实验四 描述性统计分析
实验四描述性统计分析
一、集中趋势的测度
定类数据:众数
定序数据:中位数和分位数
定距和定比数据:均值
众数、中位数和均值的比较
1.一组数据向其中心值靠拢的倾向和程度
2.测度集中趋势就是寻找数据一般水平的代表值或中心值
3.不同类型的数据用不同的集中趋势测度值
4.低层次数据的集中趋势测度值适用于高层次的测量数据,反过来,高层次
数据的集中趋势测度值并不适用于低层次的测量数据
5.选用哪一个测度值来反映数据的集中趋势,要根据所掌握的数据的类型来
确定
I.众数(Mode)
1、集中趋势的测度值之一
2、出现次数最多的变量值
3、不受极端值的影响
4、可能没有众数或有几个众数
5、主要用于定类数据,也可用于定序数据和数值型数据
II.中位数(Median)
6、集中趋势的测度值之一
7、排序后处于中间位置上的值
8、不受极端值的影响
9、主要用于定序数据,也可用数值型数据,但不能用于定类数据 10、 各变量值与中位数的离差绝对值之和最小,即
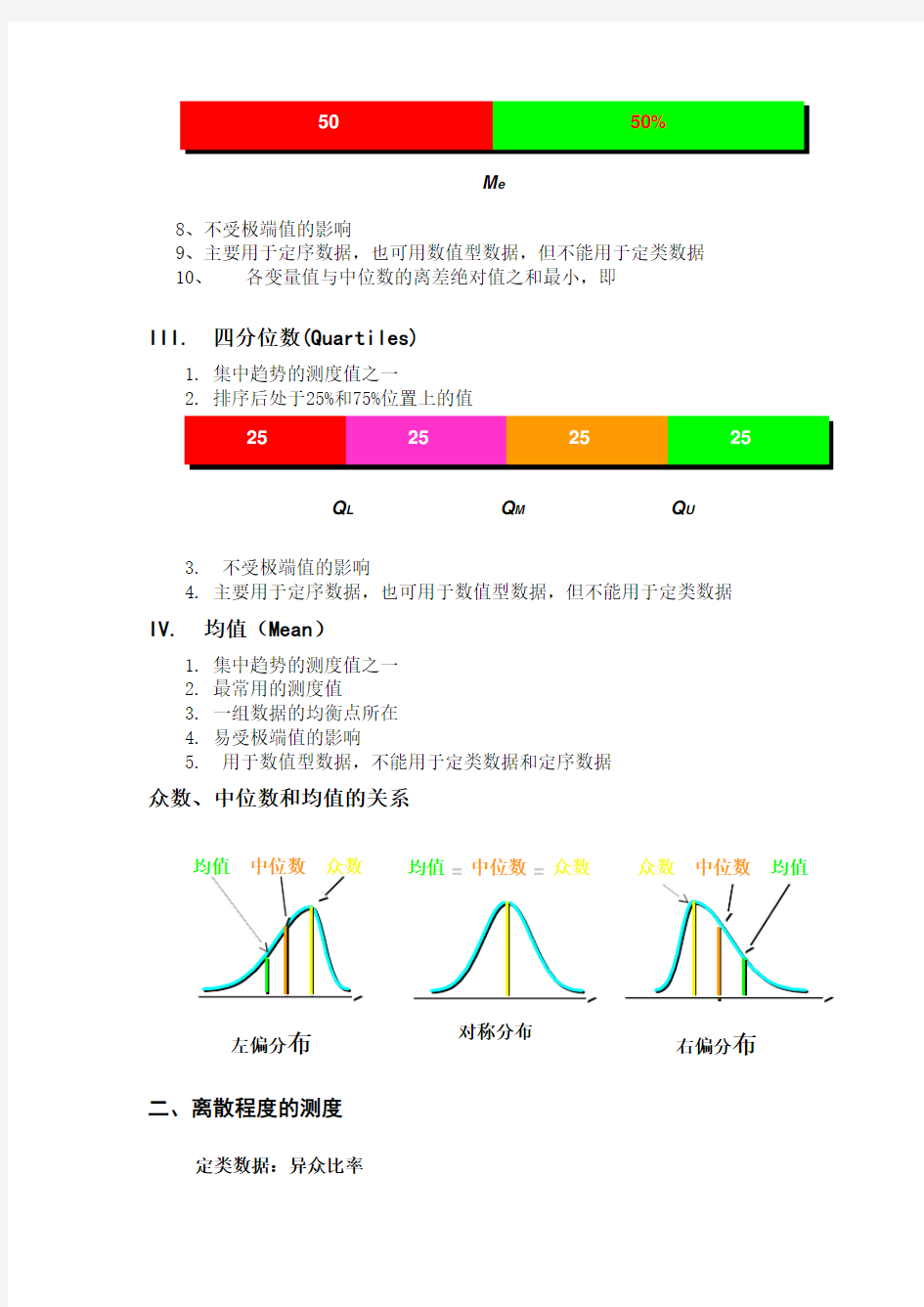
III. 四分位数(Quartiles)
1. 集中趋势的测度值之一
2. 排序后处于25%和75%位置上的值
3. 不受极端值的影响
4. 主要用于定序数据,也可用于数值型数据,但不能用于定类数据
IV. 均值(Mean )
1. 集中趋势的测度值之一
2. 最常用的测度值
3. 一组数据的均衡点所在
4. 易受极端值的影响
5. 用于数值型数据,不能用于定类数据和定序数据
众数、中位数和均值的关系
二、离散程度的测度
定类数据:异众比率
M e
50%
50%
Q L Q M Q U
25%
25%
25%
25%
对称分布
均值 = 中位数 = 众数
右偏分布
众数 中位数 均值
左偏分布
定序数据:四分位差
定距和定比数据:方差及标准差
I.异众比率
1. 离散程度的测度值之一
2. 非众数组的频数占总频数的比率
3. 仅用于定类数据
4. 用于衡量众数的代表性
II.四分位差
1. 离散程度的测度值之一
2. 也称为内距或四分间距
3. 上四分位数与下四分位数之差
QD = QU - QL
4.反映了中间50%数据的离散程度
5.不受极端值的影响
6.用于衡量中位数的代表性
III.方差和标准差(Variance and Std。deviation)
1. 离散程度的测度值之一
2. 最常用的测度值
3. 反映了数据的分布
4.反映了各变量值与均值的平均差异
5.根据总体数据计算的,称为总体方差或标准差;根据样本数据计算的,称为样本方差或标准差
IV.偏态(kurtosis)
1. 数据分布偏斜程度的测度
2. 偏态系数=0为对称分布
3. 偏态系数> 0为右偏分布
4. 偏态系数< 0为左偏分布
V.峰度(skewness)
1. 数据分布扁平程度的测度
2. 峰度系数=3扁平程度适中
3. 偏态系数<3为扁平分布
4. 偏态系数>3为尖峰分布
三、描述统计量的软件实现
1、Excel
选择工具==>数据分析==>描述统计
即可输出大部分描述统计量。
但EXCEL只能按行或列进行分组统计,因此在编辑数据时要注意。
2、SPSS
SPSS的许多模块均可完成描述性分析,但专门为该目的而设计的几个模块则集中在Analyze→Descriptive Statistics菜单中,最常用的是列在最前面的四个过程:
●Frequencies过程的特色是产生频数表;
●Descriptives过程则进行一般性的统计描述;
●Explore过程用于对数据概况不清时的探索性分析;
●Crosstabs过程则完成计数资料和等级资料的统计描述和一般的统计检验;
●我们常用的X2 检验也在其中完成。
2.1 Frequencies过程
此过程可以方便地对数据按组进行归类整理,形成各变量的不同水平的频数分布表和图形,以便对各变量的数据特征和观测量分布状况有一个概括的认识。频数分布表是描述性统计中最常用的方法之一。它还可对数据的分布趋势进行初步分析。
【Statistics 按钮】
● Percentile Values复选框组定义需要输出的百分位数,可计算四分
位数(Quartiles)、每隔指定百分位输出当前百分位数(Cut points
for equal groups)、或直接指定某个百分位数(Percentiles),如直接指定输出P2.5和P97.5;
● Central tendency 复选框组用于定义描述集中趋势的一组指标:均数
(Mean)、中位数(Median)、众数(Mode)、总和(Sum) ;
● Dispersion复选框组用于定义描述离散趋势的一组指标:标准差
(Std.deviation)、方差(Variance)、全距 (Range)、最小值(Minimum)、最大值(Maximum)、均值标准误差(S.E.mean) ;
● Distribution复选框组用于定义描述分布特征的两个指标:偏度系数
(Skewness)和峰度系数(Kurtosis) ;
● Values are group midpoints复选框当你输出的数据是分组频数数据,
并且具体数值是组中值时,选中该复选框以通知SPSS,免得它犯错误。
【Chart 按钮】
● Chart type 单选钮组 定义统计图类型,有四种选择:无、条图(Bar chart )、饼图(Pie chart)、直方图Histogram ),其中直方图还可以选择是否加上正态曲线(With normal curve ) ;
● Chart Values 单选钮组 定义是按照频数还是按百分比做图(即影响纵坐标刻度)。 例4.1 利用房价原始数据图.Sav 绘制频数表、直方图,计算均数、标准差、中位数M 、p2.5和p97.5。
1. Analyze==>Descriptive Statistics==>Frequencies
2. Variables 框:选入Price
3. 单击Statistics 钮:
4. 选中Mean 、Std.deviation 、Median 复选框
5. 单击Percentiles :输入2.5:单击Add :输入97.5:单击Add :
6. 单击Continue 钮
7. 单击Charts 钮:
8. 选中Bar charts 9. 单击Continue 钮 10. 单击OK 。
