两组之间性别组成有无差异,做卡方检验
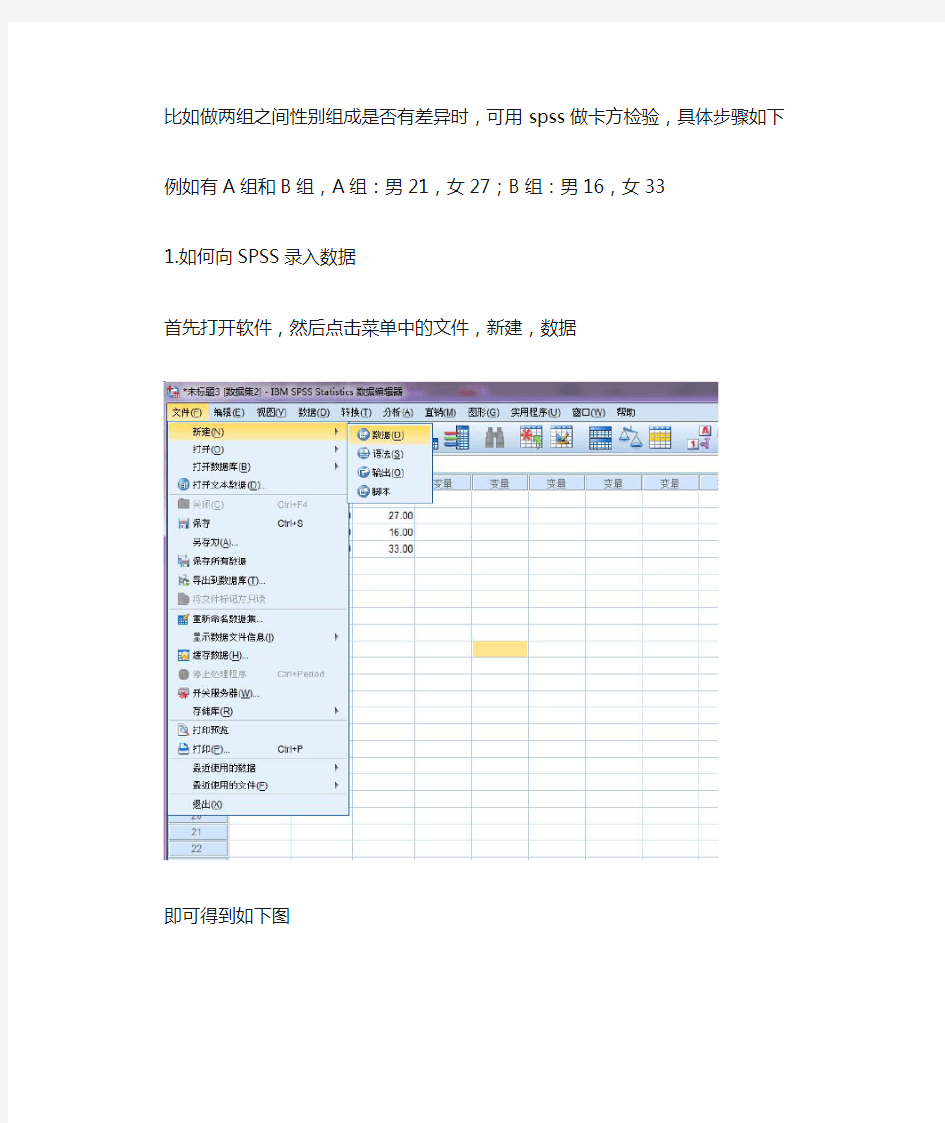
比如做两组之间性别组成是否有差异时,可用spss做卡方检验,具体步骤如下例如有A组和B组,A组:男21,女27;B组:男16,女33
1.如何向SPSS录入数据
首先打开软件,然后点击菜单中的文件,新建,数据
即可得到如下图
2、录入数据
点击spss下方的变量视图按钮
然后在名称下方第一个格子中输入组别名称下方第二个格子中输入性别
名称下方第三个格子中输入人数
如下图所示,其它数字什么的是自动生成的
3、然后在标签那一栏相对应的同样输入组别,性别和人数
如下图所示
4、点击值那一栏的数,第一个格子写有无,并且旁边有个小按钮,点击一下,即可编辑组别的属性
比如组别是A 和B组,则就在值标签中,值输入1,标签中输入A,然后点击添加,同样值输入2,标签输入B,点击添加,就做好了组别的输入,如下图所示
同样方法对性别也进行如此编辑,值输入1,标签为男,添加;然后值输入2,标签为女,添加这样就完成了组别和性别的编辑
5、点击spss下方的数据视图开始人数的录入
在第一列输入两个1和两个2,因为有两个组,分别为1和2,并且每个组都有男和女
如下图
然后在第二列,分别输入1 ,2,1, 2 ,此时的1和2代表性别,如下图所示
然后第三列输入各自的人数,即A组男为21,女为27,B组男为16,女为33输入后如下图
6、数据分析
点击菜单栏中的数据,加权个案
在对话框中,点击加权个案,然后将代表人数的列名称加到频率变量
点击确定
7、点击菜单中的分析,统计描述,交叉表,如下图
将代表行的组别栏加入行,代表列的性别栏加入列,然后点击统计量,选择卡方和下方的Mc…..
