ieee标准的32位浮点数转换为十进制的计算方法

IEEE标准的32位浮点数转换为十进制的计算方法
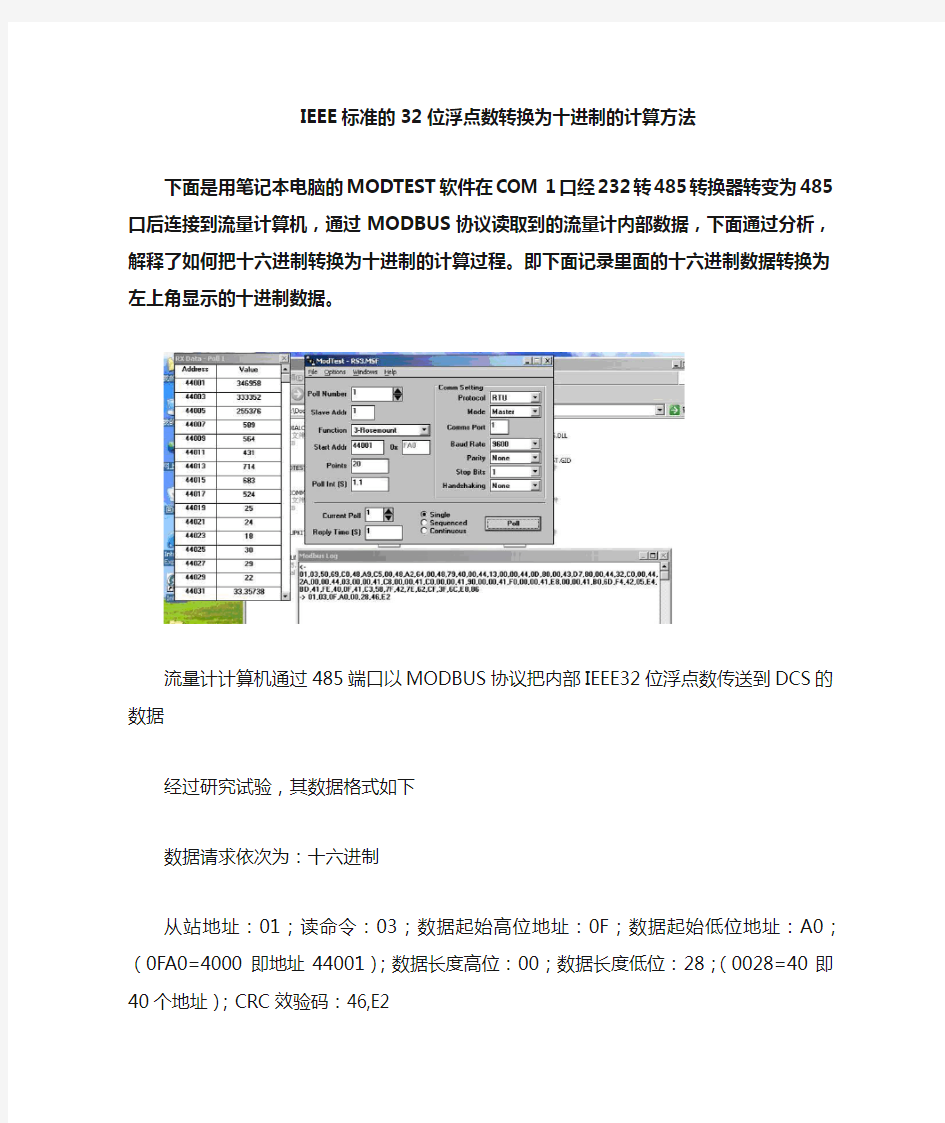
下面是用笔记本电脑的MODTEST软件在COM 1口经232转485转换器转变为485口后连接到流量计算机,通过MODBUS协议读取到的流量计内部数据,下面通过分析,解释了如何把十六进制转换为十进制的计算过程。即下面记录里面的十六进制数据转换为左上角显示的十进制数据。
流量计计算机通过485端口以MODBUS协议把内部IEEE32位浮点数传送到DCS的数据经过研究试验,其数据格式如下
数据请求依次为:十六进制
从站地址:01;读命令:03;数据起始高位地址:0F;数据起始低位地址:A0;(0FA0=4000即地址44001);数据长度高位:00;数据长度低位:28;(0028=40即40个地址);CRC效验码:46,E2
数据应答格式:
从站地址:01;读命令反馈:03;数据长度:50;第一个地址:69;C0;48;A9;第二个地址:C5;00;48;A2;以下类推,直到最后两位CRC:E8;86
第一个地址:69;C0;48;A9是如何换算为346958的呢?