最上方为表格名称,左上方为分析变量名,可见样本量N 为105例,缺失
值0例,均数Mean=220.72,中位数Median=213.00,标准差STD=47.108,P2.5=134.10,P97.5=326.35。
案例1:利用居民储蓄调查表数据进行频数分析,实现: 目标一:分析储户的户口和职业的基本情况;
提示:为使频数分布表一目了然,可调整频数分布表中数据的输出顺序,如按频数的降序输出,户口按饼图输出,职业按条形图输出;
目标二:分析储户一次存(取)款金额的分布,并对城镇储户和农村储户进行比较。
提示:由于存(取)款金额数据为定距型变量,直接采用频数分析不利于对其分布形态的把握,因此考虑先用数据分组功能(Transform→Record)对数据分组后再编制频数分布表;
进行数据拆分,并分别计算城镇储户和农村储户的一次存(取)款金额的四分位数,并通过四分位数比较两者分布上的差异。
2.2 Descriptives过程
可对变量进行描述统计量分析,计算并列出一系列相应的统计指标,包括平均值、算术和、标准差、最大值、最小值等,且可将原始数据转换成标准Z分值(标准正态评分值)并存入数据库。
选择菜单Analyze==>descriptive==> Descriptives 对话框的界面如下所示:
【Save standardized values as variables复选框】
确定是否将原始数据的标准正态评分存为新变量。
案例2:利用居民储蓄调查表数据计算基本描述统计量,实现:
目标一:计算存(取)款金额的基本描述统计量,并分别对城镇储户和农村储户进行比较;
提示:首先按照户口对数据进行拆分;
目标二:分析储户一次存(取)款的数量是否存在不均衡现象。
提示:可以从分析金额是否有大量异常值入手;
计算存(取)款金额的标准化值,并选中Save Standardized As Variables选项,将自动计算存(取)款金额的标准化值,并存为Za5;
对Za5进行排序,并分为三组(Za5<=-3低金额组,-3< Za5<3中金额组, Za5>=3高金额组)后进行频数分析;
观察低金额组(即低异常值组)和高金额组(即高异常值组)的比例,如异常组的总比例大于理论值0.3%,即认为存(取)款金额存在一定的不均衡现象。
2.3 Explore过程
功能: 1.检查数据是否有错误
2.数值的分布特征
3.对数据的规律的初步观察
选择菜单Analyze==>descriptive==> Explore 对话框的界面如下所示:
【Display单选钮组】
用于选择输出结果中是否包含统计描述、统计图或两者均包括。
【Dependent List框】用于选入需要分析的变量。
【Factor List框】如果想让所分析的变量按某种因素取值分组分析,则在这里选入分组变量。
【Label cases by框】
选择一个变量,他的取值将作为每条记录的标签。最典型的情况是使用记录ID 号的变量。
【Statistics钮】
弹出Statistics对话框,用于选择所需要的描述统计量。有如下选项:
● Descriptives复选框:输出均数、中位数、众数、5%修正均数、标准
误、方差、标准差、最小值、最大值、全距、四分位全距、峰度系数、峰
度系数的标准误、偏度系数、偏度系数的标准误及指定的均数可信区间。
● M-estimators复选框:作中心趋势的粗略最大似然确定,输出四个不
同权重的最大似然确定数。
● Outliers复选框:输出五个最大值与五个最小值。
● Percentiles复选框:输出第5%、10%、25%、50%、75%、90%、95%位数。
【Plot钮】
弹出Plot对话框,用于选择所需要的统计图。有如下选项:
● Boxplots单选框组:确定箱式图的绘制方式,可以是按组别分组绘制
(Factor levels together),也可以不分组一起绘制(Depentends
together),或者不绘制(None)。
● Descriptive复选框组:可以选择绘制茎叶图(Stem-and-leaf)和直方
图(Histogram)。
● Normality plots with test复选框:绘制正态分布图并进行变量是
否符合正态分布的检验。
● Spread vs. Level with Levene Test单选框组:当选择了分组变量
时,绘制spread-versus-level图,设置绘图时变量的转换方式,并进行组间方差齐性检验。
【Options钮】
用于选择对缺失值的处理方式,可以是不分析有任一缺失值的记录、不分析计算某统计量时有缺失值的记录,或报告缺失值。
以下是房价茎叶图:
price
price Stem-and-Leaf Plot
Frequency Stem & Leaf
3.00 1 . 223
3.00 1 . 455
16.00 1 . 6667777777777777
20.00 1 . 88888888888999999999
14.00 2 . 00000000001111
14.00 2 . 22222222233333
13.00 2 . 4444444455555
8.00 2 . 66666777
7.00 2 . 8899999
4.00 3 . 0111
2.00 3 . 22
1.00 3 . 4
Stem width: 100
Each leaf: 1 case(s)
以上是茎叶图,整数位为茎,小数位为叶。这样可以非常直观的看出数据的分布范围及形态,在国外非常流行。
以上是箱线图,中间的黑粗线为均数,红框为四分位间距的范围,上下两
个细线为最大、最小值。
案例3:利用居民储蓄调查表数据分析储户存(取)款金额的分布情况。 2.4 Crosstabs 过程(列联表分析)
Crosstabs 过程用于分析多个变量不同取值下的分布,掌握多变量的联合分布特征,进而分析变量之间的相互影响和关系。称列联表分析或交叉分组下的频数分析。 两大基本任务:
1)根据收集到的样本数据编制二维或多维交叉列联表;
2)在交叉列联表的基础上,对两两变量间是否存在一定的相关性进行分析。 Crosstabs 过程不能产生一维频数表(单变量频数表),该功能由Frequencies 过程实现。
交叉列联表的卡方检验: 检验行变量和列变量是否独立?
