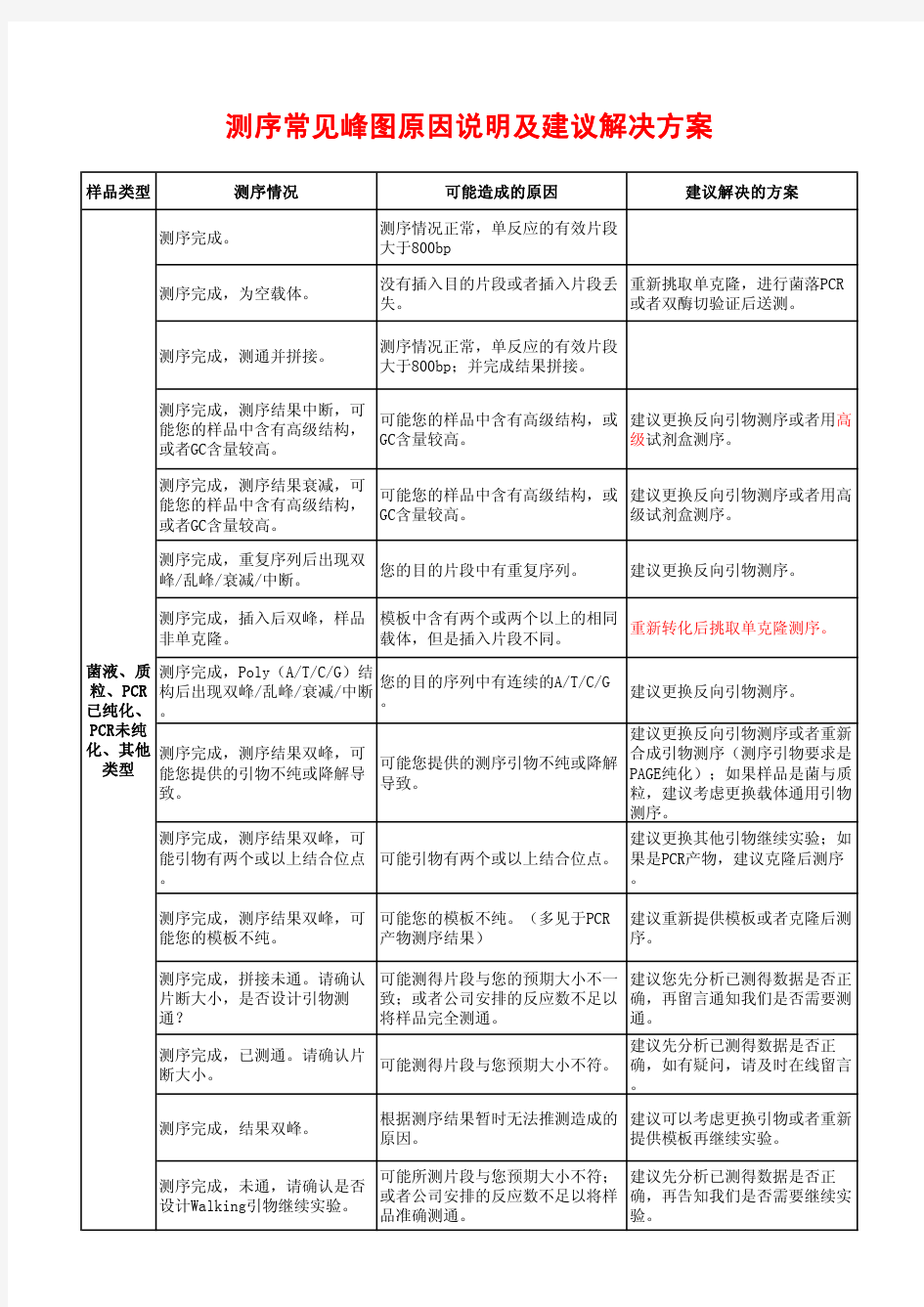
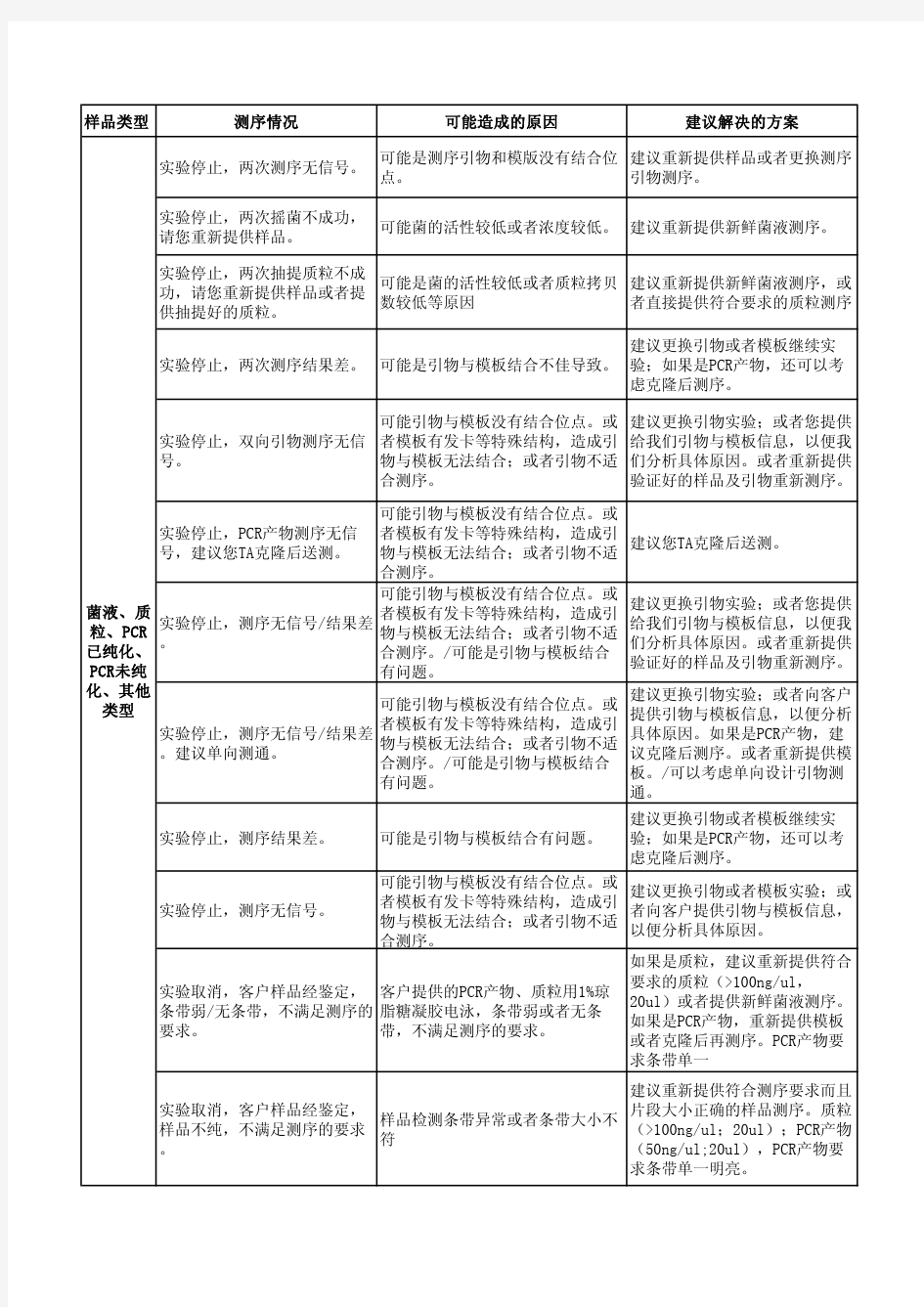
测序常见峰图原因说明及建议解决方案
测序峰图
峰的高低说明了信号的强弱,宽窄表示的是分离效果,可以对比板胶电泳的亮度和条带的宽窄。重叠则说明了样品中有长度相同但是序列不同的片段。 Q-1.为什么提供新鲜的菌液?如何提供新鲜的菌液?返回顶端 A-1.首先,新鲜的菌液易于培养,可以获得更多的DNA,同时最大限度地保证菌种的纯度。如果您提供新鲜菌液,用封口膜封口以免泄露;也可以将培养好的 4~5ml菌液沉淀下来,倒去上清液以方便邮寄。同时邮寄时最好用盒子以免邮寄过程中压破。 Q-2.DNA测序样品用什么溶液溶解比较好?返回顶端 A-2.溶解DNA测序样品时,用灭菌蒸馏水溶解最好。DNA的测序反应也是Taq酶的聚合反应,需要一个最佳的酶反应条件。如果DNA用缓冲液溶解后,在进行测序反应时,DNA溶液中的缓冲液组份会影响测序反应的体系条件,造成Taq酶的聚合性能下降。 有很多客户在溶解DNA测序样品时使用TE Buffer。的确,TE Buffer能增加DNA样品保存期间的稳定性,并且TE Buffer对DNA测序反应的影响也较小,但根据我们的经验,我们还是推荐使用灭菌蒸馏水来溶解DNA测序样品。 Q-3.提供DNA测序样品时,提供何种形态的比较好?返回顶端 A-3.我们推荐客户提供菌体,由我们来提取质粒,这样DNA样品比较稳定。如果您可以提供DNA样品,我们也很欢迎,但一定要注意样品纯度和数量。如果提供的DNA量不够,我们就需要对质粒进行转化,此时需收取转化费。有些质粒提取法提取的DNA质量很好,象TaKaRa、Qiagen、Promega的质粒制备试剂盒等。提供的测序样品为PCR产物时,特别需要注意DNA的纯度和数量。PCR产物必须进行切胶回收,否则无法得到良好的测序效果。 有关DNA测序样品的详细情况请严格参照“测序样品的提供”部分的说明。 Q-4.提供的测序样品为菌体时,以什么形态提供为好?返回顶端 A-4.一般,菌体的形态有:平板培养菌、穿刺培养菌,甘油保存菌或新鲜菌液等。我们提倡寄送穿刺培养菌或新鲜菌液。 平板培养菌运送特别不方便,我们收到的一些平板培养菌的培养皿在运送过程中常常已经破碎,面目全非,需要用户重新寄样。这样既误时间,又浪费客户的样品。一旦是客户非常重要的样品时,其后果更不可设想。而甘油保存菌则容易污染。 制作穿刺菌时,可在1.5 ml的Tube管中加入琼脂培养基,把菌体用牙签穿刺于琼脂培养基(固体)中,37℃培养一个晚上后便可使用。穿刺培养菌在4℃下可保存数个月,并且不容易污染,便于运送。
