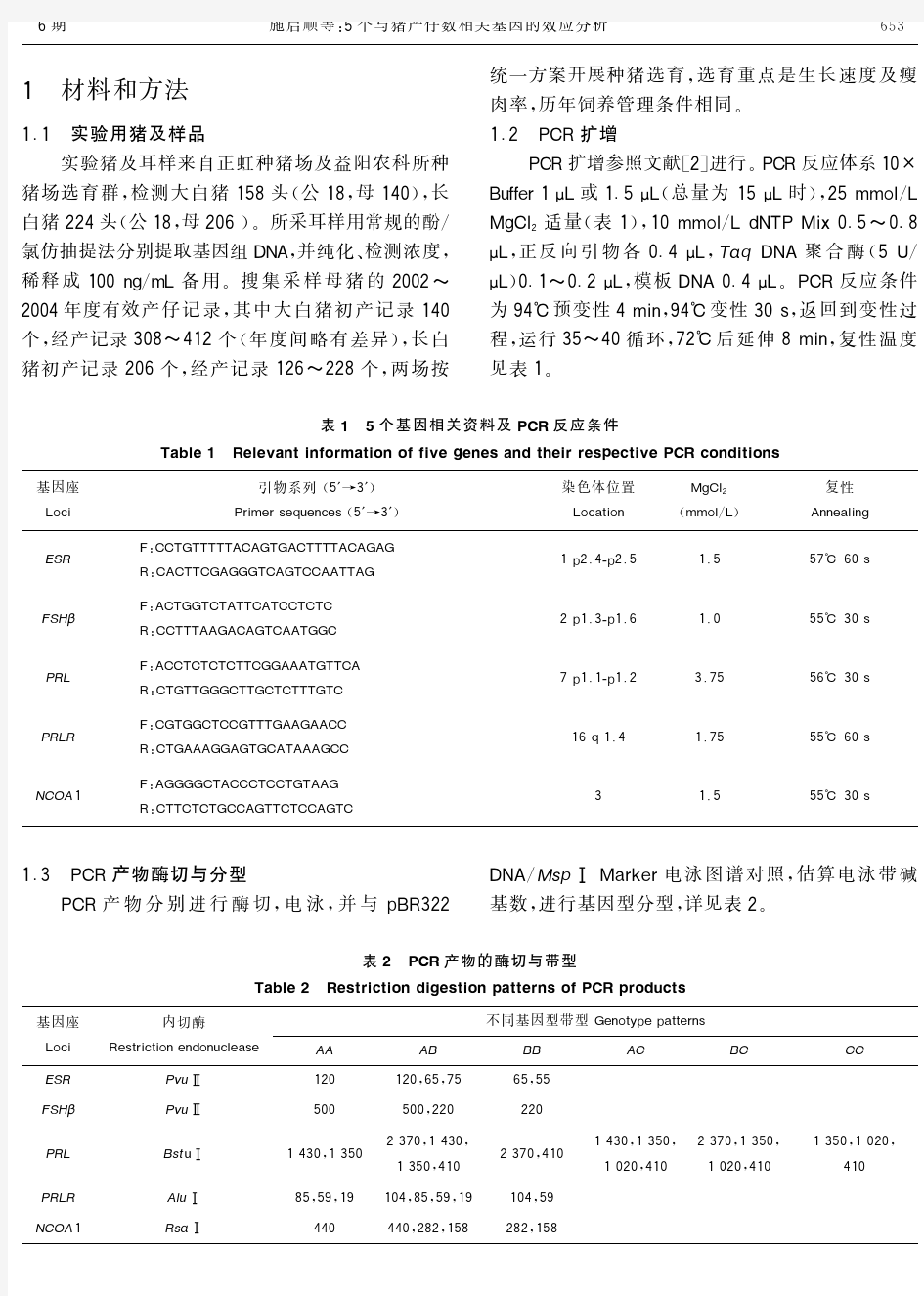
5个与猪产仔数相关基因的效应分析

拷贝数变异及其研究进展
拷贝数变异及其研究进展 摘要:拷贝数变异(Copy number variations, CNVs)主要指1kb-1Mb的DNA片段的缺失、插入、重复等。文章主要介绍了CNVs的基本知识及其机理,着重介绍了其各种检测技术,并进一步阐明CNVs对人类疾病及哺乳动物疾病的影响。此外,对其研究发展进行可行性展望。 关键词:拷贝数变异机理检测技术疾病 2004年,两个独立实验小组几乎同时报道,在人类基因组中广泛存在DNA片段大小从 1 kb到几个Mb范围内的拷贝数变异(CNVs)现象。在2006 年的《Nature》杂志上,来自英国Wellcome Sanger研究所以及美国Affymetrk公司等多国研究人员组成的研究小组公布了第1张人类基因组的第1代CNV图谱,后续又有3篇文章陆续发表在《Nature Genetics》和《Genome Research》杂志上,聚焦这一重大发现。受到检测手段的限制,这类遗传变异直到最近2年才为研究者所重视,并迅速成为当前人类遗传学研究的热点。CNVs 最初在患者的基因组中发现,但后来发现CNVs也大量存在于正常个体的基因组内,主要引起基因(或部分基因)的缺失或增多。拷贝数的变异过程既与疾病相关,也与基因组自身的进化有关。 针对CNVs的发现,美国遗传学家JamesR.Lupski提出“我们不能再将人与人之间的差异想当然地认为仅是单碱基突变的结果,因为还存在更复杂的来自于CNVs的结构性差异”。Lupski认为,CNVs的发现将改变人类对遗传学领域的认知,并将影响19世纪被誉为“遗传学之父”的孟德尔及 1953年发现“DNA双螺旋”的弗兰西斯?克里克与吉姆?沃特森所确立的人类遗传学基准 1 CNV概述 1.1 CNV的概念 基因组变异包括多种形式,包括SNPs,数目可变串联重复位点VNTRs (微卫星等),转座元件 (Alu序列等),结构变异(重复、缺失、插入等)。CNVs指大小从1kb到1Mb 范围内亚微观片段拷贝数突变,这些拷贝片段的缺失、复制、倒置等的变异都统称为CNVs,但不包括由转座子的插人和缺失引起的基因变异(如0-6kb Kpn I重复)[1]。由于多态是用于描述在一定人群中某个等位基因的频率不低于1%,但到目前为止,多数人类的CNVs 频率还未知[2]。目前发现的CNVs 都收录在人类基因组变异数据库中,CNVs平均大小为118 kb。全世界范围内的CNVs研究目标是:建立人类基因组的CNVs地图集,以及建立CNVs与表型、CNVs与SNPs等方面的关系。 1.2 CNV产生机理 美国学者Redon等认为,CNV可以被认为是简单的DNA结构变化(如单一片段的扩增、缺失、插入),或者可能是复杂的染色体扩增、缺失和插入的各种组合形式。在人类基因组的研究中发现,CNV在基因组中的分布似乎是有一定规律的,它常发生在同源重复序列或DNA重复片段之内或之间的区域,且CNV和基因组的DNA重复序列(SD)呈极显著正相关。由此,学者们认为,CNV的发生或者说绝大多数CNV的发生是非等位基因同源重组(NAHR)的结果[3]。
世代平均数的遗传分析1加性-显性模型的基因效应估计
世代平均数的遗传分析 Ⅰ.加性-显性模型的基因效应估计 莫惠栋 A Genetic Analysis of Generation Means Ⅰ.Estimation of Genic Effects for Additive -Dominance Model 一、 概 述 控制一个数量性状的多基因系统,其个别基因的效应,一般都不可能用孟德尔的归类法进行分析。因为这些基因的个别效应太小而又极易受环境的影响,难以划分不同基因型舰的界限。但是,一切数量性状,都有着一个特定的多基因系统(遗传作用)加环境修饰而形成的频率分布,这是在任何数量遗传实验中都可以观察到的。而频率分布,我们知道,其特征是可以用以诸如平均数、方差、协方差等统计数描述的。因此,计算这些统计数,并理解其遗传学意义(这是至关重要的),同样可对多基因控制的性状作出遗传分析。只是应注意到:(1)这类分析通常都是将多基因系统作为一个整体来处理,因而其结果是该系统中全部基因成员的一种总的或平均的性质,个别基因的作用一般不是很清楚;(2)这类分析多是依赖于“黑箱”理论的一种最佳估计,如果一系统中的各别基因皆能在细胞学上定位,并在生物化学上明了其作用方式,分析当然可以更为深入。 数量性状的遗传分析,在遗传理论和育种实践上,都有重要意义,而且又是一个相当庞大的论题。我们将从自花授粉植物世代平均数的遗传分析入手,联系我国育种实际,逐步展开讨论。 二、世代平均数的加性-显性模型 设某性状仅由一对等位基因A a -控制,其中A 对a 为增效(A 表示增效,a 表示减小), 且纯合体AA 和aa 的平均值(中亲值)为m 。则AA 和aa 的基因型值可分别记为 AA m d =+和aa m d =-,而杂合体Aa 的基因型值可记为Aa m h =+。这里,()d AA aa =-,是纯合情况下以等位基因A 替代a 的平均效应,称加性效应;h 是杂合 体Aa 的基因型值对m 的离差(其加性期望的离差),即h Aa m =-,表示了等位基因A 和 a 的交互作用,称显性效应。为简化表达,可以m 为原点记各基因型值,即,AA d Aa h --和aa d --。这样显然可得: (1) 若0h =或0h d =(即,,AA m d Aa m aa m d =+==-),不存在显性。 (2) 若0h d <<或0()1h d <<(即()m Aa m d <<+),为正向部分显性。
