统计学(第五版)课后答案
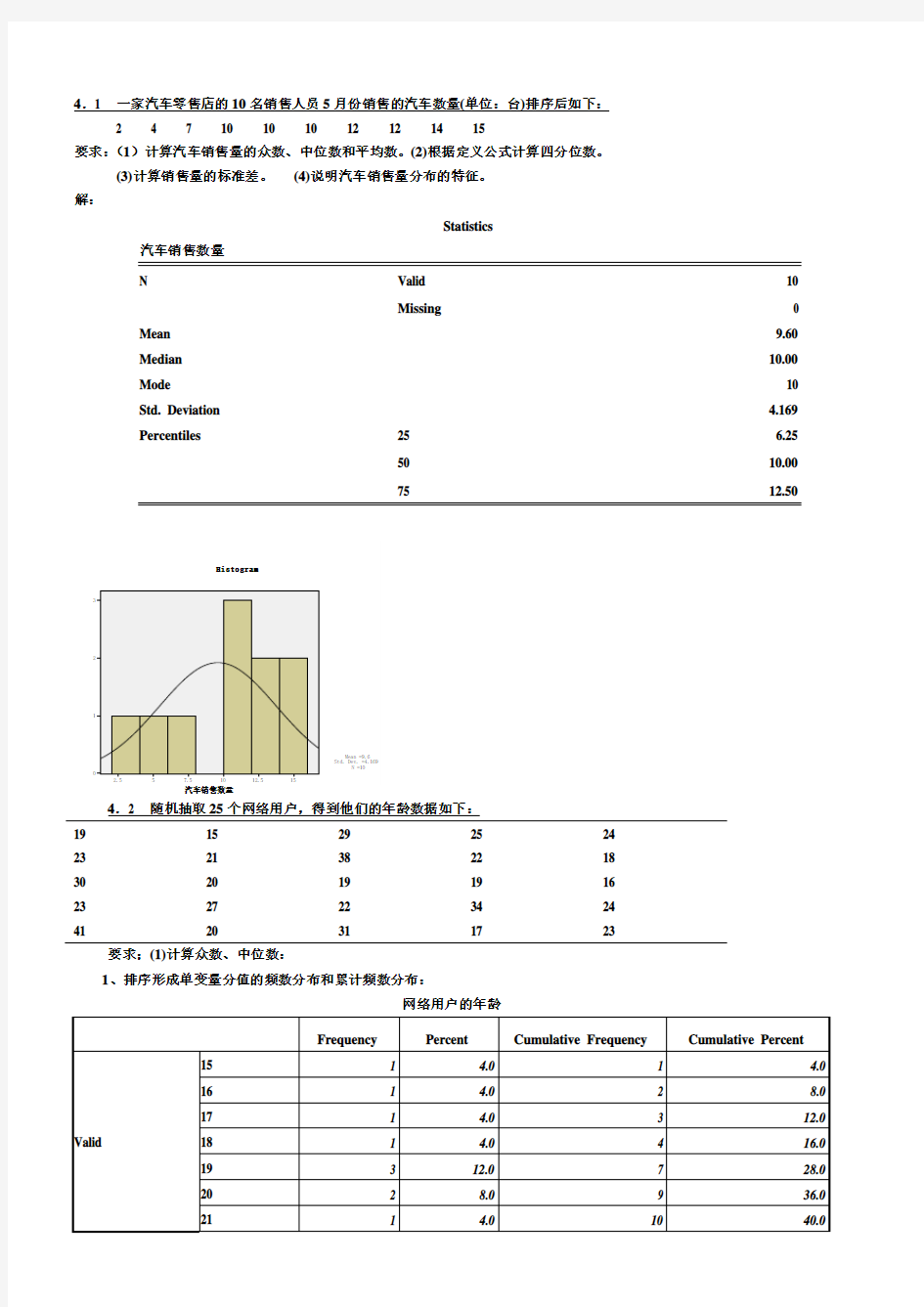

4.1 一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下:
2 4 7 10 10 10 12 12 14 15
要求:(1)计算汽车销售量的众数、中位数和平均数。(2)根据定义公式计算四分位数。
(3)计算销售量的标准差。(4)说明汽车销售量分布的特征。
解:
Statistics
汽车销售数量
N Valid 10
Missing 0 Mean 9.60 Median 10.00 Mode 10 Std. Deviation 4.169 Percentiles 25 6.25
50 10.00
75 12.50
4.2 随机抽取25个网络用户,得到他们的年龄数据如下:
19 15 29 25 24
23 21 38 22 18
30 20 19 19 16
23 27 22 34 24
41 20 31 17 23
要求;(1)计算众数、中位数:
1、排序形成单变量分值的频数分布和累计频数分布:
网络用户的年龄
从频数看出,众数Mo 有两个:19、23;从累计频数看,中位数Me=23。
(2)根据定义公式计算四分位数。 Q1位置=25/4=6.25,因此Q1=19,Q3位置=3×25/4=18.75,因此Q3=27,或者,由于25 和27都只有一个,因此Q3也可等于25+0.75×2=26.5。 (3)计算平均数和标准差; Mean=24.00;Std. Deviation=6.652 (4)计算偏态系数和峰态系数: Skewness=1.080;Kurtosis=0.773
(5)对网民年龄的分布特征进行综合分析:分布,均值=24、标准差=6.652、呈右偏分布。如需看清楚分布形态,需要进行分组。 为分组情况下的直方图:
为分组情况下的概率密度曲线:
分组:
1、确定组数:()lg 25lg() 1.398
111 5.64lg(2)lg 20.30103
n K
=+
=+=+=,取k=6
2、确定组距:组距=( 最大值 - 最小值)÷ 组数=(41-15)÷6=4.3,取5
3、分组频数表
网络用户的年龄(Binned)
分组后的均值与方差:
分组后的直方图:
4.6 在某地区抽取120家企业,按利润额进行分组,结果如下:
要求:(1)计算120家企业利润额的平均数和标准差。(2)计算分布的偏态系数和峰态系数。解:
Statistics
企业利润组中值Mi(万元)
N Valid 120
Missing 0
Mean 426.6667
Std. Deviation 116.48445
Skewness 0.208
Std. Error of Skewness 0.221 Kurtosis
-0.625 Std. Error of Kurtosis
0.438
4.9 一家公司在招收职员时,首先要通过两项能力测试。在A 项测试中,其平均分数是100分,标准差是15分;在B 项测试中,
其平均分数是400分,标准差是50分。一位应试者在A 项测试中得了115分,在B 项测试中得了425分。与平均分数相比,该应试者哪一项测试更为理想?
解:应用标准分数来考虑问题,该应试者标准分数高的测试理想。
Z A =
x x s -=11510015-=1;Z B =x x s -=425400
50
-=0.5 因此,A 项测试结果理想。 4.
11 对10名成年人和10名幼儿的身高进行抽样调查,结果如下: 要求:(1)如果比较成年组和幼儿组的身高差异,你会采用什么样的统计量?为什么? 均值不相等,用离散系数衡量身高差异。 (2)比较分析哪一组的身高差异大?
幼儿组的身高差异大。
7.3从一个总体中随机抽取n=100的随机样本,得到x=104560,假定总体标准差σ=86414,构建总体均值μ的95%的置信区间。解: 已知n =100,x =104560,σ = 85414,1-α=95% ,
由于是正态总体,且总体标准差已知。总体均值
μ在1-α置信水平下的置信区间为
104560 ± 1.96×85414÷√100= 104560 ±16741.144
7.4 从总体中抽取一个n=100的简单随机样本
,得到x =81,s=12
。
样本均值服从正态分布:2,x
N n σμ?? ??
?或
2,s x
N n μ?? ???
