环境小卫星多光谱数据预处理方法
环境小卫星多光谱数据数据预处理
【裁剪、配准、FLAASH精确大气校正】
第一步:安装环境小卫星数据处理补丁
使用HJ-1数据读取补丁
拷贝该sav 文件到ENVI安装目录的save_add 目录下
启动ENVI->File->Open External File 有HJ-1A1B选项即为安装成功
第二步:数据读取和定标
主菜单->File->Open External File->HJ-1A1B,打开环境小卫星数据读取补丁。
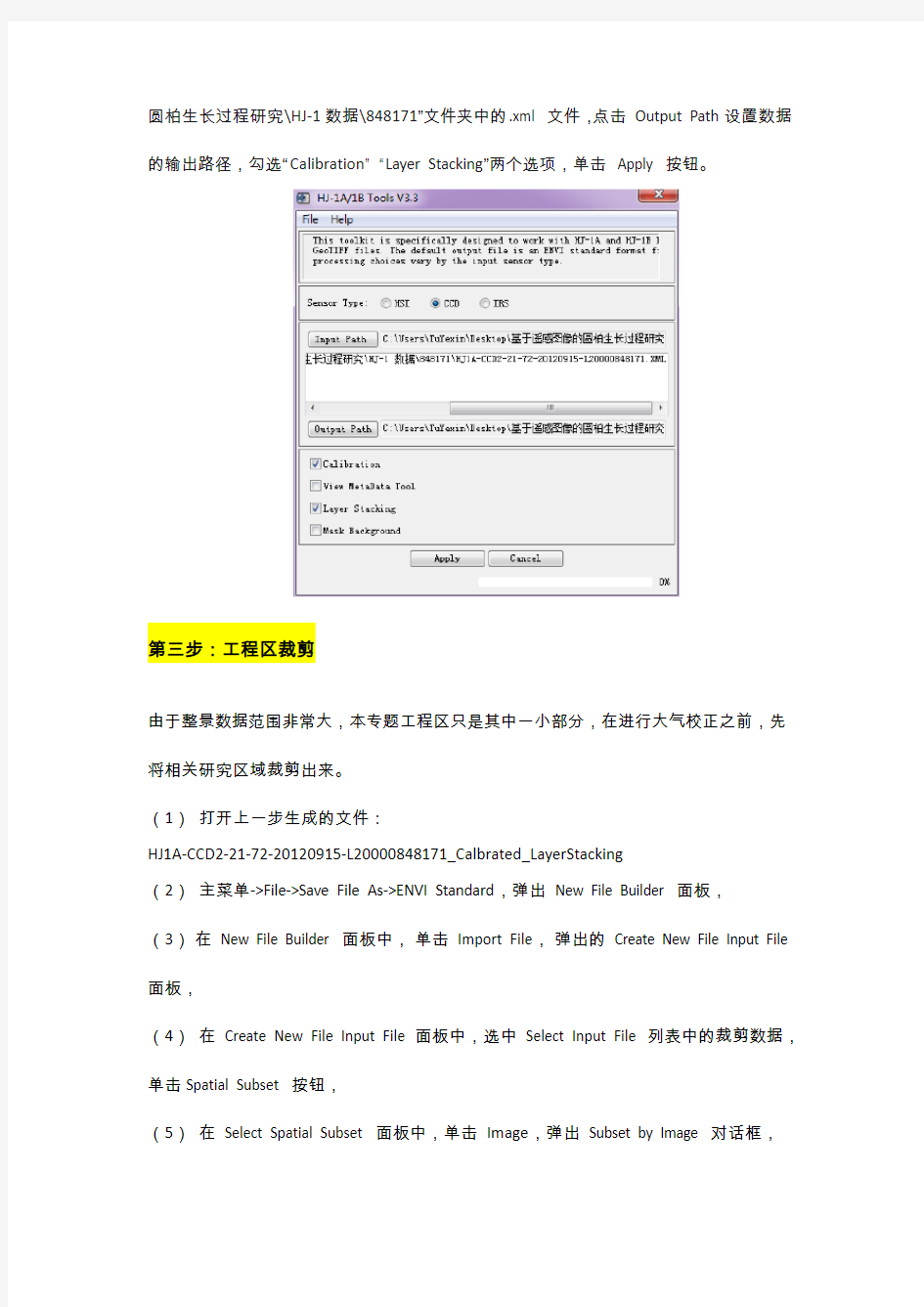
在HJ-1A/1B Tools V3.3 面板中,选择CCD,点击Input File 输入“\基于遥感图像的
圆柏生长过程研究\HJ-1数据\848171”文件夹中的.xml 文件,点击Output Path设置数据的输出路径,勾选“Calibration”“Layer Stacking”两个选项,单击Apply 按钮。
第三步:工程区裁剪
由于整景数据范围非常大,本专题工程区只是其中一小部分,在进行大气校正之前,先将相关研究区域裁剪出来。
(1)打开上一步生成的文件:
HJ1A-CCD2-21-72-20120915-L20000848171_Calbrated_LayerStacking
(2)主菜单->File->Save File As->ENVI Standard,弹出New File Builder 面板,
(3)在New File Builder 面板中,单击Import File,弹出的Create New File Input File 面板,
(4)在Create New File Input File 面板中,选中Select Input File 列表中的裁剪数据,单击Spatial Subset 按钮,
(5)在Select Spatial Subset 面板中,单击Image,弹出Subset by Image 对话框,
(6)在Subset by Image 对话框中,按住鼠标左键拖动图像中的红色矩形框确定裁剪区域,裁剪出相关的区域,单击OK,
(7)在Select Spatial Subset 面板中,可以看到裁剪区域信息,单击OK,
(8)在Create New File Input File 对话框中,单击OK,
(9)在New File Builder,单击Choose 设置输出文件名“裁剪”及路径,单击OK。
完成相关区域的裁剪。
第四步:大气校正
环境小卫星提供了波谱响应函数,以文本形式提供,第一列表示波长(nm),后面四列分别表示4个波段对应波长的波谱响应值。需要制作波谱曲线来描述波谱响应函数,用于大气矫正。
1)制作波谱曲线
(1)主菜单Window→Start New Plot Window,打开ENVI→Plot Window面板,在波谱绘制窗口中,选择File→Input Data→ASCII,导入”HJ1A-CCD2-光谱响应函数.txt”文本文件,如图所示,自动将第一列作为X轴,后面4列作为Y轴,波长单位选择nanometers,单击OK。
(2)如图,在绘制窗口生成了4条曲线,选择Edit→Data Parameters,编辑每条线的名称为b1,b2,b3,b4,便于区分。
(3)选择File→Save Plot As→Spectral Library,在Output Plot to Spectral Library面板中,单击Select All Items,单击OK。
(4)在Output Plot to Spectral Library面板中,有输出曲线相关参数设置,按默认,选择输出路径和文件名,单击OK,将波谱曲线保存为波谱库文件:环境1A星CCD2光谱响应.sli。
2)FLAASH大气矫正
(1)数据准备
FLAASH 对图像文件有以下几个要求:
①数据是经过定标后的辐射亮度(辐射率)数据,单位是:(μW)/(cm2*nm*sr)。
②数据带有中心波长(wavelenth)值,如果是高光谱还必须有波段宽度(FWHM),这两个参数都可以通过编辑头文件信息输入(Edit Header)。
③数据类型:支持四种数据类型:浮点型(floating)、长整型(long integer )、整型(integer)和无符号整型(unsigned int)。数据存储类型:ENVI 标准栅格格式文件,且是BIP 或者BIL。
④波谱范围:400-2500nm。
本次用的环境小卫星经过以上处理,已经定标为W*m^(-2)*sr^(-1)*um^(-1)单位、浮点型的辐射率数据,有中心波长信息,下面将BSQ 格式转成BIL 格式。
选择主菜单Basic Tools→Convert Data(BSQ,BIL,BIP),选择已经经过定标和配准的数据裁剪.img,在Convert File Parameters 中,Output Interleave 选择BIL,选择Convert In Place:yes,单击OK。
(2)设置参数进行FLAASH 大气校正
①主菜单Spectral FLAASH, 打开FLAASH 大气校正模块;
②点击Input Radiance Image,选择BIL 格式的环境小卫星数据裁剪.img,在Radiance Scale Factors 面板中选择Use single scale factor for all bands,由于定标的辐射量数据与FLAASH 的辐射亮度的单位相差10 倍,所以在此Single scale factor 选择默认:10【通过定标的辐射量数据与FLAASH 的辐射亮度的单位换算,可知二者相差10倍,故Single scale factor 选择10】,单击OK;
③设置输出文件及路径设置
④传感器基本信息设置:
成像中心点经纬度、传感器高度、成像区域平均高度、成像时间设置,这些都可以
从数据头文件中读取HJ1A-CCD2-21-72-20120915-L20000848171.XML。
【传感器高度(Sensor Altitude):650km
像元大小(Pixel Size):30m
地面高程(Ground elevation):0.05km】
【备注:Flight Date 参照影像文件夹相应XML文件】
⑤大气模型(Atmospheric Model),选择MLS,
气溶胶模型(Aerosol Model),选择Rural,
气溶胶反演方法(Aerosol Retrieval),选择None,
能见度(Initial Visibility)设置为40km。
【备注:大气模型根据经纬度和日期来定】
⑥单击Multispectral Setting 按钮,在Filter Function File 导入之前做好的光谱响应曲线“环境1A星CCD2光谱响应.sli”,单击OK;
⑦单击Advanced Settings,在高级设置中,Tile Size 默认的是Cash size 的大小,手动改为100Mb,单击OK;
