时间序列计量经济模型

10.1
1) 画出利润和红利的散点图,并直观地考察这两个时间序列是否是平稳的。
(A表示利润,B表示红利)
利润和红利的散点图如下:
表1 利润的散点图图2 红利的散点图
由图1以及图2可以看出,利润和红利的均值与方差不稳定,因此可能是非平稳的。
2)应用单位根检验分别检验利润和红利两个序列是否是平稳的。
利润序列有截距项,在EViews中选取截距项,同时最大之后长度取11进行单位根检验,检验结果如下:
t统计量大于所有显著水平下的MacKinnon临界值,故不能拒绝原假设,该序列是不平稳的。红利序列有截距项,在EViews中选取截距项,同时最大之后长度取11进行单位根检验,检验结果如下:
t统计量大于所有显著水平下的MacKinnon临界值,故不能拒绝原假设,该序列是不平稳的。
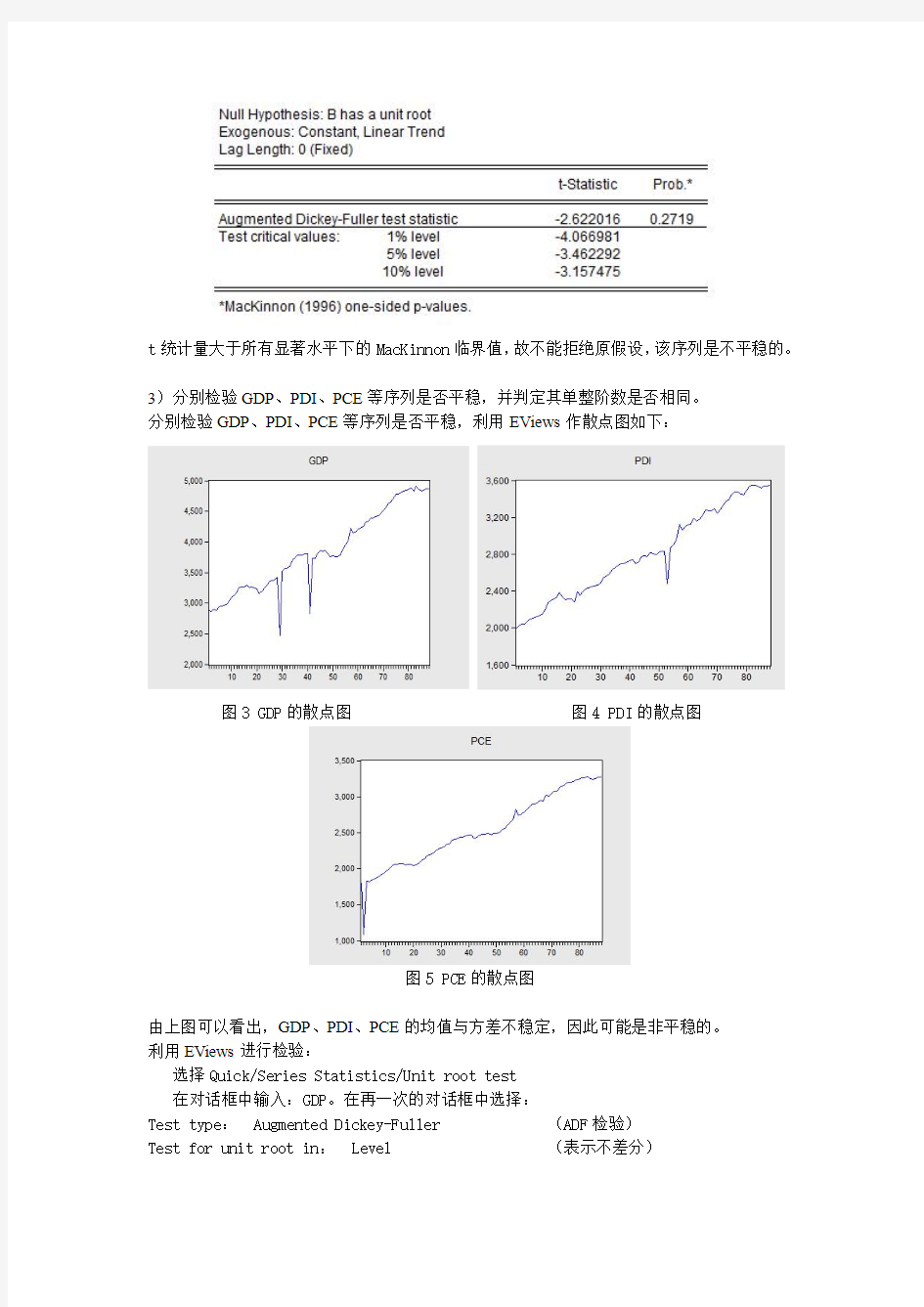
3)分别检验GDP、PDI、PCE等序列是否平稳,并判定其单整阶数是否相同。
分别检验GDP、PDI、PCE等序列是否平稳,利用EViews作散点图如下:
图3 GDP的散点图图4 PDI的散点图
图5 PCE的散点图
由上图可以看出,GDP、PDI、PCE的均值与方差不稳定,因此可能是非平稳的。
利用EViews进行检验:
选择Quick/Series Statistics/Unit root test
在对话框中输入:GDP。在再一次的对话框中选择:
Test type: Augmented Dickey-Fuller (ADF检验)
Test for unit root in: Level (表示不差分)
Include in test equation: Trend and intercept (含常数项和趋势项)
User specified: 0 (指p=1,即AR(1))出现表格:
t统计量小于所有显著水平下的MacKinnon临界值,故可以拒绝原假设,该序列是平稳的。
t统计量小于所有显著水平下的MacKinnon临界值,故可以拒绝原假设,该序列是不平稳的。
t统计量小于所有显著水平下的MacKinnon临界值,故可以拒绝原假设,该序列是不平稳的。综上所述,GDP、PDI、PCE序列是平稳的。
在Eviews中输入数据表,并给数据序列命名:GDP。
点击Quick/Series Statistics/Correlogram (相关图)
出现对话框,选择:Level (表示不差分),
在Lags to include(滞后阶数p) 中输入: 30。(一般p 取[n/10] 或[n/4] ,n 为样本量)。 单击ok, 得到
图6 Correlodram of GDP
自相关图缓慢衰减到0(落于置信区间以内), 偏相关图表现出一阶截尾特征(K>1后的值落于置信区间以内)。自相关函数呈现拖尾,偏相关函数在k > 1后的值在零的附近波动。因此可以认为该序列为 AR(1) 序列:
11t t t Y Y φμ-=+
利用同样的方法可以得到:
图7 Correlodram of PDI
图8 Correlodram of PCE
自相关图缓慢衰减到0(落于置信区间以内), 偏相关图表现出一阶截尾特征(K>1后的值落于置信区间以内)。自相关函数呈现拖尾,偏相关函数在k > 1后的值在零的附近波动。因此可以认为该序列为AR(1) 序列。
综上所述,GDP、PDI、PCE的单整阶数是相同的。
计量经济学——时间序列
课程论文 题目:第三产业产值的影响因素分析 学院财会学院_ 专业会计专硕 班级会计专硕1501 课程名称计量经济学(课程设计) 学号 学生姓名 60 指导教师赵卫亚 成绩 二○一五年十二月
第三产业产值的影响因素分析 摘要:本文利用计量经济分析方法和1990—2010年的时间序列统计资料,建立了我国第三产业产值影响因素模型。建模过程中,处理了模型中的协整检验、自相关性等问题。本文认为我国第三产业产值主要受GDP和我国城乡居民存款储蓄的影响,因此需要引起足够的重视,正确开展工作,促进第三产业的发展。 关键词:第三产业产值;时间序列分析;GDP;城乡居民存款储蓄 一、引言 第三产业是指除第一二产业以外的其他行业。自从我国进入改革开放以来,我国不仅在积极发展第一产业和第二产业的同时,也在积极扶植第三产业的发展。我国属于发展中国家,仅靠出口农产品或初级工业品很难在国际社会中立有一足之地。进入21世纪,第三产业的发展迫切需要成为促进经济发展的主要动力。这主要是因为第三产业基本以服务业为主,这就使其具有了行业多,范围广等特点,从而能够提供更多的就业机会,相对于其他产业服务业的就业门滥相对来说也较低,能吸纳农村等剩余劳动力,并且第三产业的发展,也能有效地促进第一产业和第二产业的发展,加速推进我国的工业化和现代化进程,提高我国的综合国力。我国的第三产业较其他发达国家仍有很大的差距,所以加快本国第三产业发展迫在眉睫。 第三产业不仅在占国民生产总值比重方面不断提高,其内部的产业结构也在不断地发生着变化。最初我国第三产业的发展主要集中以餐饮等为主的传统服务业上,而随着新型服务业的产生,我国开始侧重向金融保险业、房地产业等方面的发展,其数量和质量的提高使得第三产业在我国经济发展的过程中产生的作用也越来越显著。 因此,研究第三产业产值的影响因素分析具有实际意义。 二、文献综述 江小涓、李辉(2004)建立了一个多元回归模型来分析收入水平、消费结构、城市化以及其他因素对第三产业未来发展的影响,提出第三产业比例随着人均GDP水平增长而增加[1]。郭彩霞(2009)对1978到2008年相关数据进行实证分析,得到要想加快农村现代化就必须要促进第三产业的发展结论[2]。王小宁(2009)认为第三产业固定资产的投资对第三产业产值具有重大的影响[3]。徐群、于德淼、赵春阁在对第三产业发展研究时主要是利用线性回归模型来对我国第三产业的影响因素进行分析,对我国第三产业发展现状的研究和趋势预测就是利用的主成分分析和逐步回归分析方法[4]。