DNA测序结果分析
学习 通常一份测序结果图由红、黑、绿和蓝色测序峰组成,代表不同的碱基序列。测序图的两端(本图原图的后半段被剪切掉了)大约50个碱基的测序图部分通常杂质的干扰较大,无法判读,这是正常现象。这也提醒我们在做引物设计时,要避免将所研究的位点离PCR序列的两端太近(通常要大于50个碱基距离),以免测序后难以分析比对。 我的课题是研究基因多态性的,因此下面要介绍的内容也主要以判读测序图中的等位基因突变位点为主。 实际上,要在一份测序图中找到真正确实的等位基因多态位点并不是一件容易的事情。由于临床专业的研究生,这些东西是没人带的,只好自己研究。开始时大概的知道等位基因位点在假如在测序图上出现像套叠的两个峰,就是杂合子位点。实际比对了数千份序列后才知道,情况并非那么简单,下面测序图中标出的两
个套峰均不是杂合子位点,如图并说明如下: 说明:第一组套峰,两峰的轴线并不在同一位置,左侧的T峰是干扰峰;第二组套峰,虽两峰轴线位置相同,但两峰的位置太靠近了,不是杂合子峰,蓝色的C峰是干扰峰通常的杂合子峰由一高一略低的两个轴线相同的峰组成,此处的序列被机器误判为“C”,实际的序列应为“A”,通常一个高大碱基峰的前面1~2个位点很容易产生一个相同碱基的干扰峰,峰的高度大约是高大碱基峰的1/2,离得越近受干扰越大。一个摸索出来的规律是:主峰通常在干扰峰的右侧,干扰峰并不一定比主峰低。最关键的一点是一定要拿疑似为杂合子峰的测序图位点与测序结果的文本序列和基因库中的比对结果相比较;一个位点的多个样本相比较;你得出的该位点的突变率与权威文献或数据库中的突变率相比较。通常,对于一个疑似突变位点来说,即使是国际上权威组织大样本的测序结果中都没有报道的话,那么单纯通过测序结果就判定它是突变点,是并不严谨的,因一份PCR产物中各个碱基的实际含量并不相同,很难避免不产生误差的。对于一个未知
TALEN和CAS9技术移码敲除测序峰图分析方法说明-仅供参考
1.为什么TALEN和CAS9技术移码敲除项目需通过测序判定基因型? TALEN和CAS9技术是通过特异识别和核酸酶切割,使DNA双链断开,机体启动DNA损伤修复机制,在非同源末端连接修复过程中,碱基的随机增减造成目标基因功能缺失。这一修复过程通常会产生1-30个左右的碱基缺失,PCR后凝胶电泳无法将碱基缺失链和wt链区分开,所以只能通过测序判断。 2.如何判断TALEN和CAS9技术移码敲除项目的基因型? a. 野生型或基因敲除的纯合子基因型的判定: 1)如下图所示,只有单峰的为野生型或基因敲除的纯合子。 2)将只有单峰的序列文件与wt序列比对,可判定野生型或基因敲除的纯合子基因型(网站或生物软件比对均可). 如下图的对比结果为野生型:
如下图的比对结果为缺失一个C的纯合子 b.杂合子基因型的判定: 1).如下图所示,测序图谱中出现叠峰的为杂合子 若将叠峰的序列文件直接与wt序列比对,叠峰后的序列会对应不上(因为叠峰的序列只显示了信号强一点的那个碱基,实际上每个叠峰对应两个碱基),如下图所示:
所以不能通过直接比对来分析,需通过峰图分析,在峰图中峰的颜色与碱基对应关系如下:A:绿色 T:红色 C:蓝色 G:黑色 2)将wt的峰图与杂合子的峰图用软件同时打开,从出现叠峰的位置开始分析(杂合子的一条链是wt链,一条链是缺失链): 上图第一个峰图是野生型的序列,与第二个峰图叠峰开始对应的序列为: Gttaact ccgagcagcaaagaaatgatgtccc 上图第二个峰图是杂合子的测序峰图,从叠峰位置开始的序列为: Gttaact ccgagcagcaaagaaatgatgtccc(wt链) Ccgagcagcaaagaaatgatgtcccaagcctt(缺失链) 由此可判定为该杂合子的基因型为缺失gttaact(-7)
DNA测序结果分析比对(实例)
DNA测序结果分析比对(实例) 关键词:dna测序结果2013-08-22 11:59来源:互联网点击次数:14423 从测序公司得到的一份DNA测序结果通常包含.seq格式的测序结果序列文本和.ab1格式的测序图两个文件,下面是一份测序结果的实例: CYP3A4-E1-1-1(E1B).ab1 CYP3A4-E1-1-1(E1B).seq .seq文件可以用系统自带的记事本程序打开,.ab1文件需要用专门的软件打开。软件名称:Chromas 软件Chromas下载 .seq文件打开后如下图: .ab1文件打开后如下图: 通常一份测序结果图由红、黑、绿和蓝色测序峰组成,代表不同的碱基序列。测序图的两端(下图原图的后半段被剪切掉了)大约50个碱
基的测序图部分通常杂质的干扰较大,无法判读,这是正常现象。这也提醒我们在做引物设计时,要避免将所研究的位点离PCR序列的两端太近(通常要大于50个碱基距离),以免测序后难以分析比对。 我的课题是研究基因多态性的,因此下面要介绍的内容也主要以判读测序图中的等位基因突变位点为主。 实际上,要在一份测序图中找到真正确实的等位基因多态位点并不是一件容易的事情。一般认为等位基因位点假如在测序图上出现像套叠的两个峰,就是杂合子位点。实际比对后才知道,情况并非那么简单,下面测序图中标出的两个套峰均不是杂合子位点,如图并说明如下:
说明: 第一组套峰,两峰的轴线并不在同一位置,左侧的T峰是干扰峰;第二组套峰,虽两峰轴线位置相同,但两峰的位置太靠近了,不是杂合子峰,蓝色的C峰是干扰峰通常的杂合子峰由一高一略低的两个轴线相同的峰组成,此处的序列被机器误判为“C”,实际的序列应为“A”,通常一个高大碱基峰的前面 1~2个位点很容易产生一个相同碱基的干扰峰,峰的高度大约是高大碱基峰的1/2,离得越近受干扰越大。 一个摸索出来的规律是:主峰通常在干扰峰的右侧,干扰峰并不一定比主峰低。最关键的一点是一定要拿疑似为杂合子峰的测序图位点与测序结果的文本序列和基因库中的比对结果相比较;一个位点的多个样本相比较;你得出的该位点的突变率与权威文献或数据库中的突变率相比较。 通常,对于一个疑似突变位点来说,即使是国际上权威组织大样本的测序结果中都没有报道的话,那么单纯通过测序结果就判定它是突变点,是并不严谨的,因一份 PCR产物中各个碱基的实际含量并不相同,很难避免不产生误差的。对于一个未知突变位点的发现,通常还需要用到更精确的酶切技术。 (责任编辑:大汉昆仑王)
测序结果分析教学文案
测序结果的判读 测序结果为.abi格式,可用软件chrosmas打开,一种颜色的峰代表一个碱基,峰的高低表信号的强弱。一个正常的N表示机器没法判读是哪种碱基,原因是:杂峰的信号高于机器默认的值,机器会认为该处有两个峰,因此不能判断确定是哪个峰,需要人工判读。以下三种情况会出现N:有杂合子,有杂峰,反应已结束。
原因:测序产物纯化不够 注意:染料峰位于序列的前100 碱基以内;酒精峰位于序列的220 ~ 320 碱基之间
产生的原因是样品或毛细管内有灰尘等固体小颗粒 原因:测序反应失败。 解决办法:改进条件,重做反应。注意两个关键因素:引物与模板之间的比例:3.2 pmol: 200 ng。模板DNA 的纯度和用量:1.6 ~ 2.0
原因:残余的Dye 太多,纯化不够。有测序反应,但效率低下信号太弱 解决办法:纯化充分。避开引物峰,确定新的分析起点 1、PCR产物测序时出现重叠峰 问题图1(模板中有碱基缺失,往往是单一位点(1-1)或两个位点(1-2)碱基缺失导致测序结果移码) 解决方法:将PCR产物克隆到质粒(如T载体)中挑单克隆测序,或将PCR产物进行PAGE 纯化(至少琼脂糖充分电泳后切胶纯化)后再进行测序。 问题图2(PCR产物不纯,含部分序列一致的两种以上的片段,长度不一)
解决方法:主要原因是PCR产物没有纯化,含有部分序列一致的两种以上长度不一的片段,将PCR产物进行PAGE纯化(至少琼脂糖充分电泳后切胶纯化)后再进行测序,便可解决。 问题图3(测序引物有碱基缺失) 测序引物有碱基缺失(一般是引物的5'端缺失),和模板的碱基缺失即图1有些类似,所不同的是模板碱基缺失一般是在一段正常测序序列后才出现移码,而引物碱基缺失的话,则从测序一开始就出现移码,表面在图形上便是一开始就是严重的峰形重叠。 解决方法:重新合成引物,或将引物进行PAGE纯化 2、克隆测序时出现峰形重叠
