HashMap源代码分析

HashMap源代码分析
大家在项目中很频繁的用到了java.util.HashMap 类,但是你对其内部实现是否了解呢?最近我分析了一下该类的源码,抛砖引玉,和大家分享讨论一下。
1、HashMap的基本属性及数据结构
HashMap的基本数据结构是数组,而数组元素是链表,其元素类型是Entry。HashMap 是根据对key的hash运算决定将Entry放在数组的哪个位置上的,而对于hash值相同的元素,就会放在同一个链表中。
HashMap中有一个声明为“transient Entry[] table”的属性,Entry是HashMap存储的基本数据类,其基本属性如下:
final K key;
V value;
Entry
final int hash;
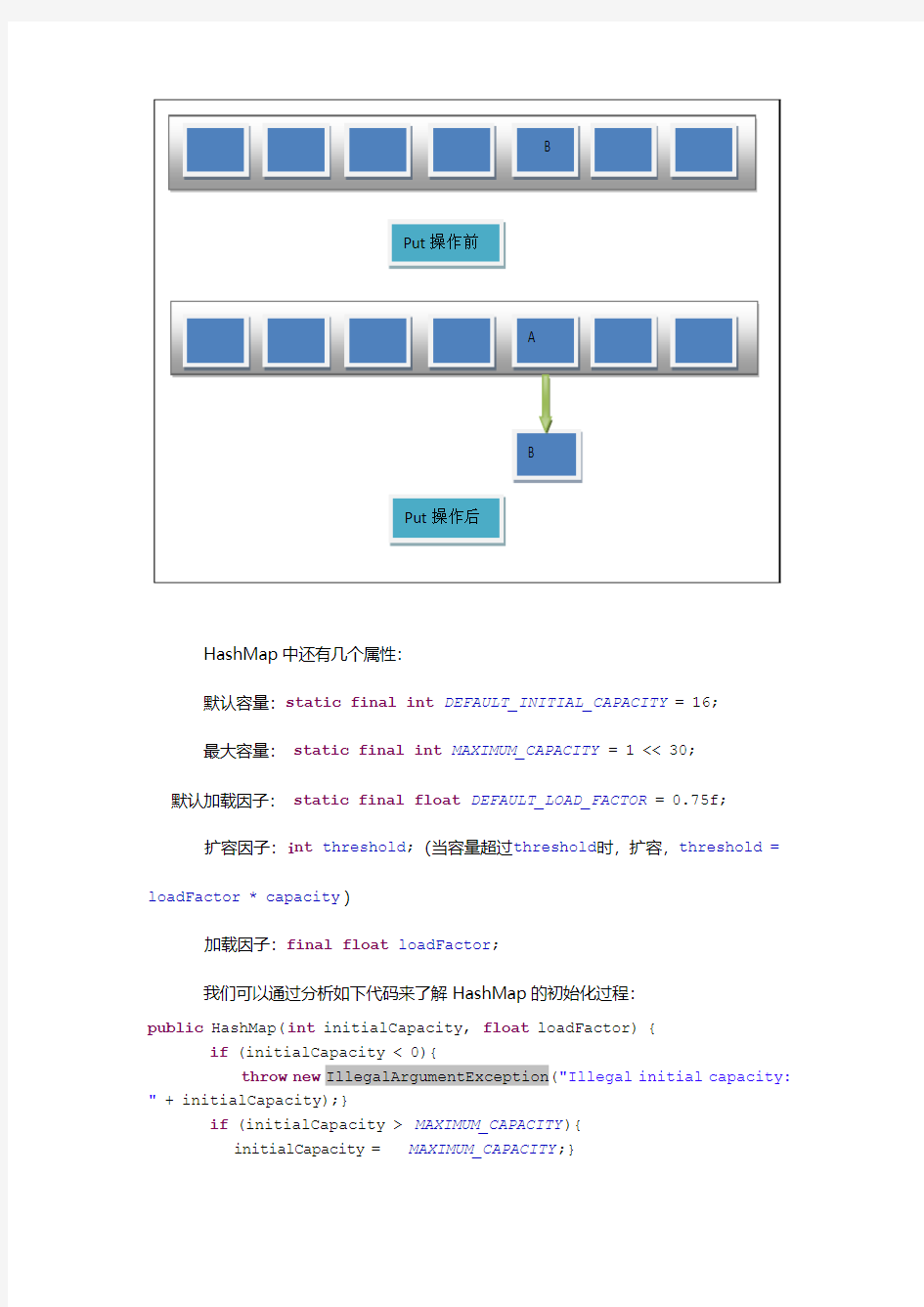
key和value自然不用说,hash是key的hash值,next的类型是Entry,它存在的价值就是解决hash冲突的!如果put一个key-value对时,经过hash运算,该K-V对对应的Entry A应该放在Entry[] table中第5的位置,但是该位置已经有Entry B存在了,那么就将A.next = B,A放在第5的位置上。如下图所示:
HashMap中还有几个属性:
默认容量:static final int DEFAULT_INITIAL_CAPACITY = 16;
最大容量:static final int MAXIMUM_CAPACITY = 1 << 30;
默认加载因子:static final float DEFAULT_LOAD_FACTOR = 0.75f;
扩容因子:i nt threshold;(当容量超过threshold时,扩容,threshold = loadFactor * capacity)
加载因子:final float loadFactor;
我们可以通过分析如下代码来了解HashMap的初始化过程:
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0){
throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);}
if (initialCapacity > MAXIMUM_CAPACITY){
initialCapacity = MAXIMUM_CAPACITY;}
if (loadFactor <= 0 || Float.isNaN(loadFactor)){
throw new IllegalArgumentException("Illegal load factor: " + loadFactor);}
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity){
capacity <<= 1;}
this.loadFactor = loadFactor;
threshold = (int)(capacity * loadFactor);
table = new Entry[capacity];
init();
}
该构造函数的参数是我们期望的初始化容量initialCapacity和装载因子loadFactor。
我们通过
while (capacity < initialCapacity){
capacity <<= 1;}
这段代码可以了解到,capacity是大于initialCapacity的最小2次幂数值。也就是说,如果我们的参数initialCapacity = 10,loadFactor = 0.8,那么实际上capacity = 16,该HashMap 的初始容量是16,当元素个数超过10 * 0.8 = 8的时候,map进行扩容。
要注意的是,HashMap对key进行hash时,不是取的key的key.hashCode()方法,而是对key的hashcode作一些运算得到最后的hash值,在所有涉及到entry的操作中都要计算hash = hash(key.hashCode())。有了对元素key两次hash后的hash值,又如何找到元素位于table中的哪个位置呢?
