应用多元分析作业二浙江万里学院
实验六聚类分析
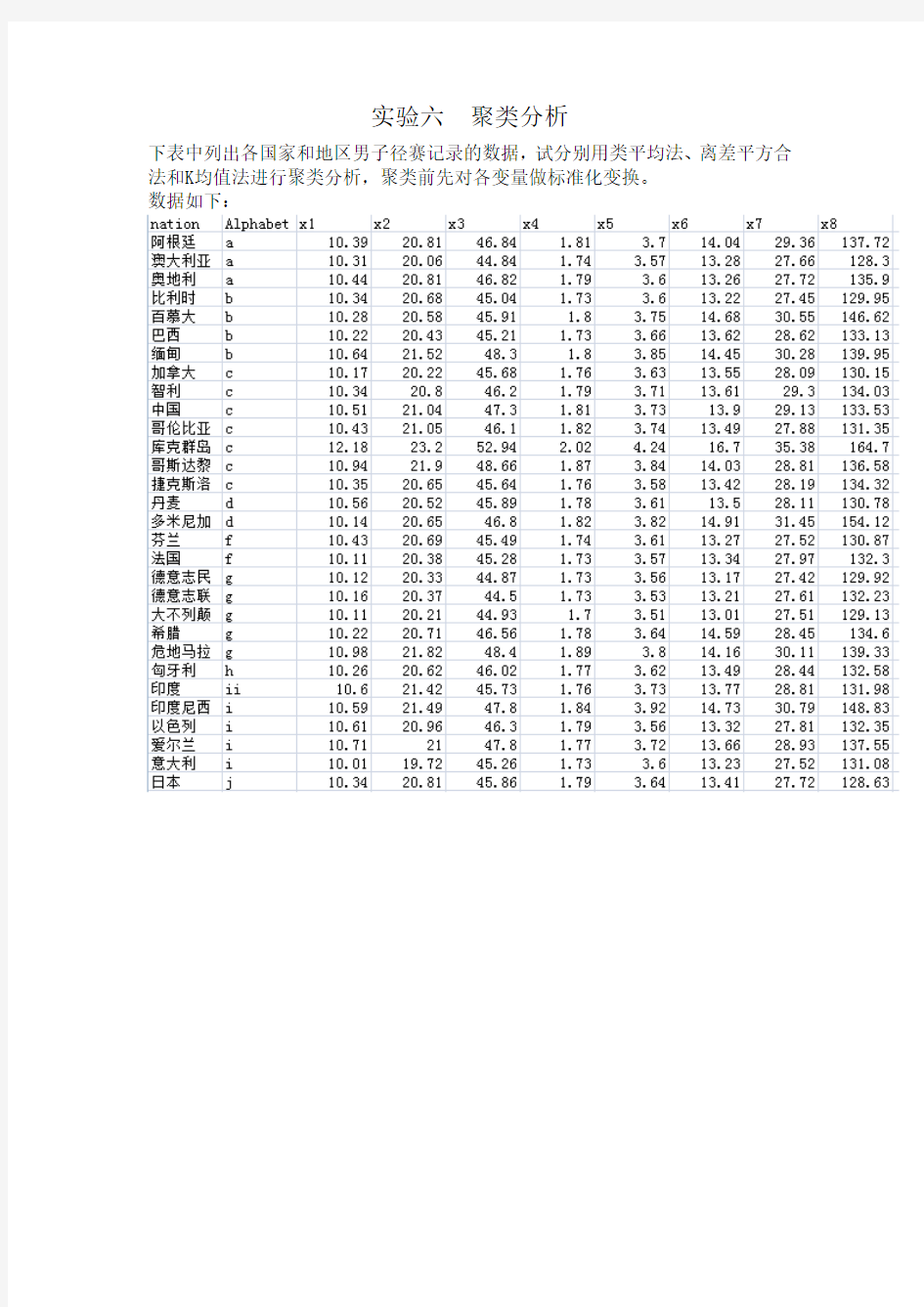
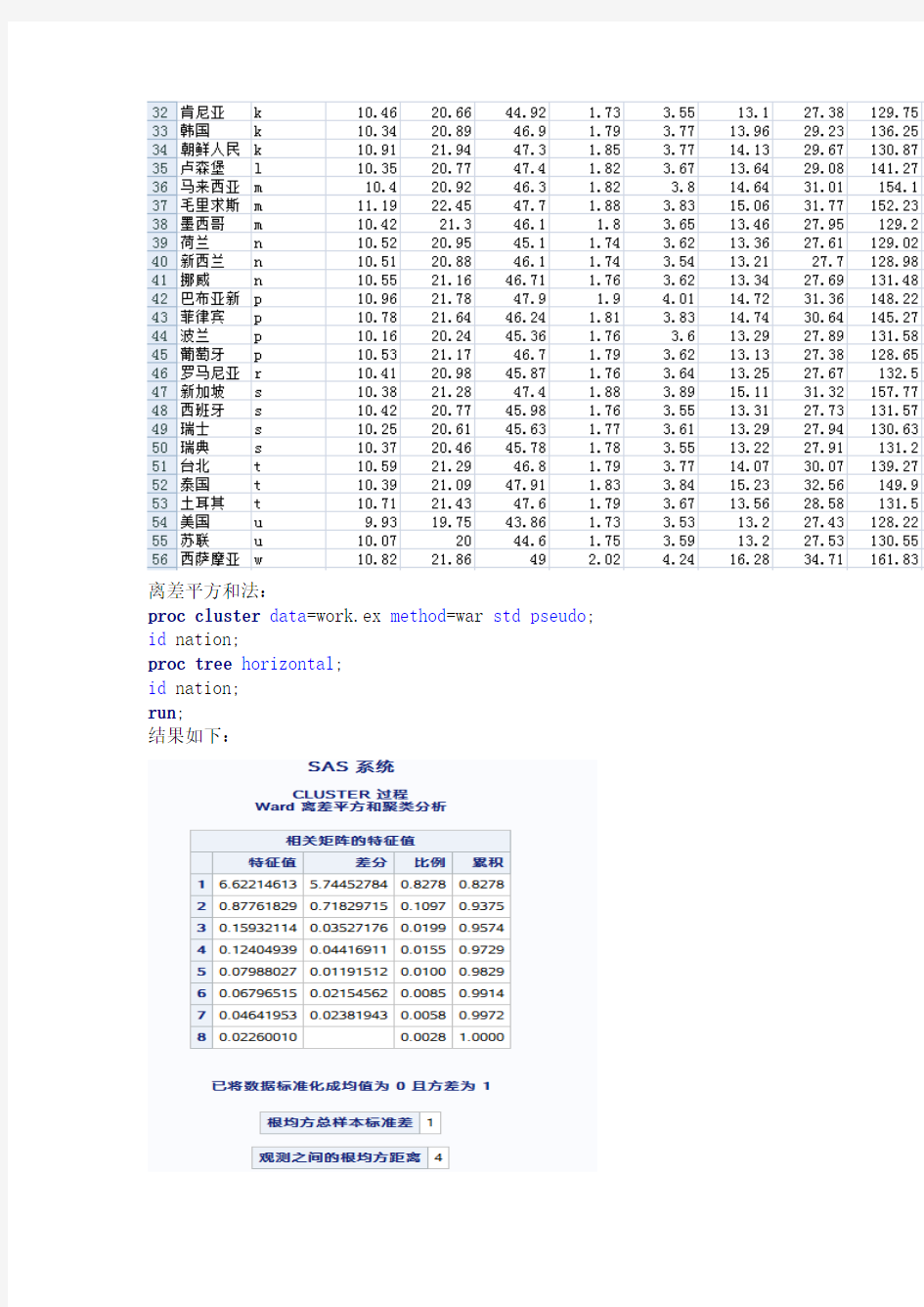
下表中列出各国家和地区男子径赛记录的数据,试分别用类平均法、离差平方合法和K均值法进行聚类分析,聚类前先对各变量做标准化变换。
数据如下:
离差平方和法:
proc cluster data=work.ex method=war std pseudo; id nation;
proc tree horizontal;
id nation;
run;
结果如下:
类平均法:
proc cluster data=work.ex method=ave std pseudo; id nation;
proc tree horizontal;
id nation;
run;
结果如下:
由上面的类平均法可知:k可取5,即在k均值法中取k=5. K均值法:
proc standard data=work.ex mean=0std=1out=stan; proc fastclus data=stan maxc=5drift list;
var x1-x8;
id nation;
run;
结果如下:
统计学原理期末卷A
浙江万里学院 期末考试1 课程名称:统计学原理(专升本) 1、(单选题)某地区有10万人口,共有80个医院。平均每个医院要服务1250人,这个指标就是( )。(本题 2、0分) A、平均指标 B、强度相对指标 C、总量指标 D、发展水平指标 答案:B、 解析:无、 2、(单选题)总量指标数值大小( )(本题2、0分) A、随总体范围扩大而增大 B、随总体范围扩大而减小 C、随总体范围缩小而增大 D、与总体范围大小无关 答案:A、 解析:无、 3、(单选题)数据筛选的主要目的就是( )。(本题2、0分) A、发现数据的错误 B、对数据进行排序 C、找出所需要的某类数据 D、纠正数据中的错误 答案:C、 解析:无、 4、(单选题)抽样调查所特有的误差就是( )。(本题2、0分) A、A 由于样本的随机性而产生的误差 B、B 登记误差 C、C 系统性误差 D、D ABC都错 答案:A、 解析:无、 5、(单选题)某工厂有100名职工,把她们的工资加总除以100,这就是对100个( )求平均数(本题2、0分) A、A 变量
B、B 标志 C、C 变量值 D、D 指标 答案:C、 解析:无、 6、(单选题)“增长1%的绝对值”反映的就是同样的增长速度在不同条件下所包含的绝对水平。(本题2、0分) A、计量单位 B、数据类型 C、时间 D、调查方法 答案:C、 解析:无、 7、(单选题)在其她条件不变的情况下,当总体数据的离散程度较大时,总体均值的置信区间( )。(本题2、0分) A、可能变宽也可能变窄 B、变窄 C、变宽 D、保持不变 答案:C、 解析:无、 8、(单选题)将某企业职工的月收入依次分为2000元以下、2000元~3000元、3000元~4000元、4000元~5000元、5000元以上几个组。第一组的组中值近似为( )(本题2、0分) A、2000 B、1000 C、1500 D、2500 答案:C、 解析:无、 9、(单选题)统计指标有如下特点( )。(本题2、0分) A、A 数量性、综合性、具体性 B、B 准确性、及时性、完整性 C、C 大量性、同质性、差异性 D、D 科学性、客观性、社会性 答案:A、 解析:无、 10、(单选题)设 zc 为检验统计量的计算值,检验的假设为H 0 : μ =μ0 , H 1 : μ ≠μ0 , zc = - 1、96 时,计算出的 P 值为( )。(本题2、0
实验7 OSPF路由协议配置 实验报告
浙江万里学院实验报告 课程名称:数据通信与计算机网络及实践 实验名称:OSPF路由协议配置 专业班级:姓名:小组学号:2012014048实验日期:6.6
再测试。要求写出两台路由器上的ospf路由配置命令。
[RTC-rip-1]import ospf [RTC-rip-1]quit [RTC]ospf [RTC-ospf-1]import rip [RTC-ospf-1]quit
结合第五步得到的路由表分析出现表中结果的原因: RouteB 通过RIP学习到C和D 的路由情况,通过OSPF学习到A 的路由信息 实验个人总结 班级通信123班本人学号后三位__048__ 本人姓名_ 徐波_ 日期2014.6.06 本次实验是我们的最后一次实验,再次之前我们已经做了很多的有关于华为的实验,从一开始的一头雾水到现在的有一些思路,不管碰到什么问题,都能够利用自己所学的知识去解决或者有一些办法。这些华为实验都让我受益匪浅。 实验个人总结 班级通信123班本人学号后三位__046__ 本人姓名_ 金振宁_ 日期2014.6.06 这两次实验都可以利用软件在寝室或者去其他的地方去做,并不拘泥于实验室,好好的利用华为的模拟机软件对我们来说都是非常有用的。 实验个人总结 班级通信123班本人学号后三位__044_ 本人姓名_ 陈哲日期2014.6.06
理解OSPF路由协议,OSPF协议具有如下特点: 适应范围:OSPF 支持各种规模的网络,最多可支持几百台路由器。 快速收敛:如果网络的拓扑结构发生变化,OSPF 立即发送更新报文,使这一变化在自治系统中同步。 无自环:由于OSPF 通过收集到的链路状态用最短路径树算法计算路由,故从算法本身保证了不会生成自环路由。 实验个人总结 班级通信123班本人学号后三位__050 本人姓名_ 赵权日期2014.6.06 通过本次实验学会了基本的在路由器上配置OSPF路由协议,组建一个简单的路由网络。想必以后的生活中有可能会用到。
应用多元统计分析SAS作业审批稿