流量计发送的是IEEE标准的32位浮点数
首先要把69;C0;48;A9进行高低16位交换变成:48;A9;69;C0
变为32位二进制数:01001000 10101001 01101001 11000000
其中最高位为0,代表是正数
接下来的八位:10010001变成十进制是145,根据IEEE规范应减去127得18,这是小数点右移的位数;
剩下的23位是纯二进制小数即:0.0101001 01101001 11000000 加1后得1.0101001 01101001 11000000
小数点右移18位后得10101001 01101001 110.00000
变为十进制得346958
其它地址的32位浮点数计算方法同上
浮点数存储
浮点数存储.txt世上最珍贵的不是永远得不到或已经得到的,而是你已经得到并且随时都有可能失去的东西!爱情是灯,友情是影子。灯灭时,你会发现周围都是影子。朋友,是在最后可以给你力量的人。浮点数: 浮点型变量在计算机内存中占用4字节(Byte),即32-bit。遵循IEEE-754格式标准。一个浮点数由2部分组成:底数m 和指数e。 ±mantissa × 2exponent (注意,公式中的mantissa 和 exponent使用二进制表示) 底数部分使用2进制数来表示此浮点数的实际值。 指数部分占用8-bit的二进制数,可表示数值范围为0-255。 指数应可正可负,所以IEEE规定,此处算出的次方须减去127才是真正的指数。所以float 的指数可从 -126到128 底数部分实际是占用24-bit的一个值,由于其最高位始终为 1 ,所以最高位省去不存储,在存储中只有23-bit。 到目前为止,底数部分 23位加上指数部分 8位使用了31位。那么前面说过,float是占用4个字节即32-bit,那么还有一位是干嘛用的呢?还有一位,其实就是4字节中的最高位,用来指示浮点数的正负,当最高位是1时,为负数,最高位是0时,为正数。 浮点数据就是按下表的格式存储在4个字节中: Address+0 Address+1 Address+2 Address+3 Contents SEEE EEEE EMMM MMMM MMMM MMMM MMMM MMMM S: 表示浮点数正负,1为负数,0为正数 E: 指数加上127后的值的二进制数 M: 24-bit的底数(只存储23-bit) 注意:这里有个特例,浮点数为0时,指数和底数都为0,但此前的公式不成立。因为2的0次方为1,所以,0是个特例。当然,这个特例也不用认为去干扰,编译器会自动去识别。 举例1:计算机存储中的二进制数如何转换成实际浮点数 通过上面的格式,我们下面举例看下-12.5在计算机中存储的具体数据: Address+0 Address+1 Address+2 Address+3 Contents 0xC1 0x48 0x00 0x00 接下来我们验证下上面的数据表示的到底是不是-12.5,从而也看下它的转换过程。 由于浮点数不是以直接格式存储,他有几部分组成,所以要转换浮点数,首先要把各部分的值分离出来。 Address+0 Address+1 Address+2 Address+3 格式 SEEEEEEE EMMMMMMM MMMMMMMM MMMMMMMM
单精度浮点数的转换和解析
1 单精度浮点数的转换和解析 工业现场通信经常遇到浮点数解析的问题,如果需要自己模拟数据而又不懂浮点数解析的话会很麻烦!很久以前根据modbus 报文格式分析得到的,供大家参考。 浮点数保存的字节格式如下: 地址 +0 +1 +2 +3 内容 SEEE EEEE EMMM MMMM MMMM MMMM MMMM MMMM 这里 S 代表符号位,1是负,0是正 E 偏移127的幂,二进制阶码=(EEEEEEEE)-127。 M 24位的尾数保存在23位中,只存储23位,最高位固定为1。此方法用最较少的位数实现了 较高的有效位数,提高了精度。 零是一个特定值,幂是0 尾数也是0。 浮点数-12.5作为一个十六进制数0xC1480000保存在存储区中,这个值如下: 地址 +0 +1 +2 +3 内容0xC1 0x48 0x00 0x00 浮点数和十六进制等效保存值之间的转换相当简单。下面的例子说明上面的值-12.5如何转 换。 浮点保存值不是一个直接的格式,要转换为一个浮点数,位必须按上面的浮点数保存格式表 所列的那样分开,例如: 地址 +0 +1 +2 +3 格式 SEEE EEEE EMMM MMMM MMMM MMMM MMMM MMMM 二进制 11000001 01001000 00000000 00000000 十六进制 C1 48 00 00 从这个例子可以得到下面的信息: 符号位是1 表示一个负数 幂是二进制10000010或十进制130,130减去127是3,就是实际的幂。 尾数是后面的二进制数10010000000000000000000
浮点数规格化和教案
第一节 X=(-1)S×(1.M)×2E-127e=E-127 X=(-1)S×(1.M)×2E-1023 e=E-1023 我承认以前对这俩公式避之不及不予深究努力自己说服自己而未能得逞,部分原因是跟“移码与真值的关系”扯上关系,这“移码与真值的关系”想搞清先得把引入移码的充分理由给我个说法,不幸玩过头正事误了。上回说了“补码省心移码悦目”能算是今时不同往日了吧,现在轮到对IEEE754浮点数规格化表示法杀无赦去死吧。 首先,“IEEE规格化形式”是对“传统规格化形式”进一步严格要求来的。 IEEE规格化形式唯一,而浮点数记法多种多样。 (1.75)10=1.11×20 (IEEE规格化表示)=0.111×21 (传统规格化表示) =0.0111×22=0.00111×23 其次,既然IEEE想到对“传统规格化形式”进一步修订当然有目的,你以为作无用功呐,关键目的是什么? 规格化的目的同理。修改阶码同时左右移小数点使尾数域最高有效位固定为1,尾数就以ta所可能变化成的最大形式出现,即使遭遇类似截断的操作仍可保持尽可能高的精度。 