然后继续,在确定即完成了。
正确理解显著性检验
正确理解显著性检验(Significance Testing) 什么是显著性检验 显著性检验是用于检验实验处理组与对照组或两种不同处理组的效应之间的差异是否为显著性差异的方法,其原理就是“小概率事件实际不可能性原理”。显著性检验可用于两组数据是否有显著性差异,从而可以检验这两组数据所代表的“内涵”,如不同实验方法的差异有无,实验人员受训练的效果有无,不同来源的产品的质量差异,某产品的某特征在一定时间内稳定性,产品保质期的判断等等。 原假设 为了判断两组数据是否有显著性差异,统计学上规定原假设(null hypothesis) 为“两组数据(或数据所代表的内涵)无显著差”,而与之对立的备择假设(alternative hypothesis),则为“两组数据有显著差异”。 ⑴在原假设为真时,决定放弃原假设,称为第一类错误,即,弃真错误,其出现的概率,记作α; ⑵在原假设不真时,决定接受原假设,称为第二类错误,即,纳假错误,其出现的概率通常记作β。 通常只限定犯第一类错误的最大概率α,不考虑犯第二类错误的概率β。这样的“假设检验”又称为显著性检验,概率α称为显著性水平。 显著性检验的P值及有无显著性差异的判断: 通过显著性检验的计算方法计算而得的“犯第一类错误的概率p”,就是统计学上规定的P值。若p<或=α,则说明“放弃原假设,在统计意义上不会犯错误,即原假设是假的,也即,”两组数据无显著差异”不是真的,也即两组数据有显著差异”!反之,若p大于α,则说明两组数据间无显著差异。最常用的α值为0.01、0.05、0.10等。一般情况下,根据研究的问题,如果犯弃真错误损失大,为减少这类错误,α取值小些,反之,α取值大些。 P值及统计意义见下表
第三节-两个样本平均数差异显著性检验
第三节两个样本平均数的差异显著性检验 在实际工作中还经常会遇到推断两个样本平均数差异是否显著的问题,以了解两样本所属总体的平均数是否相同。对于两样本平均数差异显著性检验,因试验设计不同,一般可分为两种情况:一是非配对设计或成组设计两样本平均数的差异显著性检;二是配对设计两样本平均数的差异显著性检。 一、非配对设计两样本平均数的差异显著性检验 非配对设计或成组设计是指当进行只有两个处理的试验时,将试验单位完全随机地分成两个组,然后对两组随机施加一个处理。在这种设计中两组的试验单位相互独立,所得的二个样本相互独立,其含量不一定相等。非配对设计资料的一般形式见表5-2。 表5-2非配对设计资料的一般形式 处理观测值xij 样本含 量ni 平均数总体平均 数 1 x11x12…n1 =Σx1j/n1 2 x21x22…n2 =Σx2j/n2 非配对设计两样本平均数差异显著性检验的基本步骤如下:(一)提出无效假设与备择假设:=,:≠(二)计算值计算公式为: (5-3) 其中:(5-4)
= = 当时, ==(5-5) 为均数差异标准误,、,、,、分别为两样本含量、平均数、均方。 (三)根据df=(n1-1)+(n2-1),查临界值:、,将计算所得t值的绝对值与其比较,作出统计推断 【例】某种猪场分别测定长白后备种猪和蓝塘后备种猪90kg时的背膘厚度,测定结果如表5-3所示。设两品种后备种猪90kg时的背膘厚度值服从正态分布,且方差相等,问该两品种后备种猪90kg时的背膘厚度有无显著差异 表5-3长白与蓝塘后备种猪背膘厚度 品种头 数 背膘厚度(cm ) 长白1 2 、、、、、、、、、、、 蓝塘1 1 、、、、、、、、、、 1、提出无效假设与备择假设:=,:≠
