对比SnifferPro和OmniPeek分析PPPoE通讯

对比Sniffer Pro和OmniPeek分析PPPoE通讯
PPPoE是现在很常用的协议,很多地区的电信运营商在ADSL、FTTB中应用了这一协议。那么PPPoE到底是怎么回事呢,我们简单来看一下PPPoE协议,顺带比较一下最热门的网络分析工具Sniffer Pro 和WildPackets OmniPeek协议分析能力的差异。(https://www.wendangku.net/doc/a93859575.html, 保留版权)
我们在Sniffer和OmniPeek里都打开同一个文件(来自于某电信接入网段的捕获文件),一共7071个包。
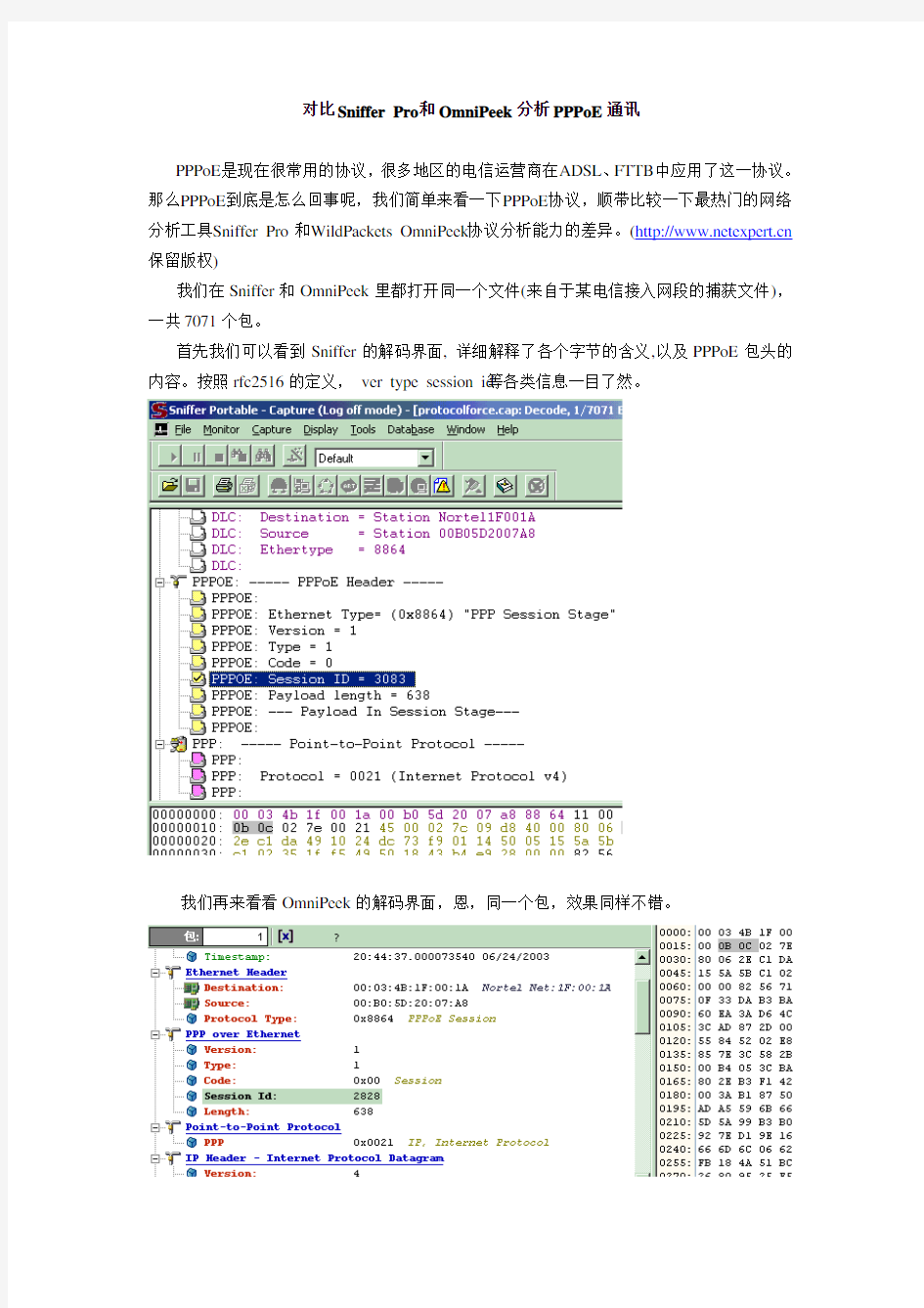
首先我们可以看到Sniffer的解码界面, 详细解释了各个字节的含义,以及PPPoE包头的内容。按照rfc2516的定义,ver type session id等各类信息一目了然。
我们再来看看OmniPeek的解码界面,恩,同一个包,效果同样不错。
但是大家有没有注意到,两个产品的解码结果居然不一样!!!!
请仔细回顾我上面截图中两者都选中的Session ID字段,同样的”0B 0C”十六进制数值居然导致了不同的解码结果。
到底是Sniffer Pro正确还是OmniPeek正确呢?核心问题出在了如何读取0B 0C这个值并理解的问题上。大家可能都会知道,在计算机内存当中,存储数值时,存储的数据结构是依照寄存器的习惯。也就是说,如果有一个数值时16进制的 02FC,那么在计算机内存中的存储格式就是 FC 02。但是在网络中由于传输字节是顺序的,因此网络中传输数值会采取高位先到的做法,即02FC在网络包中应当存储为 02 FC。
那么这个Session ID读取的时候到底是应该按照网络字节的读取方式呢还是按照计算机内存存储的方式呢?让我们来查看RFC 2516,查阅相关细节
“…… The SESSION_ID field is sixteen bits. It is an unsigned value in network byte order. It's value is defined below for Discovery
packets. The value is fixed for a given PPP session and, in fact,
defines a PPP session along with the Ethernet SOURCE_ADDR and
DESTINATION_ADDR. A value of 0xffff is reserved for future use and
MUST NOT be used ……”
哦!找到了,这个数值应当按照网络字节顺序来理解,即 0B 0C对应真实数值十六进制0B0C,十进制= …. 2828。
我们终于找到了,错误在于Sniffer Pro,他误以为Session ID是按照 0C 0B的方式来理解,得到3083的错误结果。
看来OmniPeek首先小胜一场,我们继续比较下去。
我们来看看Sniffer Pro的主机列表分析界面
嗯?似乎有点奇怪,这可是在电信端捕获亚,一共只有20几个IP地址被发现,而且很多还是内网地址,这不禁让我开始怀疑这个捕获文件到底是从哪里来的。
那让我们再看看OmniPeek分析同样这个文件的地址结果吧:
这才合理嘛,3000多个主机被发现在这7071个包中,IP地址也确实是这个电信用户的网络地址段。
Sniffer Pro在搞什么呢?为什么显示一些莫名其妙的结果呢?
