SPSS教育统计学重点

教育统计学
第一章绪论
一、什么是教育统计学:教育统计学是运用数理统计的原理和方法,研究教育问题的一门应用科学。主要任务是研究如何搜集、整理、分析由教育调查和教育试验所获得的数字资料,并以此为依据,进行科学推断,揭示教育现象所蕴含的客观规律。
二、统计学的分类:描述统计推断统计理论统计应用统计
描述统计:描述统计就是对已获得的数据进行整理、概括,显现其分布特征的统计方法.
推断统计:根据样本所提供的信息,运用概率的理论进行分析、论证,在一定可靠程度上,对总体分布特征进行估计、推测,这种统计方法称为推断统计。(内容:参数估计和假设检验目的:对总体特征作出推断)
三、具有以下三个特性的现象,称为随机现象
第一,一次试验有多种可能结果,其所有可能结果是已知的;
第二,试验之前不能预料哪一种结果会出现;
第三,在相同的条件下可以重复试验。
(延迟满足)
四、样本容量(样本包含的个体数目大样本n>30小样本n<30
五、参数和统计量
参数(parameter)
●描述总体特征的概括性数字度量,是研究者想要了解的总体的某种特征值。
●所关心的参数主要有总体均值(μ)、标准差(σ)、总体比例(π)等
●总体参数通常用希腊字母表示
统计量(statistic)
●用来描述样本特征的概括性数字度量,它是根据样本数据计算出来的一些量,是样本的
函数
●所关心的样本统计量有样本均值(?x)、样本标准差(s)、样本比例(p)等
●样本统计量通常用小写英文字母表示
●参数与统计量的符号系统
第二章数据的处理
一、名义、顺序、等距、比率
①名义变量:是指一事物与其他事物在属性、类别上不同。
1表示男,0表示女,但这里的1,0并不说明事物间差异的大小,只是分类的符号而已,即名称变量不说明事物之间差别的大小,作比较时,只能说明被比事物相同,还是不同顺序变量(ordinal variable)。
②顺序变量:是事物的某一属性的多少或大小按顺序排列起来的变量。
如教师按能力大小或成绩高低排列等级:1,2,3,……,这一系列数据表明“大于”某某,即第1高于第2,第2高于第3……,而相邻两个等级的间隔是不等距的,即1与2和2与3之间并不等距。只有等级上的差别,是一种既无相等单位又无绝对零点的变量。
③等距变量:在能力测验或知识测验中,或甲生得80分,乙生得60分,进行比较时我们可以说甲生比乙生多20分,但却不能以倍数来表示。这是因为这类数据只具有相等的单位,而没有绝对的零点。这类变量虽然有0分,但是这个0分是人为确定的。譬如某一个学生在数学测验中得了0分,我们并不能说他不没有一点数学能力或知识,这就像摄氏温度一样,0度并不意味着没有温度。
④比率变量:比率变量是一种既有相等的单位,又有绝对零点的变量,又称等比变量,像人的身高、体重、距离、时间、教育投资、学校固定资产金额等均属于这种变量。
第三章 集中量
一、集中量的定义:代表一组数据典型水平或集中趋势的量称为集中量; 用途有二,一是可以
作为一组数据的代表值;二是可以进行组与组之间的比较。
常用的集中量有算术平均数、中位数、众数等。
二、算术平均数的优缺点
1.算术平均数:最常用,优点也最多。
优点:(1)感应灵敏(2)严密确定(3)简明易懂,计算简便(4)适合代数运算(5)受抽样变动的影响
较小
缺点:(1)易受两极端数值的影响 (2)有一两个数据模糊不请时,无法计算。这时通常选择中位数。 三、算术平均数计算:是所有观察值的总和除以总频数所得之商,简称平均数或均数、均值N X
X X X N +++= 21。
四、中位数的算法
?总频数为奇数 如n=25为奇数,n+1/2=26/2=13, 所以中位数为位于第13号的那个,
?总频数为偶数 中位数为第15号和16号数值的平均,即(88+89)÷2=88.5。
五、百分位数(概念):百份位数是位于以一定顺序(一般是由小到大)排列的一组数据中某一百分位置的数值。百分位通常用第几百分位来表示,如第五百分位,它表示在所有测量数据中,测量值的累计频次达5%。以身高为例,身高分布的第五百分位表示有5%的人的身高小于此测量值,95%的身高大于此测量值。 例:P 80=75 有80%的人得分低于75 p 80=----- 有80%的人得分低于该分数
六、众数的求法:先把数据列出来,然后找出现频数最大的数,即为众数
第四章 差异量
一、差异量的定义:表示一组数据变异程度或离散程度的量称为差异量
常用的差异量指标有:方差;标准差
二、方差与标准差的优缺点:
1.优点:反应灵敏;严密确定;适合代数计算;计算简单;用样本数据推断总体差异量时,方差和标准差是最好的估计量。一般和算术平均数结合在一起使用。
2.缺点:不太容易理解;易受两极端数值的影响;有个别数值模糊时,无法计算;单位的平方不好理解。
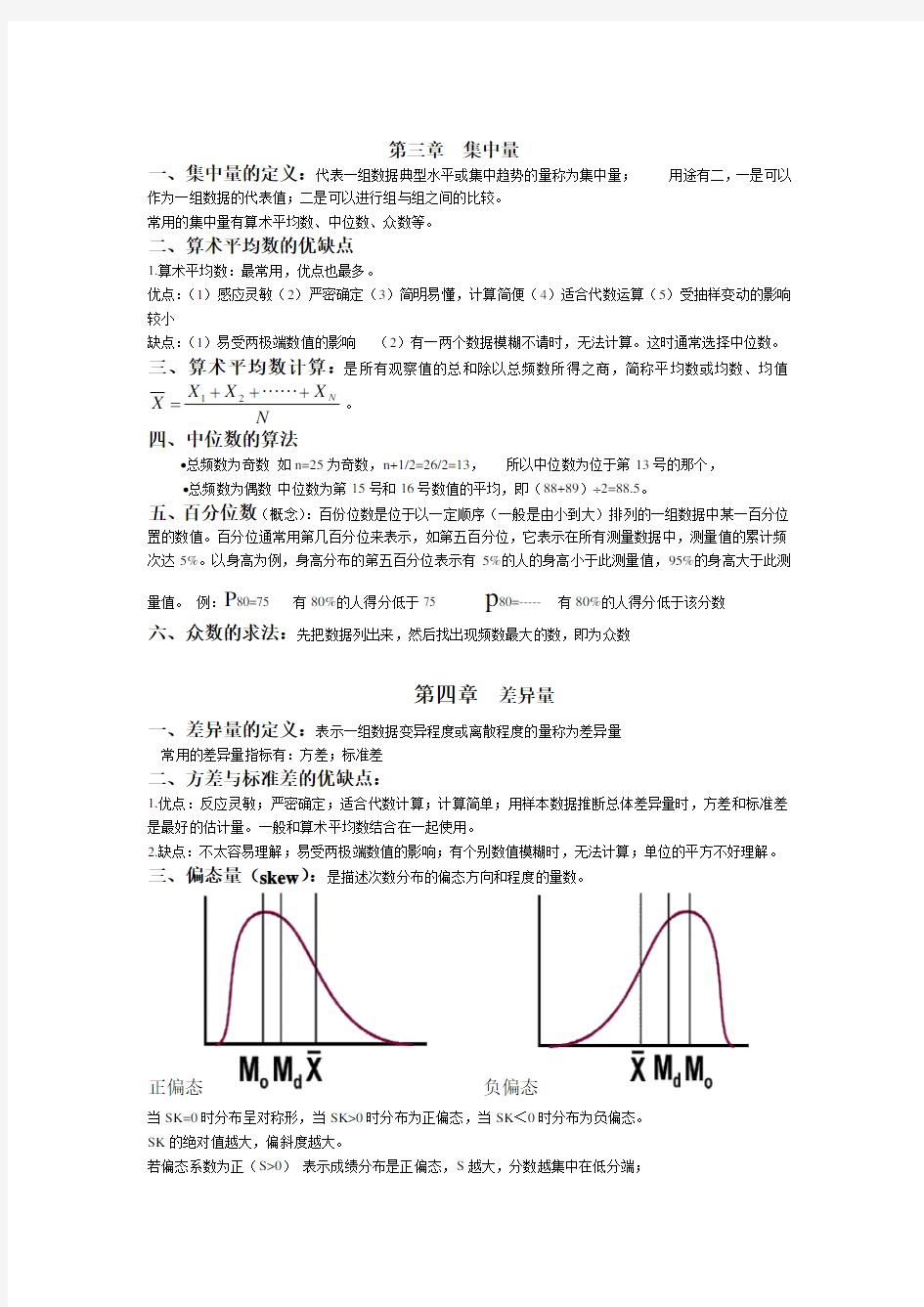
三、偏态量(skew ):是描述次数分布的偏态方向和程度的量数。
正偏态
负偏态 当SK=0时分布呈对称形,当SK>0时分布为正偏态,当SK <0时分布为负偏态。
SK 的绝对值越大,偏斜度越大。 若偏态系数为正(S>0) 表示成绩分布是正偏态,S 越大,分数越集中在低分端;
若偏态系数为负(S<0)表示成绩分布是负偏态,S越大,分数越集中在高分端;
考试难度大,学生得分普遍低,呈正偏态; 考试难度小,学生得分普遍高,呈负偏态.