从上面代码可以看出,i 的值就是元素处于table中的位置,i 是由hash和length计算出来的。
下面来看一下HashMap中的put/get/remove方法实现。
2、put/get/remove操作如何实现
先看下put方法的源码:
从代码中可以看出:当我们进行put操作的时候,先根据key的hashCode重新计算hash 值,根据hash值得到这个元素在数组中的位置(即下标),如果数组该位置上已经存放有其他元素了,那么在这个位置上的元素将以链表的形式存放,新加入的放在链头,最先加入的放在链尾。如果数组该位置上没有元素,就直接将该元素放到此数组中的该位置上。
addEntry(int hash, K key, V value, int bucketIndex)方法执行具体的插
入操作,可以看下源码:
参数hash是key两次hash计算后的hash值,bucketIndex就是该元素在table的索引。当执行put操作后,size >= threshold后,map会自动扩容为现在的2倍容量,稍后详细分析扩容的细节,先看get操作。
从源码看以看出,在执行get操作时,先进行hash运算,获取该元素在table中的位置,然后遍历该位置处得list,直到找到key与参数相同的元素,返回该元素的value,如果找不到,则返回null。
下面我们再来看下remove操作的源码:
归纳起来简单地说,HashMap 在底层将key-value 当成一个整体进行处理,这个整体就是一个Entry 对象。HashMap 底层采用一个Entry[] 数组来保存所有的key-value 对,当需要存储一个Entry 对象时,会根据hash算法来决定其在数组中的存储位置,在根据equals 方法决定其在该数组位置上的链表中的存储位置;当需要取出一个Entry时,也会根据hash算法找到其在数组中的存储位置,再根据equals方法从该位置上的链表中取出该Entry。(此段引自网络)
3、HashMap的扩容机制
当HashMap中的元素越来越多的时候,hash冲突的几率也就越来越高,因为数组的长度是固定的。所以为了提高查询的效率,就要对HashMap的数组进行扩容,数组扩容这个操作也会出现在ArrayList中,这是一个常用的操作,而在HashMap数组扩容之后,最消耗性能的点就出现了:原数组中的数据必须重新计算其在新数组中的位置,并放进去,这就是resize。
那么HashMap什么时候进行扩容呢?当HashMap中的元素个数超过数组大小(而不是map的size噢,size是所有元素的个数,capacity是数组的大小)*loadFactor时,就会进行数组扩容,loadFactor的默认值为0.75,这是一个折中的取值。也就是说,默认情况下,数组大小为16,那么当HashMap中元素个数超过16*0.75=12的时候,就把数组的大小扩展为2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知HashMap中元素的个数,那么预设元素的个数能够有效的提高HashMap的性能。
来看resize操作源码:
resize方法实际上执行的操作是以newCapacity参数值新建一个Entry数组,将table中的元素转移到新Entry中去,并且将table指向新数组。
下面来看下transfer()方法的源码:
但是为什么要扩容为两倍呢?