应用多元统计分析S A S 作业 YKK standardization office【 YKK5AB- YKK08- YKK2C- YKK18】
5-9 设在某地区抽取了14块岩石标本,其中7块含矿,7块不含矿。对每块岩石测定了Cu,Ag,Bi三种化学成分的含量,得到的数据如表1。 表1 岩石化学成分的含量数据 (1)假定两类样本服从正态分布,使用广义平方距离判别法进行判别归类(先验概率取为相等,并假定两类样本的协方差阵相等); (2)今得一块标本,并测得其Cu,Ag,Bi的含量分别为2.95,2.15和1.54,试判断该标本是含矿还是不含矿? 问题求解 1 使用广义平方距离判别法对样本进行判别归类 用SAS软件中的DISCRIM过程进行判别归类。 SAS程序及结果如下。 data d59; input group x1-x3@@; cards; 1 2.58 0.9 0.95 1 2.9 1.23 1 1 3.55 1.15 1 1 2.35 1.15 0.79 1 3.54 1.85 0.79 1 2.7 2.23 1.3 1 2.7 1.7 0.48 2 2.25 1.98 1.06 2 2.16 1.8 1.06 2 2.3 3 1.7 4 1.1 2 1.96 1.48 1.04
2 1.94 1.4 1 2 3 1.3 1 2 2.78 1.7 1.48 ; proc print data =d59; run ; proc discrim data =d59 pool =yes distance list ; class group; var x1-x3; run ; 由输出结果可知,两总体间的广义平方距离为D 2=3.19774。还可知两个三元总体均值相等的检验结果:D =3.19774,F =3.10891,p =0.0756<0.10,故在显着性水平=0.10α时量总体的均值向量有显着差异,即认为讨论这两个三元总体的判别问题是有意义的。 线性判别函数为: 判别结果为含矿的6号样本错判为不含矿;不含矿的13号样本错判为含矿。 2 对给定样本判别归类 将Cu ,Ag ,Bi 的含量数值2.95、2.15、1.54分别代入线性判别函数得: 1244.674246.978882Y Y ==,。 贝叶斯判别的解{}***1, ,k D D D = 为 {}*|()(),,1, ,(1, ,)t t j D X Y X Y X j t j k t k =>≠==, 由于1244.6742246.97888Y Y =<=,因此待判的样品判为不含矿。 5-10 已知某研究对象分为三类,每个样品考察4项指标,各类的观测样品数分别为7,4,6;类外还有3个待判样品(所有观测数据见表2)。假定样本均来自正态总体。 表2 判别分类的数据
ospf协议,实验报告
ospf协议,实验报告 篇一:实验7 OSPF路由协议配置实验报告 浙江万里学院实验报告 课程名称:数据通信与计算机网络及实践 实验名称: OSPF路由协议配置专业班级:姓名:小组学号:XX014048 实验日期: 再测试。要求写出两台路由器上的ospf路由配置命令。 第页共页 [RTC-rip-1]import ospf [RTC-rip-1]quit [RTC]ospf [RTC-ospf-1]import rip [RTC-ospf-1]quit 结合第五步得到的路由表分析出现表中结果的原因: RouteB 通过RIP学习到C和D 的路由情况,通过OSPF 学习到A 的路由信息 实验个人总结 班级通信123班本人学号后三位__048__ 本人姓名_徐波_ 日期 本次实验是我们的最后一次实验,再次之前我们已经做了很多的有关于华为的实验,从一开始的一头雾水到现在的有一些思路,不管碰到什么问题,都能够利用自己所学的知识去解决或者有一些办法。这些华为实验都让我受益匪浅。
实验个人总结 班级通信123班本人学号后三位__046__ 本人姓名_金振宁_ 日期 这两次实验都可以利用软件在寝室或者去其他的地方去做,并不拘泥于实验室,好好的利用华为的模拟机软件对我们来说都是非常有用的。 实验个人总结 班级通信123班本人学号后三位本人姓名_陈哲日期 第页共页 篇二:单区域的OSPF协议配置实验报告 学生实验报告 *********学院 篇三:OSPF实验报告 计算机学院 实验报告 ( XX 年春季学期) 课程名称:局域网设计与管理 主讲教师:李辉 指导教师:学生姓名: 学 年郑思楠号: XX012019 级: XX级
浙江万里学院环境监测期末试卷及答案
一、填空 1、江河水系或某一河段,监测时要求设置背景断面、对照断面、控制断面、监测断面等 断面,断面选定后,应根据水面的宽度确定断面上的采样垂线,再根据采样垂线的深度确定采样点的位置。监测断面和采样点确定后,应设置固定天然或人工的标志物以保证样品的代表性和可比性。 2、地表水的采样时间和采样频次的确定原则是:对较大的水系干流和中小河流,全年采样时间为丰 水期、枯水期、平水期,每期采样两次,流经城市工业区、污染较重的河流、游览水域,饮用水源地全年采样不少于 12 次,采样时间为每月一次或视具体情况而定。 3、为了克服污染物随时间的变化,通常采用优化频次的办法来解决,克服在空间上的不同, 通常采用优化布点的办法来解决。 4、测定COD的水样,采样时用硬质玻璃瓶容器贮存,保存时加硫酸。 5、硝酸-高氯酸消解法,一般先加入硝酸氧化水样中的羟基化合物,稍冷后再加另一种酸 进行消解。 6、水的颜色分为真色和表色,真色是指除去悬浮物后水的颜色,反之则为表色;采用铂钴标准比 色法是先配制标准色列再与水样的颜色进行目视比色确定,稀释倍数法是 7、取某水样50ml于坩埚中蒸干后移入103-105℃烘箱内烘至恒重,冷却后称重为32.9682g,然后再 移入马弗炉中高温燃烧,冷却后称重为31.5349g,已知坩埚的重量为31.3259g,则该水样的TSS(总 悬浮物)= 1.6423 ,TVSS(总可挥发物)= 1.4333 ,总固定性固体浓度= 32846mg/L 。 