有类错误我这种大秀逗极善于犯!就是不理会左右关系不经过大脑直接作问题少女状问很白的问题:“‘移码和真值的关系’是E=27(或210)+X,那X=E-27(或210),在怎么着里面数该是128(或1024),咋是127(或1023)?” 当E=M=全0 E(移码)=全0,对应真值-128 M(补码)=全0,对应真值0 E=M=全0,真值X=0-128=0 结合符号位S 为0或1分正零和负零 当E=全1,M=全0 E(移码)=全1,对应真值+127 M(补码)=全0,对应真值0 E=全1,M=全0,真值X=0127=∞ 结合符号位S 为0或1分+∞和-∞ 要除去表示零和无穷大这2种特殊情况 指数偏移值不选128(10000000),而选127(01111111) 对IEEE32位规格化浮点数 8位移码(隐含1位符号位)原本表示范围是-128 →+127 (除去全1(+127)全0(-128)剩下-127 →+126 ???) 实际可用指数值(即阶码真值)e范围是-126→+127 加上偏移值后,阶码E的范围变为1→254 以10的幂表示,绝对值的范围是10-38→1038 假设由S,E,M三个域组成的一个32位二进制字所表示的非零规格化浮点数x,真值表示为:x=(-1)s×(1.M)×2E-128 它所表示的规格化的最大正数、最小正数、最大负数、最小负数是多少? 第二节 1、什么是IEEE754标准 用来规范化浮点数,其格式是
32位浮点数与十进制转化
1 32位IEE754浮点格式 对于大小为32-bit的浮点数(32-bit为单精度,64-bit浮点数为双精度,80-bit为扩展精度浮点数), 1、其第31 bit为符号位,为0则表示正数,反之为复数,其读数值用s表示; 2、第30~23 bit为幂数,其读数值用e表示; 3、第22~0 bit共23 bit作为系数,视为二进制纯小数,假定该小数的十进制值为x; 十进制转浮点数的计算方法: 则按照规定,十进制的值用浮点数表示为:如果十进制为正,则s = 0,否则s = 1; 将十进制数表示成二进制,然后将小数点向左移动,直到这个数变为1.x的形式即尾数,移动的个数即为指数。为了保证指数为正,将移动的个数都加上127,由于尾数的整数位始终为1,故舍去不做记忆。对3.141592654来说, 1、正数,s = 0; 2、3.141592654的二进制形式为正数部分计算方法是除以二取整,即得11,小数部分的计算方法是乘以二取其整数,得0.0010 0100 0011 1111 0110 1010 1000,那么它的二进制数表示为11.0010 0100 0011 1111 0110 1010 1; 3、将小数点向左移一位,那么它就变为1.1001 0010 0001 1111 1011 0101 01,所以指数为1+127=128,e = 128 = 1000 0000; 4、舍掉尾数的整数部分1,尾数写成0.1001 0010 0001 1111 1011 0101 01,x = 921FB6 5、最后它的浮点是表示为0 1000 0000 1001 0010 0001 1111 1011 0101 = 40490FDA //-------------------------------------------- // 十进制转换为32位IEE754浮点格式 //-------------------------------------------- void ConvertDexToIEE754(float fpointer,ModRegisterTpyedef *SpModRegister) { double integer,decimal; unsigned long bininteger,bindecimal; Uint8 _power,i; decimal = modf(fpointer,&integer); if(decimal || integer) { bindecimal = decimal * 0x800000; //2^23 while((bindecimal & 0xff800000) > 0) bindecimal >>= 1; if(integer > 0) { bininteger = integer; for(i=0;i<32;i++) //计算整数部分的2的幂指数 { if(bininteger&0x1) _power = i; bininteger >>= 0x1; } bininteger = integer; bininteger &= ~(0x1 << _power); //去掉最高位的1 if(_power >= 23) //如果幂指数>23 则舍弃小数位部分 { bininteger >>= (_power-23); bindecimal = 127+_power; bininteger |= bindecimal << 23; } else { bininteger <<= (23 - _power); bindecimal >>= _power; bininteger |= bi ndecimal; bindecimal = 127+_power; bininteger |= bindecimal << 23; } } else if(integer == 0) { bindecimal <<= 9; _power = 0; bininteger = bindecimal; while(bininteger == ((bindecimal<<1)>>1)) { _power++; bindecimal <<= 0x1; bininteger = bindecimal; }
2.浮点数的存储原理
