SPSS多元线性回归分析报告实例操作步骤

SPSS 统计分析
多元线性回归分析方法操作与分析
实验目的:
引入1998~2008年上海市城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率和房屋空置率作为变量,来研究上海房价的变动因素。
实验变量:
以年份、商品房平均售价(元/平方米)、上海市城市人口密度(人/平方公里)、城市居民人均可支配收入(元)、五年以上平均年贷款利率(%)和房屋空置率(%)作为变量。
实验方法:多元线性回归分析法
软件:
操作过程:
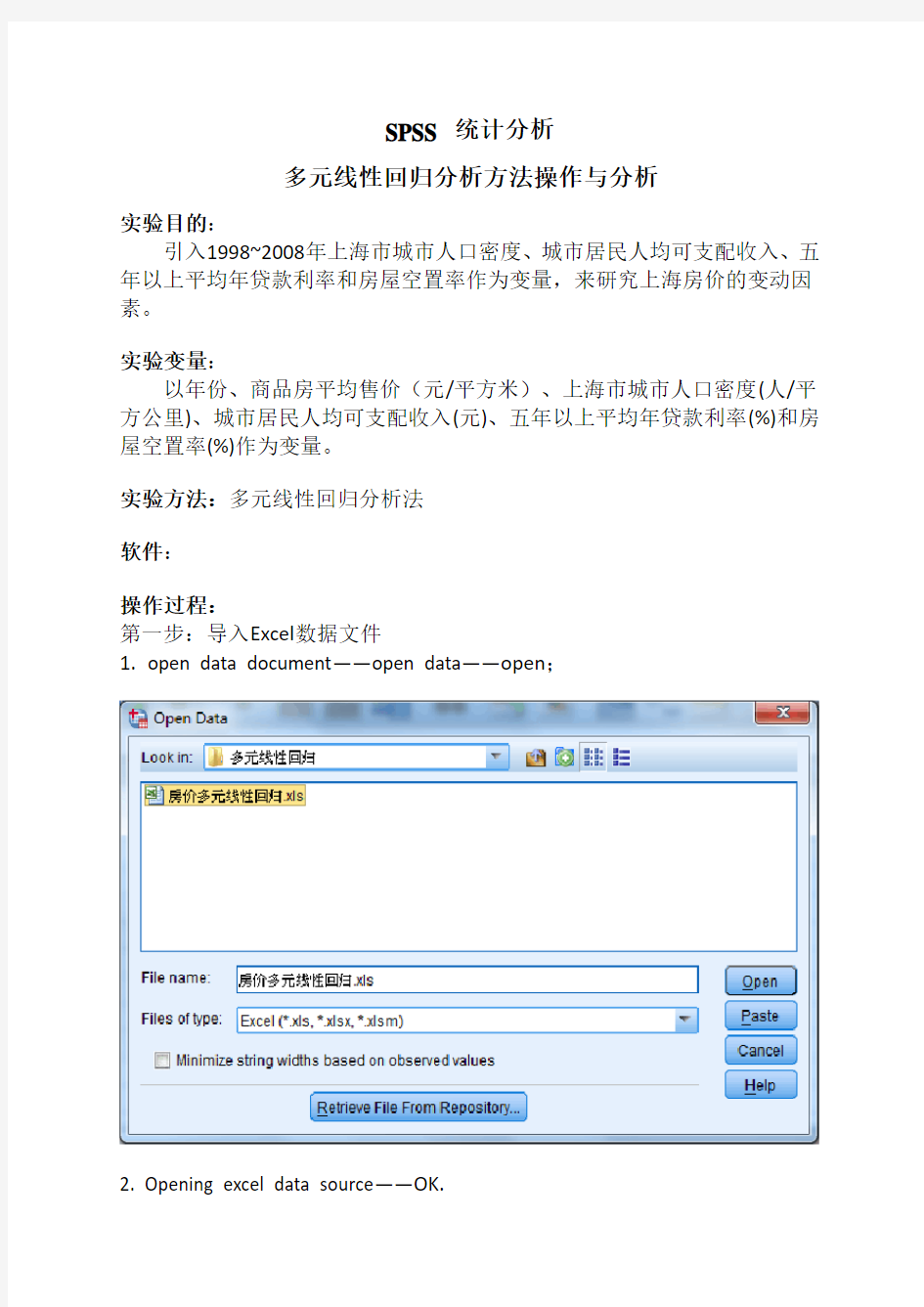
第一步:导入Excel数据文件
1.open data document——open data——open;
2. Opening excel data source——OK.
第二步:
1.在最上面菜单里面选中Analyze——Regression——Linear,Dependent(因变量)选择商品房平均售价,Independents(自变量)选择城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率、房屋空置率;Method 选择Stepwise.
进入如下界面:
2.点击右侧Statistics,勾选Regression Coefficients(回归系数)选项组中的Estimates;勾选Residuals(残差)选项组中的Durbin-Watson、Casewise diagnostics默认;接着选择Model fit、Collinearity diagnotics;点击Continue.
3.点击右侧Plots,选择*ZPRED(标准化预测值)作为纵轴变量,选择DEPENDNT(因变量)作为横轴变量;勾选选项组中的Standardized Residual Plots(标准化残差图)中的Histogram、Normal probability plot;点击Continue.
4.点击右侧Save,勾选Predicted Vaniues(预测值)和Residuals(残差)选项组中的Unstandardized;点击Continue.
5.点击右侧Options,默认,点击Continue.
6.返回主对话框,单击OK.
输出结果分析:
1.引入/剔除变量表
Variables Entered/Removed a
Model Variables Entered Variables Removed Method
1城市人口密度(人/平方公里).Stepwise (Criteria:
Probability-of-F-to-enter
<= .050,
Probability-of-F-to-remove >= .1
00).