@计量经济学主要公式
序 公式名称计算公式 号 y t = β0 + β1 x t + u t 1真实的回归模 型 2估计的回归模 型y t =+x t + 3真实的回归函 E(y t) = β0 + β1 x t 数 4估计的回归函 数=+x t 5最小二乘估计 公式 6 和的方 差 7σ2的无偏估 计量= s2 = 8 和估计 的方差 9总平方和 ∑(y t -) 2 10回归平方和 ∑(-) 2 11误差平方和 ∑(y t -)2 = ∑()2 12可决系数(确 定系数) 13检验β0,β1 是 否为零的t统 计量
14β1的置信区间 -tα(T-2) ≤β1≤+tα(T-2) 15单个y T +1的点 预测=+x T+1 16E(y T+1)的区间 预测 17单个y T+1的区 间预测 18样本相关系数 表3.4 多元线性回归模型的主要计算公式 序号公式名称计算公式 1 真实的回归模型Y= X β+ u 2 估计的回归模型Y = X+ 3 真实的回归函数E(Y) = X β 4 估计的回归函数= X 5 最小二乘估计公式= (X 'X)-1X 'Y 6 回归系数的方差Var() = σ2(X 'X)-1 7 σ2的无偏估计量= s2 ='/ (T - k) 8 回归系数估计的方差() =(X 'X)-1 9 回归平方和SSR = = '- T 10 总平方和SST = Y 'Y - T 11 残差平方和SSE = ' 12 可决系数 13 调整的可决系数
14 F统计量 15 t统计量 16 点预测公式 C = (1 x T+1 1 x T+1 2… x T+1 k-1 ) = C = 0 +1 x T+1 1 + … + k-1 x T+1 k-1 17 E(y T+1) 的置信区间预 测 C±tα/2 (1, T-k)s 18 单个y T+1的置信区间预 测 C±tα/2 (T-k)s 19 预测误差e t = - y t, t= 1, 2, …, T 20 相对误差PE = , t= 1, 2, …, T 21 误差均方根 22 绝对误差平均 23 相对误差绝对值平均 24 Theil系数 25 偏相关系数是控制z t不变条件下的x t, y t的简单相关系数。 26 y t与x t1,x t2,…,x tk–1的 复相关系数 是y t与的简单相关系数。其中是y t对x t1,x t2,…x tk–1 回归的拟合
计量经济学的概念
计量经济学是经济科学领域内的一门应用科学,以一定的经济理论和实际统计资料为基础,运用数学、统计方法与计算机技术,以建立经济计量模型为主要手段,定量分析研究具有随机特性的经济变量关系。 2、数理经济模型与计量经济模型的区别。 数理:揭示经济活动中各个因素之间的理论关系,用确定性的数学方程加以描述。 计量:揭示经济活动中各个因素之间的定量关系,用随机性的数学方程加以描述。 3、经典计量经济学模型的一般形式。 4、计量经济学的数据类型。 时间序列数据:按时间先后排列的统计数据。 截面数据:一个或多个变量在某一时点上的数据集合。 合并数据(平行数据):既包含时间序列数据又有截面 数据。 5、建立计量经济学模型的步骤。 1) 模型的数学形式。③拟定模型中待估计参数的理论期望 值。 2)样本数据的收集: 差项产生序列相关。②截面数据易引起模型随机误差项 产生异方差。③样本数据的质量:完整性、准确性、可 比性、一致性。 3)模型参数的估计。 4 度检验、变量的显着性检验、方程的显着性检验。③计 量经济学检验:序列相关、异方差法(随机误差项)、 多重共线性(解释变量)④模型预测检验。 6、计量经济学模型的应用。 1)结构分析;2)经济预测;3)政策评价;4)检验与发展经济理论。 7、如何正确选择解释变量。 作为“变量”的原因:1 2)考虑数据的可得性;3)考虑入选变量之间的关系。 8、回归分析的目的。 1)根据自变量的取值,估计应变量的均值;2)检验建立在经济理论基础上的假设;3) 值,预测应变量的均值。 9、总体回归函数(PRF)和样本回归函数(SRF)各变量系数名称及函数方程。 10、随机误差项(Ui)的性质或主要内容。
第九章时间序列计量经济学模型案例
第九章时间序列计量经济学模型案例 1、1949—2001年中国人口时间序列数据见表8,由该数据(1)画时间序列图和差分图;(2)求中国人口序列的相关图和偏相关图,识别模型形式;(3)估计时间序列模型;(4)样本外预测。 表9.1 中国人口时间序列数据(单位:亿人) 年份人口y t 年份人口y t年份人口y t年份人口y t年份人口y t 1949 5.4167 1960 6.6207 1971 8.5229 1982 10.159 1993 11.8517 1950 5.5196 1961 6.5859 1972 8.7177 1983 10.2764 1994 11.985 1951 5.63 1962 6.7295 1973 8.9211 1984 10.3876 1995 12.1121 1952 5.7482 1963 6.9172 1974 9.0859 1985 10.5851 1996 12.2389 1953 5.8796 1964 7.0499 1975 9.242 1986 10.7507 1997 12.3626 1954 6.0266 1965 7.2538 1976 9.3717 1987 10.93 1998 12.4761 1955 6.1465 1966 7.4542 1977 9.4974 1988 11.1026 1999 12.5786 1956 6.2828 1967 7.6368 1978 9.6259 1989 11.2704 2000 12.6743 1957 6.4653 1968 7.8534 1979 9.7542 1990 11.4333 2001 12.7627 1958 6.5994 1969 8.0671 1980 9.8705 1991 11.5823 1959 6.7207 1970 8.2992 1981 10.0072 1992 11.7171 (1)画时间序列图 y的数据窗口 打开 t 得到中国人口序列图