?高狭峰:S较小,分数分布高窄,集中在平均数两侧。
?低阔峰:S较大,分数分布低阔,散布较广。
?正态峰:分布介于高峰态和低峰态之间。
第五章参数估计
一、推断统计:推断统计是研究如何利用样本数据来推断总体特征的统计方法。
点估计含义:直接用样本统计量的值作为总体参数的估计值,样本均值就是总体均值μ的一个估计量。如果样本均值?x = 3 ,μ的估计值
点估计的理论依据1。对称分布的中位数与平均数重合,其样本平均数就是总体平均数和总体中位数的无偏估计量,也是一致估计量. 2。根据中心极限定理,只要样本容量足够大,就可以近似地用正态分布去描述它. 3。一般情况下,样本平均数是比样本中位数更有效的估计量,因为在大量样本中,样本平均数的平均误差比样本中位数的平均误差小.
二、良好点估计量的条件无偏性一致性有效性
区间估计:一定概率条件下样本统计量估计总体参数可能落入范围估计一个包含总体参数在内的区间,通常用区间的大小或者实际参数落在某个区间的概率两种方式表达区间估计的结果
1.根据一个样本的观察值给出总体参数的估计范围
2.给出总体参数落在这一区间的概率
3.例如: 总体均值落在50~70之间,置信度为95%
1)置信区间定义:置信区间是指在特定的可靠性(即置信系数)要求下,估计总体参数所落的区
间范围,亦即进行估计的全距。
置信区间的涵义:
以95%的可信区间为例,对于某一个区间而言,它包含总体均数的可能性为95%,而不包含总体均数的可能性仅为5%。因此在实际应用中,以这种方法估计总体均数犯错误的概率仅为5%。
2)置信系数(置信度)定义:置信系数是指被估计的总体参数落在置信区间内的概率D ,或以
1-a 表示。置信系数是用来说明置信区间可靠程度的概率,也是进行正确估计的概率。
?符号:D(Degree of reliability),或1-α
?别名:置信水平、置信系数、置信概率
?常用值:D(1-α)=.95 D(1-α)=.99
三、显著性水平:统计学中把这种拒绝零假设的概率,显著性水平是统计推断时,可能犯错误
的概率。α值和可靠度之间的关系是:两者之和为1。α值越大,可靠度就越低;α值越小,可靠度就越高。一个置信系数同时反映了在做出一个估计时所犯错误的小概率(),即可靠性为95%时,意味着犯错误的概率为5%;可靠性为99%时,意味着犯错误的概率为1%。
显著性检验的一般步骤:
1.提出假设
2.选择检验统计量并计算其值
3.确定检验形式
4.统计决断
双侧Z检验统计决断规则
单侧Z检验统计决断规则
四、正态分布区间与横轴围成的面积为 1
五、假设检验的步骤
A、提出原假设和备择假设
B、确定适当的检验统计量
C、规定显著性水平
D、计算检验统计量的值
E、作出统计决策
第六章平均数差异检验
一、独立样本定义:两个样本内的个体是随机抽取的,它们之间不存在一一的对应关系。
二、两独立样本T检验:是根据样本数据对两个样本来自的两独立总体的均值是否有显著差
异进行推断。
SPSS13.0操作:Analyze——compare means——Independent samples T test
?前提条件:
1、两样本应该是相互独立的。
2、样本来自的两个总体应该服从正态分布。
?样本平均数与总体平均数之间差异的假设检验又叫做总体平均数的显著
性检验。如果某个样本平均数与总体平均数的差异达到了显著性水平就可以推翻零假设,可以认为这个样本不是来自该总体,而是来自其他总体;
如果这个样本平均数与总体平均数的差异未达到显著性水平,则要接受零假设,这时就得承认这个样本来自该总体。
?将介绍如何由两个样本平均数之差检验两个相应总体平均数之差的显著
性。如果某两个样本平均数之间的差异达到了一定的限度,即达到了显著性水平,就可以认为这两个样本来自不同的总体,或者说,这两个样本各自所代表的总体之间有真正的差异;如果两个样本平均数之间的差异不显著,则可以认为,这两个样本平均数之间的差异是由抽样误差造成的,它们所来自的总体的平均数相等或就来自同一个总体。
基本原理:与一个样本平均数与总体平均数差异的检验相同。首先对两个相应的总体平均数之间提出没有差异的虚无假设和有差异的备择假设,然后考察虚无假设成立的概率如何。如果概率较小,就拒绝虚无假设,接受备择假设,说明两个总体平均数差异显著;反之,则说明两个总体平均数差异不显著。
三、配对样本的两种情况:(1)用同一测验对同一组被试在试验前后进行两次测验,所获得的两组测验结果是相关样本。(2)根据某些条件基本相同的原则,把被试一一匹配成对,然后将每对被试随机地分入实验组和对照组,对两组被试施行不同的实验处理之后,用同一测验所获得的测验结果,也是相关样本。
配对样本T检验:SPSS13.0操作:Analyze——compare means——paired samples T test 四、什么时候进行配对样本t检验,什么时候进行独立样本T检验
方差分析
●一、方差分析的概念:方差分析是检验多个样本均数间差异是否具有统计意义的一种统计
学方法。
单因素方差分析
一、定义:单因素方差分析测试摸一个控制变得不同水平是否给观察变量造成了显著差异和变动,
例:培训是否给学生造成显著影响
SPSS13.0操作方法:Analyze——compare means——one-way ANOV A factor 自变量 dependent list 因变量(1各自变量,多个因变量)
相关分析
?一、相关的概念
两个变量之间不精确、不稳定的变化关系称为相关关系。它与事物之间普遍存在的另外两种关系即因果关系和共变关系是不同的。
?二、积差相关:
?当两个变量都是正态连续变量,两者之间呈线性关系时,表示这两个变量之间的相关。
?三、点二列相关:
?当两列变量中一个是正态连续变量,而另一个是真正的二分名义变量,表示这两个变量之间
的相关,称为点二列相关
?四、相关系数
?