如果有Sniffer Pro专家在这里,一定会指出,这种情况需要进行Protocol Forcing。为什么需要?因为Sniffer Pro的专家系统、主机列表功能、Matrix功能等都是和协议解码模块分开的,协议解码支持PPPoE不代表其他功能支持。如果需要获取全部主机等信息,必须命令Sniffer Pro强行跳过包头包含PPPoE的字节,然后从真正的IP包头进行分析。
我们来设置一下,Option中的Protocol Forcing 选择跳过前22个字节
22个字节是因为计算了14个字节的2层包头(6字节目标MAC+6字节源MAC+2字节帧类型)和8个字节的PPPoE包头。
应用以后,重新载入捕获文件,重新点击主机列表,现在我们看到了“正常的”Sniffer Pro
这才象话,Sniffer做了他应该做的事情。
Sniffer Pro经过Forcing设置后可以认为及格,OmniPeek良好的分析获得了满分。
现在我们要帮一帮Sniffer Pro,让我们使用Sniffer引以为豪的Matrix功能吧,这可是最激动人心的设计之一。
哎呀,Overflow了,Matrix无法
承受这么多的条目,而且即使可以,
也看不清了。叹,网络分析真的这么
难吗?
我们看看右图中的OmniPeek的
流量分布图功能结果。
果然很眩,而且很形象,每个节
点还可以拖动以便获得最好的效果。
刚才还提到了Sniffer Pro的Protocol Forcing,那么是不是经过Protocol Forcing就万事大吉了呢。
我们看看经过Protocol Forcing后的Sniffer解码功能。
经过了Protocol Forcing,本来有的数据链路层解码也没有了。
经过这个简单的比较,我们同时了解了PPPoE包头的组成,长度以及如何在Sniffer Pro 以及OmniPeek里做一些基本解码、统计、可视化分析。非常感谢并且欢迎访问https://www.wendangku.net/doc/a93859575.html,,我们将会更深入PPPoE协议,了解整个协议堆栈从认证到传输控制的各个部分。
Vader@https://www.wendangku.net/doc/a93859575.html,
2005年1月28日
wireshark抓包分析报告TCP和UDP
计 算 机 网 络Wireshark抓包分析报告
目录 1. 使用wireshark获取完整的UDP报文 (3) 2. 使用wireshark抓取TCP报文 (3) 2.1 建立TCP连接的三次握手 (3) 2.1.1 TCP请求报文的抓取 (4) 2.1.2 TCP连接允许报文的抓取 (5) 2.1.3 客户机确认连接报文的抓取 (6) 2.2 使用TCP连接传送数据 (6) 2.3 关闭TCP连接 (7) 3. 实验心得及总结 (8)
1. 使用wireshark获取完整的UDP报文 打开wireshark,设置监听网卡后,使用google chrome 浏览器访问我腾讯微博的首页 p.t.qq./welcomeback.php?lv=1#!/list/qqfriends/5/?pgv_ref=im.perinfo.perinfo.icon? ptlang=2052&pgv_ref=im.perinfo.perinfo.icon,抓得的UDP报文如图1所示。 图1 UDP报文 分析以上的报文容,UDP作为一种面向无连接服务的运输协议,其报文格式相当简单。第一行中,Source port:64318是源端口号。第二行中,Destination port:53是目的端口号。第三行中,Length:34表示UDP报文段的长度为34字节。第四行中,Checksum之后的数表示检验和。这里0x表示计算机中16进制数的开始符,其后的4f0e表示16进制表示的检验和,把它们换成二进制表示为:0100 1111 0000 1110. 从wireshark的抓包数据看出,我抓到的UDP协议多数被应用层的DNS协议应用。当一台主机中的DNS应用程序想要进行一次查询时,它构成了一个DNS 查询报文并将其交给UDP。UDP无须执行任何实体握手过程,主机端的UDP为此报文添加首部字段,并将其发出。 2. 使用wireshark抓取TCP报文 2.1 建立TCP连接的三次握手 建立TCP连接需要经历三次握手,以保证数据的可靠传输,同样访问我的腾讯微博主页,使用wireshark抓取的TCP报文,可以得到如图2所示的客户机和服务器的三次握手的过程。 图2 建立TCP连接的三次握手
网络协议分析——抓包分析
计算机网络技术及应用实验报告开课实验室:南徐学院网络实验室
第一部分是菜单和工具栏,Ethereal提供的所有功能都可以在这一部分中找到。第二部分是被捕获包的列表,其中包含被捕获包的一般信息,如被捕获的时间、源和目的IP地址、所属的协议类型,以及包的类型等信息。 第三部分显示第二部分已选中的包的每个域的具体信息,从以太网帧的首部到该包中负载内容,都显示得清清楚楚。 第四部分显示已选中包的16进制和ASCII表示,帮助用户了解一个包的本来样子。 3、具体分析各个数据包 TCP分析:
源端口 目的端口序号 确认号 首部长度窗口大小值
运输层: 源端口:占2个字节。00 50(0000 0000 1001 0000) 目的端口:占2个字节。C0 d6(1100 0000 1101) 序号:占四个字节。b0 fe 5f 31(1011 0000 0101 1110 0011 0001) 确认号:占四个字节。cd 3e 71 46(1100 1101 0011 1110 0110 0001 0100 0110) 首部长度:共20个字节:50(0101 0001) 窗口大小值:00 10(0000 0000 0001 00000) 网络层: 不同的服务字段:20 (0010 0000)
总的长度:00 28(0000 0000 0010 10000) 识别:81 28(1000 0001 0010 10000) 片段抵消:40 00(0100 0000 0000 0000) 生存时间:34 (0011 0100) 协议: 06(0000 0110)
drozer使用详解
