上机操作4 拉丁方试验设计的SPSS分析

上机操作4 拉丁方试验设计的SPSS分析
习题:采用拉丁方对草莓品种进行比较试验,分析不同品种间是否存在显著性差异
草莓品种试验产量(kg/株)
解:
(1)假设不同品种间不存在显著性差异
(2)定义变量,输入数据
草莓产量
横行区组:1、2、3、4、5
列区组:1、2、3、4、5
品种:1——A、2——B、3——C、4——D、5——E
在变量视图中输入变量名称(草莓产量、横行区组、列区组、品种),调整变量参数;
在数据视图中对应变量名称下输入数据
(3)分析过程
①检验产量是否符合正态分布
图形→Q-Q图→变量(草莓产量)→确定
②检验方差是否齐性
分析→比较均值→单因素ANVOA→因变量(草莓产量)、因子(品种)→选项
→描述、方差同质性检验→确定
③运用常规线性模型,进行方差单变量分析,作多重比较
分析→常规线性模型→单变量→因变量(草莓产量)、固定因子(品种、横行区组、列区组)→模型(定制模型)→主效应→模型(品种、横行区组、列区组)→继续→两两比较→因子(品种、横行区组、列区组)→两两比较检验(品种)→Tukey、Duncan→继续→确定
(4)输出结果分析
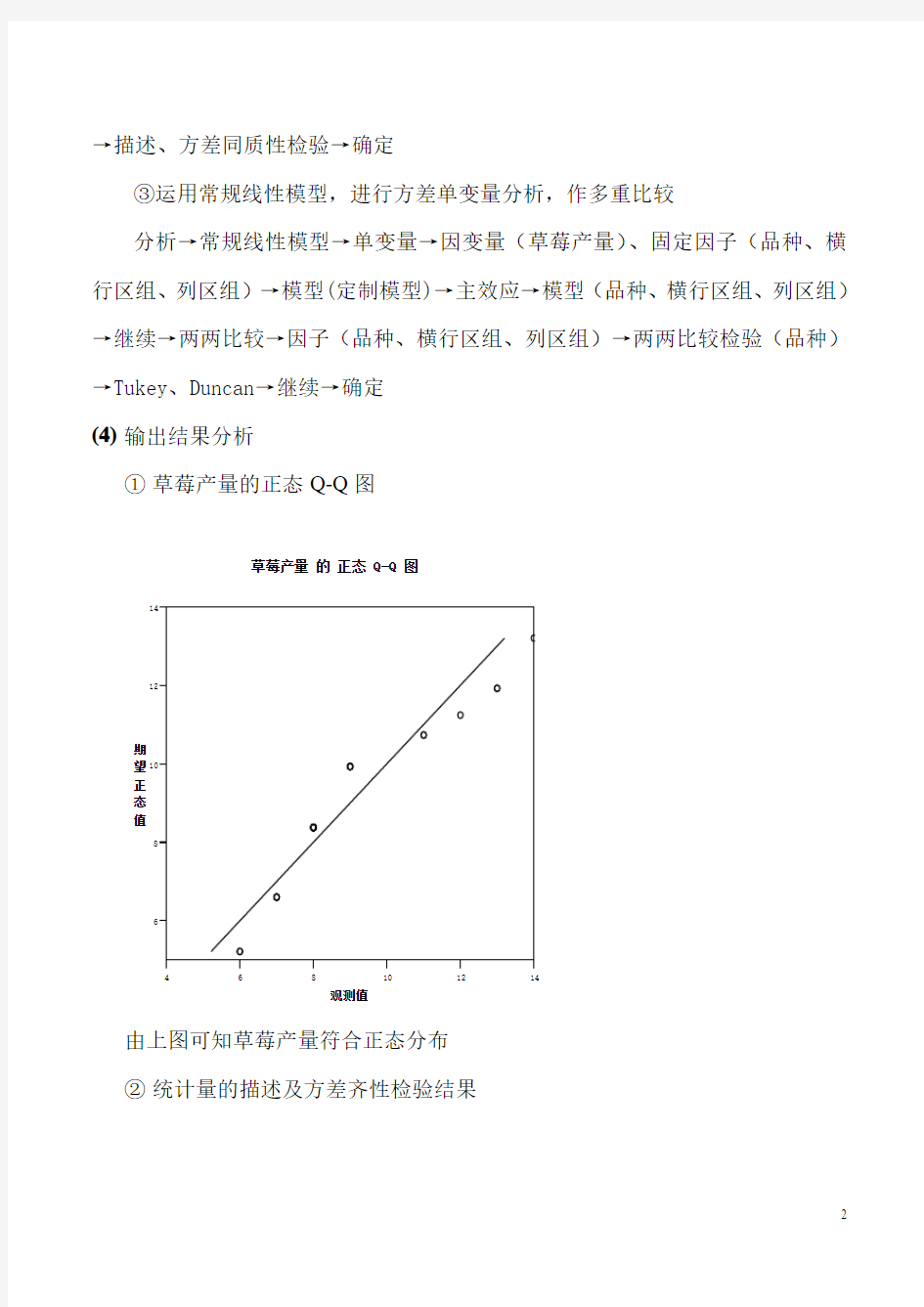
①草莓产量的正态Q-Q图
由上图可知草莓产量符合正态分布
②统计量的描述及方差齐性检验结果
各品种草莓产量的均值、标准差、标准误如上图所示
Sig = 0.604 > 0.05 无显著性差异,方差齐性即各品种草莓产量满足方差齐性检验条件
③方差的单变量分析及多重比较结果
品种 Sig < 0.01 极显著
与原假设矛盾,即不同品种间存在显著性差异
由上图Tukey分析可知,品种4、5、2、1之间无显著性差异,品种3与其他品种之间有显著性差异,且品种3的草莓产量最高
由上图Duncan分析可知,品种4、5、2、1之间无显著性差异,品种3与其他品种之间有显著性差异,且品种3的草莓产量最高
综上可知,各品种同品种3之间均存在显著性差异,且品种3的草莓产量最高
结论:品种C草莓产量最高
拉丁方设计的spss分析
. 上机操作4:拉丁方设计的spss分析 习题:采用拉丁方对草莓品种进行比较试验,分析不同品种之间的产量是否存在显著性差异。 草莓品种试验产量(kg/株) 解:1.假设 H:不同品种之间的产量不存在显 H:著的影响;A0不同品种之间的产量存在显著的影响。 2.定义变量,输入数据:在变量视图中写入变量名称“产量”、“行区组”、“列区组”“品种”,宽度均为8,小数均为0。并在数据视图依次输入变量。“A”“B”“C”“D”“E”和“Ⅰ”“Ⅱ”“Ⅲ”“Ⅳ”“Ⅴ”分别用“1”“2”“3”“4”“5”表示。 3.分析过程: (1)正态分布检验: 工具栏“图形”——“P-P图”,在“变量”中放入“产量”,
“检验分布”为“正态”,“确定”。 (2)方差齐性检验: 1 / 6 . a.工具栏“分析”——“比较均值”——“单因素ANOVA”。 b.在“因变量”中放入“产量”,在“固定因子”中分别放入“品种”。 c.点击“选项”,在“统计量”中点击“描述性”和“方差同质 性检验”,“继续”。 d.“确定”。 (3)显著性差异检验: a.工具栏“分析”——“常规线性模型”——“单变量”。 b.在“因变量”中放入“产量”,在“固定因子”中分别放入“品种”、“行区组”和“列区组”。 c.点击“模型”,“定制”,将“品种”“行区组”和“列区组” 放入“模型”下。在“建立项”中选择“主效应”,“继续”。d.点击“两两比较”,将“品种”放入“两两比较检验”中,点 击“假定方差齐性”中的“LSD”“Tukey”和“Duncan”。 4.生成图表,输出结果分析: (1)正态分布检验: 2 / 6 . 产量的正态 P-P 图1.0 所以产量符合正态分图中数据点都分布在一条直线上,P-P 布。)
SPSS实验报告.pdf
专业班级:金融106姓名:周吉利1222朱宁宁1224杨程琤1212周孟杰1207实验日期:2012.3.27 浙江万里学院实验报告 课程名称:2011/2012学年第二学期统计实验 实验名称:备择实验专业班级:金融105-106姓名:叶美君1219胡志晖1206黄世杰1208崔 迦楠1175 实验日期:2012.3.29 成绩: 教师:
专业班级:金融106姓名:周吉利1222朱宁宁1224杨程琤1212周孟杰1207实验日期:2012.3.27 一、实验目的:统计分析的目的在于研究总体特征。但是,由于各种各样的原因,我们能够得到的往往只能是从总体中随机抽取的一部分观察对象,他们构成了样本,只有通过对样本的研究,我们才能对总体的实际情况作出可能的推断。因此描述性统计分析是统计分析的第一步,做好这一步是进行正确统计推断的先决条件。通过描述性统计分析可以大致了解数据的分布类型和特点、数据分布的集中趋势和离散程度,或对数据进行初步的探索性分析(包括检查数据是否有错误,对数据分布特征和规律进行初步观察)。 本试验旨在于:引到学生利用正确的统计方法对数据进行适当的整理和显示, 描述并探索出数据内在的数量规律性,掌握统计思想,培养学生学习统计学的兴趣,为继续学习推断统计方法及应用各种统计方法解决实际问题打下必要而坚实的基础。 二、实验内容: 1.表 2.7为某班级16位学生的身高数据,对其进行频数分析,并对实验报告作出说明。 表2.7 某班16位学生的身高数据 学号性别身高(cm )学号性别身高(cm ) 1 M 170 9 M 150 2 F 17 3 10 M 157 3 F 169 11 F 177 4 M 15 5 12 M 160 5 F 174 13 F 169 6 F 178 14 M 154 7 M 156 15 F 172 8 F 171 16 F 180 三、实验过程: 1、输入某班级16位学生的身高数据。 2、然后选择分析,描述统计,频率,并选择统计量。
