世毕盟战绩;斩获 Yale 生物统计 PhD 全奖 OFFER

祝贺来自北大数院概统系学员斩获 Yale 生物统计PhD 全奖 OFFER !
2016-12-24世毕盟教育
今日捷报
祝贺来自北大数院概统系学员
斩获
2017 FALL
Yale 生物统计 PhD
全奖 OFFER !
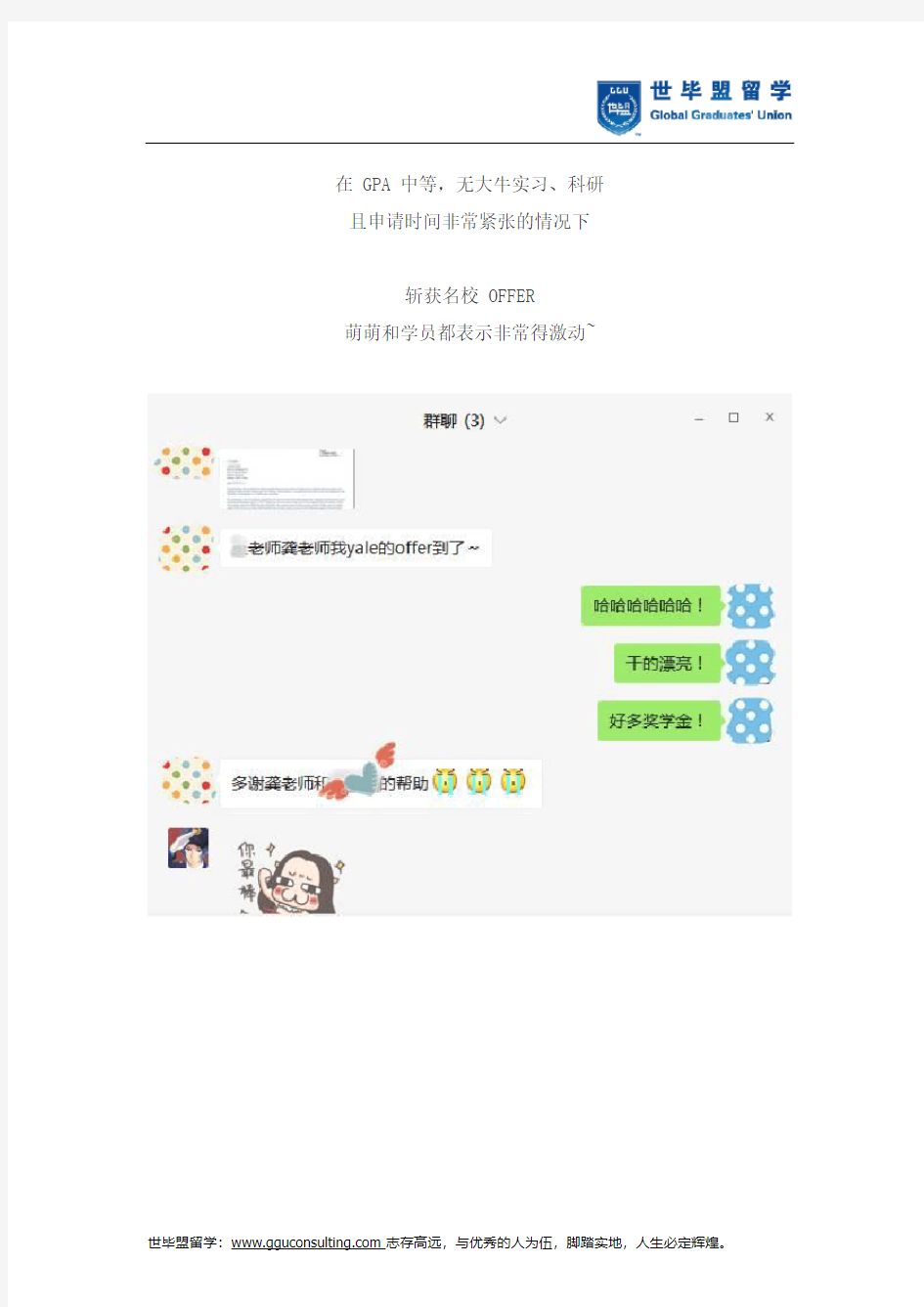
在 GPA 中等,无大牛实习、科研且申请时间非常紧张的情况下
斩获名校 OFFER
萌萌和学员都表示非常得激动~
(摘自学员邮件原文)
我是GGU学员,来自北京大学数学科学学院,申请的方向主要是生物统计博士项目。这封信主要是想分享一下我在申请文书修改中的感受,表达对Mentor龚老师、培训师以及GNET(GGU Native Expert Team)的感谢。
先说我的培训师,他是我在GGU互相交流最多的人了。在我开始写第一稿文书之前,老师就认真地帮我制定文书的框架结构,使我对我的文书内容有了最初的
idea。万事开头难,如果没有老师最初的文书指导,我想我的文书不会完成的这么顺利。
接下来是文书修改环节。培训师为我和我的mentor龚老师安排了一次meeting。我的第一版文书有1500字之多,我当时也知道自己的内容太冗余,但是我的疑惑是我也不知道哪里应该删哪里应该留。龚老师在短短的时间内就将我文书的结构梳理的非常清楚,并给出了一个将我的科研经历,研究兴趣和最终选择无缝衔接的逻辑结构,真正做到了每句话都有理有据,帮我说出了一个动人有深度的个人陈述。按照龚老师的逻辑修改后,我的文书只剩下1000字左右了。
GNET高效的服务也让我非常感动。由于之前有些耽搁,文书被我一直拖到ddl 前不到一周。在按照龚老师的建议修改完成后,我离申请截止日就还剩两天了,但是我的语言还需要润色。我在当天上午向龚老师提出了加急,结果当天晚上就收到了反馈,试问还有哪个留学机构能做到?收到的润色后的文书虽然大体意思还是我原来的意思,但关键是语言非常地道,细节注意的非常好,让人读起来非常舒服。
最终我居然在申请截止日前提交了七个项目的申请。我的文书从初稿完成到终稿敲定一共用了三天。这种事情我认为只有GGU可以办到。而且在网申提交时,培训师也是全程护送,一条一条帮我对,十分认真负责。让我的网申提交的非常踏实。
GGU高效的团队在本次申请中不仅让我的文书增色许多,更帮我赢得了许多时间,从而在如此紧张的情况下也能条理应对。再次向大家的认真、负责、耐心、专业表示感谢!