Mercury(Android APP 应用安全评估) Mercury 是一款优秀的开源Android APP应用安全评估框架,它最赞的功能是可以动态的与android设备中的应用进行IPC(组件通信)交互。 一、安装与启动 1. 安装 (1)windows安装 第一步:下载Mercury 2.2.2 (Windows Installer) 第二步:在Android设备中安装agent.apk adb install agent.apk (2)*inux安装(Debian/Mac) apt-get install build-essential python-dev python-setuptools #以下步骤mac也适合 easy_install --allow-hosts https://www.wendangku.net/doc/a93859575.html, protobuf==2.4.1 easy_install twisted==10.2.0 (为了支持Infrastructure模式) wget https://www.wendangku.net/doc/a93859575.html,/assets/415/mercury-2.2.2.tar.gz tar zxvf mercury-2.2.2.tar.gz easy_install mercury-2.0.0-py2.7.egg 2. 启动 有三种方式 (1)USB方式的 第一步:在PC上使用adb进行端口转发,转发到Mercury使用的端口31415 adb forward tcp:31415 tcp:31415 第二步:在Android设备上开启Mercury Agent 选择embedded server-enable
抓包分析的方法
抓包分析的方法: 1. 先按照下面的方法将抓到的包的TIME STAMP 打开。 Ethereal →view →time display format →Date and time of day 2. 假定在一定的时间段里抓到三个包A1.cap,A2.cap,A 3.cap,则在合并包的时候按照从后往前 的时间顺序,打开A3.cap 再在菜单中选 FILE ->merge-->选择相应路径,选定A2.cap 选定 merge packet chronological 并将其另存为32.cap 3. 按照2的方法,将收集到的多个包组合成为一个全包AB.CAP 。 4.打开全包AB.CAP, 如需分析H248信令,则按照如下流程过虑 i.在里边先过虑:megaco.termid=="tdm/410" ,这里的终端标识 tdm/410请依照自己节点的相应标识输入; ii.从出来的信令里找到context ID CCC 和主叫侧rtp 端口号X1X1X1X1 被叫侧rtp 端口X2X2X2X3再修改 过虑条件为megaco.termid=="tdm/410" or megaco.context==CCC 这样再过虑出来的megaco 信令另存后就是比较全的信令流程; 如需看是否有丢包,以及AG 和TG 等的打包时间等,还需进行RTP 的分析,则继续按照如下条件过虑: iii .再修改过虑条件为 UDP.port==X1X1X1X1 or UDP.port==X2X2X2X2 这样过虑出来的包都是rtp 流,再如下操作: Analyze →decode as-→(选中decode) transport 里UDP 选both →再在右面的筐里选RTP. 如图所示: 再进行如附件的操作: statistics →RTP — stream analyse 经过虑后可以看到前向和后向的rtp 的相关信息,里边有是丢包情况的统计信息,Delta 是打包时长等。 如需听听RTP 语音流是什么内容,则再按照如下操作: 选 SA VE PAYLOAD →选择存储路径->format 选Both ----→channels 选both ,并将其存为 HHH.au 这样得到的hhh.au 文件就可以用Adobe Audition 工具打开即可听到其中的话音内容。
wireshark抓包分析了解相关协议工作原理
安徽农业大学 计算机网络原理课程设计 报告题目wireshark抓包分析了解相关协议工作原理 姓名学号 院系信息与计算机学院专业计算机科学与技术 中国·合肥 二零一一年12月
Wireshark抓包分析了解相关协议工作原理 学生:康谦班级:09计算机2班学号:09168168 指导教师:饶元 (安徽农业大学信息与计算机学院合肥) 摘要:本文首先ping同一网段和ping不同网段间的IP地址,通过分析用wireshark抓到的包,了解ARP地址应用于解析同一局域网内IP地址到硬件地址的映射。然后考虑访问https://www.wendangku.net/doc/a93859575.html,抓到的包与访问https://www.wendangku.net/doc/a93859575.html,抓到的包之间的区别,分析了访问二者网络之间的不同。 关键字:ping 同一网段不同网段 wireshark 协议域名服务器 正文: 一、ping隔壁计算机与ping https://www.wendangku.net/doc/a93859575.html,抓到的包有何不同,为什么?(1)、ping隔壁计算机 ARP包:
ping包: (2)ing https://www.wendangku.net/doc/a93859575.html, ARP包:
Ping包: (3)考虑如何过滤两种ping过程所交互的arp包、ping包;分析抓到的包有
何不同。 答:ARP地址是解决同一局域网上的主机或路由器的IP地址和硬件地址的映射问题,如果要找的主机和源主机不在同一个局域网上,就会解析出网 关的硬件地址。 二、访问https://www.wendangku.net/doc/a93859575.html,,抓取收发到的数据包,分析整个访问过程。(1)、访问https://www.wendangku.net/doc/a93859575.html, ARP(网络层): ARP用于解析IP地址与硬件地址的映射,本例中请求的是默认网关的硬件地址。源主机进程在本局域网上广播发送一个ARP请求分组,询问IP地址为192.168.0.10的硬件地址,IP地址为192.168.0.100所在的主机见到自己的IP 地址,于是发送写有自己硬件地址的ARP响应分组。并将源主机的IP地址与硬件地址的映射写入自己ARP高速缓存中。 DNS(应用层): DNS用于将域名解析为IP地址,首先源主机发送请求报文询问https://www.wendangku.net/doc/a93859575.html, 的IP地址,DNS服务器210.45.176.18给出https://www.wendangku.net/doc/a93859575.html,的IP地址为210.45.176.3
zheng-环境搭建及系统部署文档20170213(三版)
1Een 项目描述 基于Spring+SpringMVC+Mybatis分布式敏捷开发系统架构:内容管理系统(门户、博客、论坛、问答等)、统一支付中心(微信、支付宝、在线网银等)、用户权限管理系统(RBAC细粒度用户权限、统一后台、单点登录、会话管理)、微信管理系统、第三方登录系统、会员系统、存储系统 https://www.wendangku.net/doc/a93859575.html,/zhengAdmin/src/ 2项目组织结构
3项目模块图 4项目使用到的技术4.1后端技术 Spring Framework SpringMVC: MVC框架