spss实验报告心得体会
spss实验报告心得体会 篇一:SPSS学习报告总结心得 应用统计分析学习报告 本科的时候有概率统计和数理分析的基础,但是从来没有接触过应用统计分析的东西,SPSS也只是听说过,从来没有学过。一直以为这一块儿会比较难,这学期最初学的时候,因为没有认真看老师给的英文教材,课下也没有认真搜集相关资料,所以学起来有些吃力,总感觉听起来一头雾水。老师说最后的考核是通过提交学习报告,然后我从图书馆里借了些教材查了些资料,发现很多问题都弄清楚了。结合软件和书上的例子,实战一下,发现SPSS的功能相当强大。最后总结出这篇报告,以巩固所学。 SPSS,全称是Statistical Product and Service Solutions,即“统计产品与服务解决方案”软件,是IBM公司推出的一系
列用于统计学分析运算、数据挖掘、预测分析和决策支持任务的软件产品及相关服务的总称,也是世界上公认的三大数据分析软件之一。SPSS具有统计分析功能强大、操作界面友好、与其他软件交互性好等特点,被广泛应用于经济管理、医疗卫生、自然科学等各个领域。具体到管理方面,SPSS也是一个进行数据分析和预测的强大工具。这门课中也会用到AMOS软件。 关于SPSS的书,很多都是首先介绍软件的。这个软件易于安装,我装的是的,虽然有一些改变和优化,但是主体都是一样的,而且都是可视化界面,用起来很方面且容易上手。所以,我学习的重点是卡方检验和T检验、方差分析、相关分析、回归分析、因子分析、结构方程模型等方法的适用范围、应用价值、计算方式、结果的解释和表述。 首先是T检验这一部分。由于参数检验的基础不牢固,这部分也是最初开始接触应用统计的东西,学起来很多东
拉丁方设计的spss分析
上机操作4:拉丁方设计的spss分析 习题:采用拉丁方对草莓品种进行比较试验,分析不同品种之间的产量是否存在显著性差异。 草莓品种试验产量(kg/株) 解:1.假设 H0:不同品种之间的产量不存在显著的影响; H A:不同品种之间的产量存在显著的影响。 2.定义变量,输入数据:在变量视图中写入变量名称“产量”、“行区组”、“列区组”“品种”,宽度均为8,小数均为0。并在数据视图依次输入变量。“A”“B”“C”“D”“E”和“Ⅰ”“Ⅱ”“Ⅲ”“Ⅳ”“Ⅴ”分别用“1”“2”“3”“4”“5”表示。 3.分析过程: (1)正态分布检验: 工具栏“图形”——“P-P图”,在“变量”中放入“产量”,“检验分布”为“正态”,“确定”。 (2)方差齐性检验:
a.工具栏“分析”——“比较均值”——“单因素ANOVA”。 b.在“因变量”中放入“产量”,在“固定因子”中分别放入“品种”。 c.点击“选项”,在“统计量”中点击“描述性”和“方差同质性检验”,“继续”。 d.“确定”。 (3)显著性差异检验: a.工具栏“分析”——“常规线性模型”——“单变量”。 b.在“因变量”中放入“产量”,在“固定因子”中分别放入“品种”、“行区组”和“列区组”。 c.点击“模型”,“定制”,将“品种”“行区组”和“列区组”放入“模型”下。在“建立项”中选择“主效应”,“继续”。 d.点击“两两比较”,将“品种”放入“两两比较检验”中,点击“假定方差齐性”中的“LSD”“Tukey”和“Duncan”。 4.生成图表,输出结果分析: (1)正态分布检验:
P-P图中数据点都分布在一条直线上,所以产量符合正态分布。 (2)方差齐性检验: 表1-1
拉丁方设计的spss分析
上机操作4:拉丁方设计的spss分析 习题:采用拉丁方对草莓品种进行比较试验,分析不同品种之间 的产量是否存在显著性差异。 草莓品种试验产量(kg/株) 解:1.假设H o:不同品种之间的产量不存在显著的影响;H A:不同品种之间的产量存在显著的影响。 2.定义变量,输入数据:在变量视图中写入变量名称“产量”、 “行区组”、“列区组”“品种”,宽度均为8,小数均为0。 并在数据视图依次输入变量。“A” “B' “C' “D‘ “E”和“I” “ v” 分别用“ 1”“ 2 ”“ 3”“ 4”“ 5” 表示。 3.分析过程: (1 )正态分布检验: 工具栏“图形” 一一“P-P图”,在“变量”中放入“产量”,“检验分布”为“正态”,“确定”。 (2)方差齐性检验:
a.工具栏“分析”一一“比较均值”一一“单因素ANOV”。 b.在“因变量”中放入“产量”,在“固定因子”中分别放入“品种”。 c.点击“选项”,在“统计量”中点击“描述性”和“方差同质性检验”,“继续”。 d.“确定”。 (3)显著性差异检验: a.工具栏“分析”——“常规线性模型”——“单变量”。 b.在“因变量”中放入“产量”,在“固定因子”中分别放入“品种”、“行区组” 和“列区组”。 c.点击“模型”,“定制”,将“品种” “行区组” 和“列区组”放入“模型”下。在“建立项”中选择“主效应”,“继续”。 d.点击“两两比较”,将“品种”放入“两两比较检验” 中,点击“假定方差齐性”中的“ LSD' “ Tukey”和“ Dun can”。 4.生成图表,输出结果分析: (1)正态分布检验:
SPSS实验报告
SPSS实验报告统计分析与SPSS的应用 实验报告 组员:高琴 200900701005 闭玉媚 200900701006 吴辉萍 200900701007 黄艳秋 200900701008 覃茜茜 200900701009 案例2-1 数据组织方式示例--住房状况调查表: 已定义好的SPSS数据结构示例如下:
案例2-4 横向合并数据文件 合并了奖金数据后的职工基本情况: 案例 3-1 数据的排序--职工数据
