基于云模型改进的粒子群K均值聚类算法

聚类分析K-means算法综述
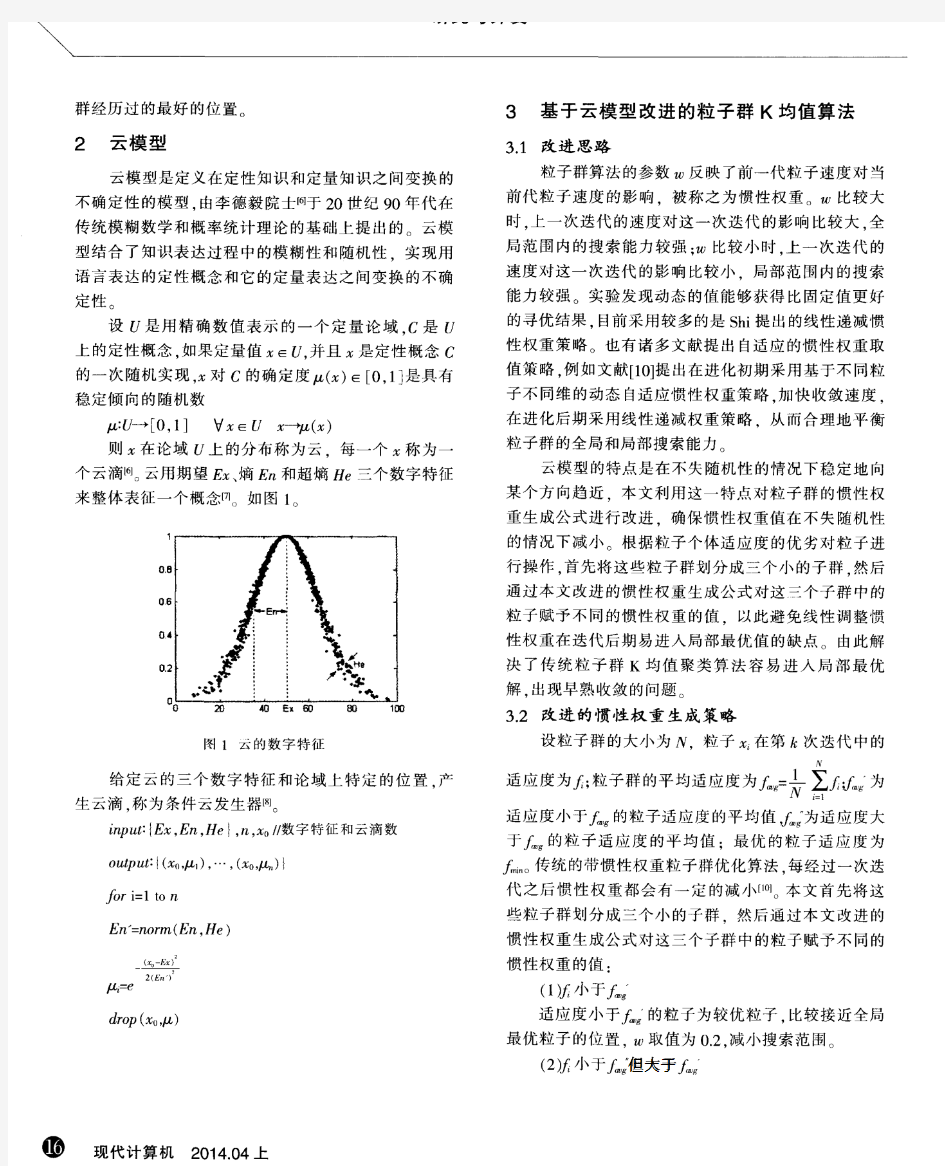
聚类分析K-means算法综述 摘要:介绍K-means聚类算法的概念,初步了解算法的基本步骤,通过对算法缺点的分析,对算法已有的优化方法进行简单分析,以及对算法的应用领域、算法未来的研究方向及应用发展趋势作恰当的介绍。 关键词:K-means聚类算法基本步骤优化方法应用领域研究方向应用发展趋势 算法概述 K-means聚类算法是一种基于质心的划分方法,输入聚类个数k,以及包含n个数据对象的数据库,输出满足方差最小标准的k个聚类。 评定标准:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。聚类相似度是利用各聚类中对象的均值所获得一个“中心对象”(引力中心)来进行计算。 解释:基于质心的划分方法就是将簇中的所有对象的平均值看做簇的质心,然后根据一个数据对象与簇质心的距离,再将该对象赋予最近的簇。 k-means 算法基本步骤 (1)从n个数据对象任意选择k 个对象作为初始聚类中心 (2)根据每个聚类对象的均值(中心对象),计算每个对象与这些中心对象的距离;并根据最小距离重新对相应对象进行划分 (3)重新计算每个(有变化)聚类的均值(中心对象) (4)计算标准测度函数,当满足一定条件,如函数收敛时,则算法终止;如果条件不满足则回到步骤(2) 形式化描述 输入:数据集D,划分簇的个数k 输出:k个簇的集合 (1)从数据集D中任意选择k个对象作为初始簇的中心; (2)Repeat (3)For数据集D中每个对象P do (4)计算对象P到k个簇中心的距离 (5)将对象P指派到与其最近(距离最短)的簇;
(6)End For (7)计算每个簇中对象的均值,作为新的簇的中心; (8)Until k个簇的簇中心不再发生变化 对算法已有优化方法的分析 (1)K-means算法中聚类个数K需要预先给定 这个K值的选定是非常难以估计的,很多时候,我们事先并不知道给定的数据集应该分成多少个类别才最合适,这也是K一means算法的一个不足"有的算法是通过类的自动合并和分裂得到较为合理的类型数目k,例如Is0DAIA算法"关于K一means算法中聚类数目K 值的确定,在文献中,根据了方差分析理论,应用混合F统计量来确定最佳分类数,并应用了模糊划分嫡来验证最佳分类数的正确性。在文献中,使用了一种结合全协方差矩阵RPCL算法,并逐步删除那些只包含少量训练数据的类。文献中针对“聚类的有效性问题”提出武汉理工大学硕士学位论文了一种新的有效性指标:V(k km) = Intra(k) + Inter(k) / Inter(k max),其中k max是可聚类的最大数目,目的是选择最佳聚类个数使得有效性指标达到最小。文献中使用的是一种称为次胜者受罚的竞争学习规则来自动决定类的适当数目"它的思想是:对每个输入而言不仅竞争获胜单元的权值被修正以适应输入值,而且对次胜单元采用惩罚的方法使之远离输入值。 (2)算法对初始值的选取依赖性极大以及算法常陷入局部极小解 不同的初始值,结果往往不同。K-means算法首先随机地选取k个点作为初始聚类种子,再利用迭代的重定位技术直到算法收敛。因此,初值的不同可能导致算法聚类效果的不稳定,并且,K-means算法常采用误差平方和准则函数作为聚类准则函数(目标函数)。目标函数往往存在很多个局部极小值,只有一个属于全局最小,由于算法每次开始选取的初始聚类中心落入非凸函数曲面的“位置”往往偏离全局最优解的搜索范围,因此通过迭代运算,目标函数常常达到局部最小,得不到全局最小。对于这个问题的解决,许多算法采用遗传算法(GA),例如文献中采用遗传算法GA进行初始化,以内部聚类准则作为评价指标。 (3)从K-means算法框架可以看出,该算法需要不断地进行样本分类调整,不断地计算调整后的新的聚类中心,因此当数据量非常大时,算法的时间开销是非常大 所以需要对算法的时间复杂度进行分析,改进提高算法应用范围。在文献中从该算法的时间复杂度进行分析考虑,通过一定的相似性准则来去掉聚类中心的候选集,而在文献中,使用的K-meanS算法是对样本数据进行聚类。无论是初始点的选择还是一次迭代完成时对数据的调整,都是建立在随机选取的样本数据的基础之上,这样可以提高算法的收敛速度。
实验三 K-均值聚类算法实验报告
实验三 K-Means聚类算法 一、实验目的 1) 加深对非监督学习的理解和认识 2) 掌握动态聚类方法K-Means 算法的设计方法 二、实验环境 1) 具有相关编程软件的PC机 三、实验原理 1) 非监督学习的理论基础 2) 动态聚类分析的思想和理论依据 3) 聚类算法的评价指标 四、算法思想 K-均值算法的主要思想是先在需要分类的数据中寻找K组数据作为初始聚类中心,然后计算其他数据距离这三个聚类中心的距离,将数据归入与其距离最近的聚类中心,之后再对这K个聚类的数据计算均值,作为新的聚类中心,继续以上步骤,直到新的聚类中心与上一次的聚类中心值相等时结束算法。 实验代码 function km(k,A)%函数名里不要出现“-” warning off [n,p]=size(A);%输入数据有n个样本,p个属性 cid=ones(k,p+1);%聚类中心组成k行p列的矩阵,k表示第几类,p是属性 %A(:,p+1)=100; A(:,p+1)=0; for i=1:k %cid(i,:)=A(i,:); %直接取前三个元祖作为聚类中心 m=i*floor(n/k)-floor(rand(1,1)*(n/k)) cid(i,:)=A(m,:); cid; end Asum=0; Csum2=NaN; flags=1; times=1; while flags flags=0; times=times+1; %计算每个向量到聚类中心的欧氏距离 for i=1:n