使用SPSS进行两组独立样本的t检验、F检验、显著性差异、计算p值
使用SPSS 进行两组独立样本的t检验、F检验、显著性差异、计算p值 SPSS版本为SPSS 20. 如有以下两组独立的数据,名称分别为“111”,“222”。 111组:4、5、6、6、4 222组:1、2、3、7、7 首先打开SPSS,输入数据,命名分组,体重和组名要对应,111组的就不要输入到222组了。数据视图如下: 变量视图如下,名称可以改成“分组嗷嗷嗷”“体重喵喵喵”等
点击“分析”-“比较均值”-“独立样本T检验” 来到这里,分组变量为“分组嗷嗷嗷”,检验变量为“体重喵喵喵”。
【关键的一步】点击分组嗷嗷嗷,进行“定义组”
【关键的一步】输入对应的两组数据的组名:“111”和“222” 点击确定,可见数据与组名对应上了。
点击“确定”,生成T检验的报告,即将大功告成!
第一个表都知道什么回事就不缩了,excel都能实现的。 第二个表才是重点,不然用SPSS干嘛。 F检验:在两样本t检验中要用到F检验,F检验又叫方差齐性检验,用于判断两总体方差是否相等,即方差齐性。 如图:F旁边的Sig的值为.007 即0.007,<0.01, 即两组数据的方差显著性差异! 看到“假设方差相等”和“假设方差不相等”了么? 此时由于F检验得出Sig <0.01,即认为假设方差不相等!因此只关注红框中的数据即可。 如图,红框内,Sig(双侧),为.490即0.490,也就是你们要求的P值啦, Sig ( 也就是P值) >0.05,所以两组数据无显著性差异。 PS:同理,如果F检验的Sig >.05(即>0.05),则认为两个样本的假设方差相等。 所以相应的t检验的结果就看上面那行。 by 20150120 深大医学院FG
T检验、F检验和统计学意义,想了解显著性差异的也可以来看
一般而言,为了确定从样本(sample)统计结果推论至总体时所犯错的概率,我们会利用统计学家所开发的一些统计方法,进行统计检定。 通过把所得到的统计检定值,与统计学家建立了一些随机变量的概率分布(probability distribution)进行比较,我们可以知道在多少%的机会下会得到目前的结果。倘若经比较后发现,出现这结果的机率很少,亦即是说,是在机会很少、很罕有的情况下才出现;那我们便可以有信心的说,这不是巧合,是具有统计学上的意义的(用统计学的话讲,就是能够拒绝虚无假设null hypothesis,Ho)。相反,若比较后发现,出现的机率很高,并不罕见;那我们便不能很有信心的直指这不是巧合,也许是巧合,也许不是,但我们没能确定。 F值和t值就是这些统计检定值,与它们相对应的概率分布,就是F分布和t分布。统计显著性(sig)就是出现目前样本这结果的机率。 2,统计学意义(P值或sig值) 结果的统计学意义是结果真实程度(能够代表总体)的一种估计方法。专业上,p值为结果可信程度的一个递减指标,p值越大,我们越不能认为样本中变量的关联是总体中各变量关联的可靠指标。p值是将观察结果认为有效即具有总体代表性的犯错概率。如p=提示样本中变量关联有5%的可能是由于偶然性造成的。即假设总体中任意变量间均无关联,我们重复类似实验,会发现约20个实验中有一个实验,我们所研究的变量关联将等于或强于我们的实验结果。(这并不是说如果变量间存在关联,我们可得到5%或95%次数的相同结果,当总体中的变量存在关联,重复研究和发现关联的可能性与设计的统计学效力有关。)在许多研究领域,的p值通常被认为是可接受错误的边界水平。 3,T检验和F检验