置信区间为:22x
z x z αα?-+
?(1)构建μ的90%的置信区间。2z α=
0.05z =1.645,置信区间为:(81-1.645×1.2,81+1.645×1.2)=(79.03,82.97) (2)构建μ的95%的置信区间。2z α=
0.025z =1.96,置信区间为:(81-1.96×1.2,81+1.96×1.2)=(78.65,83.35) (3)构建μ的99%的置信区间。2z α
=
0.005z =2.576,置信区间为:(81-2.576×1.2,81+2.576×1.2)=(77.91,84.09)
7.5利用下面的信息,构建总体均值的置信区间
(1)x =25,σ=3.5,n=60,置信水平为95% (2)x =119.6,s=23.89,n=75,置信水平为95%
(3)x =3.419,s=0.974,n=32,置信水平为90%
解:∵
∴ 1) 1-α=95% ,
其置信区间为:25±1.96×3.5÷√60= 25±0.885
2) 1-α=98% ,则α=0.02, α/2=0.01, 1-α/2=0.99,查标准正态分布表,可知: 2.33
其置信区间为: 119.6±2.33×23.89÷√75= 119.6±6.345
3) 1-α=90%,
1.65 其置信区间为: 3.149±1.65×0.974÷√32= 3.149±0.284
7.7 某大学为了解学生每天上网的时间,在全校7 500名学生中采取重复抽样方法随机抽取36人,调查他们每天上网的时间,得到下面的数据
求该校大学生平均上网时间的置信区间,置信水平分别为95%。 解:(1)样本均值x =3.32,样本标准差s=1.61; (2)抽样平均误差: 重复抽样:
x σ≈
不重复抽样:
x σ≈
=0.268×0.998=0.267
(3)置信水平下的概率度:1α-=0.95,t=2z α=
0.025z =1.96
(4)边际误差(极限误差):2x
x x t z ασσ?=?=? 1α-=0.95,2x x x t z ασσ?=?=?=0.025x z σ?
重复抽样:x
x z ασ?=?=0.025x z σ?=1.96×0.268=0.525 不重复抽样:2x
x z ασ?=?=0.025x z σ?=1.96×0.267=0.523
(5)置信区间:
1α-=0.95,
重复抽样:
(),x x x x -?+?=()3.320.525,3.320.525-+=(2.79,3.85) 不重复抽样:
(),x x x x -?+?=()3.320.441,3.320.441-+=(2.80,3.84)
7.8从一个正态总体中随机抽取样本量为8的样本,各样本值分别为:10、8、12、15、6、13、5、11.,求总体均值μ的95%的置信区间
解:本题为一个小样本正态分布,σ未知。 先求样本均值: = 80÷8=10
再求样本标准差:= √84/7 = 3.4641
于是 , μ的置信水平为1-α的置信区间是
,
已知1-α=25,n = 8,则α=0.05,α/2=0.025,查自由度为n-1 = 7的 分布表得临界值
2.45
所以,置信区间为: 10±2.45×3.4641÷√7
7.11 某企业生产的袋装食品采用自动打包机包装,每袋标准重量为l00g 。现从某天生产的一批产品中按重复抽样随机抽取50
已知食品包重量服从正态分布,要求:
(1)确定该种食品平均重量的95%的置信区间。
解:大样本,总体方差未知,用z 统计量
x z =
()0,1N 样本均值=101.4,样本标准差s=1.829 置信区间:22
x
z x z α
α?-+ ?
1α-=0.95
,2z α=
0.025z =1.96
2x z x z αα?-+ ?
=101.4 1.96 1.96?-+ ?=(100.89,101.91) (2)如果规定食品重量低于l00g 属于不合格,确定该批食品合格率的95%的置信区间。 解:总体比率的估计大样本,总体方差未知,用z 统计量
z =
()0,1N 样本比率=(50-5)/50=0.9
置信区间:22
p z p z
αα? -+ ? 1α-=0.95,z α=
0.025z =1.96
22p z p z αα? -+ ?=0.9 1.96 1.96?
-+ ?
=(0.8168,0.9832) 7.18某小区共有居民500户,小区管理着准备采用一项新的供水设施,想了解居民是否赞成。采取重复抽样方法随机抽取了50户,
其中有32户赞成,18户反对。
(1)求总体中赞成该项改革的户数比例的置信区间
(2)若小区管理者预计赞成的比例能达到80%,估计误差不超过10%,应抽取多少户进行调查?
解:1)已知N=50,P=32/50=0.64,α=0.05,α/2 =0.025 ,则 1.96
置信区间:P±√{P(1-P)/N}= 0.64±1.96√0.64×0.36/50= 0.64±1.96×0.48/7.07=0.64±0.133
2)已知丌=0.8 , E = 0.1, α=0.05,α/2 =0.025 ,则 1.96
N= 2丌(1-丌)/E2= 1.962×0.8×0.2÷0.12≈62
8.1已知某炼铁厂的含碳量服从正态分布N(4.55,0.1082),现在测定了9炉铁水,其平均含碳量为4.484,如果估计方差没有变化,
可否认为现在生产的铁水平均含碳量为4.55?
解:已知μ0=4.55,σ2=0.1082,N=9,=4.484,
这里采用双侧检验,小样本,σ已知,使用Z统计。假定现在生产的铁水平均含碳量与以前无显著差异。则,
H0 :μ =4.55 ; H1 :μ≠4.55 α=0.05,α/2 =0.025 ,查表得临界值为 1.96
计算检验统计量: = (4.484-4.55)/(0.108/√9)= -1.833
决策:∵Z值落入接受域,∴在α=0.05的显著性水平上接受H0。
结论:有证据表明现在生产的铁水平均含碳量与以前没有显著差异,可以认为现在生产的铁水平均含碳量为4.55。
8.2 一种元件,要求其使用寿命不得低于700小时。现从一批这种元件中随机抽取36件,测得其平均寿命为680小时。已知该元件寿命服从正态分布,σ=60小时,试在显著性水平0.05下确定这批元件是否合格。
解:H0:μ≥700;H1:μ<700 已知:x=680 σ=60
由于n=36>30,大样本,因此检验统计量:
x
z
=-2
当α=0.05,查表得zα=1.645。因为z<-zα,故拒绝原假设,接受备择假设,说明这批产品不合格。
8.3某地区小麦的一般生产水平为亩产250公斤,其标准差为30公斤,先用一种花费进行试验,从25个小区抽样,平均产量为270
公斤。这种化肥是否使小麦明显增产?
解:已知μ0 =250,σ = 30,N=25,x =270 这里是小样本分布,σ已知,用Z统计量。右侧检验,α =0.05,则Zα=1.645 提出假设:假定这种化肥没使小麦明显增产。即H0:μ≤250 H1: μ> 250
计算统计量:Z = (x-μ0)/(σ/√N)= (270-250)/(30/√25)= 3.33
结论:Z统计量落入拒绝域,在α =0.05的显著性水平上,拒绝H0,接受H1。
决策:有证据表明,这种化肥可以使小麦明显增产。
10..1从3个总体中各抽取容量不同的样本数据,结果如下。检验3个总体的均值之间是否有显著差异
方差分析:单因素方差分析
SUMMARY
组观测数求和平均方差
样本1 5 790 158 61.5
样本2 4 600 150 36.66667
样本3 3 507 169 121
方差分析
差异源SS df MS F P-value F crit
组间618.9167 2 309.4583 4.6574 0.040877 8.021517 组内598 9 66.44444
总计1216.917 11
10.。2下面是来自5个总体的样本数据
方差分析:单因素方差分析
SUMMARY
组观测数求和平均方差
样本1 3 37 12.33333 4.333333
样本2 5 50 10 1.5
样本3 4 48 12 0.666667
样本 5 80 16 1.5
样本5 6 78 13 0.8
方差分析
差异源SS df MS F P-value F crit
组间93.76812 4 23.44203 15.82337 1.02E-05 4.579036 组内26.66667 18 1.481481
总计120.4348 22
取显著性水平a=0.01,检验4台机器的装填量是否相同?