◆ 建立零假设(H0);列联表分析中卡方检验的零假设为行变量与列变量独立;
◆ 选择和建立检验统计量;列联表分析中卡方检验的检验统计量是Pearson 卡方统计量。
◆确定显著性水平和临界值;
◆结论和决策。
方法一:如果卡方的观测值大于卡方临界值,可拒绝零假设;
方法二:如果卡方观测值的概率p值小于等于α,拒绝零假设。
在SPSS中,上述列联表卡方检验的过程,除用户要自行确定显著性水平和进行决策外,其余各步都是SPSS自动完成的;
SPSS将自动计算卡方统计量的观测值以及大于等于该值的概率P值;
因此,在应用中,用户只要明确零假设,便可方便地按照第二种决策方式进行决策。
事实上,所有的假设检验均是这样进行的。
例4.2利用下表格数据,进行列联表分析。
解:由于此处给出的直接是频数表,因此在建立数据集时可以直接输入三个变量――行变量、列变量和指示每个格子中频数的变量,然后用Weight Cases对话框指定频数变量,最后调用Crosstabs过程进行X2检验。假设三个变量分别名为R、C和W,则数据集结构和命令如下:
1. Data==>Weight Cases
2. Weight Cases by单选框:选中
3. Freqency Variable:选入W
4.单击OK钮
5. Analyze==>Descriptive Statistics==>Crosstabs
6. Rows框:选入R
7. Columns框:C
8. Statistics钮:Chi-square复选框:选中:单击Continue钮
9.单击OK钮
从左到右为:检验统计量值(Value)、自由度(df)、双侧近似概率
(Asymp.Sig.2-sided)、双侧精确概率(Exact Sig.2-sided)、单侧精确概率(Exact Sig.1-sided);
从上到下为:Pearson卡方(Pearson Chi-Square即常用的卡方检验)、连续性校正的卡方值(Continuity Correction)、对数似然比方法计算的卡方(Likelihood Ratio)、Fisher‘s确切概率法(Fisher’s Exact Test)、线性相关的卡方值(Linear by Linear Association)、有效记录数(N of Valid Cases)。
另外,Continuity Correction和Pearson卡方值处分别标注有a和b,表格下方为相应的注解:a.只为2*2表计算。b.0%个格子的期望频数小于5,最小的期望频数为13.78。因此,这里无须校正,直接采用第一行的检验结果,即
X2=6.133,P=0.013,如给定显著性α为0.05,由于卡方的频率p值小于α,因此拒绝零假设,即认为两组方法治疗效果有差异。
如果交叉列联表中有20%以上单元格中的期望频数小于5,则一般不宜使用卡方检验。在这种情况下,可以采用似然率卡方检验等方法进行修正。
例4.3 以数据加工(职工数据).sav为例,检验职称和文化程度是否有关联?
1. Analyze==>Descriptive Statistics==>Crosstabs;
2.如果进行二维列联表分析,将行变量职称(zc)选择到Row(s)框,
将列变量文化程度(xl)选择到Column框中;
3.选择Display clustered bar charts选项,指定绘制各变量交叉分
组下频数分布柱形图,suppress tables表示不输出列联表,仅分析行列变量间关系;
4.单击Cell按钮指定列联表单元格中的输出内容;
5.单击Format按钮指定列联表各单元的输出排列顺序,SPSS默认以
行变量取值的升序排列;
6.单击Statistics按钮指定用哪种方法分析行变量和列变量间的关
系,一般选择Chi-Square卡方检验。
案例4:利用居民储蓄调查表数据进行计算,实现以下两个目标:
目标一:分析城镇储户和农村储户对“未来两年内收入状况的变化趋势”是否持相同的态度;
提示:列联表的行变量为户口(a13),列变量为未来收入情况(a3),在列联表中输出各种百分比,期望频数、剩余、标准化剩余,同时显示各交叉分组下频数分布柱形图,并利用卡方检验方法,对城镇和农村储户对该问题的态度是否一致进行分析;
目标二:分析城镇和农村储户对储蓄是否合算的认同是否一致。
提示:该分析中列联表的行变量为户口(a13),列变量为什么合算(a1),在列联表的基础上进行卡方检验。
补充:多选项分析
多选项分析是针对问卷调查中的多选项问题的。
对于多选项问题由于答案个数不止一个,如果仍按单选问题的方式设置SPSS变量,那么该变量虽然能够存储多个答案,但却无法直接支持对问题的分析。即对一个多选项问题仅设置一个SPSS变量在数据处理和分析中是行不通的。
●将多选项问题分解;(前面已讲过)
●利用前面讲到的频数分析或交叉分组下的频数分析等方法进行分析。
多选项频数分析或多选项交叉分组下的频数分析
1、定义多项选择变量集
将多选项问题分解并设置成多个变量后,指定这些变量为一个集合。
1、选择菜单 Analyze==>Multiple Response==>Define sets;
2、从数值型变量中将进入多选项变量集的变量选择到Variables in sets框中;
3、在variables are coded as框中指定多选项变量集中的变量是按照哪种方法分解的。Dichotomies表示以多选项二分法分解,并在counted value中输入对哪组值进行分析。Spss规定等于该值的样本为一组,其余样本为另一组;categories表示以多选项分类法分解,并在Range框和through框中输入变量取值的最小值和最大值。
4、为多选项变量集命名,系统会自动在该名字前加字符$;
5、单击Add按钮将定义好的多选项变量集加到Mult Response Sets框中。2、定义多项选择变量集
将多选项问题分解并设置成多个变量后,指定这些变量为一个集合。
选择菜单 Analyze==>Multiple Response==>Define sets
3、多选项频数分析操作或多选项交叉分组下的频数分析
选择菜单Analyze==>Multiple Response==>Frequencies
或选择菜单Analyze==>Multiple Response==>Crosstabs
与前Frequencies和Crosstabs操作类似。
案例5:利用居民储蓄调查表数据进行分析,实现以下两个分析目标:
分析储户的储蓄目的;
提示:即回答储蓄的最主要目的是什么,占到多少?什么的比例最少?
分析不同年龄段储户的储蓄目的。
提示:采用多选项交叉分组下的频数分析。回答20岁以下储户中存钱主要是为了什么?其他如20~35岁的储户,35~50岁的储户,50岁以上的储户他们存钱的最主要的目的又是什么呢?
多元统计分析实例汇总
多元统计分析实例 院系:商学院 学号: 姓名:
多元统计分析实例 本文收集了2012年31个省市自治区的农林牧渔和相关农业数据,通过对对收集的数据进行比较分析对31个省市自治区进行分类.选取了6个指标农业产值,林业产值.牧业总产值,渔业总产值,农村居民家庭拥有生产性固定资产原值,农村居民家庭经营耕地面积. 数据如下表: 一.聚类法
设定4个群聚,采用了系统聚类法.下表为spss分析之后的结果.