世代平均数的遗传分析2加性-显性-上位性模型的基因效应估计
世代平均数的遗传分析 Ⅱ.加性-显性-上位性模型的基因效应估计 莫惠栋 A Genetic Analysis of Generation Means Ⅱ.Estimates of Genic Effects for Additive-dominance-epistasis Model 五、世代平均数的加性-显性-上位性模型 当(6)给出的2 2 0.05,(3)k χχ->时,即可推断该性状的遗传是不符合加性-显性模型的。在此情况下,遗传学上的进一步考虑就是还可能存在着上位性效应,即非等位基因间的交互作用。现以两对等位基因的最简单情况为例,先说明上位性效应的意义和类别。 设一性状仅受两对等位基因A a -、B b -控制,则当存在非等位基因间的交互作用时,除掉加性效应1d 和2d 、显性效应1h 和 2h 外,尚需要考虑加性×加性12()d d ?的上位性效应12()i 、加性× 显性(12()d h ?的上位性效应12()j 、显性×加性12()h d ?的上位性效应 21()j 和显性×显性12()h h ?的上位性效应12()l 。这些上位性效应皆为一级交互作用。因而,2F 代的9种可能基因型的型值(以m 为原点)可列于表5。 表5中的各基因型值皆省略了m ,它是4种纯合体(AABB 、AAbb 、aaBB 、)aabb 的型值的平均数。表5中包含着一些重要的基本概念,需加注意: (1)对纯合体而言,以A 代a 的效应为:11122()()AABB AAbb aaBB aabb d ???+-+=?? 以B 代b 的效应为:11222()()AABB aaBB AAbb aabb d ???+-+=??,1d 和2d 的互作(非等位基因互作)效应为:111222()()AABB aabb AAbb aaBB i ???+-+=??,所以,纯合体基因
功能基因的序列比对方法
功能基因的序列比对 <1>.切除载体和(或)引物 a.打开所有的原始引物序列于一个EditSeq的窗口中 b. export all as one c.保存 d.打开这个保存的文件,开始切除载体和引物 e.选择载体插入点两侧的序列(10-15个的样子)搜索注意:不存在正反向的问题,都是一个
方向,因为测序的时候是选择两个载体上的引物其中的一条来往后测序的! 切完之后另存为 f. 重新打开这个文件,开始切除引物 方法同切载体,但是要注意正反向的问题。比如mcrA基因,其引物为Forward: 5'-GGTGGTGTMGGATTCACACARTAYGCWACAGC-3' Reverse: 5'-TTCATTGCRTAGTTWGGRTAGTT-3'
先找Forward 5’端,此时只找到的部分序列。切去5’端。 然后再切这些切掉5’端序列的3’端的序列,此时其3’端序列应该是Reverse 的反向互补序列。 切去这个反向互补序列,这样一来这个些序列就已经被切去两端的引物了。 但此时还剩下另一部分未切除任何引物的序列,此时记下这些序列的编号,先切去Reverse 5’
端。 再用Forward 的反向互补序列切去3’端,这样剩下的序列也都被切除两端的引物了。 <2>将所有序列调整为同向序列: a. 选择前面记录编号的序列,将这些序列一个个都转换为其反向互补序列。这样一来所有的序列都成为同向序列了,即在DNA两条反向互补链的其中一条上的比较了。
b. 保存该文件 <3> 生成OTUs Google 搜索”Fastgroup II” 或https://www.wendangku.net/doc/f016907761.html,/fg_tools.htm
中日韩人种基因拷贝数变异图谱出炉
中日韩人种基因拷贝数变异图谱出炉 韩国首尔大学基因医学研究所徐廷瑄教授领导的研究小组宣称,他们通过对30名中国人、韩国人和日本人的基因组研究,成功绘制出中日韩人种超高清基因拷贝数变异图谱,并根据该图谱发现,亚洲人独有的基因拷贝数变异共有3500多个。 所谓基因拷贝数变异(Copy Number Vriations)是指在人类基因组中广泛存在的,从1000bp(碱基对)到数百万bp范围内的缺失、插入、重复和复杂多位点的变异。研究表明,不少人类复杂性状疾病都和拷贝数变异有密切关系。 2019年,第一张人类基因组第一代基因拷贝数变异图谱问世。这张遗传图谱是通过对欧洲、非洲和亚洲祖先4个人群的270个个体样品进行分析,用两个互补的技术——单核苷酸多态性(SNPs)基因分型和以克隆为基础的比较基因组杂交进行基因拷贝数变异筛选,获得了一共1447个拷贝数变异。 之后的一系列研究显示,基因拷贝数变异是个体之间在基因组序列差异上的一个重要源泉,是研究基因组进化和表型差异的一个重要因素。许多关于基因拷贝数变异的研究结果表明,拷贝数变异可导致不同程度的基因表达差异,对正常表型的构成及疾病的发生发展具有一定作用。拷贝数变异研究在法医学方面也具有重要意义,在探索法医学个体识别的遗