案例4-1 频数分析的应用举例
案例4-3 计算基本描述统计量的应用举例 本市户口和外地户口家庭人均住房面积的基本描述统计量Descriptive Statistics 户口状况 本市户口外地户口 有效的 N :列表有效的 N :列表 人均面积状态: 人均面积状态: N 统计量 2825 2825 168 168 全距统计量 112.60 97.67 极小值统计量 2.40 3.33 极大值统计量 115.00 101.00 均值统计量 21.7258 26.7165 标准差统计量 12.17539 18.96748
偏度统计量 2.181 1.429 标准误 .046 .187 峰度统计量 8.311 2.121 标准误 .092 .373 结果分析: 上表表明本市户口家庭的人均住房面积的平均值(21.7平方米)低于外地户口家庭(26.7平方米),但外地户口的标准差却高于本市户口。无论本市户口还是外地户口,人均住房面积的分布均呈一定的右偏分布(两个偏度统计量分别为2.18和1.43),且本市户口的偏斜程度更大些;同时,本市户口和外地户口家庭的人均住房面积均呈尖峰分布(两个峰度统计量分别为8.3和2.1),且本市更尖峰。由此可见,本市户口和外地户口中的大部分家庭的人均住房面积都低于各自的平均水平,此时,仅用均值刻画住房状况是不准确的。 案例4-5 交叉分组下的频数分析应用举例 表4-9 本市户口和外地户口家庭对“未来三年是否打算买房”看法的列联表户口状况* 未来三年交叉制表 未来三年 不买购买合计 户口状况外地户口计数 109 59 168 户口状况中的 % 64.9% 35.1% 100.0% 未来三年中的 % 5.0% 8.2% 5.8% 总数的 % 3.8% 2.0% 5.8% 标准残差 -1.5 2.6 本市户口计数 2052 660 2712 户口状况中的 % 75.7% 24.3% 100.0%
SPSS上机实验报告
S P S S上机实验报告 Company Document number:WUUT-WUUY-WBBGB-BWYTT-1982GT
实验名称:频数分布 实验目的和要求:绘制频数分布表、频数分布直方图并分析集中趋势指标、差异性指标和分布形状指标 实验内容:绘制频数分布表和频数分布直方图并分析 实验记录、问题处理: 绘制频数分布表 销售额 频率百分比有效百分比累积百分比 有效 1 1 1 2 1 1 1 2 2 2 2 1 1 1 2 1 1 1 1 2 2 1 合计30 频数分布直方图 集中趋势指标、差异性指标和分布形状指标统计量 销售额 N 有效30 缺失0 均值
实验结果分析: 从统计量表可以看出有效样本数有30个,没有缺失值。平均销售额是,标准差为。 从频数分布表可以看出样本值、频数占总数的百分比、累计百分比。 从带正态曲线的直方图可以看出销售额集中在110 实验名称:列联表 成绩: 实验目的和要求:绘制频数表、相对频数表并进行显着性检验和关系强度分析 实验内容:绘制频数表、相对频数表并分析 实验记录、问题处理: 满意度* 性别 交叉制表 性别 合计 男性 女性 满意度 不满意 计数 19 8 27 满意度 中的 % % % % 性别 中的 % % % % 总数的 % % % % 一般 计数 23 21 44 满意度 中的 % % % % 性别 中的 % % % % 总数的 % % % % 满意 计数 12 17 29 满意度 中的 % % % % 性别 中的 % % % % 总数的 % % % % 合计 计数 54 46 100 满意度 中的 % % % % 性别 中的 % % % % 总数的 % % % % 卡方检验 值 df 渐进 Sig. (双 侧) Pearson 卡方 2 .090 似然比 2 .085 线性和线性组合 1 .031 均值的标准误 中值 众数 标准差 方差 偏度 偏度的标准误 .427 峰度 峰度的标准误 .833 全距 极小值 极大值 和 a. 存在多个众数。显示最小值
SPSS上机实验报告
实验名称:频数分布 实验目的和要求:绘制频数分布表、频数分布直方图并分析集中趋势指标、差异性指标和分布形状指标 实验内容:绘制频数分布表和频数分布直方图并分析 实验记录、问题处理: 绘制频数分布表 销售额 频率百分比有效百分比累积百分比 79.00 80.00 82.00 85.00 89.00 93.00 95.00 96.00 97.00 99.00 105.00 106.00 有效 109.00 110.00 112.00 113.00 114.00 115.00 124.00 129.00 130.00 190.00 合计1 1 1 2 1 1 1 2 2 2 2 1 1 1 2 1 1 1 1 2 2 1 30 3.3 3.3 3.3 6.7 3.3 3.3 3.3 6.7 6.7 6.7 6.7 3.3 3.3 3.3 6.7 3.3 3.3 3.3 3.3 6.7 6.7 3.3 100.0 3.3 3.3 3.3 6.7 3.3 3.3 3.3 6.7 6.7 6.7 6.7 3.3 3.3 3.3 6.7 3.3 3.3 3.3 3.3 6.7 6.7 3.3 100.0 3.3 6.7 10.0 16.7 20.0 23.3 26.7 33.3 40.0 46.7 53.3 56.7 60.0 63.3 70.0 73.3 76.7 80.0 83.3 90.0 96.7 100.0 频数分布直方图 集中趋势指标、差异性指标和分布形状指标销售额 统计量 |N有效|30 1