五、相关系数的取值范围
相关系数的取值范围在?1和+1之间,即?1≤r≤+1。其中:
?若0<r≤1,表明变量之间存在正相关关系,即两个变量的相随变动方向相同;
?若?1≤r<0,表明变量之间存在负相关关系,即两个变量的相随变动方向相反;
六、解释正负值的意义
Z分数
在一次测验中比较学生语文、数学、英语成绩(不同质的一般不能比较)要将数据转换为Z分数,可进行比较
SPSS13.0操作:Analyze——descriptive statistics ——descriptive(选
几个比较对象)同时点击save standardize values as variable ——ok
补充:
一.频数分布表.
一般是从小到大.
二.正态曲线的特点:
1.曲线在z=0处为最高点。
2.曲线以z=0处为中心,双侧对称。
3.曲线以最高点向左右缓慢下降,并无限延伸,但永远不与基线相交。
4.标准正态分布上的平均数为0,标准差为1。基线上z从-3到+3,6个标准
差之间的距离几乎含盖了全部的面积。(99.73%)
5.曲线从最高点向左右延伸时,在正负1个标准差之内,既向下又向内弯;
从正负1个标准差开始,既向下又向外弯。
《教育统计学》超详细知识点及重点笔记
华东师大心理统计学大纲 教材:《教育统计学》 第一章绪论 第一节什么是统计学和心理统计学 一、什么是统计学 统计学是研究统计原理和方法的科学。具体地说,它是研究如何搜集、整理、分析反映事物总体信息的数字资料,并以此为依据,对总体特征进行推断的原理和方法。 统计学分为两大类。一类是数理统计学。它主要是以概率论为基础,对统计数据数量关系的模式加以解释,对统计原理和方法给予数学的证明。它是数学的一个分支。另一类是应用统计学。它是数理统计原理和方法在各个领域中的应用,如数理统计的原理和方法应用到工业领域,称为工业统计学;应用到医学领域,称为医学统计学;应用到心理学领域,称为心理统计学,等等。应用统计学是与研究对象密切结合的各科专门统计学。 二、统计学和心理统计学的内容 统计学和心理统计学的研究内容,从不同角度来分,可以分为不同的类型。从具体应用的角度来分,可以分成描述统计,推断统计和实验设计三部分。 1.描述统计 对已获得的数据进行整理、概括,显示其分布特征的统计方法,称为描述统计。 2.推断统计 根据样本所提供的信息,运用概率的理论进行分析、论证,在一定可靠程度上,对总体分布特征进行估计、推测,这种统计方法称为推断统计。推断统计的内容包括总体参数估计和假设检验两部分。 3.实验设计 实验者为了揭示试验中自变量和因变量的关系,在实验之前所制定的实验计划,称为实验设计。其中包括选择怎样的抽样方式;如何计算样本容量;确定怎样的实验对照形式;如何实现实验组和对照组的等组化;如何安排实验因素和如何控制无关因素;用什么统计方法处理及分析实验结果,等等。 以上三部分内容,不是截然分开,而是相互联系的。 第二节统计学中的几个基本概念 一、随机变量 具有以下三个特性的现象,成为随机变量。第一,一次试验有多中可能结果,其所有可能结果是已知的;第二,试验之前不能预料哪一种结果会出现;第三,在相同的条件下可以重复试验。随机现象的每一种结果叫做一个随机事件。我们把能表示随机现象各种结果的变量称为随机变量。统计处理的变量都是随机变量。 二、总体和样本 总体是我们所研究的具有共同特性的个体的总和。总体中的每个单位成为个体。样本是从总体中抽取的作为观察对象的一部分个体。当总体所包含的个数有限时,这一总体称为有限总体。而总体所包含的个数无限时,则称为无限总体。样本中包含的个体数目称为样本的容量,一般用n来表示。一般来说,样本中个体数目大于30称为大样本,等于或小于30称为小样本。在对数据进行处理时,大样本和小样本所用的统计方法不一定相同。 三、统计量和参数
现代心理与教育统计学第07章习题解答
1. 何谓点估计与区间估计,它们各有哪些优缺点? 点估计就是总体参数不清楚时,用一个特定的值,即样本统计量对总体参数进行估计,但估计的参数为数轴上某一点。 区间估计是用数轴上的一段距离来表示未知参数可能落入的范围,它不具体指出总体参数是多少,能指出总体未知参数落入某一区间的概率有多大。 点估计的优点是能够提供总体参数的估计值,缺点是点估计总以误差的存在为前提,且不能提供正确估计的概率。 区间估计的优点是用概率说明估计结果的把握程度,缺点是不能确定一个具体的估计值。 2以方差的区间估计为例说明区间估计的原理 根据χ2分布: 总体方差的.95或.99置信区间为: 即总体参数(方差)落入上述区间的概率为1-α,其值为95%或99% 3.总体平均数估计的具体方法有哪些? 总体方法为点估计好区间估计,区间估计又分为: (1) 当总体分布正态方差已知时,样本平均的分布为正态分布,故依据正态分布理论估计其区间;(2)当总体分布正态方差未知时,样本平均数的分布为T 分布,依据T 分布理论估计其区间;(3)当总体非分布正态方差未知时,只有在n 大于30时渐近T 分布,样本平均数的分布渐近T 分布,依据T 分布理论估计其区间。 4总体相关系数的置信区间,应根据何种分布计算? 应根据Fisher 的Z 分布进行计算 5.解 依据样本分布理论该样本平均数的分布呈正态 其标准误为: 其置信区间为: 该科成绩的真实分数有95%的可能性在78.55----83.45之间。 6.解:此题属于总体分布正态总体方差未知的情形,故样本平均数的分布呈T 分布 其标准误为: 用df=99差T 值表,然后用直线内插法求得t α/2=1.987 其置信区间为: 该学区教学成绩的平均值有95%的可能在78.61---81.39之间。 7解:此题属于总体分布正态总体方差已知 计算标准误 ()()222212221σσσχnS S n X X n =-=-=-∑()()22/121222/2111)(ααχσχ----<<-n n S n S n 25.116 5===n x σσ45 .8355.7825.1*96.18125.1*96.1812/2/<<+<<-?+<
【精品】2019年大学专业课程★★教育统计学考试试题