计量经济学第二章主要公式
第二章主要公式 资料地址:https://www.wendangku.net/doc/9817992918.html,/jl 1、回归模型概述 (1)相关分析与回归分析 经济变量之间的关系:函数关系、相关关系 相关关系:单相关和复相关,完全相关、不完全相关和不相关,正相关与负相关,线性相关和负相关,线性相关和非线性相关。 相关分析: ——总体相关系数XY ρ= ——样本相关系数()() n i i XY X X Y Y r --= ∑ ——多个变量之间的相关程度可用复相关系数和偏相关系数度量 回归分析:相关关系 + 因果关系 (2)随机误差项:含有随机误差项是计量经济学模型与数理经济学模型的一大区别。 (3)总体回归模型 总体回归曲线:给定解释变量条件下被解释变量的期望轨迹。 总体回归函数:(|)()i i E Y X f X = 总体回归模型:(|)()i i i i i Y E Y X f X μμ=+=+ 线性总体回归模型:011,2,...,i i i Y X i n ββμ=++= (4)样本回归模型 样本回归曲线:根据样本回归函数得到的被解释变量的轨迹。 (线性)样本回归函数: 01???i i Y X ββ=+ (线性)样本回归模型:01???i i i Y X e ββ=++ 2、一元线性回归模型的参数估计 (1)基本假设 ① 解释变量:是确定性变量,不是随机变量 var()0i X = ② 随机误差项:零均值、同方差,在不同样本点之间独立,不存在序列相关等 ()01,2,...,i E i n μ== 2var()1,2,...,i i n μσ==
cov(,)0;,1,2,...,i j i j i j n μμ=≠= ③ 随机误差项与解释变量:不相关 cov(,)01,2,...,i i X i n μ== ④ (针对最大似然法和假设检验)随机误差项: 2~(0,)1,2,...,i N i n μσ= ⑤ 回归模型正确设定。 【前四条为线性回归模型的古典假设,即高斯假设。满足古典假设的线性回归模型称为古典线性回归模型。】 (2)参数的普通最小二乘估计(OLS ) 目标:21 min n i i e =∑ 对于一元线性回归模型:011,2,...,i i i Y X i n ββμ=++= 正规方程组: 011 011 ?? 2[()]0??2[()]0n i i i n i i i i Y X X Y X ββββ==?--+=????--+=??∑∑ 解得: 011 112 211??()()?()n n i i i i i i n n i i i i Y X X X Y Y x y X X x βββ====?=-???--?==??-?? ∑∑∑∑ (3)最大似然估计(ML ) 对于一元线性回归模型:011,2,...,i i i Y X i n ββμ=++= 重要的基本假设: 2~(0,)1,2,...,cov(,)0;,1,2,...,var()01,2,...,i i j i N i n i j i j n X i n μσμμ?=? =≠=?? ==? 得到:2 01~(,)1,2,...,i i Y N X i n ββσ+= 【且cov(,)0;,1,2,...,i j Y Y i j i j n =≠=,这个对最大似然法的估计很重要】 则目标:12,,...,n Y Y Y 的联合概率密度最大,即
计量经济学考试必备公式大纲
学习用途,考试专用,请用完删除自己总结1159952047 1、异方差性:对于不同的样本点,随机干扰项的方差不再是常数,而是互不相同,则认为出现了异方差性。类型:单调递增型,单调递减型,复杂型。原因:⑴模型中遗漏了随时间变化影响逐渐增大的因素。(即测量误差变化)⑵模型函数形式设定误差。⑶随机因素的影响。(即截面数据中总体各单位的差异)后果:1.参数估计量非有效2.变量的显著性检验失去意义3.模型的预测失效检验:图示检验法,戈德菲尔德-匡特检验,怀特检验,帕克检验和戈里瑟检验处理:变异方差为同方差,或尽量缓解方差变异的程度。(加权最小二乘法(WLS),异方差稳健标准误法) 2、序列相关性:如果模型的随机干扰项违背了相互独立的基本假设,则称为存在... 原因:经济数据序列惯性;模型设定的偏误;滞后效应;蛛网现象;数据的编造后果:1.参数估计量非有效;2.变量的显著性检验失去意义;3.模型的预测失效检验方法:图示法;回归检验法;D.W.检验法;拉格朗日乘数检验补救方法:广义最小二乘法(GLS),广义差分法,随机干扰项相关系数的估计,广义差分法在计量经济学软件中的实现,序列相关稳健标准误法。 3、多重共线性:如果模型的解释变量之间存在着较强的相关关系,则称模型存在多重共线性。 原因:经济变量相关的共同趋势、滞后变量的引入、样本资料的限制后果(一)完全:1、参数估计值不确定。 2、参数估计值的方差会无限大。( 二)不完全:1、有可能求出参数的估计值,但估计值很不稳定。2、参数估计值的方差会随多重共线性(近似)程度的提高而增大。3、对总体参数的区间估计将会降低精确度(置信区间变宽)。评价区间估计的两个标准: (1)估计的可靠度。(2)估计的精确度 .4、对总体参数的显著性检验(t检验)在统计上将会不显著。检验:1.检验多重共线性是否存在2.判明存在多重共线性的范围克服方法:1.排除引起共线性的变量2.差分法3.见笑参数估计量的方差 4、●经典假定:1、零均值假定。2、同方差假定。3、无自相关假定。4、解释变量与随机误差项不相关。 5、无多重共线性假定。 6、正态性假定。