Rescaled Distance Cluster Combine C A S E 0 5 10 15 20 25 Label Num +---------+---------+---------+---------+---------+ 内蒙 5 -+ 吉林 7 -+ 云南 25 -+-+ 江西 14 -+ +-+ 陕西 27 -+-+ | 新疆 31 -+ +-+ 安徽 12 -+-+ | | 广西 20 -+ +-+ +-------+ 辽宁 6 ---+ | | 浙江 11 -+-----+ | 福建 13 -+ | 重庆 22 -+ +---------------------------------+ 贵州 24 -+ | | 山西 4 -+---+ | | 甘肃 28 -+ | | | 北京 1 -+ | | | 青海 29 -+ +---------+ | 天津 2 -+ | | 上海 9 -+ | | 宁夏 30 -+---+ | 西藏 26 -+ | 海南 21 -+ | 河北 3 ---+-----+ | 四川 23 ---+ | | 黑龙江 8 -+-+ +-------------+ | 湖南 18 -+ +---+ | | | 湖北 17 -+-+ +-+ +-------------------------+ 广东 19 -+ | | 江苏 10 -------+ | 山东 15 -----------+-----------+ 河南 16 -----------+
多元统计分析实验报告
实验一 一、实验目的及要求 对应分析是你也降维的思想以达到减化数据结构的目的,凤的研究广泛用于定义属性变量构成的列联表利用对应分析方法分析问卷中教育程度与网上购物支付方式之间的相互关系。 二、实验环境 SPSS 19.0 window 7系统 三、实验内容及实验步骤(实践内容、设计思想与实现步骤) 实验题目: 通过分析问卷数据,绘制如下的教育程度与网上购物支付方式的交叉表,运用对应分析方法研究教育程度与网上购物所选择的支付方式之间的相关性,及揭示不同人群网上购物的特征等问题。 设计思想:原假设:H1:χ2>χα2[(n?1)(p?1)] 实现步骤: 1.在变量视窗中录入3个变量,用edu表示【教育程度】,用fangshi表示【在网上购物时采用什么样的支付方式】,用pinshu表示【频数】;如图所示:
2.先对数据进行预处理。执行【数据】→【加权个案】命令,弹出【加权个案】对话框。选中【加权个案】按钮,把【频数】放入【频率变量】框中,点击【确定】按钮完成。 3.打开主窗口,选择菜单栏中的【分析】→【降维】→【对应分析】命令,弹出【对应分析】对话框。 4.将【教育程度】导入【行】,将【在网上购物时采用什么样的支付方式】导入【列】。 5. 单击【定义范围(D)】,打开【对应分析:定义行范围】对话框; 定义行变量分类全距最小值为1,最大值为4,单击【更新】;点击【继续】,返回【对应分析】对话框;同方法打开【对应分析:定义列范围】对话框; 定义列变量全距最小值为1,最大值为5,单击【更新】; 6. 单击【统计量】打开【对应分析:统计量】对话框;选择【行轮廓表】,【列轮廓表】;单击【继续】,返回【对应分析】对话框, 7.选择【绘制】→【对应分析:图】对话框,选择【散点图】中的【行点】、【列点】选择【线图】中的【已转换的行类别】、【已转换的列类别】,单击【继续】,返回【对应分析】对话框。 8.单击【确定】按钮,完成设置并执行列联表分析。 四、调试过程及实验结果(详细记录实验在调试过程中出现的问题及解决方法。记录实验的结果) SPSS实验结果及分析: 上表显示了在32155名被调查者中,大多数消费者在网上购物时选择第三方支付和网上银行支付,在网上购物的消费人群以大学本科生相对最多。
SAS数据的描述性统计分析答案
实验一数据的描述性统计分析 一、选择题 1、以下( B )语句对变量进行分组,在使用前需按分组变量进行排序? 以下( C )语句可对变量进行分类,在使用前不必按分类变量进行排序? 用( A )语句可以选择输入数据集的一个行子集来进行分析? (A)WHERE语句(B)BY语句(C)CLASS语句(D)FREQ语句2、排序过程步中必须用什么语句对变量进行排序?( A ) (A)BY语句(B)CLASS语句(C)WHERE语句 3、如果要对数据集中的数据进行正态性检验,需要使用哪个过程?( B )(A)MEANS (B)UNIV ARIATE (C)FREQ 4、用UNIV ARIATE过程进行数据分析,要求此过程输出茎叶图、正态概率图等,应在语句中加上什么选项?(plot ) 5、用UNIV ARIATE过程进行数据分析,在输出结果中哪个统计量是对样本均值 为零的T检验的概率值?( A ) (A)T: Mean (B)Prob>|S| (C)Sgn Rank (D)Prob>|T| 二、假设某校100名女生的血清总蛋白含量(g/L)服从均值为75,标准差为3的正态分布,试产生样本数据,并利用SAS软件解决下面问题: 1、计算样本均值、方差、标准差、极差、四分位极差、变异系数、偏度、峰度; 2、画出直方图(垂直条形图); 3、画出茎叶图、盒形图和正态概率图; 4、试进行正态性检验。 Data N; DO i=1to100; x=75+3*normal(12345); output; end; proc print; run; proc univariate data=N; var x; run; proc gchart data=N; block x; run; proc univariate data=N plot; var x;
描述性统计分析报告--Descriptive Statistics菜单详解
第六章:描述性统计分析-- Descriptive Statistics菜单详解 描述性统计分析是统计分析的第一步,做好这第一步是下面进行正确统计推断的先决条件。SPSS的许多模块均可完成描述性分析,但专门为该目的而设计的几个模块则集中在Descriptive Statistics菜单中,最常用的是列在最前面的四个过程:Frequencies过程的特色是产生频数表;Descriptives过程则进行一般性的统计描述;Explore过程用于对数据概况不清时的探索性分析;Crosstabs 过程则完成计数资料和等级资料的统计描述和一般的统计检验,我们常用的X2检验也在其中完成。 本章讲述的四个过程在9.0及以前版本中被放置在Summarize菜单中。 §6.1 Frequencies过程 频数分布表是描述性统计中最常用的方法之一,Frequencies过程就是专门为产生频数表而设计的。它不仅可以产生详细的频数表,还可以按要求给出某百分位点的数值,以及常用的条图,圆图等统计图。 和国内常用的频数表不同,几乎所有统计软件给出的均是详细频数表,即并 不按某种要求确定组段数和组距,而是按照数值精确列表。如果想用Frequencies过程得到我们所熟悉的频数表,请先用第二章学过的Recode过程产生一个新变量来代表所需的各组段。 6.1.1 界面说明 Frequencies对话框的界面如下所示:
该界面在SPSS中实在太普通了,无须多言,重点介绍一下各部分的功能如下:【Display frequency tables复选框】 确定是否在结果中输出频数表。 【Statistics钮】 单击后弹出Statistics对话框如下,用于定义需要计算的其他描述统计量。 现将各部分解释如下:
多元统计分析实验报告