for j=1:k dist(i,j)=sqrt(sum((A(i,:)-cid(j,:)).^2));%欧氏距离 end %A(i,p+1)=min(dist(i,:));%与中心的最小距离 [x,y]=find(dist(i,:)==min(dist(i,:))); [c,d]=size(find(y==A(i,p+1))); if c==0 %说明聚类中心变了 flags=flags+1; A(i,p+1)=y(1,1); else continue; end end i flags for j=1:k Asum=0; [r,c]=find(A(:,p+1)==j); cid(j,:)=mean(A(r,:),1); for m=1:length(r) Asum=Asum+sqrt(sum((A(r(m),:)-cid(j,:)).^2)); end Csum(1,j)=Asum; end sum(Csum(1,:)) %if sum(Csum(1,:))>Csum2 % break; %end Csum2=sum(Csum(1,:)); Csum; cid; %得到新的聚类中心 end times display('A矩阵,最后一列是所属类别'); A for j=1:k [a,b]=size(find(A(:,p+1)==j)); numK(j)=a; end numK times xlswrite('data.xls',A);
粒子群优化算法综述
粒子群优化算法综述 摘要:本文围绕粒子群优化算法的原理、特点、改进与应用等方面进行全面综述。侧重于粒子群的改进算法,简短介绍了粒子群算法在典型理论问题和实际工业对象中的应用,并给出了粒子群算三个重要的网址,最后对粒子群算做了进一步展望。 关键词;粒子群算法;应用;电子资源;综述 0.引言 粒子群优化算法]1[(Particle Swarm Optimization ,PSO)是由美国的Kenned 和Eberhar 于1995年提出的一种优化算法,该算法通过模拟鸟群觅食行为的规律和过程,建立了一种基于群智能方法的演化计算技术。由于此算法在多维空间函数寻优、动态目标寻优时有实现容易,鲁棒性好,收敛快等优点在科学和工程领域已取得很好的研究成果。 1. 基本粒子群算法]41[- 假设在一个D 维目标搜索空间中,有m 个粒子组成一个群落,其中地i 个粒子组成一个D 维向量,),,,(21iD i i i x x x x =,m i ,2,1=,即第i 个粒子在D 维目标搜索空间中的位置是i x 。换言之,每个粒子 的位置就是一个潜在的解。将i x 带入一个目标函数就可以计算出其适 应值,根据适应值得大小衡量i x 的优劣。第i 个粒子的飞翔速度也是一个D 维向量,记为),,,(21iD i i i v v v v =。记第i 个粒子迄今为止搜索到的最优位置为),,,(21iD i i i p p p p =,整个粒子群迄今为止搜索到的最优位置为),,,(21gD gi g g p p p p =。 粒子群优化算法一般采用下面的公式对粒子进行操作
)()(22111t id t gd t id t id t id t id x p r c x p r c v v -+-+=+ω (1) 11+++=t id t id t id v x x (2) 式中,m i ,,2,1 =;D d ,,2,1 =;ω是惯性权重, 1c 和2c 是非负常数, 称为学习因子, 1r 和2r 是介于]1,0[间的随机数;],[max max v v v id -∈,max v 是常数,由用户设定。 2. 粒子群算法的改进 与其它优化算法一样PSO 也存在早熟收敛问题。随着人们对算 法搜索速度和精度的不断追求,大量的学者对该算法进行了改进,大致可分为以下两类:一类是提高算法的收敛速度;一类是增加种群多样性以防止算法陷入局部最优。以下是对最新的这两类改进的总结。 2.1.1 改进收敛速度 量子粒子群优化算法]5[:在量子系统中,粒子能够以某一确定的 概率出现在可行解空间中的任意位置,因此,有更大的搜索范围,与传统PSO 法相比,更有可能避免粒子陷入局部最优。虽然量子有更大的搜索空间,但是在粒子进化过程中,缺乏很好的方向指导。针对这个缺陷,对进化过程中的粒子进行有效疫苗接种,使它们朝着更好的进化方向发展,从而提高量子粒子群的收敛速度和寻优能力。 文化粒子群算法]6[:自适应指导文化PSO 由种群空间和信念空间 两部分组成。前者是基于PSO 的进化,而后者是基于信念文化的进化。两个空间通过一组由接受函数和影响函数组成的通信协议联系在一起,接受函数用来收集群体空间中优秀个体的经验知识;影响函数利用解决问题的知识指导种群空间进化;更新函数用于更新信念空间;
蚁群聚类算法综述