如何理解测序蜂图
测序峰图 测序方法 现代DNA序列测序可分为一二三代。 一代测序 第一代测序技术包括链终止法和化学降解法,其主要特点是以待测DNA为模板,根据碱 基互补规则采用DNA聚合酶体外合成新链。由于新链中渗入了带有标记的碱基类似物,可用于制 备末端带有标记的DNA单链。这些末端带有标记的DNA单链是一个群体,在凝胶电泳时可以形 成彼此仅差一个碱基的梯形条带。根据末端碱基的特有标记可以读取待测DNA的序列组成。 链终止法(Sanger法) 反应分别在4个试管中进行,每一试管中都含有: 1.待测的DNA单链片段,作为模板; 2.DNA聚合酶; 3.序列已知且与模板3'端互补的引物; 4.四种脱氧核苷三磷酸(dATP、dGTP、dCTP和dTTP) ; 5.四种双脱氧核苷酸中的一种,作为DNA链合成的末端终止剂。 在适当条件下进行互补链的合成,由于新掺入的核苷酸只能同新生链3’端的-OH连接,而2’, 3’ -双脱氧核苷三磷酸核糖基的2’, 3’位-OH的氧已脱掉,失去了和后来的核苷酸连接的可能性,这时碱基的掺入就有两种可能性: 1.dNTP掺入新生链,使链继续延伸。 2.2’, 3’ -ddNTP掺入,使新生链的合成终止。 由于两者掺入的几率不同,就形成一套长度不一的DNA片段。最后通过A、T、G和C四组反应的凝胶电泳放射自显影图谱,即可读出所测样品互补链的核苷酸序列。 i ii 要求测序时使用的DNA聚合酶不能有5’-3’外切酶活性(可将新合成DNA链的5’-末端除去核苷酸而改变链的长度)、3’-5’外切酶活性(可将错配的碱基除去,再补上正确配对的核苷酸)。这两种活性会产生干扰条带。
一代测序常见问题及解决策略
测序常见问题及解决策略 一、PCR常见问题 1.假阴性,不出现扩增条带 PCR出现假阴性结果,可从以下几个方面来寻找原因: 1)模板:①模板中有杂蛋白;②模板中有Taq酶抑制剂;③在提取制备模板时丢失过多;④模板核酸变性不彻底。 2)酶:酶失活或反应时忘了加酶。 3)Mg2+浓度:Mg2+浓度过高可降低PCR扩增的特异性,浓度过低则影响PCR 扩增产量甚至使PCR扩增失败而不出扩增条带。 4)反应条件:变性对PCR扩增来说相当重要,如变性温度低,变性时间短,极有可能出现假阴性;退火温度过低,可致非特异性扩增而降低特异性扩增效率退火温度过高影响引物与模板的结合而降低PCR扩增效率。 5)靶序列变异:靶序列发生突变或缺失,影响引物与模板特异性结合,或因靶序列某段缺失使引物与模板失去互补序列,其PCR扩增是不会成功的。 2.假阳性 假阳性:出现的PCR扩增条带与目的靶序列条带一致,有时其条带更整齐,亮度更高。