湖南省国内生产总值年度数据的时间序列分析

时间序列实验报告
一.数据介绍:本文通过对湖南省1978年—2009年32年的省地区生产总值进行分析,运用统计学和应用时间序列中的方法,同时辅以SAS统计软件,对湖南省自78年来经济体制改革之后的历年GDP数据进行了分析,通过对数据的预处理、初步分析、建模、结果分析后,建立最优经济预测模型,为省政府和企业的管理决策提供依据和建议。
二.模型构建:本文主要运用ARMA模型对所需数据进行分析处理,以做出相对应的结果和建议。
三.实证研究
1、时间序列分析
在ARMA模型当中,所要研究的序列是一个零均值的平稳随即过程产生的,即其过程的随机性质具有时间上的不变性,在图形上表现为所有样本点都在某一水平线上下随机波动。对于非平稳时间序列,需要预先对时间序列进行平稳化处理。
2、平稳性检验
首先绘制湖南省GDP数据的时间序列图。
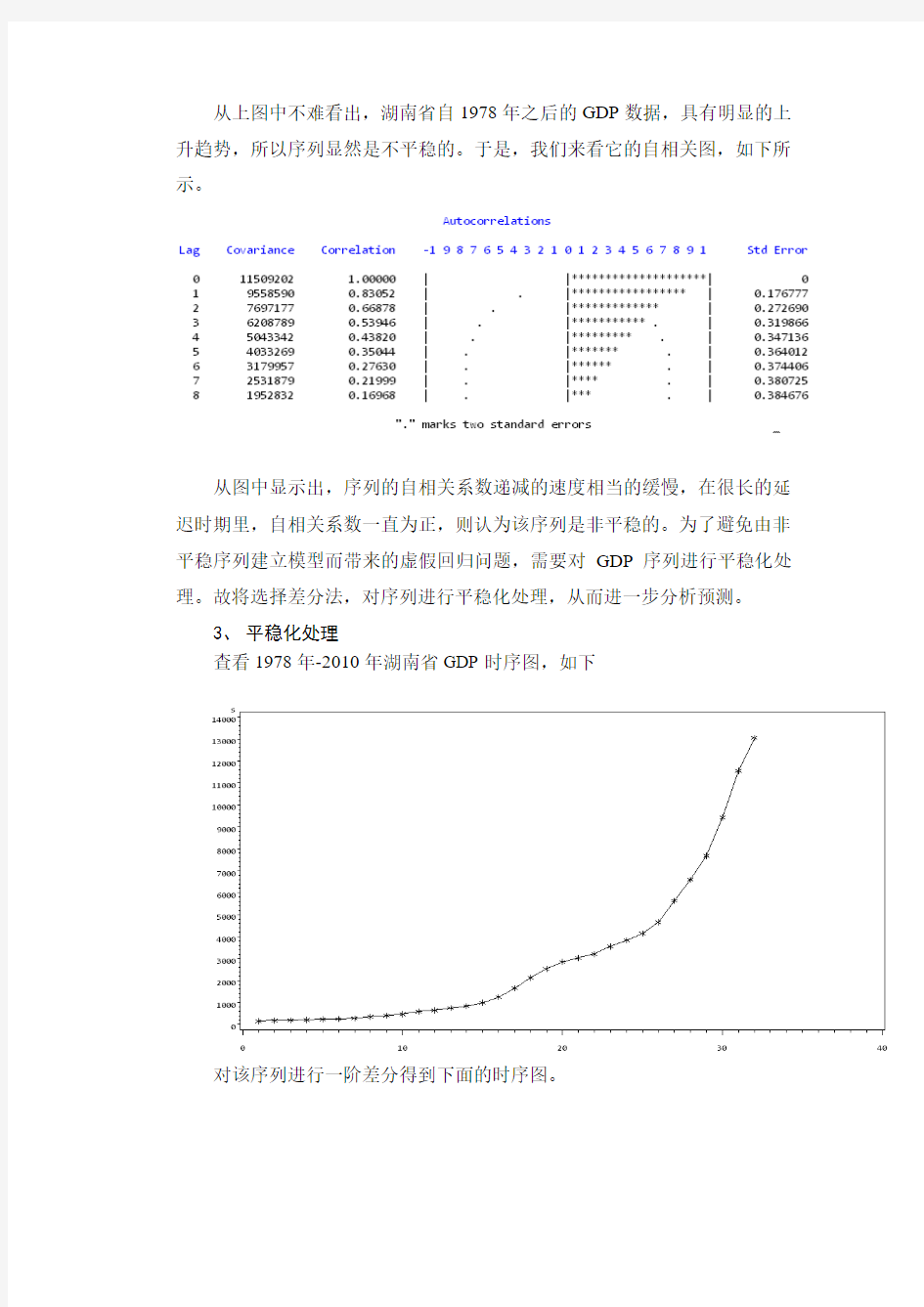
从上图中不难看出,湖南省自1978年之后的GDP数据,具有明显的上升趋势,所以序列显然是不平稳的。于是,我们来看它的自相关图,如下所示。
从图中显示出,序列的自相关系数递减的速度相当的缓慢,在很长的延迟时期里,自相关系数一直为正,则认为该序列是非平稳的。为了避免由非平稳序列建立模型而带来的虚假回归问题,需要对GDP序列进行平稳化处理。故将选择差分法,对序列进行平稳化处理,从而进一步分析预测。
3、平稳化处理
查看1978年-2010年湖南省GDP时序图,如下
对该序列进行一阶差分得到下面的时序图。
显然经过一阶差分处理之后,序列依然存在明显的长期增长趋势,对差分序列进行平稳性检验,查看序列的自相关系数图,见下图:
图中,自相关系数缓慢的减少,且在很长的一段时间内,系数一直为正,则认为一阶差分后的序列依然非平稳,需要对该序列再次进行差分。二阶差分时序图如下:
从图中可以看出,二阶差分之后的时序散点图,基本在0点左右波动,肯能是平稳的。做它的自相关系数图如下:
如图所示,可以判断二阶差分之后该序列平稳。
4.时间序列模型的建立
我们研究的序列为一元时间序列,建模的目的是利用其历史值和当前及过去的随机误差项对该变量变化前景进行预测,通常假定不同时刻的随机误差项为统计独立且正态分布的随机变量。对于时间序列预测,首先要找到与数据拟合最好的预测模型,所以阶数的确定和参数的估计是预测的关键。
5.模型识别
ARMA(p,q)模型的识别与定阶可以通过样本的自相关与偏自相关函数的观察获得。查看二阶差分序列的自相关和偏自相关系数图,如下:
由于经验不足,本文采用SAS软件中的先对最优定阶的方法来对模型定阶,其Minimum Information Criterion图如下:
由图,在自相关延迟阶数小于等于5,移动平均延迟阶数小于等于5的所有ARMA模型中,BIC信息量相对最小的是ARMA(3,4)模型。
确定了模型的阶数之后,下一步就是估计模型中的未知参数的值。在确定模型的未知参数的过程中,发现采用的ARMA(3,4)模型并不能很好的表现该序列,其P值(如下图)过大,于是重新定阶。
经过多次尝试之后确定AR (2)模型能够有很好的检验效果(如下图)。
并且其白噪声检验结果如下,证明信息已经被完全提取。
最后得出结果模型为
则去掉差分后的ARIMA(2,2,0)模型为:
t t t t t t GDP GDP GDP GDP GDP ε+-+-=----432155065.01013.155065.12
利用该模型预测2010年湖南省GDP 指标量为:
经查询知道湖南省2010年GDP 指标量为15902.12亿元,超出95℅的预测区间,但还是相差不大。基本认为模型能够很好的表示该时间序列。
预测图如下:
四.结论
本文使用时间序列分析的方法对湖南省国内生产总值的年度数据序列进行了随机性分析,并运用ARIM A 模型预测方法对我国的国内生产总值进行了小规模的预测。 通过模型识别、比较以及检验,最终选定ARIMA(2,2,0)模型:
t t t t t t GDP GDP GDP GDP GDP ε+-+-=----432155065.01013.155065.12
从该论证过程可以看出,在对经济指标做预测时,往往面对不平稳的时间序列模型,我们要进行多阶差分之后,才能得到平稳的序列,建立理想的预测模型。
参考文献
[1]王燕.应用时间序列分析
[2]徐国祥.统计预测和决策(第二版)
[3]赵蕾.ARIMA 模型在福建省GDP 预测中的应用 [4]中国统计年鉴2010,
附:
所用数据
程序
data new;
input s;
t=_n_;
cards;
146.99
178.01
191.72
209.68
232.52
257.43
287.29
349.95
397.68
469.44
584.07
640.80
744.44
833.30
986.98
1244.71
1650.02
2132.13
2540.13
2849.27
3025.53
3214.54
3551.49
3831.90
4151.54
4659.99
5641.94
6596.10
7688.67
9439.60
11555.00
13059.69
;
proc gplot data=new;
plot s*t;
symbol c=red v=circle i=jion; run;
proc arima data=new;
identify var=s nlag=8;
run;
data new;
input s;
difs=dif(s);
t=_n_;
cards;
数据
proc gplot data=new;
plot s*t difs*t;
symbol v=star c=black i=jion;
run;
proc arima data=new;
identify var=difs nlag=8;
run;
data new;
input s;
difs=dif(dif(s));
t=_n_;
cards;
数据
proc gplot data=new;
plot s*t difs*t;
symbol v=star c=black i=jion;
run;
proc arima data=new;
identify var=difs nlag=8;
run;
proc arima data=new;