Yale University
耶鲁大学(Yale University), 简称耶鲁(Yale), 坐落于美国康涅狄格州纽黑文市,是美国历史上建立的第三所大学。耶鲁大学是美国东北部老牌名校联盟“常青藤联盟(Ivy League)”的成员,也是八所常春藤盟校中最重视本科教育的大学之一。
作为美国最具影响力的私立大学之一,耶鲁大学其本科学院与哈佛大学、普林斯顿大学本科生院齐名,历年来共同角逐美国大学本科生院美国前三名的位置,位列2016-17年US News美国大学本科排名第3。。
<世毕盟留学>
来自麻省理工学院、斯坦福大学、芝加哥大学、哈佛大学、清华大学、北京大学的学子共同创建, 定位于美英名校申请的留学咨询机构和个人发展的平台。
<成功案例>
2017 Fall部分申请结果:Princeton 23例,Harvard 44例,MIT 48例,Stanford 45例,Caltech 13例,Berkeley 42例,CMU 50+例....
史上最全专业介绍系列——MIS-专业(世毕盟留学)
史上最全专业介绍系列——MIS-专业(世毕盟留学)
史上最全专业介绍系列——MIS 专业 一、MIS 专业开设情况 1、总体情况 MIS 全称是Management Information System,管理信息系统。是一个以人为主导,利用计算机硬件、软件、网络通信设备以及其他办公设备,进行信息的收集、传输、加工、储存、更新和维护,以企业战略竞优、提高效益和效率为目的,支持企业的高层决策、中层控制、基层运作的集成化的人机系统。管理信息系统由决策支持系统(DSS)、工业控制系统(CCS)、办公自动化系统(OA)以及数据库、模型库、方法库、知识库和与上级机关及外界交换信息的接口组成。总的来说,MIS 就是通过计算机技术提高企业的管理水平和经济效益。 MIS 是集计算机技术与商管类课程于一身的新兴专业。一般分配在商学院之下,部分学校的管理学院,信息学院,计算机学院也有开设相关专业。由于MIS 专业的自身属性,因此开设课程中,不但包括计算机课程,例如语言编程,数据库,网络,信息安全等,而且也包括例如会计,电子商务,商务运营,营销等商务类课程。对于先修课,学校通常要求申请者掌握一定的计算机技术,进修过如网络编程、数据库、统计、会计、微积分等科目。但先修课不是每间学校必须的。 MIS 大体上分成两个方向,一个是偏向商科管理的方向,另一个是偏向技术的方向,分别在商学院和工学院下面。 商学院之下的MIS 偏向于计算机技术结合经济管理两方面,主要有两个方向,一个是MS in MIS,此方向适合一般应届毕业生申请,如Rochester;另一个是MBA-MIS,属于MBA 的分支之一,对工作经验的要求十分高,录取者平均工作经验 3 到 5 年不等,适合工作经验丰富的人申请;
生物统计学期末考试题
生物统计学期末考试题 一名词解释(每题2分,共10分) 1.生物统计学期末考试题 2.样本:从总体中抽出的若干个体所构成的集合称为样本 3.方差:用样本容量n来除离均差平方和,得到的平方和,称为方差 4.标准差:方差的平方根就是标准差 5.标准误:即样本均数的标准差,是描述均数抽样分布的离散程度及衡量均数抽样误差大小的尺度, 反映的是样本均数之间的变异。 6.变异系数:将样本标准差除以样本平均数,得出的百分比就是变异系数 7.抽样:通常按相等的时间间隔对信号抽取样值的过程。 8.总体参数:所谓总体参数是指总体中对某变量的概括性描述。 9.样本统计量:样本统计量的概念很宽泛(譬如样本均值、样本中位数、样本方差等等),到现在 为止,不是所有的样本统计量和总体分布的关系都能被确认,只是常见的一些统计量和总体分布之间 的关系已经被证明了。 10.正态分布:若随机变量X服从一个数学期望为μ、标准方差为σ2的高斯分布, 正态分布又名 高斯分布 11.假设测验:又称显著性检验,就是根据总体的理论分布和小概率原理,对未知或不完全知道的总 体提出两种彼此对立的假设,然后由样本的实际结果,经过一定的计算,做出在一定概率意义上应该 接受的那种假设的推断。 12.方差分析:又称“变异数分析”或“F检验”,用于两个及两个以上样本均数差别的显著性检验。 13.小概率原理:一个事件如果发生的概率很小的话,那么它在一次试验中是几乎不可能发生的,但 在多次重复试验中几乎是必然发生的,数学上称之小概率原理。 15.决定系数:决定系数定义为相关系数r的平方 16.随机误差:在实际相同条件下,多次测量同一量值时,其绝对值和符号无法预计的测量误差。 17.系统误差:它是在一定的测量条件下,对同一个被测尺寸进行多次重复测量时,误差值的大小和 符号(正值或负值)保持不变;或者在条件变化时,按一定规律变化的误差 二. 判断题(每题2分,共10分) 1. 在正态分布N(μ ;σ)中,如果σ相等而μ不等,则曲线平移, ( ) 2. 如果两个玉米品种的植株高度的平均数相同,我们可以认为这两个玉米品种是来自同一总体() 3. 当我们说两个处理平均数有显著差异时,则我们有99%的把握肯定它们来自不同总体. 4小概率原理是指小概率事件在一次试验中可以认为不可能发生() 5 激素处理水稻种子具有增产效应,现在在5个试验区内种植经过高、中、低三种剂量的激素处理的水稻种此试验称为三处理五重复试验() 6.系统误差是不可避免的,并且可以用来计算试验精度。() 7.精确度就是指观察值与真值之间的差异。() 8. 实验设计的三个基本原则是重复、随机、局部控制。() 9. 正交试验设计就是从全部组合的处理中随机选取部分组合进行试验。() 10.如果回归方程Y=3+1.5X的R2=0.64,则表明Y的总变异80%是X造成。() 三. 简答题(每题5分共20分) 1. 完全随机试验设计与随机区组试验设计有什么不同? 2. 什么是小概率原理?在统计推断中有何 作用? 3. 什么是多重比较中的FISHER氏保护测验?4. 样本的方差计算中,为什么要离均差平方和 除以n-1而不是除以n? 5. 如果两个变量X和Y的相关系数小于0.5,是否它们就没有显著相关性? 6. 单尾测验与双尾测验有何异同?