【精品】2019年大学专业课程★★ 1.(方差已知区间估计) 某中学二年级语文同一试卷测验分数历年来的标准差为10.6,现从今年测验中随机抽取10份考卷,算得平均分为72,求该校此次测验平均成绩的95%置信区间。 解 72,10.610,10.95X n σα===-= [] 112 2 :72 1.96 1.9665.43,78.57x x α αμμ μ - - ? ?? -+=-?+????= 2(方差未知区间估计). 已知某校高二10名学生的物理测验分数为92、94、96、66、84、71、45、98、94、67,试求全年级平均分数的95%置信区间。 92949666847145989467 80.710 x +++++++++= = ()()1010222 21111310.999i i i i S x x x n x ==?? =-=-= ??? ∑∑ 17.632S = ( ( [] 112 2:1180.7 2.2622 2.262268.09,93.31x t n x t n ααμ--? ? --+-?? ?=-?+??= 3. 3.(方差未知单样本t 检验) 某区中学计算机测验平均分数为70.3,该区甲校15名学生此次测验平均分数为67.2,标 准差为11.4,问甲校此次测验成绩与全区是否有显著性差异? 01:70.3:70.3H H μμ=≠ 1.053x t = ==- ()()()0.97512 1114 2.1448t n t n α- -=-= 由于()0.9751.05314 2.1448t t =<=,接受0H ,甲校此次测验成绩与全区无显著性差异. 4(方差已知的单样本均值检验).某区某年高考化学平均分数为72.4,标准差为12.6,该区实验学校28名学生此次考试平均分数为74.7,问实验学校此次考试成绩是否高于全区平均水平? 01:72.4:72.4H H μμ=> 0.966x t == =
心理和教育统计学课后题答案解析
张厚粲现代心理与教育统计学第一章答案 1名词概念 (1 )随机变量 答:在统计学上把取值之前,不能准确预料取到什么值的变量,称为随机变量。 (2)总体 答:总体(population )又称为母全体或全域,是具有某种特征的一类事物的总体,是研究对象的全体。 (3)样本 答:样本是从总体中抽取的一部分个体。 (4)个体 答:构成总体的每个基本单元。 (5)次数 是指某一事件在某一类别中出现的数目,又称作频数,用f表示。 (6)频率 答:又称相对次数,即某一事件发生的次数除以总的事件数目,通常用比例或百分数来表示。 (7)概率 答:概率(probability), 概率论术语,指随机事件发生的可能性大小度量指标。其描述性定义。随机事件A在所有试验中发生的可能性大小的量值,称为事件A的概率,记为P(A)。 (8)统计量 答:样本的特征值叫做统计量,又称作特征值。 (9)参数 答:又称总体参数,是描述一个总体情况的统计指标。 (10)观测值 答:随机变量的取值,一个随机变量可以有多个观测值。 2何谓心理与教育统计学?学习它有何意义? 答:(1)心理与教育统计学是专门研究如何运用统计学原理和方法,搜集、整理、分析心理 与教育科学研究中获得的随机性数据资料,并根据这些数据资料传递的信息,进行科学推论 找出心理与教育统计活动规律的一门学科。具体讲,就是在心理与教育研究中,通过调查、实验、测量等手段有意地获取一些数据,并将得到的数据按统计学原理和步骤加以整理、计 算、绘制图表、分析、判断、推理,最后得出结论的一种研究方法。 (2)学习心理与教育统计学有重要的意义。 ①统计学为科学研究提供了一种科学方法。 科学是一种知识体系。它的研究对象存在于现实世界各个领域的客观事实之中。它的主 要任务是对客观事实进行预测和分类,从而揭示蕴藏于其中的种种因果关系。要提高对客观 事实观测及分析研究的能力,就必须运用科学的方法。统计学正是提供了这样一种科学方法。统计方法是从事科学研究的一种必不可少的工具。 ②心理与教育统计学是心理与教育科研定量分析的重要工具。 凡是客观存在事物,都有数量的表现。凡是有数量表现的事物,都可以进行测量。心理 与教育现象是一种客观存在的事物,它也有数量的表现。虽然心理与教育测量具有多变性而 且旨起它发生变化的因素很多,难以准确测量。但是它毕竟还是可以测量的。因此,在进行 心理与教育科学研究时,在一定条件下,是可以对心理与教育现象进行定量分析的。心理与 教育统计就是对心理与教育问题进行定量分析的重要的科学工具。 ③广大心理与教育工作者学习心理与教育统计学的具体意义。 a. 可经顺利阅读国内外先进的研究成果。 b. 可以提高心理与教育工作的科学性和效率。
东师教育统计学18春在线作业1
(单选题) 1: 要检验多组计数数据间的差异,适宜的统计检验方法是: A: t检验 B: Z检验 C: 秩和检验 D: 卡方检验 正确答案: (单选题) 2: 某学校3位领导对本校的10名教师进行评定,为考察这三位领导对这10位教师的评定意见是否一致,应采用: A: 斯皮尔曼等级相关 B: 积差相关 C: 肯德尔和谐系数 D: - 正确答案: (单选题) 3: A: - B: - C: - D: - 正确答案: (单选题) 4: A: - B: - C: - D: - 正确答案: (单选题) 5: A: - B: - C: - D: - 正确答案: (单选题) 6: A: - B: - C: - D: - 正确答案: (单选题) 7: 下列统计图,可表示离散变量数量关系的是: A: 直条图 B: 线形图 C: 多边图 D: 直方图 正确答案: (单选题) 8: A: - B: - C: - D: - 正确答案: (单选题) 9: A: - B: - C: -
D: - 正确答案: (单选题) 10: 某县组织六名督学对该县的七所中学进行督导评估,想考察这六名督学评估结果的一致性,则采用: A: 积差相关 B: 斯皮尔曼等级相关 C: 肯德尔和谐系数 D: 点二列相关 正确答案: (单选题) 11: 进行方差分析时,对所用数据的非必备条件是: A: 组内平均数相等 B: 总体呈正态分布 C: 变异可加 D: 各组方差齐性 正确答案: (单选题) 12: A: - B: - C: - D: - 正确答案: (单选题) 13: 某班学生身高和体重的平均数分别为152厘米和43.8千克,标准差分别为20.5厘米和7.8千克,该班学生的身高和体重哪个离散程度大一些? A: 体重 B: 身高 C: 一样 D: 无法比较 正确答案: (单选题) 14: 数据3、7、2、6、8、9、4的中位数是 A: 7 B: 5 C: 4 D: 6 正确答案: (单选题) 15: A: - B: - C: - D: - 正确答案: (多选题) 1: 下列现象中,存在相关关系的是: A: 学生的学习成绩与其家庭环境之间 B: 学生的学习成绩与其体重之间 C: 学生的学习成绩与教师的教学方法 D: 学生的学习成绩与教师的教学态度之间 E: 学生的学习成绩与其努力程度之间 正确答案: (多选题) 2: A: - B: - C: - D: - E: -
现代心理与教育统计学的复习资料
第一章心理与教育统计学基础知识 1、数据类型 称名数据 计数数据离散型数据 顺序数据 等距数据 测量数据连续型数据 比率数据 2、变量、随机变量、观测值 变量是可以取不同值的量。统计观察的指标都是具有变异的指标。当我们用一个量表示这个指标的观察结果时,这个指标是一个变量。 用来表示随机现象的变量,称为随机变量。一般用大写的X或Y表示随机变量。 随机变量所取得的值,称为观测值。一个随机变量可以有许多个观测值。 3、总体、个体和样本 需要研究的同质对象的全体,称为总体。 每一个具体研究对象,称为一个个体。 从总体中抽出的用以推测总体的部分对象的集合称为样本。 样本中包含的个体数,称为样本的容量n。 一般把容量n ≥30的样本称为大样本;而n <30的样本称为小样本。 4、统计量和参数