identify var=difs nlag=8minic p=(0:5) q=(0:5); run;
data new;
input s;
difs=dif(dif(s));
t=_n_;
cards;
数据
proc arima data=new;
identify var=s(1,1) nlag=8;
estimate p=(0,2) ;
forecast lead=1out=jj;
run;
data new;
input s;
difs=dif(dif(s));
t=_n_;
cards;
数据
proc arima data=new;
identify var=s(1,1) nlag=8;
estimate p=(0,2) ;
forecast lead=1out=jj;
data r;
do t=1to33;
output;
end;
run;
data kk;
merge r jj;
run;
proc gplot data=kk;
plot s*t=1 forecast*t=2 l95*t=3 u95*t=3/overlay; symbol1c=black i=none v=star;
symbol2c=red i=jion v=none;
symbol3c=green i=jion v=none l=32;
run;
时间序列分析——最经典的
【时间简“识”】 说明:本文摘自于经管之家(原人大经济论坛) 作者:胖胖小龟宝。原版请到经管之家(原人大经济论坛) 查看。 1.带你看看时间序列的简史 现在前面的话—— 时间序列作为一门统计学,经济学相结合的学科,在我们论坛,特别是五区计量经济学中是热门讨论话题。本月楼主推出新的系列专题——时间简“识”,旨在对时间序列方面进行知识扫盲(扫盲,仅仅扫盲而已……),同时也想借此吸引一些专业人士能够协助讨论和帮助大家解疑答惑。 在统计学的必修课里,时间序列估计是遭吐槽的重点科目了,其理论性强,虽然应用领域十分广泛,但往往在实际操作中会遇到很多“令人发指”的问题。所以本帖就从基础开始,为大家絮叨絮叨那些关于“时间”的故事! Long long ago,有多long估计大概7000年前吧,古埃及人把尼罗河涨落的情况逐天记录下来,这一记录也就被我们称作所谓的时间序列。记录这个河流涨落有什么意义当时的人们并不是随手一记,而是对这个时间序列进行了长期的观察。结果,他们发现尼罗河的涨落非常有规律。掌握了尼罗河泛滥的规律,这帮助了古埃及对农耕和居所有了规划,使农业迅速发展,从而创建了埃及灿烂的史前文明。
好~~从上面那个故事我们看到了 1、时间序列的定义——按照时间的顺序把随机事件变化发展的过程记录下来就构成了一个时间序列。 2、时间序列分析的定义——对时间序列进行观察、研究,找寻它变化发展的规律,预测它将来的走势就是时间序列分析。 既然有了序列,那怎么拿来分析呢 时间序列分析方法分为描述性时序分析和统计时序分析。 1、描述性时序分析——通过直观的数据比较或绘图观测,寻找序列中蕴含的发展规律,这种分析方法就称为描述性时序分析 描述性时序分析方法具有操作简单、直观有效的特点,它通常是人们进行统计时序分析的第一步。 2、统计时序分析 (1)频域分析方法 原理:假设任何一种无趋势的时间序列都可以分解成若干不同频率的周期波动 发展过程: 1)早期的频域分析方法借助富里埃分析从频率的角度揭示时间序列的规律 2)后来借助了傅里叶变换,用正弦、余弦项之和来逼近某个函数 3)20世纪60年代,引入最大熵谱估计理论,进入现代谱分析阶段 特点:非常有用的动态数据分析方法,但是由于分析方法复杂,结果抽象,有一定的使用局限性 (2)时域分析方法
时间序列分析与建模简介
第五章时间序列分析与建模简介 时间序列建模( Modelling via time series )。时间序列分析与建模是数理统计的重要分支,其主要学术贡献人是Box 和 Jenkins。本章扼要介绍吴宪民和 Pandit的工作,仅要求一般了解当前时间序列分析与建模的一些主要结果。参考书:“时间序列及系统分析与应用(美)吴宪民,机械工业出版社(1988)TP13/66。 引言 根据对系统观测得出的按照时间顺序排列的数据,通过曲线拟合和参数估计或者谱分析,建立数学模型的理论与方法,理论基础是数理统计。有时域和频域两类建模方法,这里概括介绍时域方法,即基于曲线拟合与参数估计(如最小二乘法)的方法。常用于经济系统建模(如市场预测、经济规划)、气象与水文预报、环境与地震信号处理和天文等学科的信号处理等等。 §5—1 ARMA模型分析 一、模型类 把具有相关性的观测数据组成的时间序列{ x k }视为以正态同分布白噪声序列{ a k }为 输入的动态系统的输出。用差分模型ARMA (n,m) 为(z-1) x k = (z-1) a k 式(5-1-1) 其中: (z-1) = 1- 1 z-1-…- n z-n (z-1) = 1- 1 z-1-…- m z-m
离散传函 式(5-1-2) 为与参考书符号一致,以下用B表示时间后移算子 即: B x k = x k-1 B即z-1,B2即z-2… (B)=0的根为系统的极点,若全部落在单位园内则系统稳定;(B)=0的根为系统的零点,若全部在单位园内则系统逆稳定。 二、关于格林函数和时间序列的稳定性 1.格林函数G i 格林函数G i 用以把x t 表示成a t 及a t 既往值的线性组合。 式(5-1-3) G I 可以由下式用长除法求得: 例1.AR(1): x t - 1 x t-1 = a t 即: G j = 1 j(显示) 例2.ARMA (1,1): x t - 1 x t-1 = a t - 1 a t G 0= 1 ; G j =( 1 - 1 ) 1 j-1 ,j 1 (显示) ∑∞=- = j j t j t a G x
时间序列分析法原理及步骤
时间序列分析法原理及步骤 ----目标变量随决策变量随时间序列变化系统 一、认识时间序列变动特征 认识时间序列所具有的变动特征, 以便在系统预测时选择采用不同的方法 1》随机性:均匀分布、无规则分布,可能符合某统计分布(用因变量的散点图和直方图及其包含的正态分布检验随机性, 大多服从正态分布 2》平稳性:样本序列的自相关函数在某一固定水平线附近摆动, 即方差和数学期望稳定为常数 识别序列特征可利用函数 ACF :其中是的 k 阶自 协方差,且 平稳过程的自相关系数和偏自相关系数都会以某种方式衰减趋于 0, 前者测度当前序列与先前序列之间简单和常规的相关程度, 后者是在控制其它先前序列的影响后,测度当前序列与某一先前序列之间的相关程度。实际上, 预测模型大都难以满足这些条件, 现实的经济、金融、商业等序列都是非稳定的,但通过数据处理可以变换为平稳的。 二、选择模型形式和参数检验 1》自回归 AR(p模型