Spring secutity|Shiro: 安全框架 Spring session: 分布式Session管理MyBatis: ORM框架 MyBatis Generator: 代码生成 Druid: 数据库连接池 Jsp|Velocity|Thymeleaf: 模板引擎ZooKeeper: 协调服务 Dubbo: 分布式服务框架 TBSchedule|elastic-job: 分布式调度框架Redis: 分布式缓存数据库 Quartz: 作业调度框架 Ehcache: 缓存框架 ActiveMQ: 消息队列 Solr|Elasticsearch: 分布式全文搜索引擎FastDFS: 分布式文件系统 Log4J: 日志管理 Swagger2: 接口文档 sequence: 分布式高效ID生产 https://www.wendangku.net/doc/a93859575.html,/yu120/sequence AliOSS|Qiniu: 云存储 Protobuf|json: 数据传输 Jenkins: 持续集成工具 Maven|Gradle: 项目构建管理
GoogleProtoBuf开发者指南
ProtoBuf开发指南 - 非官方不完整版 这个文档用于指导开发的,属于非官方发布版本进行选译的,并不完整。供参考使用。 1 概览 欢迎来到protocol buffer的开发者指南文档,一种语言无关、平台无关、扩展性好的用于通信协议、数据存储的结构化数据串行化方法。 本文档面向希望使用protocol buffer的Java、C++或Python开发者。这个概览介绍了protocol buffer,并告诉你如何开始,你随后可以跟随编程指导 ( https://www.wendangku.net/doc/a93859575.html,/apis/protocolbuffers/docs/tutorials.html )深入了解protocol buffer编码方式 ( https://www.wendangku.net/doc/a93859575.html,/apis/protocolbuffers/docs/encoding.html)。API 参考文档 ( https://www.wendangku.net/doc/a93859575.html,/apis/protocolbuffers/docs/reference/overview .html )同样也是提供了这三种编程语言的版本,不够协议语言 ( https://www.wendangku.net/doc/a93859575.html,/apis/protocolbuffers/docs/proto.html )和样式( https://www.wendangku.net/doc/a93859575.html,/apis/protocolbuffers/docs/style.html )指导都是编写 .proto 文件。 1.1 什么是protocol buffer ProtocolBuffer是用于结构化数据串行化的灵活、高效、自动的方法,有如XML,不过它更小、更快、也更简单。你可以定义自己的数据结构,然后使用代码生成器生成的代码来读写这个数据结构。你甚至可以在无需重新部署程序的情况下更新数据结构。 1.2 他们如何工作 你首先需要在一个 .proto 文件中定义你需要做串行化的数据结构信息。每个ProtocolBuffer信息是一小段逻辑记录,包含一系列的键值对。这里有个非常简单的 .proto 文件定义了个人信息: message Person { required string name=1; required int32 id=2; optional string email=3; enum PhoneType {
802.11数据抓包分析
802.11抓包分析 1.实验目的 分析802.11协议,了解802.11的帧格式 2.实验环境及工具 操作系统:ubuntu 实验工具:WireShark 3.实验原理 (1)802.11MAC层数据帧格式: Bytes 2 2 6 6 6 2 0-2312 4 Bits 2 2 4 1 1 1 1 1 1 1 1 Version:表明版本类型,现在所有帧里面这个字段都是0 Type:指明数据帧类型,是管理帧,数据帧还是控制帧,00表示管理帧,01表示控制帧,10表示数据帧 Subtype:指明帧的子类型 ,Data=0000,Data+CF-ACK=0001,Data+CF-Poll=0010, Data+CF-ACK+CF-Poll=0011,Nulldata=0100,CF-ACK=0101, CF-Poll=0110,Data+CF-ACK+CF-Poll=0111,QoS Data=1000, Qos Data+CF-ACK=1001,QoS Data+CF-Poll=1010, QoS Data+CF-ACK+CF-Poll=1011,QoS Null =1100, QoS CF-ACK=1101,QoS CF-Poll=1110,QoS Data+CF-ACK+CF-Poll=1111 To DS/From DS:这两个数据帧表明数据包的发送方向,分四种情况: 若数据包To DS为0,From DS为0,表明该数据包在网络主机间传输 若数据包To DS为0,From DS为1,表明该数据帧来自AP 若数据包To DS为1,From DS为0,表明该数据帧发送往AP 若数据包To DS为1,From DS为1,表明该数据帧是从AP发送往AP More flag.:置1表明后面还有更多段
IPV6抓包协议分析
IPV6协议抓包分析 一、实践名称: 在校园网配置使用IPv6,抓包分析IPv6协议 二、实践内容和目的 内容:网络抓包分析IPv6协议。 目的:对IPv6协议的更深层次的认识,熟悉IPv6数据报文的格式。 三、实践器材: PC机一台,网络抓包软件Wireshark 。 四、实验数据及分析结果: 1.IPv6数据报格式: 2. 网络抓包截获的数据:
3. 所截获的IPv6 的主要数据报为:? Internet Protocol Version 6?0110 .... = Version: 6?. (0000) 0000 .... .... .... .... .... = Traffic class: 0x00000000?.... .... .... 0000 0000 0000 0000 0000 = Flowlabel: 0x00000000 Payload length: 93 Next header: UDP (0x11)?Hop limit: 1?Source: fe80::c070:df5a:407a:902e (fe80::c070:df5a:407a:902e) Destination: ff02::1:2 (ff02::1:2) 4. 分析报文: 根据蓝色将报文分成三个部分:
第一部分: 33 33 00 01 00 02,目的组播地址转化的mac地址, 以33 33 00表示组播等效mac;00 26 c7 e7 80 28, 源地址的mac地址;86 dd,代表报文类型为IPv6 (0x86dd); 第二部分: 60,代表包过滤器"ip.version == 6"; 00 00 00,Traffic class(通信类别): 0x00000000; 00 5d,Payload length(载荷长度,即报文的最后一部分,或者说是报文携带的信息): 32; 11,Next header(下一个封装头): ICMPv6 (17); 01,Hop limit(最多可经历的节点跳数): 1; fe 80 00 00 00 00 00 00 c0 70 df 5a 40 7a 90 2e,源ipv6地址; ff 02 00 00 00 00 00 00 00 00 00 00 00 01 00 02,目的ipv6地址; 第三部分(报文携带的信息): 02,表示类型为Neighbor Solicitation (2); 22,表示Code: 38; 02 23是Checksum(校验和): 0x6faa [correct]; 00 5d 36 3a,Reserved(保留位): 00000000; fe 80 00 00 00 00 00 00 76 d4 35 ff fe 03 56 b0,是组播地址中要通信的那个目的地址; 01 01 00 23 5a d5 7e e3,表示
Ubuntu14.04的caffe编译及安装
Caffe Caffe CaffecuDNNAlexNetK40 1.17ms. Caffe BSD-2
sudo apt-get install build-essential # sudo apt-get install libprotobuf-dev libleveldb-dev libsnappy-dev libop encv-dev libhdf5-serial-dev protobuf-com sudo apt-get install --no-install-recommends libboost-all-dev CUDA7.5 Nvidia Ubuntudeb , sudo dpkg -i cuda-repo-ubuntu1404-7-5-local_7.5-18_amd64.deb sudo apt-get update
sudo apt-get install cuda sudo ldconfig /usr/local/cuda/lib64 660 sudo apt-get install nvidia-cuda-toolkit sudo apt-get install nvidia-352 sudo reboot Atlas sudo apt-get install libatlas-base-dev pythonpipeasy_install wget --no-check-certificate https://bootstrap.pypa.io/ez_setup.py sudo python ez_setup.py --insecure wget https://bootstrap.pypa.io/get-pip.py sudo python get-pip.py python sudo apt-get install libblas-dev liblapack-dev libatlas-base-dev gfortr an python-numpy
网络层数据包抓包分析
网络层数据包抓包分析 一.实验内容 (1)使用Wireshark软件抓取指定IP包。 (2)对抓取的数据包按协议格式进行各字段含义的分析。 二.实验步骤 (1)打开Wireshark软件,关闭已有的联网程序(防止抓取过多的包),开始抓包; (2)打开浏览器,输入https://www.wendangku.net/doc/a93859575.html,/网页打开后停止抓包。 (3)如果抓到的数据包还是比较多,可以在Wireshark的过滤器(filter)中输入http,按“Apply”进行过滤。过滤的结果就是和刚才打开的网页相关的数据包。 (4)在过滤的结果中选择第一个包括http get请求的帧,该帧用
于向https://www.wendangku.net/doc/a93859575.html,/网站服务器发出http get请求 (5)选中该帧后,点开该帧首部封装明细区中Internet Protocol 前的”+”号,显示该帧所在的IP包的头部信息和数据区: (6)数据区目前以16进制表示,可以在数据区右键菜单中选择“Bits View”以2进制表示:
(注意:数据区蓝色选中的数据是IP包的数据,其余数据是封装该IP包的其他层的数据) 回答以下问题: 1、该IP包的“版本”字段值为_0100_(2进制表示),该值代表该IP包的协议版本为: √IPv4 □IPv6 2、该IP包的“报头长度”字段值为__01000101__(2进制表示),该值代表该IP包的报头长度为__20bytes__字节。 3、该IP包的“总长度”字段值为___00000000 11101110___ (2进制表示),该值代表该IP包的总长度为__238__字节,可以推断出该IP包的数据区长度为__218__字节。 4、该IP包的“生存周期”字段值为__01000000__ (2进制表示),该值代表该IP包最多还可以经过___64__个路由器 5、该IP包的“协议”字段值为__00000110__ (2进制表示) ,该值代表该IP包的上层封装协议为__TCP__。 6、该IP包的“源IP地址”字段值为__11000000 10101000
Wireshark抓包实例分析
Wireshark抓包实例分析 通信工程学院010611班赖宇超01061093 一.实验目的 1.初步掌握Wireshark的使用方法,熟悉其基本设置,尤其是Capture Filter和Display Filter 的使用。 2.通过对Wireshark抓包实例进行分析,进一步加深对各类常用网络协议的理解,如:TCP、UDP、IP、SMTP、POP、FTP、TLS等。 3.进一步培养理论联系实际,知行合一的学术精神。 二.实验原理 1.用Wireshark软件抓取本地PC的数据包,并观察其主要使用了哪些网络协议。 2.查找资料,了解相关网络协议的提出背景,帧格式,主要功能等。 3.根据所获数据包的内容分析相关协议,从而加深对常用网络协议理解。 三.实验环境 1.系统环境:Windows 7 Build 7100 2.浏览器:IE8 3.Wireshark:V 1.1.2 4.Winpcap:V 4.0.2 四.实验步骤 1.Wireshark简介 Wireshark(原Ethereal)是一个网络封包分析软件。其主要功能是撷取网络封包,并尽可能显示出最为详细的网络封包资料。其使用目的包括:网络管理员检测网络问题,网络安全工程师检查资讯安全相关问题,开发者为新的通讯协定除错,普通使用者学习网络协议的
