8859-1"), "UTF-8"); String para = new String( request.getParameter("para").getBytes("iso8859-1"), "gb2312"); 具体的原因是因为美国人在写tomcat 时默认使用iso8859-1 进行编码造成的。 然而,在我们的servlet 和jsp 页面中有大量的参数需要进行传递,这样转换的话会带来大量的转换代码,非常不便。 二、入门级解决方法 后来,大家开始写一个过滤器,在取得客户端传过来的参数之前,通过过滤器首先将取得的参数编码设定为gb2312 ,然后就可以直接使用getParameter 取得正确的参数了。这个过滤器在tomcat 的示例代码 jsp-examples 中有详细的使用示例, 其中过滤器在web.xml 中的设定如下,示例中使用的是日文的编码,我们只要修改为gb2312 即可
KEIL常见警告与错误的解决办法.doc
KEIL常见警告与错误的解决办法 1. Warning 280:?i?:unreferenced local variable 说明局部变量i 在函数中未作任何的存取操作 解决方法消除函数中i 变量的宣告 2.Warning 206:?Music3?:missing function-prototype 说明Music3( )函数未作宣告或未作外部宣告所以无法给其他函数调用 解决方法将叙述void Music3(void)写在程序的最前端作宣告如果是其他文件的函数则要写成extern void Music3(void),即作外部宣告3. Compling :C:\8051\MANN.C Error:318:can?t open file …beep.h? 说明在编译C:\8051\MANN.C 程序过程中由于main.c用了指令 #include “beep.h”,但却找不到所致 解决方法:编写一个beep.h的包含档并存入到c:\8051 的工作目录中 4. Compling:C:\8051\LED.C Error 237:?LedOn?:function already has a body 说明LedOn( )函数名称重复定义即有两个以上一样的函数名称 解决方法:修正其中的一个函数名称使得函数名称都是独立的 5. WARNING 16:UNCALLED SEGMENT,IGNORED FOR OVERLAY PROCESS
SEGMENT: ?PR?_DELAYX1MS?DELAY 说明DelayX1ms( )函数未被其它函数调用也会占用程序记忆体空间解决方法:去掉DelayX1ms( )函数或利用条件编译#if …..#endif,可保留该函数并不编 译 6. WARNING 6 :XDATA SPACE MEMORY OVERLAP FROM : 0025H TO: 0025H 说明外部资料ROM 的0025H 重复定义地址 解决方法:外部资料ROM 的定义如下 Pdata unsigned char XFR_ADC _at_0x25 其中XFR_ADC 变量的名称为0x25,请检查是否有其它的变量名称也是定义在0x25 处并修正它 7. WARNING 206:?DelayX1ms?: missing function-prototype C:\8051\INPUT.C Error 267 :?DelayX1ms …:requires ANSI-style prototype C:\8051\INPUT.C 说明程序中有调用DelayX1ms 函数但该函数没定义即未编写程序内容或函数已定义但未作宣告 解决方法:编写DelayX1ms 的内容编写完后也要作宣告或作外部宣告可在delay.h的包含档宣告成外部以便其它函数调用 8. WARNING 1:UNRESOLVED EXTERNAL SYMBOL
- Keil编译常见问题
- Keil编译常见问题
- keil的光标及显示问题解决
- Keil C 编译器常见警告与错误信息的解决方法
- keil常见错误及解决办法
- keil软件编译常见错误解释总结和中文翻译
- keil常见警告处理大全(比较全)
- KEIL软件错误代码及错误信息
- Keil5编译问题
- Keil 51常用见警告及解决方法
- Keil复制中文注释出现乱码的解决办法
- keil编译器常见错误及解决方式
- keil5中文乱码的解决
- Keil C编译器常见警告与错误信息的解决方法
- Keil编译与下载设置及常见问题解决方案
- KEIL常见警告与错误的解决办法.doc
- KEIL 中 warning解决方法
- keil警告消除
- Keil C编译器常见警告与错误信息的解决办法
- Keil编译常见问题