我们知道,在初始化HashMap的时候,有下面的语句
该语句保证了table的初始大小是2的n次方,在resize的时候,也是将容量扩充为原来的两倍,这保证了table的大小一直都是2的n次方,而这,是很有玄机的。
我们知道indexFor操作执行的是hash&(length-1)的操作(该操作等价于hash%lengh,但是&操作比%要快),对与操作有了解的同学应该都明白,当length为2的n次幂时,length-1的二进制表示是0111…111,它能够保证与hash值进行&操作后,使元素分配的更均匀,更合理。
从上面可以看到,HashMap有一个不断扩容的过程,如果map中元素很多,将不断进行size的扩充和元素的拷贝,对于性能肯定会有很大的影响,所以我们在开发的过程中,可以根据预估的数据量对HashMap进行合理的初始化操作。
4、Fail-Fast机制
我们知道java.util.HashMap不是线程安全的,因此如果在使用迭代器的过程中有其他线程修改了map,那么将抛出ConcurrentModificationException(如果是单线程遍历时,对map进行了修改,也会抛出ConcurrentModificationException,这个问题施嘉佳4月份邮件分享过),这就是所谓fail-fast策略。
这一策略在源码中的实现是通过modCount域,modCount顾名思义就是修改次数,对HashMap内容的修改都将增加这个值,那么在迭代器初始化过程中会将这个值赋给迭代器的expectedModCount。
modCount是修改的次数,在对map进行put/remove操作的时候,都会增加这个值。通过HashIterator源码我们可以看到,遍历时会判断当前的modCount和遍历开始时的modCount是否相等,如果不相等,则表示在遍历期间,map被修改了,直接抛出ConcurrentModificationException。
参考:
深入Java集合学习系列:HashMap的实现原理
HashMap深度分析
三顾java.util.HashMap
深入理解HashMap
我的iteye: https://www.wendangku.net/doc/e418035578.html,
数学与软件科学学院实验报告 学期:13至14__ 第_2 学期 2014年3月17 日 课程名称:编译原理专业:2011级5_班 实验编号:01 实验项目:词法分析器指导教师_王开端 姓名:张世镪学号: 2011060566 实验成绩: 一、目的 学习编译原理,词法分析是编译的第一个阶段,其任务是从左至右挨个字符地对源程序进行扫描,产生一个个单词符号,把字符串形式的源程序改造成单词符号串形式的中间程序。执行词法分析的程序称为词法分析程序,也称为词法分析器或扫描器。词法分析器的功能是输入源程序,输出单词符号 做一个关于C的词法分析器,C++实现 二、任务及要求 1.词法分析器产生下述C的单词序列 这个C的所有的单词符号,以及它们的种别编码和内部值如下表: -* / & <<=>>===!= && || , : ; { } [ ] ( ) ID和NUM的正规定义式为: ID→letter(letter | didit)* NUM→digit digit* letter→a | … | z | A | … | Z
digit→ 0 | … | 9 如果关键字、标识符和常数之间没有确定的算符或界符作间隔,则至少用一个空格作间隔。空格由空白、制表符和换行符组成。 三、大概设计 1. 设计原理 词法分析的任务:从左至右逐个字符地对源程序进行扫描,产生一个个单词符号。 理论基础:有限自动机、正规文法、正规式 词法分析器又称扫描器:执行词法分析的程序 2. 词法分析器的功能和输出形式 功能:输入源程序、输出单词符号 程序语言的单词符号一般分为以下五种:关键字、标识符、常数、运算符、界符。3. 输出的单词符号的表示形式: (单词种别,单词符号的属性值) 单词种别用整数编码,关键字一字一种,标识符统归为一种,常数一种,各种符号各一种。 4. 状态转换图实现
#include
编译原理-词法分析器的设计 一.设计说明及设计要求 一般来说,编译程序的整个过程可以划分为五个阶段:词法分析、语法分析、中间代码生成、优化和目标代码生成。本课程设计即为词法分析阶段。词法分析阶段是编译过程的第一个阶段。这个阶段的任务是从左到右一个字符一个字符地读入源程序,对构成源程序的字符流进行扫描和分解,从而识别出一个个单词(也称单词符号或符号)。如保留字(关键字或基本字)、标志符、常数、算符和界符等等。 二.设计中相关关键字说明 1.基本字:也称关键字,如C语言中的 if , else , while , do ,for,case,break, return 等。 2.标志符:用来表示各种名字,如常量名、变量名和过程名等。 3.常数:各种类型的常数,如12,6.88,和“ABC” 等。 4.运算符:如 + ,- , * , / ,%, < , > ,<= , >= 等。5.界符,如逗点,冒号,分号,括号,# ,〈〈,〉〉等。 三、程序分析 词法分析是编译的第一个阶段,它的主要任务是从左到右逐个字符地对源 程序进行 扫描,产生一个个单词序列,用以语法分析。词法分析工作可以是独立的一遍,把字符流的源程序变为单词序列,输出在一个中间文件上,这个文件做为语法分析程序的输入而继续编译过程。然而,更一般的情况,常将