5、统计误差 误差是测得值与真值之间的差值。 测得值=真值+误差 统计误差归纳起来可分为两类:测量误差与抽样误差。 由于使用的仪器、测量方法、读数方法等问题造成的测得值与真值之间的误差,称为测量误差。 由于随机抽样造成的样本统计量与总体参数间的差别,称为抽样误差 第二章统计图表 一、数据的整理 在进行整理时,如果没有充足的理由证明某数据是由实验中的过失造成的,就不能轻易将其排除。对于个别极端数据是否该剔除,应遵循三个标准差法则。 二、次数分布表 (一)简单次(频)数分布表 (二)相对次数分布表
将次数分布表中各组的实际次数转化为相对次数,即用频数比率(f /N )或百分比( )来表示次数,就可以制成相对次数分布表 (三)累加次数分布表 (四)双列次数分布表 双列次数分布表又称相关次数分布表,是对有联系的两列变量用同一个表表示其次数分布。 所谓有联系的两列变量,一般是指同一组被试中每个被试两种心理能力的分数或两种心理特点的指标,或同一组被试在两种实验条件下获得的结果。 三、次数分布图 使一组数据特征更加直观和概括,而且还可以对数据的分布情况和变动趋势作粗略的分析。 简单次(频)数分布图——直方图、次数多边形图 累加次数分布图——累加直方图、累加曲线 (一)简单次数分布图--直方图 (二)简单次数分布图-次数多边图 次数分布多边形图(frequency polygon )是一种表示连续性随机变量次数分布的线形图,属于次数分布图。凡是等距分组的可以用直方图表示的数据,都可用次数多边图来表示。 绘制方法:以各分组区间的组中值为横坐标,以各组的频数为纵坐标,描点;将各点以直线连接即构成多边图形。 (三)累加次数分布图—累加直方图 (四)累加次数分布图——累加曲线 %100 N f
广东省2011年07月高等教育自学考试 00974《统计学原理》试题及答案
2011年7月高等教育自学考试 统计学原理试卷 (课程代码00974) 一、单项选择题(本大题共15小题,每小题1分,共15分)在每小题列出的四个备选项中只有一个是符合题目要求的,请将其代码填写在题后的括号内。错选、多选或未选均无分。 1.统计的基本方法包括 A.调查法、汇总发、预测法B.调查法、整理法、分析法 C.大量观观察法、综合分析法、归纳推断法D.时间数列法、统计指数法、回归分析法 2.对统计数据建立某种物理的度量单位的亮度层次是 A.定类尺度B.定序尺度 C.定距尺度D.定比尺度 3.调查单位是 A.调查对象的全部单位B.负责向上报告调查内容的单位 C.调查项目和指标的承担者D.基层企事业单位 4.对连续变量分组,最大值所在组下限为1000,又知其相邻组的组中值为750,则最大值所在组的组中值为 A.1100 B.1200 C.1250 D.1500 5.某商场2006年彩电销量为10000台,年末库存100台,这两个绝对指标是 A.时期指标B.时点指标 C.前者是时点指标,后者是时期指标D.前者是时期指标,后者是时点指标 6.下列属于比较相对指标的是 A.我国人口密度为135人/平方公里B.某年我国钢产量为日本的80% C.2006年我国GDP比上年增长9% D.2006你我国城镇职工平均工资为12000元 7.在抽样调查中,抽取样本单位必须遵循 A.可比性原则B.同质性原则 C.准确性原则D.随机性原则 8.样本容量与抽样误差的关系是 A.样本容量越大,抽样误差越大B.样本容量越大,抽样误差越小 C.样本容量越小,抽样误差越小D.两者没有关系 9.对500名大学生抽取15%的比例进行不重置抽样调查,其中优等生为20%,概率为95.45%(t=2),则优等生比重的抽样极限误差为 A.4.26% B.4.61% C.8.52% D.9.32% 10.当一个变量变化幅度与另一个变量的变化幅度基本上是同等比例时,这表明两个变量之间存在着 A.函数关系B.复相关关系 C.线性相关关系D.非线性相关关系
教育统计学复习题及答案
《教育统计学》复习题及答案一、填空题 1.教育统计学的研究对象是.教育问题。 2.一般情况下,大样本是指样本容量.大于30 的样本。 3.标志是说明总体单位的名称,它有.品质标志和数量标志两种。 4.统计工作的三个基本步骤是:、和。 5.集中量数是反映一组数据的趋势的。 6.“65、66、72、83、89”这组数据的算术平均数是。 7.6位学生的身高分别为:145、135、128、145、140、130厘米,他们的众数是。 8.若某班学生数学成绩的标准差是8分,平均分是80分,其标准差系数是。 9.参数估计的方法有和两种。 10.若两个变量之间的相关系数是负数,则它们之间存在。 11.统计工作与统计资料的关系是和的关系。 12.标准差越大,说明总体平均数的代表性越,标准差越小,说明总体平均数的代表性越。 13.总量指标按其反映的内容不同可以分为和。 二、判断题 1、教育统计学属于应用统计学。()
2、标志是说明总体特征的,指标是说明总体单位特征的。() 3、统计数据的真实性是统计工作的生命() 4、汉族是一个品质标志。() 5、描述一组数据波动情况的量数称为差异量数。() 6、集中量数反映的是一组数据的集中趋势。() 7、在一个总体中,算术平均数、众数、中位数可能相等。() 8、同一总体各组的结构相对指标数值之和不一定等于100%。() 9、不重复抽样误差一定大于重复抽样误差。() 10. 一致性是用样本统计量估计统计参数时最基本的要求。() 三、选择题 1.某班学生的平均年龄为22岁,这里的22岁为( )。 A.指标值 B.标志值 C.变量值 D.数量标志值 2.统计调查中,调查标志的承担者是( )。 A.调查对象 B.调查单位 C.填报单位 D.调查表 3.统计分组的关键是( )。 A.确定组数和组距 B.抓住事物本质 C.选择分组标志和划分各组界限 D.统计表的形式设计 4.下列属于全面调查的有( )。 A.重点调查 B.典型调查 C.抽样调查 D.普查 5.统计抽样调查中,样本的取得遵循的原则是( )。 A.可靠性 B.准确性 C.及时性 D.随机性 6. 在直线回归方程Yc =a+bx中,b表示( )。 增加1个单位,y增加a的数量增加1个单位,x增加b的数量 增加1个单位,x的平均增加量增加1个单位,y的平均增加量 7.下列统计指标中,属于数量指标的有() A、工资总额 B、单位产品成本 C、合格品率 D、人口密度 8.在其他条件不变情况下,重复抽样的抽样极限误差增加1倍,则样本单位数变为( )。 A.原来的2倍 B.原来的4倍 C.原来的1/2倍 D.原来的1/4倍 四、简答题 1.学习教育统计学有哪些意义?