1. 正态性检验 Kolmogorov-Smirnov a Shapir o-Wilk 统计量df Sig. 统计量df Sig. 净资产收益率.113 35 .200*.978 35 .677 总资产报酬率.121 35 .200*.964 35 .298 资产负债率.086 35 .200*.962 35 .265 总资产周转率.180 35 .006 .864 35 .000 流动资产周转率.164 35 .018 .885 35 .002 已获利息倍数.281 35 .000 .551 35 .000 销售增长率.103 35 .200*.949 35 .104 资本积累率.251 35 .000 .655 35 .000 *. 这是真实显著水平的下限。 a. Lilliefors 显著水平修正 此表给出了对每一个变量进行正态性检验的结果,因为该例中样本中n=35<2000,所以此处选用Shapiro-Wilk统计量。由Sig.值可以看到,总资产周转率、流动资产周转率、已获利息倍数及资本积累率均明显不遵从正态分布,因此,在下面的分析中,我们只对净资产收益率、总资产报酬率、资产负债率及销售增长率这四个指标进行比较,并认为这四个变量组成的向量遵从正态分布(尽管事实上并非如此)。这四个指标涉及公司的获利能力、资本结构及成长能力,我们认为这四个指标可以对公司运营能力做出近似的度量。 2. 主体间因子 N 行业电力、煤气及水的生产和供应 业 11 房地行业15 信息技术业9 多变量检验a 效应值 F 假设 df 误差 df Sig. 截距Pillai 的跟踪.967 209.405b 4.000 29.000 .000 Wilks 的 Lambda .033 209.405b 4.000 29.000 .000 Hotelling 的跟踪28.883 209.405b 4.000 29.000 .000 Roy 的最大根28.883 209.405b 4.000 29.000 .000 行业Pillai 的跟踪.481 2.373 8.000 60.000 .027 Wilks 的 Lambda .563 2.411b8.000 58.000 .025 Hotelling 的跟踪.698 2.443 8.000 56.000 .024 Roy 的最大根.559 4.193c 4.000 30.000 .008 a. 设计 : 截距 + 行业
多元统计分析案例分析.docx
精品资料 一、对我国30个省市自治区农村居民生活水平作聚类分析 1、指标选择及数据:为了全面分析我国农村居民的生活状况,主要考虑从收入、消费、就业等几个方面对农村居民的生活状况进行考察。因此选取以下指标:农村产品价格指数、农村住宅投资、农村居民消费水平、农村居民消费支出、农村居民家庭人均纯收入、耕地面积及农村就业人数。现从2010年的调查资料中
2、将数据进行标准化变换:
3、用K-均值聚类法对样本进行分类如下:
分四类的情况下,最终分类结果如下: 第一类:北京、上海、浙江。 第二类:天津、、辽宁、、福建、甘肃、江苏、广东。 第三类:浙江、河北、内蒙古、吉林、黑龙江、安徽、山东、河南、湖北、四川、云南。 第四类:山西、青海、宁夏、新疆、重庆、贵州、陕西、湖南、广西、江西、。从分类结果上看,根据2010年的调查数据,第一类地区的农民生活水平较高,第二类属于中等水平,第三类、第四类属于较低水平。 二、判别分析 针对以上分类结果进行判别分析。其中将新疆作作为待判样本。判别结果如下:
**. 错误分类的案例 从上可知,只有一个地区判别组和原组不同,回代率为96%。 下面对新疆进行判别: 已知判别函数系数和组质心处函数如下: 判别函数分别为:Y1=0.18x1 +0.493x2 + 0.087x3 + 1.004x4 + 0.381x5 -0.041x6 -0.631x7 Y2=0.398x1+0.687x2 + 0.362x3 + 0.094x4 -0.282x5 + 1.019x6 -0.742x7 Y3=0.394x1-0.197x2 + 0.243x3-0.817x4 + 0.565x5-0.235x6 + 0.802x7 将西藏的指标数据代入函数得:Y1=-1.08671 Y2=-0.62213 Y3=-0.84188 计算Y值与不同类别均值之间的距离分别为:D1=138.5182756 D2=12.11433124 D3=7.027544292 D4=2.869979346 经过判别,D4最小,所以新疆应归于第四类,这与实际情况也比较相符。 三,因子分析: 分析数据在上表的基础上去掉两个耕地面积和农村固定资产投资两个指标。经spss软件分析结果如下:
多元统计分析实验报告,计算协方差矩阵,相关矩阵,SAS
院系:数学与统计学学院 专业:__统计学 年级:2009 级 课程名称:统计分析 ____ 学号:____________ 姓名:_________________ 指导教师:____________ 2012年4月28日 (一)实验名称 1. 编程计算样本协方差矩阵和相关系数矩阵;
2. 多元方差分析MANOVA。 (二)实验目的 1. 学习编制sas程序计算样本协方差矩阵和相关系数矩阵; 2. 对数据进行多元方差分析。 (三)实验数据 第一题: 第二题:
(四)实验内容 1. 打开SAS软件并导入数据; 2. 编制程序计算样本协方差矩阵和相关系数矩阵; 3. 编制sas程序对数据进行多元方差分析; 4. 根据实验结果解决问题,并撰写实验报告; (五)实验体会(结论、评价与建议等) 第一题: 程序如下: proc corr data=sasuser.sha n cov; proc corr data=sasuser.sha n no simple cov; with x3 x4; partial x1 x2; run; 结果如下: (1)协方差矩阵 $AS亲坯 曲;15 Friday, Apr: I SB,沙DO COUR过程 x4 目由度=30 Xi x2x3x4x5X? -10.I9B4944-0.45E2GJ5I.3347097-G.1193E48-£0.e75?GS
-ID. 188494669,36&Q3?9-7.22IO&OS1J5692043I5.49ee^91S.Oa97SM -8.45S2645■7,221050829.S78&S46-6.372E47I-15.3084183-21.7352376-11.5674785 1.3841097 1.G5S2M7t.3726171IJ24?17B 4.e093011 4.4C12473 2.B747CM -G. I1S3S49 1.GS92043-is.soul aa 4.B09B01I68.7978495劣』S670971S.57ai1B3 -IH.05l6l?a15.43S6569-J1.73S2376孔耶124TB27.0387097105.103225&S7.3505S7E: -2D K5752??319-11337204-1L55M7S52r9747?3i19,573118337.3S0&87E33.3SQ6452 (2) 相关系数矩阵 Pearson相关系数” N =引 当HO: Rho=0 时.Prob > |r| Xi Xi xl 1.QQ000 x2 -C.23954 0.2061 x3 -0,30459 0.0957 x4 0.18975 Q.3092 x5 '0.14157 0.4475 x6 -0.83787 0.0630 -0.49292 0.0150 x2-0.23354 1.00000-0.162750.143510.022700.181520.24438 x20.20C10.31:1?0.441?0.90350.32640.1761 x3-0.30459-0.16275 1.00000-0.06219-0.34641-0.^797-0.23674 x30.095?0.381?<.00010.0563o.oses0 JS97 x40.1S8760.14351-0.86219L000000.400540,313650.22610 x40.30920.4412<.0001 D.02EG Q.085S0.2213 x5-0J 41570.02270-0.946410.40054 1.000000.317370.26750 x50.4J750.90350.0G68Q.025&0.08130 + 1620 x6-0.33?e?0.1S162-0.397970.813650.31787LOOOOO0.82976 x60.0S300.32840.02660.08580.0813C0001辺-0.432920.24938-0.288740.22810 D.267600.92976 1.00000 x70,01500J7610.19970.22130JG20<.0001 第二题: 程序如下: proc anova data=sasuser.hua ng; class kind; model x1-x4=k ind; manova h=k ind; run; 结果如下: (1)分组水平信息 The ANNA Procedure Cla^s Level Informat ion Class Level?Values kind 3 123 Number of observatIons CO (2) x1、x2、x3、x4的方差分析
05.第五讲 描述性统计分析评价方法
