异构数据库研究与实现

异构数据库研究与实现
王慧刚 2005-10-01
摘要:本文主要讲述异构数据库的关键技术问题和HG SQLHUB的实现方案。
关键字:异构数据库 HGSQL SQLHUB XML HTTP JDBC Java
引言
信息时代的高速发展,给我们带来便捷的同时,也使我们必须面对一个问题:海量的信息数据,我们如何去分析处理。这些信息经常是这样的,可能来源于一些使用不同关系型数据库的信息系统,可能来源于网络,可能来源于一些数据文件等。我们可以将这些所有的数据看成是一个大数据库,它不同于一般关系型数据库,它的结构是不规则的,我们称之为异构数据库。
透明访问这些信息,并对对它们进行处理,成为一个关键性的问题。 HG SQLHUB先走了一步,比较好解决了这个问题。下面我们来分析一下,看HG SQLHUB(以下简称SQLHUB)是怎样实现的。
分析
异构数据库的数据主要来源有:
?关系型数据库
?网络数据
?数据文件如EXCEL、XML、文本等
?其它
如果能透明的访问这些数据源,这个问题就能比较好的解决。
SQL以简洁的语法,强大的功能,被广泛的使用。所以使用SQL透明的访问异构数据库的实用性很强。
实现以上想法需要解决的问题:
?SQL引擎的开发
异构数据库的特殊性决定它不能使用一般的SQL引擎,因为处理过程中必须识
别出数据源类别,做特殊处理。我们不能修改现有的SQL引擎,独立的SQL
引擎开发可以带给我更多的自由空间。
?将异构的数据源映射为关系型数据库表
必须将异构数据源映射为关系数据库表,才能在SQL中进行处理。用户使用时
他们不用关心数据来源,只需要会用SQL语句。这才能叫SQL透明访问。
实现
SQLHUB完全使用java开发,这样就解决了跨硬件平台和跨操作系统平台的问题。
SQLHUB底层使用了自主开发HGSQL引擎。引擎实现了基础的SQL92标准,并在此基础上做了扩展,支持函数数据源,支持了Java存储过程,Java触发器等。SQLHUB内置了118个的系统函数,包括基本的数学函数、字符串函数、日期函数;扩展的数据集函数、任务函数、序列函数等。由于引擎的特殊型create、alter等语法做了特殊处理。底层的数据字典的格式为XML文件,可以方便定义。
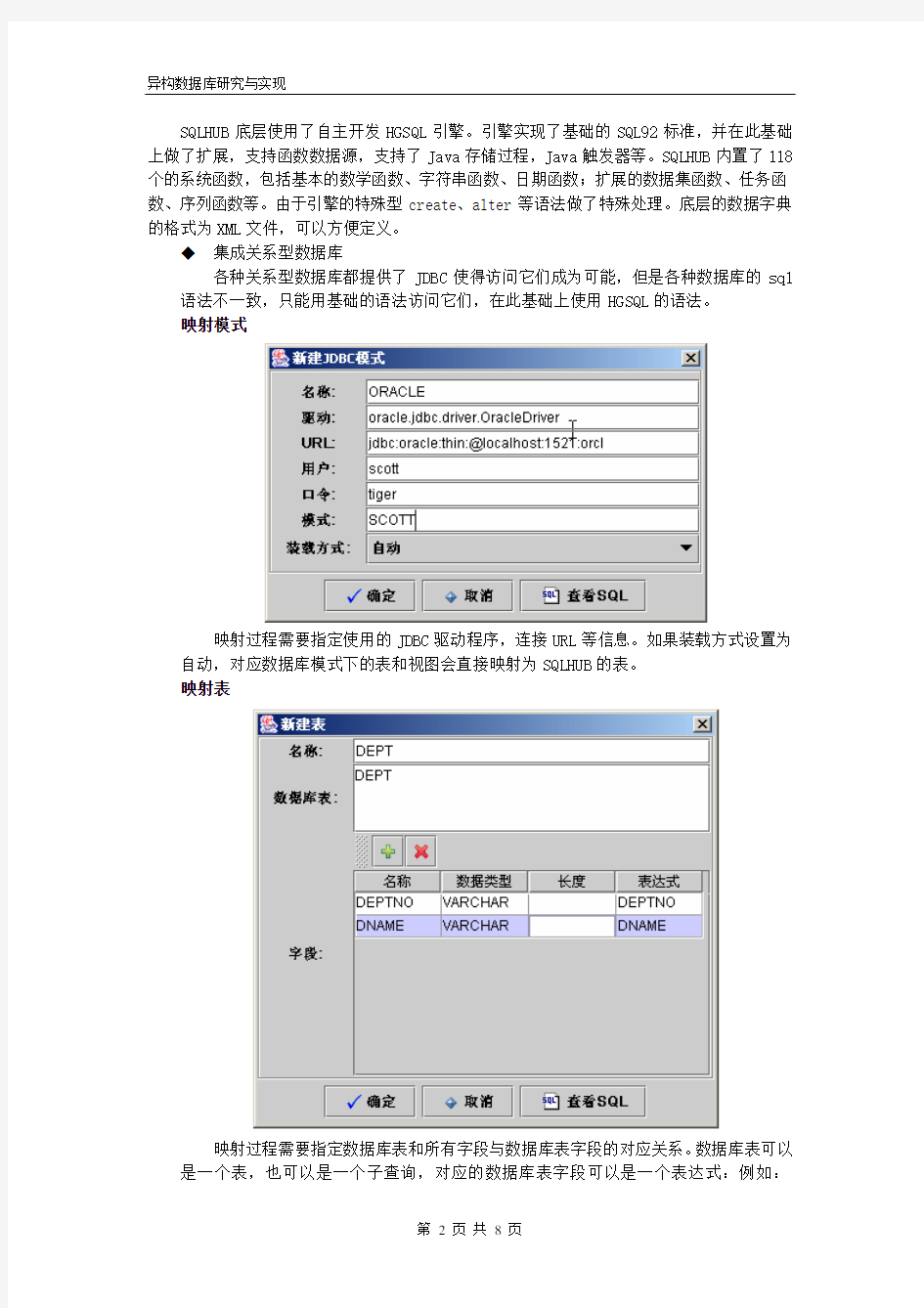
集成关系型数据库
各种关系型数据库都提供了JDBC使得访问它们成为可能,但是各种数据库的sql 语法不一致,只能用基础的语法访问它们,在此基础上使用HGSQL的语法。
映射模式
映射过程需要指定使用的JDBC驱动程序,连接URL等信息。如果装载方式设置为自动,对应数据库模式下的表和视图会直接映射为SQLHUB的表。
映射表
映射过程需要指定数据库表和所有字段与数据库表字段的对应关系。数据库表可以是一个表,也可以是一个子查询,对应的数据库表字段可以是一个表达式:例如:
substr(…),它们将被具体数据库执行。
为了兼容具体的数据库,SQLHUB语法支持具体数据库的SQL语法为SQL前加#DBSCHEMA,例如:#ORACLE select 1 from dual。
集成XML数据
XML被广泛的应用为一种数据交换格式,SQLHUB集成了XML格式并且它是以XML 为基础的。XML集成的关键是通过XPATH查询XML数据,并将它映射为二维表。开源项目DOM4J是一个很不错的项目。它可以支持XPATH的数据检索。SQLHUB使用了该JAVA 包。
映射模式
指定XML文件所在路径
映射表
映射过程指定了xml文件名称,访问数据使用的XPATH。表的各个字段与xml文件中的元素和属性的对应关系。
集成网络数据
网络是一个巨大的数据库,我们能访问到的网络数据主要是通过HTTP获得的。HTTP 中的数据格式也是一个XML,只不过格式不标准,SQLHUB作了处理。映射过程与XML 很相似,差别在于对应的是URL。
映射模式
映射表
集成EXCEL
EXCEL应用的广泛型使我们不得不考虑与它的集成,与它集成的关键问题是跨平台后的访问,知名的开源项目POI和JXL解决了这个问题,由于我们的关键是解决数据访问,对格式要求不严格,考虑到性能SQLHUB选择了JXL。
模式映射
表映射
集成TXT
文本是最基本的数据格式,SQLHUB提供了它的支持 映射模式
映射表
映射过程定义了记录分割符和字段分割符,分割符支持特殊标识回车换行\n\r,tab 键\t,典型的CSV格式,记录分割符“\n”,字段分割符“,”。
其它数据源
SQLHUB支持JAVA自定义存储过程,可以编写取得其它数据源的java类,然后定义到SQLHUB中。
SQLHUB提供了一个把文件路径作为数据源的例子,FILE函数:
SELECT * FROM SYS.FILE('C:\WINDOWS')
高级功能
?支持BLOB和CLOB
可以将图像、影音保存到SQLHUB数据库中
?支持事务处理
?支持java存储过程和java表触发器
可以以此扩展应用
?支持视图、序列
?支持OLAP函数ROLLUP和CUBE,CROSS
提供强大的数据分析功能
SELECT * FROM CROSS(QUERY('员工'),'部门','职位','工资','sum','true','合计') 分析
SELECT * FROM CROSSX(QUERY('员工'),'部门','职位','sum(工资) 工资, count() 数量, avg(工资) 平均') 分析
SELECT 部门,职位,SUM(工资) 工资 FROM 员工 GROUP BY CUBE(部门,职位)
?支持计划任务
可以设定任务实现数据的定期转换
?支持本地JDBC和网络JDBC驱动
使得应用程序可以访问SQLHUB
应用实例
?将oracle的表导入到excel表中
CREATE TABLE EXCEL.DEPT AS SELECT * FROM ORACLE.DEPT
?将百度的mp3排名信息导入到oracle数据库中
CREATE TABLE ORACLE.MP3 AS SELECT * FROM BAIDU. MP3
?XML表与ORACLE数据库关联查询
SELECT * FROM XML.员工 JOIN ORACLE.DEPT ON 员工.部门 = DEPT.DEPTNO