传变异时不能忽略拷贝数变异这一基因组多样性的新形式。首尔大学医学院此次绘制的基因拷贝数变异图谱与西方绘制的现有图谱不同,是只针对中日韩人种进行研究并绘制完成的,将有效适用于特定人群的疾病诊疗,并为今后正式研究基因拷贝数变异和疾病之间的关联性提供了良好平台。(薛严) 当第一张人类基因组草图问世时,我们对这一划时代的成就充满期待,渴望它在医学诊断、预防和治疗方面,能够迅速兑现基因组研究的初衷。10年过去了,我们发现那不过是生命科学这部天书的扉页。基因组测序现已不算难事,科学家面临的更大挑战,是从浩繁的基因组序列中找到惠及健康的有用信息。或许,研究基因拷贝数变异,我们才翻到了这部天书的某一章节。
第五次课外部效应分析
第五次课 外部效应分析 (2015-10-16,星期五) 一、生产的外部效应模型 1、模型假设 1)某钢厂S 和渔场F 分别位于同一条河的上下游。钢厂S 生产s 吨钢铁时,会向河流中排放污染物x 。渔场F 的产量f 受到钢厂S 排放污染物x 的不利影响。 2)钢厂S 和渔场F 的成本函数分别为()x s C s ,和()x f C f ,,并且0??x C f 。 2、钢厂S 的最优决策 钢厂S 的利润最大化问题: ()x s C s p s s x s Max ,,- 一阶条件:()s x s C p s s ??=**,;() x x s C s ??=* *,0 3、渔场F 的最优决策 渔场F 的利润最大化问题: ()x f C f p f f f Max ,- 一阶条件:( )f x f C p f f ??= * *, 4、外部效应分析 钢厂在追求利润最大化时,只关注钢厂的私人成本,而不是相应的社会成本。渔场虽然十分关心污染的排放量,却无法对污染量加以控制。所以,从社会的角度来看,钢厂产生的污染量总是太多,因为钢厂忽略了污染对渔场的影响。 二、消除外在性的方法 1、外部效应的内部化——合并 当钢厂和渔场合并为一个企业时,外部效用就会消除。 合并企业的利润最大化问题: ()()x f C x s C f p s p f s f s x f s Max ,,,,--+ 一阶条件:() s x s C p s s ??=,;()f x f C p f f ??=,; ()()0,,=??+??x x f C x x s C f s 最后一个条件是关键的,该条件说明合并企业将同时考虑污染对钢厂和渔场边际成本的影
功能基因的克隆及生物信息学分析
功能基因的克隆及其生物信息学分析 摘要:随着多种生物全基因组序列的获得,基因组研究正从结构基因组学(structural genomics)转向功能基因组学(functional genomics)的整体研究。功能基因组学利用结构基因组学研究获得的大量数据与信息评价基因功能(包括生化功能、细胞功能、发育功能、适应功能等),其主要手段结合了高通量的大规模的实验方法、统计和计算机分析技术[1],它代表了基因分析的新阶段,已成为21世纪国际生命科学研究的前沿。功能基因组学是利用基因组测序获得的信息和产物,发展和应用新的实验手段,通过在基因组或系统水平上全面分析基因的功能,使生物学研究从对单一基因或蛋白的研究转向多个基因或蛋白同时进行系统的研究,是在基因组静态的组成序列基础上转入对基因组动态的生物学功能学研究[2]。如何研究功能基因,也成为我们面临的一个课题,本文就克隆和生物信息学分析在研究功能基因方面的应用做一个简要的阐述。 关键词:功能基因、克隆、生物信息学分析。 1.功能基因的克隆 1.1 图位克隆方法 图位克隆又称定位克隆,它是根据目标基因在染色体上确切位置,寻找与其紧密连锁的分子标记,筛选BCA克隆,通过染色体步移法逐步逼近目的基因区域,根据测序结果或用BAC、YAC克隆筛选cDNA表达文库寻找候选基因,得到候选基因后再确定目标基因。优点是无需掌握基因产物的任何信息,从突变体开始,逐步找到基因,最后证实该基因就是造成突变的原因。通过图位克隆许多控制质量性状的单基因得以克隆,最近也有报道某些控制数量性状的主效基因(控制蕃茄果实大小的基因克隆[3]、控制水稻成熟后稻谷脱落基因克隆[4]以及小麦VRN2 基因克隆[5]等)也通过图位克隆法获得。
基因组拷贝数变异及其突变机理与人类疾病
HEREDITAS (Beijing) 2011年8月, 33(8): 857―869 ISSN 0253-9772 https://www.wendangku.net/doc/f016907761.html, 综 述 收稿日期: 2011?04?07; 修回日期: 2011?06?03 基金项目:国家自然科学基金项目(编号: 30890034, 31000552), 教育部新世纪优秀人才支持计划项目(编号: NCET-09-0322)和上海市浦江人才 计划项目(编号: 10PJ1400300)资助 作者简介:杜仁骞, 在读博士研究生, 研究方向: 基因组拷贝数变异。E-mail: renqian.du@https://www.wendangku.net/doc/f016907761.html, 通讯作者:张锋, 博士, 副教授, 博士生导师, 研究方向: 人类遗传学和医学遗传学。E-mail: feng.fudan@https://www.wendangku.net/doc/f016907761.html, DOI: 10.3724/SP.J.1005.2011.00857 基因组拷贝数变异及其突变机理与人类疾病 杜仁骞1,2, 金力1,2,3, 张锋1,2 1. 