模型意义仅通过时间序列变量的自身历史观测值来反映有关因素对预测目标的影响和作用,不受模型变量互相独立的假设条件约束,所构成的模型可以消除普通回归预测方法中由于自变量选择、多重共线性的比你更造成的困难用 PACF 函数判别 (从 p 阶开始的所有偏自相关系数均为 0 2》移动平均 MA(q模型 识别条件
平稳时间序列的偏相关系数和自相关系数均不截尾,但较快收敛到 0, 则该时间序列可能是 ARMA(p,q模型。实际问题中,多数要用此模型。因此建模解模的主要工作时求解 p,q 和φ、θ的值,检验和的值。 模型阶数 实际应用中 p,q 一般不超过 2. 3》自回归综合移动平均 ARIMA(p,d,q模型 模型含义 模型形式类似 ARMA(p,q模型, 但数据必须经过特殊处理。特别当线性时间序列非平稳时,不能直接利用 ARMA(p,q模型,但可以利用有限阶差分使非平稳时间序列平稳化,实际应用中 d (差分次数一般不超过 2. 模型识别 平稳时间序列的偏相关系数和自相关系数均不截尾,且缓慢衰减收敛,则该时间序列可能是 ARIMA(p,d,q模型。若时间序列存在周期性波动, 则可按时间周期进
数据分析-时间序列的趋势分析
数据分析-时间序列的趋势分析 无论是网站分析工具、BI报表或者数据的报告,我们很难看到数据以孤立的点单独地出现,通常数据是以序列、分组等形式存在,理由其实很简单,我们没法从单一的数据中发现什么,用于分析的数据必须包含上下文(Context)。数据的上下文就像为每个指标设定了一个或者一些参考系,通过这些参照和比较的过程来分析数据的优劣,就像中学物理上的例子,如果我们不以地面作为参照物,我们无法区分火车是静止的还是行进的,朝北开还是朝南开。 在实际看数据中,我们可能已经在不经意间使用数据的上下文了,趋势分析、比例分析、细分与分布等都是我们在为数据设置合适的参照环境。所以这边通过一个专题——数据的上下文,来总结和整理我们在日常的数据分析中可以使用的数据参考系,前面几篇主要是基于内部基准线(Internal Benchmark)的制定的,后面会涉及外部基准线(External Benchmark)的制定。今天这篇是第一篇,主要介绍基于时间序列的趋势分析,重提下同比和环比,之前在网站新老用户分析这篇文章,已经使用同比和环比举过简单应用的例子。 同比和环比的定义 定义这个东西在这里还是再唠叨几句,因为不了解定义就无法应用,熟悉的朋友可以跳过。 同比:为了消除数据周期性波动的影响,将本周期内的数据与之前周期中相同时间点的数据进行比较。早期的应用是销售业等受季节等影响较严重,为了消除趋势分析中季节性的影响,引入了同比的概念,所以较多地就是当年的季度数据或者月数据与上一年度同期的比较,计算同比增长率。 环比:反应的是数据连续变化的趋势,将本期的数据与上一周期的数据进行对比。最常见的是这个月的数据与上个月数据的比较,计算环比增长率,因为数据都是与之前最近一个周期的数据比较,所以是用于观察数据持续变化的情况。 买二送一,再赠送一个概念——定基比(其实是百度百科里附带的):将所有的数据都与某个基准线的数据进行对比。通常这个基准线是公司或者产品发展的一个里程碑或者重要数据点,将之后的数据与这个基准线进行比较,从而反映公司在跨越这个重要的是基点后的发展状况。 同比和环比的应用环境
时间序列分析
3.3时间序列分析 3.3.1时间序列概述 1.基本概念 (1)一般概念:系统中某一变量的观测值按时间顺序(时间间隔相同)排列成一 个数值序列,展示研究对象在一定时期内的变动过程,从中寻找 和分析事物的变化特征、发展趋势和规律。它是系统中某一变量 受其它各种因素影响的总结果。 (2)研究实质:通过处理预测目标本身的时间序列数据,获得事物随时间过程的 演变特性与规律,进而预测事物的未来发展。它不研究事物之间 相互依存的因果关系。 (3)假设基础:惯性原则。即在一定条件下,被预测事物的过去变化趋势会延续 到未来。暗示着历史数据存在着某些信息,利用它们可以解释与 预测时间序列的现在和未来。 近大远小原理(时间越近的数据影响力越大)和无季节性、无趋 势性、线性、常数方差等。 (4)研究意义:许多经济、金融、商业等方面的数据都是时间序列数据。 时间序列的预测和评估技术相对完善,其预测情景相对明确。 尤其关注预测目标可用数据的数量和质量,即时间序列的长度和 预测的频率。 2.变动特点 (1)趋势性:某个变量随着时间进展或自变量变化,呈现一种比较缓慢而长期的 持续上升、下降、停留的同性质变动趋向,但变动幅度可能不等。
(2)周期性:某因素由于外部影响随着自然季节的交替出现高峰与低谷的规律。 (3)随机性:个别为随机变动,整体呈统计规律。 (4)综合性:实际变化情况一般是几种变动的叠加或组合。预测时一般设法过滤 除去不规则变动,突出反映趋势性和周期性变动。 3.特征识别 认识时间序列所具有的变动特征,以便在系统预测时选择采用不同的方法。(1)随机性:均匀分布、无规则分布,可能符合某统计分布。(用因变量的散点图 和直方图及其包含的正态分布检验随机性,大多数服从正态分布。) (2)平稳性:样本序列的自相关函数在某一固定水平线附近摆动,即方差和数学 期望稳定为常数。 样本序列的自相关函数只是时间间隔的函数,与时间起点无关。其 具有对称性,能反映平稳序列的周期性变化。 特征识别利用自相关函数ACF:ρ k =γ k /γ 其中γk是y t 的k阶自协方差,且ρ0=1、-1<ρk<1。 平稳过程的自相关系数和偏自相关系数都会以某种方式衰减趋近于0,前者测度当前序列与先前序列之间简单和常规的相关程度, 后者是在控制其它先前序列的影响后,测度当前序列与某一先前序 列之间的相关程度。 实际上,预测模型大都难以满足这些条件,现实的经济、金融、商业等序列都是非稳定的,但通过数据处理可以变换为平稳的。 4.预测类型 (1)点预测:确定唯一的最好预测数值,其给出了时间序列未来发展趋势的一个
季节性时间序列分析方法