生物统计学重要知识点
生物统计学重要知识点 (说明:下列知识点为考试内容,没涉及的不需要复习。注意加粗的部分为重中之重,一定要弄懂。大家要进行有条理性的复习,望大家考出好成绩!) 第一章概论(容易出填空题和名词解释) 1、生物统计学的目的、内容、作用及三个发展阶段 2、生物统计学的基本特点 3、会解释总体、个体、样本、样本容量、变量、参数、统计数、效应和互作 4、会区分误差(随机误差和系统误差)与错误以及产生的原因 5、会区分准确度和精确度 第二章试验资料的整理与特征数的计算(容易出填空和名词解释) 1、随机抽样必须满足的两个条件 2、能看懂次数分布表和次数分布图,会计算全距、组数、组距、组限和组中值 3、会求平均数(算数、加权和几何)、中位数、众数,算术平均数的重要特性 4、会求极差、方差、标准差和变异系数,理解标准差的性质 第三章概率与概率分布(选择、填空和计算) 1、理解事件、频率及概率,事件的相互关系,加法定理和乘法定理的运用 2、概率密度函数曲线的特点和大数定律 3、二项分布、泊松分布和正态分布的概率函数和标准分布图像特征,会计算概率值 4、理解分位数的概念,弄清什么时候用单尾,什么时候用双尾 5、样本平均数差数的分布 第四章统计推断(计算) 1、无效假设和备择假设、显著水平、双尾检验和单尾检验、假设检验的两类错误,会根据 小概率原理做出是否接受无效假设的判断 2、总体方差已知和未知情况下如何进行U检验 3、一个样本平均数的t检验(例4.5) 成组数据平均数比较的t检验(例4.6和4.7) 4、一个样本频率的假设检验(例4.11),知道连续性矫正 5、参数的区间估计(置信区间)和点估计
生物统计学试题及答案
生物统计学考试 一.判断题(每题2分,共10分) √1. 分组时,组距和组数成反比。 ×2. 粮食总产量属于离散型数据。 ×3. 样本标准差的数学期望是总体标准差。 ×4. F分布的概率密度曲线是对称曲线。 √5. 在配对数据资料用t检验比较时,若对数n=13,则查t表的自由度为12。 二. 选择题(每题3分,共15分) 6.x~N(1,9),x1,x2,…,x9是X的样本,则有() x N(0,1)B.11 - x ~N(0,1)C.91 - x ~N(0,1)D.以上答案均不正确 7. 假定我国和美国的居民年龄的方差相同。现在各自用重复抽样方法抽取本国人口的1%计 算平均年龄,则平均年龄的标准误() A.两者相等 B.前者比后者大 D.不能确定大小 8. 设容量为16人的简单随机样本,平均完成工作需时13分钟。已知总体标准差为3分钟。 若想对完成工作所需时间总体构造一个90%置信区间,则() u值 B.应用t分布表查出t值 C.应用卡方分布表查出卡方值 D.应用F分布表查出F值 9. 1-α是() A.置信限 B.置信区间 C.置信距 10. 如检验k (k=3)个样本方差s i2 (i=1,2,3)是否来源于方差相等的总体,这种检验在统计上称为 ( )。 B. t检验 C. F检验 D. u检验 三. 填空题(每题3分,共15分) 11. 12. 13. 已知F分布的上侧临界值F0.05(1,60)=4.00,则左尾概率为0.05,自由度为(60,1) 的F 14. 15.已知随机变量x服从N (8,4),P(x < 4.71)(填数字) 四.综合分析题(共60分)
贵州大学《生物统计学》考试试卷(含答案)
贵州大学《生物统计学》考试试卷(含答案) 一 单项选择题(每题3分,共21分) 1.在假设检验中,显著性水平α的意义是___C___。 A. 原假设0H 成立,经检验不能拒绝的概率 B. 原假设0H 不成立,经检验不能拒绝的概率 C. 原假设0H 成立,经检验被拒绝的概率 D. 原假设0H 不成立,经检验被拒绝的概率 2.设123,,X X X 是总体2( , )N μσ的样本,μ已知,2 σ未知,则下面不是统计量的是__C___。 A. 123X X X +- B. 4 1 i i X μ=-∑ C. 2 1X σ+ D. 4 21 i i X =∑ 3.设随机变量~(0,1)X N ,X 的分布函数为()x Φ,则( 2)P X >的值为___A____。 A. ()212-Φ???? B. ()221Φ- C. ()22-Φ D. ()122-Φ 4.比较身高和体重两组数据变异程度的大小应采用__D___。 A .样本平均数 B. 样本方差 C. 样本标准差 D. 变异系数 5.设总体服从),(2 σμN ,其中μ未知,当检验0H :220σσ=,A H :220σσ≠时,应选择统计量___B_____。 A. 2 (1)n S σ- B. 2 2 (1)n S σ- X X 6.单侧检验比双侧检验的效率高的原因是___B_____。 A .单侧检验只检验一侧 B .单侧检验利用了另一侧是不可能的这一已知条件 C .单侧检验计算工作量比双侧检验小一半 D. 在同条件下双侧检验所需的样本容量比单侧检验高一倍 7.假设每升饮水中的大肠杆菌数服从参数为μ的泊松分布,则每升饮水中有3个大肠杆菌的概率是____D____。 A.63e μ μ- B.36e μμ- C.36e μ μ- D. 316 e μμ-
生物统计学第四版知识点总结
一、田间试验的特点 1、田间试验具有严格的地区性和季节性,试验周期长。 2、田间试验普遍存在试验误差 3、研究的对象和材料是农作物,以农作物生长发育的反应作为试验指标研 究其生长发育规律、各项栽培技术或栽培条件的效果。 二、田间试验的基本要求 结果重演性、结果可靠性、条件先进代表性、目的明确性 三、单因素试验的处理数就是该因素的水平数。 四、例如:甲、乙、丙三品种与高、中、低三种施肥量的两因素试验处理组 合数是? 3因素3水平的处理组合数是? 多因素试验的处理数是各因素不同水平数的所有组合。 五、如进行一个喷施叶面肥的试验,如果设置两个叶面肥浓度,对照应为 喷施等量清水。 六、简单效应的计算 N 的简单效应为40-30=10 在N1水平下,P2与P1的简单效应为38-30=8;在N2水平下,P2与P1的简单效应为54-40=14。 七、平均效应的计算 P的主效(8+14)/2=11; N的主效(10+16)/2=13; 八、互作的计算 N与P的互作为(16-10)/2=3或(14-8)/2=3 九、田间试验误差可分为系统误差和随机误差两种。