2城市居民人均可支配收入(元).Stepwise (Criteria:
Probability-of-F-to-enter
<= .050,
Probability-of-F-to-remove >= .1
00).
a. Dependent Variable: 商品房平均售价(元/平方米)
该表显示模型最先引入变量城市人口密度(人/平方公里),第二个引入模型的是变量城市居民人均可支配收入(元),没有变量被剔除。
2.模型汇总
该表显示模型的拟合情况。从表中可以看出,模型的复相关系数(R)为,判定系数(R Square)为,调整判定系数(Adjusted R Square)为,估计值的标准误差(Std. Error of the Estimate)为,Durbin-Watson检验统计量为,当DW≈2时说明残差独立。
3.方差分析表
ANOVA c
Model Sum of Squares df Mean Square F Sig.
1Regression.5061.506.000a Residual9
Total.54510
2Regression.5282.264.000b Residual8
Total.54510
a. Predictors: (Constant), 城市人口密度(人/平方公里)
b. Predictors: (Constant), 城市人口密度(人/平方公里), 城市居民人均可支配收入(元)
c. Dependent Variable: 商品房平均售价(元/平方米)
该表为多元线性回归的系数列表。表中显示了模型的偏回归系数(B)、标准误差(Std. Error)、常数(Constant)、标准化偏回归系数(Beta)、回归系数检验的t统计量观测值和相应的概率p值(Sig.)、共线性统计量显示了变量的容差(Tolerance)和方差膨胀因子(VIF)。
令x1表示城市人口密度(人/平方公里),x2表示城市居民人均可支配收入(元),根据模型建立的多元多元线性回归方程为:
y=+ x1 +
方程中的常数项为,偏回归系数b1为,b2为,经T检验,b1和b2
的概率p值分别为和,按照给定的显着性水平的情形下,均有显着性意义。
根据容差发现,自变量间共线性问题严重;VIF值为,也可以说明共线性较明显。这可能是由于样本容量太小造成的。
5.模型外的变量
6. 共线性诊断
该表是多重共线性检验的特征值以及条件指数。对于第二个模型,最大特征值为,其余依次快速减小。第三列的各个条件指数,可以看出有多重共线性。 7. 残差统计量
该表为回归模型的残差统计量,标准化残差(Std. Residual )的绝对值最大为,没有超过默认值3,不能发现奇异值。
Collinearity Diagnostics a
Model Dimension Eigenvalue
Condition Index
Variance Proportions
(Constant)
城市人口密度 (人/平方公里)
城市居民人均可
支配收入(元)
1
1 .05 .05 2
.102
.95 .95
2
1 .00 .00 .00
2 .106 .21 .0
3 .00 3
.003
.78
.97
a. Dependent Variable: 商品房平均售价(元/平方米)
Residuals Statistics a
Minimum
Maximum
Mean
Std. Deviation
N
Predicted Value
11
Residual .000 11
Std. Predicted Value .000 11
Std. Residual .000 .894 11
a. Dependent Variable: 商品房平均售价(元/平方米)
该图为回归标准化残差的直方图,正态曲线也被显示在直方图上,用以判断标准化残差是否呈正态分布。但是由于样本数只有11个,所以只能大概判断其呈正态分布。
9.回归标准化的正态P-P图
10.因变量与回归标准化预测值的散点图
附件:
原始数据:
自变量散点图:
由散点图可以看出,可进入分析的变量为城市人口密度、城市居民人均可支配收入。
SPSS线性回归分析案例
回归分析 实验内容:基于居民消费性支出与居民可支配收入的简单线性回归分析 【研究目的】 居民消费在社会经济的持续发展中有着重要的作用。影响各地区居民消费支出的因素很多,例如居民的收入水平、商品价格水平、收入分配状况、消费者偏好、家庭财产状况、消费信贷状况、消费者年龄构成、社会保障制度、风俗习惯等等。为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的经济模型去研究。 【模型设定】 我们研究的对象是各地区居民消费的差异。由于各地区的城市与农村人口比例及经济结构有较大差异,现选用城镇居民消费进行比较。模型中被解释变量Y选定为“城市居民每人每年的平均消费支出”。从理论和经验分析,影响居民消费水平的最主要因素是居民的可支配收入,故可以选用“城市居民每人每年可支配收入”作为解释变量X,选取2010年截面数据。 1、实验数据 表1: 2010年中国各地区城市居民人均年消费支出和可支配收入
2、实验过程 作城市居民家庭平均每人每年消费支出(Y)和城市居民人均年可支配收入(X)的散点图,如图1:
表2 模型汇总b 表3 相关性 从散点图可以看出居民家庭平均每人每年消费支出(Y)和城市居民人均年可支配收入(X)大体呈现为线性关系,所以建立如下线性模型:Y=a+bX
表4 系数a 3、结果分析 表2模型汇总:相关系数为0.965,判定系数为0.932,调整判定系数为0.930,估计值的标准误877.29128 表3是相关分析结果。消费性支出Y与可支配收入X相关系数为0.965,相关性很高。 表4是回归分析中的系数:常数项b=704.824,可支配收入X的回归系数a=0.668。a的标准误差为0.034,回归系数t的检验值为19.921,P值为0,满足95%的置信区间,可认为回归系数有显著意义。得线性回归方程Y=0.668X+704.824. 【实验结论】 (1)结果显示,变量之间具有如下关系式:Y=0.668X+704.824.也就是说消费与收入之间存在稳定的函数关系。随着收入的增加,消费将增加,但消费的增长低于收入的增长。这与凯尔斯的绝对收入消费理论刚好吻合。但为了研究方便,这里假设边际消费倾向为常数。由公式知X每增长1个单位,Y增加0.668个单位。
spss多元回归分析报告案例