常见原因有: 1)引物设计不合适:选择的扩增序列与非目的扩增序列有同源性,因而在进行PCR扩增时,扩增出的PCR产物为非目的性的序列。靶序列太短或引 物太短,容易出现假阳性。需重新设计引物。 2)靶序列或扩增产物的交叉污染:这种污染有两种原因:一是整个基因组或大片段的交叉污染,导致假阳性。这种假阳性可用以下方法解决:操作时应小心轻柔,防止将靶序列吸入加样枪内或溅出离心管外。二是空气中的 小片段核酸污染,这些小片段比靶序列短,但有一定的同源性。可互相拼接,与引物互补后,可扩增出PCR产物,而导致假阳性的产生,可用巢式PCR方法来减轻或消除。 3.出现非特异性扩增带 PCR扩增后出现的条带与预计的大小不一致,或大或小,或者同时出现特异性扩增带与非特异性扩增带。非特异性条带的出现,其原因:一是引物
测序图分析
测序常见峰图及原因说明 1.PCR产物电泳检测 条带单一,为什么测序结果说模板杂? 2. 什么是碱基缺失? 3. 什么是引物不纯? 4. 重复结构对测序有哪些影响?5. 什么是模板不单一? 6. Poly结构的测序结果是怎样的? 7. 含有回文结构的模板测序结果是怎样的? 8. 测序峰图为前双峰的结果是什么样的? 9. 测序峰图为后双峰是什么样的? 10. 无信号的结果:信号值(ATGC的平均值)皆小于100 11. 飘峰:这是由于用3.0特殊试剂盒时碱基产生替代而出现碱基位移 12. 没有任何干扰的结果 Q-1.PCR产物电泳检测条带单一,为什么测序结果说模板杂?返回顶端 A-1.PCR产物电泳检测的结果只是一个粗略的定性结果。对于与目的片段条带大小只相差几个碱基的非特异性PCR扩增产物是无法用肉眼区分开的。但是DNA 测序反应敏感而客观,可以直接反应出模板本身的情况。需要强调的是,高质量的 PCR产物才可能得到高质量的测序结果,如果您对PCR产物的纯度不很确定,希望您可以将PCR产物进行克隆处理,以确保得到好的测序结果。以下图为例:该反应的背景信号较高,不利于碱基的判读。 查看大图 解决办法:改变PCR条件,重新扩增。或者可以将该PCR产物克隆到质粒中,初步筛选后进行单克隆测序。 Q-2.什么是碱基缺失?返回顶端 A-2.以下图为例: 查看大图
片段,上图的PCR产物中,特别是从基因组中扩增得到的PCR碱基缺失常见在.T 186位缺失两个连续的解决方法:使用反向引物继续测序,以矫正缺失位点并达到测通的目的。或者将 (1) 该PCR产物克隆到质粒中,挑取单克隆测序。PCR (2) 如果可以确定该PCR 片段中不应该有缺失的位点,那么可以改变反应条件,重新扩增。 什么是引物不纯?Q-3. 返回顶端 A-3.以下图为例:查看大图 但是引引物不纯造成移码现象,该种现象与模板杂在峰图都表现为背景峰较杂,一般在每一个主峰前或者后都有一个同一碱基物不纯在峰图上表现的更有规律,的小峰。 