词法分析程序设计成一个子程序,每当语法分析程序需要一个单词时,则 调用该子程序。词法分析程序每得到一次调用,便从源程序文件中读入一 些字符,直到识别出一个单词,或说直到下一个单词的第一个字符为止。 四、模块设计 下面是程序的流程图 五、程序介绍 在程序当前目录里建立一个文本文档,取名为infile.txt,所有需要分析的程序都写在此文本文档里,程序的结尾必须以“@”标志符结束。程序结果输出在同一个目录下,文件名为outfile.txt,此文件为自动生成。本程序所输出的单词符号采用以下二元式表示:(单词种别,单词自身的值)如程序输出结果(57,"#")(33,"include")(52,"<")(33,"iostream") 等。 程序的功能:(1)能识别C语言中所有关键字(共32个)(单词种别分别为1 — 32 ,详情见程序代码相关部分,下同) (2)能识别C语言中自定义的标示符(单词种别为 33) (3)能识别C语言中的常数(单词种别为0) (4)能识别C语言中几乎所有运算符(单词种别分别为41 — 54) (5)能识别C语言中绝大多数界符(单词种别分别为 55 — 66)六、运行结果 输入文件infile.txt 运行结果(输出文件 outfile.txt)
词法分析器实验报告 一、实验目的及要求 本次实验通过用C语言设计、编制、调试一个词法分析子程序,识别单词,实现一个C语言词法分析器,经过此过程可以加深对编译器解析单词流的过程的了解。 运行环境: 硬件:windows xp 软件:visual c++6.0 二、实验步骤 1.查询资料,了解词法分析器的工作过程与原理。 2.分析题目,整理出基本设计思路。 3.实践编码,将设计思想转换用c语言编码实现,编译运行。 4.测试功能,多次设置包含不同字符,关键字的待解析文件,仔细察看运行结果,检测该分析器的分析结果是否正确。通过最终的测试发现问题,逐渐完善代码中设置的分析对象与关键字表,拓宽分析范围提高分析能力。 三、实验内容 本实验中将c语言单词符号分成了四类:关键字key(特别的将main说明为主函数)、普通标示符、常数和界符。将关键字初始化在一个字符型指针数组*key[]中,将界符分别由程序中的case列出。在词法分析过程中,关键字表和case列出的界符的内容是固定不变的(由程序中的初始化确定),因此,从源文件字符串中识别出现的关键字,界符只能从其中选取。标识符、常数是在分析过程中不断形成的。 对于一个具体源程序而言,在扫描字符串时识别出一个单词,若这个单词的类型是关键字、普通标示符、常数或界符中之一,那么就将此单词以文字说明的形式输出.每次调用词法分析程序,它均能自动继续扫描下去,形成下一个单词,直到整个源程序全部扫描完毕,从而形成相应的单词串。 输出形式例如:void $关键字
流程图 、程序 流程图: 开始 输入源文件路径 路径是否有 效 是初始化文件指针 否 将字符加入字符数 组Word[] 是空格,空白或换 行吗 是字母吗是数字吗否否是界符吗否打开源文件 跳过该字符 是是 文件结束? 否 将字符加入字符数 组Word[] 否 将字符加入字符数组Word[] 是 指向下一字符识别指针内容 指向下一字符 是字母惑数字 吗 是 将word 与关键字表key 进行匹 配 否匹配?是输出word 为关键字 输出word 为普通标示符 否将字符加入字符数组Word[] 指向下一字符输出word 为常数 识别指针内容 回退 是数字吗 是 否输出word 为界符 指向下一字符 结束 是输出Word 内容为不可识别 将字符加入字符数组Word[]
词法分析器源代码 #include
public class Accept2 { public static StringBuffer stack=new StringBuffer("#E"); public static StringBuffer stack2=new StringBuffer("i+i*#"); public static void main(String arts[]){ //stack2.deleteCharAt(0); System.out.print(accept(stack,stack2)); } public static boolean accept(StringBuffer stack,StringBuffer stack2){//判断识别与否 boolean result=true; outer:while (true) { System.out.format("%-9s",stack+""); System.out.format("%9s",stack2+"\n"); char c1 = stack.charAt(stack.length() - 1); char c2 = stack2.charAt(0); if(c1=='#'&&c2=='#') return true; switch (c1) {
case'E': if(!E(c2)) {result=false;break outer;} break; case'P': //P代表E’if(!P(c2)) {result=false;break outer;} break; case'T': if(!T(c2)) {result=false;break outer;} break; case'Q': //Q代表T’if(!Q(c2)) {result=false;break outer;} break; case'F': if(!F(c2)) {result=false;break outer;} break; default: {//终结符的时候 if(c2==c1){ stack.deleteCharAt(stack.length()-1); stack2.deleteCharAt(0); //System.out.println(); } else{
语法分析器(含完整源 码)
语法分析实验报告 一、实验目的: 1. 了解单词(内部编码)符号串中的短语句型结构形成规律。 2. 理解和掌握语法分析过程中语法分析思想(LL,LR)的智能算法化方法。 二、实验内容: 构造自己设计的小语言的语法分析器: 1. 小语言的语法描述(语法规则)的设计即文法的设计; 2. 把文法形式符号中所隐含的信息内容挖掘出来并用LL或LR 的资料形式(分析表)表示出来; 3. 语法分析的数据输入形式和输出形式的确定; 4. 语法分析程序各个模块的设计与调试。 主要设备和材料:电脑、winxp操作系统、VC语言系统 三、实验分工:
081 四、实验步骤: 1、语法规则 ①<程序>::= {<变量定义语句>|<赋值语句>|<条件语句> |<循环语句> } ②<变量定义语句>::=var 变量{,变量}; ③<赋值语句>::=变量:= <表达式>; ④<表达式>::=标识符{运算符标识符}; ⑤<标识符>::=变量|常量 ⑥<运算符>::=+ | - | * | / | >= | <= ⑦<条件语句>::=
给同学们的一段话 《编译原理》计算机软件专业的一门重要专业课程。该课程系统地向学生介绍编译程序的结构、工作流程及编译程序各组成部分的设计原理和实现技术。由于该课程理论性和实践性都比较强,内容较为抽象复杂,涉及到大量的软件设计算法,因此,一直是一门比较难学的课程。为了使学生更好地理解和掌握编译技术的基本概念、基本原理和实现方法,实践环节非常重要,只有通过上机进行程序设计,才能使学生对比较抽象的教学内容产生具体的感性认识,增强学生综合分析问题、解决问题的能力,并对提高学生软件设计水平大有益处。 编译原理涉及词法分析,语法分析,语义分析及优化设计等各方面。词法分析阶段是编译过程的第一个阶段,是编译的基础。这个阶段的任务是从左到右一个字符一个字符地读入源程序,即对构成源程序的字符流进行扫描然后根据构词规则识别单词(也称单词符号或符号)。从左到右逐个字符对构成源程序的字符串进行扫描,依据词法规则,识别出一个一个的标记(token),把源程序变为等价的标记串序列。执行词法分析的程序称为词法分析器,也称为扫描器。本例题是一个词法分析的设计,采用C++代码实现。 希望大家复习回顾以前学习的《C++程序设计》课程相关知识。 一、设计内容和要求 1、设计内容 对C语言的一个子集设计并实现一个简单的词法分析器,掌握利用状态转换图设计词法分析器的基本方法。 2、设计要求 利用该词法分析器完成对源程序字符串的词法分析。输出形式是源程序的单词符号二元式的代码,并保存到文件中。 (1) 假设该语言中的单词符号及种别编码如下表所示。 单词符号及种别编码 单词符号种别编码单词符号种别编码 main 1 [ 28 int 2 ] 29 char 3 { 30
词法分析实验报告 一、实验目的与要求: 1、了解字符串编码组成的词的涵,感觉一下字符串编码的方法和解读 2、了解和掌握自动机理论和正规式理论在词法分析程序和控制理论中的应用 二、实验容: 构造一个自己设计的小语言的词法分析器: 1、这个小语言能说明一些简单的变量 识别诸如begin,end,if,while等保留字;识别非保留字的一般标识符(有下划线、字符、数字,且第一个字符不能是数字)。识别数字序列(整数和小数);识别:=,<=,>=之类的特殊符号以及;,(,)等界符。 2、相关过程(函数): Scanner()词法扫描程序,提取标识符并填入display表中 3、这个小语言有顺序结构的语句 4、这个小语言能表达分支结构的语句 5、这个小语言能够输出结果 总之这个小语言词法分析器能提供以上所说明到的语法描述的功能…… 三、实验步骤: 1、测试评价 (1)、测试1:能说明一些简单的变量,如关键字、一般标识符、界符等; (2)、测试2:能输出结果:单词符号(码形式)、各种信息表(如符号表、常量表等);(3)、测试程序: var x,y,z; begin x:=2; y:=3; if (x+5>=y*y) then begin z:=y*y-x; z:=z+x*x; end else z:=x+y;
prn z; end. (4)、结果: ①、从键盘读入; 部分结果如下:
(类型:该标识符所属的类型,如关键字,变量等;下标:该标识符所对应表(如变量标识符表,常量标识符表等)中其相应的位置,下同) ②、从文件读入,输出到文件; 部分结果如下:
其他测试及结果如下:
北华航天工业学院 《编译原理》课程实验报告 课程实验题目:词法分析器实验 作者所在系部:计算机科学与工程系作者所在专业:计算机科学与技术 作者所在班级:B08512 作者学号:18 作者姓名:李桂丁 指导教师姓名:李建义 完成时间:2010年3月26日
一、实验目的 了解词法分析程序的两种设计方法:1.根据状态转换图直接编程的方式;2.利用DFA 编写通用的词法分析程序。 二、实验内容及要求 1.根据状态转换图直接编程 编写一个词法分析程序,它从左到右逐个字符的对源程序进行扫描,产生一个个的单词的二元式,形成二元式(记号)流文件输出。在此,词法分析程序作为单独的一遍,如下图所示。 具体任务有: (1)组织源程序的输入 (2)拼出单词并查找其类别编号,形成二元式输出,得到单词流文件 (3)删除注释、空格和无用符号 (4)发现并定位词法错误,需要输出错误的位置在源程序中的第几行。将错误信息输出到屏幕上。 (5)对于普通标识符和常量,分别建立标识符表和常量表(使用线性表存储),当遇到一个标识符或常量时,查找标识符表或常量表,若存在,则返回位置,否则返回0并且填写符号表或常量表。 标识符表结构:变量名,类型(整型、实型、字符型),分配的数据区地址 注:词法分析阶段只填写变量名,其它部分在语法分析、语义分析、代码生成等阶段逐步填入。 常量表结构:常量名,常量值 2.能对任何S语言源程序进行分析 在运行词法分析程序时,应该用问答形式输入要被分析的S源语言程序的文件名,然后对该程序完成词法分析任务。 3.能检查并处理某些词法分析错误 词法分析程序能给出的错误信息包括:总的出错个数,每个错误所在的行号,错误的编号及错误信息。 4. 本实验要求处理以下两种错误(编号分别为1,2): 1:非法字符:单词表中不存在的字符处理为非法字符,处理方式是删除该字符,给出错误信息,“某某字符非法”。 2:源程序文件结束而注释未结束。注释格式为:/* …… */
语法分析器 LEX代码段: %{ #include
%{ #include
实验词法分析器含源代 码 GE GROUP system office room 【GEIHUA16H-GEIHUA GEIHUA8Q8-