实验结果分析: 从统计量表可以看出有效样本数有 30个,没有 缺失值。平均销售额是106.8333,标准差为 21.78592。 从频数分布表可以看出样本值、频数占总数的百 分比、累计百分比。 从带正态曲线的直方图可以看出销售额集中在 110 实验名称:列联表 成绩: 实验目的和要求:绘制频数表、相对频数表并进 行显着性检验和关系强度分析 实验内容:绘制频数表、相对频数表并分析 实验记录、问题处理: 满意度*性别交叉制表 a.存在多个众数。显示最小值
试验设计方法spss
利用软件SPSS进行常用试验设计的统计分析 教学目的:掌握SPSS软件的数据录入、数据整理、数据导入 掌握SPSS的方差分析的实现 熟悉正交设计、均匀设计的SPSS分析的实现 了解交叉设计、析因设计、拉丁方设计的SPSS实现 了解用SPSS进行协方差分析 一练习SPSS 软件的数据录入,变量命名。 二练习SPSS软件数据的导入。 三完全随机设计的方差分析 例1 为了比较四个水稻品种对产量的影响,取一片土壤肥沃程度相同的土地,分成24个小区。水稻品种记为A1,A2,A3,A4.每个品种种植于六个小区,成熟期做随机抽样,得到各个小区产量如表1-1所示: 表1-1 水稻不同品种产量比较试验
数据格式 分组产量 164 172 168 177 156 195 278 291 297 282 285 277 375 393 378 371 363 376 455 466 449 464 470 468 分析步骤:Analyz e→Compare means→One way anova→产量选入dependent list对话框→ 分组选入fact对话框→点击post hoc→选中snk→点击continue→点击ok。 根据结果进行分析: (1)建立检验假设,确定检验水准 H0:μ1 = μ2 = μ3 = μ4 水稻不同品种之间其产量没有差别 H1:μ1 、μ2 、μ3 、μ4不全相同,即水稻不同品种之间其产量有差别。 α = .0 05 (2)根据分析结果整理方差分析表 表1-2 水稻不同品种产量比较的方差分析表 变异来源离均差平方和自由度均方F统计量P值 (3)结论 = .0< P,拒绝H0,差别有统计学意义,即四种不同品种的水稻产量不全相同。 .0 007 05 进一步做两两比较,知品种1、3、4差别无统计学意义,品种2与品种1产量之间有差别。结合其均值得品种2的产量最高,为最好的品种。
SPSS实验报告材料91487
CENTRAL SOUTH UNIVERSITY SPSS实验报告 学生王强 学号4303110516 指导教师邵留国 学院商学院 专业工商1101
实验一、数据集 实验目的:掌握基本的统计学理论,学会使用SPSS录入数据,建立SPSS数据集。 实验容: 1.3:三十名儿童身高、体重样本数据如下表所示。建立SPSS数据集。 三十名儿童身高、体重样本数据
13 14 15 男 男 男 14 14 14 168.0 164.5 153.0 50.0 44.0 58.0 28 29 30 女 女 女 15 15 15 158.0 158.6 169.0 44.3 42.8 51.1 实验步骤: 步骤一:启动SPSS。 步骤二:选择文件,新建,数据,如图。 步骤三:切换到变量视图,定义变量。其中,性别变量需要设置值标签。如图所 示。 步骤四:切换到数据视图,按照次序依次输入数据。 步骤五:保存数据。
实验结果:
实验二:统计量描述 实验目的: (1)结合图表描述掌握各种描述性统计量的构造原理及其应用。 (2)熟练掌握运用SPSS进行统计描述的基本技能。 实验容:大学生在校期间的各门课程考试成绩,尽管在学生与学生之间、院系之间、男女生之间以及不同的课程之间,都存在着各种各样的差异,但整体上的分布状况还是有规律可循的。今有两个学院共1040名男女生的统计学和经济学期末考试成绩数据,储存在SPSS数据文件中,文件名:lytjcj.sav。试运用图表描述与统计量描述的方法,对此数据展开尽可能全面和深入的描述与分析。 实验步骤: 步骤一:打开SPSS数据,文件名:lytjcj.sav。如图。
拉丁方设计的方差分析
拉丁方设计的方差分析 ——双向随机区组设计 【10.3】研究5种不同的饲料配方对奶牛产奶量的影响(检测日产奶量)。 试验单元的初始条件:不同牛只的日产奶量有较大差异,同一牛只在其一个泌乳期的不同泌乳阶段的日产奶量也有很大差异。 A=配方5,B=配方1,C=配方3,D=配方4,E=配方2 一、按照SPSS编制数据文件: 按照下列格式在Excel中编制数据,并存为“拉丁方设计的方差分析-例题10-3” 泌乳阶段牛只饲料编码日产奶量 Ⅰ 1 E 30 Ⅰ 2 D 42 Ⅰ 3 B 35 Ⅰ 4 A 28 Ⅰ 5 C 40 Ⅱ 1 A 32 Ⅱ 2 C 39 Ⅱ 3 E 36 Ⅱ 4 D 40 Ⅱ 5 B 38 Ⅲ 1 B 39 Ⅲ 2 E 28 Ⅲ 3 D 40 Ⅲ 4 C 39 Ⅲ 5 A 35 Ⅳ 1 C 39 Ⅳ 2 B 37 Ⅳ 3 A 26 Ⅳ 4 E 28
Ⅳ 5 D 43 Ⅳ 1 D 38 Ⅳ 2 A 27 Ⅳ 3 C 40 Ⅳ 4 B 37 Ⅳ 5 E 32 二、用SPSS打开“拉丁方设计的方差分析-例题10-3.xls”,并按照下列步骤完成方差分析。 1. 选择单变量多因素方差分析的菜单命令
2. 选定因变量和自变量 3. 打开“模型”对话框,按照图示进行设置。因为拉丁方设计不能进行交互作用分析,故选择“主效应”分析,并选定欲分析的变量。 4. 点击“继续”按钮,回到“单变量”对话框。选择打开“两两对比”对话框
原题关心的是饲料配方对日产奶量的影响,故只需对“饲料编码”进行多重比较。 5. 点击“继续”按钮,回到“单变量”对话框。选择打开“选项”对话框
拉丁方设计