●多元线性回归模型的基本假定:零均值假定、同方差和无自相关(条件方差不变、条件自相关等于0)、随机扰动项与解释变量不相关、无多重共线性、正态性假定独立同分布,且~ N (0,σ2) 5、拟和直线的优度-判定系数r2。TSS为总离差平方和,反映Y的样本观测值的平均差异程度;ESS 为Y的估计值与均值的离差平方和,反映解释变量的变化所引起的对Y的波动大小,即解释变量在模型中存在的重要程度;RSS为残差平方和,反映Y依据回归直线没有得到解释的变差。 6、F检验的意义(1)检验的不足。尽管具有对模型整体拟合状况的判断,但它并不能得到到底要多大时回归方程才算通过了拟合优度检验。虽然R2能够给出评价模型拟合好坏的度量,但它只是对样本的拟合程度进行评价,不能回答总体的真实状况。(2)F检验的目的。对于总体多元线性回归模型,从整体上看,多个解释变量与被解释变量之间是否存在显著的线性关系,或者说 Y 的变动是否依赖于这些解释变量的变化。由F统计量的构成可以看出(ESS服从自由度为k-1,RSS服从n-k 的分布),如果ESS显著地大于RSS,则表明不能认为所有的全为零,这时在很大程度上要拒绝。则在该意义下,说明回归方程中的所有解释变量对应变量存在显著性影响。F 检验的一般步骤是:(1)构造 F 统计量,即。(2)给定显著性水平,查F分布表,得临界值,其中k为参数的个数,n为样本容量。(3)比较判断。若F﹥,则拒绝原假使,表明回归函数从整体上看是显著的,即所有解释变量对应变量有显著性影响。 7、t 检验在多元线性回归模型里与一元的情况是一致的。需要注意的是在多元线性回归模型对参数的 t 检验中,即~ t(n-k) (在成立下)这里是服从自由度为 (n-k) 的 t 分布。因此,在多元的情况下,运用 t 检验的操作过程如下(1)提出假设(2)构造检验统计量在H 0 成立的情况下,有:~t(n-k)(3)计算t统计量值,。(4)根据t分布,给定显著性水平,查表得临界值。(5)比较判断,若,则拒绝 H 0 ,同时接受 H 1 。表明第 j 个解释变量 X j 对被解释变量 Y 存在显著性影响;否则,表明第 j 个解释变量 X j 对被解释变量 Y 不存在显著性影响。 8、
期末计量经济学公式
序号 公式名 称 计 算 公式 1 真实的回归模型 y t = ?0 + ?1 x t + u t 2 估计的回归模型 y t =+ x t + 3 真实的回归函数 E(y t ) = ?0 + ?1 x t 4 估计的回归函数 = + x t 5 最小二乘估计公式 ()()() ∑∑∑∑∑∑--=---== -=2 22 2 221X n X Y X n Y X X X Y Y X X x y x b X b Y b i i i i i i i i i 6 和的方 差 7 ? ? 的无偏估 计量 = s 2 = 8 和估计 的方差 ? 9 总平方和TSS ? (y t -) 2 10 回归平方和 RSS ? ( - ) 2 11 误差平方和 ESS ? (y t -)2 = ? ( )2 12 可决系数(确 定系数) =RSS/TSS 13 检验?0,?1 是 否为零的t 统计量 14 ?1的置信区间 -t ? (T -2) ??1 ? + t ? (T -2) 15 单个y T +1的点 预测 = + x T +1
16E(y T+1)的区间 预测 17单个y T+1的区 间预测 18样本相关系数 表 ?多元线性回归模型的主要计算公式 序号公式名称计算公式 1 真实的回归模型Y= X ?+ u 2 估计的回归模型Y = X+ 3 真实的回归函数E(Y) = X ? 4 估计的回归函数= X 5 最小二乘估计公式= (X 'X)-1X 'Y 6 回归系数的方差Var() = ? 2(X 'X)-1 7 ? ? 的无偏估计量= s2 ='/ (T - k) 8 回归系数估计的方差() =(X 'X)-1 9 回归平方和SSR = = '- T 10 总平方和SST = Y 'Y - T 11 残差平方和SSE = ' 12 可决系数 13 调整的可决系数 14 F统计量 15 t统计量 C = (1 x T+1 1 x T+1 2… x T+1 k-1 ) 16 点预测公式
计量经济学公式整理.doc
2:随机误差项的性质 (1)误差项代表了未纳入模型变量的影响; (2)即使模型中包括了决定数学分数的所有变量,其内在随机性也不可避免,这是做任何 努力都无法解释的; (3)u 代表了度量误差; (4)“奥卡姆剃刀原则”,即描述应该尽可能简单,只要不遗漏重要的信息。 3:解释回归结果的步骤 (1)看整个模型的显著性,看F 统计量的值; (2)看单个参数的显著性; (3)解释斜率的经济含义; (4)解释R 2。 4:古典线性回归模型的基本假定(同多元线性回归模型的基本假定相同) (1)所有自变量是确定性变量; (2) (3)自变量之间不存在完全多重共线性。 12:样本回归方程,i e 为残差项, i i i e X b b Y ++=21 总体回归方程,i u 为随机误差项 i i i u X B B Y ++=21 5: 样本回归函数: 随机样本回归函数: 总体回归函数: 随机总体回归方程: 观察值可表示为: 6:普通最小二乘法就是要选择参数1b 、2b ,使得参差平方和最小。 ()()() ∑∑∑∑∑∑--=---==-=2 2 2 22 21X n X Y X n Y X X X Y Y X X x y x b X b Y b i i i i i i i i i i i i i i i i i i i i i i i i i u X Y E Y e Y Y u X B B Y X B B X Y E e X b b Y X b b Y +=+=++=+=++=+=)|(?)|(?21212121