结论
HGSQL HUB已经成功解决了异构数据库的关键技术问题,随着它的推广应用,一定会在应用集成、数据挖掘、数据集成等方面起到关键积极的作用。
参考文献:《HGSQL HUB 用户参考手册》
联系方式:sqlhub@https://www.wendangku.net/doc/868441811.html,
https://www.wendangku.net/doc/868441811.html,
oracle数据库实时同步技术解决方案研究
oracle数据库实时同步技术解决方案研究 近幾年,容灾及高可用已经成为信息数据中心建设的热门课题。本文在对oracle数据库同步技术的初步研究的基础上,根据大庆油田数据中心的实际情况,提出以goldengate和dataguard这两种技术为主的同步解决方案。通过对两种技术的对比研究,根据不同的应用需求选择适合的技术,强调了数据实时同步作为数据库容灾的重要手段,通过实时的数据同步提供高可用的业务分离的应用环境,大大降低主库的压力,保证数据的安全性和高可用性。 标签:数据库同步;goldengate;dataguard;容灾;高可用 一、数据库同步技术 数据库同步是在两个以上的数据库之间进行数据交换,以使得任何一个数据库的改变,会以同样的方式出现在另一个数据库里。数据库同步可以是单向的,也可以是双向的。单向同步也叫主从同步。只有主数据库的改变可以被复制到从数据库里去,从数据库是被动的。双向同步顾名思义就是任何一端的数据变化都要同步到另一端,因为这种同步对应用的要求很高,成功的案例并不多,现实中,应用最为广泛的是单向同步。使用数据库同步技术,用户可以将一份数据发布到多台服务器上,也可以从多台服务器到一台服务器上,从而使不同的服务器用户都可以在权限的许可的范围内共享这份数据。同步技术可以确保分布在不同地点的数据自动同步更新,从而保证数据的一致性。 二、Oracle提供的数据同步方案 从实现机制来分的话,Oracle的数据同步主要分为两大类: (一)运用Oracle数据库内部的机制来实现 1、触发器/Job+DBLINK的方式,可同步和定时刷新。 这种方式主要用于单个数据表,数据量较小的情况。这种方式对网络要求较高,如果两个数据库之间的网络中断,那么主库那边就会报错,而且如果表数多或数据量大的话对数据库性能影响很大,所以这种方式现在很少被采用了。 2、物化视图刷新的方式,有增量刷新和完全刷新两种模式,定时刷新。 物化视图的方式的缺点与触发器方式的缺点基本一致,所以要慎重使用。 3、高级复制,分为多主复制和物化视图复制两种模式。其中多主复制能进行双向同步复制和异步复制,物化视图用于单向复制,定时刷新,高级复制也是基于触发器(trigger)原理,因此高级复制只能到表一级,而且只能是单向复制,否则会冲突,高级复制同样对数据库性能影响很大。
异构数据库的数据迁移
1.前言: 现在市场上数据库众多,根据2007年度的统计,Oracle仍然以45%以上的市场份额占据绝对优势,但是随着DB2 V9,SQL Server 2005的相继成熟以及mysql在web 2.0的强势,各个数据库之间的竞争已经越来越激烈,同样的数据库之间的迁移也就不可避免,下面简单描述数据库迁移的一些要点,起到抛砖引玉的作用。 2.为什么迁移? ?为了统一平台,方便开发和管理维护 各个DB的工作原理存在差异,复杂的系统需要比较高的维护能力,对开发,维护人员的要求相对较高。在一些数据整合上非常复杂,整合不同的数据库数据需要很大工作量。?原来的数据库已经不能负担系统压力,需要scale up 应用初始的设计架构没有考虑到发展以后的规模,导致用户和数据几何倍数上升后系统性能急剧下降,对运营和维护造成很大困难。 ?成本考虑,为了降低成本 原来的数据库ORACLE,TERADATA等对于实际应用来说过于庞大,维护费用过高。可以用费用相对较低的mysql,sql server代替。 ?新的前端应用程序强制要求(如ERP软件) 系统整合,由于厂商的应用程序数据库后台写死,造成只能迁移现有的数据。 ?构建数据仓库 金融保险行业,跨国的大型制造业等数据库类型过多,构建数据仓库需要单一的数据库,需要迁移异构数据库到一个平台。 3.如何迁移? ?迁移工具 1.BI工具,如informatica,datastage,OWB等通过ODBC,JDBC或者数据库自身的ETL 工具进行数据的转移。使用比较方便,不过由于价格一般较贵,对于非BI和数据仓库的数据迁移意义不大。 2.通过开发人员编写简单的java,c程序完成迁移,速度较慢,但是使用方式灵活,可以根据需要修改。适用于对数据库结构相当了解并且不熟悉数据库其他的迁移工具情况下使用。 3.各个数据库自带的工具,如Oracle新推出的migration benchmark,DB2的MTK,SQL SERVER的DTS和2005中重新整合的intergrate service。 4.数据库本身的unload,load工具。每个数据库几乎都有文本的导出导入,如oracle的sqlldr,DB2的load,imp/exp,sql server的bcp,bulk insert,mysql的select into txt等等,一般都通过特殊的API实现,故速度相对其他的普通工具要大大加快。但是对使用者的数据库知识要求较高(如索引维护,日志模式,表结构,约束等)。适合比较大型和较有难度的数据迁移,缺点是由于各个数据库数据类型的不同,可能需要修改表结构。 ?迁移人员 1.需要由非常了解应用业务和程序开发的人员,配合经验丰富的数据库维护人员一起完成,以达到数据迁移后应用程序和数据库的运转良好,数据在迁移过程中不丢失出错。 ?迁移对现在业务的影响 1.如果业务为24*7则需要反复试验以取得最佳的策略使得停机时间最短 2.新系统上线后需要做好业务数据的监控,保证应用程序处理数据的正确性
数据迁移整合方案