(1、系统误差影响试 验的准确性,随机误差影响试验的精确性。2、准确度受系统误差影 响,也受随机误差影响;精确度受随机误差影响。3、若消除系统误 差,则精确度=准确度。) 十、小区面积扩大,误差降低,但扩大到一定程度,误差降低就不明显了。 适当的时候可以考虑增加重复次数来降低误差。小区面积一般在 6-60m2,而示范小区面积不小于330m2 。 十一、通常情况下,狭长小区误差比方形小区误差小。 小区的长边必须与肥力梯度方向平行,即与肥力变化最大的方向平行。一般小区长宽比为3-10:1,甚至达20:1 十二、何时采用方形小区?(1)肥水试验;(2)边际效应值得重视的试验。 十三、一般小区面积较小的试验,重复次数可相应增多,可设3-6次重复; 小区面积较大的试验可设2-4次重复。 十四、将对照或早熟品种种在试验田四周,一般4行以上。目的?(目的是防止外来因素破坏及边际效应的影响。) 十五、算术平均数的主要特征 ?1、样本各观测值与平均数之差的和为零,即离均差之和为0。 2、离均差的平方和最小。 十六、【例3·1】在1、2、3、…、20这20个数字中随机抽取1个,求下列随机事件的概率。 (1)A=“抽得1个数字≤4”;
世毕盟留学申请经验分享:从浙大国关到JHU SAIS
Offer: Johns Hopkins University SAIS MA in International Relations, Chicago University MPP, George Washington University MA in Asian Studies, UC San Diego MA in Public and International AffairsReject: Harvard University MPPWaitlist: Columbia University MPA 一.个人背景 GPA: 3.86/4.00,本科国关TOEFL: 109 (口语26)GRE: 165+170+4.0海外交换与海外志愿者各一实习:国际组织全职实习2个Research:若干,较水 二.选校选专业在选专业的时候,我曾经对去学这几年渐渐火起来的MPP还 是继续学国关有过纠结。无论是去JHU SAIS 还是去Chicago MPP,在毕业后找工作上是有一定程度的相似的——咨询、国际组织、NGO、金融、private sector、继续深造等等都有——但是学的东西却有很多不同。在浏览各学校官网、向学长学姐请教之后,我渐渐对这两个专业和各个学校有了更多的认识。 我很快确定下来我的dream school:JHU School of International Studies。在申请的初始阶段,学校官网、学长学姐、寄托gradcafe等网站、linkedin 以及世毕盟都是很好的信息来源。建议大家在了解清楚学校和专业情况的基础 上再开始申请,这样既不容易后悔,也好做到有的放矢。
生物统计学复习重点137030032
主要统计符号注解
编号 1 2 3 4 5 6 7 8 9 11 12 13 符号 注解 希腊字母符号 统计检验的显著水平,一般 α 取 0.05 或 0.01 总体标准差。用拉丁字母 S 表示样本标准差 总体方差。用拉丁字母 S2 表示样本方差(均方) 样本平均数抽样总体方差 标准误 (样本平均数抽样总体的标准差, 表示平均数抽样误差的大小) S x 。 为标本标准误,是平均数抽样误差的估计值 总体平均数。用拉丁字母 x 表示样本平均数 卡平方值 经连续性矫正的卡平方值 自由度 df 为显著水平为 α 时的卡平方临界值 随机误差;重复内分组设计的参试材料误差 线性模型中的处理效应 表示从第 1 个观测值 xi 累加到第 n 个,观测值 xn,当
i
α
σ σ2
2 σx σx
μ χ2 χ c2 2 χ α ,df
ε τ
n
n
∑x
i=1
∑x
i =1
在意义上已明确
i
时,可简写为 ∑ x 。 ∑ 为求和符号
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32
T N n SS MS S S2 H0 HA SE DF CV CK O E F LSD LSR x~N(μ, 2) ( ,σ p,q , x~B(n,p) ( , ) a b r c f t u
x
d
d
k
拉丁字母符号 观测值总和 有限总体的总观测值数目 样本的观测值数目或样本容量(样本含量) 平方和 均方 样本标准差,用以估计总体标准差 σ 标准方差(均方) ,用以估计总体方差 σ2 无效假设 备择假设 标准误 自由度,自由度具体数值用 df 表示,如 df=8 变异系数 对照 观测次数 理论次数 F 统计数,F0.05 、F0.01 分别为 0.05、0.01 的临界值 最小显著差数(least significant difference) ( ) 最小显著极差(least significant ranges) 随机变量 x 服从参数 μ 和 σ 的正态分布,μ 为总体平均数,σ 为总体标准差 二项总体成数 p+q =1 随机变量 x 服从参数 n 和 p 的二项分布,n 为试验次数, p 为理论概率 直线回归方程中样本的回归截距 直线回归方程中标本回归系数 样本相关系数;独立性检验中相依表的行数 独立性检验中相依表的列数 观测次数 t 分布的统计数 u 正态分布的统计数;正态标准离差 样本平均数,用以估计总体平均数 μ 成对观测值的差数 成对观测值的差数的平均数 样本数或处理数
第 1 页 共 14 页
生物统计学答案 第一章 统计数据的收集与整理