7:R 2的计算公式:( R 2度量了回归模型对Y 变异的解释比例) TSS :总离差平方和 ESS :回归平方和 RSS :残差平方和 (1) (2) (3) 8:F 检验 ) 3,2(~) 3(2 )(. ...23322--+= =∑∑∑n F n e x y b x y b f d RSS f d ESS F t t t t t ()1 //1/1/1P ..-------?=n TSS k n RSS k n RSS p k n RSS k ESS k ESS k ESS F f d SS MSS f d 总离差 来自残差来自回归值值自由度平方和方差来源 9:F 与判定系数R2之间的重要关系 当R2=0,F =0,当R2=1,F 值为无穷大 10:校正的判定系数R 2 ( )k n n R R ----=1112 2 11:普通最小二乘估计量的一些重要性质: ∑∑∑====+=0 ?00 21i i i i i Y e X e n e e X b b Y 21ESS RSS TSS TSS ESS R TSS =+ = RSS ESS TSS +=)()1()1(22 k n R k R F ---=
计量经济学公式
12:样本回归方程, Y b1 b2X 总体回归方程, e为残差项, e U i为随机误差项 X i) U i b1、b2,使得参差平方和最小。 2:随机误差项的性质 (1)误差项代表了未纳入模型变量的影响; (2 )即使模型中包括了决定数学分数的所有变量,其内在随机性也不可避免,这是做任何努力都无法解释的; (3)u代表了度量误差; (4)“奥卡姆剃刀原则”,即描述应该尽可能简单,只要不遗漏重要的信息。 3:解释回归结果的步骤 (1)看整个模型的显著性,看 F统计量的值; (2 )看单个参数的显著性; (3 )解释斜率的经济含义; (4)解释R2。 4:古典线性回归模型的基本假定(同多元线性回归模型的基本假定相同) (1)所有自变量是确定性变量; (2) (3 )自变量之间不存在完全多重共线性。 Y B1B2X j 5 5: 样本回归函数:Y? b1 b2X i 随机样本回归函数:Y i b1b2X i e i 总体回归函数:E(Y| X i) B1 B2X i 随机总体回归方程:Y i B1 B2X i U i 观察值可表示为: Y i Y? e Y i E(Y 6:普通最小二乘法就是要选择参数 b1 Y b2 X
X i y i b2 茶 X X i X Y Y —2 X i X X i Y nXY Xi nX2
e 2(n 3) 7: R2的计算公式:(R2度量了回归模型对 Y 变异的解释比例) TSS:总离差平方和 ESS:回归平方和 RSS:残差平方和 (1)TSS ESS RSS (2) 1 ESS RSS TSS TSS (3) R 2婪 TSS &F 检验 ESSd.f. RSSd.f. (b 2 y t x 2t R y t x 3t ) 2 '2 yt 2t yt ‘ ?F(2,n 3) F R 2(k 1) F 2 (1 R 2) (n k) 当R2 = 0, F = 0,当R2= 1 , F 值为无穷大 10:校正的判定系数 R2 方差来源 平方和 自由度d.f. SS MSS - d f 来自回归 ESS k 1 ESS/k 1 来自残差 RSS n k RSS/ n k 总、离 TSS n 1 F 值 ESS/k 1 RSS/n k 9: F 与判定系数R2之间的重要关系
第八章 时间序列计量经济学模型(DOC)
1.1949—2001年中国人口时间序列数据见表8,由该数据(1)画时间序列图;(2)求中国人口序列的相关图和偏相关图,识别模型形式;(3)估计时间序列模型;(4)样本外预测。 表8 中国人口时间序列数据(单位:亿人) 年份人口y t年份人口y t年份人口y t年份人口y t年份人口y t 1949 5.4167 1960 6.6207 1971 8.5229 1982 10.159 1993 11.8517 1950 5.5196 1961 6.5859 1972 8.7177 1983 10.2764 1994 11.985 1951 5.63 1962 6.7295 1973 8.9211 1984 10.3876 1995 12.1121 1952 5.7482 1963 6.9172 1974 9.0859 1985 10.5851 1996 12.2389 1953 5.8796 1964 7.0499 1975 9.242 1986 10.7507 1997 12.3626 1954 6.0266 1965 7.2538 1976 9.3717 1987 10.93 1998 12.4761 1955 6.1465 1966 7.4542 1977 9.4974 1988 11.1026 1999 12.5786 1956 6.2828 1967 7.6368 1978 9.6259 1989 11.2704 2000 12.6743 1957 6.4653 1968 7.8534 1979 9.7542 1990 11.4333 2001 12.7627 1958 6.5994 1969 8.0671 1980 9.8705 1991 11.5823 1959 6.7207 1970 8.2992 1981 10.0072 1992 11.7171 (1)画时间序列图 打开 y的数据窗口 t
计量经济学时间序列计量经济模型