1.历史数据的迁移整合 本次系统是在原有系统的基础上开发完成,因此,新旧系统间就存在着切换的问题。另外,新开发的系统还存在与其他一些应用系统,例如,企业信用联网应用系统、企业登记子网站、外资登记子网站等系统进行整合使之成为一个相互连通的系统。本章将针对新老系统迁移和整合提出解决方案。 1.1.新老系统迁移整合需求分析 系统迁移又称为系统切换,即新系统开发完成后将老系统切换到新系统上来。 系统切换得主要任务包括:数据资源整合、新旧系统迁移、新系统运行监控过程。数据资源整合包含两个步骤:数据整理与数据转换。数据整理就是将原系统数据整理为系统转换程序能够识别的数据;数据转换就是将整理完成后的数据按照一定的转换规则转换成新系统要求的数据格式,数据的整合是整合系统切换的关键;新旧系统迁移就是在数据正确转换的基础上,制定一个切实可行的计划,保证业务办理顺利、平稳过渡到新系统中进行;新系统运行监控就是在新系统正常运转后,还需要监控整个新系统运行的有效性和正确性,以便及时对数据转换过程中出现的问题进行纠正。 系统整合是针对新开发的系统与保留的老系统之间的整合,以保证新开发的系统能与保留的老系统互动,保证业务的顺利开展。主要的任务是接口的开发。1.2.需要进行迁移整合的系统 1.3.数据迁移整合分析 根据招标文件工商总局新建系统的数据库基于IBM DB2,而原有系统的数据库包括ORACLE,SQL Server,DB2。这种异构数据在总局主要存在于两个方面,
即部门内部的异构数据和上下级部门之间的异构数据。同时,系统的技术构件有.NET和J2EE两大类。 对于部门内部的异构数据的集成采用数据移植的方法,如:如果数据有基于DB2管理的,有ORACLE管理的,有SQL Server管理的,就根据新系统DB2的要求,把ORACLE的数据迁移到DB2数据库中,把SQL Server的数据迁移到DB2数据库中。 上下级国工商局之间的异构数据的集成利用数据交换系统来完成,重点在于数据库存储标准、交换标准的制定和遵守,保证数据的共享,这部分工作由数据中心完成。 1.4.系统迁移和整合目标 1.4.1.系统迁移的主要目标: 1.保证系统正常运行 在数据转换过程中,由于原有的系统数据的复杂性,给数据转换工作带来了很大的难度,为了在新系统启动后不影响原系统正常的业务,因此数据转换完成后,必须保证新系统的正常运行。 2.保证原有系统在新系统中的独立性 原有系统是独立运行的系统,数据在新系统中虽然是集中存放的,但是各个系统由于存在业务上的差别,数据在逻辑上应当保持一定的独立性。 1.4. 2.系统整合的目标: 保证直接关联的系统互动,保证业务的正常办理。例如公众服务系统与基本业务系统之间互动,基本业务与协同业务之间互动等等。
Oracle数据库同步技术
基于Oracle数据库的数据同步技术大体上可分为两类:Oracle自己提供的数据同步技术和第三方厂商提供的数据同步技术。Oracle自己的同步技术有DataGuard,Streams,Advanced Replication和今年 刚收购的一款叫做GoldenGate的数据同步软件。第三方厂商的数据同步技术有Quest公司的SharePlex 和DSG的RealSync。下面对这些技术逐一进行介绍。 一、DataGuard数据同步技术 DataGuard是Oracle数据库自带的数据同步功能,基本原理是将日志文件从原数据库传输到目标数据库,然后在目标数据库上应用(Apply)这些日志文件,从而使目标数据库与源数据库保持同步。DataGuard 提供了三种日志传输(Redo Transport)方式,分别是ARCH传输、LGWR同步传输和LGWR异步传输。在上述三种日志传输方式的基础上,提供了三种数据保护模式,即最大性能(Maximum Performance Mode)、最大保护(Maximum Protection Mode)和最大可用(Maximum Availability Mode),其中最大保护模式 和最大可用模式要求日志传输必须用LGWR同步传输方式,最大性能模式下可用任何一种日志传输方式。 最大性能模式:这种模式是默认的数据保护模式,在不影响源数据库性能的条件下提供尽可能高的 数据保护等级。在该种模式下,一旦日志数据写到源数据库的联机日志文件,事务即可提交,不必等待日 志写到目标数据库,如果网络带宽充足,该种模式可提供类似于最大可用模式的数据保护等级。 最大保护模式:在这种模式下,日志数据必须同时写到源数据库的联机日志文件和至少一个目标库 的备用日志文件(standby redo log),事务才能提交。这种模式可确保数据零丢失,但代价是源数据库的可用性,一旦日志数据不能写到至少一个目标库的备用日志文件(standby redo log),源数据库将会被关闭。这也是目前市场上唯一的一种可确保数据零丢失的数据同步解决方案。 最大可用模式:这种模式在不牺牲源数据库可用性的条件下提供了尽可能高的数据保护等级。与最 大保护模式一样,日志数据需同时写到源数据库的联机日志文件和至少一个目标库的备用日志文件(standby redo log),事务才能提交,与最大保护模式不同的是,如果日志数据不能写到至少一个目标库的备用日志文件(standby redo log),源数据库不会被关闭,而是运行在最大性能模式下,待故障解决并将延迟的日志成功应用在目标库上以后,源数据库将会自动回到最大可用模式下。 根据在目标库上日志应用(Log Apply)方式的不同,DataGuard可分为Physical Standby(Redo Apply)和Logical Standby(SQL Apply)两种。 Physical Standby数据库,在这种方式下,目标库通过介质恢复的方式保持与源数据库同步,这种方 式支持任何类型的数据对象和数据类型,一些对数据库物理结构的操作如数据文件的添加,删除等也可支持。如果需要,Physical Standby数据库可以只读方式打开,用于报表查询、数据校验等操作,待这些操 作完成后再将数据库置于日志应用模式下。 Logical Standby数据库,在这种方式下,目标库处于打开状态,通过LogMiner挖掘从源数据库传 输过来的日志,构造成SQL语句,然后在目标库上执行这些SQL,使之与源数据库保持同步。由于数据 库处于打开状态,因此可以在SQL Apply更新数据库的同时将原来在源数据库上执行的一些查询、报表等操作放到目标库上来执行,以减轻源数据库的压力,提高其性能。 DataGuard数据同步技术有以下优势: 1)Oracle数据库自身内置的功能,与每个Oracle新版本的新特性(如ASM)都完全兼容,且不 需要另外付费; 2)配置管理较简单,不需要熟悉其他第三方的软件产品; 3)Physical Standby数据库支持任何类型的数据对象和数据类型;