相关知识……当然,有的人也会用它来寻找一些敏感信息。 值得注意的是,Wireshark并不是入侵检测软件(Intrusion Detection Software,IDS)。对于网络上的异常流量行为,Wireshark不会产生警示或是任何提示。然而,仔细分析Wireshark 撷取的封包能够帮助使用者对于网络行为有更清楚的了解。Wireshark不会对网络封包产生内容的修改,它只会反映出目前流通的封包资讯。Wireshark本身也不会送出封包至网络上。 2.实例 实例1:计算机是如何连接到网络的? 一台计算机是如何连接到网络的?其间采用了哪些协议?Wireshark将用事实告诉我们真相。如图所示: 图一:网络连接时的部分数据包 如图,首先我们看到的是DHCP协议和ARP协议。 DHCP协议是动态主机分配协议(Dynamic Host Configuration Protocol)。它的前身是BOOTP。BOOTP可以自动地为主机设定TCP/IP环境,但必须事先获得客户端的硬件地址,而且,与其对应的IP地址是静态的。DHCP是BOOTP 的增强版本,包括服务器端和客户端。所有的IP网络设定数据都由DHCP服务器集中管理,并负责处理客户端的DHCP 要求;而客户端则会使用从服务器分配下来的IP环境数据。 ARP协议是地址解析协议(Address Resolution Protocol)。该协议将IP地址变换成物理地址。以以太网环境为例,为了正确地向目的主机传送报文,必须把目的主机的32位IP地址转换成为48位以太网的地址。这就需要在互连层有一组服务将IP地址转换为相应物理地址,这组协议就是ARP协议。 让我们来看一下数据包的传送过程:
comake使用详解
Comake2使用详解 1、适用用户范围: 第一次使用comake2工具 使用comake2搭建环境:这时用户不需要关心COMAKE文件细节,和第一次使用comake2工具时的情形差不多,第一次使用comake2工具初始化环境 $mkdir --parent ps/se/ac/make $cd ps/se/ac/make $comake2 -S $comake2 -UB comake2 -S //初始化COMAKE文件 comake2 -S表示从平台最新基线版本获取依赖列表;comake2 -S -r 1.0.1.0表示从平台1.0.1.0版本获取依赖列表友情提示:如果你的代码库里已有COMAKE文件,可跳过这一步;如果你的模块路径是ps/se/ac/make,请cd ps/se/ac/make再执行comake2 -S命令 comake2 -UB //下载并编译依赖代码 2、comake2命令 $ comake2 -h comake[com make]能够自动帮助用户搭建环境,并且生成Makefile工具. 程序会读取目录下面的COMAKE文件,产生Makefile和环境.用户需要提供这个COMAKE文件. 参数: -h --help 查看帮助 -D --debug 开启debug选项[默认不打开].-D -D可以查看更多调试信息. -S --scratch 创建一个默认的COMAKE文件 -r --revision 从平台检出模块cvspath指定的TAG对应的依赖列表,配合-S使用,如-S -r 1.0.0.0 -E --export-configs 导出模块的4位版本依赖,存放在COMAKE.CONFIGS下面.比如-E public/ub@1.0.0.0 -W --watch-configs 查看本地依赖模块.-W -W可以查看模块引入来源.-W -W -W可以查看依赖模块的依赖. -I --import-files 在解释COMAKE文件之前导入模块 -C --change directory 切换到directory下面执行[默认当前目录] -Q --quiet 安静模式[默认不打开] -U --update-configs 更新环境 -B --build-configs 构建环境 -F --force 构建环境时强制进行[默认不进行] -e --export-local-configs 导出本地环境到CONFIGS.SCM文件 -f --scmfile= 重现编译环境 -d --devdiff 存在本地修改的共同开发依赖列表(多模块共同开发时适用) -J --make-thread-number= 如果模块使用COMAKE生成的Makefile的话,编译线程数[默认是4] -j --modules-thread-number= 并发下载、编译模块的线程数[默认是1] -K --keep-going 构建/更新环境中途出错的话,忽略错误继续[已废弃] -P --pretreatment 生成Makefile时不进行预处理[默认进行预处理] -O --quot-all-deps 生成Makefile时引用所有头文件依赖[默认过滤目录外依赖]
IP抓包分析
IP抓包实验 一.数据截图 二.分析 这个IP协议报文我是在访问一个网站时抓到的。 从截图中我们可以看到IP的版本号(Version)为4,即IPV4协议。首部长度(Head length)为20字节。服务类型(differentiated services field)为0000,说明是一般服务。数据报总长度(total length)为56 。标识(identification)为0x4a28(18984),由信源机产生,每次自动加1,当IP数据报被分片时,每个数据分片仍然沿用该分片所属的IP数据报的标识符,信宿机根据该标识符完成数据报重组。标志(FLAGS)为0x04,表示不允许分片(DON'T FRAGMENT),标志用于是否允许分片以及是否是最后一片。片位移(fragment
offset)为0,表示本片数据在它所属数据报数据区中的偏移量,是信宿机进行各分片的重组提供顺序依据。生存时间(time to live)为64,用来解决循环路径问题,数据报没经过一个路由器,TTL减1,当TTL减为0时,如果仍未到达信宿机,便丢弃该数据报。协议标识(protocol)为0x06,表示被封装的协议为TCP。首部校验和(head checksum)为0xf5f4,表示首部数据完整。源主机(客户机)地址为192.168.0.103,目的主机(服务器)地址为220.181.92.222。 0806580121 刘敏 2011年1月9日
妈妈新开了个淘宝店,欢迎前来捧场 妈妈的淘宝点开了快半年了,主要卖的是毛绒玩具、坐垫、抱枕之类的,感觉妈妈还是很用心的,花了不少功夫,所以我也来出自己的一份力,帮忙宣传一下。 并且妈妈总是去五亭龙挑最好的玩具整理、发货,质量绝对有保证。另外我家就在扬州五亭龙玩具城旁边,货源丰富,质量可靠,价格便宜。 欢迎大家来逛逛【扬州五亭龙玩具总动员】https://www.wendangku.net/doc/a93859575.html,
(完整word版)网络协议抓包分析
中国矿业大学《网络协议》 姓名:李程 班级:网络工程2009-2 学号:08093672