8、大气监测必测项目有 PM10 、 PM2.5 、 SO2/NO2/CO/O3 、硫酸盐化速率、灰尘 自然降尘量。 9、采集降水的采样器要高于基础面 1.2cm 以上,采集雪水时的采样器要求是塑料容器且上口比 采集降雨时的采样器大10cm以上。 10、固定污染源采样位置要求采样断面设置在阻力构件下游方向大于6倍管道直径处或上游方 向大于3倍管道直径处,难于满足时,应≮1.5d,并适当增加采样点数目和采样频 率,最好在5m/S的断面上设置,优先考虑在垂直管道上设置。 11、测定咽气烟尘浓度必须采用等速采样采样,当采样速度大于采样点的咽气速度 时,导致测量结果偏低,反之结果则偏高。
03第三篇 多元统计分析作业题
第三篇 多元统计分析作业题 1 证明题 1)已知ψ==A X E X Z T T T ,这里用到关系1-ψ=E A 。以二变量为例证明: 12*-Λ=ψ=A X A X Z T T T 1)(-=T T A X 。 式中X 为标准化原始变量矩阵,A 为载荷矩阵,Z 为非标准化主成分得分,Z *为标准化的因子得分,E 为单位化特征向量构成的矩阵即正交矩阵,Ψ为特征根的平方根的倒数构成的对角阵,Λ为特征根构成的对角阵,对于二变量有 ?????? ??=ψ21 /10 /1λλ, ?? ? ???=Λ21 00λλ. 2)对于二变量因子模型,我们有 ?? ?++=++=222221122 112211111εεu f a f a x u f a f a x . 试以 x 1为例证明1 2 22==+j x j j u h σ ,这里∑== p k kj j a h 1 2 22 21 211a a +=。 2 计算题 1)现有一组古生物腕足动物贝壳标本的两个变量:长度x 1和宽度x 2。所测数据如下(表2.1)。 要求: ① 利用Excel 对数据进行主成分分析。 ② 借助SPSS 对该数据进行主成分分析,并计算结果与Excel 的计算结果进行对比,理解各个表格所给参数的含义。 ③ 用本例数据验证证明题?的推导结果。 表2.1 古生物腕足动物贝壳标本数据 样品编号 长度x 1 宽度x 2 样品编号 长度x 1 宽度x 2 1 3 2 14 12 10 2 4 10 15 12 11 3 6 5 16 13 6 4 6 8 17 13 14 5 6 10 18 13 15 6 7 2 19 13 17 7 7 13 20 14 7 8 8 9 21 15 13 9 9 5 22 17 13
应用多元统计分析试题及答案
一、填空题: 1、多元统计分析是运用数理统计方法来研究解决多指标问题的理论和方法. 2、回归参数显著性检验是检验解释变量对被解释变量的影响是否著. 3、聚类分析就是分析如何对样品(或变量)进行量化分类的问题。通常聚类分析分为 Q型聚类和 R型聚类。 4、相应分析的主要目的是寻求列联表行因素A 和列因素B 的基本分析特征和它们的最优联立表示。 5、因子分析把每个原始变量分解为两部分因素:一部分为公共因子,另一部分为特殊因子。 6、若 () (,), P x N αμα ∑=1,2,3….n且相互独立,则样本均值向量x服从的分布 为_x~N(μ,Σ/n)_。 二、简答 1、简述典型变量与典型相关系数的概念,并说明典型相关分析的基本思想。 在每组变量中找出变量的线性组合,使得两组的线性组合之间具有最大的相关系数。选取和最初挑选的这对线性组合不相关的线性组合,使其配对,并选取相关系数最大的一对,如此下去直到两组之间的相关性被提取完毕为止。被选出的线性组合配对称为典型变量,它们的相关系数称为典型相关系数。 2、简述相应分析的基本思想。 相应分析,是指对两个定性变量的多种水平进行分析。设有两组因素A和B,其中因素A包含r个水平,因素B包含c个水平。对这两组因素作随机抽样调查,得到一个rc的二维列联表,记为。要寻求列联表列因素A和行因素B的基本分析特征和最优列联表示。相应分析即是通过列联表的转换,使得因素A
和因素B 具有对等性,从而用相同的因子轴同时描述两个因素各个水平的情况。把两个因素的各个水平的状况同时反映到具有相同坐标轴的因子平面上,从而得到因素A 、B 的联系。 3、简述费希尔判别法的基本思想。 从k 个总体中抽取具有p 个指标的样品观测数据,借助方差分析的思想构造一个线性判别函数 系数: 确定的原则是使得总体之间区别最大,而使每个总体内部的离差最小。将新样品的p 个指标值代入线性判别函数式中求出 值,然后根据判别一定的规则,就可以判别新的样品属于哪个总体。 5、简述多元统计分析中协差阵检验的步骤 第一,提出待检验的假设 和H1; 第二,给出检验的统计量及其服从的分布; 第三,给定检验水平,查统计量的分布表,确定相应的临界值,从而得到否定域; 第四,根据样本观测值计算出统计量的值,看是否落入否定域中,以便对待判假设做出决策(拒绝或接受)。 协差阵的检验 检验0=ΣΣ 0p H =ΣI : /2 /21exp 2np n e tr n λ???? =-?? ? ???? S S 00p H =≠ΣΣI : /2 /2**1exp 2np n e tr n λ???? =-?? ? ???? S S
ERP 销售管理实验报告
浙江万里学院实验报告 专业班级:信管111 姓名:学号:实验日期:2014.05.06