关于异构数据库数据共享的分析
龙源期刊网 https://www.wendangku.net/doc/868441811.html, 关于异构数据库数据共享的分析 作者:秦文文 来源:《中国管理信息化》2013年第04期 [摘要] 本文提出用XML进行数据转换以实现异构数据库的数据共享,从而实现了信息的标准化,有效地解决了以往集成系统信息不能用一种标准化的形式显示这一问题。 [关键词] 异构;共享;数据转换 [中图分类号] TP392 [文献标识码] A [文章编号] 1673 - 0194(2013)04- 0081- 01 异构数据库系统由相关的多个不同数据库组成,可以实现数据的共享和透明的访问,每个数据库系统都是独立存在的,并且具有数据库管理系统。异构数据库的各个组成部分具有自身的自治性,在实现数据共享的同时,每个数据库系统仍保持自己的应用特性、完整性控制和安全性控制。异构数据库系统的目标在于实现不同数据库之间的合并和共享。 1 异构数据库系统 异构数据库系统的目标在于实现不同数据库之间的数据信息资源、硬件设备资源和人力资源的合并与共享。集成的关键技术是以每个局部数据库模式为基础,建立全局的数据模式或全局视图。 2 异构数据库数据共享 由于异构数据库之间存在各种语义和语法上的冲突,要实现异构数据库中数据严格的等价转换比较困难。异构数据的转换目标是能够将源数据库中全部有意义的信息都转换到目标数据库中,而且这种转换包含尽量少的冗余信息。目前主要有如下几种数据转换方式。 2.1 使用软件工具进行转换 使用数据库管理系统的数据导入工具,将各个异构数据中的数据以文件的形势导入集成的数据库表中。如Power Builder的数据管道Data Pipeline、SQL Server的DTS、Oracle的SQL* Loader等可以实现各种异构数据库系统和文本、电子表格等文件系统格式的数据的整合和集成。编写每个分系统的数据转换代码,以完成原始数据转换、错误数据清理、数据结构转换、冗余信息消除、数据存储和数据刷新功能。 数据转换工具的缺点是不具有独立性,必须先运行该数据库产品的前端应用程序才能使用相应的数据转换工具,转换步骤繁琐,人工干预过多。此类工具一般都是各数据库的专用工具,与自身数据库的结合非常紧密。如果集成后的数据库不是数据转换工具所对应的数据库,数据转换工具就不能使用,只能用于集成具有同种类型DBMS的异构数据库。
数据库实时同步技术解决方案
数据库实时同步技术解决方案 一、前言 随着企业的不断发展,企业信息化的不断深入,企业内部存在着各种各样的异构软、硬件平台,形成了分布式异构数据源。当企业各应用系统间需要进行数据交流时,其效率及准确性、及时性必然受到影响。为了便于信息资源的统一管理及综合利用,保障各业务部门的业务需求及协调工作,常常涉及到相关数据库数据实时同步处理。基于数据库的各类应用系统层出不穷,可能涉及到包括ACCESS、SQLSERVER、ORACLE、DB2、MYSQL等数据库。目前国内外几家大型的数据库厂商提出的异构数据库复制方案主要有:Oracle的透明网关技术,IBM的CCD表(一致变化数据表)方案,微软公司的出版者/订阅等方案。但由于上述系统致力于解决异构数据库间复杂的交互操作,过于大而全而且费用较高,并不符合一些中小企业的实际需求。 本文结合企业的实际应用实践经验,根据不同的应用类型,给出了相应的数据库实时同步应用的具体解决方案,主要包括: (1) SQLSERVER 到SQLSERVER 同步方案 (2) ORACLE 到SQLSERVER 同步方案 (3) ACCESS 到SQLSERVER/ORACLE 同步方案
二、异构数据库 异构数据库系统是相关的多个数据库系统的集合,可以实现数据的共享和透明访问,每个数据库系统在加入异构数据库系统之前本身就已经存在,拥有自己的DMBS。异构数据库的各个组成部分具有自身的自治性,实现数据共享的同时,每个数据库系统仍保有自己的应用特性、完整性控制和安全性控制。异构数据库的异构性主要体现在以下几个方面: 1、计算机体系结构的异构 各数据库可以分别运行在大型机、小型机、工作站、PC嵌入式系统中。 2、基础操作系统的异构 各个数据库系统的基础操作系统可以是Unix、Windows NT、Linux等。 3、DMBS本身的异构 可以是同为关系型数据库系统的Oracle、SQL Server等,也可以是不同数据模型的数据库,如关系、模式、层次、网络、面向对象,函数型数据库共同组成一个异构数据库系统。 三、数据库同步技术
异构数据库跨库检索技术综述
异构数据库的跨库检索技术综述 黄镝 上海交通大学图书馆上海200030 [摘要] 异构数据库的跨库检索是电子资源整合的核心技术,本文介绍了异构数据库的特征、异构数据库的连接和数据交换技术;探讨了跨库检索系统应具备的功能和应注意的问题,并对国外一些有影响的跨库检索系统进行了介绍。 [关鍵词] 异构数据库跨库检索数据库连接Webfeat MetaLib [分类号] G250.73 Review of Cross Searching Technique for Heterogeneous Database Huang Di Shanghai Jiaotong University Library, Shanghai 200030 [Abstract] Cross searching technique for heterogeneous database is core technology of integrating electronic resource. The paper has introduced the character of heterogeneous database, the technology of heterogeneous databases connection and information exchanging. It also discussed the function of cross retrieval system for heterogeneous databases. The paper has also included a survey of foreign products in cross database searching. [Keywords] Heterogeneous databases Cross database searching Database connection Webfeat MetaLib 1.