⑧设置好后,在大气校正模块面板中,单击Apply。
⑨大气校正完成后,检查大气校正的结果,分别显示校正前后的图像,主菜单上选择Display->spectral Profile 打开光谱曲线窗口,显示两幅图像同一位置的光谱曲线图,如下图。
第五步:图像配准
下面以谷歌卫星地图作为基准影像对环境小卫星图像进行图像配准。
1、谷歌卫星地图的下载
(1)安装文件夹中全能地图下载器
(2)
2、ENVI配准的步骤
(1)分别打开和显示基准影像。
(2)主菜单->Map->Registration->Select GCPs:Image to Image,打开几何校正模块。
(3)选择显示2006 年土地利用分类图文件的Display 为基准影像(Base Image),显示环境星文件的Display 为待校正影像(Warp Image),点击OK 进入采集地面控
制点。
(4)打开Tools->Link->Geografic link,将两个窗口都选择为on,单击确定,找到定位的大致区域后,再Tools->Link->Geografic link,改为off,关闭链接。
(5)在两个Display 中找到相同区域,在Zoom 窗口中,点击左小下角第三个按钮,打开定位十字光标,将十字光标到相同点上,点击Ground Control Points Selection 上的Add Point 按钮,将当前找到的点加入控制点列表。
(6)用同样的方法继续寻找其余的点,当选择控制点的数量达到3 时,RMS 被自动计算。Ground Control Points Selection 上的Predict 按钮可用,选择Options->Auto Predict,打开自动预测功能。这时在Base Image上面定位点,Warp Image上会自动预测区域。
(7)完成控制点的选择,RMS 值小于1 个像素,点击Ground Control Points Selection 上的File->Save Coefficients to ASCII,将控制点保存。
(8)在Ground Control Points Selection 上,选择Options-> Warp File (as Image Map) ,选择校正文件(HJ 数据文件)。
(9)在校正参数面板中,默认投影参数和像元大小与基准影像一致,30 米。
(10)重采样选择Nearest Neighor,背景值(Background)为0.
(11)Output Image Extent:默认是根据基准图像大小计算,可以做适当的调整。
(12)选择输出路径和文件名,单击Ok 按钮。
大数据处理常用技术简介
大数据处理常用技术简介 storm,Hbase,hive,sqoop, spark,flume,zookeeper如下 ?Apache Hadoop:是Apache开源组织的一个分布式计算开源框架,提供了一个分布式文件系统子项目(HDFS)和支持MapReduce分布式计算的软件架构。 ?Apache Hive:是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,通过类SQL语句快速实现简单的MapReduce 统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。 ?Apache Pig:是一个基于Hadoop的大规模数据分析工具,它提供的SQL-LIKE语言叫Pig Latin,该语言的编译器会把类SQL的数据分析请求转换为一系列经过优化处理的MapReduce运算。 ?Apache HBase:是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。 ?Apache Sqoop:是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。 ?Apache Zookeeper:是一个为分布式应用所设计的分布的、开源的协调服务,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,简化分布式应用协调及其管理的难度,提供高性能的分布式服务?Apache Mahout:是基于Hadoop的机器学习和数据挖掘的一个分布式框架。Mahout用MapReduce实现了部分数据挖掘算法,解决了并行挖掘的问题。 ?Apache Cassandra:是一套开源分布式NoSQL数据库系统。它最初由Facebook开发,用于储存简单格式数据,集Google BigTable的数据模型与Amazon Dynamo的完全分布式的架构于一身 ?Apache Avro:是一个数据序列化系统,设计用于支持数据密集型,大批量数据交换的应用。Avro是新的数据序列化格式与传输工具,将逐步取代Hadoop原有的IPC机制 ?Apache Ambari:是一种基于Web的工具,支持Hadoop集群的供应、管理和监控。 ?Apache Chukwa:是一个开源的用于监控大型分布式系统的数据收集系统,它可以将各种各样类型的数据收集成适合Hadoop 处理的文件保存在HDFS 中供Hadoop 进行各种MapReduce 操作。 ?Apache Hama:是一个基于HDFS的BSP(Bulk Synchronous Parallel)并行计算框架, Hama可用于包括图、矩阵和网络算法在内的大规模、大数据计算。
影像预处理
遥感影像预处理 预处理是遥感应用的第一步,也是非常重要的一步。目前的技术也非常成熟,大多数的商业化软件都具备这方面的功能。预处理的大致流程在各个行业中有点差异,而且注重点也各有不同。 本小节包括以下内容: ? ? ●数据预处理一般流程介绍 ? ? ●预处理常见名词解释 ? ? ●ENVI中的数据预处理 1、数据预处理一般流程 数据预处理的过程包括几何精校正、配准、图像镶嵌与裁剪、去云及阴影处理和光谱归一化几个环节,具体流程图如图所示。 图1数据预处理一般流程
各个行业应用会有所不同,比如在精细农业方面,在大气校正方面要求会高点,因为它需要反演;在测绘方面,对几何校正的精度要求会很高。 2、数据预处理的各个流程介绍 (一)几何精校正与影像配准 引起影像几何变形一般分为两大类:系统性和非系统性。系统性一般有传感器本身引起的,有规律可循和可预测性,可以用传感器模型来校正;非系统性几何变形是不规律的,它可以是传感器平台本身的高度、姿态等不稳定,也可以是地球曲率及空气折射的变化以及地形的变化等。 在做几何校正前,先要知道几个概念: 地理编码:把图像矫正到一种统一标准的坐标系。 地理参照:借助一组控制点,对一幅图像进行地理坐标的校正。 图像配准:同一区域里一幅图像(基准图像)对另一幅图像校准影像几何精校正,一般步骤如下, (1)GCP(地面控制点)的选取 这是几何校正中最重要的一步。可以从地形图(DRG)为参考进行控制选点,也可以野外GPS测量获得,或者从校正好的影像中获取。选取得控制点有以下特征:
1、GCP在图像上有明显的、清晰的点位标志,如道路交叉点、河流交叉点等; 2、地面控制点上的地物不随时间而变化。 GCP均匀分布在整幅影像内,且要有一定的数量保证,不同纠正模型对控制点个数的需求不相同。卫星提供的辅助数据可建立严密的物理模型,该模型只需9个控制点即可;对于有理多项式模型,一般每景要求不少于30个控制点,困难地区适当增加点位;几何多项式模型将根据地形情况确定,它要求控制点个数多于上述几种模型,通常每景要求在30-50个左右,尤其对于山区应适当增加控制点。 (2)建立几何校正模型 地面点确定之后,要在图像与图像或地图上分别读出各个控制点在图像上的像元坐标(x,y)及其参考图像或地图上的坐标(X,Y),这叫需要选择一个合理的坐标变换函数式(即数据校正模型),然后用公式计算每个地面控制点的均方根误差(RMS) 根据公式计算出每个控制点几何校正的精度,计算出累积的总体均方差误差,也叫残余误差,一般控制在一个像元之内,即RMS<1。 (3)图像重采样
大数据处理技术的特点
1)Volume(大体量):即可从数百TB到数十数百PB、 甚至EB的规模。 2)Variety(多样性):即大数据包括各种格式和形态的数据。 3)Velocity(时效性):即很多大数据需要在一定的时间限度下得到及时处理。 4)Veracity(准确性):即处理的结果要保证一定的准确性。 5)Value(大价值):即大数据包含很多深度的价值,大数据分析挖掘和利用将带来巨大的商业价值。 传统的数据库系统主要面向结构化数据的存储和处理,但现实世界中的大数据具有各种不同的格式和形态,据统计现实世界中80%以上的数据都是文本和媒体等非结构化数据;同时,大数据还具有很多不同的计算特征。我们可以从多个角度分类大数据的类型和计算特征。 1)从数据结构特征角度看,大数据可分为结构化与非结构化/半结构化数据。 2)从数据获取处理方式看,大数据可分为批处理与流式计算方式。 3)从数据处理类型看,大数据处理可分为传统的查询分析计算和复杂数据挖掘计算。 4)从大数据处理响应性能看,大数据处理可分为实时/准实时与非实时计算,或者是联机计算与线下计算。前述的流式计算通常属于实时计算,此外查询分析类计算通常也要求具有高响应性能,因而也可以归为实时或准实时计算。而批处理计算和复杂数据挖掘计算通常属于非实时或线下计算。 5)从数据关系角度看,大数据可分为简单关系数据(如Web日志)和复杂关系数据(如社会网络等具有复杂数据关系的图计算)。
6)从迭代计算角度看,现实世界的数据处理中有很多计算问题需要大量的迭代计算,诸如一些机器学习等复杂的计算任务会需要大量的迭代计算,为此需要提供具有高效的迭代计算能力的大数据处理和计算方法。 7)从并行计算体系结构特征角度看,由于需要支持大规模数据的存储和计算,因此目前绝大多数禧金信息大数据处理都使用基于集群的分布式存储与并行计算体系结构和硬件平台。
高光谱数据处理基本流程
高光谱数据处理基本流 程 The document was finally revised on 2021
高光谱分辨率遥感 用很窄(10-2l)而连续的光谱通道对地物持续遥感成像的技术。在可见光到短波红外波段其光谱分辨率高达纳米(nm)数量级,通常具有波段多的特点,光谱通道数多达数十甚至数百个以上,而且各光谱通道间往往是连续的,每个像元均可提取一条连续的光谱曲线,因此高光谱遥感又通常被称为成像光谱(Imaging Spectrometry)遥感。 高光谱遥感具有不同于传统遥感的新特点: (1)波段多——可以为每个像元提供几十、数百甚至上千个波段; (2)光谱范围窄——波段范围一般小于10nm; (3)波段连续——有些传感器可以在350~2500nm的太阳光谱范围内提供几乎连续的地物光谱; (4)数据量大——随着波段数的增加,数据量成指数增加; (5)信息冗余增加——由于相邻波段高度相关,冗余信息也相对增加。 优点: (1)有利于利用光谱特征分析来研究地物; (2)有利于采用各种光谱匹配模型; (3)有利于地物的精细分类与识别。 ENVI高光谱数据处理流程: 一、图像预处理 高光谱图像的预处理主要是辐射校正,辐射校正包括传感器定标和大气纠正。辐射校正一般由数据提供商完成。 二、显示图像波谱 打开高光谱数据,显示真彩色图像,绘制波谱曲线,选择需要的光谱波段进行输出。 三、波谱库 1、标准波谱库 软件自带多种标准波谱库,单击波谱名称可以显示波谱信息。 2、自定义波谱库
ENVI提供自定义波谱库功能,允许基于不同的波谱来源创建波谱库,波谱来源包括收集任意点波谱、ASCII文件、由ASD波谱仪获取的波谱文件、感兴趣区均值、波谱破面和曲线等等。 3、波谱库交互浏览 波谱库浏览器提供很多的交互功能,包括设置波谱曲线的显示样式、添加注记、优化显示曲线等 四、端元波谱提取 端元的物理意义是指图像中具有相对固定光谱的特征地物类型,它实际上代表图像中没有发生混合的“纯点”。 端元波谱的确定有两种方式: (1)使用光谱仪在地面或实验室测量到的“参考端元”,一般从标准波谱库选择; (2)在遥感图像上得到的“图像端元”。 端元波谱获取的基本流程: (1)MNF变换 重要作用为:用于判定图像内在的维数;分离数据中的噪声;减少计算量;弥补了主成分分析在高光谱数据处理中的不足。 (2)计算纯净像元指数PPI PPI生成的结果是一副灰度的影像,DN值越大表明像元越纯。 作用及原理:
大数据处理技术的总结与分析
数据分析处理需求分类 1 事务型处理 在我们实际生活中,事务型数据处理需求非常常见,例如:淘宝网站交易系统、12306网站火车票交易系统、超市POS系统等都属于事务型数据处理系统。这类系统数据处理特点包括以下几点: 一就是事务处理型操作都就是细粒度操作,每次事务处理涉及数据量都很小。 二就是计算相对简单,一般只有少数几步操作组成,比如修改某行得某列; 三就是事务型处理操作涉及数据得增、删、改、查,对事务完整性与数据一致性要求非常高。 四就是事务性操作都就是实时交互式操作,至少能在几秒内执行完成; 五就是基于以上特点,索引就是支撑事务型处理一个非常重要得技术. 在数据量与并发交易量不大情况下,一般依托单机版关系型数据库,例如ORACLE、MYSQL、SQLSERVER,再加数据复制(DataGurad、RMAN、MySQL数据复制等)等高可用措施即可满足业务需求。 在数据量与并发交易量增加情况下,一般可以采用ORALCERAC集群方式或者就是通过硬件升级(采用小型机、大型机等,如银行系统、运营商计费系统、证卷系统)来支撑. 事务型操作在淘宝、12306等互联网企业中,由于数据量大、访问并发量高,必然采用分布式技术来应对,这样就带来了分布式事务处理问题,而分布式事务处理很难做到高效,因此一般采用根据业务应用特点来开发专用得系统来解决本问题。