PAGE解决办法:重新合成引物,或者将引物进行纯化后再进行测序。返回顶端Q-4.重复结构对测序有哪些影响?以下图为例:A-4. 查看大图 重复结构将导致测序复制框的滑移,重复结构之后峰型混乱。测到该重复结构处,即可完成模板全解决办法:使用反向引物对模板进行测序,长的拼接。 Q-5.什么是模板不单一?返回顶端 A-5.以下图为例: (1) 菌液为非单克隆: 下图是pGEM-T载体测序的结果,在83位点处测序结果出现双峰(插入后双峰),即模板中含有两个或两个以上的相同载体,但是插入片段不同。 解决办法:重新挑取单克隆或者重新提取质粒。需要注意的是,重新进行PCR 反应或者酶切鉴定仅能证明该克隆含有插入片段,并不足以证明模板的单一。查看大图 查看大图
高通量测序(NGS)数据分析中的质控
高通量测序错误总结 一、生信分析部分 1)Q20/Q30 碱基质量分数与错误率是衡量测序质量的重要指标,质量值越高代表碱基被测错的概率越小。Q30代表碱基的正确判别率是99.9%,错误率为0.1%。同时我们也可以理解为1000个碱基里有1个碱基是错误的。Q20代表该位点碱基的正确判别率是99%,错误率为1%。对于整个数据来说,我们可以认为100个碱基里可能有一个是错误的, 在碱基质量模块报告的坐标图中,背景颜色沿y-轴将坐标图分为3个区:最上面的绿色是碱基质量很好的区,Q值在30以上。中间的橘色是碱基质量在一些分析中可以接受的区,Q值在20-30之间。最下面红色的是碱基质量很差的区。在一些生信分析中,比如以检查差异表达为目的的RNA-seq分析,一般要求碱基质量在Q在Q20以上就可以了。但以检查变异为目的的数据分析中,一般要求碱基质量要在Q30以上。 一般来说,测序质量分数的分布有两个特点: 1.测序质量分数会随着测序循环的进行而降低。 2.有时每条序列前几个碱基的位置测序错误率较高,质量值相对较低。
在图中这个例子里,左边的数据碱基质量很好,而右边的数据碱基质量就比较差,需要做剪切(trimming),根据生信分析的目的不同,要将质量低于Q20或者低于Q30的碱基剪切掉。
2)序列的平均质量 这个是碱基序列平均质量报告图。横坐标为序列平均碱基质量值,纵坐标代表序列数量。通过序列的平均质量报告,我们可以查看是否存在整条序列所有的碱基质量都普遍过低的情况。一般来说,当绝大部分碱基序列的平均质量值的峰值大于30,可以判断序列质量较好。如这里左边的图,我们可以判断样品里没有显著数量的低质量序列。但如果曲线如右边的图所示,在质量较低的坐标位置出现另外一个或者多个峰,说明测序数据中有一部分序列质量较差,需要过滤掉。
测序图分析