计量经济学引子:是真回归还是伪回归?问题:●如果直接将非平稳时间序列当作平稳时间序列来进行分析,会造成什么不良后果; ●如何判断一个时间序列是否为平稳序列;●当我们在计量经济分析中涉及到非平稳时间序列时,应作如何处理?第一节时间序列基本概念本节基本内容: ●伪回归问题●随机过程的概念●时间序列的平稳性一、伪回归问题传统计量经济学模型的假定条件:序列的平稳性、正态性。所谓“伪回归”,是指变量间本来不存在相依关系,但回归结果却得出存在相依关系的错误结论。 20世纪70年代,Grange、Newbold 研究发现,造成“伪回归”的根本原因在于时序序列变量的非平稳性三、时间序列的平稳性所谓时间序列的平稳性,是指时间序列的统计规律不会随着时间的推移而发生变化。直观上,一个平稳的时间序列可以看作一条围绕其均值上下波动的曲线。从理论上,有两种意义的平稳性,一是严格平稳,另一种是弱平稳。时间序列的非平稳性是指时间序列的统计规律随着时间的位移而发生变化,即生成变量时间序列数据的随机过程的特征随时间而变化。在实际中遇到的时间序列数据很可能是非平稳序列,而平稳性在计量经济建模中又具有重要地位,因此有必要对观测值的时间序列数据进行平稳性检验。第二节 时间序列平稳性的单位根检验本节基本内容: ●单位根检验● Dickey-Fuller检验● Augmented Dickey-Fuller检验一、单位根过程单位根过程结论: 随机游动过程是非平稳的。
因此,检验序列的非平稳性就变为检验特征方程是否有单位根,这就是单位根检验方法的由来。二、Dickey-Fuller检验(DF检验)大多数经济变量呈现出强烈的趋势特征。这些具有趋势特征的经济变量,当发生经济振荡或冲击后,一般会出现两种情形: ●受到振荡或冲击后,经济变量逐渐又回它们的长期趋势轨迹;●这些经济变量没有回到原有轨迹,而呈现出随机游走的状态。若我们研究的经济变量遵从一个非平稳过程,一个变量对其他变量的回归可能会导致伪回归结果。这是研究单位根检验的重要意义所在。 2 提出假设检验用统计量为常规t统计量, 3 计算在原假设成立的条件下t统计量值,查DF检验临界值表得临界值,然后将t统计量值与DF检验临界值比较:若t统计量值小于DF检验临界值,则拒绝原假设,说明序列不存在单位根;若t统计量值大于或等于DF检验临界值,则接受原假设,说明序列存在单位根。Dickey、Fuller研究发现,DF检验的临界值同序列的数据生成过程以及回归模型的类型有关,因此他们针对如下三种方程编制了临界值表,后来Mackinnon把临界值表加以扩充,形成了目前使用广泛的临界值表,在EViews软件中使用的是Mackinnon临界值表。 DF检验存在的问题是,在检验所设定的模型时,假设随机扰动项不存在自相关。但大多数的经济数据序列是不能满足此项假设的,当随机扰动项存在自相关时,直接使用DF检验法会出现偏误,为了保证单位根检验的有效性,人们对DF检验进行拓展,从而形成了扩展的DF检验Augmented Dickey-Fuller Test ,简称为ADF检验。根据《中国
计量经济学复习大纲
计量经济学复习大纲 第一章绪论 1. 建立计量经济学模型的步骤及其要点? (1)如何正确选择解释变量? (2)如何确定模型的基本形式? (3)区分时间序列数据、横截面数据和虚变量数据。(4)何谓经济意义检验?检验的方法? (5)计量经济学模型成功的三要素及其关系。 2. 结合实际例子理解结构分析方法(弹性、乘数的运用及其模型参数解释)。 第二章一元线性回归模型理论与方法 1. 回归分析与相关分析的联系与区别? 2. 回归分析的主要目的和内容? 3. 总体回归函数PRF的内涵和形式(确定和随机)。 4. 随机干扰项的定义及其内涵? 5. 样本回归函数的形式及其与PRF的关系? 6. 线性回归模型的基本假设(结合现实经济例子给予解释说明)。 7. OLS法的原理及其参数估计量的估计方法(推导过程)、正规方程组的导出。 8. OLS估计量的计算公式(离差形式)及其参数经济意义解释(要求掌握回归函数的求解计算过程)。
9. OLS估计量的性质(要求掌握线性性、无偏性、有效性的涵义及其证明过程,基本推论要牢记且理解) 10. BLUE估计量与高斯-马尔可夫定理? 11. 一元参数估计量的概率分布形式、总体方差的无偏估计公式以及样本参数的标准差计算公式(要求牢记公式并熟练运用于计算)。 12. 拟合优度检验的原理(TSS、ESS和RSS的内涵及其关系)? 13. 变量显著性检验的方法原理(t检验) (1)小概率事件原理(零假设必须是一小概率事件)?(2)t统计量的构造? 14.. 缩小置信区间的方法:同等显著性水平下尽可能减小t检验临界值和样本参数的标准差。 一是增大样本容量;二是提高模型的拟合优度。 15. 本章练习题第2、3、7、8、9(样本参数估计量的性质)、11题要求熟练掌握。 第三章多元线性回归模型理论与方法 1. 理解偏回归系数的概念及其应用解释。 2. 多元线性回归模型的基本假定(标量和矩阵形式)。 3. 理解普通最小二乘估计的正规方程组及其参数估计量计算公式。 4. 理解最小样本容量的概念及其原理。 5. 熟练掌握和应用调整可决系数的计算公式及其与R2的关系
计量经济学考试重点整理
计量经济学考试重点整理 第一章: P1:什么是计量经济学?由哪三组组成? 定义:“用数学方法探讨经济学可以从好几个方面着手,但任何一个方面都不能和计量经济学混为一谈。计量经济学与经济统计学绝非一码事;它也不同于我们所说的一般经济理论,尽管经济理论大部分具有一定的数量特征;计量经济学也不应视为数学应用于经济学的同义语。经验表明,统计学、经济理论和数学这三者对于真正了解现代经济生活的数量关系来说,都是必要的,但本身并非是充分条件。三者结合起来,就是力量,这种结合便构成了计量经济学。” P9:理论模型的设计主要包含三部分工作,即选择变量,确定变量之间的数学关系,拟定模型中待估计参数的数值范围。 P12:常用的样本数据:时间序列,截面,虚变量数据 P13:样本数据的质量(4点) 完整性;准确性;可比性;一致性 P15-16:模型的检验(4个检验) 1、经济意义检验 2、统计检验 拟合优度检验 总体显著性检验 变量显著性检验 3、计量经济学检验 异方差性检验 序列相关性检验 共线性检验 4、模型预测检验 稳定性检验:扩大样本重新估计 预测性能检验:对样本外一点进行实际预测 P16计量经济学模型成功的三要素:理论、方法和数据。 P18-20:计量经济学模型的应用 1、结构分析 经济学中的结构分析是对经济现象中变量之间相互关系的研究。 结构分析所采用的主要方法是弹性分析、乘数分析与比较静力分析。 计量经济学模型的功能是揭示经济现象中变量之间的相互关系,即通过模型得到弹性、乘数等。 2、经济预测 计量经济学模型作为一类经济数学模型,是从用于经济预测,特别是短期预测而发展起来的。 计量经济学模型是以模拟历史、从已经发生的经济活动中找出变化规律为主要技术手段。 对于非稳定发展的经济过程,对于缺乏规范行为理论的经济活动,计量经济学模型预测功能失效。 模型理论方法的发展以适应预测的需要。