解:不相同。
ANOV A
每桶容量(L)
平方和df 均方 F 显著性
组间0.007 3 0.002 8.721 0.001
组内0.004 15 0.000
总数0.011 18
要求:
(1)人均GDP 作自变量,人均消费水平作因变量,绘制散点图,并说明二者之间的关系形态。 (2)计算两个变量之间的线性相关系数,说明两个变量之间的关系强度。 (3)利用最小二乘法求出估计的回归方程,并解释回归系数的实际意义。 (4)计算判定系数,并解释其意义。
(5)检验回归方程线性关系的显著性(a=0.05)。
(6)如果某地区的人均GDP 为5 000元,预测其人均消费水平。
(7)求人均GDP 为5 000元时,人均消费水平95%的置信区间和预测区间。
解:(1
(2)相关系数:有很强的线性关系。
相关性
人均GDP (元) 人均消费水平(元)
人均GDP (元)
Pearson 相关性 1
.998(**) 显著性(双侧) 0.000
N
7 7 人均消费水平(元)
Pearson 相关性 .998(**) 1
显著性(双侧) 0.000
N
7
7
**. 在 .01 水平(双侧)上显著相关。
(3)回归方程:回归系数的含义:人均GDP 没增加1元,人均消费增加0.309元。
系数(a) 模型 非标准化系数
标准化系数
t 显著性
B 标准误 Beta
1
(常量) 734.693 139.540 5.265 0.003 人均GDP
(元)
0.309
0.008
0.998 36.492
0.000
a. 因变量: 人均消费水平(元)
(4)人均GDP对人均消费的影响达到99.6%。
模型摘要
模型R R 方调整的R 方估计的标准差
a. 预测变量:(常量), 人均GDP(元)。
(5)F检验:
ANOV A(b)
模型平方和df 均方 F 显著性
1 回归81,444,968.680 1 81,444,968.680 1,331.69
2 .000(a)
残差305,795.034 5 61,159.007
合计81,750,763.714 6
a. 预测变量:(常量), 人均GDP(元)。
b. 因变量: 人均消费水平(元)
回归系数的检验:t检验
系数(a)
模型非标准化系数标准化系数
t 显著性B 标准误Beta
1 (常量)734.693 139.540 5.265 0.003
人均GDP
(元)
0.309 0.008 0.998 36.492 0.000
a. 因变量: 人均消费水平(元)
(6)某地区的人均GDP为5 000元,预测其人均消费水平为2278.10657元。
(7)人均GDP为5 000元时,人均消费水平95%的置信区间为[1990.74915,2565.46399],预测区间为[1580.46315,2975.74999]。
统计学(贾俊平,第四版)第五章习题答案
《统计原理》第五章练习题答案 5.1 (1)平均分数是范围在0-100之间的连续变量,Ω=[0,100] (2)已经遇到的绿灯次数是从0开始的任意自然数,Ω=N (3)之前生产的产品中可能无次品也可能有任意多个次品,Ω=[10,11,12,13…….] 5.2 设订日报的集合为A ,订晚报的集合为B ,至少订一种报的集合为A ∪B ,同时订两种报的集合为A ∩B 。 P(A ∩B)=P(A)+ P(B)-P(A ∪B)=0.5+0.65-0.85=0.3 5.3 P(A ∪B)=1/3,P(A ∩B )=1/9, P(B)= P(A ∪B)- P(A ∩B )=2/9 5.4 P(AB)= P(B)P(A ∣B)=1/3*1/6=1/18 P(A ∪B )=P(B A )=1- P(AB)=17/18 P(B )=1- P(B)=2/3 P(A B )=P(A )+ P(B )- P(A ∪B )=7/18 P(A ∣B )= P(B A )/P(B )=7/12 5.5 设甲发芽为事件A ,乙发芽为事件B 。 (1)由于是两批种子,所以两个事件相互独立,所以有:P(AB)= P(B)P(B)=0.56 (2)P(A ∪B)=P(A)+P(B)-P(A ∩B)=0.94 (3)P(A B )+ P(B A )= P(A)P(B )+P(B)P(A )=0.38 5.6 设合格为事件A ,合格品中一级品为事件B P(AB)= P(A)P(B ∣A)=0.96*0.75=0.72 5.7 设前5000小时未坏为事件A ,后5000小时未坏为事件B 。 P(A)=1/3,P(AB)=1/2, P(B ∣A)= P(AB)/ P(A)=2/3 5.8 设职工文化程度小学为事件A ,职工文化程度初中为事件B ,职工文化程度高中为事件C ,职工年龄25岁以下为事件D 。 P(A)=0.1 P(B)=0.5, P(C)=0.4 P(D ∣A)=0.2, P(D ∣B)=0.5, P(D ∣C)=0.7 P(A ∣D)=2/55)C P(C)P(D )B P(B)P(D )A P(A)P(D ) A P(A)P(D =++ 同理P(B ∣D)=5/11, P(C ∣D)=28/55 5.9 设次品为D ,由贝叶斯公式有: P(A ∣D)=)C P(C)P(D )B P(B)P(D )A P(A)P(D ) A P(A)P(D ++=0.249 同理P(B ∣D)=0.112 5.10 由二项式分布可得:P (x=0)=0.25, P (x=1)=0.5, P (x=2)=0.25 5.11 (1) P (x=100)=0.001, P (x=10)=0.01, P (x=1)=0.2, P (x=0)=0.789
心理和教育统计学课后题答案解析
张厚粲现代心理与教育统计学第一章答案 1名词概念 (1 )随机变量 答:在统计学上把取值之前,不能准确预料取到什么值的变量,称为随机变量。 (2)总体 答:总体(population )又称为母全体或全域,是具有某种特征的一类事物的总体,是研究对象的全体。 (3)样本 答:样本是从总体中抽取的一部分个体。 (4)个体 答:构成总体的每个基本单元。 (5)次数 是指某一事件在某一类别中出现的数目,又称作频数,用f表示。 (6)频率 答:又称相对次数,即某一事件发生的次数除以总的事件数目,通常用比例或百分数来表示。 (7)概率 答:概率(probability), 概率论术语,指随机事件发生的可能性大小度量指标。其描述性定义。随机事件A在所有试验中发生的可能性大小的量值,称为事件A的概率,记为P(A)。 (8)统计量 答:样本的特征值叫做统计量,又称作特征值。 (9)参数 答:又称总体参数,是描述一个总体情况的统计指标。 (10)观测值 答:随机变量的取值,一个随机变量可以有多个观测值。 2何谓心理与教育统计学?学习它有何意义? 答:(1)心理与教育统计学是专门研究如何运用统计学原理和方法,搜集、整理、分析心理 与教育科学研究中获得的随机性数据资料,并根据这些数据资料传递的信息,进行科学推论 找出心理与教育统计活动规律的一门学科。具体讲,就是在心理与教育研究中,通过调查、实验、测量等手段有意地获取一些数据,并将得到的数据按统计学原理和步骤加以整理、计 算、绘制图表、分析、判断、推理,最后得出结论的一种研究方法。 (2)学习心理与教育统计学有重要的意义。 ①统计学为科学研究提供了一种科学方法。 科学是一种知识体系。它的研究对象存在于现实世界各个领域的客观事实之中。它的主 要任务是对客观事实进行预测和分类,从而揭示蕴藏于其中的种种因果关系。要提高对客观 事实观测及分析研究的能力,就必须运用科学的方法。统计学正是提供了这样一种科学方法。统计方法是从事科学研究的一种必不可少的工具。 ②心理与教育统计学是心理与教育科研定量分析的重要工具。 凡是客观存在事物,都有数量的表现。凡是有数量表现的事物,都可以进行测量。心理 与教育现象是一种客观存在的事物,它也有数量的表现。虽然心理与教育测量具有多变性而 且旨起它发生变化的因素很多,难以准确测量。但是它毕竟还是可以测量的。因此,在进行 心理与教育科学研究时,在一定条件下,是可以对心理与教育现象进行定量分析的。心理与 教育统计就是对心理与教育问题进行定量分析的重要的科学工具。 ③广大心理与教育工作者学习心理与教育统计学的具体意义。 a. 可经顺利阅读国内外先进的研究成果。 b. 可以提高心理与教育工作的科学性和效率。