复旦大学生命科学学院现代人类学教育部重点实验室, 上海200433; 2. 复旦大学生命科学学院遗传工程国家重点实验室, 上海200433; 3. 复旦大学生物医学研究院, 上海200032 摘要: 拷贝数变异(Copy number variation, CNV)是由基因组发生重排而导致的, 一般指长度为1 kb 以上的基因 组大片段的拷贝数增加或者减少, 主要表现为亚显微水平的缺失和重复。CNV 是基因组结构变异(Structural variation, SV)的重要组成部分。CNV 位点的突变率远高于SNP(Single nucleotide polymorphism), 是人类疾病的重要致病因素之一。目前, 用来进行全基因组范围的CNV 研究的方法有: 基于芯片的比较基因组杂交技术(array-based comparative genomic hybridization, aCGH)、SNP 分型芯片技术和新一代测序技术。CNV 的形成机制有多种, 并可分为DNA 重组和DNA 错误复制两大类。CNV 可以导致呈孟德尔遗传的单基因病与罕见疾病, 同时与复杂疾病也相关。其致病的可能机制有基因剂量效应、基因断裂、基因融合和位置效应等。对CNV 的深入研究, 可以使我们对人类基因组的构成、个体间的遗传差异、以及遗传致病因素有新的认识。 关键词: 拷贝数变异; 突变机理; 疾病; 人类基因组 Copy number variations in the human genome: their mutational mechanisms and roles in diseases DU Ren-Qian 1,2, JIN Li 1,2,3, ZHANG Feng 1,2 1. MOE Key Laboratory of Contemporary Anthropology , School of Life Sciences , Fudan University , Shanghai 200433, China ; 2. State Key Laboratory of Genetic Engineering , School of Life Sciences , Fudan University , Shanghai 200433, China ; 3. Institutes of Biomedical Sciences , Fudan University , Shanghai 200032, China Abstract: Copy number variation (CNV) is the main type of structure variation (SV) caused by genomic rearrangement, which mainly includes deletion and duplication of sub-microscopic but large (>1 kb) genomic segments. CNV has been recognized as one of the main genetic factors underlying human diseases. The mutation rate (per locus) of CNV is much higher than that of single nucleotide polymorphism (SNP). The genome-wide assays for CNV study include array-based comparative genomic hybridization (aCGH), SNP genotyping microarrays, and next-generation sequencing techniques. Various molecular mechanisms are involved in CNV formation, which can be divided into two main categories, DNA re-combination-based and DNA replication-based mechanisms. CNVs can be associated with Mendelian diseases, sporadic diseases, and susceptibility to complex diseases. CNVs can convey clinical phenotypes by gene dosage, gene disruption, gene fusion, and position effects. Further studies on CNVs will shed new light on human genome structure, genetic varia-tions between individuals, and missing heritability of human diseases. Keywords: copy number variation; mutational mechanism; diseases; human genome