计量经济学模型
第七章 计量经济学应用 §7.1 计量经济学模型的设定 计量经济学模型设定的主要根据: 1) 研究目的; 2) 已有理论模型。 通常是根据研究目的所涉及的范围,决定需要分析哪些经济变量之间的关系。再设定这些变量之间的关系式。 设定变量关系式可以根据已有的理论模型、经济恒等式、经济关系式来确定(可能需要进行一定的修改)。若没有已知的关系式可用,可以根据研究目的,人为设定。 变量间具体表达式的选择 若经济理论已给出具体表达式,就直接套用。否则,可以直接假设为线性函数。其原因是经济中的所使用函数大多数都认为是连续可微的函数,因而可以用线性函数近似。 §7.2 数据调整 由于统计指标与经济变量的含义、口径一般不会一致。在模型估计之前,如有可能,应先进行调整,使统计指标的口径尽可能的接近经济变量的含义。 §7.3 变量的选择 基于上述同样的原因,及统计指标间的相关性,在设计模型结构时,需要筛选变量。 假设模型已转化为简化型,即设模型为 ??? ????++++=++++=++++=k p kp k k k p p p p x x x y x x x y x x x y εαααεαααεαααΛΛΛΛ2211222221212112121111 变量筛选有两层含义: 1) 对内生变量T k y y y ),,,,(21Λ有重要影响的外生变量是否都选入模型了? 2) 模型内的外生变量T p x x x ),,,(21Λ对内生变量T k y y y ),,,,(21Λ是否都有重要影 响? 判别准则 1) 复相关系数R (一般要求R>0.8),或方程的F -统计量; 一般来说,若R>0.9或经F-检验是显著的,则从整体上说,方程几乎包含了对响应变量有重要影响所有外生变量,外生变量对内生变量有较强的解释能力,否则,表明方程遗漏了一些对内生变量有重要影响的变量,需要增加外生变量。 当模型用于结构分析时,R 值可以低一些,用于预测时,R 值应比较大。 2) 系数显著性检验t -统计量。 下面介绍几种常用的变量筛选算法。这些算法都是一对多回归模型的搜索算法。 记in Ω是在回归模型内的预测变量集,out Ω是在回归模型外待检的预测变量集,del Ω是
计量经济学复习题及答案(超完整版)
计量经济学题库 一、单项选择题 1.计量经济学是下列哪门学科的分支学科(C)。 A.统计学B.数学C.经济学D.数理统计学 2.计量经济学成为一门独立学科的标志是(B)。 A.1930年世界计量经济学会成立B.1933年《计量经济学》会刊出版 C.1969年诺贝尔经济学奖设立D.1926年计量经济学(Economics)一词构造出来 3.外生变量和滞后变量统称为(D)。 A.控制变量B.解释变量C.被解释变量D.前定变量4.横截面数据是指(A)。 A.同一时点上不同统计单位相同统计指标组成的数据B.同一时点上相同统计单位相同统计指标组成的数据 C.同一时点上相同统计单位不同统计指标组成的数据D.同一时点上不同统计单位不同统计指标组成的数据 5.同一统计指标,同一统计单位按时间顺序记录形成的数据列是(C)。 A.时期数据B.混合数据C.时间序列数据D.横截面数据6.在计量经济模型中,由模型系统内部因素决定,表现为具有一定的概率分布的随机变量,其数值受模型中其他变量影响的变量是()。 A.内生变量B.外生变量C.滞后变量D.前定变量7.描述微观主体经济活动中的变量关系的计量经济模型是()。 A.微观计量经济模型B.宏观计量经济模型C.理论计量经济模型D.应用计量经济模型 8.经济计量模型的被解释变量一定是()。 A.控制变量B.政策变量C.内生变量D.外生变量9.下面属于横截面数据的是()。 A.1991-2003年各年某地区20个乡镇企业的平均工业产值 B.1991-2003年各年某地区20个乡镇企业各镇的工业产值 C.某年某地区20个乡镇工业产值的合计数D.某年某地区20个乡镇各镇的工业产值 10.经济计量分析工作的基本步骤是()。 A.设定理论模型→收集样本资料→估计模型参数→检验模型B.设定模型→估计参数→检验模型→应用模型 C.个体设计→总体估计→估计模型→应用模型D.确定模型导向→确定变量及方程式→估计模型→应用模型 11.将内生变量的前期值作解释变量,这样的变量称为()。 A.虚拟变量B.控制变量C.政策变量D.滞后变量 12.()是具有一定概率分布的随机变量,它的数值由模型本身决定。 A.外生变量B.内生变量C.前定变量D.滞后变量 13.同一统计指标按时间顺序记录的数据列称为()。 A.横截面数据B.时间序列数据C.修匀数据D.原始数据 14.计量经济模型的基本应用领域有()。 A.结构分析、经济预测、政策评价B.弹性分析、乘数分析、政策模拟 C.消费需求分析、生产技术分析、D.季度分析、年度分析、中长期分析 15.变量之间的关系可以分为两大类,它们是()。 A.函数关系与相关关系B.线性相关关系和非线性相关关系 C.正相关关系和负相关关系D.简单相关关系和复杂相关关系 16.相关关系是指()。 A.变量间的非独立关系B.变量间的因果关系C.变量间的函数关系D.变量间不确定性
计量经济学常用方法及应用-经济管理学院