教育统计学大纲
高纲1428 江苏省高等教育自学考试大纲 28063 教育统计学 南京师范大学编江苏省高等教育自学考试委员会办公室
Ⅰ课程的性质与设置目的 《教育统计学》是研究如何整理、分析在包括教育实验、教育调查等教育研究中所获取的数字资料,并且根据样本观察推断未知总体状况,进而把握教育发展客观规律的一门学科。教育统计学是一门应用统计学,统计学方法是教育科学研究的重要工具。《教育统计学》是高等师范院校教育专业的核心专业课程,也是江苏省高等教育自学考试小学教育专业本科段的必考科目之一。 学习《教育统计学》,首先是教育科学研究的需要。作为科研型的小学教育工作者,需要经常阅读国内外的教育研究报告和文献资料,而在这些报告或文献中,许多都是采用统计学方法来表述或解释其研究成果的。此外,我们自己的调查、实验等教育科学研究的成果也需要用统计学的方法来概括和说明。不仅如此,其实一项好的教育调查、教育实验从研究设计开始,就离不开统计学方法的支持。总之,缺乏教育统计学的知识和应用能力,不仅妨碍我们的学术交流,也严重地影响教育研究科学水平的提高。 学习《教育统计学》,同时也是科学训练的需要。统计学所运用的由个别到一般、由局部到总体的推理和思考问题的方法,是科学研究中常用的基本方法。因此通过教育统计学的学习,不仅可以掌握一些处理教育科学研究资料的技术手段,而且有助于我们科研意识的养成、科学思维的锻炼。 Ⅱ课程内容与考核目标 (考核知识点、考核要求) 第一章教育统计学的基本思想与内容 【学习目的和要求】 通过本章内容的学习,应该了解三对六种思维方式,即经验主义与理性主义的思维方式、归纳主义与演绎主义的思维方式、从局部到整体与从整体到部分的思维方式,以及教育统计学的思维方式;掌握总体、个体与样本,以及总体参数与样本统计量等基本概念;掌握样本的容量、样本的选取、抽样的类型以及常用的抽样方法;了解教育统计学的基本思想。 【学习内容】 第一节教育统计学的思维方式 一、思维方式及其基本类型 二、教育统计学的思维方式 第二节教育统计学的基本术语与符号 一、总体、样本与个体 二、总体参数与样本统计量 三、抽样方法简介 第三节教育统计学的基本思想 第四节教育统计学的基本内容 【考核知识点】 1.经验主义与理性主义
教育统计学考试复习资料
第一章:1、何谓心理与教育统计学?学习它有何意义? 教育统计学是专门研究如何运用统计学原理和方法,搜集、整理、分析教育科学研究中获得的随机性数据资料,并根据这些数据资料所传递的信息,进行科学推论找出教育活动规律的一门科学。具体讲,就是在教育研究中,通过调查、实验、测量等手段有意获取一些数据,并将得到的数据按统计学原理和步骤加以整理、计算、绘制图表、分析、判断、推理,最后得出结论的一种研究方法。 意义:(1)统计学为科学研究提供了一种科学方法。(2)教育统计学是教育科学研究定量分析的重要重要工具。 (3)广大教育工作者学习教育统计学既可以顺利地阅读国内外先进的研究成果,又可以提高工作的科学性和效率,同时也为学习教育测量打下基础。 2、教育科学研究数据的特点 (1)教育科学研究数据与结果多用数字形式呈现;(2)教育科学研究数据具有随机性和变异性;(3)教育科学研究数据具有规律性;(4)教育科学研究的目的是通过部分数据来推测总体特征。总之,在教育科学实验或调查中,所获得的数据都具有变异性与规律性的特点。 3、思考题:选用统计方法有哪几个步骤? ①要分析一下实验设计是否合理,即所获得的数据是否适合用统计方法去处理,正确的数量化是应用统计方 法的起步,如果对数量化的过程及其意义没有了解,将一些不着边际的数据加以统计处理是毫无意义的。②要分析实验数据的类型。不同数据类型所使用的统计方法有很大差别,了解实验数据的类型和水平,对选用恰当的统计方法至关重要。③要分析数据的分布规律,如总体方差的情况,确定其是否满足所选用的统计方法的前提条件。 4、教育统计学的分类 (1)依研究的问题实质来划分,教育统计学的研究内容可划分为描述一件事物的性质、比较两件事物之间的差异、分析影响事物变化的因素、一件事物两种不同属性之间的相互关系、取样方法等等。(2)依统计方法的功能进行分类,教育统计学的研究内容可分为描述统计、推论统计和实验设计。 5、描述统计:主要研究如何整理科学实验或调查得来的大量数据,描述一组数据的全貌,表达一件事物的性 质。 具体内容包括:(1)数据如何分组,如何使用各种统计图表描述一组数据的分布情况;(2)怎样计算一组数据的特征值,简缩数据,进一步描述一组数据的全貌;(3)表示一事物两种或两种以上属性间相互关系的描述及各种相关系数的计算及应用条件,描述数据分布特征的峰度及偏度系数计算方法等。 6、推论统计:主要研究如何通过局部数据所提供的信息,推论总体(或称全局)的情形。 具体内容包括:(1)如何对假设进行检验,即各种各样的假设检验,包括大样本检验方法(z检验),小样本检验方法(t检验),各种计数资料的假设检验的方法(百分数检验、χ2检验等),变异数分析的方法(F检验),回归分析方法等等。(2)总体参数的估计方法。(3)各种非参数的统计方法等。 7、思考题:描述统计、推论统计和实验设计这三部分统计内容有何关系? 教育统计学的三个组成部分的内容不是截然分开的,而是相互联系的。描述统计是推论统计的基础,推论统计离不开描述统计计算所获得的特征值;描述统计只是对数据进行一般的分析归纳,如果不进一步应用推论统计作进一步的分析,描述统计的结果就不会产生更大的价值和意义,达不到统计分析的最终目的要求。同样,只有良好的实验设计才能使所获得的数据具有意义,进一步的统计处理才能说明问题。当然一个好的实验设计,也必须符合基本的统计方法的要求,否则,再好的设计,如果事先没有确定适当的统计方法处理,在处理研究结果时可能会遇到许多麻烦问题。 8、教育统计与心理统计的异同 相同之处:二者的研究对象都是人,教育现象在很多情况下要通过人的心理现象去观察和分析,统计方法基本相同。不同之处:①在统计方法上:在教育方面的研究中,大样本的统计方法应用较多;而在心理学上小样本的方法较多。②在实验设计的水平上:教育实验中控制因素较难,采用自然实验、准实验设计方式较多,对统计结果的解释需要特别谨慎;而心理学实验则在实验室条件下进行较多,对各种实验变量的控制相对容易,统计处理结果的解释也较易进行。 9、数据的类型 (一)从数据的观测方法和来源划分,研究数据可区分为计数数据和测量数据两大类。 计数数据是指计算个数的数据,一般属性的调查获得的是此类数据,它具有独立的分类单位,一般都取整数的形式。测量数据是借助于一定的测量工具或一定的测量标准而获得的数据。 (二)根据数据反映的测量水平,可把数据区分为称名数据、顺序数据、等距数据和比率数据四种类型。
教育统计学课后练习参考答案
教育统计学课后练习参考答案 第一章 1、教育统计学,就是应用数理统计学的一般原理和方法,对教育调查和教育实验等途径所获得的数据资料进行整理、分析,并以此为依据,进行科学推断,从而揭示蕴含在教育现象中的客观规律的一门科学。 教育统计学既是统计科学中的一个分支学科,又是教育科学中的一个分支学科,是两种科学相互结合、相互渗透而形成的一门交叉学科。从学科体系来看,教育统计学属于教育科学体系的一个方法论分支;从学科性质来看,教育统计学又属于统计学的一个应用分支。 2、描述统计主要是通过对数据资料进行整理,计算出简单明白的统计量数来描述庞大的资料,以显示其分布特征的统计方法。 推断统计又叫分析统计,它根据统计学的原理和方法,从我们所研究的全体对象(即总体)中,按照等可能性原则采取随机抽样的方法,抽出总体中具有代表性的部分个体组成样本,在样本所提供的数据的基础上,运用概率理论进行分析、论证,在一定可靠程度上对总体的情况进行科学推断的一种统计方法。 3、在自然界或教育研究中,一种事物常存在几种可能出现的情况或获得几种可能的结果,这类现象称为随机现象。 随机现象具的特点: (1)一次条件完全相同的实验有多种可能的结果(这样的实验称为随机实验); (2)在实验之前不能确切知道哪种结果会发生; (3)在相同的条件下可以重复进行这样的实验。 