测序常见峰图及原因说明 1.PCR产物电泳检测条带单一,为什么测序结果说模板杂? 2. 什么是碱基缺失? 3. 什么是引物不纯? 4. 重复结构对测序有哪些影响? 5. 什么是模板不单一? 6. Poly结构的测序结果是怎样的? 7. 含有回文结构的模板测序结果是怎样的? 8. 测序峰图为前双峰的结果是什么样的? 9. 测序峰图为后双峰是什么样的? 10. 无信号的结果:信号值(ATGC的平均值)皆小于100 11. 飘峰:这是由于用3.0特殊试剂盒时碱基产生替代而出现碱基位移 12. 没有任何干扰的结果 Q-1.PCR产物电泳检测条带单一,为什么测序结果说模板杂?返回顶端A-1.PCR产物电泳检测的结果只是一个粗略的定性结果。对于与目的片段条带大小只相差几个碱基的非特异性PCR扩增产物是无法用肉眼区分开的。但是DNA 测序反应敏感而客观,可以直接反应出模板本身的情况。需要强调的是,高质量的 PCR产物才可能得到高质量的测序结果,如果您对PCR产物的纯度不很确定,希望您可以将PCR产物进行克隆处理,以确保得到好的测序结果。以下图为例:该反应的背景信号较高,不利于碱基的判读。 查看大图 解决办法:改变PCR条件,重新扩增。或者可以将该PCR产物克隆到质粒中,初步筛选后进行单克隆测序。 Q-2.什么是碱基缺失?返回顶端A-2.以下图为例: 查看大图 碱基缺失常见在PCR产物中,特别是从基因组中扩增得到的PCR片段,上图的
186位缺失两个连续的T 解决方法: (1) 使用反向引物继续测序,以矫正缺失位点并达到测通的目的。或者将该PCR产物克隆到质粒中,挑取单克隆测序。 (2) 如果可以确定该PCR片段中不应该有缺失的位点,那么可以改变PCR反应条件,重新扩增。 Q-3.什么是引物不纯?返回顶端A-3.以下图为例: 查看大图 引物不纯造成移码现象,该种现象与模板杂在峰图都表现为背景峰较杂,但是引物不纯在峰图上表现的更有规律,一般在每一个主峰前或者后都有一个同一碱基的小峰。 解决办法:重新合成引物,或者将引物进行PAGE纯化后再进行测序。 Q-4.重复结构对测序有哪些影响?返回顶端A-4.以下图为例: 查看大图 重复结构将导致测序复制框的滑移,重复结构之后峰型混乱。 解决办法:使用反向引物对模板进行测序,测到该重复结构处,即可完成模板全长的拼接。 Q-5.什么是模板不单一?返回顶端A-5.以下图为例: (1) 菌液为非单克隆: 下图是pGEM-T载体测序的结果,在83位点处测序结果出现双峰(插入后双峰),即模板中含有两个或两个以上的相同载体,但是插入片段不同。 解决办法:重新挑取单克隆或者重新提取质粒。需要注意的是,重新进行PCR 反应或者酶切鉴定仅能证明该克隆含有插入片段,并不足以证明模板的单一。查看大图