企业管理 对居民消费率影响因素的探究 ---以湖北省为例 改革开放以来,我国经济始终保持着高速增长的趋势,三十多年间综合国力得到显著增强,但我国居民消费率一直偏低,甚至一直有下降的趋势。居民消费率的偏低必然会导致我国内需的不足,进而会影响我国经济的长期健康发展。 本模型以湖北省1995年-2010年数据为例,探究各因素对居民消费率的影响及多元关系。(注:计算我国居民的消费率,用居民的人均消费除以人均GDP,得到居民的消费率)。通常来说,影响居民消费率的因素是多方面的,如:居民总 收入,人均GDP,人口结构状况1(儿童抚养系数,老年抚养系数),居民消费价格指数增长率等因素。 1.人口年龄结构一种比较精准的描述是:儿童抚养系数(0-14岁人口与 15-64岁人口的比值)、老年抚养系数(65岁及以上人口与15-64岁人口的比值〉或总抚养系数(儿童和老年抚养系数之和)。0-14岁人口比例与65岁及以上人口比例可由《湖北省统计年鉴》查得。
一、计量经济模型分析 (一)、数据搜集 根据以上分析,本模型在影响居民消费率因素中引入6个解释变量。X1:居民总收入(亿元),X2:人口增长率(‰),X3:居民消费价格指数增长率,X4:少儿抚养系数,X5:老年抚养系数,X6:居民消费占收入比重(%)。 Y:消费率(%)X1:总收入 (亿元) X2:人口增 长率(‰) X3:居民消 费价格指 数增长率 X4:少儿抚 养系数 X5:老年抚 养系数 X6:居民消 费比重(%) 1995 1997 200039 2001 2002 2003 2004 2005 2006 2007 2008 2009
实验六用spss进行非线性回归分析
实验六用SPSS进行非线性回归分析 例:通过对比12个同类企业的月产量(万台)与单位成本(元)的资料(如图1),试配合适当的回归模型分析月产量与单位成本之间的关系
图1原始数据和散点图分析 一、散点图分析和初始模型选择 在SPSS数据窗口中输入数据,然后插入散点图(选择Graphs→Scatter命令),由散点图可以看出,该数据配合线性模型、指数模型、对数模型和幂函数模型都比较合适。进一步进行曲线估计:从Statistic下选Regression菜单中的Curve Estimation命令;选因变量单位成本到Dependent框中,自变量月产量到Independent框中,在Models框中选择Linear、Logarithmic、Power和Exponential四个复选框,确定后输出分析结果,见表1。 分析各模型的R平方,选择指数模型较好,其初始模型为 但考虑到在线性变换过程可能会使原模型失去残差平方和最小的意义,因此进一步对原模型进行优化。 模型汇总和参数估计值 因变量: 单位成本 方程模型汇总参数估计值 R 方 F df1 df2 Sig. 常数b1 线性.912 1 10 .000 对数.943 1 10 .000 幂.931 1 10 .000 指数.955 1 10 .000 自变量为月产量。 表1曲线估计输出结果
二、非线性模型的优化 SPSS提供了非线性回归分析工具,可以对非线性模型进行优化,使其残差平方和达到最小。从Statistic下选Regression菜单中的Nonlinear命令;按Paramaters按钮,输入参数A:和B:;选单位成本到Dependent框中,在模型表达式框中输入“A*EXP(B*月产量)”,确定。SPSS输出结果见表2。 由输出结果可以看出,经过6次模型迭代过程,残差平方和已有了较大改善,缩小为,误差率小于, 优化后的模型为: 迭代历史记录b 迭代数a残差平方和参数 A B +133 .087 导数是通过数字计算的。 a. 主迭代数在小数左侧显示,次迭代数在小数右侧显 示。 b. 由于连续残差平方和之间的相对减少量最多为 SSCON = ,因此在 22 模型评估和 10 导数评估之后, 系统停止运行。
spss中多元回归分析实例
SPSS中多元回归分析实例在大多数的实际问题中,影响因变量的因素不是一个而是多个,我们称这类回问题为多元回归分析。可以建立因变量y与各自变量xj(j=1,2,3,…,n)之间的多元线性回归模型: Y=b+bx+bx+...+bx+e k210k12其中:b0是回归常数;bk(k=1,2,3,…,n)是回归参数;e是随机误差。 多元回归在病虫预报中的应用实例: 某地区病虫测报站用相关系数法选取了以下4个预报因子;x1为最多连续10天诱蛾量(头);x2为4月上、中旬百束小谷草把累计落卵量(块);x3为4月中旬降水量(毫米),x4为4月中旬雨日(天);预报一代粘虫幼虫发生量y(头/m2)。分级别数值列成表2-1。 预报量y:每平方米幼虫0~10头为1级,11~20头为2级,21~40头为3级,40头以上为4级。预报因子:x1诱蛾量0~300头为l级,301~600头为2级,601~1000头为3级,1000头以上为4级;x2卵量0~150块为1级,15l~300块为2级,301~550块为3级,550块以上为4级;x3降水量0~10.0毫米为1级,10.1~13.2毫米为2级,13.3~17.0毫米为3级,17.0毫米以上为4级; x4雨日0~2天为1级,3~4天为2级,5天为3级,6天或6天以上为4级。
数据保存在“DATA6-5.SA V”文件中。 1)准备分析数据 在SPSS数据编辑窗口中,创建“年份”、“蛾量”、“卵量”、“降水量”、“雨日”和“幼虫密度”变量,并输入数据。再创建蛾量、卵量、降水量、雨日和幼虫密度的分级变量“x1”、“x2”、“x3”、“x4”和“y”,它们对应的分级数值可以在SPSS数据编辑窗口中通过计算产生。编辑后的数据显示如图2-1。
SPSS 统计分析多元线性回归分析方法操作与及分析
SPSS 统计分析 多元线性回归分析方法操作与及分析 实验目的: 引入1998~2008年上海市城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率和房屋空置率作为变量,来研究上海房价的变动因素。 实验变量: 以年份、商品房平均售价(元/平方米)、上海市城市人口密度(人/平方公里)、城市居民人均可支配收入(元)、五年以上平均年贷款利率(%)和房屋空置率(%)作为变量。 实验方法:多元线性回归分析法 软件:spss19.0 操作过程: 第一步:导入Excel数据文件 1.open data document——open data——open;
2. Opening excel data source——OK. 第二步: 1.在最上面菜单里面选中Analyze——Regression——Linear ,Dependent(因变量)选择商品房平均售价,Independents(自变量)选择城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率、房屋空置率;Method选择Stepwise. 进入如下界面:
2.点击右侧Statistics,勾选Regression Coefficients(回归系数)选项组中的Estimates;勾选Residuals(残差)选项组中的 Durbin-Watson、Casewise diagnostics默认;接着选择Model fit、Collinearity diagnotics;点击Continue.