问题:long和float类型都是四个字节,为什么存储数值的范围相差极大? 原因:因为两者的存储原理时不同的。 浮点数的存储原理 作者: jillzhang 联系方式:jillzhang@https://www.wendangku.net/doc/d42964069.html, 本文为原创,转载请保留出处以及作者,谢谢 C语言和C#语言中,对于浮点类型的数据采用单精度类型(float)和双精度类型(double)来存储,float数据占用32bit,double数据占用64bit,我们在声明一个变量float f= 2.25f的时候,是如何分配内存的呢?如果胡乱分配,那世界岂不是乱套了么,其实不论是float还是double在存储方式上都是遵从IEEE的规范的,float遵从的是IEEE R32.24 ,而double 遵从的是R64.53。 无论是单精度还是双精度在存储中都分为三个部分: 1.符号位(Sign) : 0代表正,1代表为负 2.指数位(Exponent):用于存储科学计数法中的指数数据,并且采用移位存储 3.尾数部分(Mantissa):尾数部分 其中float的存储方式如下图所示: 而双精度的存储方式为:
R32.24和R64.53的存储方式都是用科学计数法来存储数据的,比如8.25用十进制的科学计数法表示就为:8.25*,而120.5可以表示为:1.205*,这些小学的知识就不用多说了吧。而我们傻蛋计算机根本不认识十进制的数据,他只认识0,1,所以在计算机存储中,首先要将上面的数更改为二进制的科学计数法表示,8.25用二进制表示可表示为1000.01,我靠,不会连这都不会转换吧?那我估计要没辙了。120.5用二进制表示为:1110110.1用二进制的科学计数法表示1000.01可以表示为1.0001* ,1110110.1可以表示为1.1101101*,任何一个数都的科学计数法表示都为1.xxx*,尾数部分就可以表示为xxxx,第一位都是1嘛,干嘛还要表示呀?可以将小数点前面的1省略,所以23bit的尾数部分,可以表示的精度却变成了24bit,道理就是在这里,那24bit能精确到小数点后几位呢,我们知道9的二进制表示为1001,所以4bit能精确十进制中的1位小数点,24bit就能使float能精确到小数点后6位,而对于指数部分,因为指数可正可负,8位的指数位能表示的指数范围就应该为:-127-128了,所以指数部分的存储采用移位存储,存储的数据为元数据+127,下面就看看8.25和120.5在内存中真正的存储方式。 首先看下8.25,用二进制的科学计数法表示为:1.0001* 按照上面的存储方式,符号位为:0,表示为正,指数位为:3+127=130 ,位数部分为,故8.25的存储方式如下图所示: 而单精度浮点数120.5的存储方式如下图所示:
32位浮点数转换为十进制
流量计计算机通过485端口以MODBUS协议把内部IEEE32位浮点数传送到DCS的数据经过研究试验,其数据格式如下 数据请求依次为:十六进制 从站地址:01;读命令:03;数据起始高位地址:0F;数据起始低位地址:A0;(0FA0=4000即地址44001);数据长度高位:00;数据长度低位:28;(0028=40即40个地址);CRC效验码:46,E2 数据应答格式: 从站地址:01;读命令反馈:03;数据长度:50;第一个地址:69;C0;48;A9;第二个地址:C5;00;48;A2;以下类推,直到最后两位CRC:E8;86 第一个地址:69;C0;48;A9是如何换算为346958的呢? 流量计发送的是IEEE标准的32位浮点数 首先要把69;C0;48;A9进行高低16位交换变成:48;A9;69;C0 变为32位二进制数:01001000 10101001 01101001 11000000 其中最高位为0,代表是正数 接下来的八位:10010001变成十进制是145,根据IEEE规范应减去127得18,这是小数点右移的位数; 剩下的23位是纯二进制小数即:0.0101001 01101001 11000000 加1后得1.0101001 01101001 11000000 小数点右移18位后得10101001 01101001 110.00000 变为十进制得346958 其它地址的32位浮点数计算方法同上 标题:《IEEE754 学习总结》 发信人:Vegeta 时间:2004-11-11,10:32 详细信息: 一:前言 二:预备知识 三:将浮点格式转换成十进制数 四:将十进制数转换成浮点格式(real*4) 附:IEEE754 Converte 1.0介绍 一:前言
有关浮点数在内存中的存储
有关浮点数在内存中的存储 最近想看一下C中float和double型数据在内存中是如何表示的,找到了如下一些东东,与大家分享一下 c语言中FLOAT 是如何表示的?尾数,阶码是如何在32位上安排的,即哪几位是尾数,哪几位是阶码,那一位是符号位。听说与CPU有关,是真的吗? 在C++里,实数(float)是用四个字节即三十二位二进制位来存储的。其中有1位符号位,8位指数位和23位有效数字位。实际上有效数字位是24位,因为第一位有效数字总是“1”,不必存储。 有效数字位是一个二进制纯小数。8位指数位中第一位是符号位,这符号位和一般的符号位不同,它用“1”代表正,用”0“代表负。整个实数的符号位用“1”代表负,“0”代表正。 在这存储实数的四个字节中,将最高地址字节的最高位编号为31,最低地址字节的最低位编号为0,则实数各个部分在这32个二进制位中的分布是这样的:31位是实数符号位,30位是指数符号位,29---23是指数位,22---0位是有效数字位。注意第一位有效数字是不出现在内存中的,它总是“1”。 将一个实数转化为C++实数存储格式的步骤为: (1)先将这个实数的绝对值化为二进制格式,注意实数的整数部分和小数部分化为二进制的方法是不同的。 (2)将这个二进制格式实数的小数点左移或右移n位,直到小数点移动到第一个有效数字的右边。 (3)从小数点右边第一位开始数出二十三位数字放入第22到第0位。 (4)如果实数是正的,则在第31位放入“0”,否则放入“1”。 (5)如果n 是左移得到的,说明指数是正的,第30位放入“1”。如果n是右移得到的或n=0,则第30位放入“0”。 (6)如果n是左移得到的,则将n减去一然后化为二进制,并在左边加“0”补足七位,放入第29到第23位。如果n是右移得到的或n=0,则将n化为二进制后在左边加“0”补足七位,再各位求反,再放入第29到第23位。 将一个计算机里存储的实数格式转化为通常的十进制的格式的方法如下: (1)将第22位到第0位的二进制数写出来,在最左边补一位“1”,得到二十四位有效数字。将小数点点在最左边那个“1”的右边。 (2)取出第29到第23位所表示的值n。当30位是“0”时将n各位求反。当30位是“1”时将n增1。 (3)将小数点左移n位(当30位是“0”时)或右移n位(当30位是“1”时),得到一个二进制表示的实数。 (4)将这个二进制实数化为十进制,并根据第31位是“0”还是“1”加上正号或负号即可。
浮点数的表示和基本运算
浮点数的表示和基本运算 1 浮点数的表示 通常,我们可以用下面的格式来表示浮点数 S P M 其中S是符号位,P是阶码,M是尾数 对于IBM-PC而言,单精度浮点数是32位(即4字节)的,双精度浮点数是64位(即8字节)的。两者的S,P,M所占的位数以及表示方法由下表可知 S P M表示公式偏移量 1823(-1)S*2(P-127)*1.M127 11152(-1)S*2(P-1023)*1.M1023 以单精度浮点数为例,可以得到其二进制的表示格式如下 S(第31位)P(30位到 23位) M(22位到 0位) 其中S是符号位,只有0和1,分别表示正负;P是阶码,通常使用移码表示(移码和补码只有符号位相反,其余都一样。对于正数而言,原码,反码和补码都一样;对于负数而言,补码就是其绝对值的原码全部取反,然后加1.) 为了简单起见,本文都只讨论单精度浮点数,双精度浮点数也是用一样的方式存储和表示的。 2 浮点数的表示约定 单精度浮点数和双精度浮点数都是用IEEE754标准定义的,其中有一些特殊约定。 (1) 当P = 0, M = 0时,表示0。 (2) 当P = 255, M = 0时,表示无穷大,用符号位来确定是正无穷大还是负无穷大。
(3) 当P = 255, M != 0时,表示NaN(Not a Number,不是一个数)。 当我们使用.Net Framework的时候,我们通常会用到下面三个常量 Console.WriteLine(float.MaxValue); // 3.402823E+38 Console.WriteLine(float.MinValue); //-3.402823E+38 Console.WriteLine(float.Epsilon); // 1.401298E-45 //如果我们把它们转换成双精度类型,它们的值如下 Console.WriteLine(Convert.ToDouble(float.MaxValue)); // 3.40282346638529E+38 Console.WriteLine(Convert.ToDouble(float.MinValue)); //-3.40282346638529E+38 Console.WriteLine(Convert.ToDouble(float.Epsilon)); // 1.40129846432482E-45 那么这些值是如何求出来的呢? 根据上面的约定,我们可以知道阶码P的最大值是11111110(这个值是254,因为255用于特殊的约定,那么对于可以精确表示的数来说,254就是最大的阶码了)。尾数的最大值是11111111111111111111111。 那么这个最大值就是:0 11111110 11111111111111111111111。 也就是 2(254-127) * (1.11111111111111111111111)2 = 2127 * (1+1-2-23) = 3.40282346638529E+38 从上面的双精度表示可以看出,两者是一致的。最小的数自然就是- 3.40282346638529E+38。 对于最接近于0的数,根据IEEE754的约定,为了扩大对0值附近数据的表示能力,取阶码P = -126,尾数 M = (0.00000000000000000000001)2 。此时该数的二进制表示为:0 00000000 00000000000000000000001 也就是2-126 * 2-23 = 2-149 = 1.40129846432482E-45。这个数字和上面的Epsilon 是一致的。 如果我们要精确表示最接近于0的数字,它应该是 0 00000001 00000000000000000000000 也就是:2-126 * (1+0) = 1.17549435082229E-38。 3 浮点数的精度问题 浮点数以有限的32bit长度来反映无限的实数集合,因此大多数情况下都是一个近似值。同时,对于浮点数的运算还同时伴有误差扩散现象。特定精度下看似
浮点转定点方法总结
浮点转定点方法总结 —孔德琦
目录 定点运算方法................................................ 错误!未定义书签。 数的定标 ............................................... 错误!未定义书签。 C语言:从浮点到定点 ................................. 错误!未定义书签。 加法.................................................... 错误!未定义书签。 乘法..................................................... 错误!未定义书签。 除法..................................................... 错误!未定义书签。 三角函数运算............................................ 错误!未定义书签。 开方运算................................................ 错误!未定义书签。 附录...................................................... 错误!未定义书签。 附录1:定点函数库...................................... 错误!未定义书签。 附录2:正弦和余弦表..................................... 错误!未定义书签。