(完整版)医学统计学第六版课后答案
第一章绪论 一、单项选择题 答案 1. D 2. E 3. D 4. B 5. A 6. D 7. A 8. C 9. E 10. D 二、简答题 1答由样本数据获得的结果,需要对其进行统计描述和统计推断,统计描述可以使数据更容易理解,统计推断则可以使用概率的方式给出结论,两者的重要作用在于能够透过偶然现象来探测具有变异性的医学规律,使研究结论具有科学性。 2答医学统计学的基本内容包括统计设计、数据整理、统计描述和统计推断。统计设计能够提高研究效率,并使结果更加准确和可靠,数据整理主要是对数据进行归类,检查数据质量,以及是否符合特定的统计分析方法要求等。统计描述用来描述及总结数据的重要特征,统计推断指由样本数据的特征推断总体特征的方法,包括参数估计和假设检验。 3答统计描述结果的表达方式主要是通过统计指标、统计表和统计图,统计推断主要是计算参数估计的可信区间、假设检验的P 值得出相互比较是否有差别的结论。 4答统计量是描述样本特征的指标,由样本数据计算得到,参数是描述总体分布特征的指标可由“全体”数据算出。 5答系统误差、随机测量误差、抽样误差。系统误差由一些固定因素产生,随机测量误差是生物体的自然变异和各种不可预知因素产生的误差,抽样误差是由于抽样而引起的样本统计量与总体参数间的差异。 6答三个总体一是“心肌梗死患者”所属的总体二是接受尿激酶原治疗患者所属的总体三是接受瑞替普酶治疗患者所在的总体。 第二章定量数据的统计描述 一、单项选择题 答案 1. A 2. B 3. E 4. B 5. A 6. E 7. E 8. D 9. B 10. E 二、计算与分析 2
统计学课后答案
4.1 一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下: 2 4 7 10 10 10 12 12 14 15 要求:(1)计算汽车销售量的众数、中位数和平均数。(2)根据定义公式计算四分位数。 (3)计算销售量的标准差。 (4)说明汽车销售量分布的特征。 解: Statistics 汽车销售数量 N Valid10 Missing0 Mean Median Mode10 Std. Deviation Percentiles25 50 75 4.2 随机抽取25个网络用户,得到他们的年龄数据如下: 1915292524 2321382218 3020191916 2327223424 4120311723 要求;(1)计算众数、中位数: 1、排序形成单变量分值的频数分布和累计频数分布: 网络用户的年龄
从频数看出,众数Mo 有两个:19、23;从累计频数看,中位数Me=23。 (2)根据定义公式计算四分位数。 Q1位置=25/4=,因此Q1=19,Q3位置=3×25/4=,因此Q3=27,或者,由于25 和27都只有一个,因此Q3也可等于25+×2=。 (3)计算平均数和标准差; Mean=;Std. Deviation= (4)计算偏态系数和峰态系数: Skewness=;Kurtosis= (5)对网民年龄的分布特征进行综合分析:分布,均值=24、标准差=、呈右偏分布。如需看清楚分布形态,需要进行分组。 为分组情况下的直方图: 为分组情况下的概率密度曲线: 分组: 1、确定组数:()lg 25lg() 1.398111 5.64lg(2)lg 20.30103 n K =+ =+=+=,取k=6 2、确定组距:组距=( 最大值 - 最小值)÷ 组数=(41-15)÷6=,取5 3、分组频数表 网络用户的年龄 (Binned)
统计学第五章课后题及答案解析
第五章 一、单项选择题 1.抽样推断的目的在于() A.对样本进行全面调查 B.了解样本的基本情况 C.了解总体的基本情况 D.推断总体指标 2.在重复抽样条件下纯随机抽样的平均误差取决于() A.样本单位数 B.总体方差 C.抽样比例 D.样本单位数和总体方差 3.根据重复抽样的资料,一年级优秀生比重为10%,二年级为20%,若抽样人数相等时,优秀生比重的抽样误差() A.一年级较大 B.二年级较大 C.误差相同 D.无法判断 4.用重复抽样的抽样平均误差公式计算不重复抽样的抽样平均误差结果将()A.高估误差 B.低估误差 C.恰好相等 D.高估或低估 5.在其他条件不变的情况下,如果允许误差缩小为原来的1/2,则样本容量()A.扩大到原来的2倍 B.扩大到原来的4倍 C.缩小到原来的1/4 D.缩小到原来的1/2 6.当总体单位不很多且差异较小时宜采用() A.整群抽样 B.纯随机抽样 C.分层抽样 D.等距抽样 7.在分层抽样中影响抽样平均误差的方差是() A.层间方差 B.层内方差 C.总方差 D.允许误差 二、多项选择题 1.抽样推断的特点有() A.建立在随机抽样原则基础上 B.深入研究复杂的专门问题 C.用样本指标来推断总体指标 D.抽样误差可以事先计算 E.抽样误差可以事先控制 2.影响抽样误差的因素有() A.样本容量的大小 B.是有限总体还是无限总体 C.总体单位的标志变动度 D.抽样方法 E.抽样组织方式 3.抽样方法根据取样的方式不同分为() A.重复抽样 B.等距抽样 C.整群抽样 D.分层抽样 E.不重复抽样 4.抽样推断的优良标准是() A.无偏性 B.同质性 C.一致性 D.随机性 E.有效性 5.影响必要样本容量的主要因素有() A.总体方差的大小 B.抽样方法
教育统计学与SPSS课后作业答案祥解题目
教育统计学课后作业 一、P118 1 题目:10位大一学生平均每周所花的学习时间与他们的期末考试成绩见表6-17.试问: (1)学习时间与考试成绩之间是否相关? (2)比较两组数据谁的差异程度大一些? (3)比较学生2与学生9的期末考试测验成绩。 表6-17 学习时间与期末考试成绩 1 2 3 4 5 6 7 8 9 10 学习时间考试成绩40 58 43 73 18 56 10 47 25 58 33 54 27 45 17 32 30 68 47 69 解题步骤: (1)第一步:定义变量:“xuexishijian”、“xuexichengji”后,输入数据.如下图: 1
第二步:单击选择“分析(Analyze)”中的“相关(Correlate)”中的“双变量(Bivariate Correlations)”, 将上图中的“xuexishijian”和“xuexichengji”添加到右边变量框中,如下图: 第三步:点击“确定“后,输出结果如下图: 第四步:分析结果