2数据统计分析 数据统计主要就是被各类企业通过分析自己得销售记录等企业日常得运营数据,以辅助企业管理层来进行运营决策。典型得使用场景有:周报表、月报表等固定时间提供给领导得各类统计报表;市场营销部门,通过各种维度组合进行统计分析,以制定相应得营销策略等. 数据统计分析特点包括以下几点: 一就是数据统计一般涉及大量数据得聚合运算,每次统计涉及数据量会比较大。二就是数据统计分析计算相对复杂,例如会涉及大量goupby、子查询、嵌套查询、窗口函数、聚合函数、排序等;有些复杂统计可能需要编写SQL脚本才能实现. 三就是数据统计分析实时性相对没有事务型操作要求高。但除固定报表外,目前越来越多得用户希望能做做到交互式实时统计; 传统得数据统计分析主要采用基于MPP并行数据库得数据仓库技术.主要采用维度模型,通过预计算等方法,把数据整理成适合统计分析得结构来实现高性能得数据统计分析,以支持可以通过下钻与上卷操作,实现各种维度组合以及各种粒度得统计分析。 另外目前在数据统计分析领域,为了满足交互式统计分析需求,基于内存计算得数据库仓库系统也成为一个发展趋势,例如SAP得HANA平台。 3 数据挖掘 数据挖掘主要就是根据商业目标,采用数据挖掘算法自动从海量数据中发现隐含在海量数据中得规律与知识。
遥感卫星影像预处理做哪些
北京揽宇方圆信息技术有限公司热线:4006019091 遥感影像数据预处理 影像融合不同传感器的数据具有不同的时间、空间和光谱分辨率以及不同的极 化方式。单一传感器获取的影像信息量有限,往往难以满足应用需要, 通过影像融合可以从不同的遥感影像中获得更多的有用信息,补充单一 传感器的不足。全色图影像一般具有较高空间分辨率,多光谱影像光谱 信息较丰富。为提高多光谱影像的空间分辨率,可以将全色影像融合进 多光谱图像,通过融合既提高多光谱影像空间分辨率,又保留其多光谱 特性。对卫星数据的全色及多光谱波段进行融合。包括选取最佳波段, 从多种分辨率融合方法中选取最佳方法进行全色波段和多光谱波段融 合,使得图像既有高的空间分辨率和纹理特性,又有丰富的光谱信息, 从而达到影像地图信息丰富、视觉效果好、质量高的目的。 影像匀色相邻的遥感图像,由于成像日期、季节、天气、环境等因素可能有差异, 不仅存在几何畸变问题,而且还存在辐射水平差异导致同名地物在相 邻图像上的色彩亮度值不一致。如不进行色调调整就把这种图像镶嵌起 来,即使几何配准的精度很高,重叠区复合得很好,但镶嵌后两边的影 像色调差异明显,接缝线十分突出,既不美观,也影响对地物影像与专 业信息的分析与识别,降低应用效果。要求镶嵌完的数据色调基本无差 异,美观。遥感影像匀色后保证影像整体色彩一致性。 影像镶嵌将不同的图像文件合在一起形成一幅完整的包含感兴趣区域的图像,通 过镶嵌处理,可以获得更大范围的地面图像。参与镶嵌的图像可以是不 同时间同一传感器获取的,也可以是不同时间不同传感器获取的图像, 但同时要求镶嵌的图像之间要有一定的重叠度。 影像去云雾影像数据常常有云雾覆盖,针对有云雾覆盖的影像,可以通过后期技术 处理去除薄云雾,达到影像最佳效果。 影像纠正依据控制点,利用相应软件模块对数据进行几何精校正,这一步骤包括 利用地面控制点(GCPs)找出实际地形,计算配准中控制点的误差,利 用DEM消除地形起伏引起的位移,然后对图像进行重采样等。形成符合 某种地图投影或图形表达要求的新影像。 即插即用无使用门槛,可与各类GIS软件系统无缝衔接 第 1 页
遥感数据预处理
遥感讲座——遥感影像预处理 据预处理是遥感应用的第一步,也是非常重要的一步。目前的技术也非常成熟,大多数的商业化软件都具备这方面的功能。预处理的大致流程在各个行业中有点差异,而且注重点也各有不同。下面是预处理中比较常见的流程。 1、数据预处理一般流程 数据预处理的过程包括几何精校正、配准、图像镶嵌与裁剪、去云及阴影处理和光谱归一化几个环节,具体流程图如图所示。 各个行业应用会有所不同,比如在精细农业方面,在大气校正方面要求会高点,因为它需要反演;在测绘方面,对几何校正的精度要求会很高。 2、数据预处理的各个流程介绍 (一)几何精校正与影像配准 引起影像几何变形一般分为两大类:系统性和非系统性。系统性一般有传感器本身引起的,有规律可循和可预测性,可以用传感器模型来校正;非系统性几何变形是不规律的,它可以是传感器平台本身的高度、姿态等不稳定,也可以是地球曲率及空气折射的变化以及地形的变化等。 在做几何校正前,先要知道几个概念: 地理编码:把图像矫正到一种统一标准的坐标系。 地理参照:借助一组控制点,对一幅图像进行地理坐标的校正。 图像配准:同一区域里一幅图像(基准图像)对另一幅图像校准
影像几何精校正,一般步骤如下, (1)GCP(地面控制点)的选取 这是几何校正中最重要的一步。可以从地形图(DRG)为参考进行控制选点,也可以野外GPS测量获得,或者从校正好的影像中获取。选取得控制点有以下特征: 1、GCP在图像上有明显的、清晰的点位标志,如道路交叉点、河流交叉点等; 2、地面控制点上的地物不随时间而变化。 GCP均匀分布在整幅影像内,且要有一定的数量保证,不同纠正模型对控制点个数的需求不相同。卫星提供的辅助数据可建立严密的物理模型,该模型只需9个控制点即可;对于有理多项式模型,一般每景要求不少于30个控制点,困难地区适当增加点位;几何多项式模型将根据地形情况确定,它要求控制点个数多于上述几种模型,通常每景要求在30-50个左右,尤其对于山区应适当增加控制点。 (2)建立几何校正模型 地面点确定之后,要在图像与图像或地图上分别读出各个控制点在图像上的像元坐标(x,y)及其参考图像或地图上的坐标(X,Y),这叫需要选择一个合理的坐标变换函数式(即数据校正模型),然后用公式计算每个地面控制点的均方根误差(RMS)根据公式计算出每个控制点几何校正的精度,计算出累积的总体均方差误差,也叫残余误差,一般控制在一个像元之内,即RMS<1。 (3)图像重采样 重新定位后的像元在原图像中分布是不均匀的,即输出图像像元点在输入图像中的行列号不是或不全是正数关系。因此需要根据输出图像上的各像元在输入图像中的位置,对原始图像按一定规则重新采样,进行亮度值的插值计算,建立新的图像矩阵。常用的内插方法包括: 1、最邻近法是将最邻近的像元值赋予新像元。该方法的优点是输出图像仍然保持原来的像元值,简单,处理速度快。但这种方法最大可产生半个像元的位置偏移,可能造成输出图像中某些地物的不连贯。 2、双线性内插法是使用邻近4个点的像元值,按照其距内插点的距离赋予不同的权重,进行线性内插。该方法具有平均化的滤波效果,边缘受到平滑作用,而产生一个比较连贯的输出图像,其缺点是破坏了原来的像元值。 3、三次卷积内插法较为复杂,它使用内插点周围的16个像元值,用三次卷积函数进行内插。这种方法对边缘有所增强,并具有均衡化和清晰化的效果,当它仍然破坏了原来的像元值,且计算量大。 一般认为最邻近法有利于保持原始图像中的灰级,但对图像中的几何结构损坏较大。后两种方法虽然对像元值有所近似,但也在很大程度上保留图像原有的几何结构,如道路网、水系、地物边界等。
高光谱数据处理基本流程