人类遗传变异-拷贝数变异(CNVs)和疾病研究及检测
在人类细胞遗传学研究的早期,人们在显微镜下研究染色体,发现了染色体的拷贝数、重排和结构方面存在变异,而且在很多情况下这些变异可能与疾病相关。在分辨率频谱的另一端即高分辨率区域,DNA短片段的分析和测序方法的发展导致了短串联重复序列和单核苷酸多态性(SNPs)的发现。显而易见,人为遗传变异范围包括从序列水平上单一碱基对的变化到用显微镜检测到的几兆碱基长度的染色体差异。最近,通过观测亚微观DNA片段中广泛颁布的拷贝数变异,我们对于人类遗传变异的认识又进一步得到了拓展。全基因组扫描方法的实行大大推动了这种关于人为变异的新认识,这些方法给我们提供了一个在显微镜细胞遗传学(>5-10Mb)和DNA序列分析(1-700bp)之间的对基因组中间范围遗传变异进行解读的强有力工具。正如图6所示的结构变民中的中等分辨率范围内的测亚微观部分。 现在已经发展了很多方法来检测这类中等大小范围内的DNA遗传变异,DNA生物芯片技术可能是其中最为有效的方法。拷贝数变异(CNV)鉴定的主要方法是比较基因组杂交(CGH),而商业的标准CGH芯片在人类基因组的每1Mb长度范围有一个细菌人工染色体(BAC)克隆,这样就很难精确鉴定小于50kb的单拷贝数差异。昂飞的人类基因组图谱SNP芯片500K和SNP 5.0芯片的标记间距离中位数为2.5kb,最近推出的SNP 6.0的中位数则少于700个碱基对。这类基因型芯片通过将测试样本所获取的信息强度与其他个体的进行比较来确定每个位点相对基因组拷贝数。同时,拷贝数检测运算法中将探针的长度和GC含量考虑到其中,从而进一步降低了基因型芯片检测噪音。另外一个优点是,基因型芯片对拷贝数变异区域进行全面检测,并通过在连续的几个探针中要有重大的比率变化来确认。所以说,这样的工具明显提高了检测的精确度。除了提供拷贝数信息,SNP 基因型芯片提供的基因型信息不但可以用于遗传关联性研究,还可以用于检测杂合性丢失,这为缺失的存在提供支持证据,还可能提示片段性单亲二体。 近年来通过拷贝数变异(CNVs)的研究,我们知道人类群体中的任何两个个体基因组结构上的差异比核苷酸序列水平上的差异更大(请参阅应用案例2)。保守的估计显示个体之间CNVs总计有4Mb(相当于每800bp 就有1个不同)。不保守估计则认为有多达5-24Mb范围内存在CNVs。无论是哪种估计,平均来说CNVs中的核苷酸变异数量比SNPs还要多,后者总数大约是2.5Mb(相当于每1,200个bp中有1个SNP)。因此人类个休之间的所有基因组差异性要远远大于先前所认为的,至少存在0.2%的差异:结构水平上有0.12%以上的差异,核苷酸水平上有0.08%的差异。 昂飞芯片技术革新不但为之前未被发现的人类健康人群中存在的基因组变异的基础研究敞开了大门,也为研究疾病的遗传基础打开了一扇新的窗户.致癌基因的扩增和/或肿 瘤抑制基因的缺失是癌症起始和发展的特点,这一特点近来被认为可用来暗示癌症对治疗剂的反应。因此在细胞系和肿瘤样品中对这些 2008年7月23日第三十三期第 8 页,共 14 页下一页 返 回
第2章 外部效应
第2章外部效应 一、习题 1.填空题 (1)外部效应就是未在价格中得以反映的经济交易____或____。 (2)外部效应按照结果来分类可分为____和____。 (3)负的外部效应是指,给交易双方之外的第三者带来的未在价格中得以反映的____。(4)政府用于矫正外部效应的财政措施有_____和____。 (5)矫正性的税收的突出特征是其税额同____相等。 2.判断题 (1)在存在正的外部效应的情况下,无论是产品的买者,还是卖者,都会在其决策中意识到他们之间的交易会给其他人带来益处。() (2)所有的给交易双方之外的第三者带来的影响都可称作外部效应。() (3)在存在外部效应的情况下,私人边际效益和边际成本会同社会边际效益和边际成本发生偏离。() (4)在存在负的外部效益的情况下,一种物品或服务的私人边际成本大于其社会边际成本。() (5)存在外部边际效益递减的正的外部效应时,市场机制下的产量水平总是缺乏效率的。() 3.单项选择题 (1)下面关于正的外部效应和负的外部效应的四项论述中,正确的有()。 ①正的外部效应是指给交易双方之外的第三者带来的未在价格中得以反映的经济效益 ②负的外部效应是指给交易双方之外的第三者带来的未在价格中得以反映的成本费用 ③具有正的外部效应的物品或服务往往会出现供给不足 ④具有负的外部效应的物品或服务往往会出现供给过多 A.1个 B.2个 C.3个 D.4个 (2)关于“金钱的外部效应”的论述,正确的是()。 A.因某种物品或服务需求量或供给量变动而以价格上涨或下降形式给现有消费者带来的影响,称作“金钱的外部效应” B.那些对第三者所造成的无法通过价格或者说不能在价格中得以反映的影响,就是“金钱的外部效应” C.“金钱的外部效应”同样会导致资源配置的扭曲 D.“金钱的外部效应”也在政府要采取措施加以矫正的外部效应范围之列 (3)下面对负的外部效应的分析,四种情况中发生的可能性最小的是()。 A.随着年产量增加一倍,外部总成本可能也随之增加一倍,外部边际成本保持不变 B.随着年产量增加一倍,外部总成本的增加可能大于一倍,外部边际成本递增 C.随着年产量增加一倍,外部总成本的增加可能小于一倍,外部边际成本递减 D.随着年产量增加一倍,外部总成本的增加可能小于一倍,外部边际成本递增