词法分析器实验报告 一、实验目的及要求 本次实验通过用C语言设计、编制、调试一个词法分析子程序,识别单词,实现一个C语言词法分析器,经过此过程可以加深对编译器解析单词流的过程的了解。 运行环境: 硬件:windows xp 软件:visual c++6.0 二、实验步骤 1.查询资料,了解词法分析器的工作过程与原理。 2.分析题目,整理出基本设计思路。 3.实践编码,将设计思想转换用c语言编码实现,编译运行。 4.测试功能,多次设置包含不同字符,关键字的待解析文件,仔细察看运行结果,检测该分析器的分析结果是否正确。通过最终的测试发现问题,逐渐完善代码中设置的分析对象与关键字表,拓宽分析范围提高分析能力。 三、实验内容 本实验中将c语言单词符号分成了四类:关键字key(特别的将main说明为主函数)、普通标示符、常数和界符。将关键字初始化在一个字符型指针数组*key[]中,将界符分别由程序中的case列出。在词法分析过程中,关键字表和case列出的界符的内容是固定不变的(由程序中的初始化确定),因此,从源文件字符串中识别出现的关键字,界符只能从其中选取。标识符、常数是在分析过程中不断形成的。 对于一个具体源程序而言,在扫描字符串时识别出一个单词,若这个单词的类型是关键字、普通标示符、常数或界符中之一,那么就将此单词以文字说明的形式输出.每次调用词法分析程序,它均能自动继续扫描下去,形成下一个单词,直到整个源程序全部扫描完毕,从而形成相应的单词串。
一、实验目的 设计、编制并调试一个语法分析程序,加深对语法分析原理的理解。 二实验要求 要求语法分析器的输入是单词串(含词的字符串形式、在源文件中的起止位置、 词的类别),输出是源程序中各句子的单词起止编号、句子的语法树。 三实验内容 以下不同语法分析器中任选一个: 1. 2. 3. 4. 递归下降分析器。可分解为:文法输入及解析、消除左递归、提取左公 共因子、产生式匹配。 LL(1)分析器。可分解为:文法输入及解析、分析表构造(含 SELECT 集 求解)、主控程序、语法树展示。 算符优先文法分析器。可分解为:文法输入及解析、分析表构造、主控 程序、语法树展示。 LR(1)分析器。可分解为:文法输入及解析、分析表构造(含项目及项目 簇集求解)、主控程序、语法树展示。 四、实验步骤 给定的文法G[E] E->TE' E'->+TE' | £ T->FT' T'->*F T ' | £ F->(E) | i 采用递归下降分析法编写语法分析程序及 LL (1)语法分析法编写语法分析程序。 实验代码: #in clude
语法分析实验报告 一、实验目的: 1. 了解单词(内部编码)符号串中的短语句型结构形成规律。 2. 理解和掌握语法分析过程中语法分析思想(LL,LR)的智能算法化方法。 二、实验内容: 构造自己设计的小语言的语法分析器: 1. 小语言的语法描述(语法规则)的设计即文法的设计; 2. 把文法形式符号中所隐含的信息内容挖掘出来并用LL或LR 的资料形式(分析表)表示出来; 3. 语法分析的数据输入形式和输出形式的确定; 4. 语法分析程序各个模块的设计与调试。 主要设备和材料:电脑、winxp操作系统、VC语言系统 三、实验分工: 学号姓名实验分工 08 实验代码设计及编写 08150 检查校对代码 0815 写电子版实验报告
08150 查找、分析、整理资料 08150 查找、分析、整理资料 08050 0815 081 四、实验步骤: 1、语法规则 ①<程序>::= {<变量定义语句>|<赋值语句>|<条件语句> |<循环语句> } ②<变量定义语句>::=var 变量{,变量}; ③<赋值语句>::=变量:= <表达式>; ④<表达式>::=标识符{运算符标识符}; ⑤<标识符>::=变量|常量 ⑥<运算符>::=+ | - | * | / | >= | <= ⑦<条件语句>::=
编译原理实验报告 ******************************************************************************* ******************************************************************************* PL0语言功能简单、结构清晰、可读性强,而又具备了一般高级程序设计语言的必须部分,因而PL0语言的编译程序能充分体现一个高级语言编译程序实现的基本方法和技术。PL/0语言文法的EBNF表示如下: <程序>::=<分程序>. <分程序> ::=[<常量说明>][<变量说明>][<过程说明>]<语句> <常量说明> ::=CONST<常量定义>{,<常量定义>}; <常量定义> ::=<标识符>=<无符号整数> <无符号整数> ::= <数字>{<数字>} 】 <变量说明> ::=VAR <标识符>{, <标识符>}; <标识符> ::=<字母>{<字母>|<数字>} <过程说明> ::=<过程首部><分程序>{; <过程说明> }; <过程首部> ::=PROCEDURE <标识符>; <语句> ::=<赋值语句>|<条件语句>|<当循环语句>|<过程调用语句> |<复合语句>|<读语句><写语句>|<空> <赋值语句> ::=<标识符>:=<表达式> <复合语句> ::=BEGIN <语句> {;<语句> }END <条件语句> ::= <表达式> <关系运算符> <表达式> |ODD<表达式> <表达式> ::= [+|-]<项>{<加法运算符> <项>} ; <项> ::= <因子>{<乘法运算符> <因子>} <因子> ::= <标识符>|<无符号整数>| ‘(’<表达式>‘)’ <加法运算符> ::= +|- <乘法运算符> ::= *|/ <关系运算符> ::= =|#|<|<=|>|>= <条件语句> ::= IF <条件> THEN <语句> <过程调用语句> ::= CALL 标识符 <当循环语句> ::= WHILE <条件> DO <语句> <读语句> ::= READ‘(’<标识符>{,<标识符>}‘)’ <写语句> ::= WRITE‘(’<表达式>{,<表达式>}‘)’ ¥ <字母> ::= a|b|…|X|Y|Z <数字> ::= 0|1|…|8|9 【预处理】 对于一个pl0文法首先应该进行一定的预处理,提取左公因式,消除左递归(直接或间接),接着就可以根据所得的文法进行编写代码。