五、实验中遇到的问题及相应的解决方案 如果需要删除已经生成的单据或发票,必须先删除凭证,然后在“应收单审核”窗口中取消审核操作,通过执行“应收单审核\应收单列表”命令,在“应收单列表”窗口中删除。 存货核算系统必须执行正常单据记账后,才能确认销售成本,并生成结转销售成本凭证。 有时候自己填写的发货单不能保存,是由于之前做采购管理的时候采购的数量不够,这时候要么在做销售的时候少卖一些,要么再去采购一些。 业务单据中录入项目不能选择业务单据(比如采购入库单、其他出库单等)在表体中已经有项目,但是在添置业务单据时,不能对表体中的项目进行选择录入。只能对项目编号进行选择。在基础设置/单据设计中,打开业务单据,然后增加“项目编码”,保存即可。 六、实验心得 亲身实践后,我的总体感觉是,很多实验前面进行了很多单据的相关操作后,为的就是最后生成一张凭证,实验操作的过程进展的也并不总是那么顺利,只要稍有失误,如漏了其中某一步骤,就导致最后凭证不能生成。所以感觉业务员操作还是很不好做的,更不用说是开发这个系统的人了,进行每一步操作都要谨慎小心。在上课的过程中,不敢有一丝丝的大意,只要在刚开始的过程中有一个小地方没有做完全,就会让稍后的业务采购中有一部分实现不了。每一堂实验课都动手按书本上的步骤实际操作。在实验过程中还是会犯一些小错误,总是需要老师的帮助。 在这段时间中,我对这个系统有了一定的了解。在实验中学习理论知识,这使我对理论中的ERP有了更直观的认识。然而,我总是会存在一些小问题。总是莫名其妙的会出现一些错误,总会让我很无可奈何。还好有同学和老师愿意帮助我。我觉得我在这个学习中学到很多实践课上学不到的内容,感觉十分的充实。
应用多元统计分析习题解答_第五章
第五章 聚类分析 判别分析和聚类分析有何区别 答:即根据一定的判别准则,判定一个样本归属于哪一类。具体而言,设有n 个样本,对每个样本测得p 项指标(变量)的数据,已知每个样本属于k 个类别(或总体)中的某一类,通过找出一个最优的划分,使得不同类别的样本尽可能地区别开,并判别该样本属于哪个总体。聚类分析是分析如何对样品(或变量)进行量化分类的问题。在聚类之前,我们并不知道总体,而是通过一次次的聚类,使相近的样品(或变量)聚合形成总体。通俗来讲,判别分析是在已知有多少类及是什么类的情况下进行分类,而聚类分析是在不知道类的情况下进行分类。 试述系统聚类的基本思想。 答:系统聚类的基本思想是:距离相近的样品(或变量)先聚成类,距离相远的后聚成类,过程一直进行下去,每个样品(或变量)总能聚到合适的类中。 对样品和变量进行聚类分析时, 所构造的统计量分别是什么简要说明为什么这样构造 答:对样品进行聚类分析时,用距离来测定样品之间的相似程度。因为我们把n 个样本看作p 维空间的n 个点。点之间的距离即可代表样品间的相似度。常用的距离为 (一)闵可夫斯基距离:1/1 ()() p q q ij ik jk k d q X X ==-∑ q 取不同值,分为 (1)绝对距离(1q =) 1 (1)p ij ik jk k d X X ==-∑ (2)欧氏距离(2q =) 21/2 1 (2)() p ij ik jk k d X X ==-∑ (3)切比雪夫距离(q =∞) 1()max ij ik jk k p d X X ≤≤∞=- (二)马氏距离 (三)兰氏距离 对变量的相似性,我们更多地要了解变量的变化趋势或变化方向,因此用相关性进行衡量。 将变量看作p 维空间的向量,一般用 2 1()()()ij i j i j d M -'=--X X ΣX X 11()p ik jk ij k ik jk X X d L p X X =-=+∑
浙江万里学院会计学试卷
A卷 一、单项选择题(每题1分) 1.借贷记帐法起源于( B )。 A、英国 B、意大利 C、美国 D、希腊 2.提取无形资产减值准备金这一做法体现的原则是( C )。 A、配比原则 B、重要性原则 C、谨慎原则 D、客观性原则 3.在借贷记帐法下,帐户的贷方登记( B )。 A、资产的增加 B、负债的增加 C、费用的增加 D、收入的减少 4.定期对外提供会计报表,这是( D )的要求。 A、会计主体 B、货币计量 C、持续经营 D、会计分期 5.会计科目是( A ) A、账户的名称 B、账簿的名称 C、报表项目的名称 D、会计要素的名称 6.“四柱清册”是我国古代会计模式,四柱中的“实在”是指( D )。 A、期初结存 B、本期收入 C、本期付出 D、期末结存 7.( B )是记录经济业务,明确经济责任,作为记账依据的书面证明。 A、记账凭证 B、会计凭证 C、汇总记账凭证 D、原始凭证 8.下列不属于资产类账户的是( D )。 A、预付账款 B、原材料 C、应收账款 D、实收资本 9.按照权责发生制原则,下述各项目中属于本年收入的是( D )。 A、收到上年所销产品的货款85000元 B、预收下年度仓库租金4500元 C、预付下年度财产保险费6000元 D、本年销售产品一批,价款20000元,货款将于下年收到 10.原始凭证按取得的来源不同,可分为( B )。 A、一次凭证和累计凭证 B、自制原始凭证和外来原始凭证 C、原始凭证和汇总原始凭证 D、收款凭证、付款凭证和转账凭证 11.下列支出中属于资本性支出的是( C )。 A、材料采购支出 B、工资费用支出 C、购置设备支出 D、广告宣传费支出 12.复式记账法是指任何一笔经济业务都必须用相等的金额在两个或两个以上的有关账户中( D )。 A、一个记增加,另一个记减少 B、两个都记增加
应用多元统计分析SAS作业第六章资料