功能基因的序列比对方法
<1>.切除载体和(或)引物 a.打开所有的原始引物序列于一个EditSeq的窗口中 b. export all as one c.保存 d.打开这个保存的文件,开始切除载体和引物 e.选择载体插入点两侧的序列(10-15个的样子)搜索注意:不存在正反向的问题,都是一个方向,因为测序的时候是选择两个载体上的引物其中的一条来往后测序的! 切完之后另存为 f.重新打开这个文件,开始切除引物 方法同切载体,但是要注意正反向的问题。比如mcrA基因,其引物为 Forward: 5'-GGTGGTGTMGGATTCACACARTAYGCWACAGC-3' Reverse: 5'-TTCATTGCRTAGTTWGGRTAGTT-3' 先找Forward 5’端,此时只找到的部分序列。切去5’端。 然后再切这些切掉5’端序列的3’端的序列,此时其3’端序列应该是Reverse 的反向互补序列。 切去这个反向互补序列,这样一来这个些序列就已经被切去两端的引物了。 但此时还剩下另一部分未切除任何引物的序列,此时记下这些序列的编号,先切去Reverse 5’端。 再用Forward 的反向互补序列切去3’端,这样剩下的序列也都被切除两端的引物了。 <2>将所有序列调整为同向序列:
a.选择前面记录编号的序列,将这些序列一个个都转换为其反向互补序列。这样一来所有的序列都成为同向序列了,即在DNA两条反向互补链的其中一条上的比较了。 b.保存该文件 <3>生成OTUs Google 搜索”Fastgroup II” 或grouping--注意勾选的选项) Choose method 里面相似度可以选97%或98% 提交之后出现的窗口如 可以看到被分为了10个OUT 每个OUT都自动选择了一个代表序列。全选将其复制到word中,备用。并把其中的那些代表序列都复制下来粘贴到TXT 保存。 <4>寻找嵌合体:一般是对16S rRNA来说的 两个网站: (或搜decipher chimera) (或搜bellerophon chimera check) <5>翻译 网站: 在保存有OTUs的TXT文件中,一个一个翻译成蛋白质序列。最后保存。 在用Expasy翻译的时候选择第二个选项 点击翻译
基因表达及分析技术
基因表达及其分析技术 生命现象的奥秘隐藏在基因组中,对基因组的解码一直是现代生命科学的主流。基因组学研究可以说是当今生命科学领域炙手可热的方向。从DNA 测序到SNP、拷贝数变异(copy number variation , CNV)等DNA多态性分析,到DNA 甲基化修饰等表观遗传学研究,生命过程的遗传基础不断被解读。 基因组研究的重要性自然不言而喻。应该说,DNA 测序技术在基因组研究 中功不可没,从San ger测序技术到目前盛行的新一代测序技术(Next Gen eration Seque ncing NGS)到即将走到前台的单分子测序技术,测序技术是基因组解读最重要的主流技术。而基因组测序、基因组多态性分析、DNA 甲基化修饰等表观遗传分析等在基因组研究中是最前沿的课题。但是基因组研究终究类似“基因算命”,再清晰的序列信息也无法真正说明一个基因的功能,基因功能的最后鉴定还得依赖转录组学和蛋白组学,而转录作为基因发挥功能的第一步,对基因功能解读就变得至关重要。声称特定基因、特定SNP、特定CNV、特定DNA修饰等与某种表型有关,最终需要转基因、基因敲除、突变、 RNAi 、中和抗体等技术验证,并必不可少要结合基因转录、翻译和蛋白修饰等数据。 基因实现功能的第一步就是转录为mRNA或非编码RNA,转录组学主要研究基因转录为RNA 的过程。在转录研究中,下面几点是必须考虑的: 1,基因是否转录(基因是否表达)及基因表达水平高低(基因是低丰度表达还是中、高丰度表达)。特定基因有时候在一个细胞中只有一个拷贝的表达,而表达量会随细胞类型不同或发育、生长阶段不同或生理、病理状态不同而改变。因此任何基
田间试验与统计分析课程课后习题spss分析结果模板(第五章、第六章)
一、实验信息 软件版本:spss19 姓名:任志强学号:201607309 班级:农区1601 日期:2018.6.21 二、实验内容 (1)安装sas软件; (2)结合spss软件操作讲解课本第139页例题; (3)利用spss软件对课本习题5-12,、5-13、5-14、6-1、6-6、6-7进行数据的具体分析。 三、实验目的 学习使用sas和spss的数据分析功能生成实验结果。 四、指导教师:刘永建教授 五、实验结果及分析 (一)习题5-12 1.实验数据(产量单位:Kg/666.67m2)
a. R 方 = 1.000(调整 R 方 = 0.999) 不同品种产量差异显著性值=0.006<0.05,所以不同品种产量存在显著性差异,不同种植密度产量差异显著性值=0.007<0.05,所以不同种植密度产量之间存在显著性差异。因而还必须进行品种和密度两因素不同水平平均产量的多重比较。 2.多重比较 ①不同品种平均产量的多重比较(显著性水平=0.05) 对于不同品种玉米产量的多重比较采用SSR法,得出品种1产量显著高于和品种2、3产量,品种2、3产量之间没有显著差异。