第七章季节性时间序列分析方法 由于季节性时间序列在经济生活中大量存在,故将季节时间序列从非平稳序列中抽出来,单独作为一章加以研究,具有较强的现实意义。本章共分四节:简单随机时间序列模型、乘积季节模型、季节型时间序列模型的建立、季节调整方法X-11程序。 本章的学习重点是季节模型的一般形式和建模。 §1 简单随机时序模型 在许多实际问题中,经济时间序列的变化包含很多明显的周期性规律。比如:建筑施工在冬季的月份当中将减少,旅游人数将在夏季达到高峰,等等,这种规律是由于季节性(seasonality)变化或周期性变化所引起的。对于这各时间数列我们可以说,变量同它上一年同一月(季度,周等)的值的关系可能比它同前一月的值的相关更密切。 一、季节性时间序列 1.含义:在一个序列中,若经过S个时间间隔后呈现出相似性,我们说该序列具有以S为周期的周期性特性。具有周期特性的序列就称为季节性时间序列,这里S为周期长度。 注:①在经济领域中,季节性的数据几乎无处不在,在许多场合,我们往往可以从直观的背景及物理变化规律得知季节性的周期,如季度数据(周期为4)、月度数据(周期为12)、周数据(周期为7);②有的时间序列也可能包含长度不同的若干种周期,如客运量数据(S=12,S=7) 2.处理办法: (1)建立组合模型; (1)将原序列分解成S个子序列(Buys-Ballot 1847)
对于这样每一个子序列都可以给它拟合ARIMA 模型,同时认为各个序列之间是相互独立的。但是这种做法不可取,原因有二:(1)S 个子序列事实上并不相互独立,硬性划分这样的子序列不能反映序列{}t x 的总体特征;(2)子序列的划分要求原序列的样本足够大。 启发意义:如果把每一时刻的观察值与上年同期相应的观察值相减,是否能将原序列的周期性变化消除?(或实现平稳化),在经济上,就是考查与前期相比的净增值,用数学语言来描述就是定义季节差分算子。 定义:季节差分可以表示为S t t t S t S t X X X B X W --=-=?=)1(。 二、 随机季节模型 1.含义:随机季节模型,是对季节性随机序列中不同周期的同一周期点之间的相关关系的一种拟合。 AR (1):t t S t S t t e W B e W W =-?+=-)1(11??,可以还原为:t t S S e X B =?-)1(1?。 MA (1):t S t S t t t e B W e e W )1(11θθ-=?-=-,可以还原为:t S t S e B X )1(1θ-=?。 2.形式:广而言之,季节型模型的ARMA 表达形式为 t S t S e B V W B U )()(= (1) 这里,?? ? ??----=----=?=qS q S S S pS P S S S t d S t B V B V B V B V B U B U B U B U X W ΛΛ2212211)(1)()(平稳。 注:(1)残差t e 的内容;(2)残差t e 的性质。 §2 乘积季节模型 一、 乘积季节模型的一般形式 由于t e 不独立,不妨设),,(~m d n ARIMA e t ,则有 t t d a B e B )()(Θ=?φ (2) 式中,t a 为白噪声;n n B B B B ???φ----=Λ22111)(;m m B B B B θθθ----=ΘΛ22111)(。 在(1)式两端同乘d B ?)(φ,可得: t S t d S t D S d S t d S a B B V e B B V X B U B W B U B )()()()()()()()(Θ=?=??=?φφφ (3) 注:(1)这里t D S S X B U ?)(表示不同周期的同一周期点上的相关关系;t d X B ?)(φ则表示同一周期内
时间序列分析简介与模型
第二篇 预测方法与模型 预测是研究客观事物未来发展方向与趋势的一门科学。统计预测是以统计调查资料为依据,以经济、社会、科学技术理论为基础,以数学模型为主要手段,对客观事物未来发展所作的定量推断和估计。根据社会、经济、科技的预测结论,人们可以调整发展战略,制定管理措施,平衡市场供求,进行各种各样的决策。预测也是制定政策,编制规划、计划,具体组织生产经营活动的科学基础。20世纪三四十年代以来,随着人类社会生产力水平的不断提高和科学技术的迅猛发展,特别是近年来以计算机为主的信息技术的飞速发展,更进一步推动了预测技术在国民经济、社会发展和科学技术各个领域的应用。 预测包含定性预测法、因果关系预测法和时间序列预测法三类。本篇对定性预测法不加以介绍,对后两类方法选择以下几种介绍方法的原理、模型的建立和实际应用,分别为:时间序列分析、微分方程模型、灰色预测模型、人工神经网络。 第五章 时间序列分析 在预测实践中,预测者们发现和总结了许多行之有效的预测理论和方法,但以概率统计理论为基础的预测方法目前仍然是最基本和最常用的方法。本章介绍其中的时间序列分析预测法。此方法是根据预测对象过去的统计数据找到其随时间变化的规律,建立时间序列模型,以推断未来数值的预测方法。时间序列分析在微观经济计量模型、宏观经济计量模型以及经济控制论中有广泛的应用。 第一节 时间序列简介 所谓时间序列是指将同一现象在不同时间的观测值,按时间先后顺序排列所形成的数列。时间序列一般用 ,,,,21n y y y 来表示,可以简记为}{t y 。它的时间单位可以是分钟、时、日、周、旬、月、季、年等。
一、时间序列预测法 时间序列预测法就是通过编制和分析时间序列,根据时间序列所反应出来的发展过程、方向和趋势,进行类推或延伸,借以预测下一段时间或以后若干年可能达到的水平。其容包括:收集与整理某种社会现象的历史资料;将这些资料进行检查鉴别,排成数列;分析时间序列,从中寻找该社会现象随时间变化而变化的规律,得出一定的模型,以此模型去预测该社会现象将来的情况。 二、时间序列数据的特点 通常,时间序列经过合理的函数变换后都可以看作是由三个部分叠加而成,这三个部分是趋势项部分、周期项部分和随机项部分。 1. 趋势性 许多序列的一个最主要的特征就是存在趋势。这种趋势可能是向下的也可能是向上的,也许比较陡,也许比较平缓,或者是指数增长,或者近似线性。总之,时间序列的趋势性是依据时间序列进行预测的本质所在。 2. 季节性/周期性 当数据按照月或季观测时,通常的情况是这样的:时间序列会呈现出明显的季节性。对季节性也不存在一个非常精确的定义。通常,当某个季节的观测值具有与其它季节的观测值明显不同的特征时,就称之为季节性。 