6-10 今有6个铅弹头,用“中子活化”方法测得7种微量元素的含量数据(见表1)。 (1) 试用多种系统聚类法对6个弹头进行分类;并比较分类结果; (2) 试用多种方法对7种微量元素进行分类。 问题求解 1对6个弹头进行分类 对数据进行标准化变换,样品间距离定义为欧式距离,系统聚类的方法分别使用类平均法(A VE )、中间距离法(MID )、可变类平均法(FLE )和离差平方合法(WARD )。使用SAS 软件CLUSTER 过程对数据进行聚类分析(程序见附录1)。 1.1类平均法 图1 类平均聚类法相关矩阵特征值图 图2 类平均聚类分析法聚类历史图 由图2可知,NCL=1时半偏R 2最大且伪F 统计量在NCL=2,5时和伪t 方统计量在NCL=1,4时较大。因此,将6个弹头分为两类{}{}(2) (2) 121,2,4,6,3,5G G ==。SAS 绘制的谱系聚类图如图 3所示。
图3 类平均聚类分析法谱系聚类图 1.2中间距离法 图4 中间距离聚类法相关矩阵特征值图 图5 中间距离聚类法聚类历史图 由图5可知,中间距离法与类平均法结果一致。因此,也将6个弹头分为两类 {}{}(2)(2) 121,2,4,6,3,5G G ==。 SAS 绘制的谱系聚类图如图6所示。
图6中间距离聚类法谱系聚类图 1.3可变类平均法 图7可变类平均聚类法分析结果图 图8 可变类平均聚类法聚类历史图 由图8可知,可变类平均法(=0.25 β-)输出结果与前两种方法稍有不同,NCL=1时半偏R2最大且伪F统计量在NCL=2时次大,NCL=5时最大;而伪t方统计量在NCL=1时最大。因此,分
SPSS实验报告.pdf
专业班级:金融106姓名:周吉利1222朱宁宁1224杨程琤1212周孟杰1207实验日期:2012.3.27 浙江万里学院实验报告 课程名称:2011/2012学年第二学期统计实验 实验名称:备择实验专业班级:金融105-106姓名:叶美君1219胡志晖1206黄世杰1208崔 迦楠1175 实验日期:2012.3.29 成绩: 教师:
专业班级:金融106姓名:周吉利1222朱宁宁1224杨程琤1212周孟杰1207实验日期:2012.3.27 一、实验目的:统计分析的目的在于研究总体特征。但是,由于各种各样的原因,我们能够得到的往往只能是从总体中随机抽取的一部分观察对象,他们构成了样本,只有通过对样本的研究,我们才能对总体的实际情况作出可能的推断。因此描述性统计分析是统计分析的第一步,做好这一步是进行正确统计推断的先决条件。通过描述性统计分析可以大致了解数据的分布类型和特点、数据分布的集中趋势和离散程度,或对数据进行初步的探索性分析(包括检查数据是否有错误,对数据分布特征和规律进行初步观察)。 本试验旨在于:引到学生利用正确的统计方法对数据进行适当的整理和显示, 描述并探索出数据内在的数量规律性,掌握统计思想,培养学生学习统计学的兴趣,为继续学习推断统计方法及应用各种统计方法解决实际问题打下必要而坚实的基础。 二、实验内容: 1.表 2.7为某班级16位学生的身高数据,对其进行频数分析,并对实验报告作出说明。 表2.7 某班16位学生的身高数据 学号性别身高(cm )学号性别身高(cm ) 1 M 170 9 M 150 2 F 17 3 10 M 157 3 F 169 11 F 177 4 M 15 5 12 M 160 5 F 174 13 F 169 6 F 178 14 M 154 7 M 156 15 F 172 8 F 171 16 F 180 三、实验过程: 1、输入某班级16位学生的身高数据。 2、然后选择分析,描述统计,频率,并选择统计量。
浙江万里学院微观经济学历年期末试题总结
一、判断题 ( X ) 1. 支持价格是政府规定的某种产品的最高价格。 (√ ) 2. 经济分析中一般假定消费者的目标是效用最大化。 (√) 3.完全竞争市场的含义:指不受任何阻碍和干扰的市场结构. (√ ) 4. 在一条直线型的需求曲线上每一点的需求弹性系数都不一样。 (√ ) 5. 消费者均衡的实现条件是消费者花在每一元钱上的商品的边际效用都相等。 ( X ) 6. 在同一平面内,两条无差异曲线是可以相交的。 (√ ) 7.需求规律的含义是, 在其他条件不变的情况下,某商品的需求量与价格之间成反方向变动。 ( X ) 8. 规模经济和边际收益递减规律所研究的是同一个问题。 (×) 9. 基尼系数越大,收入分配越平均。 (√ ) 10、在一个国家或家庭中,食物支出在收入中所占比例随着收入的增加而减少。 (√ ) 11. 边际成本曲线总是交于平均成本曲线的最低点。 (√) 12. 完全竞争市场中厂商所面对的需求曲线是一条水平线。 (√) 13. 一个博弈中存在纳什均衡,但不一定存在占优均衡。 (√) 14.边际替代率是消费者在获得相同的满足程度时,每增加一种商品的数量与放弃的另一种商品的数量之比。 (√) 15. 微观经济学的中心理论是价格理论。 ( X ) 16. 经济学按研究内容的不同可分为实证经济学和规范经济学。 (√) 17. 需求弹性这一概念表示的是需求变化对影响需求的因素变化反应程度 (√) 18. 消费者均衡表示既定收入下效用最大化。 ( X ) 19. 经济学按研究内容的不同可分为实证经济学和规范经济学。 ( X ) 20. 平均产量曲线可以和边际产量曲线在任何一点上相 交。 (√) 21. 在长期分析中,固定成本与可变成本的划分是不存在的。 (√) 22. 吉芬商品的需求曲线与正常商品的需求曲线是不相同的。 (√ ) 23. 任何经济决策都必须考虑到机会成本。 (√ ) 24、指经济变量之间存在函数关系时,弹性表示因变量的变动率对自变量的变动 率的反应程度。需求价格弹性指价格变动的比率所引起的需求量变动的比率,即 求量变动对价格变动的反应程度。 (√ ) 25. 在完全竞争市场中每一厂商长期均衡时都没有超额利润。 (X ) 26. 平均产量曲线可以和边际产量曲线在任何一点上相交。 (√ ) 27. 寡头垄断市场的最大特征就是寡头厂商之间的相互依赖性。(√) 28. 微观经济学的研究对象是包括单个消费者、单个生产者、单个市
乙酸乙酯皂化反应实验报告(详细参考)