3 由上图可知:学习时间与学习成绩之间的pearson 相关系数为0.714,p (双侧)为0.20。自由度 df=10-2=8时,查“皮尔逊积差相关系数显著临界值表”知:r 0.05= 0.623 ; r 0.01=0.765。 因为0.765 > 0.714 >0.623,所以在0.05水平上学习时间和学习成绩是相关显著的。 (2)SPSS 软件分析结果如下图: 由上图可知:学习时间标准差和平均值为:S 1=12.037 ?X 1= 29.00 ;学习时间标准差和平均值为:S 2=12.437?X 2=56.00 根据差异系数公式可知: 学习时间差异系数为:%100?=X S CV S =12.037/29.00×100%=41.51% 学习成绩差异系数为:%100?= X S CV S =12.437/56.00×100%=22.27% 有上述结果可知学习时间差异程度大于学习成绩差异程度。 (4) 把学生2和学生9的期末考试成绩转化成标准分数: Z 2=(X -?X) /S= (73—56)/12.437=1.367 Z 9=(X-?X)/S=(68—56)/12.437=0.965 由上计算可知:学生2期末考试测验成绩优于学生9的期末考试测验成绩。 二、P119 2 题目:某班数学的平均成绩为90,标准差10;化学的平均分为85,标准差为8;物理的平均分为79,标准差为15.某生这三科成绩分别为95,80,80.试问 (1) 该生在哪一学科上突出一些? (2) 该班三科成绩的差异度如何?有无学习分化现象? (3) 该生的学期分数是多少? (4) 三科的总平均和总标准差是多少? 解题步骤:
贾俊平统计学(第六版)思考题答案
1、什么是统计学? 统计学是一门收集、分析、表述、解释数据的科学和艺术。 2、描述统计:研究的是数据收集、汇总、处理、图表描述、概括与分析等统计方法。 推断统计:研究的是如何利用样本数据来推断总体特征。 3、统计学据可以分成哪几种类型,个有什么特点? 按照计量尺度不同,分为:分类数据、顺序数据、数值型数据。 分类数据:只能归于某一类别的,非数字型数据。 顺序数据:只能归于某一有序类别的,非数字型数据。 数值型数据:按数字尺度测量的观察值,结果表现为数值。 按收集方法不同。分为:观测数据、和实验数据 观测数据:通过调查或观测而收集到的数据;不控制条件; 社会经济领域 实验数据:在试验中收集到的数据;控制条件;自然科学领域。 按时间不同,分为:截面数据、时间序列数据 截面数据:在相同或近似相同的时间点上收集的数据。 时间序列数据:在不同时间收集的数据。 4、举例说明总体、样本、参数、统计量、变量这几个概念。 总体:是包含全部研究个体的集合,包括有限总体和无限总体(围、数目判定) 样本:从总体中抽取的一部分元素的集合。 参数:用来描述总体特征的概括性数字度量。(平均数、标准差、比例等) 统计量:用来描述样本特征的概括性数字度量。(平均数、标准差、比例等) 变量:是说明样本某种特征的概念,其特点:从一次观察到下一次观察结果会呈现出差别或变化。(商品销售额、受教育程度、产品质量等级等) (对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。) 5、变量可以分为哪几类? 分类变量:说明事物类别;取值是分类数据。 顺序变量:说明事物有序类别;取值是顺序数据 数值型变量:说明事物数字特征;取值是数值型数据。 变量也可以分为:随机变量和非随机变量;经验变量和理论变量 6、举例说明离散型变量和连续型变量。 离散型变量:只能取有限个、可数值的变量。(企业个数、产品数量) 连续型变量:可以在一个或多个区间中取任何值的变量。(年龄、温度、零件尺寸误差)7、请举出统计应用的几个例子。 市场调查、人口普查等。 8、请举出应用统计学的几个领域。 社会科学中的经济分析、政府政策制定等;自然科学中的物理、生物领域等。
统计学课后习题答案第五章 指数
第五章指数 一﹑单项选择题 1.广义的指数是指反映 A.价格变动的相对数 B.物量变动的相对数 C.总体数量变动的相对数 D.各种动态相对数 2.狭义的指数是反映哪一总体数量综合变动的相对数? A.有限总体 B.无限总体 C.简单总体 D.复杂总体 3.指数按其反映对象范围不同,可以分为 A.个体指数和总指数 B.数量指标指数和质量指标指数 C.定基指数和环比指数 D.平均指数和平均指标指数 4.指数按其所表明的经济指标性质不同可以分为 A.个体指数和总指数 B.数量指标指数和质量指标指数 C.定基指数和环比指数 D.平均指数和平均指标指数 5.按指数对比基期不同,指数可分为 A.个体指数和总指数 B.定基指数和环比指数 C.简单指数和加权指数 D.动态指数和静态指数 6.下列指数中属于数量指标指数的是 A.商品价格指数 B.单位成本指数 C.劳动生产率指数 D.职工人数指数 7.下列指数中属于质量指标指数的是 A.产量指数 B.销售额指数 C.职工人数指数 D.劳动生产率指数 8.由两个总量指标对比所形成的指数是 A.个体指数 B.综合指数 C.总指数 D.平均指数 9.综合指数包括 A.个体指数和总指数 B.数量指标指数和质量指标指数 C.定基指数和环比指数 D.平均指数和平均指标指数 10.总指数编制的两种基本形式是 A.个体指数和综合指数 B.综合指数和平均指数 C.数量指标指数和质量指标指数 D.固定构成指数和结构影响指数 11.数量指标指数和质量指标指数的划分依据是 A.指数化指标性质不同 B.所反映的对象范围不同 C.所比较的现象特征不同 D.指数编制的方法不同 12.编制综合指数最关键的问题是确定 A.指数化指标的性质 B.同度量因素及其时期 C.指数体系 D.个体指数和权数 13.编制数量指标指数的一般原则是采用下列哪一指标作为 同度量因素 A.基期的质量指标 B.报告期的质量指标 C.报告期的数量指标 D.基期的数量指标 14.编制质量指标指数的一般原则是采用下列哪一指标作为
教育统计学复习题及答案
《教育统计学》复习题及答案一、填空题 1.教育统计学的研究对象是.教育问题。 2.一般情况下,大样本是指样本容量.大于30 的样本。 3.标志是说明总体单位的名称,它有.品质标志和数量标志两种。 4.统计工作的三个基本步骤是:、和。 5.集中量数是反映一组数据的趋势的。 6.“65、66、72、83、89”这组数据的算术平均数是。 7.6位学生的身高分别为:145、135、128、145、140、130厘米,他们的众数是。 8.若某班学生数学成绩的标准差是8分,平均分是80分,其标准差系数是。 9.参数估计的方法有和两种。 10.若两个变量之间的相关系数是负数,则它们之间存在。 11.统计工作与统计资料的关系是和的关系。 12.标准差越大,说明总体平均数的代表性越,标准差越小,说明总体平均数的代表性越。 13.总量指标按其反映的内容不同可以分为和。 二、判断题 1、教育统计学属于应用统计学。()
2、标志是说明总体特征的,指标是说明总体单位特征的。() 3、统计数据的真实性是统计工作的生命() 4、汉族是一个品质标志。() 5、描述一组数据波动情况的量数称为差异量数。() 6、集中量数反映的是一组数据的集中趋势。() 7、在一个总体中,算术平均数、众数、中位数可能相等。() 8、同一总体各组的结构相对指标数值之和不一定等于100%。() 9、不重复抽样误差一定大于重复抽样误差。() 10. 一致性是用样本统计量估计统计参数时最基本的要求。() 三、选择题 1.某班学生的平均年龄为22岁,这里的22岁为( )。 A.指标值 B.标志值 C.变量值 D.数量标志值 2.统计调查中,调查标志的承担者是( )。 A.调查对象 B.调查单位 C.填报单位 D.调查表 3.统计分组的关键是( )。 A.确定组数和组距 B.抓住事物本质 C.选择分组标志和划分各组界限 D.统计表的形式设计 4.下列属于全面调查的有( )。 A.重点调查 B.典型调查 C.抽样调查 D.普查 5.统计抽样调查中,样本的取得遵循的原则是( )。 A.可靠性 B.准确性 C.及时性 D.随机性 6. 在直线回归方程Yc =a+bx中,b表示( )。 增加1个单位,y增加a的数量增加1个单位,x增加b的数量 增加1个单位,x的平均增加量增加1个单位,y的平均增加量 7.下列统计指标中,属于数量指标的有() A、工资总额 B、单位产品成本 C、合格品率 D、人口密度 8.在其他条件不变情况下,重复抽样的抽样极限误差增加1倍,则样本单位数变为( )。 A.原来的2倍 B.原来的4倍 C.原来的1/2倍 D.原来的1/4倍 四、简答题 1.学习教育统计学有哪些意义?