3. 异常观测值 异常观测值指那些严重偏离趋势围的特殊点。异常观测值的出现往往是由于某些不可抗 1958 年自然灾害和1966年左右“文化大革命”对我国经拒的外部条件的影响。如1960 济的影响,造成经济指标陡然下降现象;1992年,我国银行紧缩政策造成的房地产业泡沫破灭,而使得房地产业的经济数据发生突然变化的例子等等。 4. 条件异方差性 所谓条件异方差性,表现出来就是异常数据观测值成群地出现,故也称为“波动积聚性”。由于方差是风险的测度,因此波动存在的积聚性的预测对于评估投资决策是很有用的,对于期权和其它金融衍生产品的买卖决策也是有益的。 5. 非线性 对非线性的最好定义就是“线性以外的一切”。非线性常常表现为“机制转换”(regime witches)或者“状态依赖”(State pendence)。其中状态依赖意味着时间序列的特征依赖于其现时的状态;不同的时刻,其特征不一样。当时间序列的特征在所有的离散状态都不一样时,就成为机制转换特性。 三、时间序列的分类 1. 按研究的对象的多少可分为单变量时间序列和多变量时间序列。 如果所研究的对象是一个变量,如某个国家的国生产总值,即为单变量时间序列。果所研究的对象是多个变量,如按年、月顺序排列的气温、气压、雨量数据,为多变量时间序列。多变量时间序列不仅描述了各个变量的变化规律,而且还表示了各变量间相互依存关系的动态规律性。 2. 按时间的连续性可将时间序列分为离散时间序列和连续时间序列。 如果某一序列中的每一个序列值所对应的时间参数为间断点,则该序列就是一个离散时间序列。如果某一序列中的每个序列值所对应的时间参数为连续函数,则该序列就是一个连续时间序列。 3. 按序列的统计特性可分为平稳时间序列和非平稳时间序列两类。
时间序列的平稳化处理方法
15.1.2 时间序列数据的平稳化处理 打开相应的数据文件或者建立一个数据文件后,可以在SPSS Statistics数据编辑器窗口中对时间序列数据进行平稳化。 1)在菜单栏中选择"转换"|"创建时间序列"命令,打开如图15-3所示的"创建时间序列"对话框。 2)选择变量。从源变量列表中选择需要进行平稳化处理的变量,然后单击按钮将选中的变量选入"变量->新名称"列表中。进入"变量->新名称"列表中的变量显示为"新变量名称=平稳函数(原变量名称顺序)"。 3)进行相应的设置。在"名称和函数"中可以对平稳处理后生成的新变量重命名并选择平稳化处理的方法,设置完毕后单击"更改"按钮就完成了新变量的命名和平稳化处理方法的选择。 SPSS提供了8种平稳处理的方法,各选项及其功能如表15-1所示。 表15-1 "函数"下拉列表框中的选项及功能 方法功能 差值指对非季度数据进行差分处理。其中,一阶差分即数据前一项减去后一项得到的值,因此一阶差分会损失第一个数据。同理,n阶差分会损失前n个数据。
在“顺序”文本框中输入差分的阶数。差分是时间序列非平稳数据平稳处理的最常用的方法, 特别是在ARIMA模型中 季节差分指对季节数据进行差分处理。其中,一阶差分指该 年份的第n季度的数据与下一年份第n季度的数据做 差。由于每年有四个季节,因此m阶差分就会损失m个数据 中心移动平均指以当期值为中心取指定跨度内的均值,在“跨度”文本框中指定取均值的范围。该方法比较 适用于正态分布的数据 先前移动平均指取当期值以前指定跨度内的均值,在“跨度”文本框中指定取均值的范围 运行中位数指以当期值为中心取指定跨度内的中位数,在“跨度”文本框中指定取中位数的范围。其中,该方法与 中心移动平均方法可互为替代 累计求和表示以原数据的累计求和值代替当期值 滞后表示以原始数据滞后值代替当期值,在“顺序”文本框中指定滞后阶数 提前表示以原始数据提前值代替当期值,在“顺序”文本框中指定提前阶数 平滑表示对原数据进行T4253H方法的平滑处理。该方 法首先对原数据依次进行跨度为4、2、5、3的中心移动平均处理,然后以Hanning为权重再做移动 平均处理,得到一个平滑时间序列 设置完毕后,单击"确定"按钮,就可以在SPSS Statistics数据视图和查看器窗口得到平稳处理的结果。
太阳黑子数时间序列分析数据
Re:【求助】请问谁有太阳黑子数据 只有1700-1987年的 年份黑子数: 1700 5.0 1701 11.0 1702 16.0 1703 23.0 1704 36.0 1705 58.0 1706 29.0 1707 20.0 1708 10.0 1709 8.0 1710 3.0 1711 0.0 1712 0.0 1713 2.0 1714 11.0 1715 27.0 1716 47.0 1717 63.0 1718 60.0 1719 39.0 1720 28.0 1721 26.0 1722 22.0 1723 11.0 1724 21.0 1725 40.0 1726 78.0 1727 122.0 1728 103.0 1729 73.0 1730 47.0 1731 35.0
1733 5.0 1734 16.0 1735 34.0 1736 70.0 1737 81.0 1738 111.0 1739 101.0 1740 73.0 1741 40.0 1742 20.0 1743 16.0 1744 5.0 1745 11.0 1746 22.0 1747 40.0 1748 60.0 1749 80.9 1750 83.4 1751 47.7 1752 47.8 1753 30.7 1754 12.2 1755 9.6 1756 10.2 1757 32.4 1758 47.6 1759 54.0 1760 62.9 1761 85.9 1762 61.2 1763 45.1 1764 36.4 1765 20.9 1766 11.4 1767 37.8
计量经济学--时间序列数据分析