拉丁方设计 ----------------------------------------------------------------- “拉丁方”的名字最初是由R、A、Fisher给出的。拉丁方设计(latin square design)是从横行和直列两个方向进行双重局部控制,使得横行和直列两向皆成单位组,是比随机单位组设计多一个单位组的设计。在拉丁方设计中,每一行或每一列都成为一个完全单位组,而每一处理在每一行或每一列都只出现一次,也就是说,在拉丁方设计中,试验处理数=横行单位组数=直列单位组数=试验处理的重复数。在对拉丁方设计试验结果进行统计分析时,由于能将横行、直列二个单位组间的变异从试验误差中分离出来,因而拉丁方设计的试验误差比随机单位组设计小,试验精确性比随机单位组设计高。 拉丁方设计又叫平衡对抗设计(baIanced design)、轮换设计。这三个名称是从其模式、作用和方法三个不同的角度来说明这种设计的意义。 所谓平衡对抗设计,是指在实验中,由于前一个实验处理往往会影响后一个实验处理的效果,而该实验设计的作用就在于提供对实验处理顺序的控制,使实验条件均衡,抵消由于实验处理的先后顺序的影响而产生的顺序误差,因而也可称之为抵消法设计。 所谓轮换设计,是指在实验中,由于学习的首因效应,先实验的内容,被试容易记住;又因为学习的近因效应,对于刚刚学过的内容,被试回忆的效果一般也较好。因此、在实验方法上,有必要使不同实验条件出现的先后顺序轮换,使情境条件以及先后顺序对各个实验组的机会均等,打破顺序界限。 所谓拉丁方设计,是指平衡对抗设计的结构模式,犹如拉丁字母构成的方阵。例如四组被试接受A、B、C、D四种处理,其实验模式为: 上述模式表可以看出,每种处理即表中的字母在每一行和每一列都出现了一次而且仅出现了一次。像这样的一个方阵列就称为一个拉丁方。要构成一个拉丁方,必须使行数等于列数,并且两者都要等于实验处理的种数。 在只有两个实验处理的情况下,通常采用的平衡对抗设计是以ABBA的顺序来安排实验处理的顺序。或者把单组被试分为两半.一半按照ABBA的顺序实施处理,另一半按照BAAB 的顺序实施处理。 一、拉丁方简介 (一)拉丁方——以n个拉丁字母A,B,C……,为元素,作一个n阶方阵,若这n 个拉丁方字母在这n阶方阵的每一行、每一列都出现、且只出现一次,则称该n阶方阵为n×n 阶拉丁方。 例如:2×2阶、3×3阶拉丁方。
SPSS实验报告
《统计分析与SPSS的应用》 实验报告 班级:090911 学号:09091141 姓名:律江山 评分: 南昌航空大学经济管理学院 南昌航空大学经济管理学院学生实验报告 实验课程名称:统计分析与SPSS的应用 专业经济学班级学号09091141 姓名律江山成绩 实验地点G804 实验性质:演示性 验证性综合性设计性 实验项目名称基本统计分析(交叉分组下的频数分析)指导教师周小刚一、实验目的 掌握利用SPSS 软件进行基本统计量均值与均值标准误、中位数、众数、全距、方差和标准差、四分位数、十分位数和百分位数、频数、峰度、偏度的计算,进行标准化Z分数及其线形转换,统计表、统计图的显示。 二、实验内容及步骤(包括实验案例及基本操作步骤) (1)实验案例:居民储蓄存款。 (2)基本步骤:1、单击菜单选项analyze→descriptive statistics→crosstabs 2、选择行变量到row(s)框中,选择列变量到column(s)框中 3、选择dispiay clustered bar charts选项,指定绘制各变量交叉分组下的频数分布棒图。 三、实验结论(包括SPSS输出结果及分析解释) 实验结论: 较大部分储户认为在未来收入会基本不变,收入会增加的比例高于会减少的比例;城镇储户中认为 收入会增加的比例高于会减少的比例,但农村储户恰恰相反;可见城镇和农村储户在对该问题的看法上存在分歧。 城镇户口较内存户口收入有明显的增加,但未来收入减少的比例差距不大。其中二者未来收入大部分基本保持不变。
南昌航空大学经济管理学院学生实验报告 实验课程名称:统计分析与SPSS的应用 专业经济学班级学号09091141 姓名律江山成绩实验地点G804 实验性质:演示性 验证性综合性设计性 实验项目名称参数检验(两独立样本T检验) 指导 教师 周小刚 一、实验目的 掌握利用 SPSS 进行单样本 T 检验、两独立样本 T 检验和两配对样本 T 检验的基本方法,并能够解释软件运行结果。利用来自两个总体的独立样本,推断两个总体的均值是否存在显著差异。 二、实验内容及步骤(包括实验案例及基本操作步骤) (1)实验案例;居民储蓄存款 (2)实验步骤;1、单击菜单analyze→compare means→independent→sample t test; 2、选择实验变量到testariable(s)框; 3、选择总体标志变量到grouping variable框中; 4、单击define groups 定义两总体的标志值。 5、两独立样本t检验的option选项含义与单体样本t检验的相同。 三、实验结论(包括SPSS输出结果及分析解释) 实验结论: t统计量的观测值为0.879,对应的双尾概率P值为0.380.如果显著性水平a为0.05,由于概率P的值大于0.05,不能拒绝零假设,即城镇储户和农村储户一次存款金额的平均值无显著差异。
SPSS实验报告4