浙江万里学院生物与环境学院 化学工程实验技术实验报告 实验名称:乙酸乙酯皂化反应 姓名成绩 班级学号 同组姓名实验日期 指导教师签字批改日期年月日
一、实验预习(30分) 1.实验装置预习(10分)_____年____月____日 指导教师______(签字)成绩 2.实验仿真预习(10分)_____年____月____日 指导教师______(签字)成绩 3.预习报告(10分) 指导教师______(签字)成绩 (1)实验目的 1.用电导率仪测定乙酸乙酯皂化反应进程中的电导率。 2.掌握用图解法求二级反应的速率常数,并计算该反应的活化能。 3.学会使用电导率仪和超级恒温水槽。 (2)实验原理 乙酸乙酯皂化反应是个二级反应,其反应方程式为 CH3COOC2H5+Na++OH-→CH3COO-+Na++C2H5OH 当乙酸乙酯与氢氧化钠溶液的起始浓度相同时,如均为a,则反应速率表示为 (1)式中,x为时间t时反应物消耗掉的浓度,k为反应速率常数。将上式积分得 (2) 起始浓度a为已知,因此只要由实验测得不同时间t时
的x值,以对t作图,应得一直线,从直线的斜率便可求出k值。 乙酸乙酯皂化反应中,参加导电的离子有OH-、Na+和CH3COO-,由于反应体系是很稀的水溶液,可认为CH3COONa是全部电离的,因此,反应前后Na+的浓度不变,随着反应的进行,仅仅是导电能力很强的OH-离子逐渐被导电能力弱的CH3COO-离子所取代,致使溶液的电导逐渐减小,因此可用电导率仪测量皂化反应进程中电导率随时间的变化,从而达到跟踪反应物浓度随时间变化的目的。 令G0为t=0时溶液的电导,G t为时间t时混合溶液的电导,G∞为t=∞(反应完毕)时溶液的电导。则稀溶液中,电导值的减少量与CH3COO-浓度成正比,设K为比例常数,则 由此可得 所以(2)式中的a-x和x可以用溶液相应的电导表示,将其代入(2)式得: 重新排列得: (3) 因此,只要测不同时间溶液的电导值G t和起始溶液的电导值G0,然后 以G t对作图应得一直线,直线的斜率为,由此便求出某温 度下的反应速率常数k值。由电导与电导率κ的关系式:G=κ代入(3)式得: (4) 通过实验测定不同时间溶液的电导率κt和起始溶液 的电导率κ0,以κt,对作图,也得一直线,从直线的斜率也可求出反应速率数k值。如果知道不同温度下的反应速率常数k(T2)和k(T1),根据Arrhenius公式,可计算出该反应的活化能E和反应半衰期。 (5)
浙江万里学院工程数学
关于考试 1、概率论考试题型与分值:共26小题,填空题(每空2分,10小题 13个空,共26分),单项选择题(每题2分,共20分,10小题),解答题,要求写出计算过程或求解理由(共54分,6小题) 2、范围:第一至第四章,书上作业,上课例题 3、补考卷包括线性代数与概率论两部分,题型为选择与解答题,与两次的考试差不多 第6次讨论题目 1、一枚硬币抛4次,观察正反面情况,若用基本事件表示“恰有一 次出现正面”: 这个试验的样本空间中所含的基本事件数有多少: 2、98个产品中有4个次品,任取3个,求没有次品的概率: 3、已知P(B)=0.3 1)若A 、B 是两个互不相容且P(A ∪B)=0.9,求P(A); 2)若P(A)=0.4, P(AB)=0.15,求P(A -B); 3)若P(A|B)=5 2,求P (AB )。; 4)A 与B 相互独立,P(A)=1/4,求A ,B 至少发生一个的概率。 4、设随机变量X 服从参数λ的泊松分布,则期望E(X},方差D(X)。 5、设随机变量X 具有分布函数???<≥-=-0,00,e 1)(2x x x F x ,求P{X>3} 6、连续型随机变量X 在区间(1,3)服从均匀分布,求P(X=2.5) 7、盒中有13支粉笔(3支红色),现从盒中取出一支粉笔观察其颜 色,然后放回,再独立重复以上步骤,直到第15次试验才取得
第4次红粉笔的概率(用表达式即可)。若设重复独立试验次数为39次,求红粉笔最有可能出现的次数。 8、设二维随机变量(X ,Y )的概率密度为),(y x f ,则}1{>X P 为 9、(X ,Y)是二维随机向量,关于两个变量之间的关系,判断如下说 法 A .若X 、Y 独立,则X 、Y 必不相关 B .若X 、Y 独立,则X 、Y 必相关 C ..若X 、Y 不相关,则X 、Y 必独立 D .若X 、Y 不独立,则X 、Y 必不相关 10、设X 、Y 分别表示甲乙两个人完成某项工作所需的时间,若 )()(Y E X E <,)()(Y D X D >,判断如下说法 A .甲的工作效率及稳定性都不如乙 B .甲的工作效率较低,但稳定性较好 C .甲的工作效率较高,但稳定性较差 D.甲的工作效率及稳定性都比乙好 11、设连续型随机变量X 的密度函数满足)()(x f x f -=,)(x F 是X 的分布函数,求}11{>X P 12、X ~N(80,52) (1) 求P{X>70} ,(2) 求数k ,使得P{80-k 应用多元统计分析课后答案 第五章 聚类分析 5.1 判别分析和聚类分析有何区别? 答:即根据一定的判别准则,判定一个样本归属于哪一类。具体而言,设有n 个样本,对每个样本测得p 项指标(变量)的数据,已知每个样本属于k 个类别(或总体)中的某一类,通过找出一个最优的划分,使得不同类别的样本尽可能地区别开,并判别该样本属于哪个总体。聚类分析是分析如何对样品(或变量)进行量化分类的问题。在聚类之前,我们并不知道总体,而是通过一次次的聚类,使相近的样品(或变量)聚合形成总体。通俗来讲,判别分析是在已知有多少类及是什么类的情况下进行分类,而聚类分析是在不知道类的情况下进行分类。 5.2 试述系统聚类的基本思想。 答:系统聚类的基本思想是:距离相近的样品(或变量)先聚成类,距离相远的后聚成类,过程一直进行下去,每个样品(或变量)总能聚到合适的类中。 