_统计学概论第六版习题集总答案
第一章总论 一、填空题 1.威廉·配弟、约翰·格朗特 2.统计工作、统计资料、统计学、统计工作、统计资料、统计学3.数量对比分析 4.大量社会经济现象总体的数量方面 5.大量观察法、统计分组法、综合指标法、统计推断法 6.统计设计、统计调查、统计整理、统计分析 7.信息、咨询、监督 8.同质性 9.大量性、同质性、差异性 10.研究目的、总体单位 11.这些单位必须是同质的 12.属性、特征 13.变量、变量值 14.总体单位、总体 15.是否连续、离散、性质 二、是非题 1.非2.非3.是4.非5.是6.非7.是8.是9.是10.非11.非12.非13.非14.是15.非 三、单项选择题 1.C 2.B 3.C 4.A 5.C 6.C 7.A 8.A 9.C 10.B 11.A 12.B 13.C 14.A 15.A 四、多项选择题 1.BC 2.ABC 3.ABE 4.ABCD 5.BCDE 6.AC 7.ABCDE 8.BD 9.AB 10.ABCD 11.BD 12.ABCD 13.BD 14.ABD 15.ABC 五、简答题 略 第二章统计调查
一、填空题 1.统计报表普查重点调查抽样调查典型调查 2.直接观察法报告法采访法 3. 统计报表专门调查 4. 经常性一次性 5. 调查任务和目的调查项目组织实施计划 6. 单一表一览表 7. 基层填报单位综合填报单位 8. 原始记录统计台帐 9. 单一一览 二、是非题 1.是 2.是 3.非 4.是 5.非 6.是 7.是 8.非 9.是 10.是 三、单项选择题 1. D 2. A 3. C 4. A 5. B 6. C 7. B 8. D 9. C 10. B 四、多项选择题 1. BCE 2. ABCDE 3. ADE 4. ADE 5.ACDE 6. ABD 7. BCDE 8. ABE 9.ACD 五、简答题 略 第三章统计整理 一、填空题 1.统计汇总选择分组标志 2.资料审核统计分组统计汇总编制统计表 3.不同相同 4.频率比率(或频率) 5.全距组距 6.上限以下 7.组中值均匀 8.离散连续重叠分组 9.手工汇总电子计算机汇总 10.平行分组体系复合分组体系 11.主词宾词
统计学课后习题参考答案
思考题与练习题 参考答案 【友情提示】请各位同学完成思考题与练习题后再对照参考答案。回答正确,值得肯定;回答错误,请找出原因更正,这样使用参考答案,能力会越来越高,智慧会越来越多。学而不思则罔,如果直接抄答案,对学习无益,危害甚大。想抄答案者,请三思而后行! 第一章绪论 思考题参考答案 1.不能,英军所有战机=英军被击毁的战机+英军返航的战机+英军没有弹孔的战机,因为英军被击毁的战机有的掉入海里、敌军占领区,或因堕毁而无形等,不能找回;没有弹孔的战机也不可能自己拿来射击后进行弹孔位置的调查。即便被击毁的战机找回或没有弹孔的战机自己拿来射击进行实验,也不能从多个弹孔中确认那个弹孔就是危险的。 2.问题:飞机上什么区域应该加强钢板?瓦尔德解决问题的思想:在她的飞机模型上逐个不重不漏地标示返航军机受敌军创伤的弹孔位置,找出几乎布满弹孔的区域;发现:没有弹孔区域就是军机的危险区域。 3.能,拯救与发展自己的参考路径为:①找出自己的优点,②明确自己大学阶段的最佳目标,③拟出一个发扬自己优点,实现自己大学阶段最佳目标的可行计划。 练习题参考答案 一、填空题 1.调查。
2.探索、调查、发现。 3、目的。 二、简答题 1.瓦尔德;把剩下少数几个没有弹孔的区域加强钢板。 2.统计学解决实际问题的基本思路,即基本步骤就是:①提出与统计有关的实际问题;②建立有效的指标体系;③收集数据;④选用或创造有效的统计方法整理、显示所收集数据的特征;⑤根据所收集数据的特征、结合定性、定量的知识作出合理推断;⑥根据合理推断给出更好决策的建议。不解决问题时,重复第②-⑥步。 3.在结合实质性学科的过程中,统计学就是能发现客观世界规律,更好决策,改变世界与培养相应领域领袖的一门学科。 三、案例分析题 1.总体:我班所有学生;单位:我班每个学生;样本:我班部分学生;品质标志:姓名;数量标志:每个学生课程的成绩;指标:全班学生课程的平均成绩 ;指标体系:上学期全班同学学习的科目 ;统计量:我班部分同学课程的平均成绩 ;定性数据:姓名 ;定量数据: 课程成绩 ;离散型变量:学习课程数;连续性变量:学生的学习时间;确定性变量:全班学生课程的平均成绩;随机变量:我班部分同学课程的平均成绩,每个同学进入教室的时间;横截面数据:我班学生月门课程的出勤率;时间序列数据:我班学生课程分别在第一个月、第二个月、第三个月、第四个月的出勤率;面板数据:我班学生课程分别在第一个月、第二个月、第三个月、第四个月的出勤率;选用描述统计。 2.(1)总体:广州市大学生;单位:广州市的每个大学生。(2)如果调查中了解的就是价格高低,为定序尺度;如果调查中了解的就是商品丰富、价格合适、节约时间,为定类尺度。(3)广州市大学生在网上购物的平均花费。(4)就是用统计量作为参数的估计。(5)推断统计。 3.(1)10。(2)6。(3)定类尺度:汽车名称,燃油类型;定序尺度:车型大小;定距尺度:引擎的汽缸数;定比尺度:市区驾车的油耗,公路驾车的油耗。(4)定性变量:汽车名称,车型大小,燃油类型;定量变量:引擎的汽缸数,市区驾车的油耗,公路驾车的油耗。(5)40%;(6)30%。 第二章收集数据 思考题参考答案
统计学习题答案 第5章 参数估计
第5章 参数估计 ●1. 从一个标准差为5的总体中抽出一个容量为40的样本,样本均值为25。 (1) 样本均值的抽样标准差x σ等于多少? (2) 在95%的置信水平下,允许误差是多少? 解:已知总体标准差σ=5,样本容量n =40,为大样本,样本均值x =25, (1)样本均值的抽样标准差 x σ=0.7906 (2)已知置信水平1-α=95%,得 α/2Z =1.96, 于是,允许误差是E = α/2 Z 6×0.7906=1.5496。 ●2.某快餐店想要估计每位顾客午餐的平均花费金额,在为期3周的时间里选取49名顾客组成了一个简单随机样本。 (3) 假定总体标准差为15元,求样本均值的抽样标准误差; (4) 在95%的置信水平下,求允许误差; (5) 如果样本均值为120元,求总体均值95%的置信区间。 解:(1)已假定总体标准差为σ=15元, 则样本均值的抽样标准误差为 x σ15=2.1429 (2)已知置信水平1-α=95%,得 α/2Z =1.96, 于是,允许误差是E = α/2 Z 6×2.1429=4.2000。 (3)已知样本均值为x =120元,置信水平1-α=95%,得 α/2Z =1.96, 这时总体均值的置信区间为 α/2 x Z 0±4.2=124.2115.8 可知,如果样本均值为120元,总体均值95%的置信区间为(115.8,124.2)元。 ●3.某大学为了解学生每天上网的时间,在全校7500名学生中采取不重复抽样方法随机抽取36人,调查他们每天上网的时间,得到下面的数据(单位:小时): 3.3 3.1 6.2 5.8 2.3 4.1 5.4 4.5 3.2 4.4 2.0 5.4 2.6 6.4 1.8 3.5 5.7 2.3 2.1 1.9 1.2 5.1 4.3 4.2 3.6 0.8 1.5 4.7 1.4 1.2 2.9 3.5 2.4 0.5 3.6 2.5
教育统计学课后练习参考答案