计算机工程与应用2006.16 引言 聚类分析是数据挖掘领域中的一个重要分支[1],是人们认 和探索事物之间内在联系的有效手段,它既可以用作独立的 据挖掘工具,来发现数据库中数据分布的一些深入信息,也 以作为其他数据挖掘算法的预处理步骤。所谓聚类(clus- ring)就是将数据对象分组成为多个类或簇(cluster),在同一 簇中的对象之间具有较高的相似度,而不同簇中的对象差别大。传统的聚类算法主要分为四类[2,3]:划分方法,层次方法, 于密度方法和基于网格方法。 受生物进化机理的启发,科学家提出许多用以解决复杂优 问题的新方法,如遗传算法、进化策略等。1991年意大利学A.Dorigo等提出蚁群算法,它是一种新型的优化方法[4]。该算不依赖于具体问题的数学描述,具有全局优化能力。随后他 其他学者[5~7]提出一系列有关蚁群的算法并应用于复杂的组优化问题的求解中,如旅行商问题(TSP)、调度问题等,取得 著的成效。后来其他科学家根据自然界真实蚂蚁群堆积尸体分工行为,提出基于蚂蚁的聚类算法[8,9],利用简单的智能体 仿蚂蚁在给定的环境中随意移动。这些算法的基本原理简单懂[10],已经应用到电路设计、文本挖掘等领域。本文详细地讨现有蚁群聚类算法的基本原理与性能,在归纳总结的基础上 出需要完善的地方,以推动蚁群聚类算法在更广阔的领域内 到应用。 2聚类概念及蚁群聚类算法 一个簇是一组数据对象的集合,在同一个簇中的对象彼此 类似,而不同簇中的对象彼此相异。将一组物理或抽象对象分组为类似对象组成的多个簇的过程被称为聚类。它根据数据的内在特性将数据对象划分到不同组(或簇)中。聚类的质量是基于对象相异度来评估的,相异度是根据描述对象的属性值来计算的,距离是经常采用的度量方式。聚类可用数学形式化描述为:设给定数据集X={x 1 ,x 2 ,…,x n },!i∈{1,2,…,n},x i ={x i1 ,x i2 , …,x
粒子群算法综述
粒子群算法综述 【摘要】:粒子群算法(pso)是一种新兴的基于群体智能的启发式全局搜索算法,具有易理解、易实现、全局搜索能力强等特点,倍受科学与工程领域的广泛关注,已得到广泛研究和应用。为了进一步推广应用粒子群算法并为深入研究该算法提供相关资料,本文对目前国内外研究现状进行了全面分析,在论述粒子群算法基本思想的基础上,围绕pso的运算过程、特点、改进方式与应用等方面进行了全面综述,并给出了未来的研究方向展望。 【关键词】:粒子群算法优化综述 优化理论的研究一直是一个非常活跃的研究领域。它所研究的问题是在多方案中寻求最优方案。人们关于优化问题的研究工作,随着历史的发展不断深入,对人类的发展起到了重要的推动作用。但是,任何科学的进步都受到历史条件的限制,直到二十世纪中期,由于高速数字计算机日益广泛应用,使优化技术不仅成为迫切需要,而且有了求解的有力工具。因此,优化理论和算法迅速发展起来,形成一门新的学科。至今已出现线性规划、整数规划、非线性规划、几何规划、动态规划、随机规划、网络流等许多分支。这些优化技术在诸多工程领域得到了迅速推广和应用,如系统控制、人工智能、生产调度等。随着人类生存空间的扩大,以及认识世界和改造世界范围的拓宽,常规优化法如牛顿法、车辆梯度法、模式搜索法、单纯形法等已经无法处理人们所面的复杂问题,因此高效的
优化算法成为科学工作者的研究目标之一。 1.粒子群算法的背景 粒子群算法(particle swarm optimization,pso)是一种新兴的演化算法。该算法是由j.kennedy和r.c.eberhart于1995年提出的一种基于群智能的随机优化算法。这类算法的仿生基点是:群集动物(如蚂蚁、鸟、鱼等)通过群聚而有效的觅食和逃避追捕。在这类群体的动物中,每个个体的行为是建立在群体行为的基础之上的,即在整个群体中信息是共享的,而且在个体之间存在着信息的交换与协作。如在蚁群中,当每个个体发现食物之后,它将通过接触或化学信号来招募同伴,使整个群落找到食源;在鸟群的飞行中,每只鸟在初始状态下处于随机位置,且朝各个方向随机飞行,但随着时间推移,这些初始处于随机状态的鸟通过相互学习(相互跟踪)组织的聚集成一个个小的群落,并以相同的速度朝着相同的方向飞行,最终整个群落聚集在同一位置──食源。这些群集动物所表现的智能常称为“群体智能”,它可表述为:一组相互之间可以进行直接通讯或间接通讯(通过改变局部环境)的主体,能够通过合作对问题进行分布求解。换言之,一组无智能的主体通过合作表现出智能行为特征。粒子群算法就是以模拟鸟的群集智能为特征,以求解连续变量优化问题为背景的一种优化算法。因其概念简单、参数较少、易于实现等特点,自提出以来已经受到国内外研究者的高度重视并被广泛应用于许多领域。
粒子群优化算法介绍及matlab程序
粒子群优化算法(1)—粒子群优化算法简介 PSO算法就是模拟一群鸟寻找食物的过程,每个鸟就是PSO中的粒子,也就是我们需要求解问题的可能解,这些鸟在寻找食物的过程中,不停改变自己在空中飞行的位置与速度。大家也可以观察一下,鸟群在寻找食物的过程中,开始鸟群比较分散,逐渐这些鸟就会聚成一群,这个群忽高忽低、忽左忽右,直到最后找到食物。这个过程我们转化为一个数学问题。寻找函数y=1-cos(3*x)*exp(-x)的在[0,4]最大值。该函数的图形如下: 当x=0.9350-0.9450,达到最大值y=1.3706。为了得到该函数的最大值,我们在[0, 4]之间随机的洒一些点,为了演示,我们放置两个点,并且计算这两个点的函数值,同时给这两个点设置在[0, 4]之间的一个速度。下面这些点就会按照一定的公式更改自己的位置,到达新位置后,再计算这两个点的值,然后再按照一定的公式更新自己的位置。直到最后在y=1.3706这个点停止自己的更新。这个过程与粒子群算法作为对照如下: 这两个点就是粒子群算法中的粒子。 该函数的最大值就是鸟群中的食物。 计算两个点函数值就是粒子群算法中的适应值,计算用的函数就是粒子群算法中的适应度函数。 更新自己位置的公式就是粒子群算法中的位置速度更新公式。 下面演示一下这个算法运行一次的大概过程: 第一次初始化 第一次更新位置