引言 近几年,图书馆通过引进和自建数据库,已使电子资源的建设具有相当规模,电子文献在文献服务中所占的比重也不断增加。在继续加强电子资源建设的同时,图书馆开始更加关注电子资源的管理工作,整合已有的资源,将不同类型、不同结构、不同环境、不同用法的各种异构数据库纳入统一的检索平台,以便于用户更方便、更高效地获取信息。 2.数据库的异构特征 图书馆要整合的数据库主要包括:书目数据库(OPAC)、题录/文摘数据库、全文数据库、电子期刊和电子图书、相关的WEB网站等。这些数据库分布在不同的服务器,由不同的信息服务公司和出版社提供、或由图书馆自建,成为各具不同特性的异构数据库,其异构特征表现为以下几个方面: 2.1 数据模型的异构分层次、网状、关系和面向对象4种。 2.2 数据结构不同如ORACLE与Sybase数据库物理模型异构、数据结构不同,而有些数据还是半结构或非结构的。 2.3 系统控制方式不同有集中式与分布式。 2.4 计算机平台的异构从巨、大、中、小型机到工作站、PC。 2.5 通信协议的不同有Z39.50、HTTP及非标准等。 2.6 通信结构模式的不同有主从结构、客户机/服务器模式、浏览器/服务器模式。 2.7 操作系统的异构有UNIX、NT、OS/2、Apache、Sun Solaris、Linux等。 2.8 网络的异构有LAN、WAN、以太总线结构与令牌环结构等。 3.异构数据库连接与存取的相关技术
数据库访问技术
7.2 数据库访问技术 访问数据库中的数据对象时,一般可采用两种访问方式:一是登录用户直接借助DBMS 的数据操纵工具,通过图形或SQL命令接口联机访问;另外一种为程序代码通过应用程序编程接口(Application Programming Interface,API)进行数据库连接验证以及数据操作。两种数据库访问方式,可以抽象为图7.5的层次结构,从中可见中间的接口组件是数据库访问的桥梁与核心,本节主要就该部分的通用接口技术(即API访问方式)部分进行介绍。 图7.5 数据库访问结构示意 根据底层数据操作模式的差异,数据库接口可简单分为:本地(Local)数据库接口和客户机/服务器(Client/Server)数据库接口。 1.本地数据库接口 通过DBMS将用户数据请求转换成为简单的磁盘访问命令,并交由操作系统的文件管理系统执行;然后DBMS从文件管理系统得到数据响应并加以处理。由于DBMS数据文件组织结构的差异,本地型DBMS只能够读取特定的数据源。 2.客户机/服务器数据库接口 数据处理工作分散到工作站和服务器上处理。工作站通过特定的数据库通信API,把数据访问请求传给相应的服务器的后端数据驱动程序。由于不同客户机/服务器数据库管理系统通信机制的差异,异构数据库之间也难以实现透明通信互访。 因此,仅依靠特定DBMS提供的数据库访问接口难以支撑透明的、通用的异构数据库访问。后台数据库管理系统的变更或升级,需要程序员对特定API的重新学习,以及对应用程序代码的改写;而市场上DBMS产品众多,必将进一步加大系统开发人员的学习和维护压力,应用程序与数据源间的独立性难以真正实现。为此,建立更为通用的数据访问技术规范,为程序用户提供一套完整、统一的数据库访问接口,得到了数据库业界广泛认同与支持,并由此产生了众多成熟的数据库访问接口应用技术规范。 到目前为止,主流的数据库访问技术包括ODBC、MFC ADO、RDO、OLE DB、ADO、https://www.wendangku.net/doc/868441811.html,以及JDBC等通用技术标准。这些通用数据库访问技术的出现与发展大大降低了数据库系统开发与维护门槛,改善了数据库系统的移植性、扩展性,极大推动了数据库技术的发展与普及。下面就主流数据库访问技术发展与演化进行介绍。
数据库同步
一个是远程SQLServer数据库,一个是本地SQLServer数据库 回答 验证码:换一张 登录并发表取消 回答 dhy40022008-11-18 10:15:22 下介绍实现复制的步骤。(以快照复制为例) 准备工作: 1.在发布服务器上,新建一个共享目录,做为发布的快照文件的存放目录,操作: 我的电脑--D:\ 新建一个目录,名为: PUB --右键这个新建的目录 --属性--共享 --选择"共享该文件夹"(另外还可以通过"权限"按纽来设置具体的用户权限 --确定 2.设置SQL代理(SQLSERVERAGENT)服务的启动用户 开始--程序--管理工具--服务 --右键SQLSERVERAGENT --属性--登陆--选择"此账户" --输入".\Administrator",或者选择其他系统管理员 --"密码"中输入该用户的密码 3.设置SQL Server身份验证模式,解决连接时的权限问题 企业管理器 --右键SQL实例--属性
--安全性--身份验证 --选择"SQL Server 和Windows" --确定 4.在发布服务器和订阅服务器上互相注册 企业管理器 --右键SQL Server组 --新建SQL Server注册... --下一步--可用的服务器中,输入你要注册的远程服务器名--添加 --下一步--连接使用,选择第二个"SQL Server身份验证" --下一步--输入用户名和密码 --下一步--选择SQL Server组,也可以创建一个新组 --下一步--完成 lixiaohui11520012008-11-20 10:29:07 假设你的远程SQLServer数据库和你的本地是局域网,不知道sqlServer里面有没有dblin k(oracle中有,oracle就是用DBLink实现数据库同步的)。 