计量经济学专题及应用 【授课计划:计划讲8个专题。主要是对计量经济学中5块常用的方法进行总结性和归纳性的介绍,侧重于讲在实际经济研究和实证分析中碰到相应问题时,计量经济方法上应当怎样处理,为什么要这样处理,如何处理,并结合STATA 讲应用例子。此外,1次专题介绍STATA的基础功能,1次专题系统梳理计量经济学的基础理论,还有1次专题结合实际研究例子,介绍一手数据搜集的调查设计和组织。通过上述课程,使学生能够在已经接受过基本理论和方法训练的基础上,更好地理解计量经济学的内容,并培养和提高开展实证研究的能力】 1、STATA简介及简单应用 介绍目前国内外最流行的计量经济分析软件STATA的基本功能和用法,通过简单例子介绍STATA在数据清理和管理、描述性统计分析、回归分析等方法的用法。同时插入EXCEL在处理数据方面的一些功能和应用。上午讲课,下午习题课。 2、计量经济分析基础 对计量经济学的基础理论进行总结性和归纳性的回顾、输理和介绍,重点讲假设检验和回归的道理,以及回归诊断。上午讲课,下午习题课。 3、项目评估与政策分析应用 系统介绍计量经济学在项目评估和政策分析上的方法和应用,特别介绍虚拟变量模型的建立及其在政策分析和项目评估研究中的应用。上午讲课,下午习题课。 4、经济学中的内生性问题及相关计量经济方法 总结和介绍计量经济学中内生性问题在经济研究中的涵义和问题,内生性问题产生的主要原因,对计量估计结果的影响,内生性问题的处理方法(工具变量和两阶段估计等)和应用例子。上午讲课,下午习题课。 5、微观个体行为的计量经济分析方法 总结和介绍分析微观个体行为的属性和受限因变量模型(Probit, Logit, Tobit, Heckman, Mlogit, Clogit等)等常用微观计量经济方法,包括模型内涵和适用范
计量经济学:时间序列模型习题与解析(1)复习课程
第九章 时间序列计量经济学模型的理论与方法 练习题 1、 请描述平稳时间序列的条件。 2、 单整变量的单位根检验为什么从DF 检验发展到ADF 检验? 3、设,10,sin cos ≤≤+=t t t x t θηθξ其中ηξ,是相互独立的正态分布N(0, 2 σ)随机变 量,θ是实数。试证:{10,≤≤t x t }为平稳过程。 4、 用图形及LB Q 法检验1978-2002年居民消费总额时间序列的平稳性,数据如下: 5、 利用4中数据,用ADF 法对居民消费总额时间序列进行平稳性检验。 6、 利用4中数据,对居民消费总额时间序列进行单整性分析。 7、 根据6中的结论,对居民消费总额的差分平稳时间序列进行模型识别。 8、 用Yule Walker 法和最小二乘法对7中的居民消费总额的差分平稳时间序列进行时间序 列模型估计,并比较估计结果。 9、 有如下AR(2)随机过程: t t t t X X X ε++=--2106.01.0 该过程是否是平稳过程? 10、求MA(3)模型3213.05.08.01---+-++=t t t t t u u u u y 的自协方差和自相关函数。 11、设动态数据,92.0,82.0,74.0,9.0,7.0,8.0654321======x x x x x x ,78.07=x ,84.0,72.0,86.01098===x x x 求样本均值x ,样本方差0?γ,样本自协方差1?γ、2?γ和样 本自相关函数1?ρ 、2?ρ。 12、判断如下ARMA 过程是否是平稳过程: 12114.01.07.0----+-=t t t t t x x x εε
建立计量经济学模型的步骤和要点
建立计量经济学模型的步骤和要点 | [<<][>>] 一、理论模型的设计 对所要研究的经济现象进行深入的分析,根据研究的目的,选择模型中将包含的因素,根据数据的可得性选择适当的变量来表征这些因素,并根据经济行为理论和样本数据显示出的变量间的关系,设定描述这些变量之间关系的数学表达式,即理论模型。例如上节中的生产函数 就是一个理论模型。理论模型的设计主要包含三部分工作,即选择变量、确定变量之间的数学关系、拟定模型中待估计参数的数值范围。 1. 确定模型所包含的变量 在单方程模型中,变量分为两类。作为研究对象的变量,也就是因果关系中的“果”,例如生产函数中的产出量,是模型中的被解释变量;而作为“原因”的变量,例如生产函数中的资本、劳动、技术,是模型中的解释变量。确定模型所包含的变量,主要是指确定解释变量。可以作为解释变量的有下列几类变量:外生经济变量、外生条件变量、外生政策变量和滞后被解释变量。其中有些变量,如政策变量、条件变量经常以虚变量的形式出现。 严格他说,上述生产函数中的产出量、资本、劳动、技术等,只能称为“因素”,这些因素间存在着因果关系。为了建立起计量经济学模型,必须选择适当的变量来表征这些因素,这些变量必须具有数据可得性。于是,我们可以用总产值来表征产出量,用固走资产原值来表征资本,用职工人数来表征劳动,用时间作为一个变量来表征技术。这样,最后建立的模型是关于总产值、固定资产原值、职工人数和时间变量之间关系的数学表达式。下面,为了叙述方便,我们将“因素”与“变量”间的区别暂时略去,都以“变量”来表示。 关键在于,在确定了被解释变量之后,怎样才能正确地选择解释变量。
- 计量经济学-10时间序列分析
- 时间序列计量经济学
- 时间序列计量经济学模型案例11949—2001年中国人口时间
- 计量经济学——时间序列
- 第八章 时间序列计量经济学模型(DOC)
- 计量经济学--时间序列数据分析
- 计量经济学时间序列分析
- 时间序列分析计量经济学南开大学
- 计量经济学:时间序列模型习题与解析.doc
- 时间序列计量经济学模型
- 时间序列计量经济学
- 计量经济学 时间序列讲解
- 第九章时间序列计量经济学模型案例
- 时间序列计量经济学模型的理论及其方法
- 时间序列和计量经济学中常见的几种Q统计量
- 计量经济学时间序列分析.
- 高级计量经济学时间序列分析
- 计量经济学课件:第10章 时间序列计量经济模型
- 计量经济学 时间序列
- 计量经济学第七讲时间序列分析