安徽建筑大学 数据统计分析 实验报告 专业统计学班级(二)班学生姓 名廖星和学号 11207040214 实验日期 2013.11.13 实验一描述性统计分析 一、实验目的:统计分析的目的在于研究总体特征。但是,由于各种各样的原因,我们 能够得到的往往只能是从总体中随机抽取的一部分观察对象,他们构成了样本,只有通过对 样本的研究,我们才能对总体的实际情况作出可能的推断。因此描述性统计分析是统计分析 的第一步,做好这一步是进行正确统计推断的先决条件。通过描述性统计分析可以大致了解 数据的分布类型和特点、数据分布的集中趋势和离散程度,或对数据进行初步的探索性分析 (包括检查数据是否有错误,对数据分布特征和规律进行初步观察)。 本本实验旨在于:引到学生利用正确的统计方法对数据进行适当的整理和显示,描述并 探索出数据内在的数量规律性,掌握统计思想,培养学生学习统计学的兴趣,为继续学习推 断统计方法及应用各种统计方法解决实际问题打下必要而坚实的基础。 二、实验原理: 描述统计是统计分析的基础,它包括数据的收集、整理、显示,对数据中有用信息的提 取和分析,通常用一些描述统计量来进行分析。 集中趋势的特征值:算术平均数、调和平均数、几何平均数、众数、中位数等。其中均 数适用于正态分布和对称分布资料,中位数适用于所有分布类型的资料。 离散趋势的特征值:全距、内距、平均差、方差、标准差、标准误、离散系数等。其中 标准差、方差适用于正态分布资料,标准误实际上反映了样本均数的波动程度。 分布特征值:偏态系数、峰度系数、他们反映了数据偏离正态分布的程度。根实验中每 种统计方法所涉及到的数理背景,或者数学理论的简要描述。 三、实验内容: 下面这个例题是关于房地产调查,该文件包括问卷id,姓名,性别,家庭年收入,年龄 等变量,现在我们就此数据给出相关的描述性统计说明,并就问卷调查者情况的一些描述性 统计量,如均值、频数、方差等描述统计量的计算。 四、实验步骤: 1.频数分析(frequencies)1 在spss中的频数分析的实现步骤如下: 选择菜单“【文件】—>【打开】—>【数据】”在对话框中找到需要分析的教学案 例-地产调查数据库.sav数据文件,然后选择“打开”。 选择菜单“【分析】—>【描述统计】—>【频率】”。如图1.1所示 图1.1 frequencies对话框 确定所要分析的变量户型结构,在变量选择确定之后,在同一窗口上,点击“statistics” 按钮,打开统计量对话框,如下图1.2所示,选择统计输出选项。 图1.2 统计量子对话框 图1.3 charts子对话框 结果输出与分析 点击frequencies 对话框中的“ok”按钮,即得到下面的结果。 2.描述统计(descriptives)2 选择菜单【分析】→【描述统计】→【描述】,如图1.7所示 2 描述统计主要对定距型
SPSS上机实验报告四
SPSS上机实验报告 一、实验内容 1.数据合并: (1)纵向拼接(添加个案):合并数据a.sav和b.sav (2)横向合并(添加变量):合并数据a.sav和c.sav 2.对数据CCSS_Sample.sav作下列操作: (1)频率分析:对S0城市,S4学历分别做分析; (2)交叉列表:月份对城市做交叉分析;观察值;计算(行、列)百分百; (3)对多选题C0贷款情况进行分析:多响应频率分析; 3.对数据Employee data.sav,分析员工的性别、受教育程度、少数名族、职位类别的分布情况,并尝试分析这些属性之间的关系以及这些属性和工资之间的关系. 二、实验步骤 1.合并数据 (1)纵向拼接:打开spss软件,在菜单中打开a.sav文件,选择菜单:[数据]→[合并文件]→[添加个案],在弹出的窗口中将选择外部spss数据文件并在浏览中选择b.sav,点击继续,在弹出的窗口中将“非成对变量”中的所有变量添加到“新的活动数据集中的变量”,勾选“将个案表现为变量”,点击确定。结果如图:
(2)横向合并:打开a.sav,选择菜单:[数据]→[合并文件]→[添加变量],在弹出的窗口中选择外部数据文c.sav,在弹出的窗口中勾选“按照排序文件中的关键变量匹配个案”,将“已排除变量”中的id添加到“关键变量”中,点击确定。结果如图: 2.(1)频率分析:在spss中打开CCSS_Sample.sav,选择菜单:[分析]→[描述统计]→[频率],在弹出的窗口中双击左边框中的S0城市,S4学历加入到右边变量框中,如图: 点击确定。结果如图:
分析:在北京,上海,广州工作的人数基本相同;大专毕业的人最多,其次是高中/中学毕业生和本科毕业生,硕士及以上学历的人非常少,仅占5%。 (2)交叉列表:打开CCSS_Sample.sav数据,选择菜单:[分析]→[描述统计]→[交叉表],在弹出的窗口中从左边框中将月份添加到行中,将城市添加到列中,如图: 单击[单元格],勾选百分比中的行和列,如图:
SPSS学习系列22.方差分析
22. 方差分析 一、方差分析原理 1. 方差分析概述 方差分析可用来研究多个分组的均值有无差异,其中分组是按影响因素的不同水平值组合进行划分的。 方差分析是对总变异进行分析。看总变异是由哪些部分组成的,这些部分间的关系如何。 方差分析,是用来检验两个或两个以上均值间差别显著性(影响观察结果的因素:原因变量(列变量)的个数大于2,或分组变量(行变量)的个数大于1)。一元时常用F检验(也称一元方差分析),多元时用多元方差分析(最常用Wilks’∧检验)。 方差分析可用于: (1)完全随机设计(单因素)、随机区组设计(双因素)、析因设计、拉丁方设计和正交设计等资料; (2)可对两因素间交互作用差异进行显著性检验; (3)进行方差齐性检验。 要比较几组均值时,理论上抽得的几个样本,都假定来自正态总体,且有一个相同的方差,仅仅均值可以不相同。还需假定每一个观察值都由若干部分累加而成,也即总的效果可分成若干部分,而每一部分都有一个特定的含义,称之谓效应的可加性。所谓的方差是离均差平方和除以自由度,在方差分析中常简称为均方(Mean Square)。