4、总体,也叫做母体或全域,是指具有某种共同特征的个体的总和。 当所研究的总体数量非常大时,可以从总体中抽取其中一部分个体来观测,由此来推断总体的信息,从总体中抽出的这部分个体就称为样本,它是用以表征总体的个体的集合。 通常将样本中样本个数大于或等于30个的样本称为大样本,小于30个的称为小样本。 5、复置抽样指每次抽出的个体经观测后,仍放回原总体,然后再从总体中抽取下一个个体。 6、反映总体特征的量数叫做总体参数,简称参数。反映样本特征的量数叫做样本统计量,简称统计量。 参数是总体的真正数值,是固定的常量,理论上应该通过计算总体中全部个体的数值而获得,但由于总体中个体的数量通常很大,总体参数往往很难获得,在统计分析中一般通过样本的数值来估计。在进行推断统计时,就是根据样本统计量来推断总体相应的参数。 第二章 1、按照数据的来源,可分为计数数据和度量数据;按照数据的取值情况,可分为间断性数据和连续性数据;按照数据的测量水平,可分为称名数据、顺序数据、等距数据和比率数据。 2、数据整理的基本方法包括对数据进行排序、统计分组、绘制统计图表等。 3、表的结构要简洁明了;表的层次要清晰;主谓分明。 4、连续性数据:(2),(3);间断性数据:(1),(4)。 5、略 6、(1)50;(2)75;(3)34;(4)5;(5)45
教育统计学的内容主要包括
教育统计学的内容主要包括
1、教育统计学的内容主要包括:描述统计与推断统计 2、测量结果能在其上取定数值的量尺,从量化水平高低的角度可分为:名义量尺、顺序量尺、等距量尺与比率量尺。在名义量尺上所指定的数字,只具有类别标志的意义,而无性质优劣,分量多寡的意义。顺序量尺上的数字量化水平则较高,有优劣、大小、先后之别,如学业成绩评定优劣。等距量尺上的数字量化水平又更高,这种数字是单位相等但零点可任意指定的线性连续体系上的值,如温度、可比可加。比率量尺是一种有绝对零点的,等单位的线性连续体系。如身高、体重等。能加、减、乘、除 3、测量工作按一定的规则进行,体现为三种东西即:测量工具、施测和评分的程序与要求、结果解释参照系或参照物 4、心理测量跟物理测量的两点突出差异:一间接性;二要抽样进行 5、数据的种类①从数据来源分成计数数据、测量评估数据和人工编码数据②根据数据所反映的变量的性质分分为称名变量数据、顺序变量数据、等距变量和比率变量数据 6、顺序变量数据之间虽有次序与等级关系,但不具有相等单位,也不具有绝对的数量大小和零点。因此只能进行顺序递推运算,不能做加减乘除运算。等距变量不能用乘、除法运算来反映两个数据之间的倍比关系,能做加减运算。比率变量数据可以进行加、减、乘、除运算 7、数据三个特点①数据的离散性②数据的变异性③数据的规律性 8、统计一批数据的次数分布两种方法:一、按不同的测量值逐点统计次数;二、为了简缩数据以区间跨度来统计次数。如分数段统计 9、编制简单次数分布步骤①求全距②定组数③定组距④写组限⑤求组中值⑥归类划记⑦登记次数 10、相对次数分布表主要能反映各组数据的百分比结构 11、累积次数分布表还分成“以下”累积次数分布表与“以上”累积次数分布表两种。“以下”累积其目的在于反映位于某个分数“以下”的累积次数共有多少
现代心理与教育统计学答案
第一章 1名词概念 (1)随机变量 答:在统计学上把取值之前,不能准确预料取到什么值的变量,称为随机变量。(2)总体 答:总体(population)又称为母全体或全域,是具有某种特征的一类事物的总体,是研究对象的全体。 (3)样本 答:样本是从总体中抽取的一部分个体。 (4)个体 答:构成总体的每个基本单元。 (5)次数 是指某一事件在某一类别中出现的数目,又称作频数,用f表示。 (6)频率 答:又称相对次数,即某一事件发生的次数除以总的事件数目,通常用比例或百分数来表示。 (7)概率 答:概率(probability),概率论术语,指随机事件发生的可能性大小度量指标。其描述性定义。随机事件A在所有试验中发生的可能性大小的量值,称为事件A 的概率,记为P(A)。 (8)统计量 答:样本的特征值叫做统计量,又称作特征值。 (9)参数 答:又称总体参数,是描述一个总体情况的统计指标。 (10)观测值 答:随机变量的取值,一个随机变量可以有多个观测值。 2何谓心理与教育统计学?学习它有何意义? 答:(1)心理与教育统计学是专门研究如何运用统计学原理和方法,搜集、整理、分析心理与教育科学研究中获得的随机性数据资料,并根据这些数据资料传递的信息,进行科学推论找出心理与教育统计活动规律的一门学科。具体讲,就是在心理与教育研究中,通过调查、实验、测量等手段有意地获取一些数据,并将得到的数据按统计学原理和步骤加以整理、计算、绘制图表、分析、判断、推理,最后得出结论的一种研究方法。 (2)学习心理与教育统计学有重要的意义。 ①统计学为科学研究提供了一种科学方法。 科学是一种知识体系。它的研究对象存在于现实世界各个领域的客观事实之中。它的主要任务是对客观事实进行预测和分类,从而揭示蕴藏于其中的种种因果关系。要提高对客观事实观测及分析研究的能力,就必须运用科学的方法。
教育统计学试题库
教育统计学 一、选择题 1、当一组数据用中位数来反映集中趋势时,这组数据最好用哪种统计量来表示离散程度?( B ) A. 全距( 差异量) B. 四分位距(差异量) C. 方差(差异量) D. 标准差(差异量) 2、总体不呈正态分布,从该总体中随机抽取容量为1000 的一切可能样本的平均数的分布接近于:( D ) A. 二项分布 B.F 分布 C. t 分布 D. 正态分布 3、检验某个频数分布是否服从正态分布时需采用:( C ) A. Z检验 B. t 检验 C. X 2检验 D. F 检验 4、对两组平均数进行差异的显著性检验时,在下面哪种情况下不需要进行方差齐性检验?( B ) A. 两个独立样本的容量相等且小于30; B. 两个独立样本的容量相等且大于30; C. 两个独立样本的容量不等,n1小于30, n2大于30; D. 两个独立样本的容量不等,n1大于30, n2小于30。 5、下列说法中哪一个是正确的?( C ) A. 若r1=0.40 , r2=0.20,那么r1 就是r2 的2 倍;
B. 如果r=0.80 ,那么就表明两个变量之间的关联程度达到80%; C. 相关系数不可能是2; D. 相关系数不可能是-1 。 6、当两列变量均为二分变量时,应计算哪一种相关?( B ) A. 积差相关(两个连续型变量) B. ?相关 C. 点二列相关(一个是连续型变量,另一个是真正的二分名义变量) D. 二列相关(两个连续型变量,其中之一被人为地划分成二分变量。) 7、对多组平均数的差异进行显著性检验时需计算:( A ) A.F值 B. t 值 C. x 2 值 D.Z 值 8、比较不同单位资料的差异程度,可以采用何种差异量?( A ) A. 差异系数 B. 方差 C. 全距 D. 标准差 二、名词解释 1. 分层抽样:按与研究内容有关的因素或指标先将总体划分成几个部分,然后从各部分(即各层)中进行单纯随机抽样或机械抽样,这种抽样方法称为分层抽样。 2. 描述统计:对已获得的数据进行整理、概括,显现其分布特征的统计方法称为描述统计。 3. 集中量:集中量是代表一组数据典型水平或集中趋势的量。它能反映频数分
2017年秋教育统计学答案(20200627082742)
综合作业20170802 1. (单选题)从含有N 个元素的总体中抽取n 个元素作为样 本,使得总体中的每一个元素都有相同的机会(概率)被抽中, 这样的抽样方式称为( )(本题6.0分) 简单随机抽样 整群抽样 系统抽样(等距抽样) 分层抽样(类型抽样) 学生答案:A 标准答案:A 解析: 得分:6 2. (单选题)从含有N 个元素的总体中抽取n 个元素作为样 本,使得总体中的每一个样本量为 n 的样本都有相同的机会(概 率)被抽中,这样的抽样方式称为( )(本题6.0分) A 、简单随机抽样 3 B 、整群抽样 B c 、系统抽样(等距抽样) D 、分层抽样(类型抽样) B 、