3.点击右侧Plots,选择*ZPRED(标准化预测值)作为纵轴变量,选择DEPENDNT(因变量)作为横轴变量;勾选选项组中的Standardized Residual Plots(标准化残差图)中的Histogram、Normal probability plot;点击Continue. 4.点击右侧Save,勾选Predicted Vaniues(预测值)和Residuals (残差)选项组中的Unstandardized;点击Continue.
多元线性回归实例分析
SPSS--回归-多元线性回归模型案例解析!(一) 多元线性回归,主要是研究一个因变量与多个自变量之间的相关关系,跟一元回归原理差不多,区别在于影响因素(自变量)更多些而已,例如:一元线性回归方程为: 毫无疑问,多元线性回归方程应该为: 上图中的x1, x2, xp分别代表“自变量”Xp截止,代表有P个自变量,如果有“N组样本,那么这个多元线性回归,将会组成一个矩阵,如下图所示: 那么,多元线性回归方程矩阵形式为: 其中:代表随机误差,其中随机误差分为:可解释的误差和不可解释的误差,随机误差必须满足以下四个条件,多元线性方程才有意义(一元线性方程也一样) 1:服成正太分布,即指:随机误差必须是服成正太分别的随机变量。 2:无偏性假设,即指:期望值为0 3:同共方差性假设,即指,所有的随机误差变量方差都相等 4:独立性假设,即指:所有的随机误差变量都相互独立,可以用协方差解释。 今天跟大家一起讨论一下,SPSS---多元线性回归的具体操作过程,下面以教程教程数据为例,分析汽车特征与汽车销售量之间的关系。通过分析汽车特征跟汽车销售量的关系,建立拟合多元线性回归模型。数据如下图所示:
点击“分析”——回归——线性——进入如下图所示的界面:
将“销售量”作为“因变量”拖入因变量框内,将“车长,车宽,耗油率,车净重等10个自变量拖入自变量框内,如上图所示,在“方法”旁边,选择“逐步”,当然,你也可以选择其它的方式,如果你选择“进入”默认的方式,在分析结果中,将会得到如下图所示的结果:(所有的自变量,都会强行进入) 如果你选择“逐步”这个方法,将会得到如下图所示的结果:(将会根据预先设定的“F统计量的概率值进行筛选,最先进入回归方程的“自变量”应该是跟“因变量”关系最为密切,贡献最大的,如下图可以看出,车的价格和车轴跟因变量关系最为密切,符合判断条件的概率值必须小于0.05,当概率值大于等于0.1时将会被剔除)
spss多元线性回归分析92134
SPSS多元线性回归分析试验 在科学研究中,我们会发现某些指标通常受到多个因素的影响,如血压值除了受年龄影响之外,还受到性别、体重、饮食习惯、吸烟情况等因素的影响,用方程定量描述一个因变量y与多个自变量x1、x2、x3.......之间的线性依存关系,称为多元线性回归。 有学者认为血清中低密度脂蛋白增高是引起动脉硬化的一个重要原因。现测量30名怀疑患有动脉硬化的就诊患者的载脂蛋白A、载脂蛋白B、载脂蛋白E、载脂蛋白C、低密度脂蛋白中的胆固醇含量。资料如下表所示。求低密度脂蛋白中的胆固醇含量对载脂蛋白A、载脂蛋白B、载脂蛋白E、载脂蛋白C的线性回归方程。 表1 30名就诊患者资料表
221101499.524.7184 2316086 5.310.8118 241121238.016.6127 251471108.518.4137 26204122 6.121.0126 27131102 6.613.4130 281701278.424.7135 291731238.719.0188 3013213113.829.2122 spss数据处理步骤: (1)打开spss输入数据后,点击“分析”-“回归”-“线性”。然后将“低密度脂蛋白”选入因变量框,将“载脂蛋白A”“载脂蛋白B”“载脂蛋白E”“载脂蛋白C”依次选入自变量框。方法选为“逐步”。 (2)单击“统计量”选项,原有选项基础上选择“R方变化”。在残差中选“Durbin-Watson”,单击“继续”。
(3)单击“绘制”,将“DEPENDNT”选入“X2”中,将“*SRESID”选入“Y”中,在标准残差图选项中选择“直方图”和“正态概率图”。单击“继续”。 (4)单击“选项”,在原有选项的基础上单击“继续”,最后单击“确定”,就完
SPSS多元回归分析报告实例
多元回归分析 在大多数的实际问题中,影响因变量的因素不是一个而是多个,我们称这类回问题为多元回归分析。可以建立因变量y与各自变量x j(j=1,2,3,…,n)之间的多元线性回归模型: 其中:b0是回归常数;b k(k=1,2,3,…,n)是回归参数;e是随机误差。 多元回归在病虫预报中的应用实例: 某地区病虫测报站用相关系数法选取了以下4个预报因子;x1为最多连续10天诱蛾量(头);x2为4月上、中旬百束小谷草把累计落卵量(块);x3为4月中旬降水量(毫米),x4为4月中旬雨日(天);预报一代粘虫幼虫发生量y(头/m2)。分级别数值列成表2-1。 预报量y:每平方米幼虫0~10头为1级,11~20头为2级,21~40头为3级,40头以上为4级。 预报因子:x1诱蛾量0~300头为l级,301~600头为2级,601~1000头为3级,1000头以上为4级;x2卵量0~150块为1级,15l~300块为2级,301~550块为3级,550块以上为4级;x3降水量0~10.0毫米为1级,10.1~13.2毫米为2级,13.3~17.0毫米为3级,17.0毫米以上为4级;x4雨日0~2天为1级,3~4天为2级,5天为3级,6天或6天以上为4级。 表2-1 x1 x2 x3 x4 y 年蛾量级别卵量级别降水量级别雨日级别幼虫密 度 级别 1960 1022 4 112 1 4.3 1 2 1 10 1 1961 300 1 440 3 0.1 1 1 1 4 1 1962 699 3 67 1 7.5 1 1 1 9 1 1963 1876 4 675 4 17.1 4 7 4 55 4 1965 43 1 80 1 1.9 1 2 1 1 1 1966 422 2 20 1 0 1 0 1 3 1 1967 806 3 510 3 11.8 2 3 2 28 3