实验一:抓数据链路层的帧 一、实验目的 分析MAC层帧结构 二、准备工作 本实验需要2组试验主机,在第一组上安装锐捷协议分析教学系统,使用其中的协议数据发生器对数据帧进行编辑发送,在第二组上安装锐捷协议分析教学系统,使用其中的网络协议分析仪对数据帧进行捕获分析。 三、实验内容及步骤 步骤一:运行ipconfig命令
步骤二:编辑LLC信息帧并发送 步骤三:编辑LLC监控帧和无编号帧,并发送和捕获:步骤四:保存捕获的数据帧 步骤五:捕获数据帧并分析 使用iptool进行数据报的捕获: 报文如下图: 根据所抓的数据帧进行分析: (1)MAC header 目的物理地址:00:D0:F8:BC:E7:06 源物理地址:00:16:EC:B2:BC:68 Type是0x800:意思是封装了ip数据报 (2)ip数据报
由以上信息可以得出: ①版本:占4位,所以此ip是ipv4 ②首部长度:占4 位,可表示的最大十进制数值是15。此ip数据报没有选项,故它的最大十进制为5。 ③服务:占8 位,用来获得更好的服务。这里是0x00 ④总长度:总长度指首都及数据之和的长度,单位为字节。因为总长度字段为16位,所以数据报的最大长度为216-1=65 535字节。 此数据报的总长度为40字节,数据上表示为0x0028。 ⑤标识(Identification):占16位。IP软件在存储器中维持一个计数器,每产生一个数据报,计数器就加1,并将此值赋给标识字段。但这个“标识”并不是序号, 因为IP是无连接的服务,数据报不存在按序接收的问题。当数据报由于长度超过网络的MTU 而必须分片时,这个标识字段的值就被复制到所有的数据报的标识字段中。相同的标识字段的值使分片后的各数据报片最后能正确地重装成为原来的数据报。 在这个数据报中标识为18358,对应报文16位为47b6 ⑥标志(Flag):占3 位,但目前只有2位有意义。标志字段中的最低位记为MF (More Fragment)。MF=1即表示后面“还有分片”的数据报。MF=0表示这已是若干数据报片中的最后一个。标志字段中间的一位记为DF(Don't Fragment),意思是“不能分片”。只有当DF=0时才允许分片。这个报文的标志是010,故表示为不分片!对应报文16位为0x40。 ⑦片偏移:因为不分片,故此数据报为0。对应报文16位为0x00。 ⑧生存时间:占8位,生存时间字段常用的英文缩写是TTL (Time To Live),其表明数据报在网络中的寿命。每经过一个路由器时,就把TTL减去数据报在路由器消耗掉的一段时间。若数据报在路由器消耗的时间小于1 秒,就把TTL值减1。当TTL值为0时,就丢弃这个数据报。经分析,这个数据报的的TTL为64跳!对应报文16位为0x40。 ⑨协议:占8 位,协议字段指出此数据报携带的数据是使用何种协议,以便使目的主机的IP层知道应将数据部分上交给哪个处理过程。这个ip数据报显示使用得是TCP协议对
Protobuf编码详解
prtotocol buffer是google于2008年开源的一款非常优秀的序列化反序列化工具,它最突出的特点是轻便简介,而且有很多语言的接口(官方的支持C++,Java,Python,C,以及第三方的Erlang, Perl等)。本文从protobuf如何将特定结构体序列化为二进制流的角度,看看为什么Protobuf如此之快。 一,示例 从例子入手是学习一门新工具的最佳方法。下面我们通过一个简单的例子看看我们如何用protobuf 的C++接口序列化反序列化一个结构体。 1,编辑您将要序列化的结构体描述文件Hello.proto 每个结构体必须用message来描述,其中的每个字段的修饰符有required, repeated和optional 三种,required表示该字段是必须的,repeated表示该字段可以重复出现,它描述的字段可以看做C语言中的数组,optional表示该字段可有可无。 同时,必须人为地为每个字段赋予一个标号field_number,如上图中的1,2,3,4所示。更详细的proto文件的编写规则见这里。 2,用protoc工具“编译”Hello.proto protoc工具使用的一般格式是: protoc -I=$SRC_DIR --cpp_out=$DST_DIR $SRC_DIR/xxx.proto 其中SRC_DIR是proto文件所在的目录,DST_DIR是编译proto文件后生成的结构体处理文件的目录 之后会生成对结构体Hello.proto中描述的各字段做序列化反序列化的类 3, 编写序列化进程https://www.wendangku.net/doc/a93859575.html,
我们用set方法为结构体中的每个成员赋值,然后调用SerializeToOstream将结构体序列化到文件log中。 并编译它: 4,编写反序列化进程https://www.wendangku.net/doc/a93859575.html, 用ParseFromIstream将文件中的内容序列化到类Hello的对象msg中。 并编译它: , 5,做序列化和反序列化操作 上面只是一个简单的例子,并没有对protobuf的性能做测试,protobuf的性能测试详见这里。
TCP-IP协议抓包分析实验报告
TCP协议分析实验 学号: 姓名: 院系: 专业:
一.实验目的 学会使用Sniffer抓取ftp的数据报,截获ftp账号及密码,并分析TCP 头的结构、分析TCP的三次“握手”和四次“挥手”的过程,熟悉TCP 协议工作方式。 二.实验(软硬件以及网络)环境 利用VMware虚拟机建立网络环境,并用Serv-U FTP Server在计算机上建立FTP服务器,用虚拟机进行登录。 三.实验工具 sniffer嗅探器,VMware虚拟机,Serv-U FTP Server。 四.实验基本配置 Micrsoft Windows XP操作系统 五.实验步骤 1.建立网络环境。 用Serv-U FTP Server在计算机上建立一台FTP服务器,设置IP地址 为:,并在其上安装sniffer嗅探器。再并将虚拟机作为一台FTP客户 端,设置IP地址为:。设置完成后使用ping命令看是否连通。 2.登录FTP 运行sniffer嗅探器,并在虚拟机的“运行”中输入,点确定后出现 如下图的登录窗口: 在登录窗口中输入:用户名(hello),密码(123456)【在Serv-U FTP Server中已设定】,就登录FTP服务器了。再输入“bye”退出FTP 3.使用sniffer嗅探器抓包 再sniffer软件界面点击“stop and display”,选择“Decode”选 项,完成FTP命令操作过程数据包的捕获。 六.实验结果及分析 1.在sniffer嗅探器软件上点击Objects可看到下图:
再点击“DECODE(反解码)”按钮进行数据包再分析,我们一个一个的分析数据包,会得到登录用户名(hello)和密码(123456)。如下图: 2. TCP协议分析 三次握手: 发报文头——接受报文头回复——再发报文(握手)开始正式通信。