第一章 统计数据的收集与整理 1.1 算术平均数是怎样计算的?为什么要计算平均数? 答:算数平均数由下式计算:,含义为将全部观测值相加再被观测值的个数 除,所得之商称为算术平均数。计算算数平均数的目的,是用平均数表示样本数据的集中点, 或是说是样本数据的代表。 1.2 既然方差和标准差都是衡量数据变异程度的,有了方差为什么还要计算标准差? 答:标准差的单位与数据的原始单位一致,能更直观地反映数据地离散程度。 1.3 标准差是描述数据变异程度的量,变异系数也是描述数据变异程度的量,两者之间有什么不同? 答:变异系数可以说是用平均数标准化了的标准差。在比较两个平均数不同的样本时所得结果更可靠。 1.4 完整地描述一组数据需要哪几个特征数? 答:平均数、标准差、偏斜度和峭度。 1.5 下表是我国青年男子体重(kg )。由于测量精度的要求,从表面上看像是离散型数据,不要忘记,体重是通过度量得到的,属于连续型数据。根据表中所给出的数据编制频数分布表。 66 69 64 65 64 66 68 65 62 64 69 61 61 68 66 57 66 69 66 65 70 64 58 67 66 66 67 66 66 62 66 66 64 62 62 65 64 65 66 72 60 66 65 61 61 66 67 62 65 65 61 64 62 64 65 62 65 68 68 65 67 68 62 63 70 65 64 65 62 66 62 63 68 65 68 57 67 66 68 63 64 66 68 64 63 60 64 69 65 66 67 67 67 65 67 67 66 68 64 67 59 66 65 63 56 66 63 63 66 67 63 70 67 70 62 64 72 69 67 67 66 68 64 65 71 61 63 61 64 64 67 69 70 66 64 65 64 63 70 64 62 69 70 68 65 63 65 66 64 68 69 65 63 67 63 70 65 68 67 69 66 65 67 66 74 64 69 65 64 65 65 68 67 65 65 66 67 72 65 67 62 67 71 69 65 65 75 62 69 68 68 65 63 66 66 65 62 61 68 65 64 67 66 64 60 61 68 67 63 59 65 60 64 63 69 62 71 69 60 63 59 67 61 68 69 66 64 69 65 68 67 64 64 66 69 73 68 60 60 63 38 62 67 65 65 69 65 67 65 72 66 67 64 61 64 66 63 63 66 66 66 63 65 63 67 68 66 62 63 61 66 61 63 68 65 66 69 64 66 70 69 70 63 64 65 64 67 67 65 66 62 61 65 65 60 63 65 62 66 64 答:首先建立一个外部数据文件,名称和路径为:E:\data\exer1-5e.dat 。所用的SAS 程序和计算结果如下: proc format; value hfmt 56-57='56-57' 58-59='58-59' 60-61='60-61' 62-63='62-63' 64-65='64-65' 66-67='66-67' 68-69='68-69' 70-71='70-71' 72-73='72-73' 74-75='74-75'; run; n y y n i i ∑== 1
英美的MPP项目(世毕盟留学)
英美的MPP项目(世毕盟留学) 第一,什么是MPP/MPA项目的核心内容。 Master of Public Policy(MPP)和Master of Public Administration(MPA)属于public affairs education中的两大项目,这两个项目都强调通过分析、评估政策,执行政策和项目去回应政策议题和解决社会问题~~这两个项目都是比较practical和career-oriented的~~所谓的职业导向(career-oriented),就是希望培养在public service领域服务的人才,毕业后一般是直接找工作。(如果以后是希望念博士继续学术生涯,那么最好仔细考虑一下要不要申请这类项目) 第二、MPP和MPA的区别 虽然MPP和MPA经常被混为一谈,但是两者还是有不同侧重点的。MPP是policy-focused,它强调通过解读数据和信息去分析政策、制定政策和评估政策,比MPA稍微要研究型一点。MPP在课程设置中也更强调经济学和政策分析。相比而言,MPA则是administration-oriented,强调政策的执行和组织管理,所以在课程中更多金融和人力管理的内容。
大家可以简单了解两者的区别~~~在决定申请MPP还是MPA的时候,最好留意两者之间的细微差别,在准备申请材料(PS)的时候也有所侧重~~ 第三、英国和美国MPP/MPA不一样的地方 以牛津的MPP为例,重点介绍英国MPP的项目申请情况。首先,从学制来看,英国项目(一年)比美国(两年)要短。这个时间长短当然是很重要的问题,一年的项目非常的紧张,由于课业繁重平时很难兼职或者实习,毕业之后立刻面临找工作的问题。两年时间则稍微宽松,有充足的时间实习、找工作。其次,从项目的课程设置来看,英国还是比较跨学科和国际化。以牛津的MPP为例,core course包括哲学、法律、科学、经济学,课堂上讨论的议题不仅仅限于英国本土而是全世界范围,学生也非常国家化,一个大班一百多人会有来自70个不同国家的同学。可能是英国本来国土范围小,且作为欧盟的一部分,所以课程中会有更多comparative的视角,跟欧盟中的其他国家比较。至于美国,我所了解的是有些学校在课堂上讨论的是非常本土化的议题,这对于国际学生来说可能是一种挑战。 从研究方法上,MPP/MPA都强调定量方法,是必修课,尽管难易程度有加。但就我个人感觉而言,英国没有美国quantitative-oriented,对定量和经济学背景的要求也没有那么高,教授的课程也比较简单,也许是因为欧洲这边的传统方法是定性。所以对定量没有什么信心或者兴趣的同学可以考虑一下申请英国的学校~~ 如果决定了要申请MPP/MPA,并且不确定以后是否还会申请博士,那么就要确认你所申请/就读的项目是不是可以为博士做准备。例如,牛津的MPP是一个professional degree,要申请博士的话这个master degree是不被认可的,需要重新读一个学术性的master degree,我身边就有朋友是这种情况~~我自己也是还不确定,最后选择了一个比较学术性的项目CSP而非MPP。 第四、有哪些学校开设MPP/MPA,其课程设置和背景要求是怎样的。 开设MPP/MPA的学校其实很多。在美国,这个项目比较强的有哈佛、哥大、芝加哥、乔治城、UC Berkeley和康奈尔,英国牛津、剑桥、LSE、UCL、爱丁堡等,不同学校、不同项目的具体要求是什么可以在官网上去具体查看。申请项目前建议一定要查清楚这个项目的具体要求和侧重点。举个例子,牛津和剑桥的MPP项目都是近年来新建立的,牛津的项目很大,招一百多人,剑桥的项目则很小,只招二十多人,并且特别关注science和technology,所以理工科背景(尤其computer science)的人申请可能会比较有优势哦。 从课程设置来看,MPP和MPA大同小异。主要分为两部分,核心课程和选修类。