第二次更新位置 第21次更新 最后的结果(30次迭代) 最后所有的点都集中在最大值的地方。
粒子群优化算法(2)—标准粒子群优化算法 在上一节的叙述中,唯一没有给大家介绍的就是函数的这些随机的点(粒子)是如何运动的,只是说按照一定的公式更新。这个公式就是粒子群算法中的位置速度更新公式。下面就介绍这个公式是什么。在上一节中我们求取函数y=1-cos(3*x)*exp(-x)的在[0, 4]最大值。并在[0,4]之间放置了两个随机的点,这些点的坐标假设为x1=1.5,x2=2.5;这里的点是一个标量,但是我们经常遇到的问题可能是更一般的情况—x 为一个矢量的情况,比如二维z=2*x1+3*x22的情况。这个时候我们的每个粒子均为二维,记粒子P1=(x11,x12),P2=(x21,x22),P3=(x31,x32),......Pn=(xn1,xn2)。这里n 为粒子群群体的规模,也就是这个群中粒子的个数,每个粒子的维数为2。更一般的是粒子的维数为q ,这样在这个种群中有n 个粒子,每个粒子为q 维。 由n 个粒子组成的群体对Q 维(就是每个粒子的维数)空间进行搜索。每个粒子表示为:x i =(x i1,x i2,x i3,...,x iQ ),每个粒子对应的速度可以表示为v i =(v i1,v i2,v i3,....,v iQ ),每个粒子在搜索时要考虑两个因素: 1. 自己搜索到的历史最优值 p i ,p i =(p i1,p i2,....,p iQ ),i=1,2,3,....,n ; 2. 全部粒子搜索到的最优值p g ,p g =(p g1,p g2,....,p gQ ),注意这里的p g 只有一个。 下面给出粒子群算法的位置速度更新公式: 112()()()()k k k k i i i i v v c rand pbest x c rand gbest x ω+=+??-+??-, 11k k k i i i x x av ++=+. 这里有几个重要的参数需要大家记忆,因为在以后的讲解中将会经常用到,它们是: ω是保持原来速度的系数,所以叫做惯性权重。1c 是粒子跟踪自己历史最优值的权重系数,它表示粒子自身的认识,所以叫“认知”。通常设置为2。2c 是粒子跟踪群体最优值的权重系数,它表示粒子对整个群体知识的认识,所以叫做“社会知识”,经常叫做“社会”。通常设置为2。()rand 是[0,1]区间内均匀分布的随机数。a 是对位置更新的时候,在速度前面加的一个系数,这个系数我们叫做约束因子。通常设置为1。这样一个标准的粒子群算法就介绍结束了。下图是对整个基本的粒子群的过程给一个简单的图形表示。 判断终止条件可是设置适应值到达一定的数值或者循环一定的次数。 注意:这里的粒子是同时跟踪自己的历史最优值与全局(群体)最优值来改变自己的位置预速度的,所以又叫做全局版本的标准粒子群优化算法。
K-means-聚类算法研究综述
K-means聚类算法研究综述 摘要:总结评述了K-means聚类算法的研究现状,指出K-means聚类算法是一个NP难优化问题,无法获得全局最优。介绍了K-means聚类算法的目标函数,算法流程,并列举了一个实例,指出了数据子集的数目K,初始聚类中心选取,相似性度量和距离矩阵为K-means聚类算法的3个基本参数。总结了K-means聚类算法存在的问题及其改进算法,指出了K-means 聚类的进一步研究方向。 关键词:K-means聚类算法;NP难优化问题;数据子集的数目K;初始聚类中心选取;相似性度量和距离矩阵 Review of K-means clustering algorithm Abstract: K-means clustering algorithm is reviewed. K-means clustering algorithm is a NP hard optimal problem and global optimal result cannot be reached. The goal,main steps and example of K-means clustering algorithm are introduced. K-means algorithm requires three user-specified parameters: number of clusters K,cluster initialization,and distance metric. Problems and improvement of K-means clustering algorithm are summarized then. Further study directions of K-means clustering algorithm are pointed at last. Key words: K-means clustering algorithm; NP hard optimal problem; number of clusters K; cluster initialization; distance metric K-means聚类算法是由Steinhaus1955年、Lloyed1957年、Ball & Hall1965年、McQueen1967年分别在各自的不同的科学研究领域独立的提出。