Ubuntu下安装Caffe
Ubuntu下安装Caffe 安装需要的软件: 1. Ubuntu14.0.4 2. cuda-repo-ubuntu1504-7-5-local_7.5-18_amd64 3. caffe-master 安装Ubuntu的过程在这里不做介绍。系统安装好了之后,执行下面的操作。 在线安装的步骤,在此之前将更新源换成163的,下载速度会快很多: 1. sudo apt-get update 2. sudo apt-get upgrade 以上更新系统相关软件 3. sudo apt-get install build-essential 4. sudo apt-get install libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-dev libboost-all-dev libhdf5-serial-dev 5. sudo apt-get install libgflags-dev libgoogle-glog-dev liblmdb-dev protobuf-compiler 6. sudo apt-get install libatlas-base-dev python-dev vim 以上为在线安装的依赖项需要按顺序执行 7. 切换到cuda安装包的目录下,执行sudo dpkg -i cuda-repo-ubuntu1504-7-5- local_7.5-18_amd64 8. sudo apt-get update 9. sudo apt-get install -y cuda 以上为安装CUDA驱动。(Nvidia驱动在这个过程也会自动装好) 10. vim ~/.bashrc 11. 按i进入编辑状态,将光标移到最下面一行。输入export PATH=/usr/local/cuda- 7.5/bin:$PATH 12. 输入export LD_LIBRARY_PATH=/usr/local/cuda- 7.5/lib64:$LD_LIBRARY_PATH,按:wq保存并退出 13. source ~/.bashrc 以上为配置环境变量 14. 将下载好的caffe源文件解压缩,即caffe-master然后切到那个目录中执行cp Makefile.config.example Makefile.config 15. vim Makefile.config 16. 按i进入编辑状态,修改:CUDA_DIR :=/usr/local/cuda-7.5 17. 如果使用了MATLAB或者Python需要按照Makefile.config文件中的提示在 Makefile.config进行相应的路径修改即可。 以上为配置Caffe相关路径 18. make all 19. make test 20. make runtest
Unity3D客户端和Java服务端使用Protobuf
Unity3D客户端和Java服务端使用Protobuf 本文测试环境: 系统:WINDOWS 7(第3、6步)、OS X 10.9(第4步)软件:VS 2012(第3、6步)、Eclipse(第5、6步) 硬件:iPad 2(第4步)、Macbook Pro Mid 2012(第4步)文章目录: 1、关于Protobuf的C#实现 2、为什么有些Protobuf发布到iOS就用不了,甚至有些在PC都用不了? 3、手动处理C#版本的Protobuf 3.1、创建一个C#工程,先手动创建每一个要通过Protobuf序列化或反序列化的数据模型类,然后导出dll 3.2、创建一个用于序列化的C#工程,然后运行生成dll 3.3、将上面两个工程生成的dll拖到unity中 4、在Unity中反序列化Protobuf 5、服务端Java也用Protobuf 6、太烦了?!客户端也要自动处理Protobuf1、关于Protobuf 的C#实现 首先,U3D里面Protobuf使用的是C#的实现,那么目前有几个可选的C#实现:
C#: https://www.wendangku.net/doc/a93859575.html,/p/protobuf-csharp-port C#: https://www.wendangku.net/doc/a93859575.html,/p/protosharp/ C#: https://https://www.wendangku.net/doc/a93859575.html,/protobuf/ C#/.NET/WCF/VB: https://www.wendangku.net/doc/a93859575.html,/p/protobuf-net/我这里选用的是https://www.wendangku.net/doc/a93859575.html,/p/protobuf-net/(你可以在 https://https://www.wendangku.net/doc/a93859575.html,/p/protobuf-net/downloads/list 这里下载到他的代码和工具),它比较好的一点是,提供了各种平台的支持,解压后在“Full”目录中可以看到各个平台的支持看到里面的unity了吗,它里面的protobuf-net.dll将是我们准备用到的。2、为什么有些Protobuf发布到iOS就用不了,甚至有些在PC都用不了? a、Protobuf使用了JIT,即在运行时动态编译,而这个特性在Unity发布到iOS时候是不支持的。因此,会导致你在PC 上可以正常运行,发布到iOS就有问题。 b、Protobuf是基于.net 2.0以上框架写的,而Unity仅支持.net 2.0,或者有些使用2.0中比较多的特性,而你在Unity 中发布设置了.net 2.0的子集。后者你只需要在Player setting中修改设置就可以了。 上面两项也可适用于其它第三方类库,如果你自己下载了一个在PC上或C#里面能正常使用的类库,在U3D里面就不能用了,那么请检查是否是上面两条原因导致的。3、手动
- WireShark抓包网络报文分析实验报告
- IPV6抓包协议分析
- 抓包分析HTTP
- 抓包分析的方法
- IGMP及抓包分析要点
- Wireshark抓包分析PPT学习课件
- 计算机网络抓包实验分析
- Wireshark抓包分析专题培训课件
- DHCP报文精细分析,加上wireshark抓包
- 网络层数据包抓包分析
- 2.7 HTTP抓包分析
- 网络抓包分析介绍
- 科来网络分析系统抓包简明教程
- wireshark抓包分析报告TCP和UDP
- 网络抓包分析程序
- 网络抓包与分析培训.pptx
- wireshark实验抓包分析
- WIRESHARK抓包分析TCP和UDP
- 实验二 网络抓包及协议分析软件使用说明
- 802.11数据抓包分析