多元线性回归实例分析报告
SPSS--回归-多元线性回归模型案例解析!(一) 多元线性回归,主要就是研究一个因变量与多个自变量之间的相关关系,跟一元回归原理差不多,区别在于影响因素(自变量)更多些而已,例如:一元线性回归方程 为: 毫无疑问,多元线性回归方程应该 为: 上图中的 x1, x2, xp分别代表“自变量”Xp截止,代表有P个自变量,如果有“N组样本,那么这个多元线性回归,将会组成一个矩阵,如下图所示: 那么,多元线性回归方程矩阵形式为: 其中:代表随机误差, 其中随机误差分为:可解释的误差与不可解释的误差,随机误差必须满足以下四个条件,多元线性方程才有意义(一元线性方程也一样) 1:服成正太分布,即指:随机误差必须就是服成正太分别的随机变量。 2:无偏性假设,即指:期望值为0 3:同共方差性假设,即指,所有的随机误差变量方差都相等 4:独立性假设,即指:所有的随机误差变量都相互独立,可以用协方差解释。 今天跟大家一起讨论一下,SPSS---多元线性回归的具体操作过程,下面以教程教程数据为例,分析汽车特征与汽车销售量之间的关系。通过分析汽车特征跟汽车销售量的关系,建立拟合多元线性回归模型。数据如下图所示:
点击“分析”——回归——线性——进入如下图所示的界面:
将“销售量”作为“因变量”拖入因变量框内, 将“车长,车宽,耗油率,车净重等10个自变量拖入自变量框内,如上图所示,在“方法”旁边,选择“逐步”,当然,您也可以选择其它的方式,如果您选择“进入”默认的方式,在分析结果中,将会得到如下图所示的结果:(所有的自变量,都会强行进入) 如果您选择“逐步”这个方法,将会得到如下图所示的结果:(将会根据预先设定的“F统计量的概率值进行筛选,最先进入回归方程的“自变量”应该就是跟“因变量”关系最为密切,
相关分析和一元线性回归分析SPSS报告
用下面的数据做相关分析和一元线性回归分析: 选用普通高等学校毕业生数和高等学校发表科技论文数量做相关分析和一元线性回归分析。 一、相关分析 1.作散点图
普通高等学校毕业生数和高等学校发表科技论文数量的相关图 从散点图可以看出:普通高等学校毕业生数和高等学校发表科技论文数量的相关性很大。 2.求普通高等学校毕业生数和高等学校发表科技论文数量的相关系 数
把要求的两个相关变量移至变量中,因为都是定距数据,选择相关系数中的Pearson,点击确定,可以得到下面的结果:
两相关变量的Pearson相关系数=0.0998,表示呈高度正相关;相关系数检验对应的概率P值=0.000,小于显著性水平0.05,应拒绝原假设(两变量之间不具有相关性),即毕业生人数好发表科技论文数之间的相关性显著。 3.求两变量之间的相关性
选择相关系数中的全部,点击确定: Correlations (万人) (篇) Kendall's tau_b (万人) Correlation Coefficient 1.000 1.000** Sig. (2-tailed) . . N 14 14 (篇) Correlation Coefficient 1.000** 1.000 Sig. (2-tailed) . . N 14 14 Spearman's rho (万人) Correlation Coefficient 1.000 1.000** Sig. (2-tailed) . . N 14 14 (篇) Correlation Coefficient 1.000** 1.000 Sig. (2-tailed) . . N 14 14 **. Correlation is significant at the 0.01 level (2-tailed).
SPSS—非线性回归(模型表达式)案例解析
SPSS—非线性回归(模型表达式)案例解析 2011-11-16 10:56 由简单到复杂,人生有下坡就必有上坡,有低潮就必有高潮的迭起,随着SPSS 的深入学习,已经逐渐开始走向复杂,今天跟大家交流一下,SPSS非线性回归,希望大家能够指点一二! 非线性回归过程是用来建立因变量与一组自变量之间的非线性关系,它不像线性模型那样有众多的假设条件,可以在自变量和因变量之间建立任何形式的模型非线性,能够通过变量转换成为线性模型——称之为本质线性模型,转换后的模型,用线性回归的方式处理转换后的模型,有的非线性模型并不能够通过变量转换为线性模型,我们称之为:本质非线性模型 还是以“销售量”和“广告费用”这个样本为例,进行研究,前面已经研究得出:“二次曲线模型”比“线性模型”能够更好的拟合“销售量随着广告费用的增加而呈现的趋势变化”,那么“二次曲线”会不会是最佳模型呢? 答案是否定的,因为“非线性模型”能够更好的拟合“销售量随着广告费用的增加而呈现的变化趋势” 下面我们开始研究: 第一步:非线性模型那么多,我们应该选择“哪一个模型呢?” 1:绘制图形,根据图形的变化趋势结合自己的经验判断,选择合适的模型 点击“图形”—图表构建程序—进入如下所示界面:
点击确定按钮,得到如下结果:
放眼望去, 图形的变化趋势,其实是一条曲线,这条曲线更倾向于"S" 型曲线,我们来验证一下,看“二次曲线”和“S曲线”相比,两者哪一个的拟合度更高! 点击“分析—回归—曲线估计——进入如下界面
在“模型”选项中,勾选”二次项“和”S"两个模型,点击确定,得到如下结果:
SPSS多元线性回归分析教程