高光谱分辨率遥感 用很窄(10-2l)而连续的光谱通道对地物持续遥感成像的技术。在可见光到短波红外波段其光谱分辨率高达纳米(nm)数量级,通常具有波段多的特点,光谱通道数多达数十甚至数百个以上,而且各光谱通道间往往是连续的,每个像元均可提取一条连续的光谱曲线,因此高光谱遥感又通常被称为成像光谱(ImagingSpectrometry)遥感。 高光谱遥感具有不同于传统遥感的新特点: (1)波段多——可以为每个像元提供几十、数百甚至上千个波段; (2)光谱范围窄——波段范围一般小于10nm; (3)波段连续——有些传感器可以在350~2500nm的太阳光谱范围内提供几乎连续的地物光谱; (4)数据量大——随着波段数的增加,数据量成指数增加; (5)信息冗余增加——由于相邻波段高度相关,冗余信息也相对增加。 优点: (1)有利于利用光谱特征分析来研究地物; (2)有利于采用各种光谱匹配模型; (3)有利于地物的精细分类与识别。 ENVI高光谱数据处理流程: 一、图像预处理 高光谱图像的预处理主要是辐射校正,辐射校正包括传感器定标和大气纠正。辐射校正一般由数据提供商完成。 二、显示图像波谱 打开高光谱数据,显示真彩色图像,绘制波谱曲线,选择需要的光谱波段进行输出。 三、波谱库 1、标准波谱库 软件自带多种标准波谱库,单击波谱名称可以显示波谱信息。 2、自定义波谱库 ENVI提供自定义波谱库功能,允许基于不同的波谱来源创建波谱库,波谱
来源包括收集任意点波谱、ASCII文件、由ASD波谱仪获取的波谱文件、感兴趣区均值、波谱破面和曲线等等。 3、波谱库交互浏览 波谱库浏览器提供很多的交互功能,包括设置波谱曲线的显示样式、添加注记、优化显示曲线等 四、端元波谱提取 端元的物理意义是指图像中具有相对固定光谱的特征地物类型,它实际上代表图像中没有发生混合的“纯点”。 端元波谱的确定有两种方式: (1)使用光谱仪在地面或实验室测量到的“参考端元”,一般从标准波谱库选择; (2)在遥感图像上得到的“图像端元”。 端元波谱获取的基本流程: (1)MNF变换 重要作用为:用于判定图像内在的维数;分离数据中的噪声;减少计算量;弥补了主成分分析在高光谱数据处理中的不足。 (2)计算纯净像元指数PPI PPI生成的结果是一副灰度的影像,DN值越大表明像元越纯。 作用及原理: 纯净像元指数法对图像中的像素点进行反复迭代,可以在多光谱或者高光谱影像中寻找最“纯”的像元。(通常基于MNF变换结果来进行)
大数据采集技术和预处理技术
现如今,很多人都听说过大数据,这是一个新兴的技术,渐渐地改变了我们的生活,正是由 于这个原因,越来越多的人都开始关注大数据。在这篇文章中我们将会为大家介绍两种大数 据技术,分别是大数据采集技术和大数据预处理技术,有兴趣的小伙伴快快学起来吧。 首先我们给大家介绍一下大数据的采集技术,一般来说,数据是指通过RFID射频数据、传 感器数据、社交网络交互数据及移动互联网数据等方式获得的各种类型的结构化、半结构化 及非结构化的海量数据,是大数据知识服务模型的根本。重点突破高速数据解析、转换与装 载等大数据整合技术设计质量评估模型,开发数据质量技术。当然,还需要突破分布式高速 高可靠数据爬取或采集、高速数据全映像等大数据收集技术。这就是大数据采集的来源。 通常来说,大数据的采集一般分为两种,第一就是大数据智能感知层,在这一层中,主要包 括数据传感体系、网络通信体系、传感适配体系、智能识别体系及软硬件资源接入系统,实 现对结构化、半结构化、非结构化的海量数据的智能化识别、定位、跟踪、接入、传输、信 号转换、监控、初步处理和管理等。必须着重攻克针对大数据源的智能识别、感知、适配、 传输、接入等技术。第二就是基础支撑层。在这一层中提供大数据服务平台所需的虚拟服务器,结构化、半结构化及非结构化数据的数据库及物联网络资源等基础支撑环境。重点攻克 分布式虚拟存储技术,大数据获取、存储、组织、分析和决策操作的可视化接口技术,大数 据的网络传输与压缩技术,大数据隐私保护技术等。 下面我们给大家介绍一下大数据预处理技术。大数据预处理技术就是完成对已接收数据的辨析、抽取、清洗等操作。其中抽取就是因获取的数据可能具有多种结构和类型,数据抽取过 程可以帮助我们将这些复杂的数据转化为单一的或者便于处理的构型,以达到快速分析处理 的目的。而清洗则是由于对于大数并不全是有价值的,有些数据并不是我们所关心的内容, 而另一些数据则是完全错误的干扰项,因此要对数据通过过滤去除噪声从而提取出有效数据。在这篇文章中我们给大家介绍了关于大数据的采集技术和预处理技术,相信大家看了这篇文 章以后已经知道了大数据的相关知识,希望这篇文章能够更好地帮助大家。
红外与近红外光谱常用数据处理算法
一、数据预处理 (1)中心化变换 (2)归一化处理 (3)正规化处理 (4)标准正态变量校正(标准化处理)(Standard Normal Variate,SNV)(5)数字平滑与滤波(Smooth) (6)导数处理(Derivative) (7)多元散射校正(Multiplicative Scatter Correction,MSC) (8)正交信号校正(OSC) 二、特征的提取与压缩 (1)主成分分析(PCA) (2)马氏距离 三、模式识别(定性分类) (1)基于fisher意义下的线性判别分析(LDA) (2)K-最邻近法(KNN) (3)模型分类方法(SIMCA) (4)支持向量机(SVM) (5)自适应boosting方法(Adaboost) 四、回归分析(定量分析) (1)主成分回归(PCR) (2)偏最小二乘法回归(PLS) (3)支持向量机回归(SVR)
一、数据预处理 (1) 中心化变换 中心化变换的目的是在于改变数据相对于坐标轴的位置。一般都是希望数据集的均值与坐标轴的原点重合。若x ik 表示第i 个样本的第k 个测量数据,很明显这个数据处在数据矩阵中的第i 行第k 列。中心化变换就是从数据矩阵中的每一个元素中减去该元素所在元素所在列的均值的运算: u ik k x x x =- ,其中k x 是n 个样本的均值。 (2) 归一化处理 归一化处理的目的是是数据集中各数据向量具有相同的长度,一般为单位长度。其公式为: 'ik x = 归一化处理能有效去除由于测量值大小不同所导致的数据集的方差,但是也可能会丢失重要的方差。 (3)正规化处理 正规化处理是数据点布满数据空间,常用的正规化处理为区间正规化处理。其处理方法是以原始数据集中的各元素减去所在列的最小值,再除以该列的极差。 min() 'max()min() ik ik k k x xk x x x -= - 该方法可以将量纲不同,范围不同的各种变量表达为值均在0~1范围内的数据。但这种方法对界外值很敏感,若存在界外值,则处理后的所有数据近乎相等。 (4) 标准化处理(SNV )也称标准正态变量校正 该处理能去除由单位不同所引起的不引人注意的权重,但这种方法对界外点不像区间正规化那样的敏感。标准化处理也称方差归一化。它是将原始数据集各个元素减去该元素所在列的元素的均值再除以该列元素的标准差。 ';ik k ik k k x x x S S -==