浮点数在内存中的存储方式
浮点数在内存中的存储方式 任何数据在内存中都是以二进制的形式存储的,例如一个short型数据1156,其二进制表示形式为00000100 10000100。则在Intel CPU架构的系统中,存放方式 为10000100(低地址单元) 00000100(高地址单元),因为Intel CPU的架构是小端模式。但是对于浮点数在内存是如何存储的?目前所有的C/C++编译器都是采用IEEE所制定的标准浮点格式,即二进制科学表示法。 在二进制科学表示法中,S=M*2^N 主要由三部分构成:符号位+阶码(N)+尾数(M)。对于float型数据,其二进制有32位,其中符号位1位,阶码8位,尾数23位;对于double型数据,其二进制为64位,符号位1位,阶码11位,尾数52位。 31 30-23 22-0 float 符号位阶码尾数 63 62-52 51-0 double 符号位阶码尾数 符号位:0表示正,1表示负 阶码:这里阶码采用移码表示,对于float型数据其规定偏置量为127,阶码有正有负,对于8位二进制,则其表示范围为-128-127,double型规定为1023,其表示范围为 -1024-1023。比如对于float型数据,若阶码的真实值为2,则加上127后为129,其阶码表示形式为10000010 尾数:有效数字位,即部分二进制位(小数点后面的二进制位),因为规定M的整数部分恒为1,所以这个1就不进行存储了。
下面举例说明: float型数据125.5转换为标准浮点格式 125二进制表示形式为1111101,小数部分表示为二进制为1,则125.5二进制表示为1111101.1,由于规定尾数的整数部分恒为1,则表示为1.1111011*2^6,阶码为6,加上127为133,则表示为10000101,而对于尾数将整数部分1去掉,为1111011,在其后面补0使其位数达到23位,则为11110110000000000000000 则其二进制表示形式为 0 10000101 11110110000000000000000,则在内存中存放方式为: 00000000 低地址 00000000 11111011 01000010 高地址 而反过来若要根据二进制形式求算浮点数如0 10000101 11110110000000000000000 由于符号为为0,则为正数。阶码为133-127=6,尾数为11110110000000000000000,则其真实尾数为1.1111011。所以其大小为 1.1111011*2^6,将小数点右移6位,得到1111101.1,而1111101的十进制为125,0.1的十进制为1*2^(-1)=0.5,所以其大小为125.5。 同理若将float型数据0.5转换为二进制形式
单双精度浮点数的IEEE标准格式
单双精度浮点数的IEEE标准格式 目前大多数高级语言(包括C)都按照IEEE-754标准来规定浮点数的存储格式,IEEE754规定,单精度浮点数用4字节存储,双精度浮点数用 8字节存储,分为三个部分:符号位、阶和尾数。阶即指数,尾数即有效小数位数。单精度格式阶占8位,尾数占24位,符号位1位,双精度则为11为阶,53 位尾数和1位符号位,如下图所示: 31 30 23 22 0 63 62 52 51 0 细心的人会发现,单双精度各部分所占字节数量比实际存储格式都了一位,的确是这样,事实是,尾数部分包括了一位隐藏位,允许只存储23位就可以表示24位尾数,默认的1位是规格化浮点数的第一位,当规格化一个浮点数时,总是调整它使其值大于等于1而小于2,亦即个位总是为1。例如1100B,对其规格化的结果为1.1乘以2的三次方,但个位1并不存储在23位尾数部分内,这个1是默认位。 阶以移码的形式存储。对于单精度浮点数,偏移量为127(7FH),而双精度的偏移量为1023(3FFH)。存储浮点数的阶码之前,偏移量要先加到阶码上。前面例子中,阶为2的三次方,在单精度浮点数中,移码后的结果为127+3即130(82H),双精度为1026(402H)。 浮点数有两个例外。数0.0存储为全零。无限大数的阶码存储为全1,尾数部分全零。符号位指示正无穷或者负无穷。 下面举几个例子:
所有字节在内存中的排列顺序,intel的cpu按little endian顺序,motorola 的cpu按big endian顺序排列。
IEEE754标准的一个规格化 32位浮点数x的真值可表示为 x=(-1)^S*(1.M)*2^(E-127)e=E-127 31 30 23 0 |S | E |M | [例1]若浮点数x的754标准存储格式为(41360000)16,求其浮点数的十进制数值。 解:将16进制展开后,可得二进制数格式为 0 100,0001,0 011,0110,0000,0000,0000,0000 S E M 指数e=100,0001,0-01111111=00000011=(3)10 包含隐藏位1的尾数1.M=1.011,0110,0000,0000,0000,0000 于是有x=(-1)^0*(1.M)*2^(E-127) =+(1.011011)2*2^3 =(11.375)10 [例2]将数(20.59375)10转化为754标准的32位浮点数的二进制存储格式。