ai000052009-10-04 08:05:07 MSSQL数据同步利用数据库复制技术实现数据同步更新(来自网络,也是非常完美的教程) 复制的概念 复制是将一组数据从一个数据源拷贝到多个数据源的技术,是将一份数据发布到多个存储站点上的有效方式。使用复制技术,用户可以将一份数据发布到多台服务器上,从而使不同的服务器用户都可以在权限的许可的范围内共享这份数据。复制技术可以确保分布在不同地点的数据自动同步更新,从而保证数据的一致性。 SQL复制的基本元素包括 出版服务器、订阅服务器、分发服务器、出版物、文章 SQL复制的工作原理 SQLSERVER主要采用出版物、订阅的方式来处理复制。源数据所在的服务器是出版服务器,负责发表数据。出版服务器把要发表的数据的所有改变情况的拷贝复制到分发服务器,分发服务器包含有一个分发数据库,可接收数据的所有改变,并保存这些改变,再把这些改变分发给订阅服务器 SQLSERVER复制技术类型 SQLSERVER提供了三种复制技术,分别是: 1、快照复制(呆会我们就使用这个) 2、事务复制 3、合并复制
分布式数据库数据同步技术研究
分布式数据库数据同步技术研究 由于分析式数据库同步技术应用越来越广泛,因此相关的研究也备受人们关注。本文主要是从分布式数据库同步技术的流程,以及数据同步的方法来对其进行阐述,以供大家参考。 标签:分布式数据库同步技术研究 一、前言 经济逐步发展,企业的数量和规模都在不断增多,每个企业在各地都有自己的子公司,为了能够使不同的公司运用相同的数据,就要采取数据库同步技术来解决。但是,因为其操作复杂,对网络以及系统的依赖性比较高,其运用时经常出现各种问题。 二、分布式数据库同步技术概述 1.分布式数据库的定义以及特征 分布式数据库又称DDB,其是Distributed Database的英文简称,它是一个数据库的集合,该集合包括计算机网络当中的每一个场地以及节点上面的数据库。分布式数据库有两大特点,即分布性和逻辑的协调性相统一。分布性是指所有的数据不是仅仅存放在单个的计算机的储存器上,而是根据整体的需要,将数据进行划分,形成具有一定结构的数据子集,然后将其储存在各个场所中;逻辑协调性就是指分布在不同场所的数据子集,其相互之间互相制约,使其形成一个逻辑上的整体。 2.数据同步技术 数据同步技术利用的是分布式数据库,使数据库中位于不同场所的数据实现同步更新,从而实现数据库的分布式处理应用。该项技术可以大大地提高用户使用和处理数据的透明程度,使每一个站点的自治性也有所提高。 三、技术同步的过程 根据数据同步流程,按照典型的三步数据同步过程,采用基于XML与.NET Removing的分布式数据同步模型,该数据同步模型采用松散一致性的单向数据同步方式,同步时由源端以推式方式进行。数据同步系统由三个部分组成,分别是更新差异数据模块、捕获差异数据模块以及分发差异数据。 该模型主要适用的是具有触发器功能的数据库管理系统,其是在https://www.wendangku.net/doc/868441811.html,平台上面构建而成的,它通过触发器来讲源数据库中的数据变化情况进行捕获,其数据变化的差异称作为差异数据,差异数据会在源端进行储存,
异构数据库在高校管理信息系统整合中的应用
异构数据库在高校管理信息系统整合中的应用 随着“互联网+”国家战略的提出,政府及公共服务部门也围绕着这一计划提出了服务升级的需求。如何将原有孤立、自治的管理信息系统进行资源整合,实现信息共享是当下的研究热点。此文以高校的管理信息系统整合为案例,探索了一条成本小、可靠性强的中间件异构数据库方式来实现原有管理信息系统整合的道路。通过XML解析工具将各子系统数据库更新的数据转换为XML消息,再通过中间件应用服务器提供的JMS消息服务,来实现各子系统数据库应用程序和中央數据库系统应用程序的消息传递,以达到信息同步、资源共享的目的。 标签:异构数据库;中间件技术;管理信息系统 0 引言 随着“互联网+”国家战略的提出,如何基于互联网为大众提供方便快捷的服务已是当下研究的一个热门课题。 高等学校作为公共服务的重要一环,办学规模不断扩大,为了便于管理,高校各部门都建立了各自的管理系统。 对现有的应用系统而言,各系统相互孤立,数据不能共享,造成了很多不必要的浪费和重复建设[1]。 如何将这些异构的信息系统整合,实现信息交互资源共享是当下校园信息化建设的一个难点。 异构数据库技术的提出解决了这一难题。 1 异构数据库定义 异构数据库是将各个已经存在的、自治的及异构的数据库系统集合在一起。异构数据库继承和发展了分布式数据库技术,分布式数据库由多个结构相同的子数据库组成,在物理上可以分布在各地,但实际上只有一个数据库系统为其服务,提供统一的查询与更新;而异构数据库则是以多个结构不同、运行独立的数据库系统为基础,通过统一的规则集成的一个分布式数据库系统[2]。 简言之异构数据库系统,就是通过统一的表示、存储和管理集成存在的异构的且独立的数据库,使用户感觉获取到的数据都具有单一的模式且存储在单个数据库中。 2 异构数据库集成方法 一般来说,异构数据库集成方法主要有:数据仓库(Data Warehouse)及中
异构数据库系统之间进行数据通信的技术
异构数据库系统之间进行数据通信的技术 侯爱民1 (东莞理工学院计算机科学与技术系 广东东莞 523808) 摘要 数据库在企业信息管理中占有重要的地位。面对各种各样的数据库(Orcale ,Sybase SQL Anywhere ,MS SQL Server ,Informix ,等等)和同一个数据库的不同版本,如何保留历史数据和利用共享数据,是企业管理者所关心的一件事情。本文讨论了采用数据管道来解决数据库系统之间进行数据通信(即从一个数据库系统中传递历史数据或共享数据到另一个数据库系统中)的一种技术,论述了利用可视化的高级语言开发工具(PowerBuilder )及其数据管道对象来实现这项技术的原理、方法及程序实现。 