时间序列数据的计量分析方法 1.时间序列平稳性问题及处理方案 1.1序列平稳性的定义 从平稳时间序列中任取一个随机变量集,并把这个序列向前移动h 个时期,那么其联合概率分布仍然保持不变。 平稳时间序列要求所有序列间任何相邻两项之间的相关关系有相同的性质。 1.2不平稳序列的后果 可能两个变量本身不存在关系而仅仅因为有相似的时间趋势而得出它有关系,也就是出现伪回归;破坏回归分析的假设条件,使得回归结果和各种检验结果不可信。 1.3平稳性检验方法:ADF 检验 1.3.1ADF 检验的假设: 辅助回归方程:11t t i t i t i Y Y t Y ραργβμ--==+++?+∑(是否有截距和时间趋势项 在做检验时要做选择) 原假设:H 0:p=0,存在单位根 备择假设:H 1:P<0,不存在单位根 结果识别方法:ADF Test Statistic 值小于显著性水平的临界值,或者P 值小于显著性水平则拒绝原假设并得出结论:所检测序列不存在单位根,即序列是平稳序列。 1.3.2实例 对1978年2008年的中国GDP 数据进行ADF 检验,结果如表一。 表一 ADF 检验结果 Augmented Dickey-Fuller test statistic t-Statistic Prob.* 3.063621 1 Test critical values: 1% level -3.699871 5% level -2.976263 10% level -2.62742 从结果可以看出,ADF 的t 统计量值大于10%显著性水平上的临界值,P 值为1,接受原假设,说明所检测的GDP 数据是不平稳序列。 1.4不平稳序列的处理方法 1.4.1方法 如果所要分析的数据是不平稳序列,可以对序列进行差分使其变成平稳序列,但是这样做的后果是使新得出的数据丧失了许多原序列的特征,我们能从数据中得到的信息会变少,通常差分的次数不能超过两次。 经验表明,存量数据是二阶单整,做二次差分可以使其平稳,流量数据是一阶单整,做一次差分可以使其平稳,增量数据通常就是平稳序列。 1.4.2实例
用EVIEWS处理时间序列分析
应用时间序列分析 实验手册
目录 目录 (2) 第二章时间序列的预处理 (3) 一、平稳性检验 (3) 二、纯随机性检验 (9) 第三章平稳时间序列建模实验教程 (10) 一、模型识别 (10) 二、模型参数估计(如何判断拟合的模型以及结果写法) (14) 三、模型的显著性检验 (17) 四、模型优化 (18) 第四章非平稳时间序列的确定性分析 (19) 一、趋势分析 (19) 二、季节效应分析 (34) 三、综合分析 (38) 第五章非平稳序列的随机分析 (44) 一、差分法提取确定性信息 (44) 二、ARIMA模型 (57) 三、季节模型 (62)
第二章时间序列的预处理 一、平稳性检验 时序图检验和自相关图检验 (一)时序图检验 根据平稳时间序列均值、方差为常数的性质,平稳序列的时序图应该显示出该序列始终在一个常数值附近随机波动,而且波动的范围有界、无明显趋势及周期特征 例2.1 检验1964年——1999年中国纱年产量序列的平稳性 1.在Eviews软件中打开案例数据 图1:打开外来数据 图2:打开数据文件夹中案例数据文件夹中数据
文件中序列的名称可以在打开的时候输入,或者在打开的数据中输入 图3:打开过程中给序列命名 图4:打开数据
2.绘制时序图 可以如下图所示选择序列然后点Quick选择Scatter或者XYline;绘制好后可以双击图片对其进行修饰,如颜色、线条、点等 图1:绘制散点图 图2:年份和产出的散点图
100 200300400 5006001960 1970198019902000 YEAR O U T P U T 图3:年份和产出的散点图 (二)自相关图检验 例2.3 导入数据,方式同上; 在Quick 菜单下选择自相关图,对Qiwen 原列进行分析; 可以看出自相关系数始终在零周围波动,判定该序列为平稳时间序列。 图1:序列的相关分析
数据分析时间序列的趋势分析
数据分析时间序列的趋 势分析 Pleasure Group Office【T985AB-B866SYT-B182C-BS682T-STT18】
数据分析-时间序列的趋势分析无论是网站分析工具、BI报表或者数据的报告,我们很难看到数据以孤立的点单独地出现,通常数据是以序列、分组等形式存在,理由其实很简单,我们没法从单一的数据中发现什么,用于分析的数据必须包含上下文(Context)。数据的上下文就像为每个指标设定了一个或者一些参考系,通过这些参照和比较的过程来分析数据的优劣,就像中学物理上的例子,如果我们不以地面作为参照物,我们无法区分火车是静止的还是行进的,朝北开还是朝南开。 在实际看数据中,我们可能已经在不经意间使用数据的上下文了,趋势分析、比例分析、细分与分布等都是我们在为数据设置合适的参照环境。所以这边通过一个专题——数据的上下文,来总结和整理我们在日常的数据分析中可以使用的数据参考系,前面几篇主要是基于内部基准线(Internal Benchmark)的制定的,后面会涉及外部基准线(External Benchmark)的制定。今天这篇是第一篇,主要介绍基于时间序列的趋势分析,重提下同比和环比,之前在网站新老用户分析这篇文章,已经使用同比和环比举过简单应用的例子。 同比和环比的定义 定义这个东西在这里还是再唠叨几句,因为不了解定义就无法应用,熟悉的朋友可以跳过。 同比:为了消除数据周期性波动的影响,将本周期内的数据与之前周期中相同时间点的数据进行比较。早期的应用是销售业等受季节等影响较严重,为了消除趋势分析中季节性的影响,引入了同比的概念,所以较多地就是当年的季度数据或者月数据与上一年度同期的比较,计算同比增长率。
统计学中常用的数据分析方法8时间序列分析
统计学中常用的数据分析方法 时间序列分析 动态数据处理的统计方法,研究随机数据序列所遵从的统计规律,以用于解决实际问题;时间序列通常由4种要素组成:趋势、季节变动、循环波动和不规则波动。 主要方法:移动平均滤波与指数平滑法、ARIMA横型、量ARIMA 横型、ARIMAX模型、向呈自回归横型、ARCH族模型 时间序列是指同一变量按事件发生的先后顺序排列起来的一组观察值或记录值。构成时间序列的要素有两个:其一是时间,其二是与时间相对应的变量水平。实际数据的时间序列能够展示研究对象在一定时期内的发展变化趋势与规律,因而可以从时间序列中找出变量变化的特征、趋势以及发展规律,从而对变量的未来变化进行有效地预测。 时间序列的变动形态一般分为四种:长期趋势变动,季节变动,循环变动,不规则变动。 时间序列预测法的应用: 系统描述:根据对系统进行观测得到的时间序列数据,用曲线拟合方法对系统进行客观的描述; 系统分析:当观测值取自两个以上变量时,可用一个时间序列中的变化去说明另一个时间序列中的变化,从而深入了解给定时间序列产生的机理; 预测未来:一般用ARMA模型拟合时间序列,预测该时间序列未来值; 决策和控制:根据时间序列模型可调整输入变量使系统发展过程保持在目标值上,即预测到过程要偏离目标时便可进行必要的控制。 