解:首先分别将整数部分和小数部分转换成二进制 (20.59375)10=+(10100.10011)2 然后移动小数点使其在1,2位之间 10100.10011=1.010010011*2^4 e=4 于是得到:S=0,E=e+127=131,M=010010011 最后得到32位浮点数的二进制存储格式为 0 100,0001,1 010,0100,1100,0000,0000,0000 =(41A4C000)16 从存储结构和算法上来讲,double和float是一样的,不一样的地方仅仅是float是32位的,double是64位的,所以double能存储更高的精度。 任何数据在内存中都是以二进制(0或1)顺序存储的,每一个1或0被称为1位,而在 x86CPU上一个字节是8位。比如一个16位(2字节)的 short int型变量的值是1000,那么它的二进制表达就是:00000011 11101000。由于Intel CPU的架构原因,它是按字节倒序存储的,那么就因该是这样:11101000 00000011,这就是定点数1000在内存中的结构。 目前C/C++编译器标准都遵照IEEE制定的浮点数表示法来进行float,double运算。这种结构是一种科学计数法,用符号、指数和尾数来表示,底数定为2——即把一个浮点数表示为尾数乘以2的指数次方再添上符号。下面是具体的规格: ````````符号位阶码尾数长度 float 1 8 23 32 double 1 11 52 64
浮点数在计算机内存中的存储格式
浮点数在计算机内存中的存储格式 对于浮点类型的数据采用单精度类型(float)和双精度类型(double)来存储,float数据占用 32bit,double数据占用 64bit,我们在声明一个变量float f = 2.25f的时候,是如何分配内存的呢?其实不论是float类型还是double类型,在计算机内存中的存储方式都是遵从IEEE的规范的,float 遵从的是IEEE R32.24 ,而double 遵从的是R64.53。 无论是单精度还是双精度,在内存存储中都分为3个部分: 1) 符号位(Sign):0代表正,1代表为负; 2) 指数位(Exponent):用于存储科学计数法中的指数数据,并且采用移位存储; 3) 尾数部分(Mantissa):尾数部分; 其中float的存储方式如下图所示: 而双精度的存储方式为: R32.24和R64.53的存储方式都是用科学计数法来存储数据的,比如8.25用十 进制的科学计数法表示就为:8.25*,而120.5可以表示为:1.205*。而我 们傻蛋计算机根本不认识十进制的数据,它只认识0和1,所以在计算机内存中,首先要将上面的数更改为二进制的科学计数法表示,8.25用二进制表示可表示为1000.01,120.5用二进制表示为:1110110.1。用二进制的科学计数法 表示1000.01可以表示为1.00001*,1110110.1可以表示为 1.1101101*,任何一个数的科学计数法表示都为 1.xxx*, 尾数部分就可以表示为xxxx,第一
位都是1嘛,干嘛还要表示呀?可以将小数点前面的1省略,所以23bit的尾数部分,可以表示的精度却变成了 24bit,道理就是在这里,那24bit能精确到小数点后几位呢,我们知道9的二进制表示为1001,所以4bit能精确十进制中的1位小数点,24bit就能使float能精确到小数点后6位,而对于指数部分,因为指数可正可负,8位的指数位能表示的指数范围就应该为:-127-128了,所以指数部分的存储采用移位存储,存储的数据为元数据+127。 下面就看看8.25和120.5在内存中真正的存储方式: 首先看下8.25,用二进制的科学计数法表示为:1.0001* 按照上面的存储方式,符号位为0,表示为正;指数位为3+127=130,位数部分为 1.00001,故8.25的存储方式如下: 0xbffff380: 01000001000001000000000000000000 分解如下:0--10000010--00001000000000000000000 符号位为0,指数部分为10000010,位数部分为 00001000000000000000000 同理,120.5在内存中的存储格式如下: 0xbffff384: 01000010111100010000000000000000 分解如下:0--10000101--11100010000000000000000 那么如果给出内存中一段数据,并且告诉你是单精度存储的话,你如何知道该数据的十进制数值呢?其实就是对上面的反推过程,比如给出如下内存数据: 01000001001000100000000000000000 第一步:符号位为0,表示是正数; 第二步:指数位为10000010,换算成十进制为130,所以指数为130-127=3; 第三步:尾数位为01000100000000000000000,换算成十进制为 (1+1/4+1/64); 所以相应的十进制数值为:2^3*(1+1/4+1/64)=8+2+1/8=10.125 再看一个例子,观察其输出: 02 { 03 float f1 = 2.2; 04 float f2 = 2.25;
十进制数和单精度浮点数的相互转换
将十进制数转换成浮点格式(real*4) [例1]: 十进制26.0转换成二进制 11010.0 规格化二进制数 1.10100*2^4 计算指数 4+127=131 符号位指数部分尾数部分 0 10000011 10100000000000000000000 以单精度(real*4)浮点格式存储该数0100 0001 1101 0000 0000 0000 0000 0000 0x41D0 0000 [例2]: 0.75 十进制0.75转换成二进制 0.11 规格化二进制数 1.1*2^-1 计算指数 -1+127=126 符号位指数部分尾数部分 0 01111110 10000000000000000000000 以单精度(real*4)浮点格式存储该数0011 1111 0100 0000 0000 0000 0000 0000 0x3F40 0000 [例3]: -2.5 十进制-2.5转换成二进制 -10.1 规格化二进制数 -1.01*2^1 计算指数 1+127=128 符号位指数部分尾数部分 1 10000000 01000000000000000000000 以单精度(real*4)浮点格式存储该数1100 0000 0010 0000 0000 0000 0000 0000 0xC020 0000