K-means聚类算法被提出来后,在不同的学科领域被广泛研究和应用,并发展出大量不同的改进算法。虽然K-means聚类算法被提出已经超过50年了,但目前仍然是应用最广泛的划分聚类算法之一[1]。容易实施、简单、高效、成功的应用案例和经验是其仍然流行的主要原因。 文中总结评述了K-means聚类算法的研究现状,指出K-means聚类算法是一个NP难优化问题,无法获得全局最优。介绍了K-means聚类算法的目标函数、算法流程,并列举了一个实例,指出了数据子集的数目K、初始聚类中心选取、相似性度量和距离矩阵为K-means聚类算法的3个基本参数。总结了K-means聚类算法存在的问题及其改进算法,指出了K-means聚类的进一步研究方向。 1经典K-means聚类算法简介 1.1K-means聚类算法的目标函数 对于给定的一个包含n个d维数据点的数据集 12 {x,x,,x,,x} i n X=??????,其中d i x R ∈,以及要生成的数据子集的数目K,K-means聚类算法将数据对象组织为 K个划分{c,i1,2,} k C K ==???。每个划分代表一个类c k,每个类c k有一个类别中心iμ。选取欧氏距离作为相似性和 距离判断准则,计算该类内各点到聚类中心 i μ的距离平方和 2 (c) i i k i k x C J xμ ∈ =- ∑(1) 聚类目标是使各类总的距离平方和 1 (C)(c) K k k J J = =∑最小。 22 1111 (C)(c) i i K K K n k i k ki i k k k x C k i J J x d x μμ ==∈== ==-=- ∑∑∑∑∑ (2)其中, 1 i i ki i i x c d x c ∈ ? =? ? ? 若 若 ,显然,根据最小二乘 法和拉格朗日原理,聚类中心 k μ应该取为类别 k c类各数据点的平均值。 K-means聚类算法从一个初始的K类别划分开始,然
K均值聚类算法优缺点
J.B.MacQueen 在 1967 年提出的K-means算法[22]到目前为止用于科学和工业应用的诸多聚类算法中一种极有影响的技术。它是聚类方法中一个基本的划分方法,常常采用误差平方和准则函数作为聚类准则函数,误差平方和准则函数定义为: (3-1)其中,是类中数据对象的均值,即,(j=1,2,…,n),是K个聚类中心,分别代表K个类。 K-means算法的工作原理:算法首先随机从数据集中选取 K个点作为初始聚类中心,然后计算各个样本到聚类中的距离,把样本归到离它最近的那个聚类中心所在的类。计算新形成的每一个聚类的数据对象的平均值来得到新的聚类中心,如果相邻两次的聚类中心没有任何变化,说明样本调整结束,聚类准则函数已经收敛。本算法的一个特点是在每次迭代中都要考察每个样本的分类是否正确。若不正确,就要调整,在全部样本调整完后,再修改聚类中心,进入下一次迭代。如果在一次迭代算法中,所有的样本被正确分类,则不会有调整,聚类中心也不会有任何变化,这标志着已经收敛,因此算法结束。 算法描述如下: 算法:K-means。划分的 K-means 算法基于类中对象的平均值。 输入:类的数目K和包含N个对象的数据库。 方法: ① 对于数据对象集,任意选取K个对象作为初始的类中心; ② 根据类中对象的平均值,将每个对象重新赋给最相似的类; ③ 更新类的平均值,即计算每个类中对象的平均值; ④ Repeat ②③; ⑤ 直到不再发生变化。 其中,初始聚类中心的选择对聚类结果的影响是很大的,如图3.1,图a是三个类的实际分布,图b是选取了好的初始聚类中心(+字标记的数据对象)得到的结果。图c是选取不好的初始聚类中心得到的结果,从中可以看到,选择初始聚类中心是很关键的。 a b c
粒子群优化算法及其应用研究【精品文档】(完整版)
摘要 在智能领域,大部分问题都可以归结为优化问题。常用的经典优化算法都对问题有一定的约束条件,如要求优化函数可微等,仿生算法是一种模拟生物智能行为的优化算法,由于其几乎不存在对问题的约束,因此,粒子群优化算法在各种优化问题中得到广泛应用。 本文首先描述了基本粒子群优化算法及其改进算法的基本原理,对比分析粒子群优化算法与其他优化算法的优缺点,并对基本粒子群优化算法参数进行了简要分析。根据分析结果,研究了一种基于量子的粒子群优化算法。在标准测试函数的优化上粒子群优化算法与改进算法进行了比较,实验结果表明改进的算法在优化性能明显要优于其它算法。本文算法应用于支持向量机参数选择的优化问题上也获得了较好的性能。最后,对本文进行了简单的总结和展望。 关键词:粒子群优化算法最小二乘支持向量机参数优化适应度