5.3 对样品和变量进行聚类分析时, 所构造的统计量分别是什么?简要说明为什么这样构造? 答:对样品进行聚类分析时,用距离来测定样品之间的相似程度。因为我们把n 个样本看作p 维空间的n 个点。点之间的距离即可代表样品间的相似度。常用的距离为 (一)闵可夫斯基距离:1/1()()p q q ij ik jk k d q X X ==-∑ q 取不同值,分为 (1)绝对距离(1q =) 1 (1)p ij ik jk k d X X ==-∑ (2)欧氏距离(2q =) 21/2 1 (2)() p ij ik jk k d X X ==-∑ (3)切比雪夫距离(q =∞) 1()max ij ik jk k p d X X ≤≤∞=- (二)马氏距离 (三)兰氏距离 21()()()ij i j i j d M -'=--X X ΣX X 11()p ik jk ij k ik jk X X d L p X X =-= +∑ 一、单项选择题(一) 1.下列不属于我国环境标准体系的是( C )。 A.国家环境标准B.国家环境保护部标准 C.地方环境保护行业标准D.地方环境标准 2. 《规划环境影响评价技术导则》适用于国务院有关部门、( C )及其有关部门组织编制的规划的环境影响评价。 A.市级以上地方人民政府B.县级以上地方人民政府 C.设区的市级以上地方人民政府D.设区的市级以上环境保护行政部门 3. 以下不属于国家已颁布污染物排放标准的是( B )。 A.《加油站大气污染物排放标准》B.《钢铁工业大气污染物排放标准》 C.《水泥工业大气污染物排放标准》D.《炼焦炉大气污染物排放标准》 4.下列关于跨行业综合性污染物排放标准与行业污染物排放标准的说法,错误的是(D ) A.有行业排放标准的执行行业排放标准 B.《锅炉大气污染物排放标准》属行业性排放标准 C.没有行业排放标准的执行综合性排放标准 D.综合性排放标准与行业排放标准有时可交叉执行 5.根据《环境影响评价技术导则—总纲》,哪些项目需进行资源利用合理性分析。( D ) A.所有建设项目 B.已开展规划环境影响评价的 C.污染型项目 D.未开展规划环境影响评价的 6.根据《环境影响评价技术导则—总纲》,关于环境影响评价方法的选取,说法正确的是( B )。 A优先选用先进的技术方法,鼓励使用成熟的技术方法,慎用处于研究阶段尚没有定论的方法 B优先选用成熟的技术方法,鼓励使用先进的技术方法,慎用处于研究阶段尚没有定论的方法 C.优先选用先进的技术方法,鼓励使用处于研究阶段的技术方法,慎用有争议的方法 D.优先选用成熟的技术方法,鼓励使用科学研究阶段的技术方法,慎用有争议的方法 7.根据《环境影响评价技术导则—总纲》,对于环境质量和区域污染源现状调查监测点位的布设原则是( B )。 A.均匀布设兼顾代表性 B.以环境功能区为主兼顾均布性和代表性 C.以环境敏感目标为主兼顾均布性和代表性 D.以上下风向为主兼顾均布性和代表性 8.大气环境评价工作分级的方法是根据(B )计算确定。 A.推荐模式中的ADMS模式 B. 推荐模式中的估算模式 C.等标排放量的公式 D. 推荐模式中的AERMOD模式 9.某项目建在风景名胜区,P max =8.0%,大气工作等级为(B )。 A.一 B.二 C.三 D.四 10.某建设项目经计算确定D10%为2km,则该项目的大气环境评价范围为以排放源为中心点,以( C )。 A.2km为半径的圆 B.周长4km矩形区域 C.2.5km为半径的圆 D.边长4km矩形区域 11.大气环境质量现状监测布点方法为(C )。 A.同心圆布点法B.扇形布点法 C.极坐标布点法D.梅花形布点法 12.下列关于气象观测资料调查的基本原则说法正确的是( A ) A.对于一级评价项目,应调查评价范围20年以上的主要气候统计资料 B.对于二级评价项目,应调查评价范围15年以上的主要气候统计资料 C.对于三级评价项目,应调查评价范围10年以上的主要气候统计资料 D.对于各级评价项目,均应调查评价范围10年以上的主要气候统计资料 13.大气环境一级评价项目预测内容中,非正常排放情况,需预测全年( A )小时气象条件下,环境空气保护目标的最大地面小时浓度和评价范围内的最大地面小时浓度。 A.逐时或逐次B.逐日或逐次 C.逐日或逐时D.长期气象条件下 14.下列污染类别,需预测所有因子的是( A )。 A.新增污染源的正常排放B.新增污染源的非正常排放 C.削减污染源D.被取代污染源 15.基于估算模式计算某企业的大气环境防护距离时,甲污染物计算的距离为205m,乙污染物计算的距离为300m,丙污染物计算的距离为350m,则该企业的大气环境防护距离应取( C )。 A.400m B.500m C.350m D.325m 16.水环境非点源调查的原则基本上采用( D )的方法。 A.现场调查B.遥感判读C.现场测试D.搜集资料 17.依据《环境影响评价技术导则地面水环境》,所有建设项目地面水环境影响评价均应预测的影响时期 实验报告 一、实验名称 多元统计分析作业题。 二、实验目的 (一)了解并掌握主成分分析与因子分析的基本原理和简单解法。 (二)学会使用matlab编写程序进行因子分析,求得特征值、特征向量、载荷矩阵等值。(三)学会使用排序、元胞数组、图像表示最后的结果,使结果更加直观。 三、实验内容与要求 四、实验原理与步骤 (一)第一题: 1、实验原理: 因子分析简介: (1) 1.1 基本因子分析模型 设p维总体x=(x1,x2,....,xp)'的均值为u=(u1,u2,....,u3)',因子分析的一般模型为 x1=u1+a11f1+a12f2+........+a1mfm+ε 1 x2=u2+a21f1+a22f2+........