将浮点格式转换成十进制数 [例1]: 0x00280000(real*4) 转换成二进制 00000000001010000000000000000000 符号位指数部分(8位)尾数部分 0 00000000 01010000000000000000000 符号位=0;因指数部分=0,则:尾数部分M为m: 0.01010000000000000000000=0.3125 该浮点数的十进制为: (-1)^0*2^(-126)*0.3125 =3.6734198463196484624023016788195e-39 [例2]: 0xC04E000000000000(real*8) 转换成二进制1100000001001110000000000000000000000000000000000000000000000000 符号位指数部分(11位)尾数部分 1 10000000100 1110000000000000000000000000000000000000000000000000 符号位=1;指数=1028,因指数部分不为全'0'且不为全'1',则:尾数部分M为1+m:1.1110000000000000000000000000000000000000000000000000=1.875 该浮点数的十进制为: (-1)^1*2^(1028-1023)*1.875 =-60
浮点数1
浮点数在计算机中用以近似表示任意某个实数。具体的说,这个实数由一个整数或定点数(即尾数)乘以某个基数(计算机中通常是2)的整数次幂得到,这种表示方法类似于基数为10的科学记数法。 浮点计算是指浮点数参与的运算,这种运算通常伴随着因为无法精确表示而进行的近似或舍入。 一个浮点数a由两个数m和e来表示:a = m × be。在任意一个这样的系统中,我们选择一个基数b(记数系统的基)和精度p(即使用多少位来存储)。m(即尾数)是形如±d.ddd...ddd的p位数(每一位是一个介于0到b-1之间的整数,包括0和b-1)。如果m的第一位是非0整数,m称作规格化的。有一些描述使用一个单独的符号位(s 代表+或者-)来表示正负,这样m必须是正的。e是指数。 这种设计可以在某个固定长度的存储空间内表示定点数无法表示的更大范围的数。 例如,一个指数范围为±4的4位十进制浮点数可以用来表示43210,4.321或0.0004321,但是没有足够的精度来表示432.123和43212.3(必须近似为432.1和43210)。当然,实际使用的位数通常远大于4。 此外,浮点数表示法通常还包括一些特别的数值:+∞和?∞(正负无穷大)以及NaN('Not a Number')。无穷大用于数太大而无法表示的时候,NaN则指示非法操作或者无法定义的结果。 大部份计算机采用二进制(b=2)的表示方法。位(bit)是衡量浮点数所需存储空间的单位,通常为32位或64位,分别被叫作单精度和双精度。有一些计算机提供更大的浮点数,例如英特尔公司的浮点运算单元Intel8087协处理器(以及其被集成进x86处理器中的后代产品)提供80位长的浮点数,用于存储浮点运算的中间结果。还有一些系统提供128位的浮点数 浮点数的表示 在实际应用中,往往会使用实数,例如下面的一些十进制实数: 179.2356=0.1792356x10^3 0.000000001=0.1x10^8 3155760000=0.215576x10^6 很明显,上述第一个数既有整数也有小数,不能用定点数格式化直接表示,后两个数则可能超出了定点数的表示范围,所以计算机引入了类似与科学表示法来标示实数。 (1)典型的浮点数格式 在机器中,典型的浮点数格式如图所示 浮点数代码由两部分组成:阶码E和尾数M。浮点数真值为: N=+/-(R^E)xM R是阶码的底。在机器中一般规定R为2,4,8或16,与尾数的基数相同。例如尾数为二进制,则R也为2。同一种机器的R值是固定不变的,所以不需要在浮点数代码中表示出来,他是隐含约定的。因此,机器中的浮点数只需表示出阶码和尾数部分。 E是阶码,即指数值,为带符号整数,常用移码或补码表示。 M是尾数,通常是纯小数,常用原码或补码表示。
非标准浮点数和标准的浮点数之间的转换
地址:安徽省、合肥市、肥东县、店埠镇,合肥市福来德电子科技有限公司Microchip 公司单片机所采用的浮点数格式是IEEE-754标准的变异型。 1、变异型32位浮点数格式为::阶码E (8位),符号S (1位),尾数M (23位) 变异型32位浮点数的二进制格式为::E7,E6,E5,E4,E4,E3,E2,E1,E0,S ,M22,M21,M20,M19,M18,M17,M16,M15,M14,M13,M12,M11,M10,M9,M8,M7,M6,M5,M4,M3,M2,M1,M0共计32位值。 存储模式 :大端格式,高字节存放在低地址位置。 2、标准型32位浮点数格式为::符号S (1位),阶码E (8位),尾数M (23位) 标准型32位浮点数的二进制格式为::S ,E7,E6,E5,E4,E4,E3,E2,E1,E0,M22,M21,M20,M19,M18,M17,M16,M15,M14,M13,M12,M11,M10,M9,M8,M7,M6,M5,M4,M3,M2,M1,M0共计32位值。 存储模式 :小端格式,高字节存放在高地址位置。 #include<18f6720.h> //#include