特点: 假定事物的过去趋势会延伸到未来; 预测所依据的数据具有不规则性; 撇开了市场发展之间的因果关系。 ①时间序列分析预测法是根据市场过去的变化趋势预测未来的发展,它的前提是假定事物的过去会同样延续到未来。事物的现实是历史发展的结果,而事物的未来又是现实的延伸,事物的过去和未来是有联系的。市场预测的时间序列分析法,正是根据客观事物发展的这种连续规律性,运用过去的历史数据,通过统计分析,进一步推测市场未来的发展趋势。市场预测中,事物的过去会同样延续到未来,其意思是说,市场未来不会发生突然跳跃式变化,而是渐进变化的。 时间序列分析预测法的哲学依据,是唯物辩证法中的基本观点,即认为一切事物都是发展变化的,事物的发展变化在时间上具有连续性,市场现象也是这样。市场现象过去和现在的发展变化规律和发展水平,会影响到市场现象未来的发展变化规律和规模水平;市场现象未来的变化规律和水平,是市场现象过去和现在变化规律和发展水平的结果。
时间序列分析
时间序列分析 时间序列分析(Time series analysis)是一种动态数据处理的统计方法。该方法基于随机过程理论和数理统计学方法,研究随机数据序列所遵从的统计规律,以用于解决实际问题。 时间序列分析简介 它包括一般统计分析(如自相关分析,谱分析等),统计模型的建立与推断,以及关于时间序列的最优预测、控制与滤波等内容。经典的统计分析都假定数据序列具有独立性,而时间序列分析则侧重研究数据序列的互相依赖关系。后者实际上是对离散指标的随机过程的统计分析,所以又可看作是随机过程统计的一个组成部分。例如,记录了某地区第一个月,第二个月,……,第N个月的降雨量,利用时间序列分析方法,可以对未来各月的雨量进行预报。 随着计算机的相关软件的开发,数学知识不再是空谈理论,时间序列分析主要是建立在数理统计等知识之上,应用相关数理知识在相关方面的应用等。 时间序列分析参考 编辑 参考自:科学技术方法大辞典 时间序列是按时间顺序的一组数字序列。时间序列分析就是利用这组数列,应用数理统计方法加以处理,以预测未来事物的发展。时间序列分析是定量预测方法之一,它的基本原理:一是承认事物发展的延续性。应用过去数据,就能推测事物的发展趋势。二是考虑到事物发展的随机性。任何事物发展都可能受偶然因素影响,为此要利用统计分析中加权平均法对历史数据进行处理。该方法简单易行,便于掌握,但准确性差,一般只适用于短期预测。时间序列预测一般反映三种实际变化规律:趋势变化、周期性变化、随机性变化。 时间序列分析是根据系统观测得到的时间序列数据,通过曲线拟合和参数估计来建立数学模型的理论和方法。它一般采用曲线拟合和参数估计方法(如非线性最小二乘法)进行。时间序列分析常用在国民经济宏观控制、区域综合发展规划、企业经营管理、市场潜量预测、气象预报、水文预报、地震前兆预报、农作物病虫灾害预报、环境污染控制、生态平衡、天文学和海洋学等方面。 时间序列分析组成要素 一个时间序列通常由4种要素组成:趋势、季节变动、循环波动和不规则波动。 趋势:是时间序列在长时期内呈现出来的持续向上或持续向下的变动。 季节变动:是时间序列在一年内重复出现的周期性波动。它是诸如气候条件、生产条件、节假日或人们的风俗习惯等各种因素影响的结果。 循环波动:是时间序列呈现出得非固定长度的周期性变动。循环波动的周期可能会持续一段时间,但与趋势不同,它不是朝着单一方向的持续变动,而是涨落相同的交替波动。 不规则波动:是时间序列中除去趋势、季节变动和周期波动之后的随机波动。不规则波动通常总是夹杂在时间序列中,致使时间序列产生一种波浪形或震荡式的变动。只含有随机波动的序列也称为平稳序列。 时间序列分析基本步骤 时间序列建模基本步骤是: ①用观测、调查、统计、抽样等方法取得被观测系统时间序列动态数据。
时间序列分析方法
深圳大学研究生课程论文 题目对时间序列分析方法的学习报告成绩 专业软件工程(春) 课程名称、代码数据库与数据挖掘142201013021 年级2013 姓名朱文静 学号20134313005 时间2014 年11 月 任课教师傅向华
1时间序列分析方法及其应用综述 1.1时间序列分析概念 时间序列分析(Time series analysis)是一种动态数据处理的统计方法。该方法基于随机过程理论和数理统计学方法,研究随机数据序列所遵从的统计规律,以用于解决实际问题。 时间序列是按时间顺序的一组数字序列。时间序列分析就是利用这组数列,应用数理统计方法加以处理,以预测未来事物的发展。时间序列分析是定量预测方法之一,它的基本原理:一是承认事物发展的延续性。应用过去数据,就能推测事物的发展趋势。二是考虑到事物发展的随机性。任何事物发展都可能受偶然因素影响,为此要利用统计分析中加权平均法对历史数据进行处理。该方法简单易行,便于掌握,但准确性差,一般只适用于短期预测。时间序列预测一般反映三种实际变化规律:趋势变化、周期性变化、随机性变化。 时间序列分析是根据系统观测得到的时间序列数据,通过曲线拟合和参数估计来建立数学模型的理论和方法。它一般采用曲线拟合和参数估计方法(如非线性最小二乘法)进行。时间序列分析常用在国民经济宏观控制、区域综合发展规划、企业经营管理、市场潜量预测、气象预报、水文预报、地震前兆预报、农作物病虫灾害预报、环境污染控制、生态平衡、天文学和海洋学等方面。 1.2时间序列分析特点 时间序列分析预测法是根据市场过去的变化趋势预测未来的发展,它的前提是假定事物的过去会同样延续到未来。事物的现实是历史发展的结果,而事物的未来又是现实的延伸,事物的过去和未来是有联系的。市场预测的时间序列分析法,正是根据客观事物发展的这种连续规律性,运用过去的历史数据,通过统计分析,进一步推测市场未来的发展趋势。市场预测中,事物的过去会同样延续到未来,其意思是说,市场未来不会发生突然跳跃式变化,而是渐进变化的。 时间序列分析预测法的哲学依据,是唯物辩证法中的基本观点,即认为一切事物都是发展变化的,事物的发展变化在时间上具有连续性,市场现象也是这样。市场现象过去和现在的发展变化规律和发展水平,会影响到市场现象未来的发展变化规律和规模水平;市场现象未来的变化规律和水平,是市场现象过去和现在变化规律和发展水平的结果。 由于事物的发展不仅有连续性的特点,而且又是复杂多样的。因此,在应用时间序列分析法进行市场预测时应注意市场现象未来发展变化规律和发展水平,不一定与其历史和现在的发展变化规律完全一致。随着市场现象的发展,它还会出现一些新的特点。因此,在时间序列分析预测中,决不能机械地按市场现象过去和现在的规律向外延伸。必须要研究分析市场现象变化的新特点,新表现,并且将这些新特点和新表现充分考虑在预测值内。这样才能对市场现象做出既延续其历史变化规律,又符合其现实表现的可靠的预测结果。 时间序列分析预测法突出了时间因素在预测中的作用,暂不考虑外界具体因素的影响。时间序列在时间序列分析预测法处于核心位置,没有时间序列,就没