大数据处理常用技术有哪些
大数据处理常用技术有哪些? storm,hbase,hive,sqoop.spark,flume,zookeeper如下 ?Apache Hadoop:是Apache开源组织的一个分布式计算开源框架,提供了一个分布式文件系统子项目(HDFS)和支持MapReduce分布式计算的软件架构。 ?Apache Hive:是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,通过类SQL语句快速实现简单的MapReduce 统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。 ?Apache Pig:是一个基于Hadoop的大规模数据分析工具,它提供的SQL-LIKE语言叫Pig Latin,该语言的编译器会把类SQL的数据分析请求转换为一系列经过优化处理的MapReduce运算。 ?Apache HBase:是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。 ?Apache Sqoop:是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。 ?Apache Zookeeper:是一个为分布式应用所设计的分布的、开源的协调服务,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,简化分布式应用协调及其管理的难度,提供高性能的分布式服务?Apache Mahout:是基于Hadoop的机器学习和数据挖掘的一个分布式框架。Mahout用MapReduce实现了部分数据挖掘算法,解决了并行挖掘的问题。 ?Apache Cassandra:是一套开源分布式NoSQL数据库系统。它最初由Facebook开发,用于储存简单格式数据,集Google BigTable的数据模型与Amazon Dynamo的完全分布式的架构于一身 ?Apache Avro:是一个数据序列化系统,设计用于支持数据密集型,大批量数据交换的应用。Avro是新的数据序列化格式与传输工具,将逐步取代Hadoop原有的IPC机制 ?Apache Ambari:是一种基于Web的工具,支持Hadoop集群的供应、管理和监控。 ?Apache Chukwa:是一个开源的用于监控大型分布式系统的数据收集系统,它可以将各种各样类型的数据收集成适合Hadoop 处理的文件保存在HDFS 中供Hadoop 进行各种MapReduce 操作。 ?Apache Hama:是一个基于HDFS的BSP(Bulk Synchronous Parallel)并行计算框架, Hama可用于包括图、矩阵和网络算法在内的大规模、大数据计算。
高光谱预处理实验指导书
高光谱遥感图像预处理 实验指导书 指导教师:赵泉华
一、实习目的 通过高光谱遥感图像预处理的学习,使学生在课堂教学及实验课教学的基础上进一步将理论与实践相结合,消化和理解课堂所学理论知识,达到初步掌握利用ENVI等软件预处理高光谱遥感图像,并熟悉高光谱遥感图像预处理流程与方法的目的。 二、实习方式 学生自学指导书为主,指导教师讲授为辅; 利用计算机,结合相应遥感图像及ENVI软件的具体操作进行。 三、练习数据 机载高光谱AVIRIS数据。 四、实习内容与要求 掌握高光谱遥感图像预处理的理论与方法,利用ENVI中FLAASH大气校正工具和快速大气校正工具对高光谱数据进行大气校正及快速大气校正。
实验一、高光谱FLAASH数据大气校正 实验目的:通过实验操作,掌握高光谱遥感图像FLAASH数据的大气校正的基本方法和步骤,深刻理解遥感图像大气校正的意义。 实验内容:ENVI软件中高光谱图像预处理模块下的图像大气校正。 高光谱图像的预处理主要是辐射校正,辐射校正包括传感器定标和大气校正。辐射校正一般由数据提供商完成。太阳辐射通过大气以某种方式入射到物体表面然后再反射回传感器,由于大气气溶胶、地形和邻近地物等影像,使得原始影像包含物体表面,大气,以及太阳的信息等信息的综合。如果我们想要了解某一物体表面的光谱属性,我们必须将它的反射信息从大气和太阳的信息中分离出来,这就需要进行大气校正过程。 操作步骤: 1.打开文件 File→Open→CupriteAVIRISSubset.dat→打开。 2. FLAASH Atmospheric Correction Module Input Parameters设置 在Toolbox 中打开FLAASH 工具Radiometric Correction/Atmospheric Correction Module/FLAASH Atmospheric Correction→双击启动→进入FLAASH Atmospheric Correction Module Input Parameters 面板。 图1-1 FLAASH Atmospheric Correction Module Input Parameters 面板 (1)Input Radiance Image:点击Input Radiance Image→选择CupriteAVIRISSubset.dat 文件→在打开的Radiance Scale Factors 面板中,选择默认Read array of scale factors (1 per band) from ASCII file→OK→在对话框中选择AVIRIS11_gain.txt 文件→打开→在Input ASCII File 对话框中,将Scale Column改为1→OK;
光谱预处理方法的作用与目的
光谱预处理方法的作用与目的 光谱预处理的方法有很多,应结合实际情况合理选取最好的预处理方法。 1.均值中心化(mean centering):增加样品光谱之间的差异,从而提高模型的 稳健性和预测能力。 2.标准化(autoscaling):该方法给光谱中所有变量相同的权重,在对低浓度 成分建立模型时特别适用。 3.归一化(normalization):常用于微小光程差异引起的光谱变化。 4.平滑去噪算法(smoothing):是消除噪声最常用的一种方法。其效果与选择 的串口数有关,窗口数太大,容易失真;窗口数过小,效果不佳。 5.导数(derivative):可有效的消除基线和其他背景的干扰,分别重叠峰,提 高分辨率和灵敏度。 6.标准正太变换(SNV):主要用来消除固体颗粒大小、表面散射以及光程变 化对漫反射光谱的影响。去趋势算法常用在SNV处理后的光谱,用来消除南反射光谱的基线漂移。 7.多元散射校正(msc):作用于SNV 差不多,主要是消除颗粒分布不均匀及 颗粒大小产生的散射影响,在固体漫反射和浆状物透射和反射光谱中运用比较多。 8.傅里叶变换(FT):能够实现时域和频域之间的转换。仪器的噪声相对于信 息信号而言,其振幅更小,频率更高,故舍去高频率的部分信号可以消除大部分光谱噪声,使信号更加平滑,利用低频信号,通过傅里叶反变换,对原始光谱数据重构,达到去除噪声的目的。 9.小波变换(WT):将信号转变成一系列的小波函数的叠加,这些小波函数都 是由一个母小波函数经过平移和尺度伸缩得到,小波变换在时域和频域同时具有良好的局部化性质,他可以对高频成分采用逐步精细化的时域或空间域取代步长,从而达到聚焦到对象的任意细节。