第五讲描述性统计分析评价方法——综合指标 实际上,从这一讲开始的教学内容都是介绍教育评价技术中的重要方法——教育统计分析方法,也即是分析资料的方法。其中包括描述性统计分析方法和推断性统计分析方法两大部分。 一、描述性统计分析评价方法的主要特点。对数据资料计算综合指标,然后根据综合指标值对教育客观事物给予评价。所谓综合指标指的是从数量方面综合说明事物特征的指标。常用的综合指标有绝对数、相对数、平均数和标准差。重点介绍后面两种。 二、综合指标的计算及解释 (一)绝对数(规模) (二)相对数(程度) (三)平均数(水平) 通常可用符号表示平均数 1.算术平均数(未经分类汇总的测量数据资料)计算方法见p62的(4.1)公式。 2.加权平均数(已经分类汇总的资料)
①组距数列平均数(对测量数据分组统计人数)例如P63表4-1的资料。计算方法如P63的(4.2)公式及83名教师平均年龄的计算。 * 为了减少计算的麻烦,在此介绍计算器统计功能的使用: A、操作步骤 计算器的统计功能的计算只能得到如下六个统计结果:n(数据个数)、(数据和)、(数据平方和)、(平均数)、(总体标准差)和S(样本标准差)。操作步骤如下:1)显示统计状态:2ndF STAT(或SD) 2)输入数据:每输入一个数据按DATA 3)取出统计结果:这时六个统计结果均处于待取状态,可根据需要取出其中的结果。 B、注意事项 1)若需继续进行第二组数据的统计运算时,需取消统计状态,再按上述步骤操作。按2ndF STAT即可取消统计的状态。 2)若不需要计算、、、、和S时(即进行 其他一般运算时),也应取消统计状态)。
利用Excel进行数据整理和描述性统计分析
实训一利用Excel进行数据整理和描述性统计分析 一、实训目的 目的有三:(1)掌握Excel中基本的数据处理方法;(2)学会使用Excel进行统计分组;(3)学会使用Excel计算各种描述性统计指标,能以此方式独立完成相关作业。 二、实训要求 1、已学习教材相关内容,理解数据整理中的统计计算问题;理解描述性统计指标中的统计计算问题;已阅读本次实训指导书,了解Excel中相关的计算工具。 2、准备好一个统计分组问题、准备好一个或几个描述性统计指标计算问题及相应数据(可用本实训所提供问题与数据)。 3、以Word文件形式(其中的统计表和统计图用Excel制作)提交实训报告(含:实训过程记录、疑难问题发现与解决记录(可选))。此条为所有实训所要求。 三、实训内容和操作步骤 (一)问题与数据 有顾客反映某家航空公司售票处售票的速度太慢。为此,航空公司收集了解100位顾客购票所花费时间的样本数据(单位:分钟),结果如下表。
航空公司认为,为一位顾客办理一次售票业务所需的时间在五分钟之内就是合理的。上面的数据是否支持航空公司的说法顾客提出的意见是否合理请你对上面的数据进行适当的分析,回答下列问题。 (1)对数据进行等距分组,整理成频数分布表,并绘制频数分布图(直方图、折线图、饼图)。 (2)根据分组后的数据,计算中位数、众数、算术平均数和标准差。 (3)分析顾客提出的意见是否合理为什么 (4)使用哪一个平均指标来分析上述问题比较合理 答:(1): 2:
从表中我们可以得到中位数为众数为1平均数为标准差为 (3):合理,虽然他的平均数是<5属于正常范围,但是依旧有将近20%的购票时间>5分钟属于超过正常范围,那就是速度太慢了。平均数不能代表一切。 所以顾客提出的理由是正确的,购票太慢的现象确实存在。 (4):平均数比较合理,它能较好的反映购票的大概时间。比较有代表性! 实训二用Excel数据分析功能进行统计整理 和计算描述性统计指标 一、实训目的 学会使用Excel数据分析功能进行统计整理和计算各种描述性统计指标,能以此方式独立完成相关作业。 二、实训要求 1、已学习教材相关内容,理解统计整理和描述性统计指标中的统计计算问题;已阅读本次实验导引,了解Excel中相关的计算工具。 2、准备好一个统计分组问题、准备好一个或几个数字特征计算问题及相应数据(可用本实验导引所提供问题与数据)。 3、以Word文件形式(其中的统计表和统计图用Excel制作)提交实训报告(含:实训过程记录、疑难问题发现与解决记录(可选))。此条为所有实训所要求。 三、实训内容和操作步骤
多元统计分析实验报告
多元统计分析实验报告 Document serial number【UU89WT-UU98YT-UU8CB-UUUT-UUT108】
1. 正态性检验 Kolmogorov-Smirnov a Shapir o-Wilk 统计量df Sig.统计量df Sig. 净资产收益 .11335.200*.97835.677 率 总资产报酬 .12135.200*.96435.298 率 资产负债率.08635.200*.96235.265 总资产周转 .18035.006.86435.000 率 流动资产周 .16435.018.88535.002 转率 已获利息倍 .28135.000.55135.000 数 销售增长率.10335.200*.94935.104 资本积累率.25135.000.65535.000 *. 这是真实显着水平的下限。 a. Lilliefors 显着水平修正 此表给出了对每一个变量进行正态性检验的结果,因为该例中样本中 n=35<2000,所以此处选用Shapiro-Wilk统计量。由Sig.值可以看到,总资产周转率、流动资产周转率、已获利息倍数及资本积累率均明显不遵从正态分布,因此,在下面的分析中,我们只对净资产收益率、总资产报酬率、资产负债率及销售增长率这四个指标进行比较,并认为这四个变量组成的向量遵从正态分布(尽管事实上并非如此)。这四个指标涉及公司的获利能力、资本结构及成长能力,我们认为这四个指标可以对公司运营能力做出近似的度量。 2. 主体间因子 N
行业电力、煤气及水的 生产和供应业 11 房地行业15 信息技术业9 多变量检验a 效应值F假设 df 误差 df Sig. 截距Pillai 的跟 踪 .967.000 Wilks 的 Lambda .033.000 Hotelling 的跟踪 .000 Roy 的最大 根 .000 行业Pillai 的跟 踪 .481.027 Wilks 的 Lambda .563.025 Hotelling 的跟踪 .698.024 Roy 的最大 根 .559.008 a. 设计 : 截距 + 行业 b. 精确统计量 c. 该统计量是 F 的上限,它产生了一个关于显着性级别的下 限。 上面第一张表是样本数据分别来自三个行业的个数。第二张表是多变量检验表,该表给出了几个统计量,由Sig.值可以看到,无论从哪个统计量来看,三个行业的运营能力(从净资产收益率、总资产报酬率、资产负债率及销售增长率这四个指标的整体来看)都是有显着差别的。 3. 主体间效应的检验
多元统计分析实验报告doc
多元统计与程序设计》课程实验报告 项目名称: 学生姓名: 学生学号: 指导教师: 完成日期:
1 实验内容 2 模型建立与求解 2.1聚类分析的形成思路 2.2.1类平均法 2.2.2谱系图的形成 2.3.快速聚类法 (以上内容见课本) 3 实验数据与实验结果 3.1实验数据 设有20个土壤样品分别对5个变量的观测数据如表5.16所示,试利用 聚类法对其进行样品聚类分析 样品号 含沙量1X 淤泥含量2X 粘土含量3X 有机物4X PH 值5X 1 77.3 13.0 9.7 1.5 6.4 2 82.5 10.0 7.5 1.5 6.5 3 66.9 20.0 12.5 2.3 7.0 4 47.2 33.3 19.0 2.8 5.8 5 65.3 20.5 14.2 1.9 6.9 6 83.3 10.0 6.7 2.2 7.0 7 81.6 12.7 5.7 2.9 6.7 8 47.8 36.5 15.7 2.3 7.2 9 48.6 37.1 14.3 2.1 7.2 10 61.6 25.5 12.6 1.9 7.3 11 58.6 26.5 14.9 2.4 6.7 12 69.3 22.3 8.4 4.0 7.0 13 61.8 30.8 7.4 2.7 6.4 14 67.7 25.3 7.0 4.8 7.3 15 57.2 31.2 11.6 2.4 6.3 16 67.2 22.7 10.1 33.3 6.2 17 59.2 31.2 9.6 2.4 6.0 18 80.2 13.2 6.6 2.0 5.8