关键词 信息管理,数据库,数据管道,通信 A Technique of Data Communication between HDB Aimin Hou (Department of Computer Science and Technology , Dongguan University of Technology, Guangdong Dongguan 523808,China) Abstract : Database plays a key role in the business informatiom management . Facing the fact that there exist many different kinds of databases (for example , Qracle , Sybase SQL Anywhere , MS SQL Server , Informix , etc) and a various versions of the same database , how does the business manager remain the old data and enjoy the share data ? It is indeed a tough problem which the business manager should concern with . This paper discusses a technique for using data pipeline to solve the data communication between databases , so as to transfer the old or share data from one database to another , and presents the principle 、method and program of this technique which is accomplished based on a visual programming language (i .e . PowerBuilder) and a PB’s data pipeline object . Keywords : information management ; database ; data pipeline ; communication 学科分类:520 人们在进行信息化管理时要使用数据库系统。市场上的数据库产品多如牛毛,大型数据库系统有Oracle ,Sybase SQL Anywhere ,MS SQL Server ,Informix 等。桌面数据库有Access ,FoxPro ,Paradox 等。既然市场存在如此多的数据库系统,那么,在它们之间进行数据共享就是一件十分重要和自然的事情了。 另一方面,即使同一个用户,他也很有可能前后使用了两套管理系统产品,或一套管理系统的两种版本的产品。这两套或两种管理系统各自使用的数据库系统可能是同构的,也可能是异构的。不管怎样,尽最大的可能利用以前的数据,减少不必要的重复投资和工作量,就是一件具有现实意义的事情了。 为了实现不同数据库系统之间的数据共享,人们必须找到一种行之有效的方法,在各个数据库系统之间传递数据,并且要保证在传递过程中数据的一致性和完整性。利用可视化的高级语言(PowerBuilder )中的数据管道对象,就可以实现这样的通信技术。本文着重讨论了这项 1 侯爱民,男,1963年生,副教授,硕士。主要研究领域为智能安全系统,神经网络,数据库系统 _______________________________________________________________________________https://www.wendangku.net/doc/868441811.html,
数据库同步更新
数据库同步更新 一、两类方法实现数据库实时更新 1、简单表更新可通过创建触发器实现时时更新,如果数据量大的话,不建议此类。x 2、数据量大的话,可通过数据库复制技术实现。 二,方法概述: 复制是将数据或数据库对象从一个数据库复制和分发到另外一个数据库,并进行数据同步,从而使源数据库和目标数据库保持一致。使用复制,可以在局域网和广域网、拨号连接、无线连接和 Internet 上将数据分发到不同位置以及分发给远程或移动用户。 一组SQL SERVER2005复制有发布服务器、分发服务器、订阅服务器(图1 复制服务器之间的关系图)组成,他们之间的关系类似于书报行业的报社或出版社、邮局或书店、读者之间的关系。以报纸发行为例说明,发布服务器类似于报社,报社提供报刊的内容并印刷,是数据源;分发服务器相当于邮局,他将各报社的报刊送(分发)到订户手中;订阅服务器相当于订户,从邮局那里收到报刊。在实际的复制中,发布服务器是一种数据库实例,它通过复制向其他位置提供数据,分发服务器也是一种数据库实例,它起着存储区的作用,用于复制与一个或多个发布服务器相关联的特定数据。每个发布服务器都与分发服务器上的单个数据库(称作分发数据库)相关联。分发数据库存储复制状态数据和有关发布的元数据,并且在某些情况下为从发布服务器向订阅服务器移动的数据起着排队的作用。在很多情况下,一个数据库服务器实例充当发布服务器和分发服务器两个角色。这称为“本地分发服务器”。订阅服务器是接收复制数据的数据库实例。一个订阅服务器可以从多个发布服务器和发布接收 数据。 (图1) 复制有三种类:事务复制、快照复制、合并复制。
事务复制是将复制启用后的所有发布服务器上发布的内容在修改时传给订阅服务器,数据更改将按照其在发布服务器上发生的顺序和事务边界,应用于订阅服务器,在发布内部可以保证事务的一致性。快照复制将数据以特定时刻的瞬时状态分发,而不监视对数据的更新。发生同步时,将生成完整的快照并将其发送到订阅服务器。合并复制通常是从发布数据库对象和数据的快照开始,并且用触发器跟踪在发布服务器和订阅服务器上所做的后续数据更改和架构修改。订阅服务器在连接到网络时将与发布服务器进行同步,并交换自上次同步以来发布服务器和订阅服务器之间发生更改的所有行。 1、复制实例 这里以配置一个事务复制来说明复制配置过程。 试验在同一台机器的二个实例间进行,实例名分别是SERVER01、SERVER02 。将SERVER01配置发布服务器和分发服务器(也就是前面提到的“本地分发服务器”),SERVER02配置为 订阅服务器。在本例中将SERVER01中一个DBCoper库中person表作为发布的数据,在发布前请确保person表有主键、SQL SERVER 代理自动启动、发布数据库是日志是完整模式。第一步:完全备份SERVER01 DBCopy数据库,在SERVER02上恢复DBCopy数据库(复制前的同步,使用发布的源和目标数据一致) 第二步:在SERVER01上设置发布和分发A 在SERVER01的复制节点—>本地发布右键选择新建订阅(图2) ()(图2) B B 在新建发布向导中首先要求选择分发服务器,本例选择本机作为分发服务器,选择默认值。(图3)