生物统计学考试试卷及答案
考试轮次:2017-2018学年第一学期期末考试试卷编号 考试课程:[120770] 生物统计与实验设计命题负责人曾汉元 适用对象:生物与食品工程学院生物科学专业2015级审查人签字 考核方式:上机考试试卷类型:A卷时量:150分钟总分:100分 注意:答案中要求保留必要的计算和推理过程,全部答案保存为一个Word文档,文件名 为学号最后两位数+姓名。考试结束后不要关机。提交答卷后,请到主机看一下是否提交成功。第1题12分,第3题5分,第10题13分,其余的题各10分。 1、下表为某大学96位男生的体重测定结果(单位:kg),请根据资料分别计算以下指标:(1)算术平均数;(2)几何平均数;(3)中位数;(4)众数;(5)极差;(6)方差;(7)标准差;(8)变异系数;(9)标准误。(10) 绘制各体重分布柱形图。 66 69 64 65 64 66 70 64 59 67 66 66 60 66 65 61 61 66 67 68 62 63 70 65 64 66 68 64 63 60 60 66 65 61 61 66 59 66 65 63 58 66 66 68 64 65 71 61 62 69 70 68 65 63 66 65 67 66 74 64 70 64 59 67 66 66 60 66 65 61 61 66 67 68 62 63 70 65 64 66 68 64 63 60 60 66 65 61 61 66 59 66 65 63 58 66 2、已知1000株水稻的株高服从正态分布N(97,3 2),求: (1)株高在94cm以上的概率? (2)株高在90~99cm之间的概率? (3)株高在多少cm之间的中间概率占全体的99%? 3.已知某批30个小麦样品的平均蛋白质含量为14.5%,σ=2.50%,试进行95%置信度下的蛋白质含量的区间估计和点估计。 4、有一大麦杂交组合,F2代的芒性状表型有钩芒、长芒和短芒三种,观察计得其株数依次分别为348、11 5、157,试检验其比率是否符合9:3:4的理论比率。 5、某医院用某种中药治疗7例再生障碍性贫血患者,现将血红蛋白含量(g/L)变化的数据列在下面,假定资料满足各种假设测验所要求的前提条件,问:治疗前后之间的差别有无显著性意义? 患者编号 1 2 3 4 5 6 7 治疗前血红蛋白含量65 75 50 76 65 72 68 治疗后血红蛋白含量82 112 125 85 80 105 128
数量遗传学知识点总结
第一章绪论 一、基本概念 遗传学:生物学中研究遗传和变异,即研究亲子间异同的分支学科。数量遗传学:采用生物统计学和数学分析方法研究数量性状遗传规律的遗传学分支学科。 二、数量遗传学的研究对象 数量遗传学的研究对象是数量性状的遗传变异。 1.性状的分类 性状:生物体的形态、结构和生理生化特征与特性的统称。如毛色、角型、产奶量、日增重等。 根据性状的表型变异、遗传机制和受环境影响的程度可将性状分为数量性状、质量性状和阈性状3类。 数量性状:遗传上受许多微效基因控制,性状变异连续,表型易受环境因素影响的性状,如生长速度、产肉量、产奶量等。 质量性状:遗传上受一对或少数几对基因控制,性状变异不连续,表型不易受环境因素影响的性状,如毛色、角的有无、血型、某些遗传疾病等。 阈性状:遗传上受许多微效基因控制,性状变异不连续,表型易受或不易受环境因素影响的性状。有或无性状:也称为二分类性状(Binary traits)。如抗病与不抗病、生存与死亡等。分类性状:如产羔数、产仔数、乳头数、肉质评分等。 必须进行度量,要用数值表示,而不是简单地用文字区分; 要用生物统计的方法进行分析和归纳; 要以群体为研究对象; 组成群体某一性状的表型值呈正态分布。 3.决定数量性状的基因不一定都是为数众多的微效基因。有许多数量性状受主基因(major gene)或大效基因(genes with large effect)控制。 果蝇的巨型突变体基因(gt);小鼠的突变型侏儒基因(dwarf, df);鸡的矮脚基因(dw);美利奴绵羊中的Booroola基因(FecB);牛的双肌(double muscling)基因(MSTN);猪的氟烷敏感基因(RYR1)三、数量遗传学的研究内容
生物统计学期末复习题库及答案
第一章 填空 1.变量按其性质可以分为(连续)变量和(非连续)变量。 2.样本统计数是总体(参数)的估计值。 3.生物统计学是研究生命过程中以样本来推断(总体)的一门学科。 4.生物统计学的基本内容包括(试验设计)和(统计分析)两大部分。 5.生物统计学的发展过程经历了(古典记录统计学)、(近代描述统计学)和(现代推断统计学)3个阶段。 6.生物学研究中,一般将样本容量(n ≥30)称为大样本。 7.试验误差可以分为(随机误差)和(系统误差)两类。 判断 1.对于有限总体不必用统计推断方法。(×) 2.资料的精确性高,其准确性也一定高。(×) 3.在试验设计中,随机误差只能减小,而不能完全消除。(∨) 4.统计学上的试验误差,通常指随机误差。(∨) 第二章 填空 1.资料按生物的性状特征可分为(数量性状资料)变量和(质量性状资料)变量。 2. 直方图适合于表示(连续变量)资料的次数分布。 3.变量的分布具有两个明显基本特征,即(集中性)和(离散性)。 4.反映变量集中性的特征数是(平均数),反映变量离散性的特征数是(变异数)。 5.样本标准差的计算公式s=( )。 判断题 1. 计数资料也称连续性变量资料,计量资料也称非连续性变量资料。(×) 2. 条形图和多边形图均适合于表示计数资料的次数分布。(×) 3. 离均差平方和为最小。