教育统计学课后练习参考答案 第一章 1、教育统计学,就是应用数理统计学的一般原理和方法,对教育调查和教育实验等途径所获得的数据资料进行整理、分析,并以此为依据,进行科学推断,从而揭示蕴含在教育现象中的客观规律的一门科学。 教育统计学既是统计科学中的一个分支学科,又是教育科学中的一个分支学科,是两种科学相互结合、相互渗透而形成的一门交叉学科。从学科体系来看,教育统计学属于教育科学体系的一个方法论分支;从学科性质来看,教育统计学又属于统计学的一个应用分支。 2、描述统计主要是通过对数据资料进行整理,计算出简单明白的统计量数来描述庞大的资料,以显示其分布特征的统计方法。 推断统计又叫分析统计,它根据统计学的原理和方法,从我们所研究的全体对象(即总体)中,按照等可能性原则采取随机抽样的方法,抽出总体中具有代表性的部分个体组成样本,在样本所提供的数据的基础上,运用概率理论进行分析、论证,在一定可靠程度上对总体的情况进行科学推断的一种统计方法。 3、在自然界或教育研究中,一种事物常存在几种可能出现的情况或获得几种可能的结果,这类现象称为随机现象。 随机现象具的特点: (1)一次条件完全相同的实验有多种可能的结果(这样的实验称为随机实验); (2)在实验之前不能确切知道哪种结果会发生; (3)在相同的条件下可以重复进行这样的实验。 4、总体,也叫做母体或全域,是指具有某种共同特征的个体的总和。 当所研究的总体数量非常大时,可以从总体中抽取其中一部分个体来观测,由此来推断总体的信息,从总体中抽出的这部分个体就称为样本,它是用以表征总体的个体的集合。 通常将样本中样本个数大于或等于30个的样本称为大样本,小于30个的称为小样本。 5、复置抽样指每次抽出的个体经观测后,仍放回原总体,然后再从总体中抽取下一个个体。 6、反映总体特征的量数叫做总体参数,简称参数。反映样本特征的量数叫做样本统计量,简称统计量。 参数是总体的真正数值,是固定的常量,理论上应该通过计算总体中全部个体的数值而获得,但由于总体中个体的数量通常很大,总体参数往往很难获得,在统计分析中一般通过样本的数值来估计。在进行推断统计时,就是根据样本统计量来推断总体相应的参数。 第二章 1、按照数据的来源,可分为计数数据和度量数据;按照数据的取值情况,可分为间断性数据和连续性数据;按照数据的测量水平,可分为称名数据、顺序数据、等距数据和比率数据。 2、数据整理的基本方法包括对数据进行排序、统计分组、绘制统计图表等。 3、表的结构要简洁明了;表的层次要清晰;主谓分明。 4、连续性数据:(2),(3);间断性数据:(1),(4)。 5、略 6、(1)50;(2)75;(3)34;(4)5;(5)45
统计学课后答案
第一部分 课程指导 第一章绪论 一、本章重点 1.统计的基本涵义。统计工作、统计资料和统计学,统计资料是统计工作的成果;统计学是统计工作的经验总结和理论概括,统计学与统计工作是理论与实践的关系。 2.统计学的历史大体可分为古典统计学时期、近代统计学时期、现代统计学时期。曾经产生过记述学派、政治算术学派、数理统计学派和社会经济统计学派等流派。赫尔曼·康令、特弗里德·阿亨瓦尔、威廉·配第、约翰·格朗特、阿道夫·凯特勒、克尼斯等是各个不同时期、不同流派的代表人物。《政治算术》、《社会物理学》是统计学说史上的典型著作。 3.统计的研究对象是大量社会经济现象的数量方面,社会经济现象的数量表现,现象变化的数量关系和数量界限,通过这个对象的研究以认识和利用社会经济发展变化的规律。 4.统计具有数量性、总体性、具体性、社会性等特点。大量观察法、统计分组法、综合指标法和归纳推理法是统计研究的基本方法。 5.统计的基本任务是对国民经济与社会发展情况进行统计调查、统计分析、提供统计资料和统计咨询意见,实行统计监督。统计具有信息的职能、咨询的职能、监督的职能。一个完整的统计工作过程包括:统计设计、统计调查、统计整理和统计分析四个阶段。 6.总体与总体单位、标志与指标、变异与变量是统计中常用的基本概念。同质性、大量性、差异性是统计总体的基本特征。统计指标具有数量性、综合性、具体性三个特点。指标的构成必须完整、指标的名称必须具有正确的涵义和理论依据、要明确指标的计算口径和范围、要有科学的计算方法等是对一个统计指标的基本要求。掌握统计指标体系的概念和基本分类。 二、难点释疑 1.对于社会经济统计的性质及研究对象,要从马克思主义认识论的基本原理,客观事物质与量的辩证统一关系出发,从统计总体本身具有大量性、同质性、差异性特点出发,联系社会经济统计的实践,从统计要发现规律、描述规律、认识规律、利用规律等递进关系上来深刻正确的理解。 2.熟记、掌握以下基本概念:统计总体与总体单位,标志与指标、统计指标体系。要掌握这些重要概念的联系与区别、特点、表现形式及其基本分类等。 三、练习题: (一)填空题 1.“统计”一词有三种涵义,即统计工作、()和()。
最新《统计分析与SPSS的应用(第五版)》课后练习答案(第5章)
《统计分析与SPSS的应用(第五版)》(薛薇) 课后练习答案 第5章SPSS的参数检验 1、某公司经理宣称他的雇员英语水平很高,如果按照英语六级考试的话,一般平均得分为 75分。现从雇员中随机选出11人参加考试,得分如下: 80, 81, 72, 60, 78, 65, 56, 79, 77,87, 76 请问该经理的宣称是否可信。 原假设:样本均值等于总体均值即u=u0=75 步骤:生成spss数据→分析→比较均值→单样本t检验→相关设置→输出结果(Analyze->compare means->one-samples T test;) 采用单样本T检验(原假设H0:u=u0=75,总体均值与检验值之间不存在显著差异); 单个样本统计量 N 均值标准差均值的标准误 成绩11 73.73 9.551 2.880 单个样本检验 检验值 = 75 t df Sig.(双侧) 均值差值差分的 95% 置信区间下限上限 成绩-.442 10 .668 -1.273 -7.69 5.14 分析:指定检验值:在test后的框中输入检验值(填75),最后ok! 分析:N=11人的平均值(mean)为73.7,标准差(std.deviation)为9.55,均值标准误差(std error mean)为2.87.t统计量观测值为-4.22,t统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668,六七列是总体均值与原假设值差的95%的置信区间,为(-7.68,5.14),由此采用双尾检验比较a和p。T统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668>a=0.05所以不能拒绝原假设;且总体均值的95%的置信区间为(67.31,80.14),所以均值在67.31~80.14内,75包括在置信区间内,所以经理的话是可信的。 2、在某年级随机抽取35名大学生,调查他们每周的上网时间情况,得到的数据如下(单位:小时): (1)请利用SPSS对上表数据进行描述统计,并绘制相关的图形。 (2)基于上表数据,请利用SPSS给出大学生每周上网时间平均值的95%的置信区间。 (1)分析→描述统计→描述、频率
精选-《教育统计学》复习题及答案
《教育统计学》复习题及答案 一、填空题 1.教育统计学的研究对象是.教育问题。 2.一般情况下,大样本是指样本容量.大于30 的样本。 3.标志是说明总体单位的名称,它有.品质标志和数量标志两种。 4.统计工作的三个基本步骤是:、和。 5.集中量数是反映一组数据的趋势的。 6.“65、66、72、83、89”这组数据的算术平均数是。 7.6位学生的身高分别为:145、135、128、145、140、130厘米,他们的众数是。 8.若某班学生数学成绩的标准差是8分,平均分是80分,其标准差系数是。 9.参数估计的方法有和两种。 10.若两个变量之间的相关系数是负数,则它们之间存在。 11.统计工作与统计资料的关系是和的关系。 12.标准差越大,说明总体平均数的代表性越,标准差越小,说明总体平均数的代表性越。 13.总量指标按其反映的内容不同可以分为和。 二、判断题 1、教育统计学属于应用统计学。() 2、标志是说明总体特征的,指标是说明总体单位特征的。() 3、统计数据的真实性是统计工作的生命() 4、汉族是一个品质标志。() 5、描述一组数据波动情况的量数称为差异量数。() 6、集中量数反映的是一组数据的集中趋势。() 7、在一个总体中,算术平均数、众数、中位数可能相等。() 8、同一总体各组的结构相对指标数值之和不一定等于100%。() 9、不重复抽样误差一定大于重复抽样误差。() 10. 一致性是用样本统计量估计统计参数时最基本的要求。() 三、选择题 1.某班学生的平均年龄为22岁,这里的22岁为( )。