线性回归分析的SPSS操作 本节内容主要介绍如何确定并建立线性回归方程。包括只有一个自变量的一元线性回归和和含有多个自变量的多元线性回归。为了确保所建立的回归方程符合线性标准,在进行回归分析之前,我们往往需要对因变量与自变量进行线性检验。也就是类似于相关分析一章中讲过的借助于散点图对变量间的关系进行粗略的线性检验,这里不再重复。另外,通过散点图还可以发现数据中的奇异值,对散点图中表示的可能的奇异值需要认真检查这一数据的合理性。 一、一元线性回归分析 1.数据 以本章第三节例3的数据为例,简单介绍利用SPSS如何进行一元线性回归分析。数据编辑窗口显示数据输入格式如下图7-8(文件7-6-1.sav): 图7-8:回归分析数据输入 2.用SPSS进行回归分析,实例操作如下: 2.1.回归方程的建立与检验 (1)操作 ①单击主菜单Analyze / Regression / Linear…,进入设置对话框如图7-9所示。从左边变量表列中把因变量y选入到因变量(Dependent)框中,把自变量x选入到自变量(Independent)框中。在方法即Method一项上请注意保持系统默认的选项Enter,选择该项表示要求系统在建立回归方程时把所选中的全部自变量都保留在方程中。所以该方法可命名为强制进入法(在多元回归分析中再具体介绍这一选项的应用)。具体如下图所示:
图7-9 线性回归分析主对话框 ②请单击Statistics…按钮,可以选择需要输出的一些统计量。如Regression Coefficients(回归系数)中的Estimates,可以输出回归系数及相关统计量,包括回归系数B、标准误、标准化回归系数BETA、T值及显著性水平等。Model fit项可输出相关系数R,测定系数R2,调整系数、估计标准误及方差分析表。上述两项为默认选项,请注意保持选中。设置如图7-10所示。设置完成后点击Continue返回主对话框。 图7-10:线性回归分析的Statistics选项图7-11:线性回归分析的Options选项 回归方程建立后,除了需要对方程的显著性进行检验外,还需要检验所建立的方程是否违反回归分析的假定,为此需进行多项残差分析。由于此部分内容较复杂而且理论性较强,所以不在此详细介绍,读者如有兴趣,可参阅有关资料。 ③用户在进行回归分析时,还可以选择是否输出方程常数。单击Options…按钮,打开它的对话框,可以看到中间有一项Include constant in equation可选项。选中该项可输出对常数的检验。在Options对话框中,还可以定义处理缺失值的方法和设置多元逐步回归中变量进入和排除方程的准则,这里我们采用系统的默认设置,如图7-11所示。设置完成后点击Continue返回主对话框。 ④在主对话框点击OK得到程序运行结果。
多元回归分析SPSS案例
多元回归分析 在大多数得实际问题中,影响因变量得因素不就就是一个而就就是多个,我们称这类回问题为多元回归分析。可以建立因变量y与各自变量x j(j=1,2,3,…,n)之间得多元线性回归模型: 其中:b0就就是回归常数;b k(k=1,2,3,…,n)就就是回归参数;e就就是随机误差。 多元回归在病虫预报中得应用实例: 某地区病虫测报站用相关系数法选取了以下4个预报因子;x1为最多连续10天诱蛾量(头);x2为4月上、中旬百束小谷草把累计落卵量(块);x3为4月中旬降水量(毫米),x4为4月中旬雨日(天);预报一代粘虫幼虫发生量y(头/m2)。分级别数值列成表2-1。 预报量y:每平方米幼虫0~10头为1级,11~20头为2级,21~40头为3级,40头以上为4级。 预报因子:x1诱蛾量0~300头为l级,301~600头为2级,601~1000头为3级,1000头以上为4级;x2卵量0~150块为1级,15l~300块为2级,301~550块为3级,550块以上为4级;x3降水量0~10、0毫米为1级,10、1~13、2毫米为2级,13、3~17、0毫米为3级,17、0毫米以上为4级;x4雨日0~2天为1级,3~4天为2级,5天为3级,6天或6天以上为4级。 表2-1
数据保存在“DATA6-5、SAV”文件中。 1)准备分析数据 在SPSS数据编辑窗口中,创建“年份”、“蛾量”、“卵量”、“降水量”、“雨日”与“幼虫密度”变量,并输入数据。再创建蛾量、卵量、降水量、雨日与幼虫密度得分级变量“x1”、“x2”、“x3”、“x4”与“y”,它们对应得分级数值可以在SPSS数据编辑窗口中通过计算产生。编辑后得数据显示如图2-1。 图2-1 或者打开已存在得数据文件“DATA6-5、SAV”。 2)启动线性回归过程 单击SPSS主菜单得“Analyze”下得“Regression”中“Linear”项,将打开如图2-2所示得线性回归过程窗口。
SPSS如何进行线性回归分析操作
SPSS如何进行线性回归分析操作 本节内容主要介绍如何确定并建立线性回归方程。包括只有一个自变量的一元线性回归和和含有多个自变量的多元线性回归。为了确保所建立的回归方程符合线性标准,在进行回归分析之前,我们往往需要对因变量与自变量进行线性检验。 也就是类似于相关分析一章中讲过的借助于散点图对变量间的关系进行粗略的线性检验,这里不再重复。另外,通过散点图还可以发现数据中的奇异值,对散点图中表示的可能的奇异值需要认真检查这一数据的合理性。 一、一元线性回归分析 用SPSS进行回归分析,实例操作如下: 单击主菜单Analyze / Regression / Linear…,进入设置对话框如图7-9所示。从左边变量表列中把因变量y选入到因变量(Dependent)框中,把自变量x选入到自变量(Independent)框中。在方法即Method 一项上请注意保持系统默认的选项Enter,选择该项表示要求系统在建立回归方程时把所选中的全部自变量都保留在方程中。所以该方法可命名为强制进入法(在多元回归分析中再具体介绍这一选项的应用)。 具体如下图所示: .
. 请单击Statistics…按钮,可以选择需要输出的一些统计量。如Regression Coefficients(回归系数)中的Estimates,可以输出回归系数及相关统计量,包括回归系数B、标准误、标准化回归系数BETA、T值及显著性水平等。Model fit项可输出相关系数R,测定系数R2,调整系数、估计标准误及方差分析表。上述两项为默认选项,请注意保持选中。设置如图7-10所示。设置完成后点击Continue返回主对话框。 . .