(∨) 4. 资料中出现最多的那个观测值或最多一组的中点值,称为众数。(∨) 5. 变异系数是样本变量的绝对变异量。(×) 单项选择 1. 下列变量中属于非连续性变量的是( C ). A. 身高 B.体重 C.血型 D.血压 2. 对某鱼塘不同年龄鱼的尾数进行统计分析,可做成( A )图来表示. A. 条形 B.直方 C.多边形 D.折线 3. 关于平均数,下列说法正确的是( B ). A. 正态分布的算术平均数和几何平均数相等. B. 正态分布的算术平均数和中位数相等. C. 正态分布的中位数和几何平均数相等. D. 正态分布的算术平均数、中位数、几何平均数均相等。 4. 如果对各观测值加上一个常数a ,其标准差( D )。 A. 扩大√a 倍 B.扩大a 倍 C.扩大a 2倍 D.不变 5. 比较大学生和幼儿园孩子身高的变异度,应采用的指标是( C )。 A. 标准差 B.方差 C.变异系数 D.平均数 第三章 12 2--∑∑n n x x )(
细说IEOR PhD(世毕盟留学)
细说IEOR PhD IE起源于传统制造业,但是如今的IE已经很少再做制造业方面的研究(比如生产排程),培养一些master 输入业界已经够用了。作为有志向攻读Phd的青年,有必要了解一下如今的IEOR倾向的研究方向。 Operations Research/Management science是IE的核心。就是应用mathematical modeling,statistic,simulation 来为某个应用领域做决策的学科。其中大家听说的manufactory, supply chain, healthcare, revenue management, disaster respond等等方向都是OR/MS 作为依托的应用领域。有些系在某应用领域项目比较多,研究的老师比较多,带头人就愿意专门分出来,成立个组什么的。但实质差别不大,只是学的应用领域的东西不同。OR是所有IE系都有的,只是应用领域各自都有特点和侧重。OR方向我会之后详细讲解。类似的还有商学院operations management/decision science专业,很多数学课都会来IE系来学,但他们不要求特别高的数学理论,而侧重商业分析。剩下的方向都是小众,你只有在不多的学校找到相应的研究方向。我对每个方向和每个学校并不是特别清楚,所以大概介绍一下。你可以去IIE 网站了解更多IE的东西。 Statistic,IE也研究统计,主要是研究制造业中quality control,process improvement, reliability analysis。代表学校ASU,做集成电路生产制造,rutgers。Stochastic/simulation, 研究仿真理论,理论性比较强。Northwestern 仿真界的牛校。 Human factor, 我只知道是设计产品更符合人体工效学,使人操作更顺手,降低疲劳积累速度,减少失误,从而提高工作效率。代表学校,VT,Wisconsin-M, OSU。Information system,这个方向在IE系成气候的并不多。代表学校,Wisconsin-M 有研究healthcare information system,USC。
2017福师《生物统计学》答案
一、单选题(共 32 道试题,共 64 分。) V 1. 最小二乘法是指各实测点到回归直线的 A. 垂直距离的平方和最小 B. 垂直距离最小 C. 纵向距离的平方和最小 D. 纵向距离最小 2. 被观察到对象中的()对象称为() A. 部分,总体 B. 所有,样本 C. 所有,总体 D. 部分,样本 3. 必须排除______因素导致“结果出现”的可能,才能确定“结果出现”是处理因素导致的。只有确定了______,才能确定吃药后出现的病愈是药导致的。 A. 非处理因素,不吃药就不可能出现病愈 B. 处理因素,不吃药就不可能出现病愈 C. 非处理因素,吃药后确实出现了病愈 D. 处理因素,吃药后确实出现了病愈 4. 张三观察到李四服药后病好了。由于张三的观察是“个案”,因此不能确定______。 A. 确实进行了观察 B. 李四病好了 C. 病好的原因 D. 观察结果是可靠的 5. 四个样本率作比较,χ2>χ20.05,ν可认为
A. 各总体率不同或不全相同 B. 各总体率均不相同 C. 各样本率均不相同 D. 各样本率不同或不全相同 6. 下列哪种说法是错误的 A. 计算相对数尤其是率时应有足够的观察单位或观察次数 B. 分析大样本数据时可以构成比代替率 C. 应分别将分子和分母合计求合计率或平均率 D. 样本率或构成比的比较应作假设检验 7. 总体指的是()的()对象 A. 要研究,部分 B. 观察到,所有 C. 观察到,部分 D. 要研究,所有 8. 以下叙述中,除了______外,其余都是正确的。 A. 在比较未知参数是否不等于已知参数时,若p(X>x)<α/2,则x为小概率事件。 B. 在比较未知参数是否等于已知参数时,若p(X=x)<α,则x为小概率事件。 C. 在比较未知参数是否大于已知参数时,若p(X>x)<α,则x为小概率事件。 D. 在比较未知参数是否小于已知参数时,若p(X 1.Stanford University 斯坦福大学的统计系提供统计学的硕士学位和博士学位,其中包括硕士学位中的数学科学方向以及博士学位中的生物统计方向。 统计系与ICME (Institute for Computational and Mathematical Engineering)合作提供了一个data science方向的硕士项目,旨在培养学生在数据科学中的计算能力。在成功完成数据科学硕士学位后,学生们可以继续攻读统计学、ICME、MS&E 或计算机科学方面的博士学位,或成为一名行业的数据科学专业人士。完成硕士学位并不能保证获得博士学位。 生统小分支:感兴趣的学生需要申请统计系的博士项目,并且在个人陈述和学术兴趣方面注明对生物统计学的兴趣。 2.University of California—Berkeley 加州大学伯克利分校的统计学硕士项目,目的是让学生在需要统计技能的行业中为他们的职业生涯做好准备。重点是解决工业所遇到的统计挑战,而不是准备博士学位。时长:24学分,两学期,但是,在跟导师协商之后,学生可以多停留一个学期。