异构数据库透明访问的研究与实现
第32卷 第3期河北理工大学学报(自然科学版)V ol 32 No 3 2010年8月Journal of H ebei Polytechnic University(Natural Sc ience Ed ition)Aug.2010 文章编号:1674-0262(2010)03-0060-03 异构数据库透明访问的研究与实现 王洪辉,张振友,路翠芳 (河北理工大学计算机与自动控制学院,河北唐山063009) 关键词:异构数据库;EJB;XML;B/S 摘 要:研究了在I n ter net环境下,基于XML技术的异构数据库系统的联合使用,为企事业单 位的信息交换、电子商务和电子政务提供一个对多数据库系统访问的应用平台。该系统使用 J AVA组件技术中的Enterprise Java B ean组件实现MVC模式的模型,具有先进性、实用性、可 靠性、界面友好和易扩充性等特征。 中图分类号:TP311 13 文献标志码:A 0 引言 随着W eb与异构数据库的结合及Inter net在全球的迅速普及,以异构数据库互用技术为代表的信息互用技术已渗透到人类社会包括工业、商业、国防等的各个领域。异构数据库系统是相关的多个数据库系统的集合,可以实现数据的共享和透明访问。异构数据库的各个组成部分具有自身的自治性,实现数据共享的同时,每个数据库系统仍保有自己的应用特性、完整性控制和安全性控制。 1 X M L 1 1 XM L简介 X M L[1]是由W3C(W o rl d W ide W eb Consorti u m)开发的可扩展标示语言,它将SG M L的丰富功能与HT-M L的易用性结合到W eb的应用中,以一种开放的、自我描述的方式定义了数据结构。在描述数据内容的同时能突出对结构的描述,从而体现出数据之间的关系,它的特点是简单、开放、可扩充性。作为一种标示语言,XML标准是由W3C组织推出的一系列规范组成的,它主要包括XML、可扩展样式表语言(Ex tensible S tyle Sheet Language)、文档对象模型DOM(Docum ent Ob ject M ode)以及文档类型定义DTD(Docum ent Type Definiti o n)等。 1 2 XM L的特点 X M L的主要技术特点: (1)XML是一种元标记语言,与HT M L不同,XML不是一种具体的标记语言,它没有固定的标记符号; (2)XML数据的自描述性。是指XML中的语义标识,一方面限定了元素的层次结构,另一方面也说明了元素的含义,在XML搜索结果中,由标识就可以知道内容的含义,这使得搜索结果更有意义; (3)XML的核心是数据。一般来说一个文档里,都具有文档数据、文档结构、文档样式三个要素。而对于X M L文档来说,数据是其核心 在XM I中将样式与内容是分开处理的。 收稿日期:2009-10-10
数据中心同步平台建设方案
数据中心同步平台建设方案 第一章概述 1.1 平台建设背景 当前政府、企业的信息化的状况是,各政府和企业一般都设计和建设了属于机构、业务本身的应用、流程以及数据的信息处理系统,独立、异构、涵盖各自业务内容的信息处理系统,系统设计建设的时期不同、业务模式不同,信息化建设缺乏有效的总体规划,重复建设;缺乏统一的设计标准,大多数系统都是由不同的厂商在不同的平台上,使用不同的语言进行开发的,信息交互共享困难,存在大量的信息孤岛和流程孤岛。为了有效整合分散异构的信息资源,消除“信息孤岛”现象,提高政府和企业的信息化水平。宇思公司要开发的数据共享交换平台,主要目的是有效整合分散异构系统的信息资源,消除“信息孤岛”现象,提高政府和企业的信息化水平,灵活实现不同系统间的信息交换、信息共享与业务协同,加强信息资源管理,开展数据和应用整合,进一步发挥信息资源和应用系统的效能,提升信息化建设对业务和管理的支撑作用。 要求新构建的数据共享交换平台要遵循标准的、面向服务架构(SOA)的方式,基于先进的企业服务总线ESB技术,遵循先进技术标准和规范,为跨地域、跨部门、跨平台不同应用系统、不同数据库之间的互连互通提供包含提取、转换、传输和加密等操作的数据交换服务,实现扩展性良好的“松耦合”结构的应用和数据集成;同时
要求数据共享交换平台,能够通过分布式部署和集中式管理架构,可以有效解决各节点之间数据的及时、高效地上传下达,在安全、方便、快捷、顺畅的进行信息交换的同时精准的保证数据的一致性和准确性,实现数据的一次 数据共享交换平台-设计方案 采集、多系统共享;要求数据交换平台节点服务器适配器的可视化配置功能,可以有效解决数据交换平台的“最后一公里”问题,快速实现不同机构、不同应用系统、不同数据库之间基于不同传输协议的数据交换与信息共享,为各种应用和决策支持提供良好的数据环境。要求数据共享交换平台能够把各种纷繁复杂的数据系统集成在一起完成特定业务,提供同构数据、异构数据之间的数据抽取、格式转换、内容过滤、内容转换、同异步传输、动态部署、可视化管理监控等方面功能,支持的数据包括各主流数据库(如Oracle、SQL Server、MySQL等)、地理空间数据(如卫星影像、矢量数据)、常规文件(word、excel、pdf)等各种格式,并可以根据用户需求定制开发特定业务服务。 1.2 应用场景 场景一:中国科学院电子学研究所的信息交换需求 实现各个数据中心间的数据库层面的数据共享交换,各中心之间是双向的、实时的数据交换,各数据节点的数据库是同构的数据库系统(即Oracle),数据的类型是基于数据库表格的规则数据,字段类型包含BLOB字段类型。目前各数据节点的数据结构(表)是相同的,主要是一表对一表的数据交换,数据抽取和过滤需求比较简单。目前数据共享交换是通过Oracle GoldenGate数据库同步工具来