最常见的近红外光谱的预处理技术的综述
最常见的近红外光谱的预处理技术的综述 smund Rinnan,Frans van den Berg,S?ren Balling Engelsen 摘要:预处理在近红外(NIR)光谱数据处理化学计量学建模中已经成为不可分割的一部分。预处理的目的是消除光谱中物理现象在为了提高后续多元回归、分类模型或探索性分析。最广泛使用的预处理技术可以分为两类:散射校正方法和光谱间隔方法。综述和比较了算法的基础理论和当前的预处理方法以及定性和定量的后果的应用程序。其目的是提供更好的NIR 最终模型的建立,在此我们通过对光谱的预处理基本知识进行梳理。 关键词:乘法散射校正;近红外光谱法;标准化;诺里斯威廉姆斯推导;预处理;Savitzky-Golay 平滑;散射校正;光谱导数;标准正态变量;综述 1.引言 目前为止,没有能够优化数据来进行代替,但是经过适当的数据收集和处理将会起到优化效果,对光谱数据进行预处理是最重要的一步(例如最优化之前叠层建模),常用的方法有主成分分析(PCA)和偏最小二乘法(PLS)。在大量的文献中,多变量光谱应用食品、饲料和医药分析,比较不同的预处理的结果研究模型的预测结果是不可分割的组成部分。近红外反射/透射率(NIR / NIT)光谱的光谱技术,到目前为止最多被使用的和最大的多样性在预处理技术,主要是由于入非线性光散射的光谱可以引起显著影响。由于类似规模的波长的电磁辐射和粒子大小的近红外光谱在生物样品,近红外光谱技术是一种不被广泛使用是由于存在散射效应(包括基线转变和非线性),这将会影响样品光谱的结果的记录。然而,通过应用合适的预处理,可以很大程度上消除这些影响。 在应用研究中,比较了几乎完全不同的定标模型(定量描述符和相应关系)。几乎没有出现评估的差异和相似性的报道。替代技术即修正的含义(例如,谱描述符数据)在研究中很少被讨论。本文旨在讨论建立了预处理方法对近红外光谱和模型之间的关系,更具体地说,这些技术都是对应独立的响应变量,所以我们只讨论方法,不需要一个响应值。我们同时关注预处理工艺理论方面的和实际效果,这种方法适用于近红外光谱/ NIT光谱。 对固体样品,干扰系统的差异主要是因为光散射的不同和有效路径长度的不同。这些不受欢迎的变化常常构成了样本集的总变异的主要部分,可以观察到得转变基线(乘法效应)和其他现象称为非线性。一般来说,近红外光谱反射率测量的一个示例将测量普及性的反映和镜面反射辐射(镜面反射)。镜面反射通常由仪表设计和几何的采样最小化,因为它们不含任何化学信息。这个diffusively反射的光,这反映在广泛的方向,是信息的主要来源在近红外光谱。然而,diffusively反射光将包含信息的化学成分不仅示例(吸收)而且结构(散射)。主要的形式的光散射(不包括能量转移与样品)瑞利和洛伦兹米氏。两者都是过程中电磁辐射是分散的(例如,通过小粒子,泡沫,表面粗糙度,水滴,晶体缺陷,microorganelles、细胞、纤维和密度波动)。 当粒子尺寸大于波长,因为通常情况下,NIR光谱,是主要的洛仑兹米氏散射。相比之下,瑞利散射,是各向异性,洛伦兹米氏散射依赖的形状散射粒子和不强烈波长依赖性。 对生物样品,散射特性是过于复杂,所以软或自适应补偿,光谱预处理技术,正如我们近红外光谱在本文中进行讨论,要求删除散射从纯粹的、理想的吸收光谱。 显然,预处理不能纠正镜面反射率(直接散射),自谱不包含任何精细结构。光谱主要由镜面反射率应该总是被移除之前为离群值多元数据分析,因为他们仍将是局外人,甚至在预处理。图1显示了一组13好蔗糖和样品不同粒径加一坏蔗糖的例子展示如何(极端)镜面反射率表现比正常的光谱。 图1还演示了总体布局的大多数数据在本文中。上部的图,一个条形图显示了主成分得分值第一主成分(PC)后的样本集数据意味着定心[1]。下面部分显示预处理效果的数据集(或
大数据处理:技术与流程
大数据处理:技术与流程 文章来源:ECP大数据时间:2013/5/22 11:28:34发布者:ECP大数据(关注:848) 标签: “大数据”是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。特点是:数据量大(Volume)、数据种类多样(Variety)、要求实时性强(Velocity)。对它关注也是因为它蕴藏的商业价值大(Value)。也是大数据的4V特性。符合这些特性的,叫大数据。 大数据会更多的体现数据的价值。各行业的数据都越来越多,在大数据情况下,如何保障业务的顺畅,有效的管理分析数据,能让领导层做出最有利的决策。这是关注大数据的原因。也是大数据处理技术要解决的问题。 大数据处理技术 大数据时代的超大数据体量和占相当比例的半结构化和非结构化数据的存在,已经超越了传统数据库的管理能力,大数据技术将是IT领域新一代的技术与架构,它将帮助人们存储管理好大数据并从大体量、高复杂的数据中提取价值,相关的技术、产品将不断涌现,将有可能给IT行业开拓一个新的黄金时代。 大数据本质也是数据,其关键的技术依然逃不脱:1)大数据存储和管理;2)大数据检索使用(包括数据挖掘和智能分析)。围绕大数据,一批新兴的数据挖掘、数据存储、数据处理与分析技术将不断涌现,让我们处理海量数据更加容易、更加便宜和迅速,成为企业业务经营的好助手,甚至可以改变许多行业的经营方式。 大数据的商业模式与架构----云计算及其分布式结构是重要途径 1)大数据处理技术正在改变目前计算机的运行模式,正在改变着这个世界:它能处理几乎各种类型的海量数据,无论是微博、文章、电子邮件、文档、音频、视频,还是其它形态的数据;它工作的速度非常快速:实际上几乎实时;它具有普及性:因为它所用的都是最普通低成本的硬件,而云计算它将计算任务分布在大量计算机构成的资源池上,使用户能够按需获取计算力、存储空间和信息服务。云计算及其技术给了人们廉价获取巨量计算和存储的能力,云计算分布式架构能够很好地支持大数据存储和处理需求。这样的低成本硬件+低成本软件+低成本运维,更加经济和实用,使得大数据处理和利用成为可能。
近红外光谱分析技术的数据处理方法