这样的学生,被期望在第二学期和第三学期之间的暑假找到实习。 3.Harvard University 哈佛大学的统计学硕士项目读完之后,可以选择继续攻读博士项目,也可以直接就业,满足许多领域的统计需求,如金融部门、软件开发部门和政府部门。 对于录取来说,统计学方面的研究生学习的最低数学准备是线性代数和高等微积分。理想情况下,每个学生的准备应该至少包括一项数学概率和数学统计。另外,在统计学和相关的数学领域进行的额外的研究,如分析和测量理论,是有帮助的。 一、填空 变量按其性质可以分为连续变量和非连续变量。 样本统计数是总体参数的估计量。 生物统计学是研究生命过程中以样本来推断总体的一门学科。 生物统计学的基本内容包括试验设计、统计分析两大部分。 统计学的发展过程经历了古典记录统计学、近代描述统计学、现代推断统计学3 个阶段。 生物学研究中,一般将样本容量n >30称为大样本。 试验误差可以分为随机误差、系统误差两类。 资料按生物的性状特征可分为数量性状资料变量和质量性状资料变量。 直方图适合于表示连续变量资料的次数分布。 变量的分布具有两个明显基本特征,即集中性和离散性。 反映变量集中性的特征数是平均数,反映变量离散性的特征数是变异数。 林星s= 样本标准差的计算公式s= 如果事件A和事件B为独立事件,则事件A与事件B同时发生地概率P (AB) = P(A)*P(B)。 二项分布的形状是由n和p两个参数决定的。 正态分布曲线上,卩确定曲线在x轴上的中心位置,c确定曲线的展开程度。样本平均数的标准误等于c Wi。 t分布曲线和正态分布曲线相比,顶部偏低,尾部偏高。 统计推断主要包括假设检验和参数估计两个方面。 参数估计包括点估计和区间估计假设检验首先要对总体提出假设,一般应作两个假设,一个是无效假设,一个是备择假设。 对一个大样本的平均数来说,一般将接受区和否定区的两个临界值写作卩-U a^x_ 卩+U a c x 在频率的假设检验中,当np或nq v30时,需进行连续性矫正。 2检验主要有3种用途:一个样本方差的同质性检验、适应性检验和独立性检验。 2检验中,在自由度df = (1)时,需要进行连续性矫正,其矫正的2 = ( p85 )。 2分布是连续型资料的分布,其取值区间为[0.+ %)。 猪的毛色受一对等位基因控制,检验两个纯合亲本的F2代性状分离比是否符合 孟德尔第一遗传规律应采用适应性检验法。 独立性检验的形式有多种,常利用列联表进行检验。 根据对处理效应的不同假定,方差分析中的数学模型可以分为固定模型、随机模型和混合模型混合模型3类。 在进行两因素或多因素试验时,通常应该设置重复,以正确估计试验误差,研究因素间的交互作用。 在方差分析中,对缺失数据进行弥补时,应使补上来数据后,误差平方和最小。方差分析必须满足正态性、可加性、方差同质性3个基本假定。 如果样本资料不符合方差分析的基本假定,则需要对其进行数据转换,常用的数据转换方法有平方根转换、对数转换、正反弦转换等。 相关系数的取值范围是[-1,1]O 2018年复旦大学生命科学学院生物统计学 [0714Z1]考试科目、 参考书目、复习经验 一、招生信息 所属学院:生命科学学院 所属门类代码、名称:理学[07] 所属一级学科代码、名称:统计学[0714] 二、研究方向 01 (全日制)统计遗传学的理论与实验研究 02 (全日制)计算生物学方法学与应用研究 03 (全日制)生物统计的理论与方法学研究 三、考试科目 ①101思想政治理论 ②201英语一 ③301数学一或302数学二 ④873遗传学和细胞生物学或874生物统计学或875生物信息学 四、复习指导 一、参考书的阅读方法 (1)目录法:先通读各本参考书的目录,对于知识体系有着初步了解,了解书的内在逻辑结构,然后再去深入研读书的内容。 (2)体系法:为自己所学的知识建立起框架,否则知识内容浩繁,容易遗忘,最好能够闭上眼睛的时候,眼前出现完整的知识体系。 (3)问题法:将自己所学的知识总结成问题写出来,每章的主标题和副标题都是很好的出题素材。尽可能把所有的知识要点都能够整理成问题。 二、学习笔记的整理方法 (1)第一遍学习教材的时候,做笔记主要是归纳主要内容,最好可以整理出知识框架记到笔记本上,同时记下重要知识点,如假设条件,公式,结论,缺陷等。记笔记的过程可以强迫自 己对所学内容进行整理,并用自己的语言表达出来,有效地加深印象。第一遍学习记笔记的工作量较大可能影响复习进度,但是切记第一遍学习要夯实基础,不能一味地追求速度。第一遍要以稳、细为主,而记笔记能够帮助考生有效地达到以上两个要求。并且在后期逐步脱离教材以后,笔记是一个很方便携带的知识宝典,可以方便随时查阅相关的知识点。 (2)第一遍的学习笔记和书本知识比较相近,且以基本知识点为主。第二遍学习的时候可以结合第一遍的笔记查漏补缺,记下自己生疏的或者是任何觉得重要的知识点。再到后期做题的时候注意记下典型题目和错题。 (3)做笔记要注意分类和编排,便于查询。可以在不同的阶段使用大小合适的不同的笔记本。也可以使用统一的笔记本但是要注意各项内容不要混杂在以前,不利于以后的查阅。同时注意编好页码等序号。另外注意每隔一定时间对于在此期间自己所做的笔记进行相应的复印备份,以防原件丢失。统一的参考书书店可以买到,但是笔记是独一无二的,笔记是整个复习过程的心血所得,一定要好好保管。统计专业解析(世毕盟留学)
生物统计学试题及答案
2018年复旦大学生命科学学院生物统计学 [0714Z1]考试科目、参考书目、复习指导
- _生物统计学_系列教材的建设与实践_金凤
- 数量遗传学知识点总结
- 生物统计学学习心得
- 信息系统项目管理师重点记忆257个知识点(最新总结归纳)
- 数量遗传学知识点总结
- 生物统计学课后答案
- 2018年复旦大学生命科学学院生物统计学 [0714Z1]考试科目、参考书目、复习指导
- 《生物统计学》复习要点
- 生物统计学学习心得
- 注重应用能力培养的生物统计学课程建设
- 生物统计学复习重点137030032
- 02078 生物统计学
- 生物统计学
- 生物统计学 (2)
- 动物生物统计学知识点整理
- 新药临床试验中的生物统计学知识要点概述(精)
- 个人对生物统计学的认知
- 数量遗传学知识点总结
- 对提升《生物统计学》教学效果的思考
- 生物统计学第四版知识点总结