+a2mfm+ε 2 ......... xp=up+ap1f1+fp2f2+..........+apmfm+εp 其中,f1,f2,.....,fm为m个公共因子;εi是变量xi(i=1,2,.....,p)所独有的特殊因子,他们都是不可观测的隐变量。称aij(i=1,2,.....,p;j=1,2,.....,m)为变量xi的公共因子fi上的载荷,它反映了公共因子对变量的重要程度,对解释公共因子具有重要的作用。上式可以写为矩阵形式 x=u+Af+ε 其中A=(aij)pxm 称为因子载荷矩阵;f=(f1,f2,....,fm)'为公共因子向量;ε=(ε1,ε2,.....εp)称为特殊因子向量 (2) 1.2 共性方差与特殊方差 xi的方差var(xi)由两部分组成,一个是公共因子对xi方差的贡献,称为共性方差;一个是特殊因子对xi方差的贡献,称为特殊方差。每个原始变量的方差都被分成了共性方差和特殊方差两部分。 (3) 1.3 因子旋转 因子分析的主要目的是对公共因子给出符合实际意义的合理解释,解释的依据就是因子载荷阵的个列元素的取值。当因子载荷阵某一列上各元素的绝对值差距较大时,并且绝对值大的元素较少时,则该公共因子就易于解释,反之,公共因子的解释就比较困难。此时可以考虑对因子和因子载荷进行旋转(例如正交旋转),使得旋转后的因子载荷阵的各列元素的绝对值尽可能量两极分化,这样就使得因子的解释变得容易。 因子旋转方法有正交旋转和斜交旋转两种,这里只介绍一种普遍使用的正交旋转法:最大方差旋转。这种旋转方法的目的是使因子载荷阵每列上的各元素的绝对值(或平方值)尽可能地向两极分化,即少数元素的绝对值(或平方值)取尽可能大的值,而其他元素尽量接近于0. (4) 1.4 因子得分 在对公共因子做出合理解释后,有时还需要求出各观测所对应的各个公共因子的得分,就比如我们知道某个女孩是一个美女,可能很多人更关心该给她的脸蛋、身材等各打多少分,常用的求因子得分的方法有加权最小二乘法和回归法。 注意:因子载荷矩阵和得分矩阵的区别: 因子载荷矩阵是各个原始变量的因子表达式的系数,表达提取的公因子对原始变量的影响程度。因子得分矩阵表示各项指标变量与提取的公因子之间的关系,在某一公因子上得分高,表明该指标与该公因子之间关系越密切。简单说,通过因子载荷矩阵可以得到原始指标变量的线性组合,如X1=a11*F1+a12*F2+a13*F3,其中X1为指标变量1,a11、a12、a13分别为与变量X1在同一行的因子载荷,F1、F2、F3分别为提取的公因子;通过因子得分矩阵可以得到公因子的线性组合,如F1=a11*X1+a21*X2+a31*X3,字母代表的意义同上。 (5) 1.5 因子分析中的Heywood(海伍德)现象 如果x的各个分量都已经标准化了,则其方差=1。即共性方差与特殊方差的和为1。也就是说共性方差与特殊方差均大于0,并且小于1。但在实际进行参数估计的时候,共性方差 主成分分析 6.1 试述主成分分析的基本思想。 答:我们处理的问题多是多指标变量问题,由于多个变量之间往往存在着一定程度的相关性,人们希望能通过线性组合的方式从这些指标中尽可能快的提取信息。当第一个组合不能提取止。这就是主成分分析的基本思想。 6.2 主成分分析的作用体现在何处? 答:一般说来,在主成分分析适用的场合,用较少的主成分就可以得到较多的信息量。以各个主成分为分量,就得到一个更低维的随机向量;主成分分析的作用就是在降低数据“维数” 6.3 简述主成分分析中累积贡献率的具体含义。 答:主成分分析把p 个原始变量12,, ,p X X X 的总方差()tr Σ分解成了p 个相互独立的变量p 个主成分的,忽略 一些带有较小方差的主成分将不会给总方差带来太大的影响。这里我们()m p <个主成分,则称1 1 p m m k k k k ψλλ ===∑∑ 为主成分1, ,m Y Y 的累计贡献率,累计贡献率表明1,,m Y Y 综合12,, ,p X X X 的能力。通常取m ,使得累计贡 献率达到一个较高的百分数(如85%以上)。 答:这个说法是正确的。 即原变量方差之和等于新的变量的方差之和 6.5 试述根据协差阵进行主成分分析和根据相关阵进行主成分分析的区别。 答:从相关阵求得的主成分与协差阵求得的主成分一般情况是不相同的。从协方差矩阵出发的,其结果受变量单位的影响。主成分倾向于多归纳方差大的变量的信息,对于方差小的变量就可能体现得不够,也存在“大数吃小数”的问题。实际表明,这种差异有时很大。我 6.6 已知X =()’的协差阵为 试进行主成分分析。 解:=0 计算得 当 时 ,应用多元统计分析课后答案
浙江万里学院期末考环评选择题
数学建模多元统计分析
应用多元统计分析习题解答-主成分分析
- 浙江万里学院关于修订本科专业人才培养方案的指导性意见
- 归硕士应聘小学教师 因学历非全日制被拒
- 基于Moodle平台的教学管理应用与实践——以浙江万里学院为例
- 关于做好2018-2019学年第一学期
- 教务管理系统WEB端使用指引-浙江万里学院教务部
- 示范建设课程考核与评比实施方案浙江万里学院教务部
- (基于问题学习)教育研究
- 2007年各项学科专业竞赛获奖情况一览-浙江万里学院教务部
- 浙江万里学院学生自主拓展专业素质学分认定表
- 第六届浙江省高等教育教学成果奖获奖项目公示名单
- 浙江万里学院学生违纪处理办法
- 浙江万里学院cis策划
- 电气本10级 PLC 13-14学年第二学期期终考试(A) - 副本
- 浙江万里学院钱湖校区通讯录
- 关于做好20162017学年第二学期期末实践教学工作暨校友
- 教学活动简讯
- 专业素质拓展管理系统使用指南
- 浙江万里学院
- 浙江万里学院硕士学位授予单位
- 浙江万里学院硕士学位授予单位