目录 摘要...................................................................... I 目录....................................................................... II 1.概述. (1) 1.1引言 (1) 1.2研究背景 (1) 1.2.1人工生命计算 (1) 1.2.2 群集智能理论 (2) 1.3算法比较 (2) 1.3.1粒子群算法与遗传算法(GA)比较 (2) 1.3.2粒子群算法与蚁群算法(ACO)比较 (3) 1.4粒子群优化算法的研究现状 (4) 1.4.1理论研究现状 (4) 1.4.2应用研究现状 (5) 1.5粒子群优化算法的应用 (5) 1.5.1神经网络训练 (6) 1.5.2函数优化 (6) 1.5.3其他应用 (6) 1.5.4粒子群优化算法的工程应用概述 (6) 2.粒子群优化算法 (8) 2.1基本粒子群优化算法 (8) 2.1.1基本理论 (8) 2.1.2算法流程 (9) 2.2标准粒子群优化算法 (10) 2.2.1惯性权重 (10) 2.2.2压缩因子 (11) 2.3算法分析 (12) 2.3.1参数分析 (12) 2.3.2粒子群优化算法的特点 (14) 3.粒子群优化算法的改进 (15) 3.1粒子群优化算法存在的问题 (15) 3.2粒子群优化算法的改进分析 (15) 3.3基于量子粒子群优化(QPSO)算法 (17) 3.3.1 QPSO算法的优点 (17) 3.3.2 基于MATLAB的仿真 (18) 3.4 PSO仿真 (19) 3.4.1 标准测试函数 (19) 3.4.2 试验参数设置 (20) 3.5试验结果与分析 (21) 4.粒子群优化算法在支持向量机的参数优化中的应用 (22) 4.1支持向量机 (22) 4.2最小二乘支持向量机原理 (22)
粒子群算法的研究现状及其应用
智能控制技术 课程论文 中文题目: 粒子群算法的研究现状及其应用姓名学号: 指导教师: 年级与专业: 所在学院: XXXX年XX月XX日
1 研究的背景 优化问题是一个古老的问题,可以将其定义为:在满足一定约束条件下,寻找一组参数值,使系统的某些性能指标达到最大值或最小值。在我们的日常生活中,我们常常需要解决优化问题,在一定的范围内使我们追求的目标得到最大化。为了解决我们遇到的最优化问题,科学家,们进行了不懈的努力,发展了诸如牛顿法、共轭梯度法等诸多优化算法,大大推动了优化问题的发展,但由于这些算法的低运行效率,使得在计算复杂度、收敛性等方面都无法满足实际的生产需要。 对此,受达尔文进化论的影响,一批新的智能优化算法相继被提出。粒子群算法(PSO )就是其中的一项优化技术。1995 年Eberhart 博士和Kennedy 博士[1]-[3]通过研究鸟群捕食的行为后,提出了粒子群算法。设想有一群鸟在随机搜索食物,而在这个区域里只有一块食物,所有的鸟都不知道食物在哪里。那么找到食物最简单有效的办法就是鸟群协同搜寻,鸟群中的每只鸟负责离其最近的周围区域。 粒子群算法是一种基于群体的优化工具,尤其适用于复杂和非线性问题。系统初始化为一组随机解,通过迭代搜寻最优值,通过采用种群的方式组织搜索,同时搜索空间内的多个区域,所以特别适合大规模并行计算,具有较高的效率和简单、易操作的特性。 目前使用的粒子群算法的数学描述[3]为:设粒子的寻优空间是m 维的,粒子的数目为ps ,算法的最大寻优次数为Iter 。第i 个粒子的飞行速度为T i i1i2im v [v v ]= ,,,v ,位置为T i i1i2im x [x x x ]= ,,,,粒子的个体极值T i i1i2im Pbest [,]P = ,P ,P ,全局极值为 T i i1i2im Gbest [,]g = ,g ,g 。 粒子群算法的寻优过程主要由粒子的速度更新和位置更新两部分组成,其更新方式如下: i+11122v ()()i i i i i v c r Pbest x c r Gbest x =+?+?; i+1i+1i x x v =+, 式中:12c c ,为学习因子,一般取2;12r r ,是均与分布着[0,1]上的随机数。
K 均值聚类算法(原理加程序代码)
K-均值聚类算法 1.初始化:选择c 个代表点,...,,321c p p p p 2.建立c 个空间聚类表:C K K K ...,21 3.按照最小距离法则逐个对样本X 进行分类: ),(),,(min arg J i i K x add p x j ?= 4.计算J 及用各聚类列表计算聚类均值,并用来作为各聚类新的代表点(更新代表点) 5.若J 不变或代表点未发生变化,则停止。否则转2. 6.),(1∑∑=∈=c i K x i i p x J δ 具体代码如下: clear all clc x=[0 1 0 1 2 1 2 3 6 7 8 6 7 8 9 7 8 9 8 9;0 0 1 1 1 2 2 2 6 6 6 7 7 7 7 8 8 8 9 9]; figure(1) plot(x(1,:),x(2,:),'r*') %%第一步选取聚类中心,即令K=2 Z1=[x(1,1);x(2,1)]; Z2=[x(1,2);x(2,2)]; R1=[]; R2=[]; t=1; K=1;%记录迭代的次数 dif1=inf; dif2=inf; %%第二步计算各点与聚类中心的距离 while (dif1>eps&dif2>eps) for i=1:20 dist1=sqrt((x(1,i)-Z1(1)).^2+(x(2,i)-Z1(2)).^2); dist2=sqrt((x(1,i)-Z2(1)).^2+(x(2,i)-Z2(2)).^2); temp=[x(1,i),x(2,i)]'; if dist1 粒子群算法(1)----粒子群算法简介 二、粒子群算法的具体表述 上面罗嗦了半天,那些都是科研工作者写论文的语气,不过,PSO的历史就像上面说的那样。下面通俗的解释PSO算法。 PSO算法就是模拟一群鸟寻找食物的过程,每个鸟就是PSO.中的粒子,也就是我们需要求解问题的可能解,这些鸟在寻找食物的过程中,不停改变自己在空中飞行的位置与速度。