2. 基本思想 基本思想是,将所有测量值上的总变异按照其变异的来源分解为多个部份,然后进行比较,评价由某种因素所引起的变异是否具有统计学意义。 根据效应的可加性,将总的离均差平方和分解成若干部分,每一部分都与某一种效应相对应,总自由度也被分成相应的各个部分,各部分的离均差平方除以各自的自由度得出各部分的均方,然后列出方差分析表算出F检验值,作出统计推断。 方差分析的关键是总离均差平方和的分解,分解越细致,各部分的含义就越明确,对各种效应的作用就越了解,统计推断就越准确。 效应项与试验设计或统计分析的目的有关,一般有:主效应(包括各种因素),交互影响项(因素间的多级交互影响),协变量(来自回归的变异项),等等。 当分析和确定了各个效应项S后,根据原始观察资料可计算出各个离均差平方和SS,再根据相应的自由度df,由公式MS=SS/df,求出均方MS,最后由相应的均方,求出各个变异项的F值,F值实际上是两个均方之比值,通常情况下,分母的均方是误差项的均方。
spss上机操作实验作业
市场营销调研SPSS上机操作实验报告 姓名:刘丹霞 学号: 086221025 专业:08工商管理 方向: 市场营销 2011年6月23日
一、单因素列表分析 1 频数分布表(家庭收入分组家庭人口)
分析:由上表可以看出不同收入阶段人口频数及所占的频率. 2 箱索图(家庭收入) 分析:由表可以看出,有段和存在三个极端值,最大的一个在1000百美元以上,另外两个在450百—500百美元之间.经查,此三个极端值为:第1081号家庭收入1042百美元,第1093号家庭收入490百美元,第1052号家庭收入464百美元,还有两个极端值,处于300百—400百美元之间.鉴于1042百美元这个数值远远游离于箱体,绳索及邻近的极端值所组成的极端值之外,我们把它叫做飞点. 3 计算各个统计量(家庭人口收入)
二、多因素列表分析 (一)双向交叉列表 (家庭收入与汽车保有量交叉分组频数) ,46户在平均收入水平以上;有75户汽车汽车保有量不超过1辆,有25户超过1辆.再看交叉表部分,”低收入”与”1辆以内”的交叉为47户; ”低收入”与”1辆以上”为7户; ”高收入”
与”1辆以内”的交叉为28户; ”高收入”与”1辆以上”的交叉为18户. (二)三向交叉列表 CROSSTABS /TABLES=保有量分类BY 家庭规模BY 收入分类 /FORMAT=A V ALUE TABLES /STATISTICS=CHISQ /CELLS=COUNT /COUNT ROUND CELL. 分析:有分析数据结果可以看出,对于4口以内的家庭,低收入组只有3户拥有1辆以上的汽车,而高收入组达到5户,对于4口以上的家庭,拥有1辆以上的低收入户和高收入户分别为4户和13户.这些信息都表明,在家庭规模一定的条件下,家庭收入对汽车保有量有一定的影响. 三、参数检验 (一)单个样本平均值检验 GET FILE='E:\美国家庭汽车保量调研原始资料.sav'. T-TEST /TESTVAL=0
拉丁方试验设计
拉丁方试验设计的具体实例 拉丁方试验设计 拉丁方试验设计在统计上控制两个不相互作用的外部变量并且操纵自变量。每个外部变量或分区变量被划分为一个相等数目的区组或级别,自变量也同样被分为相同数目的级别。它是从横行和直列两个方向进行双重局部控制,使得横行和直列两向皆成单位组,是比随机单位组设计多一个单位组的设计。在拉丁方设计中,每一行或每一列都成为一个完全单位组,而每一处理在每一行或每一列都只出现一次,也就是说,在拉丁方设计中,试验处理数=横行单位组数=直列单位组数=试验处理的重复数。 拉丁方——以n个拉丁字母A,B,C……,为元素,作一个n 阶方阵,若这n个拉丁方字母在这n阶方阵的每一行、每一列都出现、且只出现一次,则称该n阶方阵为n×n阶拉丁方。第一行与第一列的拉丁字母按自然顺序排列的拉丁方,叫标准型拉丁方。 拉丁方设计一般用于5~8个处理的试验,设计的基本要求:①必须是三个因素的试验,且三个因素的水平数相等;②三因素间是相互独立的,均无交互作用;③各行、列、字母所得实验数据的方差齐(F 检验)。 试验设计的步骤:①根据主要处理因素的水平数,确定基本型拉丁方,并从专业角度使另外两个次要因素的水平数与之相同;②先将基本型拉丁方随机化,然后按随机化后的拉丁方阵安排实验。可通过对拉丁方的任两列交换位置或任两行交换位置实现随机化;③规定
行、列、字母所代表的因素与水平,通常用字母表示主要处理因素。 数据处理的相关理论:拉丁方设计实验结果的分析,是将两个单位组因素与试验因素一起,按三因素试验单独观测值的方差分析法进行。将横行单位组因素记为A ,直列单位组因素记为B ,处理因素记为C ,横行单位组数、直列单位组数与处理数记为r ,对拉丁方试验结果进行方差分析的数学模型为: ),,2,1()()(r k j i x k ij k j i k ij ===++++=εγβαμ 式中:μ为总平均数;i α为第i 横行单位组效应;j β为第j 直列单位组效应,)(k γ为第k 处理效应。单位组效应i α、j β通常是随机的,处理效应)(k γ通常是固定的,且有01=∑=r k k γ;)(k ij ε为随机误差,相互独立, 且都服从),(20σN 。 平方和与自由度划分式为: e C B A T SS SS SS SS SS +++= e C B A T v v v v v +++= 矫正数:22/..r x C = 总平方和:C x SS k ij T -=∑2 )( 横行平方和:C r x SS i A -=∑/2. 直列平方和:C r x SS j B -=∑/2. 处理平方和:C r x SS k C -=∑/2)( 误差平方和:C B A T e SS SS SS SS SS ---= 总自由度:12-=r v T 横行自由度:1-=r v A
spss实验报告
吉林财经大学实验报告