时间序列分析报告
时间序列分析报告
一.模型变量的选择和数据的出处 报告内的数据是1978年到2014年的浙江地区生产总值的原始数据。该数据来源于中华人民共和国国家统计局官网:(https://www.wendangku.net/doc/9f229089.html,/) 年份浙江地区生产总值 1978 123.72 1979 157.75 1980 179.92 1981 204.86 1982 234.01 1983 257.09 1984 323.25 1985 429.16 1986 502.47 1987 606.99 1988 770.25 1989 849.44 1990 904.69 1991 1089.33 1992 1375.7 1993 1925.91 1994 2689.28 1995 3557.55 1996 4188.53 1997 4686.11 1998 5052.62 1999 5443.92 2000 6141.03 2001 6898.34 2002 8003.67 2003 9705.02 2004 11648.7 2005 13417.68 2006 15718.47 2007 18753.73 2008 21462.69 2009 22990.35 2010 27722.31 2011 32318.85 2012 34665.33 2013 37756.59 2014 40153.5
二.将数据输入SAS程序data sas1; input year x; cards; 1978 123.72 1979 157.75 1980 179.92 1981 204.86 1982 234.01 1983 257.09 1984 323.25 1985 429.16 1986 502.47 1987 606.99 1988 770.25 1989 849.44 1990 904.69 1991 1089.33 1992 1375.7 1993 1925.91 1994 2689.28 1995 3557.55 1996 4188.53 1997 4686.11 1998 5052.62 1999 5443.92 2000 6141.03 2001 6898.34 2002 8003.67 2003 9705.02 2004 11648.7 2005 13417.68 2006 15718.47 2007 18753.73 2008 21462.69 2009 22990.35 2010 27722.31 2011 32318.85 2012 34665.33 2013 37756.59 2014 40153.5 ; run; proc print data=sas1; run;
数据分析 时间序列的趋势分析
数据分析-时间序列的趋势分析无论是网站分析工具、BI报表或者数据的报告,我们很难看到数据以孤立的点单独地出现,通常数据是以序列、分组等形式存在,理由其实很简单,我们没法从单一的数据中发现什么,用于分析的数据必须包含上下文(Context)。数据的上下文就像为每个指标设定了一个或者一些参考系,通过这些参照和比较的过程来分析数据的优劣,就像中学物理上的例子,如果我们不以地面作为参照物,我们无法区分火车是静止的还是行进的,朝北开还是朝南开。 在实际看数据中,我们可能已经在不经意间使用数据的上下文了,趋势分析、比例分析、细分与分布等都是我们在为数据设置合适的参照环境。所以这边通过一个专题——数据的上下文,来总结和整理我们在日常的数据分析中可以使用的数据参考系,前面几篇主要是基于内部基准线(Internal Benchmark)的制定的,后面会涉及外部基准线(External Benchmark)的制定。今天这篇是第一篇,主要介绍基于时间序列的趋势分析,重提下同比和环比,之前在网站新老用户分析这篇文章,已经使用同比和环比举过简单应用的例子。 同比和环比的定义 定义这个东西在这里还是再唠叨几句,因为不了解定义就无法应用,熟悉的朋友可以跳过。 同比:为了消除数据周期性波动的影响,将本周期内的数据与之前周期中相同时间点的数据进行比较。早期的应用是销售业等受季节等影响较严重,为了消除趋势分析中季节性的影响,引入了同比的概念,所以较多地就
是当年的季度数据或者月数据与上一年度同期的比较,计算同比增长率。 环比:反应的是数据连续变化的趋势,将本期的数据与上一周期的数据进行对比。最常见的是这个月的数据与上个月数据的比较,计算环比增长率,因为数据都是与之前最近一个周期的数据比较,所以是用于观察数据持续变化的情况。 买二送一,再赠送一个概念——定基比(其实是百度百科里附带的):将所有的数据都与某个基准线的数据进行对比。通常这个基准线是公司或者产品发展的一个里程碑或者重要数据点,将之后的数据与这个基准线进行比较,从而反映公司在跨越这个重要的是基点后的发展状况。 同比和环比的应用环境 其实同比、环比没有严格的适用范围或者针对性的应用,一切需要分析在时间序列上的变化情况的数据或者指标都可以使用同比和环比。 但是我的建议是为网站的目标指标建立同比和环比的数据上下文,如网站的收益、网站的活跃用户数、网站的关键动作数等,这类指标需要明确长期的增长趋势,同比和环比能够为网站整体运营的发展状况提供有力的参考。 还有个建议就是不要被同比和环比最原始或者最普遍的应用所束缚住:同比就是今年每个月或每季度的数据与去年同期比,环比就是这个月的数据与上个月比。对于方法的应用需要根据实际的应用的环境,进行合理的变通,选择最合适的途径。所以同比和环比不一定以年为周期,也不一定是每月、季度为时间粒度的统计数据,我们可以根据需要选择任意合适的周期,比如你们公司的产品运营是以周、半月、甚至每年的特定几个月为周期循环变动,