学生答案:A 标准答案:D 解析: 得分:0 3. (单选题)从总体中抽取一个元素后,把这个元素放回到总 体中再抽取第二个元素,直至抽取n 个元素为止,这样的抽样方 法称为()(本题6.0分) 重复抽样 不重复抽样 整群抽样 分层抽样(类型抽样) 学生答案:A 标准答案:A 解析: 得分:6 4. (单选题)一个元素被抽中后不再放回总体, 然后再从所剩 下的元素中抽取第二个元素, 直至抽取n 个元素为止,这样的抽 样方法称为()(本题6.0分) B 、
3 A 、重复抽样 3 B 、不重复抽样 3 c 、整群抽样 d D 、 分层抽样(类型抽样) 学生答案:B 标准答案:B 解析: 得分:6 5. (单选题)在抽样之前先将总体的元素划分为若干类,然后 为()(本题 6.0分) 简单随机抽样 整群抽样 系统抽样(等距抽样) 分层抽样(类型抽样) 学生答案:D 标准答案:D 解析: 得分:6 从各类中抽取一定数量的元素组成一个样本, 这样的抽样方式称 B 、
现代心理与教育统计学复习资料
现代心理与教育统计学 复习资料 Revised as of 23 November 2020
1、数据类型 称名数据 计数数据离散型数据 顺序数据 等距数据 测量数据连续型数据 等比数据 2、变量:是可以取不同值的量。统计观察的指标都是具有变异的指标。当我们用一个量表示这个指标的观察结果时,这个指标是一个变量。 用来表示随机现象的变量,称为随机变量。一般用大写的X或Y表示随机变量。 随机变量所取得的值,称为观测值。一个随机变量可以有许多个观测值。 3、需要研究的同质对象的全体,称为总体。 每一个具体研究对象,称为一个个体。 从总体中抽出的用以推测总体的部分对象的集合称为样本。 样本中包含的个体数,称为样本的容量n。 一般把容量n ≥30的样本称为大样本;而n <30的样本称为小样本。 4、统计量和参数 5、统计误差 误差是测得值与真值之间的差值。
统计误差归纳起来可分为两类:测量误差与抽样误差。 由于使用的仪器、测量方法、读数方法等问题造成的测得值与真值之间的误差,称为测量误差。 由于随机抽样造成的样本统计量与总体参数间的差别,称为抽样误差 第二章 一、数据的整理 在进行整理时,如果没有充足的理由证明某数据是由实验中的过失造成的,就不能轻易将其排除。对于个别极端数据是否该剔除,应遵循三个标准差法则。 二、 次数分布表 (一)简单次(频)数分布表 (二)相对次数分布表 将次数分布表中各组的实际次数转化为相对次数,即用频数比率(f /N )或百分比( )来表示次数,就可以制成相对次数分布表 (三)累加次数分布表 (四)双列次数分布表 双列次数分布表又称相关次数分布表,是对有联系的两列变量用同一个表表示其次数分布。 所谓有联系的两列变量,一般是指同一组被试中每个被试两种心理能力的分数或两种心理特点的指标,或同一组被试在两种实验条件下获得的结果。 三、次数分布图 使一组数据特征更加直观和概括,而且还可以对数据的分布情况和变动趋势作粗略的分析。 简单次(频)数分布图——直方图、次数多边形图 累加次数分布图——累加直方图、累加曲线 (一)简单次数分布图--直方图 (二)简单次数分布图-次数多边图 %100 N f
教育统计学考试试题
1.(方差已知区间估计) 某中学二年级语文同一试卷测验分数历年来的标准差为10.6,现从今年测验中随机抽取10份考卷,算得平均分为72,求该校此次测验平均成绩的95%置信区间。 解 72,10.610,10.95X n σα===-= [] 112 2 :72 1.96 1.9665.43,78.57x x α αμμ μ - - ? ? ?-+=-?+????= 2(方差未知区间估计). 已知某校高二10名学生的物理测验分数为92、94、96、66、84、71、45、98、94、67,试求全年级平均分数的95%置信区间。 92949666847145989467 80.710 x +++++++++= = ()()1010222 21111310.999i i i i S x x x n x ==?? =-=-= ??? ∑∑ 17.632S = ( ( [] 112 2:1180.7 2.2622 2.262268.09,93.31x t n x t n ααμ- -? ? --+-?? ?=-?+??= 3. 3.(方差未知单样本t 检验) 某区中学计算机测验平均分数为70.3,该区甲校15名学生此次测验平均分数为67.2,标 准差为11.4,问甲校此次测验成绩与全区是否有显著性差异? 01:70.3 :70.3H H μμ=≠ 1.053t = ==- ()()()0.97512 1114 2.1448t n t n α- -=-= 由于()0.9751.05314 2.1448t t =<=,接受0H ,甲校此次测验成绩与全区无显著性差异. 4(方差已知的单样本均值检验).某区某年高考化学平均分数为72.4,标准差为12.6,该区实验学校28名学生此次考试平均分数为74.7,问实验学校此次考试成绩是否高于全区平均水平? 01:72.4 :72.4H H μμ=> 0.966x t == = ()()10.95127 1.7033t n t α--==???
教育统计学答案
(0282)《教育统计学》复习思考题答案 一、填空题 1. 统计学是研究统计原理和方法的科学。 2.我们所研究的具有某种共同特性的个体总和称为总体。 3.一般情况下,大样本是指样本容量超过30 的样本。 4.表示总体的数字特征的特征量称为参数。 5.要了解一组数据的集中趋势,需计算该组数据的集中量。 6. “65、69、72、87、89”这组数据的算术平均数是76.4 。 7. “78、69、53、77、54”这组数据的中位数是69 。 8. 6位学生的身高分别为:145、135、128、145、140、130厘米,他们的众数是145厘米。 9. 要了解一组数据的差异程度,需计算该组数据的差异量。 10.有7个学生的语文成绩分别为:80、65、95、70、55、87、69分,他们的全距是40分。 11.若某班学生数学成绩的标准差是5分,平均分是85分,其差异系数是5.88% 。 12.比较某班学生在身高和体重两方面的差异程度,要把学生身高和体重的标准差转化为差异系数。 13.两个变量之间不精确、不稳定的变化关系称为相关关系。 14.要描述两个变量之间变化方向及密切程度,需要计算相关系数。 15. 若两个变量之间存在正相关,则它们的相关系数是正数。 16.若两个变量之间的相关系数是负数,则它们之间存在负相关。 17.质与量的相关分析的方法主要包括二列相关、点二列相关和多系列相关。 18.品质相关的分析方法包括四分相关、Φ相关和列联相关。 20. 某班50个学生中有30个女生,若随机抽取一个同学,抽到男生的概率是2/5。 21.某一种统计量的概率分布称为抽样分布。 22.平均数差异显著性检验中需要判断两个样本是相关样本还是独立样本。 23. 单纯随机抽样能保证抽样的随机性和独立性。 24. χ2检验的数据资料是点计数据。 25. 单向表是把实测的点计数据按一种分类标准编制而得的表。 26. 单向表χ2检验是对单向表的数据进行χ2检验,即单因素的χ2检验。 27. 双向表是把实测的点计数据按两种分类标准编制而得的表。 28. 双向表χ2检验是对双向表的数据进行的χ2检验,即双因素的χ2检验。 29.假设检验的方法包括参数检验和非参数检验。 30.符号秩次检验属于非参数检验。 31.标准正态曲线在Z=0处为最高点。 32.直条图是表示间断变量的统计图。 33.直方图是表示连续变量的统计图。 34.教育统计资料的来源主要是经常性资料和专题性资料。 35.教育调查从范围来看,可分为全面调查和非全面调查。 36.对数据进行统计分类的标志按照形式可分为性质类别和数量类别。 二、简述题 1.简述教育统计学的研究对象和内容。 教育统计学的主要任务是研究如何搜集、整理、分析有关教育研究和教育实践工