A.指标值 B.标志值 C.变量值 D.数量标志值 2.统计调查中,调查标志的承担者是( )。 A.调查对象 B.调查单位 C.填报单位 D.调查表 3.统计分组的关键是( )。 A.确定组数和组距 B.抓住事物本质 C.选择分组标志和划分各组界限 D.统计表的形式设计 4.下列属于全面调查的有( )。 A.重点调查 B.典型调查 C.抽样调查 D.普查 5.统计抽样调查中,样本的取得遵循的原则是( )。 A.可靠性 B.准确性 C.及时性 D.随机性 6. 在直线回归方程Yc =a+bx中,b表示( )。 A.x增加1个单位,y增加a的数量 B.y增加1个单位,x增加b的数量 C.y增加1个单位,x的平均增加量 D.x增加1个单位,y的平均增加量 7.下列统计指标中,属于数量指标的有() A、工资总额 B、单位产品成本 C、合格品率 D、人口密度 8.在其他条件不变情况下,重复抽样的抽样极限误差增加1倍,则样本单位数变为( )。 A.原来的2倍 B.原来的4倍 C.原来的1/2倍 D.原来的1/4倍 四、简答题 1.学习教育统计学有哪些意义? 答:(1)教育统计是教育科学研究的工具; (2)学习教育统计学有利于教育行政和管理工作者正确掌握情况,进行科学决策; (3)教育统计是教育评价不可缺少的工具; (4)学习教育统计学有利于训练科学的推理与思维方法。 2.统计图表的作用有哪几方面? 1)表明同类统计事项指标的对比关系; (2)揭示总体内部的结构; (3)反映统计事项的发展动态; (4)分析统计事项之间的依存关系; (5)说明总体单位的分配; (6)检查计划的执行情况; (7)观察统计事项在地域上的分布。 3.简述相关的含义及种类。 答:相关就是指事物或现象之间的相互关系。
统计学课后答案
第一章总论(16页) 一、判断题 1、统计学是数学的一个分支 答:错。统计学和数学都是研究数量规律的,虽然两者关系非常密切,但有不同的性质特点。数学撇开具体的对象,以最一般的形式研究数量的联系和空间形式;统计学的数据则总是与客观的对象联系在一起,特别是统计学中的应用统计学与各不同领域的实质性学科有着非常密切的联系,是有具体对象的方法论。从研究方法看,数学的研究方法主要是逻辑推理和演绎论证的方法,而统计学的方法本质上是归纳的方法。统计学家特别是应用统计学家需要深入实际,进行调查或试验区取得数据,研究时不仅要运用统计学的方法,而且要掌握某一专门领域的知识,才能得到有意义的成果。从成果评价标准看,数学注意方法推导的严谨性和正确性;统计学则更加注意方法的适用性和操作性。 2、统计学是一门独立的社会科学。 答、错。统计学是横跨社会科学领域和自然科学领域的多学科性的科学。 3、统计学是一门实质性科学。 答:错。实质性的科学研究该领域现象的本质关系和变化规律;而统计学则是为研究认识这些关系和规律提供数量分析的方法。 4、统计学是一门方法论科学。 答:对统计学是有关如何测定、收集和分析反映客观现象总体数量的数据,以帮助人们正确认识客观世界数量规律的方法论科学。 5、描述统计是用文字和图标对客观世界进行描述 答:错。描述统计是对彩机的数据进行登记、审核、整理、归类,在此基础上进一步计算出各种能反映总体数量特征的综合指标,并用图标的形式表示经过归纳分析而得到的各种有用信息,描述统计不仅仅使用文字和图表来描述,更重要的是要利用有关统计指标反映客观事物的数量特征。 6、对于有限总体不必应用推断统计方法。 答:错。一些有限总体,由于各种原因,并不一定能采用全面调查的方法。例如,某一批电视机是有限总体,要检验其显像管的寿命,不可能对每一台都进行观察和试验,只能采用抽样调查方法得到样本,并结合推断统计方法估计显像管的寿命。 7、社会经济统计问题都属于有限总体的问题。 答:错。不少社会经济的统计问题属于无限总体。例如要研究消费者的消费倾向,消费者不仅包括现在的消费者而且还包括未来的消费者,因而实际上是一个无限总体。 8、理论统计学与应用统计学是两类性质不同的统计学。 答:对。理论统计学具有通用方法论的性质,而应用统计学则与各不同领域的实质性学科有着非常密切的联系,具有边缘交叉和复合型学科的性质。 二、选择题 1、社会经济统计学的研究对象是(A) A. 社会经济现象的数量方面, B. 统计工作, C. 社会经济的内在规律, D. 统计方法 2、考察全国的工业企业的情况时,以下标志中属于不变标志的有(A) A. 产业分类, B. 职工人数, C. 劳动生产率, D. 所有制 3、要考察全国居民的人均住房面积,其统计总体是(A) A. 全国说有居民, B. 全国的住宅, C. 各省市自治区, D. 某一居民户 4、最早使用统计学这一学术用语的是(B) A. 政治算数学派, B. 国势学派, C. 社会统计学派, D. 树立统计学派
统计学第五章课后题及答案解析
第五章 练习题 一、单项选择题 1.抽样推断的目的在于() A.对样本进行全面调查 B.了解样本的基本情况 C.了解总体的基本情况 D.推断总体指标 2.在重复抽样条件下纯随机抽样的平均误差取决于() A.样本单位数 B.总体方差 C.抽样比例 D.样本单位数和总体方差 3.根据重复抽样的资料,一年级优秀生比重为10%,二年级为20%,若抽样人数相等时,优秀生比重的抽样误差() A.一年级较大 B.二年级较大 C.误差相同 D.无法判断 4.用重复抽样的抽样平均误差公式计算不重复抽样的抽样平均误差结果将()A.高估误差 B.低估误差 C.恰好相等 D.高估或低估 5.在其他条件不变的情况下,如果允许误差缩小为原来的1/2,则样本容量()A.扩大到原来的2倍 B.扩大到原来的4倍 C.缩小到原来的1/4 D.缩小到原来的1/2 6.当总体单位不很多且差异较小时宜采用() A.整群抽样 B.纯随机抽样 C.分层抽样 D.等距抽样 7.在分层抽样中影响抽样平均误差的方差是() A.层间方差 B.层内方差 C.总方差 D.允许误差 二、多项选择题 1.抽样推断的特点有() A.建立在随机抽样原则基础上 B.深入研究复杂的专门问题 C.用样本指标来推断总体指标 D.抽样误差可以事先计算 E.抽样误差可以事先控制 2.影响抽样误差的因素有() A.样本容量的大小 B.是有限总体还是无限总体 C.总体单位的标志变动度 D.抽样方法 E.抽样组织方式 3.抽样方法根据取样的方式不同分为() A.重复抽样 B.等距抽样 C.整群抽样 D.分层抽样 E.不重复抽样 4.抽样推断的优良标准是() A.无偏性 B.同质性 C.一致性 D.随机性 E.有效性 5.影响必要样本容量的主要因素有() A.总体方差的大小 B.抽样方法
- 医学统计学第七版课后答案及解析
- 统计学(贾俊平等)课后习题答案
- 统计学第七章课后题及答案解析
- 人卫第七版医学统计学课后答案 李康、贺佳主编
- 医学统计学课后习题答案
- 贾俊平《统计学》(第7版)考点归纳和课后习题详解(含考研真题)(第3章 数据的图表展示)【圣才出品】
- 统计学第四章习题答案 贾俊平
- 医学统计学第七版课后答案及解析
- 医学统计学第七版课后答案及解析
- 统计学原理第七版李洁明-课后选择判断题习题及答案
- 统计学方积乾 第七版 第二章 定量资料的统计描述课后练习题答案
- 统计学原理 第七章课后习题及答案
- 统计学第七章课后题及答案解析
- 大学统计学第七章练习题及答案
- 医学统计学第七版课后答案及解析知识分享
- 统计学第七章、第八章课后题答案
- 贾俊平统计学 第七版 课后思考题
- 统计学课后习题答案(全章节)剖析
- 贾俊平统计学第7版第八章例题课后习题
- 统计学第四章习题答案-贾俊平电子教案