姓名 实验 时间 实验 项目 名称 金宏强 2012 年 4 月 20 日 学号 指导教师 0802091013 南英子 实验组 成绩
利用 spss 软件对已知数据进行参数估计及假设检验
学会利用 SPSS 软件对所给样本进行参数估计及假设检验
实 验 目 的
实 验 要 求
1、以 95.45%的置信度,估计“卫生、社会保障和社会福利业”业人员平均工资的置信区间; 2、 检验“卫生、社会保障和社会福利业”与“公共管理和社会组织”二行业均工资有无显 著差异(α =0.05)
实 验 原 理
1、 单个总体均值的区间估计 2、 相依样本的 T 检验
2010 年统计年鉴 “四就业人员和职工工资 4-16 各地区按行业分城镇单位就业人员平均工资” 中“卫生、社会保障和社会福利业”与“公共管理和社会组织”二行业平均工资数据。
实 验 数 据
1、 以 95.45%的置信度,估计“卫生、社会保障和社会福利业”业人员平均工资的置 信区间; 1 定义变量,输入数据 ○
2 .选择 Analyze ○
Compare Means
One-Sample T Test;
实 验 一 步 骤
3 将变量 x1 放置 Test 栏中; ○
4 激活 ○
子 对 话 框 , 将 置 信 度 改 为 95.45% , 单 击
按钮,返回
One-Sample T Test 主对话框;
5 单击 ○
按钮执行,得结果;
如何理解拉丁方试验设计
如何理解“拉丁方实验设计”(邓涛) 近来,不少学生问到拉丁方设计如何理解的问题,而且提出不同教材的表述也不一样。为了不去一一解答,我这里再结合《应用实验心理学》上的表述作一说明。 我的基本看法是:拉丁方实验设计与区组实验设计一样,都是为了平衡额外变量,以防止这些额外变量成为混淆因子,破坏实验研究的内部效度。如果简化点来解释,一般来说,区组实验设计多用于对一个额外变量的平衡,如被试因素、时间顺序因素、空间位置因素等;拉丁方实验设计则可以看成是区组设计的扩展,即扩展到可以平衡两个额外变量(当然,如果设计巧妙,也可以达到对多于两个额外变量的平衡,但那也是在二维平衡模式上变化出来的)。为了说明,拉丁方设计及其与区组设计的联系,我们先说一说区组设计。 区组实验设计是在考察自变量影响效应的实验中,考虑到一个额外变量的影响,将这个额外变量作为区组变量,对其在各种实验处理条件下产生的影响进行平衡,同时将该区组变量引起的变异从残差中分离出来。 比如,限于实验室条件,研究者开展某一实验研究时每天只能为4名被试进行测试,实验处理也有四个水平:A、A、A、A。如果认为不在每周中的同一天进行测试,可能4213会引起测试结果的变化,这种影响又是比较重要的。于是可以将测试时间作为区组变量,即把同一天接受测试的被试看作是一个区组。这样就可以形成一个区组实验设计,如表2-8所示。 表2-8 四种实验处理的随机区组实验设计 区组 A A A A 4123一星期1 1 1 1 二星期1 1 1 1 三期星1 1 1 1 四星期1 1 1 1 现在我们进一步设想: 假如,在每天的实验中,一次只能测试一人,每天参加实验的四名被试只能分别在下午2~3点、3~4点、4~5点和5~6点的四个时段接受测试,而测试时段不同也可能会造成结果变化。这样一来,每一种实验处理条件安排的时段就也要取得平衡才行,你不能每天都在2点钟安排所有被试接受A处理条件,或3点钟接受A处理条件。于是,研究11中采用测试天和测试时段两方面因素的平衡方法安排实验,构成了一个单因素的拉丁方实验设计,设计模式如图2-9所示。在这一设计中,测试是在星期几、测试是在每一天的哪一时段,这两个额外变量就都取得了很好的平衡。 表2-9 四种实验处理的拉丁方实验设计
上机实验报告 SPSS数据文件的建立和管理
上机实验报告 SPSS数据文件的建立和管理 班级行政0902 姓名李静学号2009012401 网站_https://www.wendangku.net/doc/8e9997760.html, 一、实验内容 SPSS数据文件的建立、读取其他格式的数据文件等 二、预期目标 1.明确SPSS数据的基本组织方式和数据行列的含义。 2.熟练掌握建立SPSS数据文件以及管理SPSS数据的基本操作。 3.熟练掌握SPSS中读取Excel工作表数据的基本操作,了解读取文本和数据库数据的基本方法。 三、基本概念(教材P46页) 1.SPSS中有哪两种基本的数据组织方式?各自的特点和应用场合是什么? 一是原始数据的组织方式,二是计算数据的组织方式; 在原始数据的组织方式中,数据编辑窗口中的一行称为一个个案,所有个案组成完整的SPSS数据。数据编辑窗口中的一列称为一个变量。每个变量都有一个名字,称为变量名,它是访问和分析SPSS每个变量的唯一标识。该种方式应用于所采集的数据是原始的调查问卷数据这种场合。 在计算组织方式中,数据编辑窗口中的一行为变量的一个分组。所有行囊括了该变量的所有分组情况。数据编辑窗口中的一列仍为一个变量,代表某个问题以及相应的计算结果。该种方式应用于所采集的数据不是原始的调查问卷数据,而是经过分组汇总后的计算数据这种场合。在SPSS中该类数据应按计算数据的组织方式组织。 2.在定义SPSS数据结构时,默认的变量名和变量类型是什么?如果希望增强统计分析结果的易读性,还需要对数据结构的哪些方面进行必要说明? 字母VAR开头,后面不足5位数字;数值型、字符型、日期型;变量名标签,变量值标签 3.你认为S PSS数据窗口与Excel工作表在基本操作方式和数据组织方式方面有什么异同? SPSS的数据直观地显示在数据编辑窗口中,形成一张平面的二维表格。待分析的数据将按原始数据方式和计数数据方式组织。 其中,原始数据的组织方式,数据编辑窗口中的一行成为一个个案,所有个案组成完整的SPSS数据;而计数数据方式是经过分组汇总后的计数数据。