一.实验目的 1.深入理解有限自动机及其应用 2.掌握根据语言的词法规则构造识别其单词的有限自动机的方法 3.基本掌握词法分析程序的开发。 二.实验内容及要求 1、词法分析器的功能和输出格式 词法分析器的功能是输入源程序,输出单词符号。词法分析器的单词符号常常表示 成以下的二元式(单词种别码,单词符号的属性值)。本实验中,采用的是一类符号 一种别码的方式。 2、单词的BNF表示 <标识符>-> <字母><字母数字串> <字母数字串>-><字母><字母数字串>|<数字><字母数字串>| <下划线><字母数字串>|ε <无符号整数>-> <数字><数字串> <数字串>-> <数字><数字串> |ε <加法运算符>-> + <减法运算符>-> - <大于关系运算符>-> > <大于等于关系运算符>-> >= 3、“超前搜索”方法 词法分析时,常常会用到超前搜索方法。如当前待分析字符串为“a>+”,当前字符为’>’,此时,分析器倒底是将其分析为大于关系运算符还是大于等于关系运算符呢? 显然,只有知道下一个字符是什么才能下结论。于是分析器读入下一个字符’+’,这时可知应将’>’解释为大于运算符。但此时,超前读了一个字符’+’,所以要回退一个字符,词法分析器才能正常运行。在分析标识符,无符号整数等时也有类似情况。 4、模块结构
5.程序思路 这里以开始定义的C语言子集的源程序作为词法分析程序的输入数据。在词法分析中,自文件头开始扫描源程序字符,一旦发现符合“单词”定义的源程序字符串时,将它翻译成固定长度的单词内部表示,并查填适当的信息表。经过词法分析后,源程序字符串(源程序的外部表示)被翻译成具有等长信息的单词串(源程序的内部表示),并产生两个表格:常数表和标识符表,它们分别包含了源程序中的所有常数和所有标识符。 0.定义部分:定义常量、变量、数据结构。 1.初始化:从文件将源程序全部输入到字符缓冲区中。
郑州轻工业学院 编译原理课程设计总结报告 设计题目:词法分析器(语法分析器) 学生姓名: 系别: 专业: 班级: 学号: 指导教师: 20013年6 月2日
目录 一、设计题目 (3) 二、运行环境(软、硬件环境) (3) 三、算法设计的思想 (3) 四、算法流程图 (5) 五、算法设计分析 (5) 六、源代码 (6) 七、运行结果 (11) 八、收获及体会 (12)
(一)设计题目 词法分析器 (二)运行环境 Visual C++.6.0 (三)算法设计的思想 各种单词符号对应的种别码: 算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。 1.主程序示意图: 主程序示意图如下;其中初值包括如下两个方面:
(1)关键字表的初值。 关键字作为特殊标示符处理,把它们预先安排到一张表格中 (称为关键字表),当扫描程序识别出标识符时,查关键字表。 如果能查到匹配的单词,则该单词为关键字,否则为一般的标 识符。关键字表为一个字符串数组,其描述如下: Char*rwtab[6]={“begin”,”if”,”then”,”while”,”do”,”end”}; (2)程序需要用到的主要变量为syn,token和sum。 2.扫描子程序的算法思想 首先设置3个变量:(1)token用来存放构成单词符号的字符串;(2)sum 用来存放整型单词(3)syn用来存放单词符号的种别码。
(五)算法设计分析 算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。 其中初值包括如下两个方面:(一)关键字表的初值。关键字作为特殊标示符处理,把它们预先安排到一张表格中(称为关键字表),当扫描程序识别出标识符时,查关键字表。如果能查到匹配的单词,则该单词为关键字,否则为一般的标识符。关键字表为一个字符串数组,其描述如下:Char*rwtab[6]={“begin”,”if”,”then”,”while”,”do”,”end”}; (2)程序需要用到的主要变量为syn,token和sum。 2.扫描子程序的算法思想
实验二词法分析器 一、实验要求 为给定编程语言设计词法分析器 二、实验材料 1、单词结构 ?注释:以“//”开头到该行尾部为注释 ?关键字(共6个):int real if then else while ?标识符:以字母开头,后跟字母或数字的符号串,最长为64个字符。(注意:关键字不是标识符)?操作符(共11个):+ - / * = == < <= > >= != ?分隔符(共5个):( ) { } ; ?数字(用正规式描述): digit ← 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 整数← digit+ (最大整数为231) exponent ← E ( + | - | ε ) digit+ (最大指数为128) fraction ← . digit+ 实数← digit+ exponent | digit+ fraction ( exponent | ε ) 2、词法分析器要求 将词法分析部分设计为一个子程序(以备随后的语法分析器调用)。 输入:input.txt,其内容为指定编程语言的一段程序代码。 输出:output.txt,其内容为四元组形式(单词类型,单词本身,行号,列号),output文件中的每一行对应一个单词的信息。四元组形式中,第一项为单词类型,第二项为单词本身,第三项为单词所在的行号,第四项为单词所在的列号。 注意:词法分析器需要滤掉注释,即在词法分析过程中遇到注释则跳过,继续分析随后的单词信息,词法分析器的输出信息中不含注释。 