19 82.2 11.1 6.7 2.2 7.2 20 69.7 20.7 9.6 3.1 5.9 3.2实验过程及结果 Case Processing Summary(a) Cases Valid Missing Total N Percent N Percent N Percent 20 100.0% 0 .0% 20 100.0% a Squared Euclidean Distance used 上表是接近度矩阵,计算距离使用的是平方欧氏距离,所以样品间距离越大,样品越相异,由表中矩阵可以看出样品8号和样品9号的距离是最小的,因此它们最先聚为一类。 Average Linkage (Between Groups) Agglomeration Schedule Stage Cluster Combined Coefficient s Stage Cluster First Appears Next Stage Cluster 1 Cluster 2 Cluster 1 Cluster 2 1 8 9 .153 16
多元统计分析实验报告
多元统计分析实验报告 1、实验内容 根据课本习题3-12做相关分析。 2、实验目的 (1)检验H0:;H1:协方差阵不全相等。 (2)检验H0: U1=U2 ; H1:U1≠U2; (3)检验H0: U1=U2 =U3 ; H1:U1,U2,U3不全等; (4)检验三种化学成分相互独立。 3、实验方案分析 (1)这是关于判断三个3元正态总体的协方差阵是否相等的问题; (2)均值是否相等,在两个协方差阵相等的情况下均值是否相等的问题; (3)比较三组的3项指标是否有差异的问题,就是多总体均值向量是否相等的检验问题; (4)检验 是否独立相当于检验任意2个子向量的协方差阵是否为零矩阵; 4、实验原理及操作过程,结果如下: (1)SAS 代码实现过程如下: data d3121; input y1-y3 group @@; cards; 47.22 5.06 0.10 1 1 23 ==∑∑∑
47.45 4.35 0.15 1 47.52 6.85 0.12 1 47.86 4.19 0.17 1 47.31 7.57 0.18 1 54.33 6.22 0.12 2 56.17 3.31 0.15 2 54.40 2.43 0.22 2 52.62 5.92 0.12 2 43.12 10.33 0.05 3 42.05 9.67 0.08 3 42.50 9.62 0.02 3 40.77 9.68 0.04 3 ; proc iml; n1=5;n2=4;n3=4; n=n1+n2+n3;k=3; p=3; use d3121(obs=5); xa={y1 y2 y3 }; read all var xa into x1; print x1; use d3121(firstobs=6 obs=9); read all var xa into x2; print x2; use d3121(firstobs=10 obs=13); read all var xa into x3; print x3; xx=x1//x2//x3; ln={[5] 1} ; x10=(ln*x1)/n1; print x10; mm1=i(n1)-j(n1,n1,1)/n1; mm=i(n)-j(n,n,1)/n; a1=x1`*mm1*x1; print a1; ln={[4] 1} ; x10=(ln*x2)/n2; print x20;
描述性统计分析-Eviews
主讲人:刘莎莎 第三讲 描述性统计分析
一、 序列窗口下的描述性统计分析
知识点 1:如何以建立组对象的方式将数据导入到 Eviews 中去(第二种导入数 据的方式) 。 知识点 2:如何在序列窗口下实现简单描述性统计量和直方图,将直方图和正态 分布曲线叠加在一起,从而更直观地观察数据的分布特征。 (如何将 EViews 图形 复制粘贴到 word 中) 知识点 3:如何在序列窗口下实现描述性统计量的假设检验 知识点 4:如何实现将单序列按某一变量分类后再进行描述性统计分析(本案例 的分类变量是该天是星期几) 知识点 5:如何实现将单序列按某一变量分类后再进行假设检验 知识点 6:如何画上证综指日对数收益率的 QQ 图 知识点 7:如何估计数据的经验分布函数的参数 案例数据说明:2003 年 1 月 6 日-2009 年 6 月 26 日上证综指日对数收益率。
二、序列组窗口下的描述性统计分析
知识点 1:如何通过打开 excel 文件的方式将数据导入到 Eviews 中去。 (第三种 导入数据的方式) 。 知识点 2:如何实现多变量的描述性统计量 知识点 3:如何实现多变量描述性统计量的假设检验 案例数据说明:国家统计调查队分别在两个地区调查了 10 个家庭的收入 知识点 4:如何计算当前序列组的相关系数矩阵,协方差矩阵
主讲人:刘莎莎
案例数据说明:1983-2000 年我国粮食生产与相关投入的数据,变量包括粮食产 量(单位:万吨)、农业化肥施用量(单位:万千克)、粮食播种面积(单位: 公顷)
附注:描述性统计量的计算公式
标准差(Std.Dev.)的计算公式是:
s=
2 ( y ? y ) ∑ t t =1
T
T ?1
其中,
yt 是观测值, y 是样本平均数。
偏度(Skewness)的计算公式是:
1 T yt ? y 3 S = ∑( ) T t =1 s
其中,
yt 是观测值, y 是样本平均数,s 是样本标准差,T 是样本容量。对
称分布的偏度是零,比如正态分布。
峰度(Kurtosis)的计算公式是:
1 T yt ? y 4 S = ∑( ) T t =1 s
其中,
yt 是观测值, y 是样本平均数,s 是样本标准差,T 是样本容量。
正态分布的峰度值是 3。
多组和分类数据的描述性统计分析
§3.2多组和分类数据的描述性统计分析17 ?盒子图 盒子图能够直观简洁地展现数据分布的主要特征.我们在R 中使用boxplot()函数作盒子图.在盒子图中,上下四分位数分别确定中间箱体的顶部和底部,箱体中间的粗线是中位数所在的位置.由箱体向上下伸出的垂直部分为“触须”(whiskers),表示数据的散布范围,其为1.5倍四分位间距内距四分位点最远的数据点.超出此范围的点可看作为异常点(outlier). §3.2多组和分类数据的描述性统计分析 在对于多组数据的描述性统计量的计算和图形表示方面,前面所介绍的部分方法不能够有效地使用,例如许多函数都不能直接对数据框进行操作.这时我们需要一些其他的函数配合使用. 1.图形表示: ?散点图:前面介绍的plot,可直接对数据框操作.此时将绘出数据框中所对应的所有变量两两之间的散点图.所做图框中第一行的散点图是以第一个变量为纵坐标,分别以第二、三...个变量为横坐标的散点图.这里数据举例说明. library(DAAG);plot(hills) ?盒子图:前面介绍的boxplot,亦可直接对数据框操作,其在同一个作图区域内画出各组数的盒子图.但是注意,此时由于不同组数据的尺度可能差别很大,这样的盒子图很多时候表达出来不是很有意义.boxplot(faithful).因此这样做比较适合多组数据具有同样意义或近似尺度的情形.例如,我们想做某一数值变量在某个因子变量的不同水平下的盒子图.我们可采用类似如下的命令: boxplot(skullw ~age,data=possum),亦可加上参数horizontal=T,将该盒子图横向放置. boxplot(possum$skullw ~possum$sex,horizontal=T) ?条件散点图:当数据集中含有一个或多个因子变量时,我们可使用条件散点图函数coplot()作出因子变量不同水平下的多个散点图,当然该方法也适用于各种给定条件或限制情形下的作图.其调用格式为 coplot(formula,data)比如coplot(possum[[9]]~possum[[7]] possum[[4]]),或 coplot(skullw ~taill age,data=possum); coplot(skullw ~taill age+sex,data=possum)
描述性统计是指运用制表和分类,图形以及计筠概括性数据来描述数据的集中趋势、离散趋势、偏度、峰度。
一、描述统计 描述性统计是指运用制表和分类,图形以及计筠概括性数据来描述数据的集中趋势、离散趋势、偏度、峰度。 1、缺失值填充:常用方法:剔除法、均值法、最小邻居法、比率回归法、决策树法。 2、正态性检验:很多统计方法都要求数值服从或近似服从正态分布,所以之前需要进行正态性检验。常用方法:非参数检验的K-量检验、P-P图、Q-Q图、W检验、动差法。 二、假设检验 1、参数检验 参数检验是在已知总体分布的条件下(一股要求总体服从正态分布)对一些主要的参数(如均值、百分数、方差、相关系数等)进行的检验。 1)U验使用条件:当样本含量n较大时,样本值符合正态分布 2)T检验使用条件:当样本含量n较小时,样本值符合正态分布 A 单样本t检验:推断该样本来自的总体均数μ与已知的某一总体均数μ0 (常为理论值或标准值)有无差别; B 配对样本t检验:当总体均数未知时,且两个样本可以配对,同对中的两者在可能会影响处理效果的各种条件方面扱为相似; C 两独立样本t检验:无法找到在各方面极为相似的两样本作配对比较时使用。 2、非参数检验 非参数检验则不考虑总体分布是否已知,常常也不是针对总体参数,而是针对总体的某些一股性假设(如总体分布的位罝是否相同,总体分布是否正态)进行检验。 适用情况:顺序类型的数据资料,这类数据的分布形态一般是未知的。