线性回归分析的SPSS操作
第六节线性回归分析的SPSS操作 本节内容主要介绍如何确定并建立线性回归方程。包括只有一个自变量的一元线性回归和和含有多个自变量的多元线性回归。为了确保所建立的回归方程符合线性标准,在进行回归分析之前,我们往往需要对因变量与自变量进行线性检验。也就是类似于相关分析一章中讲过的借助于散点图对变量间的关系进行粗略的线性检验,这里不再重复。另外,通过散点图还可以发现数据中的奇异值,对散点图中表示的可能的奇异值需要认真检查这一数据的合理性。 一、一元线性回归分析 1.数据 以本章第三节例3的数据为例,简单介绍利用SPSS如何进行一元线性回归分析。数据编辑窗口显示数据输入格式如下图7-8(文件7-6-1.sav): 图7-8:回归分析数据输入 2.用SPSS进行回归分析,实例操作如下: 2.1.回归方程的建立与检验 (1)操作 ①单击主菜单Analyze / Regression / Linear…,进入设置对话框如图7-9所示。从左边变量表列中把因变量y选入到因变量(Dependent)框中,把自变量x选入到自变量(Independent)框中。在方法即Method一项上请注意保持系统默认的选项Enter,选择该项表示要求系统在建立回归方程时把所选中的全部自变量都保留在方程中。所以该方法可命名为强制进入法(在多元回归分析中再具体介绍这一选项的应用)。具体如下图所示:
图7-9 线性回归分析主对话框 ②请单击Statistics…按钮,可以选择需要输出的一些统计量。如Regression Coefficients(回归系数)中的Estimates,可以输出回归系数及相关统计量,包括回归系数B、标准误、标准化回归系数BETA、T值及显著性水平等。Model fit 项可输出相关系数R,测定系数R2,调整系数、估计标准误及方差分析表。上述两项为默认选项,请注意保持选中。设置如图7-10所示。设置完成后点击Continue返回主对话框。 图7-10:线性回归分析的Statistics选项图7-11:线性回归分析的Options选项 回归方程建立后,除了需要对方程的显著性进行检验外,还需要检验所建立的方程是否违反回归分析的假定,为此需进行多项残差分析。由于此部分内容较复杂而且理论性较强,所以不在此详细介绍,读者如有兴趣,可参阅有关资料。 ③用户在进行回归分析时,还可以选择是否输出方程常数。单击Options…按钮,打开它的对话框,可以看到中间有一项Include constant in equation可选项。选中该项可输出对常数的检验。在Options对话框中,还可以定义处理缺失值的方法和设置多元逐步回归中变量进入和排除方程的准则,这里我们采用系统的默认设置,如图7-11所示。设置完成后点击Continue返回主对话框。
(推荐下载)SPSS线性回归分析案例
(完整word版)SPSS线性回归分析案例 编辑整理: 尊敬的读者朋友们: 这里是精品文档编辑中心,本文档内容是由我和我的同事精心编辑整理后发布的,发布之前我们对文中内容进行仔细校对,但是难免会有疏漏的地方,但是任然希望((完整word版)SPSS线性回归分析案例)的内容能够给您的工作和学习带来便利。同时也真诚的希望收到您的建议和反馈,这将是我们进步的源泉,前进的动力。 本文可编辑可修改,如果觉得对您有帮助请收藏以便随时查阅,最后祝您生活愉快业绩进步,以下为(完整word版)SPSS线性回归分析案例的全部内容。
回归分析 实验内容:基于居民消费性支出与居民可支配收入的简单线性回归 分析 【研究目的】 居民消费在社会经济的持续发展中有着重要的作用。影响各地区居民消费支出的因素很多,例如居民的收入水平、商品价格水平、收入分配状况、消费者偏好、家庭财产状况、消费信贷状况、消费者年龄构成、社会保障制度、风俗习惯等等.为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的经济模型去研究。 【模型设定】 我们研究的对象是各地区居民消费的差异。由于各地区的城市与农村人口比例及经济结构有较大差异,现选用城镇居民消费进行比较。模型中被解释变量Y选定为“城市居民每人每年的平均消费支出”。从理论和经验分析,影响居民消费水平的最主要因素是居民的可支配收入,故可以选用“城市居民每人每年可支配收入”作为解释变量X,选取2010年截面数据。 1、实验数据 表1:
2、实验过程 作城市居民家庭平均每人每年消费支出(Y)和城市居民人均年可支配收入(X)的散点图,如图1:
spss实验报告线性回归曲线估计
《数据分析实务与案例实验报告》 曲线估计 学号:204 班级:2013 应用统计 姓名: ____________________ 日期:2 0 1 4 - 12 - 7 数学与统计学学院 一、实验目的
1.准确理解曲线回归分析的方法原理。 2.了解如何将本质线性关系模型转化为线性关系模型进行回归分析。 3.熟练掌握曲线估计的SPSS操作。 4.掌握建立合适曲线模型的判断依据。 5.掌握如何利用曲线回归方程进行预测。 6.培养运用多曲线估计解决身边实际问题的能力。 二、准备知识 1.非线性模型的基本内容 变量之间的非线性关系可以划分为本质线性关系和本质非线性关系。所谓本质线性关系是指变量关系形式上虽然呈非线性关系,但可以通过变量转化为线性关系,并可最终进行线性回归分析,建立线性模型。本质非线性关系是指变量之间不仅形式上呈现非线性关系,而且也无法通过变量转化为线性关系,最终无法进行线性回归分析,建立线性模型。本实验针对本质线性模型进行。下面介绍本次实验涉及到的可线性化的非线性模型,所用的变换既有自变量的变换,也有因变量的变换。 乘法模型: y x1 x2 x3 其中,,,都是未知参数,是乘积随机误差。对上式两边取自然对数得到 ln y ln ln x1 ln x 2 ln x3 ln 上式具有一般线性回归方程的形式,因而用多元线性回归的方法来处理。然而,必须强调指出的是,在求置信区间和做有关试验时,必须是 ln : N(0, 2I n) ,而不是 : N(0,2I n), 因此检验之前,要先检验ln 是否满足这个假设。 三、实验内容 已有很多学者验证了能源消费与经济增长的因果关系,证明了能源消费是促进经济增长的原因之一。也有众多学者利用C-D生产函数验证了劳动和资本对经济增长的影响机理。所有这些研究都极少将劳动、资本、和能源建立在一个模型中来研究三个因素对经济增长的作用方向和作用大小。