三、实验提示 1、对于设计词法分析器来说,首先应明确词法分析器是做什么的,然后进行分析和设计, 最后编程实现并测试。即先分析问题,再想解决问题的办法,然后再着手解决问题。2、编程实现词法分析器后,是否进行了测试?特别是,你设计的词法分析器能否滤掉注 释?能否识别小数? 3、在进行词法分析时,会遇到什么样的错误?词法分析器能否识别这些错误?当遇到这些 错误后,词法分析器如何继续进行分析? 四、实验提交资料 1、词法分析器设计思路.doc,其内容包含各类单词的DFA描述、词法分析器的处理流程 等; 2、词法分析器源程序; 3、测试输入文件input.txt及词法分析输出文件output.txt。 这三类资料打包,文件名命名为“学号姓名实验二”,上交至邮箱:tlf1220@https://www.wendangku.net/doc/e418035578.html,。 DO IT YOURSELF – CHEATING WILL BE PUNISHED
词法分析器实验报告
实验目的: 设计、编制、调试一个词法分析子程序-识别单词,加深对词法分析原理的理解。 功能描述: 该程序要实现的是一个读单词过程,从输入的源程序中,识别出各个具有独立意义的单词,即基本保留字、标识符、常数、运算符、分隔符五大类。并依次输出各个单词的部编码及单词符号自身值。(遇到错误时可显示“Error!”,然后跳过错误部分继续进行) 设计思想: 设计该词法分析器的过程中虽然没有实际将所有的状态转移表建立出来,但是所用的思想是根据状态转移表实现对单词的识别。首先构造一个保留字表,然后,每输入一个字符就检测应该进入什么状态,并将该字符连接到d串后继续输入,如此循环,最后根据所在的接受状态以及保留字表识别单词。 符号表:
状态转换图: ①标识符及保留字: letter or digitt ②number:
④ 分隔符:digit digit digit other other ) * ) ) ) (>, 2) (:=,2)
⑤ 使用环境: Windows xp下的visual c++6.0 程序测试: input1 : int a,b;
a=b+2; input2: while(a>=0) do 7x=x+6.7E+23; end; input3: begin: x:=9 if x>0 then x:=x+1; while a:=0 do b:=2*x/3,c:=a; end; output1: 3,int 3,a 5,, 3,b 5,; 3,a 2,= 3,b 2,+ 4,2 5,; output2: 1,while 5,( 3,a 2,>= 4,0 5,) 1,do error line 3 2,= 3,x 2,+ 4,6.7E+23 5,; 1,end 5,; output3: 1,begin error line 1 3,x 2,:= 4,9 1,if 3,x 2,> 4,0 1,then 3,x 2,:= 3,x 2,+ 4,1 5,; 1,while 3,a 2,:= 4,0 1,do 3,b 2,:= 4,2 2,* 3,x 2,/ 4,3 5,, 3,c 2,:= 3,a 5,; 1,end 5,;
源程序 package Analyer; import java.io.File; import java.io.FileReader; import java.io.BufferedReader; import java.io.FileNotFoundException; import java.io.IOException; import java.util.ArrayList; import java.util.HashMap; public class analyetest { public ArrayList bracket; public ArrayList keyword; public ArrayList symbol; public ArrayList semicolon; public ArrayList operator; static HashMap BRACKET; static HashMap KEYWORD; static HashMap SEMICOLON; static HashMap OPERATOR; public analyetest() { this.KEYWORD = new HashMap(); this.BRACKET = new HashMap(); this.SEMICOLON = new HashMap(); this.OPERATOR = new HashMap(); this.bracket = new ArrayList(); this.keyword = new ArrayList(); this.symbol = new ArrayList(); this.semicolon = new ArrayList(); this.operator = new ArrayList(); }
- 语法分析器(基于mini-C的源程序)
- 词法分析器源代码
- 编译原理课程设计-词法分析器(附含源代码)
- 编译原理-LR语法分析器的控制程序实验报告
- 语法分析器(含完整源码)教学文稿
- 编译原理实验-(词法语法分析-附源代码
- 编译原理词法分析器c++源程序
- 编译原理词法分析去语法分析器C语言代码
- 编译原理词法分析器C源代码
- 编译原理LR语法分析器的控制程序实验报告(整理).pptx
- 编译原理实验 (词法语法分析 附源代码
- 编译原理-LL(1)文法源代码(实验三)
- 词法分析器实验报告及源代码
- 编译原理词法语法语义分析器设计
- 编译原理 LL(1)语法分析器java版 完整源代码
- 语法分析器(含完整源码)
- 编译原理上机源代码LR语法分析器
- 语法分析源代码分析报告
- 编译原理课程设计-词法分析器(附含源代码)
- 词法分析器(含完整源码)