A 虽然是连续数据,但总体分布形态未知或者非正态; B 体分布虽然正态,数据也是连续类型,但样本容量极小,如10以下; 主要方法包括:卡方检验、秩和检验、二项检验、游程检验、K-量检验等。 三、信度分析 检査测量的可信度,例如调查问卷的真实性。 分类: 1、外在信度:不同时间测量时量表的一致性程度,常用方法重测信度 2、内在信度;每个量表是否测量到单一的概念,同时组成两表的内在体项一致性如 何,常用方法分半信度。 四、列联表分析 用于分析离散变量或定型变量之间是否存在相关。 对于二维表,可进行卡方检验,对于三维表,可作Mentel-Hanszel分层分析。列联表分析还包括配对计数资料的卡方检验、行列均为顺序变量的相关检验。 五、相关分析 研究现象之间是否存在某种依存关系,对具体有依存关系的现象探讨相关方向及相关程度。 1、单相关:两个因素之间的相关关系叫单相关,即研究时只涉及一个自变量和一个因变量; 2、复相关:三个或三个以上因素的相关关系叫复相关,即研究时涉及两个或两个以上的自变量和因变量相关; 3、偏相关:在某一现象与多种现象相关的场合,当假定其他变量不变时,其中两个变量之间的相关关系称为偏相关。 六、方差分析
多元统计分析实验报告
1. 实验目的: (1)掌握均值向量及协方差阵的检验方法。 (2)能够用SPSS软件或R软件实现均值及协方差阵的检验,并正确理解输出结果。2. 实验内容 均值向量检验和协方差阵检验 3. 实验步骤 (1)在进行比较分析之前,首先要对数据是否遵从多元正态分布进行检验。对数据进行以下操作“ An alyze-descriptive statistics-explore ”。 图一
J? Explore Difipla/ * 印th f _ Sitfistins,2[ptx J >1 >■............ . I j [ OK | Pesls Resat canwi ] | Map 图二 单击plots,选择正态分布检验,单击continue , ok得出结果 图三 (2 )多元正态分布有关均值与方差的检验,单击“ An alyze-ge neral model- multivariate ” 得到下图。 linear uptions... F悴
■0 图4 Options 打开,将省份导入 display means for 中,如图5, continue 继续,ok 运行。 ? 軒'4 r " Descriptw *51 at stilus la^es ? dfcz/bys .X ;qf :drrj Conwarc 氐味n 卜 JA n = nn Gen*i ,sl Linear Model 關 Lhwurt... GcnerdttLE j Un? Mocdi * I J M . Jirr MLrtrrarttr... Mi^gql M QC !曲 dl aoiral* /artancB ConpDTiBinds. … Rcgie-isur' 卜1 7420? n- 311200 Lcghne-i" 卜 ^34A7.nn B025JOD Mieurrt 対yr ■啟 ? Clmiify * 40580100 7£12JOO Data Keducunn 6666.00 3-Jl<00 Scab ? ^4458 m 2^0 00 Huiipur ?rn^liiu Tn 士 325P0O IDC01 00 M 怕 SM1M ? 6679.0Q E7E5.00 SuiMval 103B7.0D 4792J0D M&=?re g* 出-曰普us.. 181B4.00 4C60JO0 Mijfcile Response ? 6737 □□ 33^0 OQ Comcto=c SMpee 11735100 20QJW ijuatry control 971R00 M J OU □ POCCiM^F.. 16977.00 K^SJOO 100617 28 00 26J 12.00 32J3JQ0 q>
多元统计分析实验报告判别分析
页眉 2015——2016学年第一学期 实验报告 课程名称:多元统计分析 实验项目:判别分析 设计性□验证性□实验类别:综合性□√专业班级:
姓名:学号: 实验地点:统计与金融创新实验室(新60801) 实验时间: 指导教师:曹老师成绩: 数学与统计学院实验中心制页脚 一、实验目的统计《spss 让学生掌握判别分析的基本步骤和分析方法;学习 的内容,掌握一般判别分析与逐分析从入门到精通》P307-P320步判别分析方法。 二、实验内容,掌》应用《胃病患者的测量数据》和《表征企业类型的数据.sav、1统计分析从spss握一般判别分析与逐步判别分析方法。数据来源于《章的数据。入门到精通数据文件》第12的数据进行分析,数据见文件《何晓群多元统计2、参考教材例4-2 》中的例4-2new。)分析(数据三、实验方案(程序设计说明) 四、程序运行结果1. (1) 分析案例处理摘要未加权案例N 百分比 93.3 14 有效 6.7 缺失或越界组代码1 .0 至少一个缺失判别变量0 .0
排除的缺失或越界组代码还有至少0 一个缺失判别变量6.7 合计1 100.0 15 合计 组统计量 1 N(列表状态)类别均值标准差有效的未加权的已加权的5.000 188.60 57.138 5 铜蓝蛋白5.000 16.502 5 150.40 蓝色反应胃癌患者5.000 5.933 5 尿吲哚乙酸13.80 5.000 13.323 5 中性琉化物20.00 4.000 47.500 4 铜蓝蛋白156.25 4.000 118.75 14.104 4 蓝色反应萎缩性胃炎4.000 1.732 4 尿吲哚乙酸7.50 4.000 8.386 4 中性琉化物14.50 5.000 33.801 5 铜蓝蛋白151.00 5.000 13.012 5 蓝色反应121.40 其他胃病5.000 1.871 5 尿吲哚乙酸5.00 5.000 5 中性琉化物8.00 7.314 14.000 14 铜蓝蛋白165.93 46.787 14.000 14 蓝色反应131.00 20.203 合计14.000 14 8.86 5.318 尿吲哚乙酸14.000 10.726 14
多元统计分析实验报告1
多元统计分析 实验报告一 学生姓名刘琪 学号20111315008 院系数学与统计学院 专业统计学 课程名称多元统计分析 任课教师来鹏 二0一三年十一月五日 1、测量15名两周岁婴儿的身高胸围上半臂围的数据如下表所示, 假定这三组都服从正态总体且协方差相等,试在显著性水平
α=0.05下检验男女婴幼儿的这三项指标是否有差异。 某地区农村两周岁婴儿的体格测量数据性别身高X1胸围X2上半臂围X3男7860.616.5 男7658.112.5 男9263.214.5 男8159.016.0 男8160.814.0 男8459.515.0 女8058.414.0 女7559.213.0 女7860.314.0 女7557.412.0 女7959.512.5 女7858.114.0 女7558.012.5 女6455.511.0 女8059.212.5 data shuju4; input sex $ shenggao xiongwei biwei; cards; m 78 60.6 16.5 m 76 58.1 12.5 m 92 63.2 14.5 m 81 59.0 16.0 m 81 60.8 14.0 m 84 59.5 15.0 f 80 58.4 14.0 f 75 59.2 13.0 f 78 60.3 14.0
f 75 57.4 12.0 f 79 59.5 12.5 f 78 58.1 14.0 f 75 58.0 12.5 f 64 55.5 11.0 f 80 59.2 12.5 ; proc glm; class sex; model shenggao xiongwei biwei=sex/ss3; run; 二、1992年美国总统选举的三位候选人为布什、佩罗特和克林顿。从支持三位候选人的选民中分别抽取了20人,登记他们的年龄段(X1)和受教育程度(X2)资料如下表所示: 布什X1X2佩罗X1X2克林X1X2