多元线性回归分析案例
SPSS19.0实战之多元线性回归分析 (2011-12-09 12:19:11) 转载▼ 分类:软件介绍 标签: 文化 线性回归数据(全国各地区能源消耗量与产量)来源,可点击协会博客数据挖掘栏:国泰安数据服务中心的经济研究数据库。 1.1 数据预处理 数据预处理包括的内容非常广泛,包括数据清理和描述性数据汇总,数据集成和变换,数据归约,数据离散化等。本次实习主要涉及的数据预处理只包括数据清理和描述性数据汇总。一般意义的数据预处理包括缺失值填写和噪声数据的处理。于此我们只对数据做缺失值填充,但是依然将其统称数据清理。 1.1.1 数据导入与定义 单击“打开数据文档”,将xls格式的全国各地区能源消耗量与产量的数据导入SPSS中,如图1-1所示。 图1-1 导入数据 导入过程中,各个字段的值都被转化为字符串型(String),我们需要手动将相应的字段转回数值型。单击菜单栏的“ ”-->“ ”将所选的变量改为数值型。如图1-2所示:
图1-2 定义变量数据类型 1.1.2 数据清理 数据清理包括缺失值的填写和还需要使用SPSS分析工具来检查各个变量的数据完整性。单击“ ”-->“ ”,将检查所输入的数据的缺失值个数以及百分比等。如图1-3所示: 图1-3缺失值分析
表1-1 能源消耗量与产量数据缺失值分析 SPSS提供了填充缺失值的工具,点击菜单栏“ ”-->“ ”,即可以使用软件提供的几种填充缺失值工具,包括序列均值,临近点中值,临近点中位数等。结合本次实习数据的具体情况,我们不使用SPSS软件提供的替换缺失值工具,主要是手动将缺失值用零值来代替。 1.1.3 描述性数据汇总 描述性数据汇总技术用来获得数据的典型性质,我们关心数据的中心趋势和离中趋势,根据这些统计值,可以初步得到数据的噪声和离群点。中心趋势的量度值包括:均值(mean),中位数(median),众数(mode)等。离中趋势量度包括四分位数(quartiles),方差(variance)等。 SPSS提供了详尽的数据描述工具,单击菜单栏的“ ”-->“ ”-->“ ”,将弹出如图2-4所示的对话框,我们将所有变量都选取到,然后在选项中勾选上所希望描述的数据特征,包括均值,标准差,方差,最大最小值等。由于本次数据的单位不尽相同,我们需要将数据标准化,同时勾选上“将标准化得分另存为变量”。
基于SPSS多元线性回归分析的案例
农民收入影响因素的多元回归分析 自改革开放以来,虽然中国经济平均增长速度为9.5 % ,但二元经济结构给经济发展带来的问题仍然很突出。农村人口占了中国总人口的70 %多,农业产业结构不合理,经济不发达,以及农民收入增长缓慢等问题势必成为我国经济持续稳定增长的障碍。正确有效地解决好“三农”问题是中国经济走出困境,实现长期稳定增长的关键。其中,农民收入增长是核心,也是解决“三农”问题的关键。本文力图应用适当的多元线性回归模型,对有关农民收入的历史数据和现状进行分析,寻找其根源,探讨影响农民收入的主要因素,并在此基础上对如何增加农民收入提出相应的政策建议。 一、回归模型的建立 (1)数据的收集 根据实际的调查分析,我们在影响农民收入因素中引入3个解释变量。即:X2-财政用于农业的支出的比重, X3-乡村从业人员占农村人口的比重, X4-农作物播种面积
(1)回归模型的构建 Y i=1+2X2+3X3+4X4+u i 二、回归模型的分析 (1)多重共线性检验 (2)模型异方差的检验 异方差产生的原因有:数据质量原因、模型设定原因。由异方差引起的后果一般会导致回归系数估计结果误差较大、有关统计检验失去意义、模型的预测失效等危害,所以在建立模型的过程中必须要检验模型之间是否存在异方差。若存在异方差解决办法——加权最小二乘法。
从上表散点图判断模型的解释变量之间是否存在异方差,但从上表可以看到散点图之间的特征不是特别明显。不易于做出结论,故采用|e|与X的等级相关系数进行判定。 表2 从表2可知,在95%的置信水平下,检验统计量与为标准化残差的绝对值(|e|)之间的显著性水平P值均大于0.05,则接受原假设,检验统计量与|e|之间是独立的,不存在相关关系。说明模型不存在异方差。 (3)模型序列相关的检验 序列相关是指各随机误差项之间不独立,则称其存在自相关或序列相关性。 自相关产生的原因有:经济变量的惯性、省略解释变量的影响、错误的函数形式
- SPSS多元线性回归分析实例操作步骤
- spss多元回归分析案例
- SPSS多元线性回归分析报告实例操作步骤
- SPSS多元回归分析实例
- SPSS多元线性回归分析实例操作步骤
- 多元线性回归实例分析
- SPSS—非线性回归(模型表达式)案例解析
- SPSS多元回归分析实例教程
- SPSS多元线性回归分析实例操作步骤
- SPSS线性回归分析案例
- SPSS多元回归分析报告实例
- SPSS多元线性回归分析实例操作步骤
- spss实验报告线性回归曲线估计
- spss多元回归分析报告案例
- 基于SPSS多元线性回归分析的案例
- SPSS实现一元线性回归分析实例(整理
- SPSS多元回归分析实例
- SPSS多元线性回归分析实例操作步骤
- 多元回归分析SPSS案例
- spss中多元回归分析实例