引言 近红外是指波长在780nm~2526nm范围内的光线,是人们认识最早的非可见光区域。习惯上又将近红外光划分为近红外短波(780nm~1100nm)和长波(1100 nm~2526 nm)两个区域.近红外光谱(Near Infrared Reflectance Spectroscopy,简称NIRS)分析技术是一项新的无损检测技术,能够高效、快速、准确地对固体、液体、粉末状等有机物样品的物理、力学和化学性质等进行无损检测。它综合运用了现代计算机技术、光谱分析技术、数理统计以及化学计量学等多个学科的最新研究果,并使之融为一体,以其独有的特点在很多领域如农业、石油、食品、生物化工、制药及临床医学等得到了广泛应用,在产品质量分析、在线检测、工艺控制等方面也获得了较大成功。近红外光谱分析技术的数据处理主要涉及两个方面的内容:一是光谱预处理方法的研究,目的是针对特定的样品体系,通过对光谱的适当处理,减弱和消除各种非目标因素对光谱的影响,净化谱图信息,为校正模型的建立和未知样品组成或性质的预测奠定基础;二是近红外光谱定性和定量方法的研究,目的在于建立稳定、可靠的定性或定量分析模型,并最终确定未知样品和对其定量。 1工作原理 近红外光谱区主要为含氢基团X-H(X=O,N,S,单健C,双健C,三健C等)的倍频和合频吸收区,物质的近红外光谱是其各基团振动的倍频和合频的综合吸收表现,包含了大多数类型有机化合物的组成和分子结构的信息。因为不同的有机物含有不同的基团,而不同的基团在不同化学环境中对近红外光的吸收波长不同,因此近红外光谱可以作为获取信息的一种有效载体。近红外光谱分析技术是利用被测物质在其近红外光谱区内的光学特性快速估测一项或多项化学成分含量。被测样品的光谱特征是多种组分的反射光谱的综合表现,各组分含量的测定基于各组分最佳波长的选择,按照式(1)回归方程自动测定结果:组分含量=C0+C1(Dp)1+C2(Dp)2+…+Ck(Dp)k(1)式中:C0~k为多元线性回归系数;(Dp)1~k为各组分最佳波长的反射光密度值(D=-lgp,p为反射比)。该方程准确的反映了定标范围内一系列样品的测定结果,与实验室常规测定法之间的标准偏差SE为:SE=[Σ(y-x)2/(n-1)]1/2(2)式中:x表示实验室常规法测定值,y表示近红外光 谱法测值,n为样品数。 2光谱数据的预处理 仪器采集的原始光谱中除包含与样品组成有关的信息外,同时也包含来自各方面因素所产生的噪音信号。这些噪音信号会对谱图信息产生干扰,有些情况下还非常严重,从而影响校正模型的建立和对未知样品组成或性质的预测。因此,光谱数据预处理主要解决光谱噪音的滤除、数据的筛选、光谱范围的优化及消除其他因素对数据信息的影响,为下步校正模型的建立和未知样品的准确预测打下基础。常用的数据预处理方法有光谱数据的平滑、基线校正、求导、归一化处理等。 2.1数据平滑处理 信号平滑是消除噪声最常用的一种方法,其基本假设是光谱含有的噪声为零均随机白噪声,若多次测量取平均值可降低噪声提高信噪比。平滑处理常用方法有邻近点比较法、移动平均法、指数平均法等。 2.1.1邻近点比较法 对于许多干扰性的脉冲信号,将每一个数据点和它旁边邻近的数据点的
大数据处理技术ppt讲课稿
大数据处理技术ppt讲课稿 科信办刘伟 第一节Mapreduce编程模型: 1.技术背景: 分布式并行计算是大数据(pb)处理的有效方法,编写正确高效的大规模并行分布式程序是计算机工程领域的难题:分布式并行计算是大数据(pb)处理的有效方法,编写正确高效的大规模并行分布式程序是计算机工程领域的难题。并行计算的模型、计算任务分发、计算机结果合并、计算节点的通讯、计算节点的负载均衡、计算机节点容错处理、节点文件的管理等方面都要考虑。 谷歌的关于mapreduce论文里这么形容他们遇到的难题:由于输入的数据量巨大,因此要想在可接受的时间内完成运算,只有将这些计算分布在成百上千的主机上。如何处理并行计算、如何分发数据、如何处理错误?所有这些问题综合在一起,需要大量的代码处理,因此也使得原本简单的运算变得难以处理,普通程序员无法进行大数据处理。 为了解决上述复杂的问题,谷歌设计一个新的抽象模型,使用这个抽象模型,普通程序员只要表述他们想要执行的简单运算即可,而不必关心并行计算、容错、数据分布、负载均衡等复杂的细节,这些问题都被封装了,交个了后台程序来处理。这个模型就是mapreduce。 谷歌2004年公布的mapreduce编程模型,在工业、学术界产生巨大影响,以至于谈大数据必谈mapreduce。 学术界和工业界就此开始了漫漫的追赶之路。这期间,工业界试图做的事情就是要实现一个能够媲美或者比Google mapreduce更好的系统,多年的努力下来,Hadoop(开源)脱颖而出,成为外界实现MapReduce计算模型事实上的标准,围绕着Hadoop,已经形成了一个庞大的生态系统 2. mapreduce的概念: MapReduce是一个编程模型,一个处理和生成超大数据集的算法模型的相关实现。简单的一句话解释MapReduce就是“任务的分解与结果的汇总”。MapReduce从它名字上来看就大致可以看出个缘由,两个动词Map和Reduce,“Map(展开)”就是将一个任务分解成为多个任务,“Reduce”就是将分解后多任务处理的结果汇总起来,得出最后的分析结果。 mapreduce成功的最大因素是它简单的编程模型。程序员只要按照这个框架的要求,设计map和reduce函数,剩下的工作,如分布式存储、节点调度、负载均衡、节点通讯、容错处理和故障恢复都由mapreduce框架(比如hadoop)自动完成,设计的程序有很高的扩展性。所以,站在计算的两端来看,与我们通常熟悉的串行计算没有任何差别,所有的复杂性都在中间隐藏了。它让那些没有多少并行计算和分布式处理经验的开发人员也可以开发并行应用,开发人员只需要实现map 和reduce 两个接口函数,即可完成TB级数据的计算,这也就是MapReduce的价值所在,通过简化编程模型,降低了开发并行应用的入门门槛,并行计算就可以得到更广泛的应用。 3.mapreduce的编程模型原理 开发人员用两个函数表达这个计算:Map和Reduce,首先创建一个Map函数处理一个基于key/value pair的数据集合,输出中间的基于key/value pair的数据集合,然后再创建一个Reduce函数用来合并所有的具有相同中间key值的中间value值,就完成了大数据的处理,剩下的工作由计算机集群自动完成。 即:(input)
- 近红外光谱数据处理
- 近红外光谱分析技术的数据处理方法
- 高光谱数据处理基本流程
- 最常见的近红外光谱的预处理技术的综述
- 基于LIBS技术的光谱数据预处理算法研究
- 高光谱数据处理基本操作规范
- Hyperion高光谱数据的预处理
- 基于星载高光谱数据预处理
- 近红外光谱的数据预处理研究
- 环境小卫星多光谱数据预处理方法
- ENVI高光谱数据处理流程
- 光谱预处理方法的作用与目的
- ENVI对SAR大数据地预处理过程(详细版)
- 近红外光谱分析技术的数据处理方法
- 遥感卫星影像预处理做哪些
- 红外与近红外光谱常用大数据处理算法
- 红外与近红外光谱常用数据处理算法
- 近红外光谱分析技术的数据处理方法
- 红外与近红外光谱常用数据处理算法
- EO_1Hyperion高光谱数据的预处理