大家也可以观察一下,鸟群在寻找食物的过程中,开始鸟群比较分散,逐渐这些鸟就会聚成一群,这个群忽高忽低、忽左忽右,直到最后找到食物。这个过程我们转化为一个数学问题。寻找函数y=1-cos(3*x)*exp(-x)的在[0,4]最大值。该函数的图形如下: 当x=0.9350-0.9450,达到最大值y=1.3706。为了得到该函数的最大值,我们在[0,4]之间随机的洒一些点,为了演示,我们放置两个点,并且计算这两个点的函数值,同时给这两个点设置在[0,4]之间的一个速度。下面这些点就会按照一定的公式更改自己的位置,到达新位置后,再计算这两个点的值,然后再按照一定的公式更新自己的位置。直到最后在y=1.3706这个点停止自己的更新。这个过程与粒子群算法作为对照如下: 这两个点就是粒子群算法中的粒子。 该函数的最大值就是鸟群中的食物 计算两个点函数值就是粒子群算法中的适应值,计算用的函数就是粒子群算法中的适应度函数。 更新自己位置的一定公式就是粒子群算法中的位置速度更新公式。 下面演示一下这个算法运行一次的大概过程: 第一次初始化 第一次更新位置 第二次更新位置 第21次更新 最后的结果(30次迭代) 最后所有的点都集中在最大值的地方。 4.1粒子群算法基本原理 粒子群优化算法[45]最原始的工作可以追溯到1987年Reynolds 对鸟群社会系统Boids (Reynolds 对其仿真鸟群系统的命名)的仿真研究 。通常,群体的行为可以由几条简单的规则进行建模,虽然每个个体具有简单的行为规则,但是却群体的行为却是非常的复杂,所以他们在鸟类仿真中,即Boids 系统中采取了下面的三条简单的规则: (1)飞离最近的个体(鸟),避免与其发生碰撞冲突; (2)尽量使自己与周围的鸟保持速度一致; (3)尽量试图向自己认为的群体中心靠近。 虽然只有三条规则,但Boids 系统已经表现出非常逼真的群体聚集行为。但Reynolds 仅仅实现了该仿真,并无实用价值。 1995年Kennedy [46-48]和Eberhart 在Reynolds 等人的研究基础上创造性地提出了粒子群优化算法,应用于连续空间的优化计算中 。Kennedy 和Eberhart 在boids 中加入了一个特定点,定义为食物,每只鸟根据周围鸟的觅食行为来搜寻食物。Kennedy 和Eberhart 的初衷是希望模拟研究鸟群觅食行为,但试验结果却显示这个仿真模型蕴含着很强的优化能力,尤其是在多维空间中的寻优。最初仿真的时候,每只鸟在计算机屏幕上显示为一个点,而“点”在数学领域具有多种意义,于是作者用“粒子(particle )”来称呼每个个体,这样就产生了基本的粒子群优化算法[49]。 假设在一个D 维搜索空间中,有m 个粒子组成一粒子群,其中第i 个粒子的空间位置为123(,,,...,)1,2,...,i i i i iD X x x x x i m ==,它是优化问题的一个潜在 信息疼术2018年第6期文章编号=1009 -2552 (2018)06 -0092 -03 DOI:10.13274/https://www.wendangku.net/doc/e53224496.html,ki.hdzj.2018. 06.019 基于聚类的图像分割方法综述 赵祥宇\陈沫涵2 (1.上海理工大学光电信息与计算机学院,上海200093; 2.上海西南位育中学,上海200093) 摘要:图像分割是图像识别和机器视觉领域中关键的预处理操作。分割理论算法众多,文中 具体介绍基于聚类的分割算法的思想和原理,并将包含的典型算法的优缺点进行介绍和分析。经过比较后,归纳了在具体应用中如何对图像分割算法的抉择问题。近年来传统分割算法不断 被科研工作者优化和组合,相信会有更多的分割新算法井喷而出。 关键词:聚类算法;图像分割;分类 中图分类号:TP391.41 文献标识码:A A survey of image segmentation based on clustering ZHAO Xiang-yu1,CHEN Mo-han2 (1.School of Optical Electrical and Computer Engineering,University of Shanghai for Science and Technology,Shanghai200093,China;2.Shanghai Southwest Weiyu Middle School,Shanghai200093,China) Abstract:Image segmentation is a key preprocessing operation in image recognition and machine vision. There are many existing theoretical methods,and this paper introduces the working principle ol image segmentation algorithm based on clustering.Firstly,the advantages and disadvantages ol several typical algorithms are introduced and analyzed.Alter comparison,the paper summarizes the problem ol the selection ol image segmentation algorithm in practical work.In recent years,the traditional segmentation algorithms were improved and combined by the researchers,it believes that more new algorithms are blown out. Key words:clustering algorithm;image segmentation;classilication 0引百 近年来科学技术的不断发展,计算机视觉和图像 识别发挥着至关重要的作用。