显著性检验卡方检验等剖析
第十章 研究资料的整理与分析 本章学习目标: 1.理解量化资料整理与分析中的几个基本概念。 2.掌握几种常用的量化分析方法。 3.掌握质性资料的整理分析方法。 无论采用什么研究方法进行研究,都会搜集到大量的、杂乱的、复杂的研究资料。因此,对大量的、复杂的研究资料进行科学、合理的整理和分析,就成为教育科学研究活动的必不可少的一个环节。这一环节体现着研究者的洞见,是研究者对研究资料进行理性思维加工的过程。通过这一过程,产出研究结果。 根据研究资料的性质,研究资料可以分为质性研究资料和量化研究资料。对研究资料的整理和分析就相应的分为:质性研究资料的整理与分析和量化资料的整理与分析。 第一节 定量资料的整理与分析 一、定量资料分析中的几个基本概念 1.随机变量 在相同条件下进行试验或观察,其可能结果不止一个,而且事先无法确定,这类现象称为随机现象。表示随机现象中各种可能结果(事件)的变量就称为随机变量。教育研究中的变量,大多数都是随机变量。如身高、智商、学业测验分数等。 2.总体和样本 总体是具有某种或某些共同特征的研究对象的总和。样本是总体中抽出的部分个体,是直接观测和研究的对象。例如,要研究西安市5岁儿童的智力发展问题,西安市的5岁儿童就是研究的总体,从中抽取500名儿童,这500名儿童就成为研究的样本。 3.统计量和参数 统计量:反映样本数据分布特征的量称为统计量。例如:样本平均数、样本标准差、样本相关系数等,都属于统计量,它们分别用 表示。统计 量一般是根据样本数据直接计算而得出的。 参数:反映总体数据分布特征的量称为参数。例如:总体平均数、总体标准差、总体相关系数等。它们分别用ρσμ,,等符号来表示。总体参数常常需要根据样本统计量进行估计和推断。 4.描述统计与推断统计 描述统计是指对获得的杂乱的数据进行分类、整理和概括,以揭示一组数据
- 差异显著性检验模板
- EXCEL均数差异显著性检验
- T检验、F检验和统计学意义,想了解显著性差异的也可以来看
- 差异显著性检验
- 两个样本的差异显著性检验
- 差异显著性检验 t检验
- 第五章 差异显著性检验
- 平均数差异显著性检验
- 第8讲 差异显著性检验
- 第8讲 差异显著性检验
- 第8讲差异显著性检验
- 差异显著性检验
- 第三节-两个样本平均数差异显著性检验
- 使用SPSS进行两组独立样本的t检验、F检验、显著性差异、计算p值
- 第五章_差异显著性检验
- 显著性差异分析
- 第7章 平均数差异的显著性检验
- 第二章 差异显著性检验 t检验
- 显著性差异课件.
- 小样本 的差异显著性检验
- 简易呼吸器的市场调研报告
- 管理学罗宾斯11版中英文对照详解
- 罗宾斯《管理学》内容概要,中英文对照
- 罗宾斯管理学双语教学讲稿10
- 罗宾斯管理学双语教学讲稿3
- 斯蒂芬·P·罗宾斯-管理学(第10版)
- 管理学教材罗宾斯英文原版指南14
- (完整版)管理学罗宾斯11版中英文对照详解
- 罗宾斯管理学课后习题(英文版)--Chapter 5 Quiz
- 斯蒂芬P罗宾斯管理学归纳
- 最新国家开放大学电大本科《社会保障学》简答题案例分析题题库及答案(试卷号:1283)
- 2022电大劳动与社会保障法期末复习指导案例分析题
- 社会保障概论案例分析题
- 社会保障学案例分析题
- 社会保障案例14个
- 社会保障概论案例分析
- 《社会保障学》期末考试案例分析例题
- 社会保障案例分析
- 社会保障案例分析
- 社会保障案例14个