对于不同密度玉米产量的多重比较采用SSR法,得出密度2、3产量显著高于密度1、4,密度2、3产量之间没有显著差异,密度2、4产量之间没有显著差异,密度4产量显著高于密度1产量。 ②不同品种平均产量的多重比较(显著性水平=0.01) 已显示同类子集中的组均值。 基于观测到的均值。 误差项为均值方 (错误) =202.083。 a. 使用调和均值样本大小 = 4.000。 b. Alpha = 0.01。 已显示同类子集中的组均值。 基于观测到的均值。 误差项为均值方 (错误) = 202.083。 a. 使用调和均值样本大小 = 3.000。 b. Alpha = 0.01。 对于不同品种玉米产量的多重比较采用SSR法,得出品种1、2产量极显著高于和品种3产量,品种2、3产量之间没有极显著差异,品种1、2产量之间没有极显著差异。 对于不同密度玉米产量的多重比较采用SSR法,得出密度2、3、4产量极显著高于密度1,密度2、3、4产量之间没有极显著差异。
功能基因序列分析案例
青霉素基因序列分析 摘要:青霉素是抗菌素的一种,是指从青霉菌培养液中提制的分子中含有青霉烷、能破坏细菌的细胞壁并在细菌细胞的繁殖期起杀菌作用的一类抗生素,是第一种能够治疗人类疾病的抗生素。近年来,由于滥用抗生素,导致了大量耐药性菌株的出现,严重威胁着人类的健康,现在细菌耐药性已成为全球关注的医学与社会问题。本文以青霉素为例,阐述一种通过构建系统发育树研究不同青霉素间亲缘性,来研究细菌青霉素抗性的方法。 关键词:青霉素;基因序列;邻接法;系统发育树 引言 一、青霉素简介 青霉素( Penicillin ,或音译盘尼西林)是指分子中含有青霉烷、能破坏细菌的细胞壁并在细菌细胞的繁殖期起杀菌作用的一类抗生素,是由青霉菌中提炼出的抗生素。青霉素属于 3—内酰胺类抗生素(3—lactams), 3—内酰胺类抗生素包括青霉素、头孢菌素、碳青霉烯类、单环类、头霉素类等。青霉素是很常用的抗菌药品。但每次使用前必须做皮试,以防过敏。 青霉素是人类最早发现的抗生素,1928 年英国伦敦大学圣玛莉医学院(现属伦敦帝国学院)细菌学教授弗莱明在实验室中发现青霉菌具有杀菌作用[2] ,1938 年由麻省理工学院的钱恩、弗洛里及希特利( Norman Heatley ,1911-2004)领导的团队提炼出来。弗莱明因此与钱恩和弗洛里共同获得了1945 年诺贝尔生理医学奖。 青霉素类抗生素是3-内酰胺类中一大类抗生素的总称,它们具有相似的作用机理。细菌一般都处于低渗 (即外界的渗透压低于细菌体内部) 的环境中,因而会自发地吸收外界的水分。为了防止细胞因吸水过多而膨胀炸裂,细菌在其细胞壁中合成一种名为肽聚糖的物质,以此抵抗细菌体的自发吸水膨胀。青霉素即作用于肽聚糖的合成过程中,阻止它的合成,进而导致细菌体失去抵抗渗透压的能力而胀破。 二、抗生素抗性的产生 细菌抗药性产生的原因主要包括以下几种:(1)通过对抗生素的降解或取代活性基团,改变抗生素的结构,使抗生素失活;(2) 通过对抗生素靶位的修饰使抗生素无法与之结合而表现出抗性;(3)通过特异或通用的抗生素外排泵将抗生素排出细胞外,降低胞内抗生素浓度而表现出抗性;(4) 其他抗性机制包括在细胞膜上形成多糖类的屏障减少抗生素进入细胞内[1] 。 抗生素耐药性发生与传播与抗生素的使用直接相关,任何抗生素使用均可以导致抗生素耐药性的发生[2]。抗生素耐药性问题早在抗生素使用之初就为学者所认识。自20 世纪60 年代耐甲氧西林金黄色葡萄球菌(MRSA) 报道以来,随着更多抗生素特别是广谱抗生素如广谱3-内酰胺类和氟喹诺酮类抗生素等的广泛应用,耐药性的发生与传播越来越严重,且在上世 纪90年代学者们已开始警告后抗生素时代”的到来⑶。WHO在2001年也提出了需要全球采取紧急行动控制抗生素耐药性,并从抗生素使用(包括人与动物) 、药物和疫苗开发、药 品促销、耐药性监测及各国政府和卫生系统多个方面探讨控制耐药性问题的干预措施。在过去的10年里,抗生素耐药性已是公共卫生所面临的最大挑战之一,许多因素继续造成众多不必要的抗生素使用及浪费抗生素这一重要公共卫生资源[4]。 三、构建系统发育树对鉴定生物间亲缘关系的意义
基因芯片数据功能分析
生物信息学在基因芯片数据功能分析中的应用2009-4-29 随着人类基因组计划(Human Genome Project)即全部核苷酸测序的即将完成,人类基因组研究的重心逐渐进入后基因组时代(PostgenomeEra),向基因的功能及基因的多样性倾斜。 通过对个体在不同生长发育阶段或不同生理状态下大量基因表达的平行分析,研究相应基因在生物体内的功能,阐明不同层次多基因协同作用的机理,进而在人类重大疾病如癌症、心血管疾病的发病机理、诊断治疗、药物开发等方面的研究发挥巨大的作用。它将大大推动人类结构基因组及功能基因组的各项基因组研究计划。生物信息学在基因组学中发挥着重大的作用,而另一项崭新的技术——基因芯片已经成为大规模探索和提取生物分子信息的强有力手段,将在后基因组研究中发挥突出的作用。基因芯片与生物信息学是相辅相成的,基因芯片技术本身是为了解决如何快速获得庞大遗传信息而发展起来的,可以为生物信息学研究提供必需的数据库,同时基因芯片的数据分析也极大地依赖于生物信息学,因此两者的结合给分子生物学研究提供了一条快捷通道。 本文介绍了几种常用的基因功能分析方法和工具: 一、GO基因本体论分类法 最先出现的芯片数据基因功能分析法是GO分类法。Gene Ontology(GO,即基因本体论)数据库是一个较大的公开的生物分类学网络资源的一部分,它包含38675个Entrez Gene注释基因中的17348个,并把它们的功能分为三类: 分子功能,生物学过程和细胞组分。在每一个分类中,都提供一个描述功能信息的分级结构。这样,GO中每一个分类术语都以一种被称为定向非循环图表(DAGs)的结构组织起来。研究者可以通过GO分类号和各种GO数据库相关分析工具将分类与具体基因联系起来,从而对这个基因的功能进行描述。在芯片的数据分析中,研究者可以找出哪些变化基因属于一个共同的GO功能分支,并用统计学方法检定结果是否具有统计学意义,从而得出变化基因主要参与了哪些生物功能。