在实际应用和科学研 究中图像处理必不可少,进行图像处理必然用到图像 分割方法,根据检测图像中像素不重叠子区域,将感 兴趣目标区域分离出来。传统的图像分割方法:阈值 法[1]、区域法[2]、边缘法[3]等。近年来传统分割算法 不断被研究人员改进和结合,出现了基于超像素的分 割方法[4],本文主要介绍超像素方法中基于聚类的经 典方法,如Mean Shift算法、K-m eans 算法、Fuzzy C-mean算法、Medoidshilt算法、Turbopixels算法和 SLIC 算法。简要分析各算法的基本思想和分割效果。 1聚类算法 1.1 Mean Shil't算法 1975年,Fukunaga[5]提出一种快速统计迭代算法,即Mean Shilt算法(均值漂移算法)。直到1995 年,Cheng[6]对其进行改进,定义了核函数和权值系 数,在全局优化和聚类等方面的应用,扩大了 Mean shil't算法适用范围。1997至2003年间,Co-maniciu[7-9]提出了基于核密度梯度估计的迭代式 搜索算法,并将该方法应用在图像平滑、分割和视频 跟踪等领域。均值漂移算法的基本思想是通过反复 迭代计算当前点的偏移均值,并挪动被计算点,经过 反复迭代计算和多次挪动,循环判断是否满足条件, 达到后则终止迭代过程[10]。Mean shil't的基本形 式为: 收稿日期:2017-06 -13 基金项目:国家自然科学基金资助项目(81101116) 作者简介:赵祥宇(1992-),男,硕士研究生,研究方向为数字图像处理。 —92 — 启发式优化算法综述 一、启发式算法简介 1、定义 由于传统的优化算法如最速下降法,线性规划,动态规划,分支定界法,单纯形法,共轭梯度法,拟牛顿法等在求解复杂的大规模优化问题中无法快速有效地寻找到一个合理可靠的解,使得学者们期望探索一种算法:它不依赖问题的数学性能,如连续可微,非凸等特性; 对初始值要求不严格、不敏感,并能够高效处理髙维数多模态的复杂优化问题,在合理时间内寻找到全局最优值或靠近全局最优的值。于是基于实际应用的需求,智能优化算法应运而生。智能优化算法借助自然现象的一些特点,抽象出数学规则来求解优化问题,受大自然的启发,人们从大自然的运行规律中找到了许多解决实际问题的方法。对于那些受大自然的运行规律或者面向具体问题的经验、规则启发出来的方法,人们常常称之为启发式算法(Heuristic Algorithm)。 为什么要引出启发式算法,因为NP问题,一般的经典算法是无法求解,或求解时间过长,我们无法接受。因此,采用一种相对好的求解算法,去尽可能逼近最优解,得到一个相对优解,在很多实际情况中也是可以接受的。启发式算法是一种技术,这种技术使得在可接受的计算成本内去搜寻最好的解,但不一定能保证所得的可行解和最优解,甚至在多数情况下,无法阐述所得解同最优解的近似程度。 启发式算法是和问题求解及搜索相关的,也就是说,启发式算法是为了提高搜索效率才提出的。人在解决问题时所采取的一种根据经验规则进行发现的方法。其特点是在解决问题 时,利用过去的经验,选择已经行之有效的方法,而不是系统地、以确定的步骤去寻求答案,以随机或近似随机方法搜索非线性复杂空间中全局最优解的寻取。启发式解决问题的方法是与算法相对立的。算法是把各种可能性都一一进行尝试,最终能找到问题的答案,但它是在很大的问题空间内,花费大量的时间和精力才能求得答案。启发式方法则是在有限的搜索空间内,大大减少尝试的数量,能迅速地达到问题的解决。 2、发展历史 启发式算法的计算量都比较大,所以启发式算法伴随着计算机技术的发展,才能取得了巨大的成就。纵观启发式算法的历史发展史: 40年代:由于实际需要,提出了启发式算法(快速有效)。 50年代:逐步繁荣,其中贪婪算法和局部搜索等到人们的关注。 60年代: 反思,发现以前提出的启发式算法速度很快,但是解得质量不能保证,而且对大规模的问题仍然无能为力(收敛速度慢)。 70年代:计算复杂性理论的提出,NP问题。许多实际问题不可能在合理的时间范围内找到全局最优解。发现贪婪算法和局部搜索算法速度快,但解不好的原因主要是他们只是在局部的区域内找解,等到的解没有全局最优性。由此必须引入新的搜索机制和策略。 Holland的遗传算法出现了(Genetic Algorithm)再次引发了人们研究启发式算法的兴趣。 80年代以后:模拟退火算法(Simulated Annealing Algorithm),人工神经网络(Artificial Neural Network),禁忌搜索(Tabu Search)相继出现。 最近比较火热的:演化算法(Evolutionary Algorithm), 蚁群算法(Ant Algorithms),拟人拟物算法,量子算法等。粒子群算法(1)----粒子群算法简介
粒子群算法基本原理
基于聚类的图像分割方法综述
启发式优化算法综述【精品文档】(完整版)