第五课分析矛盾 辩证思维
第五课《分析矛盾辩证思维》 一、教学内容分析 本课分四框: 第一框矛盾是事物发展的动力和源泉 第二框矛盾的普遍性和特殊性 第三框主次矛盾和矛盾的主次方面 第四框用矛盾的观点观察问题和分析问题 (一) 矛盾是事物发展的动力和源泉 这个内容是本课的教学重点。在教学中要着重引导和帮助学生理解和把握以下内容: 1.矛盾的含义。 唯物辩证法所说的矛盾,不是指思维中“自相矛盾”的逻辑错误,而是指事物自身包含的既对立又统一的关系。要结合学生学过的自然科学、社会科学、思维科学知识统,帮助学生领会矛盾这种对立统一的关系是客观存在的。 2.矛盾的基本属性。 在教学中要引导学生结合自己的生活经验,用归纳法概括出矛盾的同一性与斗争性是矛盾的两种基本属性。 要提醒学生注意哲学上所讲的“斗争”,是对一切具体的矛盾双方互相排斥、互相斗争的抽象和概括。不能把哲学上
讲的对立、斗争与日常生活中特别是政治用语中的“对立”、“斗争”混为一谈。要使学生认识,矛盾的同一性是指矛盾双方相互吸引、相互联结的属性和趋势。具体地说: 矛盾的同一性,一是指矛盾双方相互依存,一方的存在以另一方的存在为前提,双方共处于一个统一体中;二是指矛盾着的双方,依据一定的条件,各向自己相反的方向转化。要特别引导学生注意,矛盾双方的转化是有条件的,没有一定的条件,矛盾双方是不可能转化的。 3.矛盾的同一性和斗争性相结合推动着事物的发展。 在教学中,要引导学生结合自然界、人类社会和人类思维的发展,认识世界上一切事物的运动、变化、发展,都是事物内部的矛盾双方又统一、又斗争的结果。要引导学生认识,只有矛盾的同一性和斗争性相结合,才能推动事物的运动、变化和发展。要结合党的十七大精神的学习,引导学生认识,社会主义和谐社会并不是没有矛盾的社会。构建社会主义和谐社会的过程,就是在妥善处理各种矛盾中不断前进的过程,就是不断消除不和谐因素、不断增加和谐因素的过程。事物的变化和发展,都是内因和外因共同起作用的结果。事物的内部矛盾是事物变化和发展的内因,事物的外部矛盾是事物变化和发展的外因。在事物的变化和发展过程中,内因和外因同时存在,缺一不可。内因和外因在事物发展中的
第四章-基因的结构和功能
第四章基因的结构和功能 一、教学目的和要求: 1掌握基因概念及其发展; 2 掌握基因的重组测验 3 理解利用顺反试验、互补试验鉴定两个突变型是否属于同一基因的原理; 4 了解缺失作图的原理 二、教学重点: 1基因概念及其发展; 2 基因的重组测验 三、教学难点: 缺失作图的原理 四、教学方法: 面授并辅以多媒体教学 五、教学内容 基因是一个特定的DNA或RNA片段,但并非一段DNA或RNA都是基因。 第一节基因的概念一、基因概念的发展 (一)遗传“因子”:孟德尔认为,生物性状的遗传由遗传因子所控制,性状本身不遗传。(二)染色体是基因的载体:摩尔根实验证明基因位于染色体上,并呈直线排列,提出了遗传学是连锁交换规律,建立了遗传的染色体学说,为细胞遗传学奠定了重要基础。并由此提出基因既是一个功能单位,是一个突变单位,也是一个交换单位的“三位一体”概念。∴经典遗传学认为:基因是一个最小的单位,不能分割;既是结构单位,又是功能单位。(三)DNA是遗传物质:1928年Griffith首先发现了肺炎球菌的转化,证实DNA是遗传物质而非蛋白质;Avery用生物化学的方法证明转化因子是DNA而不是其他物质。 (四)基因是有功能的DNA片段 20世纪40年代Beadle和Tatum提出一个基因一个酶的假说,沟通了蛋白质合成与基因功能的研究 1953年Watson和Crick提出DNA双螺旋结构模型,明确了DNA的复制方式。 1957年Crick 提出中心法则,61年提出三联体遗传密码,从而将DNA分子结构与生物体结合起来 1957年Benzer用大肠杆菌T4噬菌体为材料,分析了基因内部的精细结构,提出了顺反子(cistor)的概念,证明基因是DNA分之上一个特定的区段,是一个功能单位,包括许多突变位点(突变子),突变位点之间可以发生重组(重组子) 理论上,一个基因有多少对核苷酸对就有多少突变子和的重组子,实际上,突变子数少于核苷酸对数,重组子数小于突变子数。 总之:顺反子学说打破了“三位一体”的基因概念,把基因具体化为DNA分子上特定的一段顺序--- 顺反子,其内部又是可分的,包含多个突变子和重组子。 近代基因的概念:基因是一段有功能的DNA序列,是一个遗传功能单位,其内部存在有许多的重组子和突变子。 突变子:指改变后可以产生突变型表型的最小单位。 重组子:不能由重组分开的基本单位。(五)操纵子模型 1961年法国分子生物学家Jacob和Monod通过对大肠杆菌乳糖突变体研究,提出了操纵子学说(operon theory)。阐明了基因在乳糖利用中的作用。